1. Introduction
This paper addresses the statistical problem of estimating the total amount of error in an account balance obtained from auditing. To do so, the statistical toolbox employed by the auditor must be adapted to use a Bayesian approach. The conclusions drawn from the audit process are commonly based on statistical methods such as hypothesis testing, which in turn is based on compliance testing and substantive testing. The first of these is conducted to provide reasonable assurance that internal control mechanisms are present and function adequately. Substantive testing seeks to determine whether errors are present and if so, their size. In auditing practice, the total amount of error in a single statement, denoted by
, and associated substantive testing are highly important to decision making. For instance, the test
vs.
, can be conducted in order to accept or reject the amount of error detected in the audit, where
denotes the total amount of error the auditor deems material. Johnstone (1995) [
1] presented auditing evidence showing that the classical hypothesis test is incoherent and that Bayesian techniques are to be preferred.
Monetary Unit Sampling (MUS) or equivalently Dollar Unit Sampling (DUS, is commonly used to obtain sample information. In DUS, the population size is the recorded book value (
B) and the sample plan consists of selecting monetary (dollar) units with an equal chance of being selected. The amount of error for each dollar selected is the difference between its book value and its audit value. The taint of the randomly–selected dollar unit is given by the quotient between the error and the book values. Most of the audited values will be correct and so the associated errors will be zero. The taints in a dollar unit sample are recorded and used to draw inferences about the parameter of interest, i.e., the total amount of error. In practice, auditors usually assume that no amount can be over or under–estimated by an amount greater than its book value. Therefore, the range of taints extends from −100 to +100 per cent in increments of one per cent:
and the proportions of each taint are:
. For a sample DUS of size
, the practitioner knows the observed number of tainted dollar units in the sample with
i% taints,
, where
and
. In practice,
B is very large in relation to sample size
n and then the multinomial model adequately reflects the likelihood function. The likelihood of the problem is expressed as a parameter
of dimension
where
.
To complete a Bayesian analysis, a prior distribution is required, and this is frequently a conjugated Dirichlet prior. However, there are certain difficulties. On the one hand, quantifying the expert’s opinion as a probability distribution is a difficult task, especially for complex multivariate problems. Furthermore, although the auditor usually has an intuitive understanding of the magnitude, i.e., the total amount, of error , the proportion of will be unknown. Finally, the likelihood of the observed data depends on the parameters . In consequence, the analyst must consider a Bayesian scenario under partial prior information, and seek to combine prior information about with the sample information about the individual proportions.
In a non–Bayesian context, McCray (1984) [
2] introduced a heuristic procedure to obtain a maximum likelihood function. Following Hernández et al. (1998) [
3], we now propose a modification of the likelihood to make it compatible with prior information on
and then perform a Bayesian analysis. The prior distribution for the total amount of error in the population is commonly asymmetrical and right tailed, and statistically–trained auditors can readily elicit values such as the mean and/or certain quantiles. In this paper, we propose to use for the prior the maximum entropy prior with a specified mean. The advantages of this objective “automatised” prior are that it requires only a small amount of prior information, and nothing else, and is computationally feasible.
The remainder of the paper is organized as follows.
Section 2 outlines technical results needed to derived the modified likelihood we use to combine with prior distributions.
Section 3 shows how maximum entropy priors can be incorporated into the auditing context.
Section 4 then presents some numerical illustrations of the method, and the results obtained are discussed in
Section 5.
2. The Likelihood Function
Assuming the joint probability mass function given in (
1) and consider that there exists a measurable function
such that the auditor has prior information about
and
a discrete set of values of
. Observe that by construction
The following notation will be used.
denoted a separable metric space,
is the natural
-field of subsets of
, and
a sub-
-field of
,
denotes the set of all real–valued functions
which are nonnegative, bounded and
-measurable,
is a probability measure on
,
for
, is the upper–integral of
with respect to
[
4] and
is the indicator function of the set
Theorem A1 ([
5,
6]) in
Appendix provides a modified likelihood function for the subparameter
. The function
in Theorem A1 is the modified likelihood function desired. In fact, we have a
-measurable likelihood function
with
the usual Borel
-field and also we have prior information given on
with its usual
-field. As
is discrete, all atoms of its
-field are
, and therefore the sets
are belonging to the
-field
. Let
be the sub-
-field of
induced by
on
. If we define the probability of a set
by the probability of
(known a priori), we will have a probability measure on the sub-
-field
, denoted by
. Furthermore, the sub-
-field is generated by a countable partition, and in consequence the modified likelihood is given by
where for simplicity we write
to refer function in (
1). Observe that function in (
4) is constant on every set
, and thus we can write the modified likelihood as
Also we note that expressions (
4) and (
5) are similar to empirical likelihood functions [
7] and with the likelihood
induced in the notation introduced by Zehna (1966) [
8]. Likelihood function in (
5) is a
-measurable function and compatible with the prior
, thus Bayes’ theorem now apply as
We illustrate how to obtain the modified likelihood in (
5) with a simulated example.
