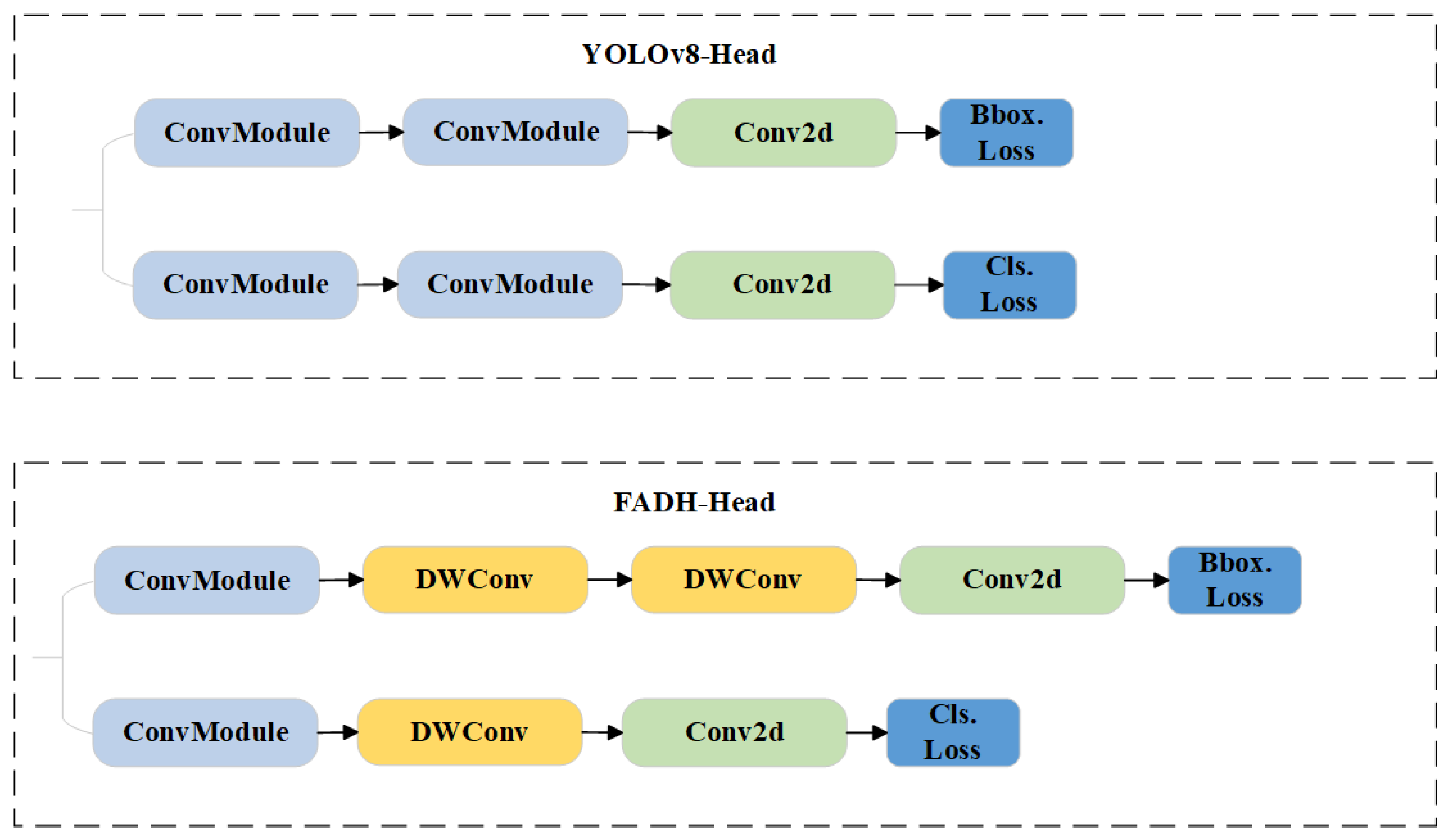
4.4. Ablation Experiment
To evaluate the effectiveness of the proposed FP-YOLOv8 model for end surface defect detection, a series of ablation experiments were conducted using YOLOv8n as the baseline. The results are summarized in
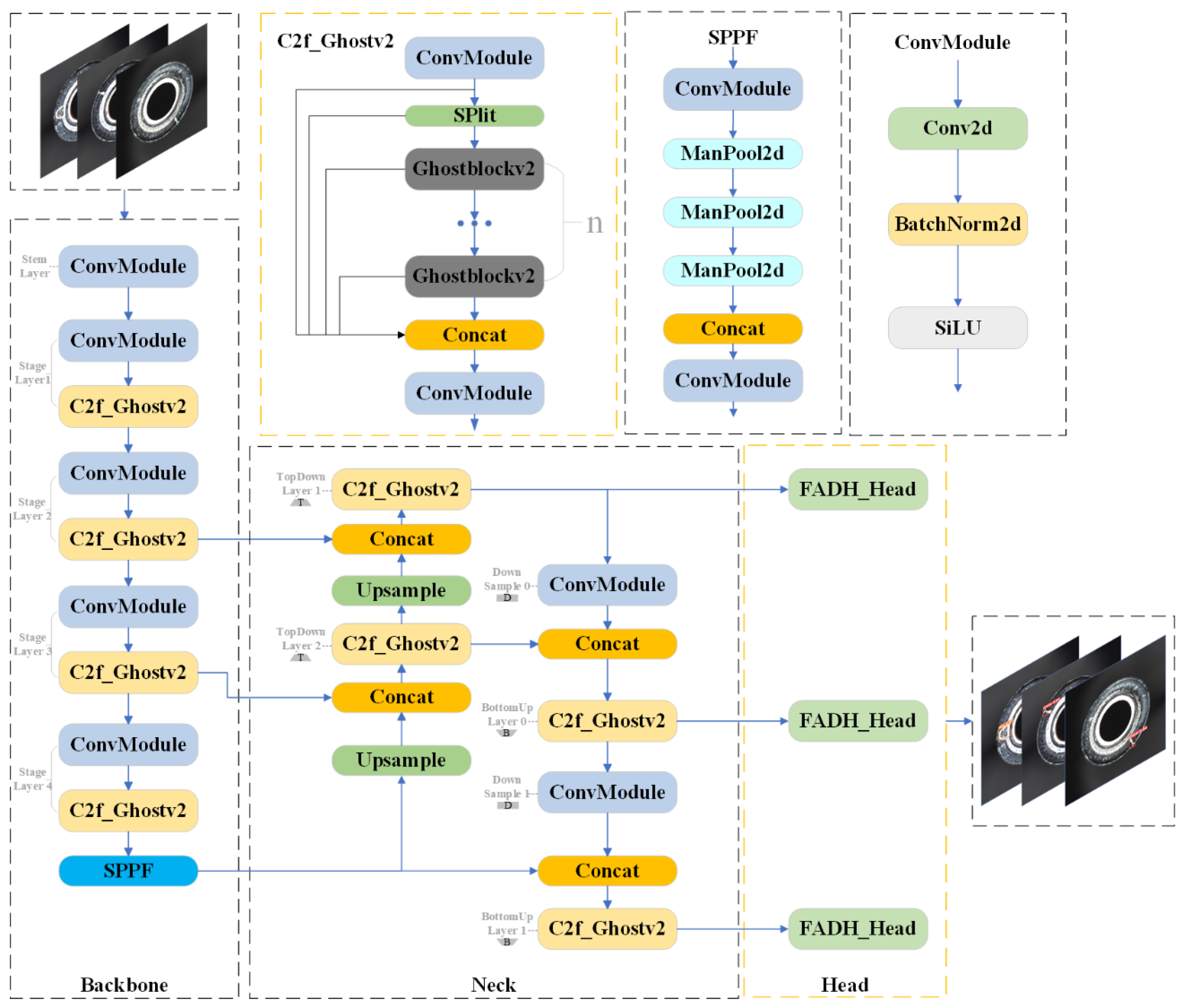
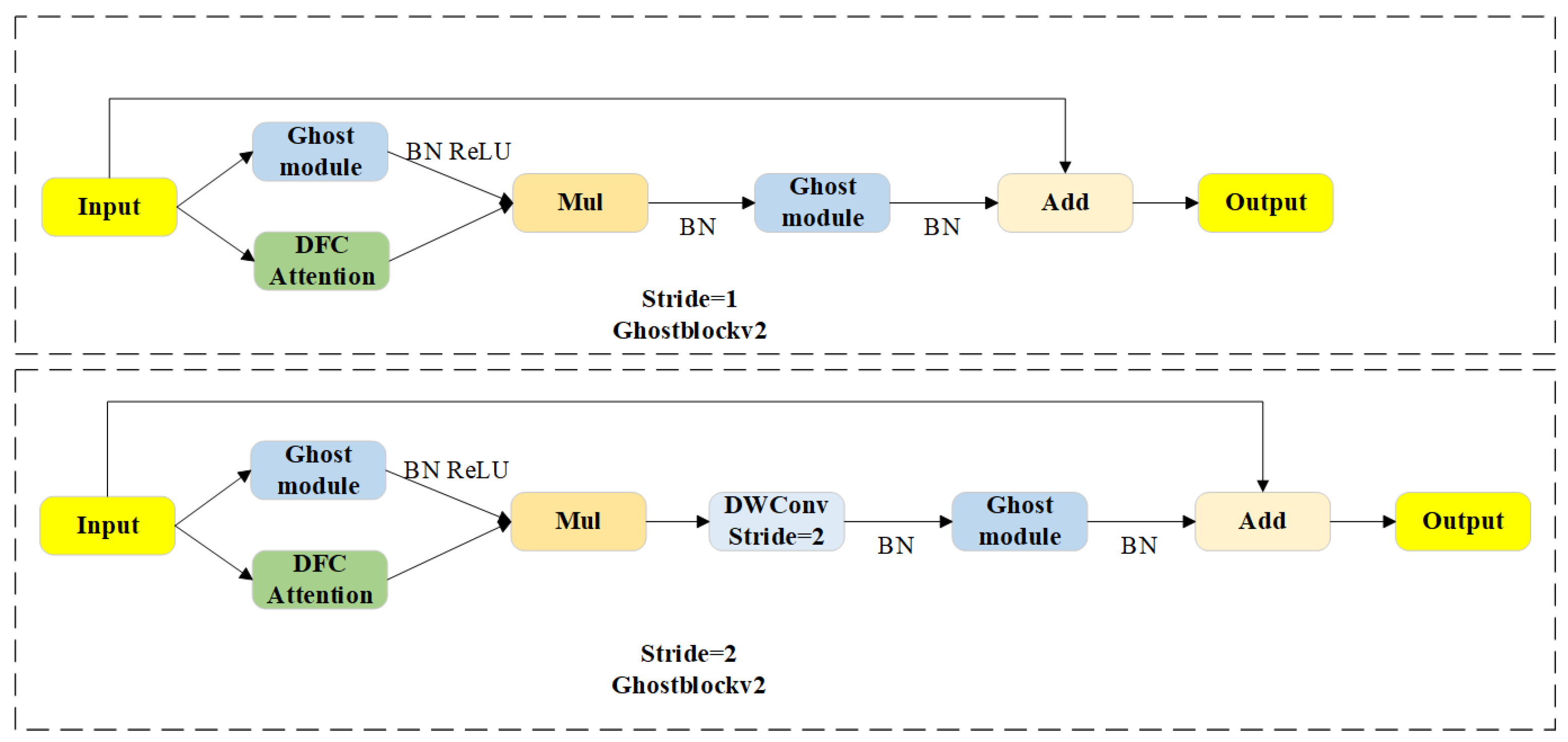
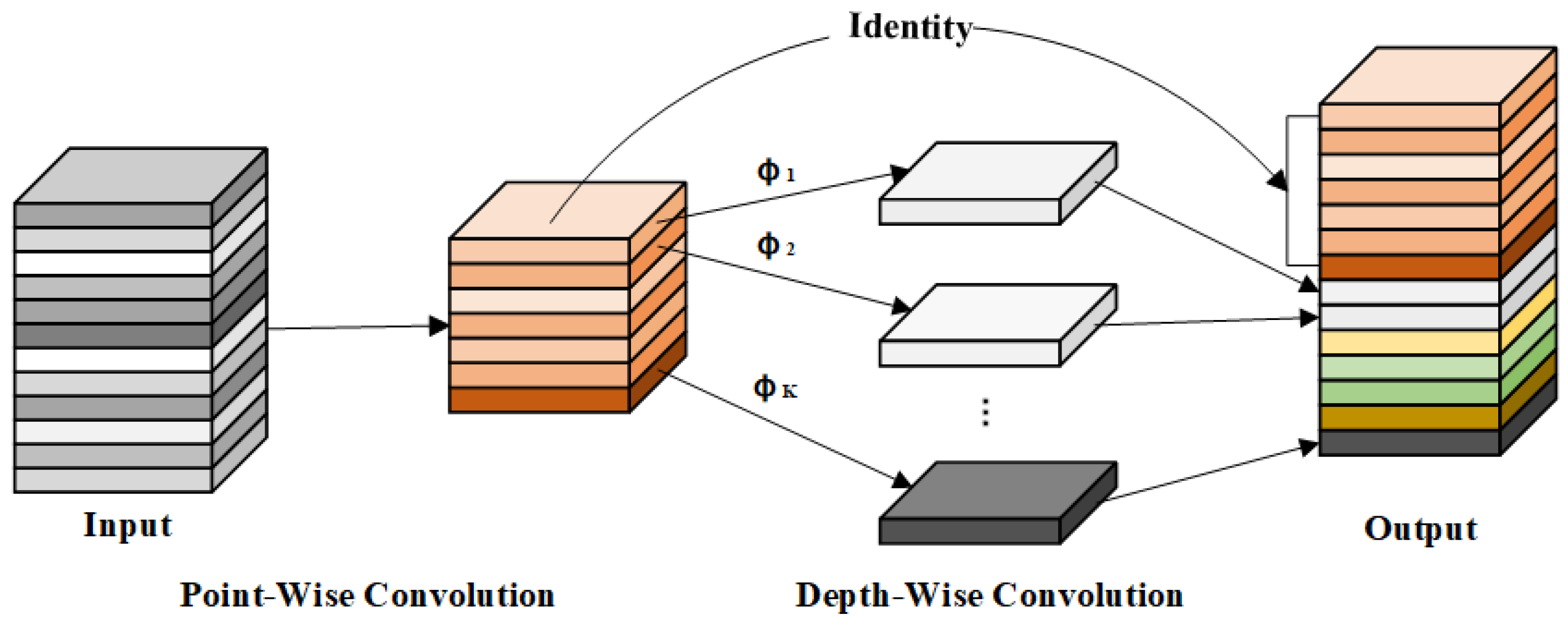
Table 3. The modules A, B, and C in the table represent the C2f_GhostV2, Dynamic ATSS, and FADH modules, respectively, with √ next to A, B, and C indicating that these