1. Introduction
The share of wind energy among various energy sources has grown significantly to 7.8% of the world’s energy consumption [
1]. Wind energy worldwide has now grown to more than 1000 GW, with most of the wind energy growth occurring in China and the United States [
2]. According to the VTT Technical Research Center [
3], approximately 20% of all wind turbine installations are in cold climate regions. In these regions, icing of wind turbines has a significant negative impact on the power generation capacity of wind farms. For example, wind turbine blade icing changes the aerodynamic shape of its surface, thus reducing its power production. It could also lead to stalling of the blades due to ice buildup. Also, because of the non-uniformity of icing, the blades would bear unbalanced loads, resulting in rotor imbalance and thus increasing the chance of structural damage. Furthermore, ice on the blades may break off and fly away at high speeds, posing a potential safety hazard to the equipment and operating personnel.
There are many works in the literature related to the detection of icing on wind turbines using SCADA data, e.g., [
4,
5,
6,
7,
8]. Detection involves obtaining whether icing exists at the current time. This work addresses icing prediction, which is different than icing detection as it involves forecasting the presence of icing at a future time. Similar to the icing detection problem, SCADA data and weather data are used here as input for icing prediction. The capability to predict icing on wind turbines ahead of time would allow taking appropriate actions such as shifting electricity production to other sources of energy, shutting down the equipment to avoid damage, or turning on heaters for those turbines that are equipped with them.
The literature on modern icing prediction or forecasting on wind turbines covers the use of deep learning networks based on SCADA (Supervisory Control and Data Acquisition) data without requiring the installation of new sensors other than those used for collecting SCADA data. In the review article [
9], we discussed the existing techniques for icing prediction together with their shortcomings. In [
10,
11], our research team introduced a prediction framework to forecast icing on wind turbines and an entire wind farm based on SCADA data via Temporal Convolutional Network (TCN) predictors. An average prediction accuracy of about 80% was reported in [
10]. In this paper, we have developed a new deep neural network model for the purpose of achieving high icing prediction accuracies at long prediction horizons.
In deep learning-based approaches to icing prediction, as depicted in
Figure 1, the current and previous values of the variables or features in SCADA data are used as the input to a deep learning network to predict one of the two states of normal operation and icing at a future time as the network output.
Previous papers on icing prediction have utilized two major types of network models to establish the relationship between historical data and future icing states. The first type has focused on capturing the temporal aspect of SCADA data, e.g., [
12,
13,
14]. However, these models mainly capture the temporal aspect of the SCADA features and do not take into consideration the spatial relationships between the features such as temperature, humidity, and wind speed. The second type of network models has focused on utilizing multiple learners to capture patterns between historical data and future icing states, e.g., [
15,
16,
17,
18,
19]. By using multiple learners, the nonlinear relationships between the SCADA features are more effectively captured. However, such models normally assume that the input features are independent, and their temporal dependency is not taken into consideration, thus making the outcome highly dependent on the selected SCADA features. In a recent paper [
20], icing prediction was performed by capturing spatial relationships between SCADA data features. It is often challenging for such models to ensure that the captured relationships between the features are meaningful, especially for the features that are influenced by the climate, such as temperature, humidity, and wind speed.
As discussed in detail in [
9], among the deep learning networks that have been applied to icing prediction, in general, higher accuracies are reported with combined networks. A combined or ensemble network usually consists of the use of two networks. Different ways are considered to integrate such two networks for capturing both the temporal and spatial information in SCADA data. For example, the CNN (Convolutional Neural Network) and GRU (Gated Recurrent Unit) were used together in [
21], or bidirectional LSTM (Long Short-Term Memory) and an SVM (Support Vector Machine) were used together in [
19]. Here, it is important to note that certain limitations exist in the existing papers when it comes to comparing their results, including differences in SCADA features used as input, differences in prediction horizons, and the use of different datasets that are not publicly available.
The main contribution of this paper lies in developing a new deep learning architecture that combines local temporal features, their long-term relationships, and their global dependency. Compared with the existing models used for icing prediction, this new model offers higher icing prediction accuracies over longer prediction horizons.
The remaining sections of this paper are organized as follows.
Section 2 introduces the ensemble model named PCTG towards achieving high-accuracy and long-term prediction of icing on wind turbine blades. Then,
Section 3 provides a description of the SCADA features used and their preprocessing. Furthermore, the experimental setup together with the evaluation metrics are stated in this section.
Section 4 presents the experimental results and their discussion in terms of prediction performance and computational aspects. Finally, the conclusions and future enhancements are mentioned in
Section 5.
