An Efficient Big Data Anonymization Algorithm Based on Chaos and Perturbation Techniques †



Abstract
1. Introduction
2. Related Works
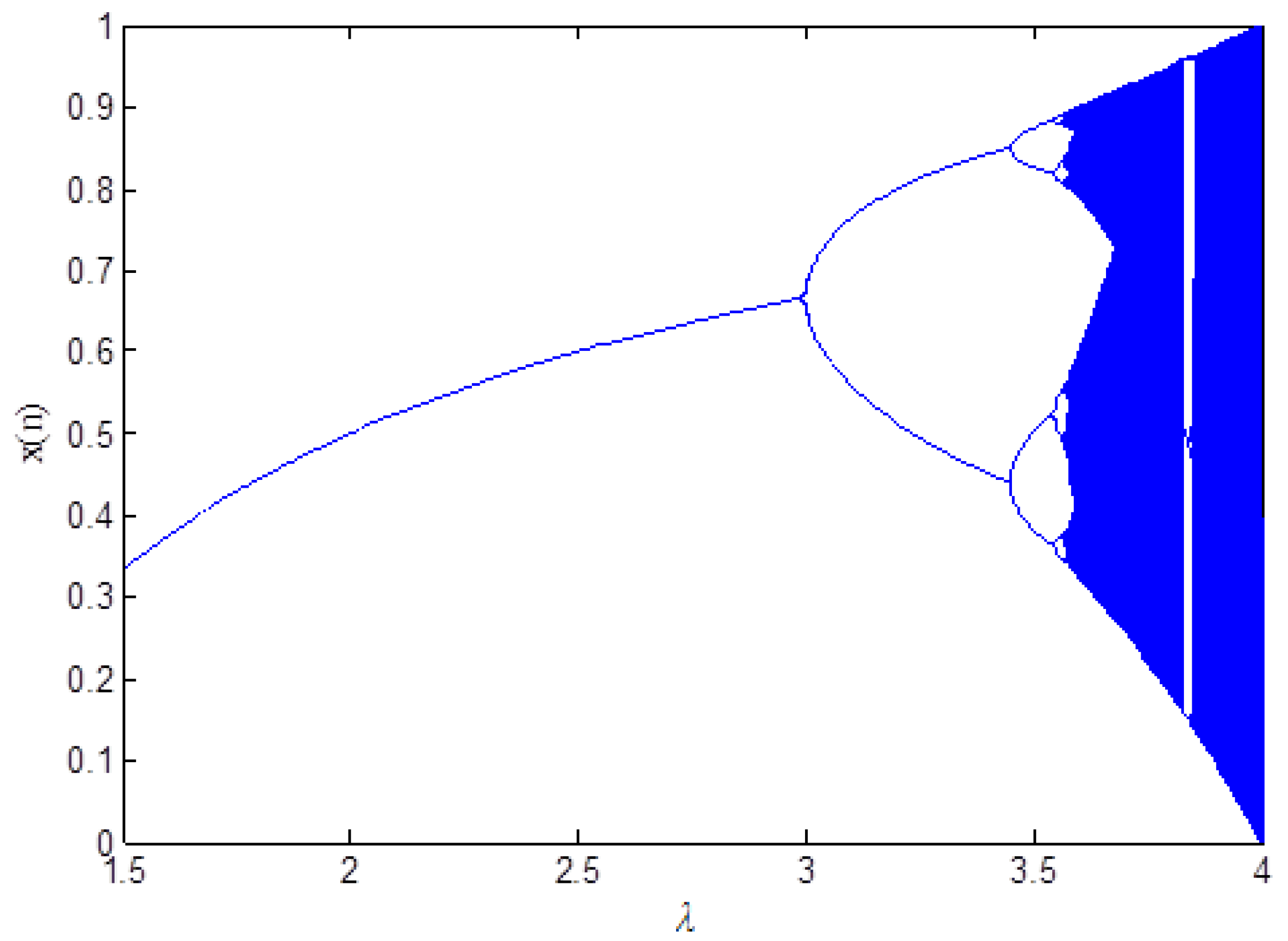
3. Proposed Privacy Preserving Algorithm
| Algorithm 1: Efficient Privacy Preserving Algorithm |
| Input: Original input data set D, quasi-identifier attributes QI (QI1, QI2, …, QIq), and sensitive attribute SA Output: Privacy preserved data set Dp Initial assignments: c = 0, λ = 3.99, iteration = 400 |
|
4. Privacy Analyses and Experimental Results
4.1. Data Set Description
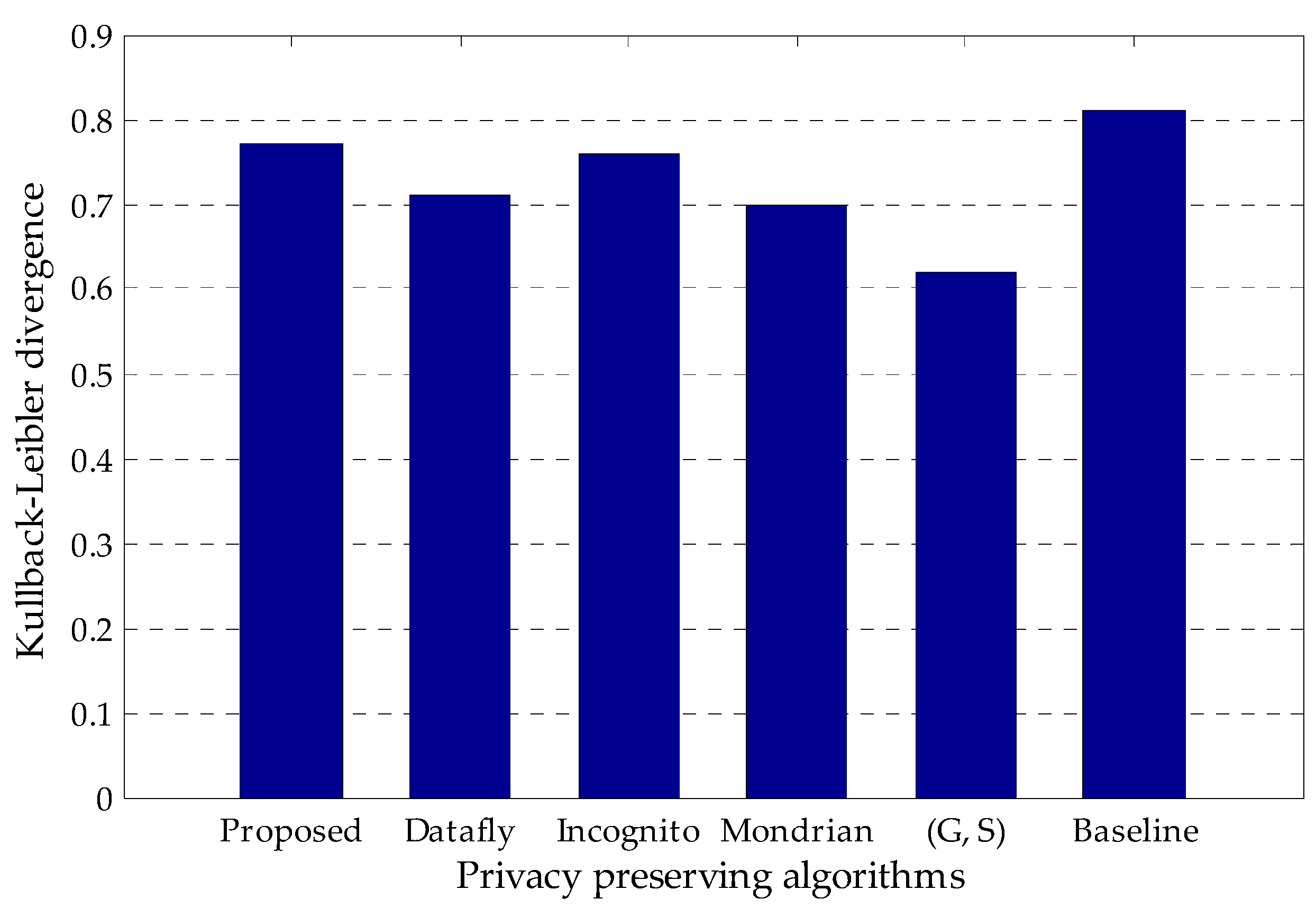
4.2. Kullback–Leibler Divergence
4.3. Probabilistic Anonymity
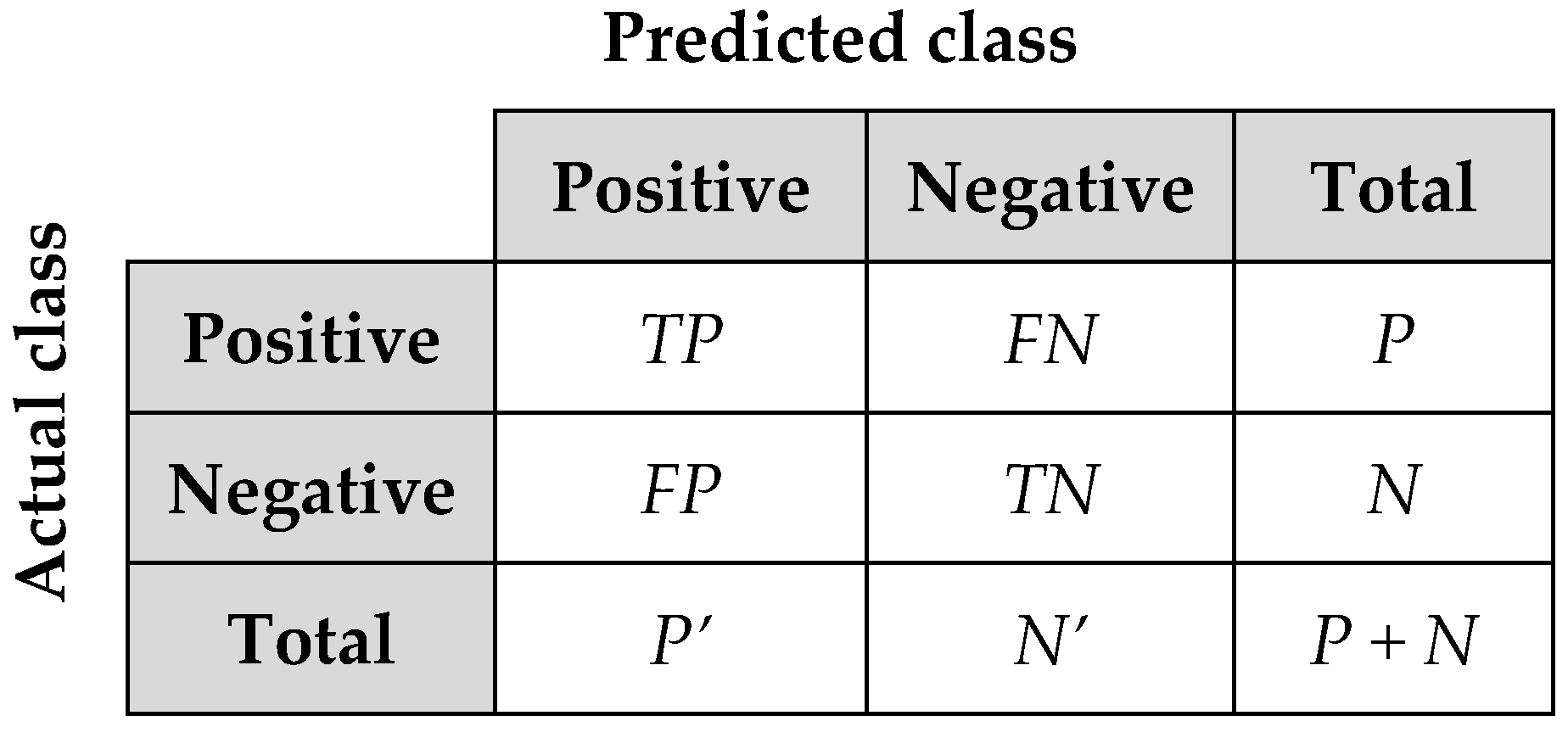
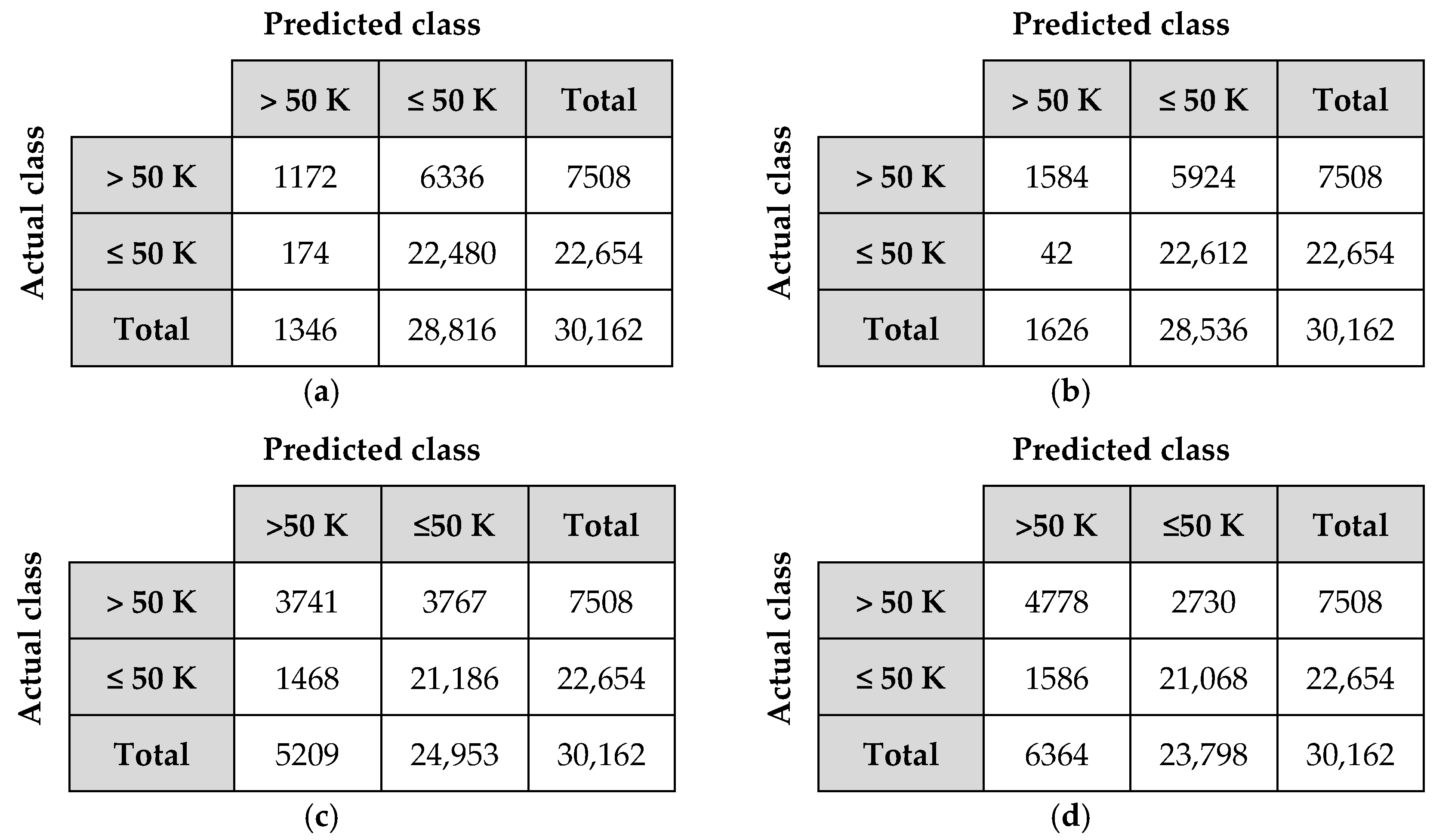
4.4. Classification Accuracy
4.5. F-Measure
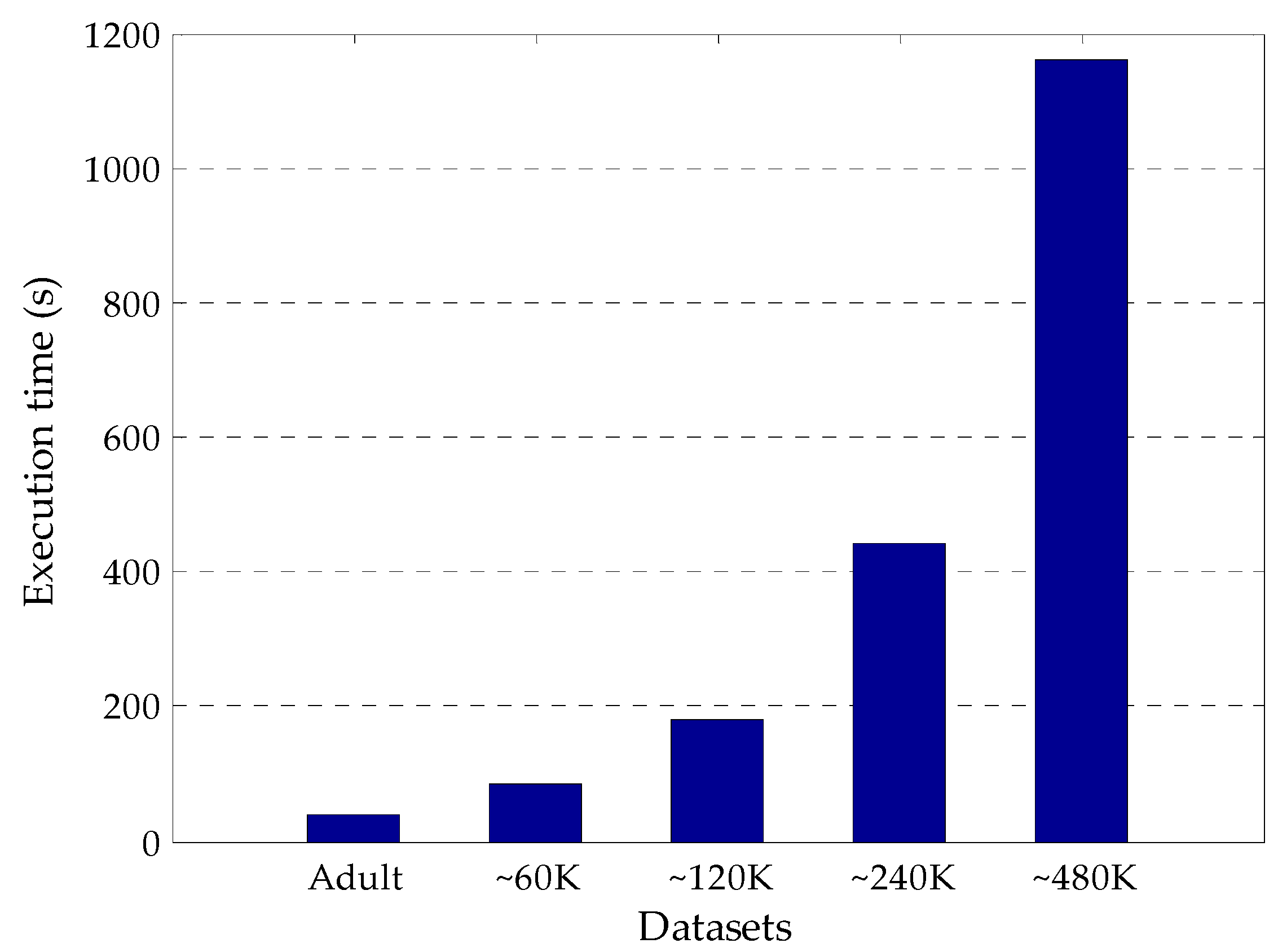
4.6. Execution Time
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Khan, N.; Yaqoob, I.; Hashem, I.A.T.; Inayat, Z.; Ali, W.K.M.; Alam, M.; Shiraz, M.; Gani, A. Big Data: Survey, Technologies, Opportunities, and Challenges. Sci. World J. 2014, 2014, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Matturdi, B.; Zhou, X.; Li, S.; Lin, F. Big Data security and privacy: A review. China Commun. 2014, 11, 135–145. [Google Scholar] [CrossRef]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, A.H. Big Data: The Next Frontier for Innovation, Competition, and Productivity; McKinsey Global Institute: New York, NY, USA, 2011.
- McCune, J.C. Data, data, everywhere. Manag. Rev. 1998, 87, 10–12. [Google Scholar]
- Tankard, C. Big data security. Netw. Secur. 2012, 2012, 5–8. [Google Scholar] [CrossRef]
- Gantz, J.; Reinsel, D. The digital universe in 2020: Big data, bigger digital shadows, and biggest growth in the Far East—United States. In IDC Country Brief, IDC Analyze the Future; IDC: Framingham, MA, USA, 2013. [Google Scholar]
- Bamford, J. The NSA Is Building the Country’s Biggest Spy Center (Watch What You Say). Wired. 2012. Available online: https://www.wired.com/2012/03/ff_nsadatacenter/all/1/ (accessed on 21 April 2018).
- Ardagna, C.A.; Damiani, E. Business Intelligence meets Big Data: An Overview on Security and Privacy. In Proceedings of the NSF Workshop on Big Data Security and Privacy, Dallas, TX, USA, 16–17 September 2014; pp. 1–6. [Google Scholar]