modules were added to the baseline model. Experimental results demonstrate that integrating the C2f_GhostV2 module reduces the number of parameters and computations by 14.3% and 21.0%, respectively, although it slightly lowers mAP50 and F1-score. This module leverages multiple Ghost modules to efficiently generate feature maps with fewer parameters through point-wise and depth-wise convolutions, thereby reducing the model’s complexity. Despite this, the layer count increases from 185 to 257, enhancing the model’s capacity for hierarchical feature learning and improving representational ability. Replacing the global attention mechanism with the DFC attention mechanism further reduces computational cost while strengthening feature representation. Upon introducing Dynamic ATSS, mAP50, and F1-score improved by 2.3% and 1.0%, respectively. This improvement is attributed to the adaptive label assignment strategy, which dynamically adjusts the IoU threshold, correctly classifying more high-quality samples as positive and enhancing detection accuracy. Following the integration of FADH, the model achieved an accuracy of 83.2%, recall of 86.2%, mAP50 of 89.0%, and an F1-score of 84.0%, improving by 2.9%, 4.0%, 2.8%, and 3.0%, respectively. These results demonstrate that FADH effectively enhances small-target detection by leveraging depth-wise separable convolutions to optimize feature extraction and reduce computational costs. The decoupled design minimizes task coupling, allowing for more precise learning of classification and regression tasks. This balance between efficiency and accuracy underscores FADH’s suitability for improving small-target defect detection.
