1. Introduction
Cross entropy and Kullback–Leibler (K-L) divergence are applied to and discussed in studies on machine learning [
1], visualization (e.g., to interpret the pipeline of visualization using the cost–benefit model [
2] and several other applications [
3]), computer graphics [
4], and many other fields. Cross entropy and K-L divergence are two fundamental quantities of information theory. Cross entropy gives the average code length needed to represent one distribution by another distribution, and the excess code needed over the optimal coding is given by the K-L divergence. As cross entropy is just the negated logarithm of likelihood, minimizing cross entropy means maximizing likelihood, and thus, cross entropy is widely used now for optimization in machine learning. K-L divergence also stands independently as a widely used metric for measuring the difference between two distributions, and it appears in many theoretical results. As examples, the definition of mutual information between two variables is a K-L divergence, and the absolute difference of K-L divergences with respect to a third distribution was recently used to define a family of metrics [
5].
Recently, order invariance for inequalities between means was presented [
6]. Since likelihood is the weighted geometric mean of the representing distribution weighted by the data distribution, likelihood and thus cross entropy will share the order invariance properties too. Order invariance properties are characterized by the stochastic order between weights or data distributions [
7]. Here, we further develop this idea in order to compare representations of different data by the same distribution, and we extend it to a new order, K-L dominance, that allows us to define inequalities between representations of the same data by different distributions. Finally, we establish the connection between the two orders. We also give numerical examples to illustrate the theoretical results.
This paper is organized as follows. After this introduction, in
Section 2, we recapitulate the meaning of cross entropy and its relationship to likelihood and K-L divergence, and we obtain the first theoretical results based on the rearrangement inequality. Next, in
Section 3, we apply the invariance results for weighted means to cross entropy. In
Section 4, we introduce a new order, K-L dominance, that allows us to establish inequalities between K-L divergences and give the relationship between stochastic and K-L order. Finally, in
Section 5, we present our conclusions and future work.
2. Cross Entropy as a Measure of Goodness of Representation
Consider two probability distributions,
,
, for all
k ,
,
(when not explicit, the sum limits will be understood to be between 1 and
n). Cross entropy
(to avoid cluttered notation we will write
instead of
) is defined as
and can be written as
(similar notation to
), where
is the entropy of distribution
, and
is the Kullback–Leibler divergence of
and
distributions. It represents the average length of code per symbol needed to represent
using
. In the context of coding, we do not let any component of
be zero, as the corresponding component of
would not be coded; thus,
is well defined. The minimum code length to code
is obtained by taking
, because
. Minimum code length will be between
and
+ 1 bit (Huffman coding, [
8]).
Cross Entropy and Likelihood
Observe that cross entropy is the negated logarithm of likelihood. Let us suppose a distribution with n states, which are guessed to be , and a relative frequency of realizations of the different states. That is, we guess that the distribution represents the collected data . Likelihood is then used as a measure of how well the distribution represents the data. The likelihood of is the true distribution of the data with relative frequency , and . Observe that is the weighted geometric mean of with weights . The likelihood represents the probability of being the true distribution of the known data . As , maximizing the likelihood is equivalent to minimizing the cross entropy.
Now, let us suppose we take an arbitrary distribution to code . Without loss of generality, we will consider two or more sequences to be equally ordered, or in the same order, when, by the same permutation of indexes, we can make it such that all the sequences are increasing. We can state the following theorem.
Theorem 1. Consider the distribution and the sequence of strictly positive numbers , . When is permuted so that is ordered in the same order as , then the cross entropy takes a global minimum, and, correspondingly, the likelihood takes a global maximum.
Proof. Using the rearrangement inequality [
6,
9] and the definition of cross entropy, the minimum of the sum of the product
is realized when the two sequences are ordered inversely to each other. That means the
sequence will be ordered as the
sequence, and, by the monotonicity of the logarithmic function, the
sequence will be ordered as the
sequence. □
As , and thus , is fixed, also takes the global minimum when is ordered as . Also, when there are elements repeated in , there can be non-ordered distributions with the same minimum cross entropy value. The extreme case is when for all k, and all orderings of will give the same result.
