An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension

Abstract
1. Introduction
2. Motivation
2.1. Sampling Issues in High-Dimensional Space
2.1.1. Sampling from High-Dimensional Gaussian Distribution
- Perturbation: Draw a Gaussian random vector .
- Optimization: Solve the linear system .
2.1.2. Designing Efficient Proposals in MH Algorithms
2.2. Auxiliary Variables and Data Augmentation Strategies
- the first condition is satisfied thanks to the definition of the joint distribution in (9), provided that is a density of a proper distribution;
- for the second condition, it can be noticed that if the first condition is met, Fubini–Tonelli’s theorem allows us to claim thatThis shows that as defined in is a valid probability density function.
- Sample from ;
- Sample from .
3. Proposed Approach
3.1. Correlated Gaussian Noise
| Algorithm 1 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by . |
Initialize: , , such that
|
| Algorithm 2 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by . |
Initialize: , , such that
|
3.2. Scale Mixture of Gaussian Noise
3.2.1. Problem Formulation
- 1.
- ,
- 2.
- ,
3.2.2. Proposed Algorithms
- Suppose first that there exists a constant such thatThen, results in Section 3.1 with a Gaussian noise can be extended to scale mixture of Gaussian noise by substituting—at each iteration t— for , and by choosing in Algorithm 1 and in Algorithm 2. The only difference is that an additional step must be added to the Gibbs algorithm to draw samples of the mixing variables from their conditional distributions given , , and .
- Otherwise, when satisfying (34) does not exist, results in Section 3.1 remain also valid when, at each iteration t, for a given value of , we replace by . However, there is a main difference with respect to the case when , which is that depends on the value of the mixing variable and hence can take different values along the iterations. Subsequently, will denote the chosen value of for a given value of . Here again, two strategies can be distinguished for setting , depending on the dependencies one wants to eliminate through the DA strategy.
| Algorithm 3 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by in the case of a scale mixture of Gaussian noise. |
Initialize: , , , ,
|
| Algorithm 4 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by in the case of a scale mixture of Gaussian noise. |
Initialize: , , , ,
|
3.2.3. Partially Collapsed Gibbs Sampling
| Algorithm 5 PCGS in the case of a scale mixture of Gaussian noise. |
Initialize: , , ,
|
3.3. High-Dimensional Gaussian Distribution
- If the prior precision matrix and the observation matrix can be diagonalized in the same basis, it can be of interest to add the auxiliary variable in the data fidelity term. Following Algorithm 1, let such that andThe resulting conditional distribution of the target signal given the auxiliary variable and the vector of observation is a Gaussian distribution with the following parameters:Then, sampling from the target signal can be performed by passing to the transform domain where and are diagonalizable (e.g., Fourier domain when and are circulant).Similarly, if it is possible to write , such that and can be diagonalized in the same basis, we suggest the introduction of an extra auxiliary variable independent of in the prior term to eliminate the coupling introduced by when passing to the transform domain. Let be such that and let the distribution of conditionally to be given byThe joint distribution of the unknown parameters is given byIt follows that the minus logarithm of the conditional distribution of given , , and is Gaussian with parameters:and
- If and are not diagonalizable in the same basis, the introduction of an auxiliary variable either in the data fidelity term or the prior allows us to eliminate the coupling between these two heterogeneous operators. Let such that andThen, the parameters of the Gaussian posterior distribution of given read:Note that if has some simple structure (e.g,. diagonal, block diagonal, sparse, circulant, etc.), the precision matrix (50) will inherit this simple structure.Otherwise, if does not present any specific structure, one could apply the proposed DA method to both data fidelity and prior terms. It suffices to introduce an extra auxiliary variable in the prior law, additionally to the auxiliary variable in (49). Let be such that andThen, the posterior distribution of given and is Gaussian with the following parameters:andwhere
3.4. Sampling the Auxiliary Variable
- (1)
- Generate ,
- (2)
- Generate with ,
- (3)
- Compute ,
- In the particular case when is circulant, sampling can be performed in the Fourier domain. More generally, since is symmetric, there exists an orthogonal matrix such that is diagonal with positive diagonal entries. It follows that sampling from the Gaussian distribution with covariance matrix can be fulfilled easily within the basis defined by the matrix .
- Suppose that satisfies with , which is the case, for example, of tight frame synthesis operators or decimation matrices. Note that . We then have:It follows that a sample from the Gaussian distribution with covariance matrix can be obtained as follows:where and are independent Gaussian random vectors with covariance matrices equal to and , respectively.
- Suppose that with and . Hence, one can set and such thatFor example, for , we have . Then, we can set . It follows thatIt appears that if it is possible to draw merely random vectors and from the Gaussian distributions with covariance matrices and , respectively (for example, when is a tight frame analysis operator and is a convolution matrix with periodic boundary condition), a sample from the Gaussian distribution with a covariance matrix can be obtained as follows:
4. Application to Multichannel Image Recovery in the Presence of Gaussian Noise
4.1. Problem Formulation
4.2. Sampling from the Posterior Distribution of the Wavelet Coefficients
|
4.3. Hyperparameters Estimation
4.3.1. Separation Strategy
4.3.2. Prior and Posterior Distribution for the Hyperparameters
4.3.3. Initialization
4.4. Experimental Results
5. Application to Image Recovery in the Presence of Two Mixed Gaussian Noise Terms
5.1. Problem Formulation
5.2. Prior Distributions
Posterior Distributions
- where such that
- , where is the Beta distribution and and are the cardinals of the sets and , respectively, so that ,
- ,
- ,
- .