- Labrinidis, A.; Jagadish, H.V. Challenges and Opportunities with Big Data. Proc. VLDB Endow. 2012, 5, 2032–2033. [Google Scholar] [CrossRef]
- Lafuente, G. The big data security challenge. Netw. Secur. 2015, 2015, 12–14. [Google Scholar] [CrossRef]
- Eyüpoğlu, C.; Aydın, M.A.; Sertbaş, A.; Zaim, A.H.; Öneş, O. Preserving Individual Privacy in Big Data. Int. J. Inf. Technol. 2017, 10, 177–184. [Google Scholar]
- Yuksel, B.; Kupcu, A.; Ozkasap, O. Research issues for privacy and security of electronic health services. Future Gener. Comput. Syst. 2017, 68, 1–13. [Google Scholar] [CrossRef]
- Sicari, S.; Rizzardi, A.; Grieco, L.A.; Coen-Porisini, A. Security, privacy and trust in Internet of Things: The road ahead. Comput. Netw. 2015, 76, 146–164. [Google Scholar] [CrossRef]
- Yao, X.; Chen, Z.; Tian, Y. A lightweight attribute-based encryption scheme for the Internet of Things. Future Gener. Comput. Syst. 2015, 49, 104–112. [Google Scholar] [CrossRef]
- Henze, M.; Hermerschmidt, L.; Kerpen, D.; Häußling, R.; Rumpe, B.; Wehrle, K. A comprehensive approach to privacy in the cloud-based Internet of things. Future Gener. Comput. Syst. 2016, 56, 701–718. [Google Scholar] [CrossRef]
- Nayahi, J.J.V.; Kavitha, V. Privacy and utility preserving data clustering for data anonymization and distribution on Hadoop. Future Gener. Comput. Syst. 2017, 74, 393–408. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. Privacy-Preserving Data Mining: Models and Algorithms; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Fung, B.C.M.; Wang, K.; Chen, R.; Yu, P.S. Privacy preserving data publishing: A survey on recent developments. ACM Comput. Surv. 2010, 42, 1–53. [Google Scholar] [CrossRef]
- Fahad, A.; Tari, Z.; Almalawi, A.; Goscinski, A.; Khalil, I.; Mahmood, A. PPFSCADA: Privacy preserving framework for SCADA data publishing. Future Gener. Comput. Syst. 2014, 37, 496–511. [Google Scholar] [CrossRef]
- Xu, L.; Jiang, C.; Wang, J.; Yuan, J.; Ren, A.Y. Information Security in Big Data: Privacy and Data Mining. IEEE Access 2014, 2, 1149–1176. [Google Scholar]
- Nayahi, J.J.V.; Kavitha, V. An Efficient Clustering for Anonymizing Data and Protecting Sensitive Labels. Int. J. Uncertain. Fuzz. 2015, 23, 685–714. [Google Scholar] [CrossRef]
- Sweeney, L. Guaranteeing anonymity when sharing medical data, the Datafly system. Proc. AMIA Annu Fall Symp. 1997, 1997, 51–55. [Google Scholar]