2. Ensemble Network PCTG
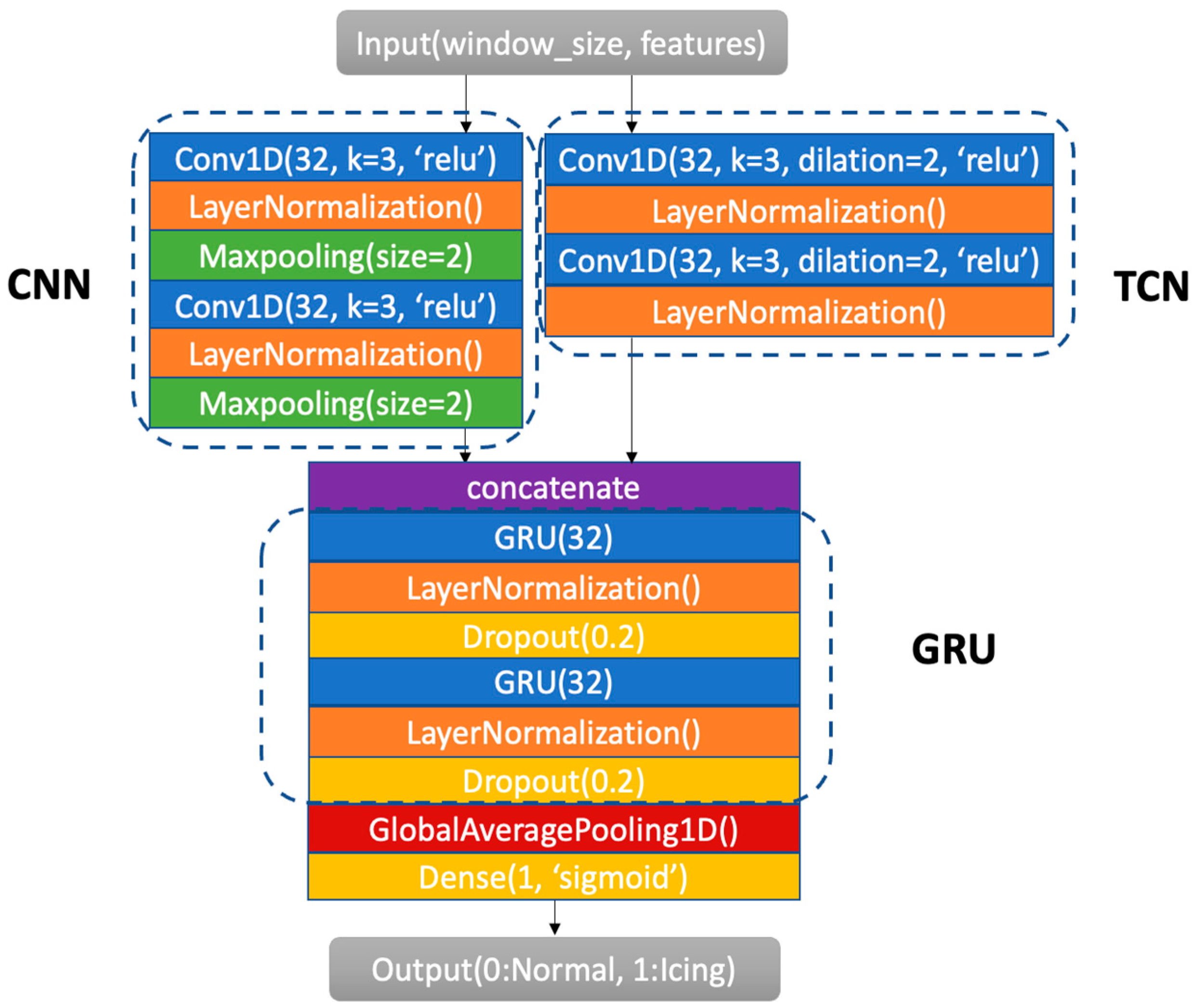
In this paper, a new network is introduced for the prediction of icing by adding CNN and GNU layers to our previously developed TCN.
Figure 2 shows the architecture of this ensemble network. The incorporation of CNN and GRU layers into the TCN allows for the more effective capture of relationships between SCADA features. The combination of these networks is named PCTG (Parallel CNN-TCN GRU) network. The PCTG uses the CNN and TCN in parallel and then integrates their outputs into the GRU. All three of these networks have been previously used for prediction tasks in different applications. The CNN has been used to capture local changes or to extract local temporal features. The TCN has been used to capture long-term dependencies through dilated convolutions. The GRU has been used to capture global time dependency via a gate mechanism. These networks have been combined in this work to take advantage of their complementary prediction attributes. Further details of this new architecture are stated next.
2.1. Objective Function
Wind turbine icing prediction can be viewed as a sequential two-class classification problem. For such problems, binary cross-entropy is commonly used as the loss function. In other words, the output probability that minimizes the following loss function is obtained:
where
N represents the number of data samples,
true icing label (0 or 1), and
predicted probability by the model (a value between 0 and 1).