5.3. Sampling from the Posterior Distribution of
5.3.1. First Variant
| AuxV1 |
|
5.3.2. Second Variant
| AuxV2 |
|
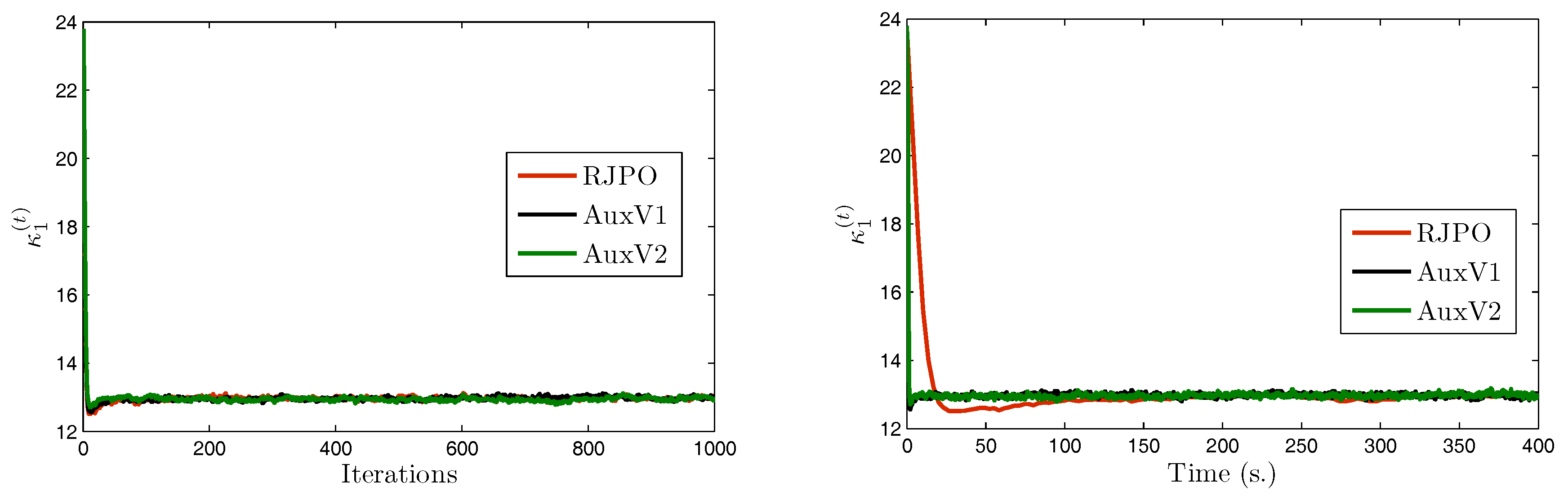
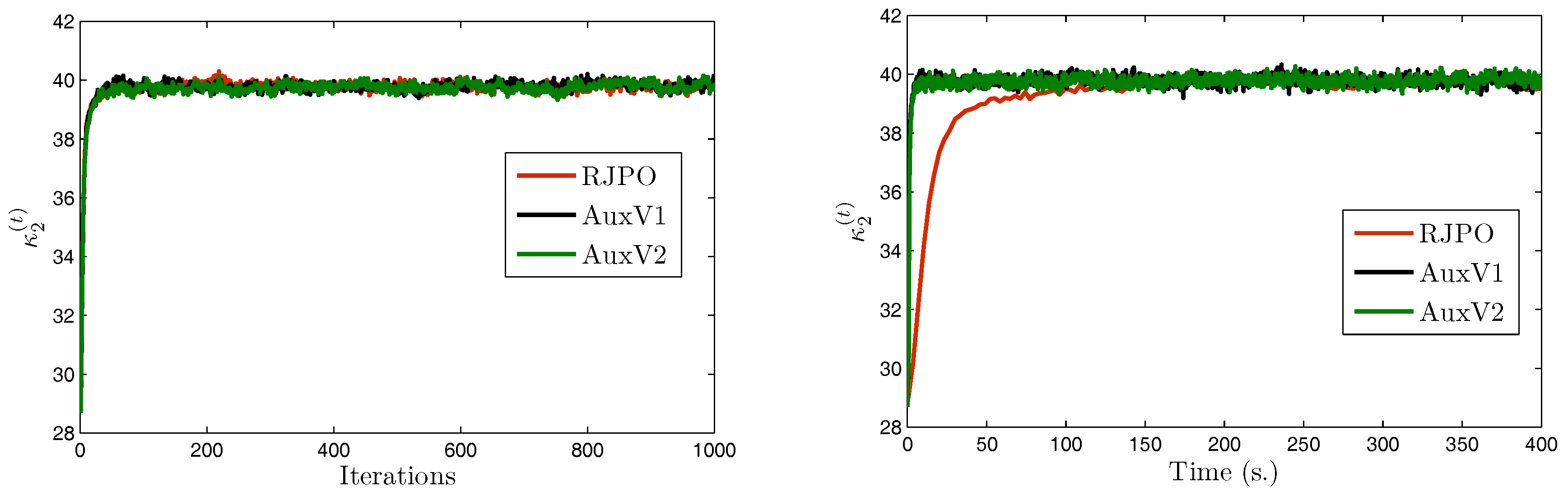
5.4. Experimental Results
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Bertero, M.; Boccacci, P. Introduction to Inverse Problems in Imaging; CRC Press: Boca Raton, FL, USA, 1998. [Google Scholar]
- Demoment, G. Image reconstruction and restoration: Overview of common estimation structure and problems. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 2024–2036. [Google Scholar] [CrossRef]
- Marnissi, Y.; Zheng, Y.; Chouzenoux, E.; Pesquet, J.C. A Variational Bayesian Approach for Image Restoration. Application to Image Deblurring with Poisson-Gaussian Noise. IEEE Trans. Comput. Imaging 2017, 3, 722–737. [Google Scholar] [CrossRef]
- Chouzenoux, E.; Jezierska, A.; Pesquet, J.C.; Talbot, H. A Convex Approach for Image Restoration with Exact Poisson-Gaussian Likelihood. SIAM J. Imaging Sci. 2015, 8, 2662–2682. [Google Scholar] [CrossRef]
- Chaari, L.; Pesquet, J.C.; Tourneret, J.Y.; Ciuciu, P.; Benazza-Benyahia, A. A Hierarchical Bayesian Model for Frame Representation. IEEE Trans. Signal Process. 2010, 58, 5560–5571. [Google Scholar] [CrossRef]
- Pustelnik, N.; Benazza-Benhayia, A.; Zheng, Y.; Pesquet, J.C. Wavelet-Based Image Deconvolution and Reconstruction. In Wiley Encyclopedia of Electrical and Electronics Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1999; pp. 1–34. [Google Scholar]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Liu, J.S. Monte Carlo Strategies in Scientific Computing; Springer Series in Statistics; Springer-Verlag: New York, NY, USA, 2001. [Google Scholar]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Interdisciplinary Statistics; Chapman and Hall/CRC: Boca Raton, FL, USA, 1999. [Google Scholar]
- Gamerman, D.; Lopes, H.F. Markov Chain Monte Carlo: Stochastic Simulation for Bayesian Inference; Texts in Statistical Science; Chapman and Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Glynn, P.W.; Iglehart, D.L. Importance sampling for stochastic simulations. Manag. Sci. 1989, 35, 1367–1392. [Google Scholar] [CrossRef]
- Gilks, W.R.; Wild, P. Adaptive rejection sampling for Gibbs sampling. Appl. Stat. 1992, 41, 337–348. [Google Scholar] [CrossRef]
- Neal, R.M. MCMC using Hamiltonian dynamics. In Handbook of Markov Chain Monte Carlo; Brooks, S., Gelman, A., Jones, G.L., Meng, X.L., Eds.; CRC Press: Boca Raton, FL, USA, 2011; pp. 113–162. [Google Scholar]
- Jarner, S.F.; Hansen, E. Geometric ergodicity of Metropolis algorithms. Stoch. Process. Appl. 2000, 85, 341–361. [Google Scholar] [CrossRef]
- Gilks, W.R.; Best, N.; Tan, K. Adaptive rejection Metropolis sampling within Gibbs sampling. Appl. Stat. 1995, 44, 455–472. [Google Scholar] [CrossRef]