- Sweeney, L. Datafly: A system for providing anonymity in medical data. In Proceedings of the Eleventh International Conference on Database Security, Lake Tahoe, CA, USA, 10–13 August 1997; pp. 356–381. [Google Scholar]
- Samarati, P.; Sweeney, L. Protecting privacy when disclosing information: K-anonymity and its enforcement through generalization and suppression. In Proceedings of the IEEE Symposium on Research in Security and Privacy, Oakland, CA, USA, 3–6 May 1998; pp. 188–206. [Google Scholar]
- Samarati, P. Protecting respondents’ identities in microdata release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzz. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzz. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Chen, T.-S.; Lee, W.-B.; Chen, J.; Kao, Y.-H.; Hou, P.-W. Reversible privacy preserving data mining: A combination of difference expansion and privacy preserving. J. Supercomput. 2013, 66, 907–917. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Mateo-Sanz, J.M.; Torra, V. Comparing SDC methods for microdata on the basis of information loss and disclosure risk. In Proceedings of the International Conference on New Techniques and Technologies for Statistics: Exchange of Technology and Knowhow, New York, NY, USA, 7–10 August 2001; pp. 807–826. [Google Scholar]
- Herranz, J.; Matwin, S.; Nin, J.; Torra, V. Classifying data from protected statistical datasets. Comput. Secur. 2010, 29, 875–890. [Google Scholar] [CrossRef]
- Kim, J.J.; Winkler, W.E. Multiplicative Noise for Masking Continuous Data; Census Statistical Research Report Series; Statistical Research Division: Washington, DC, USA, 2003. [Google Scholar]
- Liu, K.; Kargupta, H.; Ryan, J. Random projection-based multiplicative data perturbation for privacy preserving distributed data mining. IEEE Trans. Knowl. Data Eng. 2005, 18, 92–106. [Google Scholar]
- Yang, W.; Qiao, S. A novel anonymization algorithm: Privacy protection and knowledge preservation. Expert Syst. Appl. 2010, 37, 756–766. [Google Scholar] [CrossRef]
- Zhu, D.; Li, X.-B.; Wu, S. Identity disclosure protection: A data reconstruction approach for privacy-preserving data mining. Decis. Support Syst. 2009, 48, 133–140. [Google Scholar] [CrossRef]