Consider a dataset represented by
, where
denotes the input corresponding to the
nth SCADA feature or variable.
denotes the CNN, TCN, or GRU output values of channel
c at time
t.
The outputs for the CNN and TCN modules process the input SCADA data independently, and then they are concatenated and fed into the GRU module to obtain predicted probabilities.
2.2. CNN Module
The CNN module consists of two CNN layers aimed at capturing local temporal patterns in a sequence or time series. Given a dataset
, we assume
, where
denotes the CNN kernel function associated with the
nth SCADA feature. Convolution is used for extracting local attributes of the features by sliding a commonly used convolution kernel of size 3 [
22] over input data according to
Normalization and maxpooling layers are then added for the purpose of stabilizing the gradient computation and making the differences more prominent. In other words,
where
denotes the
t’th convolutional outcome of
and
for the
nth SCADA feature,
the
t’th layer normalization of the kernel function associated with
for channel
c. Finally, ReLU (Rectified Linear Unit) is utilized for the nonlinearity mapping to the output
Essentially, the use of the CNN allows local patterns of features in a time series to be extracted via convolution and maxpooling operations.
2.3. TCN Module
The TCN module consists of two TCN layers to extract long-term temporal dependencies. Dilated convolutions are carried out as follows:
Layer normalization is then applied to stabilize the gradient computation, which is
where
represents the
t’th convolutional outcome of
and
for the
nth SCADA feature,
the
t’th layer normalization of the kernel function associated with
for channel
c. Finally, ReLU (Rectified Linear Unit) is utilized for the nonlinearity mapping to the output
By dilated convolutions, the extracted patterns by the TCN are made more global-capturing long-term dependencies in a time series.
2.4. GRU Module
The outputs from the CNN and TCN modules are concatenated and inputted into a GRU module. Let the input to the GRU module be
The GRU module consists of two layers. Each layer comprises two gates: an update gate and a reset gate. These two gates maintain and adjust the state of the network by controlling the flow of information towards capturing the dependencies in time-series data. The GRU computation can be expressed as
where
represents the update gate determining how much of the information from the previous time step is passed to the current time step towards capturing long-term dependencies;
represents the reset gate determining how much of the hidden state information from the current input to the previous time step is discarded towards capturing short-term dependencies;
denotes the current memory generated by combining the current input and the hidden state of the previous time step adjusted via the reset gate;
denotes the hidden state, which is generated by balancing the hidden state of the previous time step and the current memory content via the update gate;
,
, and
denote weight matrices for the update gate, the reset gate, and the current memory, respectively. Layer normalization is applied to stabilize the gradient computation, and the dropout layers are applied to avoid model overfitting, which is
The GRU module controls the flow of data and updates the hidden states through a mechanism of resetting and updating gates. In other words, after concatenating the CNN and TCN outputs, the GRU first captures all prominent local attributes and then gradually fits their trend within a long-term relationship. As a result, compared with the CNN-GRU, the long-term trend of a time series gets more effectively captured, and thus a more accurate prediction of a far future time can be made. Compared with the TCN, this is equivalent to setting some threshold points in advance as a regularization term to prevent overfitting. The above combined network of the CNN, TCN, and GRU forms a new ensemble network named PCTG (Parallel CNN-TCN GRU).
3. Data Preprocessing and Experiment Settings
For the experiments conducted, the SCADA data of three wind turbines of a wind farm used in [
10] were considered. The accuracy and stability of the PCTG were compared with four previous prediction models. The same feature selection and ice labeling methods in [
10] were used here. The weather data corresponding to temperature and relative humidity were also added to the SCADA data as additional features. The dataset examined contains 14,000 data samples of 12 SCADA variables/features, as reported in [
10], at a sampling rate of one sample per 10 min from January 2023 to April 2023.
Table 1 includes all the features or variables used as input for the ensemble network PCTG.
Based on the ice labeling rules in [
10], about 35% of the data of the winter season from January to April generated icing state labels. For data balancing, the number of normal operation data samples was chosen to be the same as the number of icing data samples. The ratio of training to testing was set to 80% to 20% randomly chosen with no overlap between them.
Table 2 lists the rules used in [
8] for labeling data samples as ice or normal states, and
Table 3 lists the number of data samples used for the training and testing.
3.1. Baseline Models
In this study, the following baseline models were compared to our newly developed model: 1D-CNN, LSTM, CNN-GRU, XGBoost, and TCN. These models were considered due to their capabilities to cope with time-series data and their proven effectiveness in prior works discussed in [
9].