- Dobigeon, N.; Moussaoui, S.; Coulon, M.; Tourneret, J.Y.; Hero, A.O. Joint Bayesian Endmember Extraction and Linear Unmixing for Hyperspectral Imagery. IEEE Trans. Signal Process. 2009, 57, 4355–4368. [Google Scholar] [CrossRef]
- Roberts, G.O.; Gelman, A.; Gilks, W.R. Weak convergence and optimal scaling or random walk Metropolis algorithms. Ann. Appl. Probab. 1997, 7, 110–120. [Google Scholar] [CrossRef]
- Sherlock, C.; Fearnhead, P.; Roberts, G.O. The random walk Metropolis: Linking theory and practice through a case study. Stat. Sci. 2010, 25, 172–190. [Google Scholar] [CrossRef]
- Roberts, G.O.; Stramer, O. Langevin diffusions and Metropolis-Hastings algorithms. Methodol. Comput. Appl. Probab. 2002, 4, 337–357. [Google Scholar] [CrossRef]
- Martin, J.; Wilcox, C.L.; Burstedde, C.; Ghattas, O. A Stochastic Newton MCMC Method for Large-Scale Statistical Inverse Problems with Application to Seismic Inversion. SIAM J. Sci. Comput. 2012, 34, 1460–1487. [Google Scholar] [CrossRef]
- Zhang, Y.; Sutton, C.A. Quasi-Newton Methods for Markov Chain Monte Carlo. In Proceedings of the Neural Information Processing Systems (NIPS 2011), Granada, Spain, 12–17 December 2011; pp. 2393–2401. [Google Scholar]
- Girolami, M.; Calderhead, B. Riemann manifold Langevin and Hamiltonian Monte Carlo methods. J. R. Stat. Soc. Ser. B Stat. Methodol. 2011, 73, 123–214. [Google Scholar] [CrossRef]
- Van Dyk, D.A.; Meng, X.L. The art of data augmentation. J. Comput. Graph. Stat. 2012, 10, 1–50. [Google Scholar] [CrossRef]
- Féron, O.; Orieux, F.; Giovannelli, J.F. Gradient Scan Gibbs Sampler: An efficient algorithm for high-dimensional Gaussian distributions. IEEE J. Sel. Top. Signal Process. 2016, 10, 343–352. [Google Scholar] [CrossRef]
- Rue, H. Fast sampling of Gaussian Markov random fields. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 325–338. [Google Scholar] [CrossRef]
- Geman, D.; Yang, C. Nonlinear image recovery with half-quadratic regularization. IEEE Trans. Image Process. 1995, 4, 932–946. [Google Scholar] [CrossRef] [PubMed]
- Chellappa, R.; Chatterjee, S. Classification of textures using Gaussian Markov random fields. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 959–963. [Google Scholar] [CrossRef]
- Rue, H.; Held, L. Gaussian Markov Random Fields: Theory and Applications; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Bardsley, J.M. MCMC-based image reconstruction with uncertainty quantification. SIAM J. Sci. Comput. 2012, 34, A1316–A1332. [Google Scholar] [CrossRef]
- Papandreou, G.; Yuille, A.L. Gaussian sampling by local perturbations. In Proceedings of the Neural Information Processing Systems 23 (NIPS 2010), Vancouver, BC, Canada, 6–11 December 2010; pp. 1858–1866. [Google Scholar]
- Orieux, F.; Féron, O.; Giovannelli, J.F. Sampling high-dimensional Gaussian distributions for general linear inverse problems. IEEE Signal Process. Lett. 2012, 19, 251–254. [Google Scholar] [CrossRef]