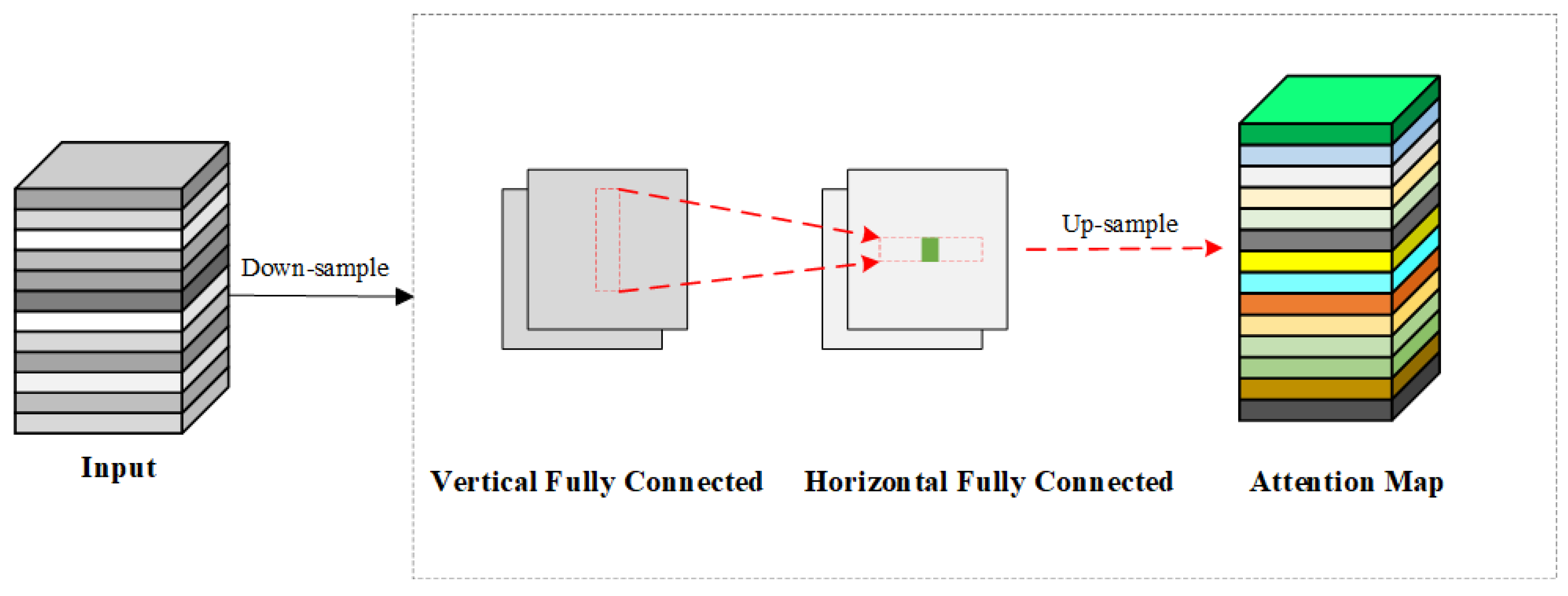
Furthermore, this paper investigates the performance of different combinations of modules A, B, and C. Integrating module B into module A improves mAP50 by 1.6%, reaching 86.2%, and raises the F1-score to 81%, while reducing the parameter count and computational cost by 14.3% and 21.0%, respectively. Ghost Modules within C2f_GhostV2 efficiently generate additional feature maps through simple linear transformations. To balance efficiency and effectiveness, the DFC attention mechanism operates on down-sampled features (halved in width and height) to cut 75% of its FLOPs, with up-sampling applied afterward to restore resolution. This combination, alongside Dynamic ATSS, which dynamically refines label allocation, results in improved accuracy and adaptability to complex scenes.