- Chen, K.; Sun, G.; Liu, L. Towards attack-resilient geometric data perturbation. In Proceedings of the Seventh SIAM International Conference on Data Mining; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 78–89. [Google Scholar]
- Chen, K.; Liu, L. Privacy-preserving multiparty collaborative mining with geometric data perturbation. IEEE Trans. Parallel Distrib. Syst. 2009, 20, 1764–1776. [Google Scholar] [CrossRef]
- Chen, K.; Liu, L. Geometric data perturbation for privacy preserving outsourced data mining. Knowl. Inf. Syst. 2011, 29, 657–695. [Google Scholar] [CrossRef]
- Islam, M.Z.; Brankovic, L. Privacy preserving data mining: A noise addition framework using a novel clustering technique. Knowl. Based Syst. 2011, 24, 1214–1223. [Google Scholar] [CrossRef]
- Pinkas, B. Cryptographic techniques for privacy-preserving data mining. ACM SIGKDD Explor. Newslett. 2002, 4, 12–19. [Google Scholar] [CrossRef]
- Liu, H.; Huang, X.; Liu, J.K. Secure sharing of personal health records in cloud computing: Ciphertext-policy attribute-based signcryption. Future Gener. Comput. Syst. 2015, 52, 67–76. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Incognito: Efficient full domain k-anonymity. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 49–60. [Google Scholar]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering, Atlanta, GA, USA, 3–7 April 2006; p. 25. [Google Scholar]
- Machanavajjhala, A.; Gehrke, J.; Kifer, D.; Venkatasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 1–47. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the IEEE International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar]
- Sun, X.; Li, M.; Wang, H. A family of enhanced (L, α) diversity models for privacy preserving data publishing. Future Gener. Comput. Syst. 2011, 27, 348–356. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Privacy preserving data mining. In Proceedings of the ACM SIGMOD Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 439–450. [Google Scholar]
- Agrawal, D.; Aggarwal, C.C. On the design and quantification of privacy preserving data mining algorithms. In Proceedings of the Twentieth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Santa Barbara, CA, USA, 21–24 May 2001; pp. 247–255. [Google Scholar]