- Gilavert, C.; Moussaoui, S.; Idier, J. Efficient Gaussian sampling for solving large-scale inverse problems using MCMC. IEEE Trans. Signal Process. 2015, 63, 70–80. [Google Scholar] [CrossRef]
- Parker, A.; Fox, C. Sampling Gaussian distributions in Krylov spaces with conjugate gradients. SIAM J. Sci. Comput. 2012, 34, B312–B334. [Google Scholar] [CrossRef]
- Lasanen, S. Non-Gaussian statistical inverse problems. Inverse Prob. Imaging 2012, 6, 267–287. [Google Scholar] [CrossRef]
- Bach, F.; Jenatton, R.; Mairal, J.; Obozinski, G. Optimization with sparsity-inducing penalties. Found. Trends Mach. Learn. 2012, 4, 1–106. [Google Scholar] [CrossRef]
- Kamilov, U.; Bostan, E.; Unser, M. Generalized total variation denoising via augmented Lagrangian cycle spinning with Haar wavelets. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2012), Kyoto, Japan, 25–30 March 2012; pp. 909–912. [Google Scholar]
- Kolehmainen, V.; Lassas, M.; Niinimäki, K.; Siltanen, S. Sparsity-promoting Bayesian inversion. Inverse Prob. 2012, 28, 025005. [Google Scholar] [CrossRef]
- Stuart, M.A.; Voss, J.; Wiberg, P. Conditional Path Sampling of SDEs and the Langevin MCMC Method. Commun. Math. Sci. 2004, 2, 685–697. [Google Scholar] [CrossRef]
- Marnissi, Y.; Chouzenoux, E.; Benazza-Benyahia, A.; Pesquet, J.C.; Duval, L. Reconstruction de signaux parcimonieux à l’aide d’un algorithme rapide d’échantillonnage stochastique. In Proceedings of the GRETSI, Lyon, France, 8–11 September 2015. (In French). [Google Scholar]
- Marnissi, Y.; Benazza-Benyahia, A.; Chouzenoux, E.; Pesquet, J.C. Majorize-Minimize adapted Metropolis-Hastings algorithm. Application to multichannel image recovery. In Proceedings of the European Signal Processing Conference (EUSIPCO 2014), Lisbon, Portugal, 1–5 September 2014; pp. 1332–1336. [Google Scholar]
- Vacar, C.; Giovannelli, J.F.; Berthoumieu, Y. Langevin and Hessian with Fisher approximation stochastic sampling for parameter estimation of structured covariance. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2011), Prague, Czech Republic, 22–27 May 2011; pp. 3964–3967. [Google Scholar]
- Schreck, A.; Fort, G.; Le Corff, S.; Moulines, E. A shrinkage-thresholding Metropolis adjusted Langevin algorithm for Bayesian variable selection. IEEE J. Sel. Top. Signal Process. 2016, 10, 366–375. [Google Scholar] [CrossRef]
- Pereyra, M. Proximal Markov chain Monte Carlo algorithms. Stat. Comput. 2016, 26, 745–760. [Google Scholar] [CrossRef]
- Atchadé, Y.F. An adaptive version for the Metropolis adjusted Langevin algorithm with a truncated drift. Methodol. Comput. Appl. Probab. 2006, 8, 235–254. [Google Scholar] [CrossRef]
- Tanner, M.A.; Wong, W.H. The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 1987, 82, 528–540. [Google Scholar] [CrossRef]
- Mira, A.; Tierney, L. On the use of auxiliary variables in Markov chain Monte Carlo sampling. Technical Report, 1997. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.35.7814 (accessed on 1 February 2018).