For the B + C combination, the model achieves a mAP50 of 84.6% and an F1-score of 83%. FADH, with its depth-wise separable convolutions, strengthens small-object detection, while its decoupled detection head optimizes classification and regression tasks. Dynamic ATSS refines sample assignment, enabling the model to better handle the challenges posed by diverse object shapes and sizes.
The combination of A + C yields significant improvements. mAP50 increases by 2.8%, reaching 89%, and detection accuracy improves to 87.6%, reflecting a 7.3% gain compared to the baseline model. Remarkably, these improvements are achieved while maintaining the same parameter count and computational cost as the A model. The DFC attention mechanism of C2f_GhostV2 captures precise spatial relationships, laying a foundation for feature enhancement. Simultaneously, the depth-wise convolutions in FADH fully utilize these enhanced features, achieving fine-grained feature representation and improved small-object detection. The synergy between C2f_GhostV2 and FADH demonstrates their strong complementarity, elevating the performance of the A + C model to new heights.
When all three modules are integrated into the FP-YOLOv8 model, significant improvements are observed. Precision, recall, mAP50, and F1-score increase by 4.3%, 8.6%, 3.3%, and 6.0%, respectively, compared to the baseline. Both computational cost and parameter count are reduced by 21.0% and 14.3%, respectively. This synergy between C2f_GhostV2, FADH, and Dynamic ATSS enhances feature representation and model efficiency, leading to substantial performance gains. C2f_GhostV2 focuses on reducing redundant features and capturing long-range spatial dependencies, while FADH strengthens fine-grained feature extraction and small-object detection. Dynamic ATSS improves detection accuracy by dynamically adjusting label assignments.
In this paper, each defect type was analyzed independently to comprehensively investigate the impact of different modules on the detection of diverse defect types. The results are presented in
Table 4, where Cr, Sc, Sk, and Fl stand for cracks, scratches, skins, and flash defects, respectively, and modules A, B, and C represent the C2f_GhostV2, Dynamic ATSS, and FADH modules, respectively, with √ next to A, B, and C indicating that these modules were added to the baseline model.
The integration of the C2f_GhostV2 module resulted in a reduction in model parameters and computational complexity, accompanied by a modest decrease in detection accuracy for certain defect types. Specifically, the accuracy for cracks, scratches, and flash defects decreased by 0.4%, 1.5%, and 7.5%, respectively, while skin defect detection improved by 3.2%. These results highlight the efficiency gains achieved by C2f_GhostV2, although they also indicate a trade-off in precision, particularly for flash defects, while suggesting potential benefits for skin defect detection.
For the Dynamic ATSS module, upon introduction, the detection accuracies for cracks, scratches, skins, and flash defects improved by 4.3%, 3.2%, 0.9%, and 0.8%, respectively, relative to the baseline. This clearly shows that the adaptive label assignment within Dynamic ATSS significantly enhances the detection accuracy across all defect types. Notably, it is especially beneficial for small targets in complex backgrounds, highlighting its crucial role in improving the detection of such challenging scenarios within different defect types.