Observe that by Theorem 1, if we have a series of distributions that are all ordered in the same order, which we can consider to be increasing, and want to represent them with a single distribution —to be chosen by permuting the elements in —then the best distribution will be the one for which we select the elements in in increasing order too.
Example 1. For any increasing sequence , we have that
- 1.
- 2.
and so on.
However, what happens when we have to choose between two distributions,
and
, to represent a set of increasing distributions,
? Can we find which one is better?
Section 4 provides some answers to this. Before answering this question, we introduce the concept of stochastic dominance in
Section 3.
3. First Stochastic Order Dominance
When for all increasing distributions
, we say that
stochastically dominates
, and we denote this relation as
[
7]. This is a partial order on the set of distributions.
The necessary and sufficient conditions for a sequence
to stochastically dominate another one
are given in the following theorem [
6].
Theorem 2. Given that the sequences and are positive and add up to 1, the following conditions are equivalent:
- (1)
The sequence stochastically dominates the sequence
- (2)
- (3)
- (4)
For all increasing sequences and for any strictly monotonous function, (quasi-arithmetic, or Kolmogorov, mean), whenever is applicable.
- (5)
There exists a strictly monotonous function such that for all increasing sequences :(quasi-arithmetic, or Kolmogorov, mean), whenever is applicable.
A sufficient condition for
is given by the following theorem [
6,
10].
Theorem 3. Given the distributions , a sufficient condition for is that whenever , then .
By Theorem 3, if is increasing, then , where is the uniform distribution; if is decreasing, then ; if is increasing and is decreasing, then .
Observe now that, by condition (5) of Theorem 2, if Equation (
3) applies for one strictly monotonous function, then, for the equivalence between conditions (4) and (5), it applies for any other strictly monotonous function. Then, by the definition of cross-entropy,
Theorem 4. Given two distributions and , if and only if for all increasing distributions , (or ).
Theorem 4 means that, if , then, taking all possible increasing representations , the code length for will be shorter than for , and the likelihood for will be bigger than the likelihood for . Observe also that if is an increasing sequence, then ; thus, the representation of by an increasing distribution will be shorter than the representation of uniform distribution , and the likelihood of will be bigger than that of .
Corollary 1. For any increasing distributions and , we have that (or .
Indeed, the above result is valid too if, by an index permutation, we can bring , to be in the same order. Thus,
Corollary 2. For any distributions and that are ordered equally, we have that .
Now, suppose is decreasing; then, . Also, for any distribution , , and thus, the following corollary,
Corollary 3. For any increasing distribution and decreasing distribution , we have that .
Also, by reordering the indexes, Corollary 3 can be extended to
Corollary 4. For any distributions and that are inversely ordered to each other, we have that .
Observe now that if is increasing and is decreasing, then, , and thus,
Corollary 5. For any increasing distribution and decreasing distribution , we have that for any increasing distribution , .
Corollary 5 is also a direct consequence of Corollaries 1 and 3.
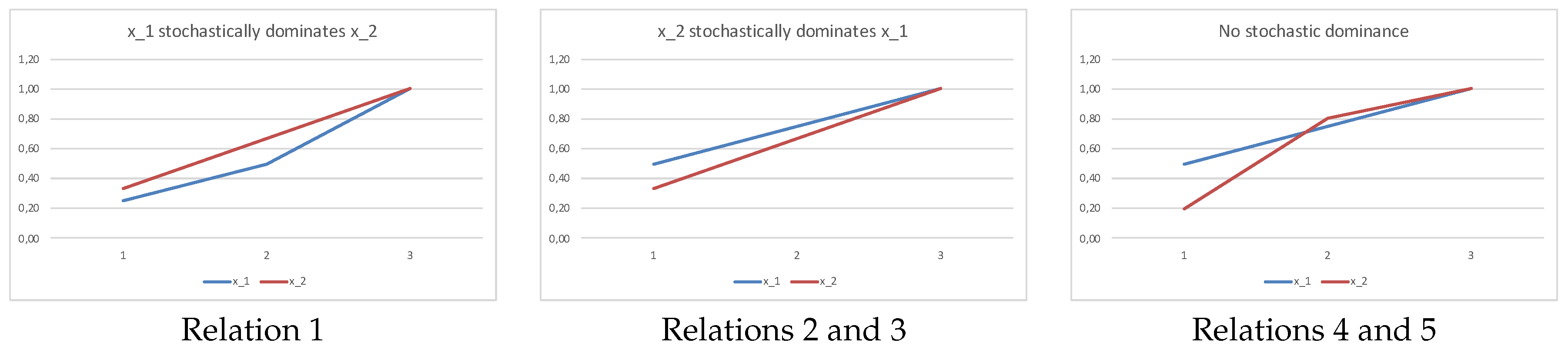
Example 2. We have:
- 1.
