1. Introduction
Suppose we are given the choice of two channels that both provide information about the same random variable, and that we want to make a decision based on the channel outputs. Suppose that our utility function depends on the joint value of the input to the channel and our resultant decision based on the channel outputs. Suppose as well that we know the precise conditional distributions defining the channels, and the distribution over channel inputs. Which channel should we choose? The answer to this question depends on the choice of our utility function as well as on the details of the channels and the input distribution. So, for example, without specifying how we will use the channels, in general we cannot just compare their information capacities to choose between them.
Nonetheless, for certain pairs of channels we can make our choice, even without knowing the utility functions or the distribution over inputs. Let us represent the two channels by two (column) stochastic matrices and , respectively. Then, if there exists another stochastic matrix such that , there is never any reason to strictly prefer ; if we choose , we can always make our decision by chaining the output of through the channel and then using the same decision function we would have used had we chosen . This simple argument shows that whatever the three stochastic matrices are and whatever the decision rule we would use if we chose channel , we can always get the same expected utility by instead choosing channel with an appropriate decision rule. In this kind of situation, where , we say that is a garbling (or degradation) of . It is much more difficult to prove that the converse also holds true:
Theorem 1. (Blackwell’s theorem [1]) Let be two stochastic matrices representing two channels with the same input alphabet. Then the following two conditions are equivalent: - 1.
When the agent chooses (and uses the decision rule that is optimal for ), her expected utility is always at least as big as the expected utility when she chooses (and uses the optimal decision rule for ), independent of the utility function and the distribution of the input S.
- 2.
is a garbling of .
Blackwell formulated his result in terms of a statistical decision maker who reacts to the outcome of a
statistical experiment. We prefer to speak of a decision problem instead of a statistical experiment. See [
2,
3] for an overview.
Blackwell’s theorem motivates looking at the following partial order over channels
with a common input alphabet:
We call this partial order the
Blackwell order (this partial order is called
degradation order by other authors [
4,
5]). If
, then
is said to be Blackwell-inferior to
. Strictly speaking, the Blackwell order is only a preorder, since there are channels
that satisfy
(when
arises from
by permuting the output alphabet). However, for our purposes, such channels can be considered as equivalent. We write
if
and
. By Blackwell’s theorem, this implies that
performs at least as well as
in any decision problem and that there exist decision problems in which
outperforms
.
For a given distribution of S, we can also compare and by comparing the two mutual informations , between the common input S and the channel outputs and . The data processing inequality shows that implies . However, the converse implication does not hold. The intuitive reason is that for the Blackwell order, not only the amount of information is important. Rather, the question is how much of the information that or preserve is relevant for a given fixed decision problem (that is, a given fixed utility function).
Given two channels
, suppose that
for all distributions of
S. In this case, we say that
is
more capable than
. Does this imply that
? The answer is known to be negative in general [
6]. In Proposition 2 we introduce a new surprising example of this phenomenon with a particular structure. In fact, in this example,
is a Markov approximation of
by a deterministic function, in the following sense: Consider another random variable
that arises from
S by applying a (deterministic) function
f. Given two random variables
S,
X, denote by
the channel defined by the conditional probabilities
, and let
and
. Thus,
can be interpreted as first replacing
S by
and then sampling
X according to the conditional distribution
. Which channel is superior? Using the data processing inequality, it is easy to see that
is less capable than
. However, as Proposition 2 shows, in general
.
We call
a Markov approximation, because the output of
is independent of the input
S given
. The channel
can also be obtained from
by “pre-garbling” (Lemma 3); that is, there is another stochastic matrix
that satisfies
. It is known that pre-garbling may improve the performance of a channel (but not its capacity) as we recall in
Section 2. What may be surprising is that this can happen for pre-garblings of the form
, which have the effect of coarse-graining according to
f.
The fact that the more capable preorder does not imply the Blackwell order shows that “Shannon information,” as captured by the mutual information, is not the same as “Blackwell information,” as needed for the Blackwell decision problems. Indeed, our example explicitly shows that even though coarse-graining always reduces Shannon information, it need not reduce Blackwell information. Finally, let us mention that there are further ways of comparing channels (or stochastic matrices); see [
5] for an overview.