- Evfimievski, A.; Srikant, R.; Agrawal, R.; Gehrke, J. Privacy preserving mining of association rules. In Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’02), Edmonton, AB, Canada, 23–25 July 2002. [Google Scholar]
- Evfimevski, A.; Gehrke, J.; Srikant, R. Limiting privacy breaches in privacy preserving data mining. In Proceedings of the ACM SIGMOD/PODS Conference, San Diego, CA, USA, 9–12 June 2003. [Google Scholar]
- Rizvi, S.J.; Haritsa, J.R. Maintaining data privacy in association rule mining. In Proceedings of the 28th VLDB Conference, Hong Kong, China, 20–23 August 2002. [Google Scholar]
- Dwork, C. Differential privacy. In Proceedings of the 33rd International Conference on Automata, Languages and Programming, Venice, Italy, 9–16 July 2006; pp. 1–12. [Google Scholar]
- Zhang, X.; Qi, L.; Dou, W.; He, Q.; Leckie, C.; Ramamohanarao, K.; Salcic, Z. MRMondrian: Scalable Multidimensional Anonymisation for Big Data Privacy Preservation. IEEE Trans. Big Data 2017. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Z.; Miklau, G.; Winslett, M.; Xiao, X. Differential privacy in data publication and analysis. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 601–606. [Google Scholar]
- Gazeau, I.; Miller, D.; Palamidessi, C. Preserving differential privacy under finite-precision semantics. Theor. Comput. Sci. 2016, 655, 92–108. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography Conference (TCC), New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Li, M.; Zhu, L.; Zhang, Z.; Xu, R. Achieving differential privacy of trajectory data publishing in participatory sensing. Inf. Sci. 2017, 400–401, 1–13. [Google Scholar] [CrossRef]
- McSherry, F.; Talwar, K. Mechanism design via differential privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science, Providence, RI, USA, 20–23 October 2007; pp. 94–103. [Google Scholar]
- Mohammed, N.; Chen, R.; Fung, B.; Yu, P.S. Differentially private data release for data mining. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 493–501. [Google Scholar]
- Chen, R.; Fung, B.C.M.; Desai, B.C. Differentially Private trajectory Data Publication. arXiv, 2011; arXiv:1112.2020. [Google Scholar]
- Li, N.; Qardaji, W.; Su, D. On sampling, anonymization, and differential privacy or, k-anonymization meets differential privacy. In Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security, Seoul, Korea, 2–4 May 2012; pp. 32–33. [Google Scholar]