- 2.
- 3.
- 4.
- 5.
In
Figure 1, we plot the sums in Equation (
1) corresponding to relation 1 and relations 2–3, 4–5 in Example 2. Observe that the sums in Equation (
1) correspond to the cumulative distribution function (cdf). A first-order stochastic dominance implies that there is no crossing of the respective cdf’s.
Discussion
We show above how the interpretation of cross entropy as a weighted mean allows for obtaining interesting order invariance results for the cross entropy of two data distributions represented by the same distribution (correspondingly for likelihood). Since, in our results, the distribution of the data is variable while the representative distribution is fixed, the resulting cross entropy depends on both entropy and K-L divergence. In the next section, we consider the data fixed and the representative distribution variable; thus, the comparison of cross entropies of a given data distribution for two representative distributions will be equivalent to the comparison of their K-L divergences.
4. A New Partial Order: K-L Dominance
We extend here the results of
Section 2. We first define a new partial order between distributions and call it K-L dominance.
Definition 1. K-L dominance. We say that distribution K-L-dominates distribution , written symbolically as , when, for all increasing distributions , .
Observe that , because, in general, .
From the definition of cross entropy, is equivalent to—for all increasing —, and thus, for all increasing sequences, coding them with will always generate a shorter codification than coding them with .
The following theorem holds:
Theorem 5. A necessary and sufficient condition for distributions , to hold (equivalent to—for all increasing distributions —, or ) or is the following: Observe that Theorem 1 is a particular case of Theorem 5, as a sequence rearranged in increasing order will always fill the second members of inequalities in Equation (
4) with respect to all other rearrangements. Thus, an increasing distribution
K-L-dominates all the distributions obtained by permuting the values of
. Observe also that Equation (
4) condition makes the
order reflexive, antisymmetric, and transitive, and thus, it is a partial order. To prove Theorem 5, let us consider first the following lemma:
Lemma 1. Consider the sequences of n numbers and . Then, conditions (1) and (2) are equivalent:
- (1)
for any sequence of n positive numbers in increasing order , the following inequality holds: - (2)
(2) the following inequalities hold:
Proof. That
is immediate, considering, respectively, the
sequences
. Let us see now that
: Define for
,
, and
,
. Observe that condition (2) is equivalent to—for all
k—
. Observe also that the
sequence augmented with
is still increasing. We have
as, by hypothesis for all
k,
, and
is an increasing sequence. □
The proof of Theorem 5 follows immediately from applying Lemma 1 to the inequality .
The following corollary follows from observing that, by taking , then, , .
Corollary 6. An increasing distribution cannot be K-L dominated by any other distribution (except trivially by itself). In particular, the uniform distribution does not dominate any other increasing distribution.
Observe now that the product
is always bigger than or equal
, as the maximum value for
subjected to the condition
is, for all
k,
. Thus, from the last inequality in Equation (
4), we have the following corollary,
Corollary 7. For all distributions , , we have that .
Observe that Corollary 7 is also a particular case of Corollary 6, considering as an increasing distribution.
Corollary 8. The uniform distribution K-L-dominates all decreasing distributions.