Proposition 2 builds upon another effect that we find paradoxical: Namely, there exist random variables and there exists a function from the support of S to a finite set such that the following holds:
S and are independent given .
.
.
Statement (1) says that everything knows about S, it knows through . Statement (2) says that knows more about than . Still, (3) says that we cannot conclude that knows more about S than . The paradox illustrates that it is difficult to formalize what it means to “know more.”
Understanding the Blackwell order is an important aspect of understanding information decompositions; that is, the quest to find new information measures that separate different aspects of the mutual information
of
k random variables
and a target variable
S (see the other contributions of this special issue and references therein). In particular, [
7] argues that the Blackwell order provides a natural criterion when a variable
has unique information about
S with respect to
. We hope that the examples we present here are useful in developing intuition on how information can be shared among random variables and how it behaves when applying a deterministic function, such as a coarse-graining. Further implications of our examples on information decompositions are discussed in [
8]. In the converse direction, information decomposition measures (such as measures of unique information) can be used to study the Blackwell order and deviations from the Blackwell order. We illustrate this idea in Example 4.
The remainder of this work is organized as follows: In
Section 2, we recall how pre-garbling can be used to improve the performance of a channel. We also show that the pre-garbled channel will always be less capable and that simultaneous pre-garbling of both channels preserves the Blackwell order. In
Section 3, we state a few properties of the Blackwell order, and we explain why we find these properties counter-intuitive and paradoxical. In particular, we show that coarse-graining the input can improve the performance of a channel.
Section 4 contains a detailed discussion of an example that illustrates these properties. In
Section 5 we use the unqiue information measure from [
7], which has properties similar to the Le Cam’s deficiency, to illustrate deviations from the Blackwell relation.
2. Pre-Garbling
As discussed above (and as made formal in Blackwell’s theorem (Theorem 1)), garbling the output of a channel (“post-garbling”) never increases the quality of a channel. On the other hand, garbling the input of a channel (“pre-garbling”) may increase the performance of a channel, as the following example shows.
Example 1. Suppose that an agent can choose an action from a finite set . She then receives a utility that depends both on the chosen action and on the value s of a random variable S. Consider the channelsand the utility function For uniform input, the optimal decision rule for isand the oppositefor . The expected utility with is 1.4, while using , it is slightly higher (1.45). It is also not difficult to check that neither of the two channels is a garbling of the other (cf. Propsition 3.22 in [5]). The intuitive reason for the difference in the expected utilities is that the channel transmits one of the states without noise and the other state with noise. With a convenient pre-processing, it is possible to make sure that the relevant information for choosing an action and for optimizing expected utility is transmitted with less noise.
Note the symmetry of the example: each of the two channels arises from the other by a convenient pre-processing, since the pre-processing is invertible. Hence, the two channels are not comparable by the Blackwell order. In contrast, two channels that only differ by an invertible garbling of the output are equivalent with respect to the Blackwell order.
The pre-garbling in Example 1 is invertible, and so it is more aptly described as a pre-processing. In general, though, pure pre-garbling and pure pre-processing are not easily distinguishable, and it is easy to perturb Example 1 by adding noise without changing the conclusion. In
Section 3, we will present an example in which the pre-garbling consists of coarse-graining. It is much more difficult to understand how coarse-graining can be used as sensible pre-processing.
Even though pre-garbling can make a channel better (or, more precisely, more suited for a particular decision problem at hand), pre-garbling cannot invert the Blackwell order:
Lemma 1. If , then .
Proof. Suppose that . Then the capacity of is less than the capacity of , which is bounded by the capacity of . Therefore, the capacity of is less than the capacity of . ☐
Additionally, it follows directly from Blackwell’s theorem that
for any channel
, where the input and output alphabets of
equal the input alphabet of
. Thus, pre-garbling preserves the Blackwell order when applied to both channels simultaneously.
Finally, let us remark that certain kinds of simultaneous pre-garbling can also be “hidden” in the utility function; namely, in Blackwell’s theorem, it is not necessary to vary the distribution of as long as the support of the (fixed) input distribution has full support S (that is, every state of the input alphabet of and appears with positive probability). In this setting, it suffices to look only at different utility functions. When the input distribution is fixed, it is more convenient to think in terms of random variables instead of channels, which slightly changes the interpretation of the decision problem. Suppose we are given random variables and a utility function depending on the value of S and an action as above. If we cannot look at both and , should we choose to look at or at to make our decision?