- Soria-Comas, J.; Domingo-Ferrer, J.; Sánchez, D.; Martínez, S. Enhancing data utility in differential privacy via microaggregation-based k-anonymity. VLDB J. 2014, 23, 771–794. [Google Scholar] [CrossRef]
- Fouad, M.R.; Elbassioni, K.; Bertino, E. A supermodularity-based differential privacy preserving algorithm for data anonymization. IEEE Trans. Knowl. Data Eng. 2014, 26, 1591–1601. [Google Scholar] [CrossRef]
- Wang, X.; Jin, Z. A differential privacy multidimensional data release model. In Proceedings of the 2nd IEEE International Conference on Computer and Communications, Chengdu, China, 14–17 October 2016; pp. 171–174. [Google Scholar]
- Xiao, Y.; Xiong, L.; Yuan, C. Differentially private data release through multidimensional partitioning. In Workshop on Secure Data Management; Springer: Berlin/Heidelberg, Germany, 2010; pp. 150–168. [Google Scholar]
- Zaman, A.N.K.; Obimbo, C.; Dara, R.A. An improved differential privacy algorithm to protect re-identification of data. In Proceedings of the 2017 IEEE Canada International Humanitarian Technology Conference, Toronto, ON, Canada, 21–22 July 2017; pp. 133–138. [Google Scholar]
- Koufogiannis, F.; Pappas, G.J. Differential privacy for dynamical sensitive data. In Proceedings of the IEEE 56th Annual Conference on Decision and Control, Melbourne, Australia, 12–15 December 2017; pp. 1118–1125. [Google Scholar]
- Li, L.-X.; Ding, Y.-S.; Wang, J.-Y. Differential Privacy Data Protection Method Based on Clustering. In Proceedings of the 2017 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Nanjing, China, 12–14 October 2017; pp. 11–16. [Google Scholar]
- Dong, B.; Liu, R.; Wang, W.H. PraDa: Privacy-preserving Data-Deduplication-as-a-Service. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1559–1568. [Google Scholar]
- Yavuz, E.; Yazıcı, R.; Kasapbaşı, M.C.; Yamaç, E. A chaos-based image encryption algorithm with simple logical functions. Comput. Electr. Eng. 2016, 54, 471–483. [Google Scholar] [CrossRef]
- Kohavi, R.; Becker, B. Adult Data Set, Data Mining and Visualization Silicon Graphics. May 1996. Available online: https://archive.ics.uci.edu/ml/datasets/adult (accessed on 21 April 2018).
- Lichman, M. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2013; Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 21 April 2018).