Proof. For all increasing and decreasing, we apply Corollary 4, and we have . ☐
Example 3. Some examples are:
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
The first and second relation are examples of Corollary 8. The third is an example of Corollary 6. The sixth is an example of Theorem 1. The fourth and fifth relations mean that the uniform distribution can both K-L dominate and non-dominate non-monotonous sequences, and we have to look for each case at the Condition (
4) of Theorem 5. The seventh relation tells us that a decreasing sequence can dominate another decreasing sequence. In
Figure 2, we plot the logarithm of products in Equation (
4) for relations 1, 3, 6, and 7, respectively. If a sequence K-L-dominates another one, the plots do not cross, and its plot appears over that of the second sequence. Inversely, no dominance means that the plots will cross.
4.1. Discussion
Remember that the equivalence between cross entropy and likelihood means that the likelihood that is the true distribution, given the data distribution , and the average length of code using to represent are related by the second quantity being the negated logarithm of the first. If you have one distribution and have the choice to use or to represent it, you want to choose the one with the minimum length of code, or, alternatively, the one with maximum likelihood. In both cases, the best is the one that gives minimum Kullback–Leibler divergence. Suppose now you want to represent data and have two alternative distributions to represent it, either , the uniform distribution, or , which is ordered in the same order as . To fix ideas and without loss of generality, let us consider that both and are in increasing order. It would seem reasonable to represent the data , which is increasing, as distribution , which is increasing too; thus, the order is preserved. However, that would work as long as ; otherwise, we should choose , the uniform distribution. This is clear from corollary 7, which tells us that, for any sequence, particularly , there will always be increasing sequences such that . Intuitively, if has a high increasing gradient, then we would choose , the increasing distribution to represent it, but if becomes smoother, then we would choose , the uniform distribution.
As an example, suppose the two distributions have to be represented by one of the distributions . To preserve the order, we would choose for both. It is intuitively a clear choice of (and a correct one, as it has a K-L divergence, half the one for ), but we might have some doubts for , where, actually, the K-L divergence is only slightly smaller for . To represent distributions , it is intuitively more clear to select the uniform distribution rather than , even if order is lost. In fact, the K-L divergence from both distributions to is one and two orders of magnitude greater, respectively, than to the uniform distribution .
4.2. Relationship between K-L Dominance and First Stochastic Dominance Orders
Summarizing K-L dominance and first stochastic dominance orders, we have
Is there a relationship between the two orders? When or, equivalently, (observe that Theorem 1 is a particular case), we can find a necessary and sufficient condition for .
Theorem 6. Given distributions , , and , then the following conditions are equivalent:
Proof. Observe first that
are also distributions (we can indeed use the simpler expressions
, but, here, we have left the negated ones to remind the reader that both numerator and denominator are negative), because they are positive sequences adding to 1. Observe also that when
, taking the logarithms in Equation (
4) and changing the sign (which changes the direction of inequalities), we obtain condition (3) in Theorem 2, which is necessary and sufficient for
. □
Example 4. Consider the distributions and their normalized negated logarithms , respectively. We have that and .
5. Conclusions and Future Work
In this paper, we present new inequalities for cross entropy and Kullback–Leibler divergence. As cross entropy is the negated logarithm of likelihood, the inequalities also hold for likelihood, changing the sense of the inequality. First, we applied to cross entropy the rearrangement inequality and recent stochastic order invariance results for Kolmogorov weighted means, as likelihood is a weighted geometric mean. Then, we introduced another partial order, K-L dominance, that applies directly to K-L divergences, and we give the relationship between both orders.
In data retrieval, exploration, analysis, and visualization, sorting some data objects into an ordered list or display is a common task performed by users. In the past, the benefit of having a sorted list has been typically articulated qualitatively. We plan to use the theorems presented in this paper to help establish an information-theoretic explanation about the cost–benefit of ordering in data retrieval, exploration, analysis, and visualization. We will also investigate the application to machine learning. We will study whether K-L-dominance order supports invariance properties, in the same way as first stochastic order supports the order invariance for weighted means, and we will look for sufficient conditions for K-L-dominance order, similar to the one in Theorem 3 for first stochastic order. Finally, we will investigate extensions of K-L dominance order: for instance, when , increasing and concave/convex, in the same way as the extensions of first stochastic order.


{kind=link}
{kind=link}