Theorem 2. (Blackwell’s theorem for random variables [7]) The following two conditions are equivalent: - 1.
Under the optimal decision rule, when the agent chooses , her expected utility is always at least as large as the expected utility when she chooses , independent of the utility function.
- 2.
.
3. Pre-Garbling by Coarse-Graining
In this section we present a few counter-intuitive properties of the Blackwell order.
Proposition 1. There exist random variables and a function from the support of S to a finite set such that the following holds:
- 1.
S and are independent given .
- 2.
.
- 3.
.
This result may at first seem paradoxical. After all, property (3) implies that there exists a decision problem involving S for which it is better to use than . Property (1) implies that any information that has about S is contained in ’s information about . One would therefore expect that, from the viewpoint of , any decision problem in which the task is to predict S and to react on S looks like a decision problem in which the task is to react to . But property (2) implies that for such a decision problem, it may in fact be better to look at .
Proof of Proposition 1. The proof is by Example 2, which will be given in
Section 4. This example satisfies
S and are independent given .
.
.
It remains to show that it is also possible to achieve the strict relation in the second statement. This can easily be done by adding a small garbling to the channel (e.g., by adding a binary symmetric channel with sufficiently small noise parameter ). This ensures , and if the garbling is small enough, this does not destroy the property . ☐
The example from Proposition 1 also leads to the following paradoxical property:
Proposition 2. There exist random variables and there exists a function from the support of S to a finite set such that the following holds: Let us again give a heuristic argument for why we find this property paradoxical. Namely, the combined channel
can be seen as a Markov chain approximation of the direct channel
that corresponds to replacing the conditional distribution
by
Proposition 2 together with Blackwell’s theorem states that there exist situations where this approximation is better than the correct channel.
Proof of Proposition 2. Let
be as in Example 2 in
Section 4 that also proves Proposition 1, and let
. In that example, the two channels
and
are equal. Moreover,
and
S are independent given
. Thus,
. Therefore, the statement follows from
. ☐
On the other hand, the channel is always less capable than :
Lemma 2. For any random variables S, X, and function , the channel is less capable than .
Proof. For any distribution of
S, let
be the output of the channel
. Then,
is independent of
S given
. On the other hand, since
f is a deterministic function,
is independent of
given
S. Together, this implies
. Using the fact that the joint distributions of
and
are identical and applying the data processing inequality gives
The setting of Proposition 2 can also be understood as a specific kind of pre-garbling. Namely, consider the channel
defined by
The effect of this channel can be characterized as a randomization of the input: the precise value of S is forgotten, and only the value of is preserved. Then, a new value is sampled for S according to the conditional distribution of S given .
Lemma 3. .
Proof. where we have used that forms a Markov chain. ☐
While it is easy to understand that pre-garbling can be advantageous in general (since it can work as preprocessing), we find it surprising that this can also happen in the case where the pre-garbling is done in terms of a function f; that is, in terms of a channel that does coarse-graining.
4. Examples
Example 2. Consider the joint distributionand the function f: {0, 1, 2} → {0, 1} with f(0) = f(1) = 0 and f(2) = 1. Then, and are independent uniform binary random variables, and f(
S) = A
nd(
X1,
X2).
By symmetry, the joint distributions of the pairs and are identical, and so the two channels and are identical. In particular, . On the other hand, consider the utility function To compute the optimal decision rule, let us look at the conditional distributions: The optimal decision rule for is a(0) = 0, a(1) = 1, with expected utility The optimal decision rule for is a(0) = 0, a(1) ∈
{0, 1} (this is not unique in this case), with expected utility How can we understand this example? Some observations:
It is easy to see that has more irrelevant information than : namely, can determine relatively precisely when . However, since gives no utility independent of the action, this information is not relevant. It is more difficult to understand why has less relevant information than . Surprisingly, can determine more precisely when : if , then “detects this” (in the sense that chooses action 0) with probability . For , the same probability is only .