With the introduction of FADH module, the detection accuracies for cracks, scratches, and skins improved by 6.8%, 0.3%, and 4.5%, respectively, although the detection accuracy for flash defects slightly decreased. This indicates that FADH is more effective in capturing detailed information at different scales, thereby improving the detection of small-object defects like cracks, scratches, and skins. It demonstrates that FADH has a distinct advantage over the original detection head of YOLOv8 in handling specific small-scale features within these defect types.
When C2f_GhostV2, Dynamic ATSS, and FADH are combined, the detection accuracies for cracks, scratches, skins, and flash defects reach 81.8%, 95.4%, 91.8%, and 89.1%, respectively. Compared to the baseline, there are improvements of 5.5%, 5.6%, and 2.3% in the detection of cracks, scratches, and flash defects. This combined model demonstrates excellent performance with enhanced sensitivity towards small-target defects. It implies that the synergy among these modules effectively addresses the challenges in detecting different defect types, particularly those related to small targets.
Additionally, the confusion matrices of the baseline YOLOv8n model and the FP-YOLOv8 model are presented in
Figure 9. The analysis of these matrices reveals that FP-YOLOv8 outperforms YOLOv8n by achieving a higher proportion of correctly classified defect types and a lower proportion of misclassifications of defect types as background. This further demonstrating the superior detection capability of FP-YOLOv8 in handling various defect types, providing more reliable results in the defect detection process.
To visually emphasize the performance gains of the proposed algorithm, heat maps generated using HiResCAM for defect identification on the end surface under the influence of different modules are shown in
Figure 10. It is evident from the figure that FP-YOLOv8 effectively focuses on defect locations and emphasizes the features of target defects in the foreground, with minimal interference from background noise.
4.5. Comparative Experiments on the Ends Surface Defect Dataset
To demonstrate the effectiveness of the proposed FP-YOLOv8 algorithm, we conducted a series of experiments using the ends surface defect dataset and compared it with several established target detection models. The results presented in