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concepts and Techniques, 3rd ed.; Elsevier, Morgan Kaufmann Publishers: San Francisco, CA, USA, 2012. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age | Sex | ZIP Code™ | Disease |
|---|---|---|---|
| 32 | Female | 34200 | Breast Cancer |
| 38 | Female | 34800 | Kidney Cancer |
| 64 | Male | 40008 | Skin Cancer |
| 69 | Female | 40001 | Bone Cancer |
| 53 | Male | 65330 | Skin Cancer |
| 56 | Male | 65380 | Kidney Cancer |
| 75 | Female | 20005 | Breast Cancer |
| 76 | Male | 20009 | Prostate Cancer |
| 41 | Male | 85000 | Lung Cancer |
| 47 | Male | 87000 | Lung Cancer |
| Age | Sex | ZIP Code™ | Disease |
|---|---|---|---|
| [30–40] | Female | 34 *** | Breast Cancer |
| [30–40] | Female | 34 *** | Kidney Cancer |
| [60–70] | * | 4000 * | Skin Cancer |
| [60–70] | * | 4000 * | Bone Cancer |
| [50–60] | Male | 653 ** | Skin Cancer |
| [50–60] | Male | 653 ** | Kidney Cancer |
| [70–80] | * | 2000 * | Breast Cancer |
| [70–80] | * | 2000 * | Prostate Cancer |
| [40–50] | Male | 8 **** | Lung Cancer |
| [40–50] | Male | 8 **** | Lung Cancer |
| Attribute | Attribute Type | Domain |
|---|---|---|
| age | continuous | [17–90] |
| workclass | nominal | Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked |
| fnlwgt | continuous | [19, 214–1, 226, 583] |
| education | nominal | Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th–8th, 12th, Masters, 1st–4th, 10th, Doctorate, 5th–6th, Preschool |
| education-num | continuous | [1–16] |
| marital-status | nominal | Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse |
| occupation | nominal | Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces |
| relationship | nominal | Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried |
| race | nominal | White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black |
| sex | nominal | Female, Male |
| capital-gain | continuous | [0–99,999] |
| capital-loss | continuous | [0–4356] |
| hours-per-week | continuous | [1–99] |
| native-country | nominal | United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US (Guam-USVI-etc.), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad & Tobago, Peru, Hong, Holand-The Netherlands |
| income (class att.) | nominal | “>50 K” and “≤50 K” |
| Data Sets | 2-Fold Cross Validation | 5-Fold Cross Validation | 10-Fold Cross Validation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VP | OneR | NB | J48 | VP | OneR | NB | J48 | VP | OneR | NB | J48 | ||
| Adult | Original | 77.84 | 80.21 | 82.75 | 85.03 | 78.36 | 80.21 | 82.84 | 85.71 | 78.42 | 80.22 | 82.88 | 85.73 |
| Privacy Preserved | 77.84 | 80.21 | 82.55 | 85.14 | 78.36 | 80.21 | 82.59 | 85.54 | 78.42 | 80.22 | 82.64 | 85.69 | |
| ~60 K | Original | 78.41 | 80.24 | 82.78 | 87.19 | 78.44 | 75.45 | 82.90 | 88.94 | 78.43 | 75.54 | 82.87 | 89.43 |
| Privacy Preserved | 78.41 | 80.24 | 82.58 | 86.92 | 78.44 | 75.45 | 82.65 | 88.73 | 78.43 | 75.54 | 82.64 | 89.31 | |
| ~120 K | Original | 78.45 | 78.16 | 82.83 | 92.15 | 78.46 | 81.20 | 82.88 | 96.95 | 78.45 | 82.31 | 82.89 | 98.13 |
| Privacy Preserved | 78.45 | 78.16 | 82.62 | 92.31 | 78.46 | 81.20 | 82.66 | 96.86 | 78.45 | 82.31 | 82.65 | 98.18 | |
| ~240 K | Original | 78.47 | 83.24 | 82.87 | 98.41 | 78.43 | 86.04 | 82.90 | 99.84 | 78.44 | 87.09 | 82.90 | 99.89 |
| Privacy Preserved | 78.47 | 83.24 | 82.65 | 98.39 | 78.43 | 86.04 | 82.65 | 99.83 | 78.44 | 87.09 | 82.65 | 99.89 | |
| ~480 K | Original | 78.40 | 88.69 | 82.90 | 99.86 | 78.42 | 89.30 | 82.90 | 99.98 | 78.44 | 88.73 | 82.90 | 99.99 |
| Privacy Preserved | 78.40 | 88.69 | 82.66 | 99.85 | 78.42 | 89.30 | 82.66 | 99.98 | 78.44 | 88.73 | 82.66 | 99.99 | |
| Privacy Preserving Algorithms | k | Classification Algorithms | |||
|---|---|---|---|---|---|
| VP | OneR | NB | J48 | ||
| Original Adult data set | – | 78.42 | 80.22 | 82.88 | 85.73 |
| Datafly [23] | 5 | 78.36 | 80.18 | 82.85 | 85.35 |
| Incognito [41] | 5 | 78.38 | 80.17 | 82.75 | 85.30 |
| Mondrian [42] | 5 | 78.38 | 80.17 | 82.83 | 85.00 |
| Entropy l-diversity (l = 2) [43] | 5 | 78.38 | 80.17 | 82.40 | 85.42 |
| (G, S) [21] | 5 | 78.43 | 80.21 | 83.46 | 85.16 |
| KNN-(G, S) [16] | 5 | 78.38 | 80.16 | 82.72 | 85.26 |
| Datafly [23] | 10 | 78.38 | 80.18 | 82.85 | 85.35 |
| Incognito [41] | 10 | 78.38 | 80.15 | 82.44 | 85.30 |
| Mondrian [42] | 10 | 78.38 | 80.17 | 82.83 | 84.97 |
| Entropy l-diversity (l = 2) [43] | 10 | 78.37 | 80.18 | 82.40 | 85.40 |
| (G, S) [21] | 10 | 78.43 | 80.21 | 83.46 | 85.16 |
| KNN-(G, S) [16] | 10 | 78.38 | 80.16 | 83.72 | 85.26 |
| Datafly [23] | 25 | 78.38 | 80.18 | 82.85 | 85.38 |