The conditional entropies of
S given
are smaller than the conditional entropies of
S given
:
One can see in which sense captures the relevant information for , and indeed for the whole decision problem: knowing is completely sufficient in order to receive the maximal utility for each state of S. However, when information is incomplete, it matters how the information about the different states of S is mixed, and two variables that have the same joint distribution with may perform differently. It is somewhat surprising that it is the random variable that has less information about S and that is conditionally independent of S given which actually performs better.
Example 2 is different from the pre-garbling Example 1 discussed in
Section 2. In the latter, both channels had the same amount of information (mutual information) about
S, but for the given decision problem the information provided by
was more relevant than the information provided by
. The first difference in Example 2 is that
has less mutual information about
S than
(Lemma 2). Moreover, both channels are identical with respect to
; i.e., they provide the same information about
, and for
it is the only information it has about
S. So, one could argue that
has additional information that does not help, but decreases the expected utility instead.
We give another example which shows that can also be chosen as a deterministic function of S.
Example 3. Consider the joint distribution The function f is as above, but now also is a function of S. Again, the two channels and are identical, and is independent of S given . Consider the utility function One can show that it is optimal for an agent who relies on to always choose action 0, which brings no reward (and no loss). However, when the agent knows that is zero, he may safely choose action 1 and has a positive probability of receiving a positive reward.
To add another interpretation to the last example, we visualize the situation in the following Bayesian network:
where, as in Proposition 2 and its proof, we let
, and we consider
as an approximation of
X. Then,
S denotes the state of the system that we are interested in, and
X denotes a given set of observables of interest.
can be considered as a “proxy” in situations where it is difficult to observe
X directly. For example, in neuroimaging, instead of directly measuring the neural activity
X, one might look at an MRI signal
. In economic and social sciences, monetary measures like the GDP are used as a proxy for prosperity.
A decision problem can always be considered as a classification problem defined by the utility by considering the optimal action as the class label of state S. Proposition 2 now says that there exist , and a classification problem , such that the approximated features (simulated from ) allow for a better classification (higher utility) than the original features X.
In such a situation, looking at will always be better than looking at either X or . Thus, the paradox will only play a role in situations where it is not possible to base the decision on directly. For example, might still be too large, or X might have a more natural interpretation, making it easier to interpret for the decision taker. However, when it is better to base a decision on a proxy rather than directly on the observable of interest, this interpretation may be erroneous.
5. Information Decomposition and Le Cam Deficiency
Given two channels
, how can one decide whether or not
? The easiest way is to check whether the equation
has a solution
that is a stochastic matrix. In the finite alphabet case, this amounts to checking the feasibility of a linear program, which is considered computationally easy. However, when the feasibility check returns a negative result, this approach does not give any more information (e.g., how far
is away from being a garbling of
). A function that quantifies how far
is from being a garbling of
is given by the
(Le Cam) deficiency and its various generalizations [
9]. Another such function is given by
defined in [
7] that accounts for the fact that the channels we consider are of the form
and
; that is, they are derived from conditional distributions of random variables. In contrast to the deficiencies,
depends on the input distribution to these channels.
Let
be a joint distribution of
S and the outputs
and
. Let
be the set of all joint distributions of the random variables
(with the same alphabets) that are compatible with the marginal distributions of
for the pairs
and
; i.e.,
In other words,
consists of all joint distributions that are compatible with
and
and that have the same distribution for
S as
. Consider the function
where
denotes the conditional mutual information evaluated with respect to the the joint distribution
Q. This function has the following property:
if and only if
[
7]. Computing
is a convex optimization problem. However, the condition number can be very bad, which makes the problem difficult in practice.
is interpreted in [
7] as a measure of the
unique information that
conveys about
S (with respect to
). So, for instance, with this interpretation Example 2 can be summarized as follows: neither
nor
has unique information about
. However, both variables have unique information about
S, although
is conditionally independent of
S given
and thus—in contrast to
—contains no “additional” information about
S. We now apply
to a parameterized version of the
And gate in Example 2.