Example 1. Consider a DUS sample of 100 items which no errors have been discovered 90 times, one taint is 10% in error, one more taint is 90%; and eight taints are −10% in error (understatement error). Also, we assume that the monetary units are drawn from a population of accounts totaling . To find the likelihood of a value θ we solve the following optimization problemsubject to:andand that all proportions are nonnegative and less than one. For example, for a total amount of error = 12,000 the proportions obtained are and , and the likelihood of this error is 0.014. All computations are easily obtained with Mathematica© using the command NMaximize.
3. The Maximum Entropy Priors
To apply Bayesian methods in auditing, a prior distribution must be assigned to the total error parameter
. References [
9,
10], among others, have described how this might be done. In practice, however, Bayesian methods are not widely used because auditors frequently find it difficult to assess a prior probability function. They often lack statistical expertise in this respect, and so cannot easily assess hyperprior parameters, which might not have an intuitive meaning. In most cases, only certain descriptive summaries, such as the mean and/or median of a probability distribution, can be assigned straightforwardly. Thus, auditors tend to feel comfortable assessing certain values of the prior distribution and disregard the other possible values of the parameter. In such a situation, the maximum entropy procedure might be an appropriate way to obtain the prior distribution required.
Let the parameter space
be an interval
. It is well known that the probability distribution
which maximizes the entropy with respect to the objective uniform prior on
subject to partial prior information given by
has the form
where
are constants to be determined from the constraints in (
7). Observe that functions
can adopt several interesting expressions. For example, for
and
we have that partial prior information consists of specifying
m central moments in the distribution. Quantiles are also easy to incorporate considering
.
For practical applications and illustrative purposes we focus on situations where only the mean is given, i.e., , and . In such case,
If , then , that is, the uniform distribution on the interval .
If
, then
where
is obtained by solving the nonlinear equation
4. Numerical Illustrations
For illustrative purposes, we present a simulated audit situation in which two auditors have partial prior information about the mean, and are comfortable using a maximum entropy prior in a DUS context. Let us consider the DUS data from an inventory with a reported book value of
, a sample size of 100 items, and observed taints of 0, 5, 10 and 90 and 94, 4, 1, 1, cases, respectively. In order to decide whether to accept the auditee’s aggregate account balance, the auditors then conduct the statistical hypothesis test of
vs.
, where
denotes an intolerable material error. Assume that a figure of five to seven per cent over the reported book value is a common value for this materiality. For instance, let us suppose that the auditors wish to test
that is,
=
$50,000.
Following (
5), for every value of the total error
the modified likelihood associated with the DUS data is obtained solving
subject to:
and
and that all proportions are nonnegative and less than one. For a given maximum entropy prior on
, we can now derive its posterior distribution using (
6). Using Bayes’ theorem, these priors can then be updated to posteriors conditioned on the data that were actually observed. To facilitate reproducibility of the results presented, a simplified code version is available as
Supplementary Material to this paper.
To compare scenarios where non prior or only limited partial prior information is available, and so the auditors must base their decisions on the information in the data, we present the following situation.