The 1D-CNN is adept at capturing local temporal patterns in sequential data through convolutional operations. This model is considered to serve as a baseline due to its simplicity in processing time-series data. LSTM is a type of RNN (Recurrent Neural Network) designed to learn long-term dependencies in time-series data. It is included here as another baseline model because of its widespread use and success in various time-series prediction tasks. XGBoost (Extreme Gradient Boosting) is another baseline model considered here that uses gradient boosted decision trees to conduct prediction. CNN-GRU is a combined model that integrates the 1D-CNN with the GRU. It utilizes the strength of the CNN to capture spatial patterns and the strength of the GRU to capture temporal dependencies. This combined network is also included as another baseline model due to its high accuracy, as reported in [
23]. TCN is another form of convolutional network tailored for time-series data. It was used in the previous study by our research team in [
8], and thus it is included here as yet another baseline model.
3.2. Window Size
The size of the window used for the input data to the models plays a crucial role in the prediction. If the window size is too short, it fails to provide sufficient input information for constructing a stable prediction model. Conversely, if the window size is excessively long, it leads to little attention to local changes and higher noise, thus diminishing prediction accuracy.
We started with the window size of 21 units (each unit represents 10 min) as reported in [
10] and increased it in steps of 4 units instead of 1 unit in order to save training time by not doing retraining for every single step size. The average prediction accuracy across the prediction horizons from 1 h to 48 h ahead was then considered to set the best window size. The window size was increased till the average prediction accuracy started falling, which was an indication of overfitting.
Figure 3 shows the result of the window size selection experiment. As can be seen from this figure and
Table 4, the best window size depends on the model used. For the next set of experiments, the best window size of each model was considered for testing. In
Figure 3, points marked by ‘
x’ represent the highest point before the accuracy drops as the window size grows, and the value shown are the accuracies at that point.
3.3. Prediction Accuracy
The commonly used metrics of accuracy and F1-score were computed to evaluate the performance of the developed wind turbine icing prediction model. Accuracy measures the portion of all the samples for which the model predicts correctly as indicated by
where icing state was taken to be positive and normal state to be negative; True Positive (TP) denotes the number of samples that were predicted to be positive, which were actually positive, while True Negative (TN) denotes the number of samples predicted to be negative, which were actually negative. Conversely, False Positive (FP) represents the number of samples predicted to be positive but were actually negative, and False Negative (FN) represents the number of samples predicted to be negative but were actually positive.
F1-score is another measure, which corresponds to the harmonic mean of Precision and Recall as defined in the following equations:
where Precision denotes the ratio of the samples that are in an actual icing state to those predicted to be in an icing state, and Recall denotes the ratio of the icing state samples that are correctly predicted to all the icing state samples. F1-score is a measure, which is inversely related to the number of incorrectly predicted samples. In other words, the higher the F1-score is, the lower the false prediction errors are.
3.4. Computational Aspects
This subsection includes the computational aspects of the model developed in comparison with the existing models. These aspects are shown in
Table 5 in terms of the number of parameters, training time, and prediction time for each model on the T4 GPU of Google Colab [
24]. The experiments were conducted using Python libraries TensorFlow (version 2.17), NumPy (version 1.26), and scikit-learn (version 1.6) on Google Colab.
Although our model takes more time to train than the other models, it should be noted that the training is carried out offline; that is, it does not play a role in the actual real-time deployment of our prediction solution. The offline training is carried out only once. What matters is how long it takes to perform a prediction as a new data sample becomes available. As shown in
Table 5, all the models carry out a prediction within a few milliseconds, which is far shorter than the data or decision update rate of 10 min. In other words, the prediction process, regardless of which model is deployed, operates in real time, noting that real time here means a prediction is made as soon as a new SCADA data sample becomes available.
5. Conclusions and Future Enhancements
In this paper, a new combined or ensemble deep learning network model named PCTG is introduced for the purpose of high-accuracy and long-term prediction of icing on wind turbine blades based on SCADA data. This model integrates the advantages of the CNN, TCN, and GRU by incorporating both short-term and long-term temporal patterns as well as dependencies on SCADA variables. The experimentations carried out have shown that this new model achieves high prediction accuracies across long prediction horizons for the two datasets examined. In summary, the newly developed data-driven icing prediction model of PCTG provides higher prediction accuracies and, at the same time, longer prediction horizons than the previously used models for the prediction of icing on wind turbines.
While this study has demonstrated the effectiveness of the developed ensemble model for wind turbine icing prediction, a number of enhancements can be performed in future research. One enhancement involves improving the model’s generalization capability by applying it to a broader range of datasets from various geographical locations. This would allow its adaptability to different climate conditions and turbine structures. Another enhancement involves training the model across multiple years upon the availability of such datasets in order to improve its generalization capability for seasonal variations. The model can also be extended as part of a fusion framework to encompass an entire wind farm consisting of many individual wind turbines by aggregating predictions from multiple turbines to predict the power production capacity of a wind farm due to icing.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}