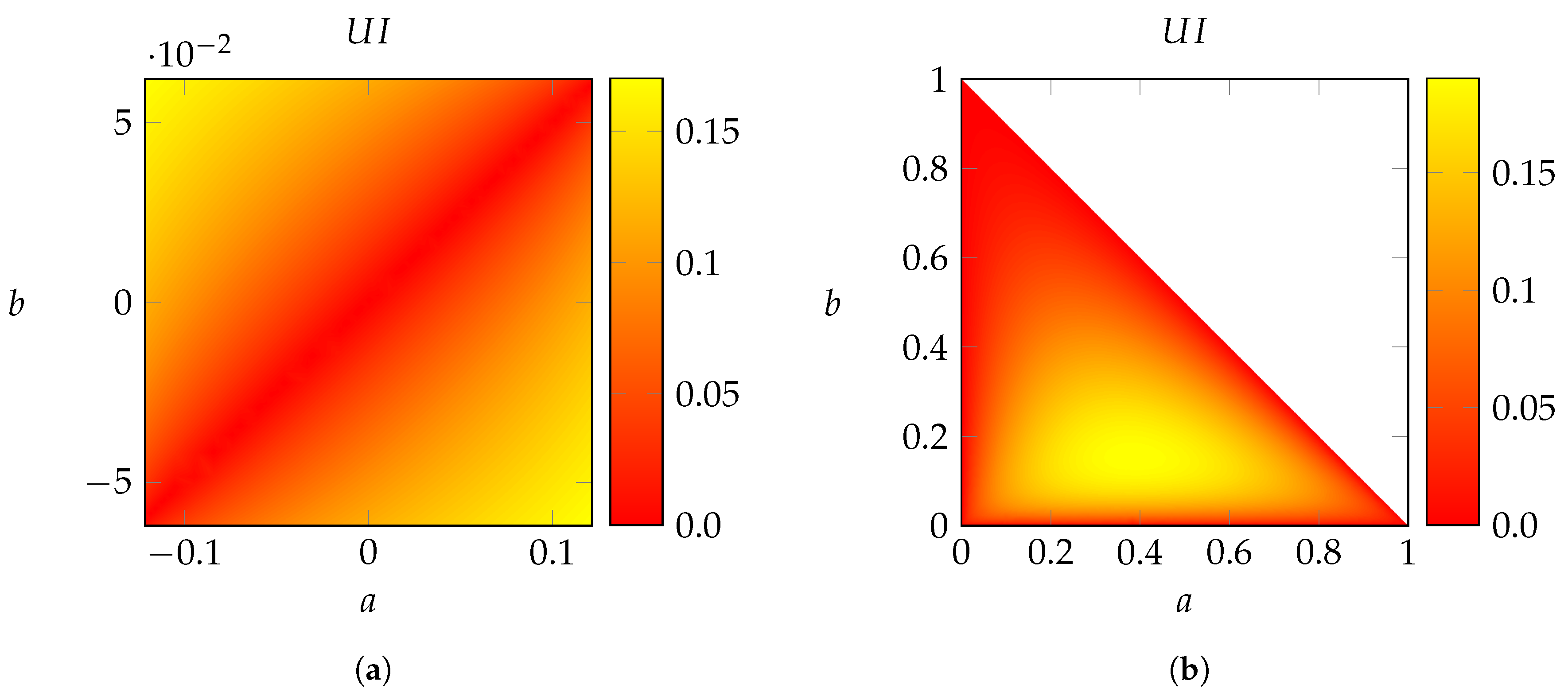
Example 4. Figure 1a shows a heat map of computed on the set of all distributions of the formwhere and . This is the set of distributions of that satisfy the following constraints: - 1.
are independent;
- 2.
f(S) = And(X1, X2), where f is as in Example 2; and
- 3.
is independent of S given .
Along the secondary diagonal , the marginal distributions of the pairs and are identical. In such a situation, the channels and are Blackwell-equivalent, and so vanishes. Further away from the diagonal, the marginal distributions differ, and grows. The maximum value is achieved at the corners for , . At the upper left corner , we recover Example 2.
Example 5. Figure 1b shows a heat map of computed on the set of all distributions of the formwhere and . This extends Example 3, which is recovered for . This is the set of distributions of that satisfy the following constraints: - 1.
is a function of S, where the function is as in Example 3.
- 2.
is independent of S given .
- 3.
The channels and are identical.

 ,
, 

{kind=link}