- Robert, C.; Casella, G. Monte Carlo Statistical Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Doucet, A.; Sénécal, S.; Matsui, T. Space alternating data augmentation: Application to finite mixture of gaussians and speaker recognition. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2005), Philadelphia, PA, USA, 23 March 2005; pp. 708–713. [Google Scholar]
- Févotte, C.; Cappé, O.; Cemgil, A.T. Efficient Markov chain Monte Carlo inference in composite models with space alternating data augmentation. In Proceedings of the IEEE Statistical Signal Processing Workshop (SSP 2011), Nice, France, 28–30 June 2011; pp. 221–224. [Google Scholar]
- Giovannelli, J.F. Unsupervised Bayesian convex deconvolution based on a field with an explicit partition function. IEEE Trans. Image Process. 2008, 17, 16–26. [Google Scholar] [CrossRef] [PubMed]
- David, H.M. Auxiliary Variable Methods for Markov Chain Monte Carlo with Applications. J. Am. Stat. Assoc. 1997, 93, 585–595. [Google Scholar]
- Hurn, M. Difficulties in the use of auxiliary variables in Markov chain Monte Carlo methods. Stat. Comput. 1997, 7, 35–44. [Google Scholar] [CrossRef]
- Damlen, P.; Wakefield, J.; Walker, S. Gibbs sampling for Bayesian non-conjugate and hierarchical models by using auxiliary variables. J. R. Stat. Soc. Ser. B Stat. Methodol. 1999, 61, 331–344. [Google Scholar] [CrossRef]
- Duane, S.; Kennedy, A.; Pendleton, B.J.; Roweth, D. Hybrid Monte Carlo. Phys. Lett. B 1987, 195, 216–222. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. J. Appl. Stat. 1993, 20, 25–62. [Google Scholar] [CrossRef]
- Idier, J. Convex Half-Quadratic Criteria and Interacting Auxiliary Variables for Image Restoration. IEEE Trans. Image Process. 2001, 10, 1001–1009. [Google Scholar] [CrossRef] [PubMed]
- Geman, D.; Reynolds, G. Constrained restoration and the recovery of discontinuities. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 367–383. [Google Scholar] [CrossRef]
- Champagnat, F.; Idier, J. A connection between half-quadratic criteria and EM algorithms. IEEE Signal Process. Lett. 2004, 11, 709–712. [Google Scholar] [CrossRef]
- Nikolova, M.; Ng, M.K. Analysis of half-quadratic minimization methods for signal and image recovery. SIAM J. Sci. Comput. 2005, 27, 937–966. [Google Scholar] [CrossRef]
- Bect, J.; Blanc-Féraud, L.; Aubert, G.; Chambolle, A. A l1-Unified Variational Framework for Image Restoration. In Proceedings of the European Conference on Computer Vision (ECCV 2004), Prague, Czech Republic, 11–14 May 2004; pp. 1–13. [Google Scholar]
- Cavicchioli, R.; Chaux, C.; Blanc-Féraud, L.; Zanni, L. ML estimation of wavelet regularization hyperparameters in inverse problems. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 1553–1557. [Google Scholar]
- Ciuciu, P. Méthodes Markoviennes en Estimation Spectrale Non Paramétriques. Application en Imagerie Radar Doppler. Ph.D. Thesis, Université Paris Sud-Paris XI, Orsay, France, October 2000. [Google Scholar]
- Andrews, D.F.; Mallows, C.L. Scale mixtures of normal distributions. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 99–102. [Google Scholar]
- West, M. On scale mixtures of normal distributions. Biometrika 1987, 74, 646–648. [Google Scholar] [CrossRef]
- Van Dyk, D.A.; Park, T. Partially collapsed Gibbs samplers: Theory and methods. J. Am. Stat. Assoc. 2008, 103, 790–796. [Google Scholar] [CrossRef]
- Park, T.; van Dyk, D.A. Partially collapsed Gibbs samplers: Illustrations and applications. J. Comput. Graph. Stat. 2009, 18, 283–305. [Google Scholar] [CrossRef]
- Costa, F.; Batatia, H.; Oberlin, T.; Tourneret, J.Y. A partially collapsed Gibbs sampler with accelerated convergence for EEG source localization. In Proceedings of the IEEE Statistical Signal Processing Workshop (SSP 2016), Palma de Mallorca, Spain, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Kail, G.; Tourneret, J.Y.; Hlawatsch, F.; Dobigeon, N. Blind deconvolution of sparse pulse sequences under a minimum distance constraint: A partially collapsed Gibbs sampler method. IEEE Trans. Signal Process. 2012, 60, 2727–2743. [Google Scholar] [CrossRef]
- Chouzenoux, E.; Legendre, M.; Moussaoui, S.; Idier, J. Fast constrained least squares spectral unmixing using primal-dual interior-point optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 7, 59–69. [Google Scholar] [CrossRef]
- Marnissi, Y.; Benazza-Benyahia, A.; Chouzenoux, E.; Pesquet, J.C. Generalized multivariate exponential power prior for wavelet-based multichannel image restoration. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2013), Melbourne, Australia, 15–18 September 2013; pp. 2402–2406. [Google Scholar]
- Laruelo, A.; Chaari, L.; Tourneret, J.Y.; Batatia, H.; Ken, S.; Rowland, B.; Ferrand, R.; Laprie, A. Spatio-spectral regularization to improve magnetic resonance spectroscopic imaging quantification. NMR Biomed. 2016, 29, 918–931. [Google Scholar] [CrossRef] [PubMed]
- Celebi, M.E.; Schaefer, G. Color medical image analysis. In Lecture Notes on Computational Vision and Biomechanics; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Criminisi, E. Spatial decision forests for MS lesion segmentation in multi-channel magnetic resonance images. NeuroImage 2011, 57, 378–390. [Google Scholar]
- Delp, E.; Mitchell, O. Image compression using block truncation coding. IEEE Trans. Commun. 1979, 27, 1335–1342. [Google Scholar] [CrossRef]
- Khelil-Cherif, N.; Benazza-Benyahia, A. Wavelet-based multivariate approach for multispectral image indexing. In Proceedings of the SPIE Conference on Wavelet Applications in Industrial Processing, Rabat, Morocco, 10 September–2 October 2004. [Google Scholar]
- Chaux, C.; Pesquet, J.C.; Duval, L. Noise Covariance Properties in Dual-Tree Wavelet Decompositions. IEEE Trans. Inf. Theory 2007, 53, 4680–4700. [Google Scholar] [CrossRef]
- Roberts, G.O.; Tweedie, L.R. Exponential Convergence of Langevin Distributions and Their Discrete Approximations. Bernoulli 1996, 2, 341–363. [Google Scholar] [CrossRef]
- Murphy, K.P. Conjugate Bayesian Analysis of the Gaussian Distribution. Technical Report, 2007. Available online: https://www.cs.ubc.ca/~murphyk/Papers/bayesGauss.pdf (accessed on 1 February 2018).