Auditor #1 adopts a reference non–informative prior for the parameter
, i.e., uniform on
. Observe that for a constant prior the Bayes’ theorem is applicable because the constant is cancelled out in (
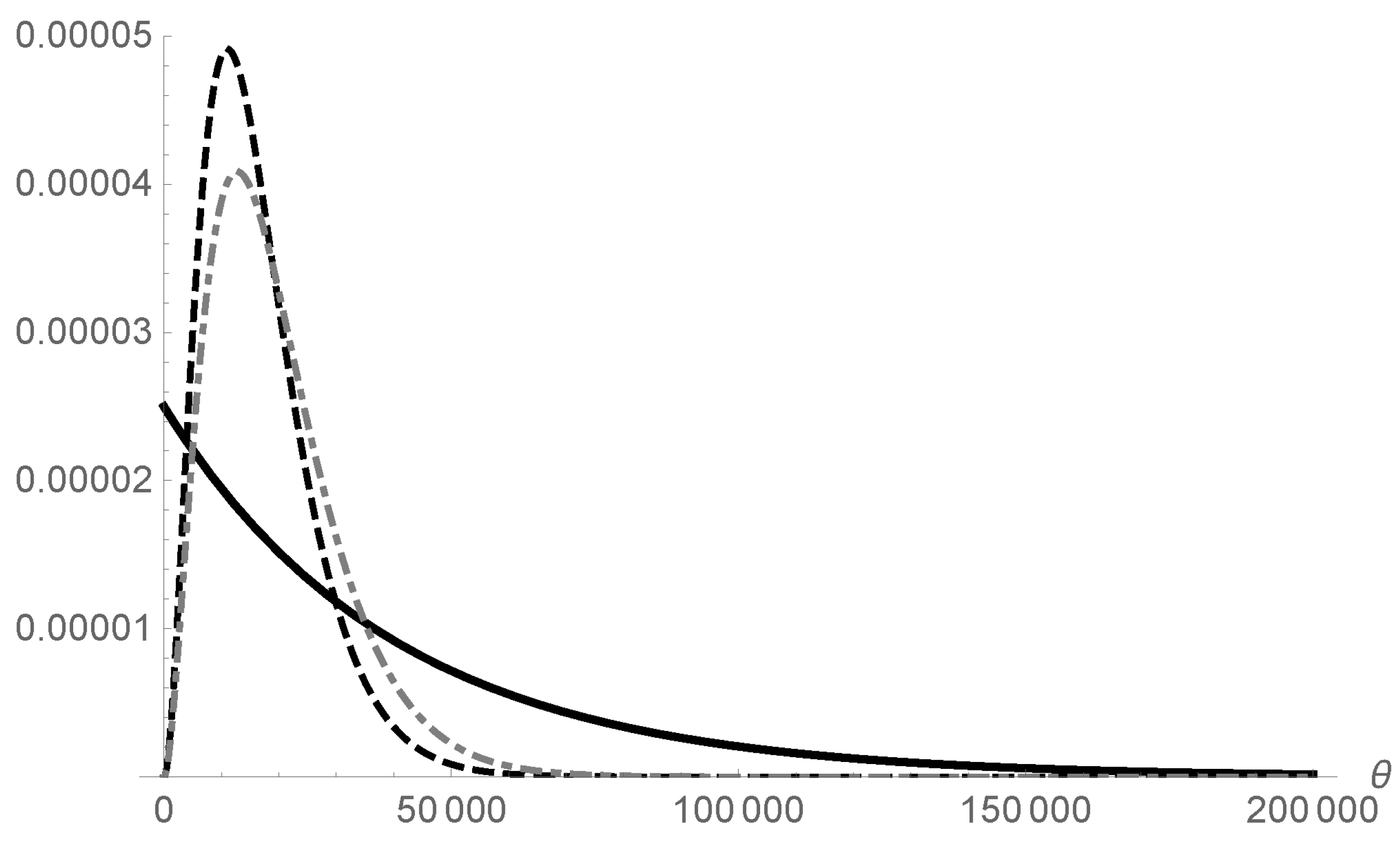
6) and the posterior distribution is equivalent to the normalised modified likelihood. Figure shows the posterior distribution (in grey) of the total amount of error for the DUS data given above.
On the other hand, the partial prior information provided by Auditor #2 is given by the a priori mean of
=
$40,000. With this partial prior information, the maximum entropy prior for
, deduced by solving Equation (
10), corresponds to
= −25. In practical applications, we suggest using a grid of 1000 total error points for a good approximation to the likelihood function.
Figure 1 shows the prior and posterior distribution for Auditor #2 with the sample information considered above. Observe that when just a small amount of prior information is included via the mean, there are differences between the posterior distributions obtained by Auditors #1 and #2. The estimated mean total error, that is, the posterior mean of the distribution in each case, is
$16,576.2 and
$19,577.2, respectively, and so the posterior distribution for Auditor #1 is more right–skewed than that obtained by Auditor #2.
The posterior probabilities of the null hypothesis are similar, presenting strong evidence for
[
11], although more so under MEP.
Table 1 details the posterior probability of the null hypothesis to be tested in (
11). All computations were conducted using
Mathematica© (version 11.2).
In practice, auditors commonly wish to obtain a high probability quantile of the posterior distribution, say 0.95, and will then accept the accounting balance if this quantile represents a small proportion of the book value, for example no more than five per cent. In
Table 1 which shows these quantiles, there is a significant difference between the non-informative and the maximum entropy case, which represent 4.4% and 3.6%, respectively, of the recorded book value. In other words, the posterior probability of the actual total error in the accounting balance being less than
$36,000 is 0.95, which represents a reduction of almost 18% in the 95%–quantile compared with a non-informative scenario.