Table 5 indicate that models such as YOLOv8n, Faster-RCNN, SSD, and Retina-Net have inferior detection accuracy, accompanied by significantly higher parameter counts and computational requirements, making them challenging to deploy on resource-limited devices. Compared to other YOLO models, YOLOv3-Tiny [
40] and YOLOv6n [
41] fall behind YOLOv8n in both detection accuracy and parameter efficiency. While YOLOv5n [
42] has a simplified structure, it does not show significant improvements in detection. Although YOLOv10n [
43] is a newer model, it does not outperform YOLOv8n. Based on a comprehensive analysis of detection accuracy, model parameters, and computational cost, YOLOv8n serves as the baseline model in this paper.
As indicated in
Table 5, the FP-YOLOv8 model surpasses other models in mAP50, F1-score, and computational efficiency, providing the most effective balance between detection accuracy and model complexity. Specifically, compared with the baseline YOLOv8n, FP-YOLOv8 improves mAP50 and F1-score by 3.3% and 6.0%, respectively, while reducing the number of parameters by 14.3% and the GFLOPs by 21.0% (from 8.1 to 6.4). Additionally, FP-YOLOv8 achieves a higher detection speed (FPS) compared to YOLOv8n. Compared with the two-stage detector Faster-RCNN, FP-YOLOv8 has only 6.2% of the parameters and requires just 4.8% of the computation, with a reduction of 128.3M GFLOPs. To further illustrate the performance differences, the metrics in
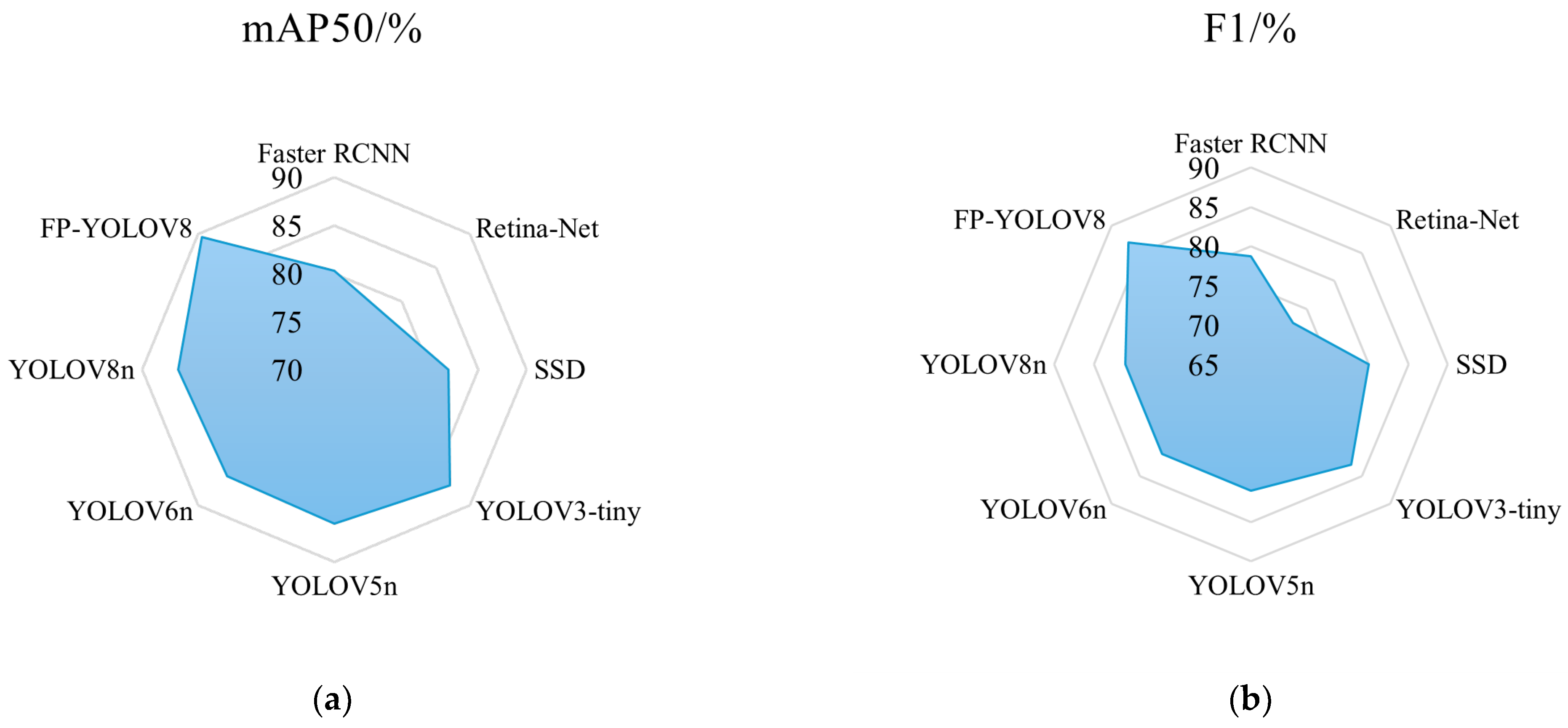
Table 5 are presented in both radar charts (
Figure 11) and bar charts (
Figure 12). As shown in
Figure 11, FP-YOLOv8 achieves the best detection performance for ends surface defects.
Figure 12 shows that FP-YOLOv8 delivers higher detection accuracy while consuming fewer computational resources.
Table 6 presents the detection accuracies of different models for four types of defects: cracks, scratches, skins, and flash defects. The results indicate that FP-YOLOv8 significantly outperforms other models in detecting cracks, scratches, and flash defects. While its performance in detecting skin defects is slightly lower than that of YOLOv3-Tiny, FP-YOLOv8 still achieves competitive accuracy. Overall, FP-YOLOv8 strikes an excellent balance between detection accuracy, model size, and computational complexity. It offers the advantages of a compact model, reduced computation, and fast detection, making it highly suitable for practical applications.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}