- Barnard, J.; McCulloch, R.; Meng, X.L. Modeling covariance matrices in terms of standard deviations and correlations, with application to shrinkage. Stat. Sin. 2000, 10, 1281–1311. [Google Scholar]
- Fink, D. A Compendium of Conjugate Priors. 1997. Available online: https://www.johndcook.com/CompendiumOfConjugatePriors.pdf (accessed on 7 February 2018).
- Flandrin, P. Wavelet analysis and synthesis of fractional Brownian motion. IEEE Trans. Inf. Theory 1992, 38, 910–917. [Google Scholar] [CrossRef]
- Velayudhan, D.; Paul, S. Two-phase approach for recovering images corrupted by Gaussian-plus-impulse noise. In Proceedings of the IEEE International Conference on Inventive Computation Technologies (ICICT 2016), Coimbatore, India, 26–27 August 2016; pp. 1–7. [Google Scholar]
- Chang, E.S.; Hung, C.C.; Liu, W.; Yina, J. A Denoising algorithm for remote sensing images with impulse noise. In Proceedings of the IEEE International Symposium on Geoscience and Remote Sensing (IGARSS 2016), Beijing, China, 10–15 July 2016; pp. 2905–2908. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem Source | Proposed Auxiliary Variable | Resulting Conditional Density |
|---|---|---|
| Average | ||||||||
|---|---|---|---|---|---|---|---|---|
| Initial | BSNR | 24.27 | 30.28 | 31.73 | 28.92 | 26.93 | 22.97 | 27.52 |
| PSNR | 25.47 | 21.18 | 19.79 | 22.36 | 23.01 | 26.93 | 23.12 | |