| Incognito [41] | 25 | 78.38 | 80.17 | 82.71 | 85.31 |
| Mondrian [42] | 25 | 78.38 | 80.17 | 82.84 | 84.99 |
| Entropy l-diversity (l = 2) [43] | 25 | 78.38 | 80.17 | 82.40 | 85.42 |
| (G, S) [21] | 25 | 78.44 | 80.20 | 82.12 | 85.16 |
| KNN-(G, S) [16] | 25 | 78.39 | 80.19 | 83.01 | 85.40 |
| Datafly [23] | 50 | 78.38 | 80.17 | 83.11 | 85.37 |
| Incognito [41] | 50 | 78.38 | 80.17 | 82.71 | 85.31 |
| Mondrian [42] | 50 | 78.38 | 80.17 | 82.85 | 85.05 |
| Entropy l-diversity (l = 2) [43] | 50 | 78.38 | 80.17 | 82.40 | 84.42 |
| (G, S) [21] | 50 | 78.42 | 80.17 | 83.44 | 85.35 |
| KNN-(G, S) [16] | 50 | 78.39 | 80.11 | 83.50 | 85.69 |
| Proposed Algorithm | – | 78.42 | 80.22 | 82.64 | 85.69 |
| Data Sets | 2-Fold Cross Validation | 5-Fold Cross Validation | 10-Fold Cross Validation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VP | OneR | NB | J48 | VP | OneR | NB | J48 | VP | OneR | NB | J48 | ||
| Adult | Original | 0.709 | 0.750 | 0.817 | 0.845 | 0.721 | 0.750 | 0.818 | 0.853 | 0.722 | 0.750 | 0.819 | 0.853 |
| Privacy Preserved | 0.709 | 0.750 | 0.814 | 0.845 | 0.721 | 0.750 | 0.814 | 0.851 | 0.722 | 0.750 | 0.815 | 0.853 | |
| ~60 K | Original | 0.723 | 0.750 | 0.818 | 0.869 | 0.723 | 0.729 | 0.819 | 0.887 | 0.723 | 0.731 | 0.819 | 0.892 |
| Privacy Preserved | 0.723 | 0.750 | 0.814 | 0.866 | 0.723 | 0.729 | 0.815 | 0.885 | 0.723 | 0.731 | 0.815 | 0.891 | |
| ~120 K | Original | 0.724 | 0.765 | 0.818 | 0.920 | 0.724 | 0.803 | 0.819 | 0.969 | 0.723 | 0.816 | 0.819 | 0.981 |
| Privacy Preserved | 0.724 | 0.765 | 0.815 | 0.922 | 0.724 | 0.803 | 0.815 | 0.968 | 0.723 | 0.816 | 0.815 | 0.982 | |
| ~240 K | Original | 0.724 | 0.825 | 0.819 | 0.984 | 0.723 | 0.858 | 0.819 | 0.998 | 0.723 | 0.870 | 0.819 | 0.999 |
| Privacy Preserved | 0.724 | 0.825 | 0.815 | 0.984 | 0.723 | 0.858 | 0.815 | 0.998 | 0.723 | 0.870 | 0.815 | 0.999 | |
| ~480 K | Original | 0.722 | 0.886 | 0.819 | 0.999 | 0.723 | 0.893 | 0.819 | 1.000 | 0.723 | 0.887 | 0.819 | 1.000 |
| Privacy Preserved | 0.722 | 0.886 | 0.815 | 0.998 | 0.723 | 0.893 | 0.815 | 1.000 | 0.723 | 0.887 | 0.815 | 1.000 | |
| Privacy Preserving Algorithms | k | Classification Algorithms | |||
|---|---|---|---|---|---|
| VP | OneR | NB | J48 | ||
| Original Adult data set | – | 0.722 | 0.750 | 0.819 | 0.853 |
| Datafly [23] | 5 | 0.722 | 0.750 | 0.819 | 0.850 |
| Incognito [41] | 5 | 0.722 | 0.749 | 0.818 | 0.847 |
| Mondrian [42] | 5 | 0.722 | 0.749 | 0.818 | 0.843 |
| Entropy l-diversity (l = 2) [43] | 5 | 0.722 | 0.749 | 0.808 | 0.849 |
| (G, S) [21] | 5 | 0.723 | 0.750 | 0.829 | 0.845 |
| KNN-(G, S) [16] | 5 | 0.722 | 0.749 | 0.817 | 0.847 |
| Datafly [23] | 10 | 0.722 | 0.749 | 0.819 | 0.849 |
| Incognito [41] | 10 | 0.722 | 0.749 | 0.812 | 0.848 |
| Mondrian [42] | 10 | 0.722 | 0.749 | 0.818 | 0.840 |
| Entropy l-diversity (l = 2) [43] | 10 | 0.722 | 0.750 | 0.808 | 0.849 |
| (G, S) [21] | 10 | 0.723 | 0.750 | 0.829 | 0.845 |
| KNN-(G, S) [16] | 10 | 0.722 | 0.749 | 0.817 | 0.847 |
| Datafly [23] | 25 | 0.722 | 0.749 | 0.819 | 0.849 |
| Incognito [41] | 25 | 0.722 | 0.749 | 0.817 | 0.847 |
| Mondrian [42] | 25 | 0.722 | 0.749 | 0.818 | 0.840 |
| Entropy l-diversity (l = 2) [43] | 25 | 0.722 | 0.749 | 0.808 | 0.849 |
| (G, S) [21] | 25 | 0.723 | 0.750 | 0.808 | 0.845 |
| KNN-(G, S) [16] | 25 | 0.722 | 0.749 | 0.822 | 0.849 |
| Datafly [23] | 50 | 0.722 | 0.749 | 0.825 | 0.848 |
| Incognito [41] | 50 | 0.722 | 0.749 | 0.817 | 0.847 |
| Mondrian [42] | 50 | 0.722 | 0.749 | 0.818 | 0.842 |
| Entropy l-diversity (l = 2) [43] | 50 | 0.722 | 0.749 | 0.808 | 0.849 |
| (G, S) [21] | 50 | 0.723 | 0.749 | 0.830 | 0.848 |
| KNN-(G, S) [16] | 50 | 0.722 | 0.749 | 0.836 | 0.853 |
| Proposed Algorithm | – | 0.722 | 0.750 | 0.815 | 0.853 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eyupoglu, C.; Aydin, M.A.; Zaim, A.H.; Sertbas, A. An Efficient Big Data Anonymization Algorithm Based on Chaos and Perturbation Techniques. Entropy 2018, 20, 373. https://doi.org/10.3390/e20050373
Eyupoglu C, Aydin MA, Zaim AH, Sertbas A. An Efficient Big Data Anonymization Algorithm Based on Chaos and Perturbation Techniques. Entropy. 2018; 20(5):373. https://doi.org/10.3390/e20050373
Chicago/Turabian StyleEyupoglu, Can, Muhammed Ali Aydin, Abdul Halim Zaim, and Ahmet Sertbas. 2018. "An Efficient Big Data Anonymization Algorithm Based on Chaos and Perturbation Techniques" Entropy 20, no. 5: 373. https://doi.org/10.3390/e20050373
APA StyleEyupoglu, C., Aydin, M. A., Zaim, A. H., & Sertbas, A. (2018). An Efficient Big Data Anonymization Algorithm Based on Chaos and Perturbation Techniques. Entropy, 20(5), 373. https://doi.org/10.3390/e20050373