The advantages of the proposed model are highlighted by comparing it with conventional methods such as the conventional Bayesian approach and the classical statistics procedure.
Accordingly, let us first consider a conventional conjugated Bayesian model with multinomial sampling distribution and a non-informative conjugated Dirichlet prior. A burn–in of 10,000 updates followed by a further 50,000 updates produces the parameter estimates
=
$48,880 and
(the
WinBUGS code is available as
Supplementary Material to this paper). Therefore, both of the new Bayesian upper bounds shown in
Table 1 are tighter than the above conventional Bayesian bound. Furthermore, the Bayesian Multinomial–Dirichlet model is fairly sensitive to the dimension of
, a concern which does not arise in the proposed formulation. For instance, the above numerical illustration developed with a non-informative Dirichlet prior over the range 0–100 obtains an unrealistic 95% upper bound of
$295,900, in contrast with the MEP upper bound which is
$36,000.
On the other hand, under a classical approach and following Fienberg et al. (1977) [
12], an upper confidence bound for an
percent confidence coefficient with the Stringer method, based on the total overstatement error, is given by
where
denotes the
upper confidence bound for the population proportion when
i errors are found in the sample. Stringer used a Poisson approximation to obtain these quantities. For the case of this numerical illustration, the bound obtained is
$43,950. Therefore, a “classical” auditor can conclude, with at least 95 percent confidence, that the total overstatement error in the population does not exceed
$43,950. However, for
= 0.01 we find that the 99 percent upper confidence bound is
$62,655, and the null hypothesis in (
11) must hten be rejected. This is somewhat confusing, as Johnstone [
1] pointed out: “…results close about the
critical accept/reject partition in conventional hypothesis tests can often result in reversed decisions …”. Furthermore,
Table 1 shows that the Bayesian MEP upper bound is tighter than the earlier classical bound.
5. Discussion
In this paper, we propose a genuine Bayesian approach as an appropriate formulation for addressing statistical auditing problems. This formulation presents several advantages for the substantive test defined in
Section 1: (i) it allows incorporation of the auditor’s judgements about the materiality of the error and makes it easy to derive a reasonable prior distribution; (ii) the Bayesian methodology proposed provides a sensible and straightforward formulation, (iii) the posterior quantities derived are very efficient compared to the existing classical methods, especially when errors are small. The results obtained by our procedure appear to be more reasonable than those achieved by conventional ones such as the classical (Stringer bounds) and the Bayesian (Dirichlet bounds) approaches.
Conventional (conjugated) Bayesian analysis under the DUS methodology, based on multinomial likelihood, needs a Dirichlet prior distribution to be elicited, a requirement which in practice is unrealistic when 201 parameters are involved [
13]. Elicitation in a high dimensional parametric space is a complex task [
14], but the model presented in this paper overcomes this difficulty. Obviously, alternative priors can be considered. As has been observed elsewhere, objective priors for discrete parameters are starting to be considered both in the univariate scenario [
15] and in the multivariate case [
16]. This constitutes an interesting line of research for future investigation.
As reported in the NRC Panel review [
17], mixture distributions can be appropriate in the audit process. In practice, auditors have found that the distribution of non–zero error amounts differs markedly between types of accounting populations, for instance, between receivables and inventory [
18]. This fact introduces additional complexity when we wish to model the audit process without considering the source of information (receivables or not, …). A further advantage of the proposed model is that it includes both over and understatement errors.
The approach we describe in the paper is ”automatic” in the sense that the model incorporates the sample information available and the partial prior information as the prior mean, and no more. No distributional assumptions are required for the likelihood function and no assumptions are made as to the priors. Given this absence of assumptions and the simplicity of the formulation, this approach may be considered reliable for audit purposes. Focusing on hypothesis testing, this paper provides a theoretical basis for using the heuristic quasi–Bayesian model [
2]. The numerical illustrations presented suggest that the resulting 95%–quantiles are consistent with the priors and the likelihood considered. In both of these priors (uniform and MEP), the posterior distributions present a moderate right skew towards a higher level of error; only one taint of 90% is observed in the sample and the model is sensitive to this taint. The use of the mean as prior information yields an evident reduction in the 95% upper bound. An interesting area for further investigation of these audit test problems would be to incorporate another intuitive descriptive summary, such as the median or the mode [
19].




{kind=link}