| SNR | 11.65 | 13.23 | 13.32 | 13.06 | 11.81 | 11.77 | 12.47 | |
| SSIM | 0.6203 | 0.5697 | 0.5692 | 0.5844 | 0.5558 | 0.6256 | 0.5875 | |
| MMSE | BSNR | 32.04 | 38.33 | 39.21 | 38.33 | 35.15 | 34.28 | 36.22 |
| PSNR | 28.63 | 25.39 | 23.98 | 26.90 | 27.25 | 31.47 | 27.27 | |
| SNR | 14.82 | 17.50 | 17.60 | 17.66 | 16.12 | 16.38 | 16.68 | |
| SSIM | 0.7756 | 0.8226 | 0.8156 | 0.8367 | 0.8210 | 0.8632 | 0.8225 | |
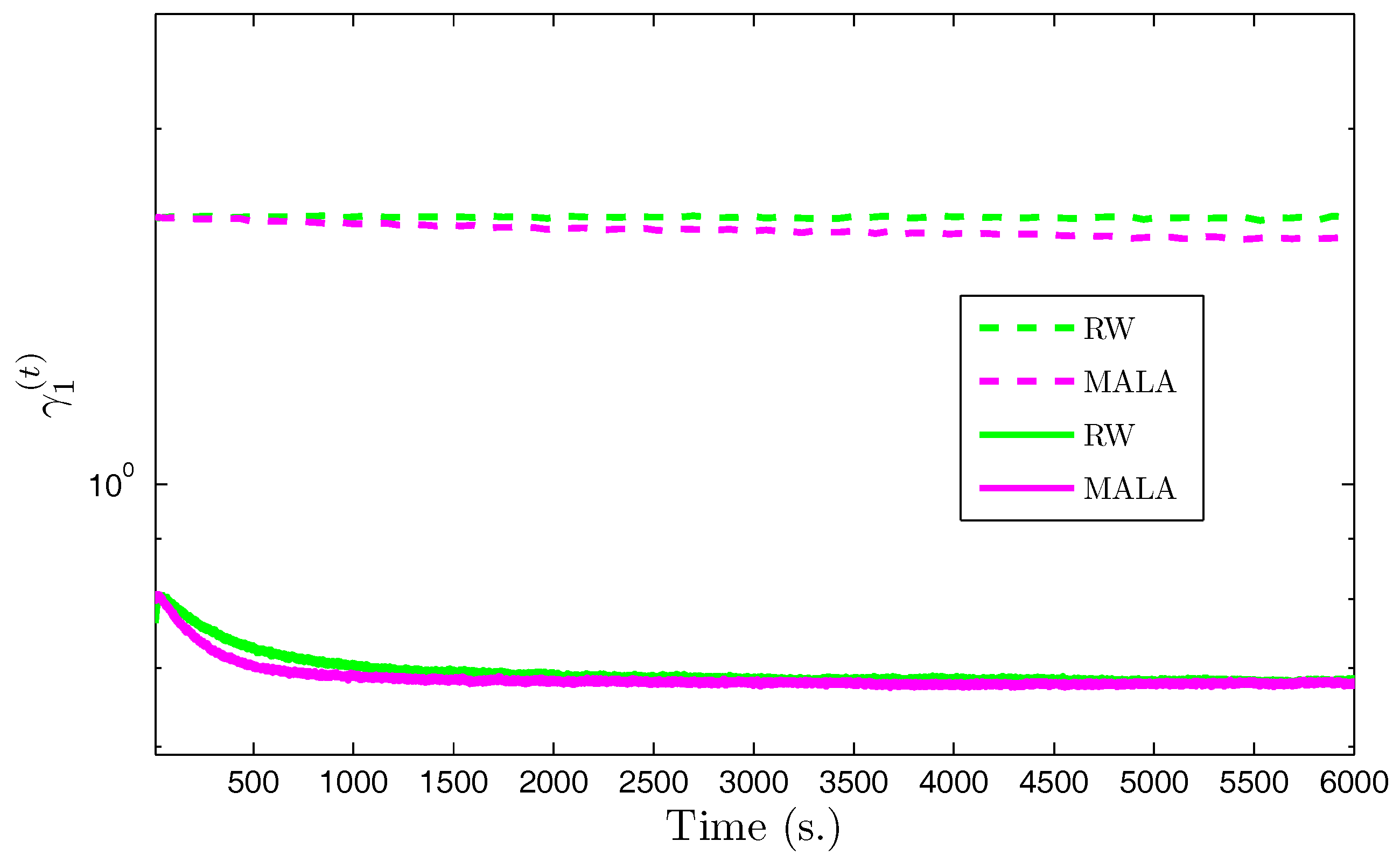
| RW | MALA | ||
|---|---|---|---|
( = 0.71) | Mean | 0.67 | 0.67 |
| Std. | (1.63 × ) | (1.29 × ) | |
( = 0.99) | Mean | 0.83 | 0.83 |
| Std. | (1.92 × ) | (2.39 × ) | |
( = 0.72) | Mean | 0.62 | 0.61 |
| Std. | (1.33 × ) | (1.23 × ) | |
( = 0.0.24) | Mean | 0.24 | 0.24 |
| Std. | (1.30 × ) | (1.39 × ) | |
( = 0.40) | Mean | 0.37 | 0.37 |
| Std. | (2.10 × ) | (2.42 × ) | |
( = 0.22) | Mean | 0.21 | 0.21 |
| Std. | (1.19 × ) | (1.25 × ) | |
( = 0.0.07) | Mean | 0.08 | 0.08 |
| Std. | (0.91 × ) | (1.08 × ) | |
( = 0.13) | Mean | 0.13 | 0.13 |
| Std. | (1.60 × ) | (1.64 × ) | |
( = 0.07) | Mean | 0.07 | 0.07 |
| Std. | (0.83 × ) | (1 × ) | |
( = 7.44 × ) | Mean | 7.80 × | 7.87 × |
| Std. | (1.34 × ) | (2.12 × ) | |
= 5.79 × | Mean | 1.89 × | 2.10 × |
| Std. | (9.96 × ) | (2.24 × ) | |
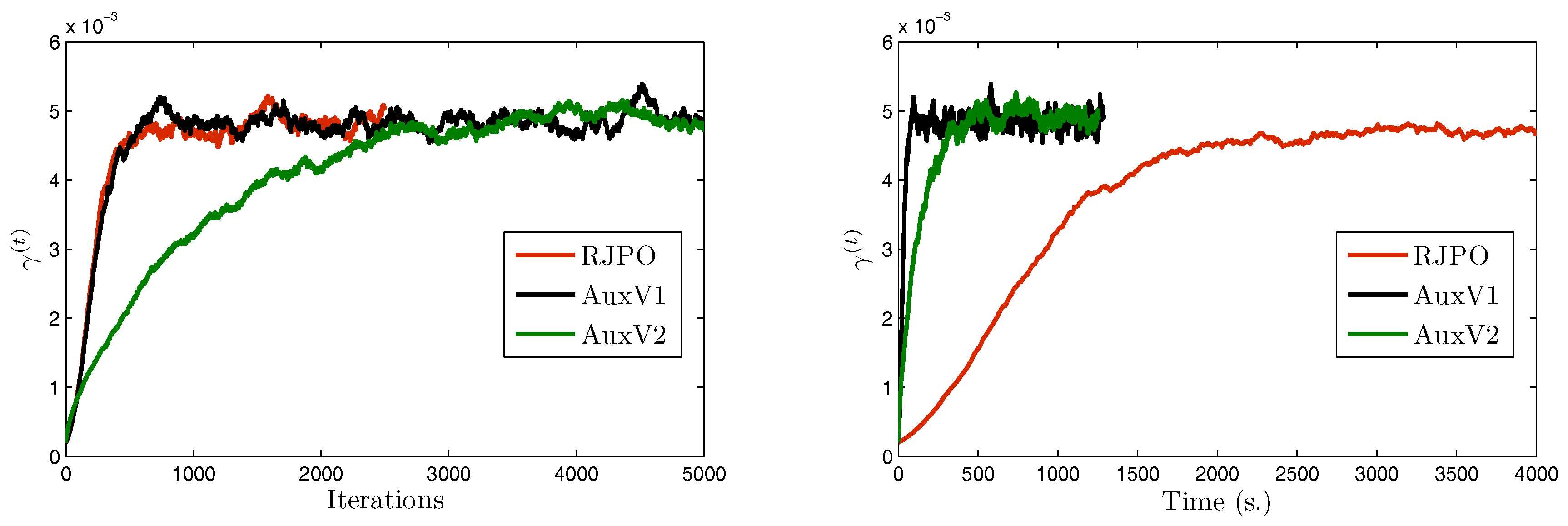
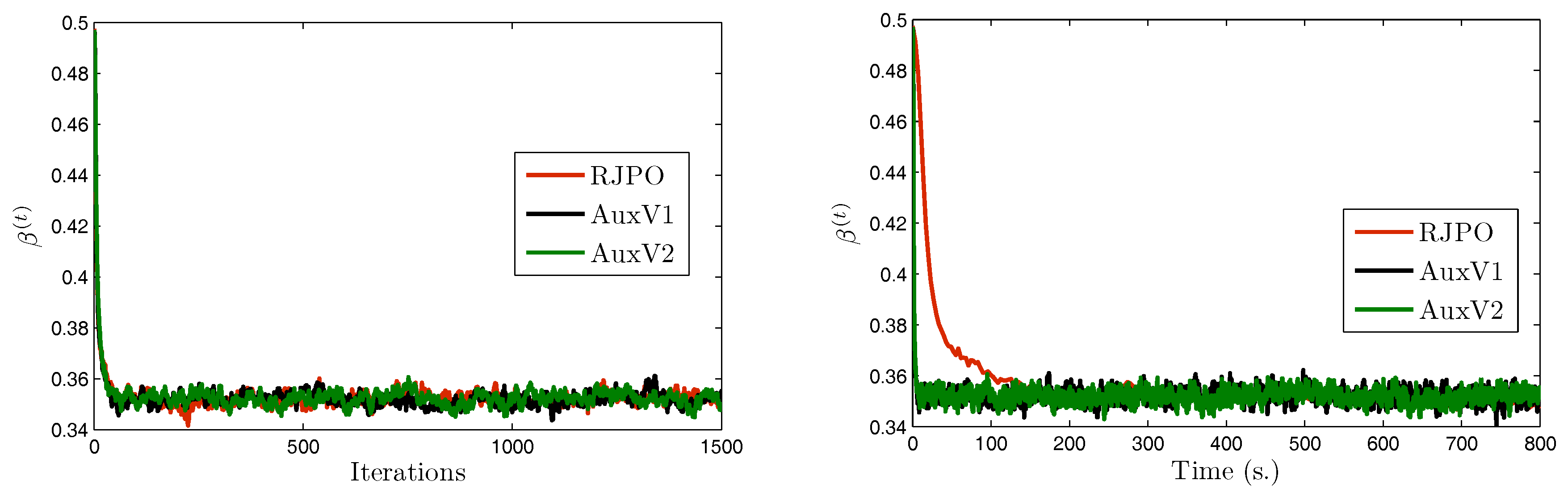
| RJPO | AuxV1 | AuxV2 | ||
|---|---|---|---|---|
( = 5.30 × ) | Mean | 4.78 × | 4.84 × | 4.90 × |
| Std. | (1.39 × ) | (1.25 × ) | (9.01 × ) | |
( = 13) | Mean | 12.97 | 12.98 | 12.98 |
| Std. | (4.49 × ) | (4.82 × ) | (4.91 × ) | |
( = 40) | Mean | 39.78 | 39.77 | 39.80 |
| Std. | (0.13) | (0.14) | (0.13) | |
( = 0.35) | Mean | 0.35 | 0.35 | 0.35 |
| Std. | (2.40 × ) | (2.71 × ) | (2.72 × ) | |
( = 140) | Mean | 143.44 | 143.19 | 145.91 |
| Std. | (10.72) | (11.29) | (9.92) | |
| RJPO | AuxV1 | AuxV2 | |
|---|---|---|---|
| T(s.) | 5.27 | 0.13 | 0.12 |
| 15.41 | 14.83 | 4.84 | |
| /T | 2.92 | 114.07 | 40.33 |
| Efficiency | 1 | 39 | 13.79 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marnissi, Y.; Chouzenoux, E.; Benazza-Benyahia, A.; Pesquet, J.-C. An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension. Entropy 2018, 20, 110. https://doi.org/10.3390/e20020110
Marnissi Y, Chouzenoux E, Benazza-Benyahia A, Pesquet J-C. An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension. Entropy. 2018; 20(2):110. https://doi.org/10.3390/e20020110
Chicago/Turabian StyleMarnissi, Yosra, Emilie Chouzenoux, Amel Benazza-Benyahia, and Jean-Christophe Pesquet. 2018. "An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension" Entropy 20, no. 2: 110. https://doi.org/10.3390/e20020110
APA StyleMarnissi, Y., Chouzenoux, E., Benazza-Benyahia, A., & Pesquet, J.-C. (2018). An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension. Entropy, 20(2), 110. https://doi.org/10.3390/e20020110