
InCrowd-VI: A Realistic Visual–Inertial Dataset for Evaluating Simultaneous Localization and Mapping in Indoor Pedestrian-Rich Spaces for Human Navigation



Abstract
:1. Introduction
- Most existing datasets focus on vehicle-based scenarios or controlled environments with limited dynamic elements.
- Available pedestrian-focused datasets like ADVIO and BPOD lack the combination of high crowd density and accurate ground truth needed for robust SLAM evaluation.
- Datasets that do include crowded scenes, such as NAVER LABS, are typically collected from fixed or robotic platforms that do not capture natural human motion patterns.
- Existing datasets do not comprehensively address the challenges of indoor navigation, such as varying crowd densities, motion transitions, and complex architectural features.
- Introduction of InCrowd-VI, a novel visual–inertial dataset specifically designed for human navigation in indoor pedestrian-rich environments, filling a critical gap in existing research resources.
- Provision of ground-truth data, including accurate trajectories (approximately 2 cm accuracy) and semi-dense 3D point clouds for each sequence, enabling rigorous evaluation of SLAM algorithms.
- Evaluation of state-of-the-art visual odometry and SLAM algorithms using InCrowd-VI, revealing their limitations in realistic crowded scenarios.
- Identification of crucial areas for improvement in SLAM systems designed for visually impaired navigation in complex indoor environments.
2. Related Work
2.1. Robotics and Autonomous Systems
2.2. Pedestrian Odometry Dataset
- Natural human motion patterns captured through head-worn sensors represent visually impaired navigation scenarios better than the data collected using robotic or handheld devices in existing datasets.
- Comprehensive coverage of crowd densities ranging from empty to heavily crowded, allowing systematic evaluation of SLAM performance under varying levels of dynamic obstacles.
- Realistic indoor scenarios, including challenging architectural features and environmental conditions that are critical for practical navigation applications.
- High-quality ground-truth trajectories even in crowded scenes, enabling precise evaluation of SLAM performance in challenging dynamic environments.
- Long-duration sequences that test system stability and drift in real-world navigation scenarios.
3. InCrowd-VI Dataset
3.1. Sensor Framework
3.1.1. Sensor Calibration
Camera Intrinsics [27]
IMU Calibration [28]
Extrinsic Calibration
3.2. Methodology
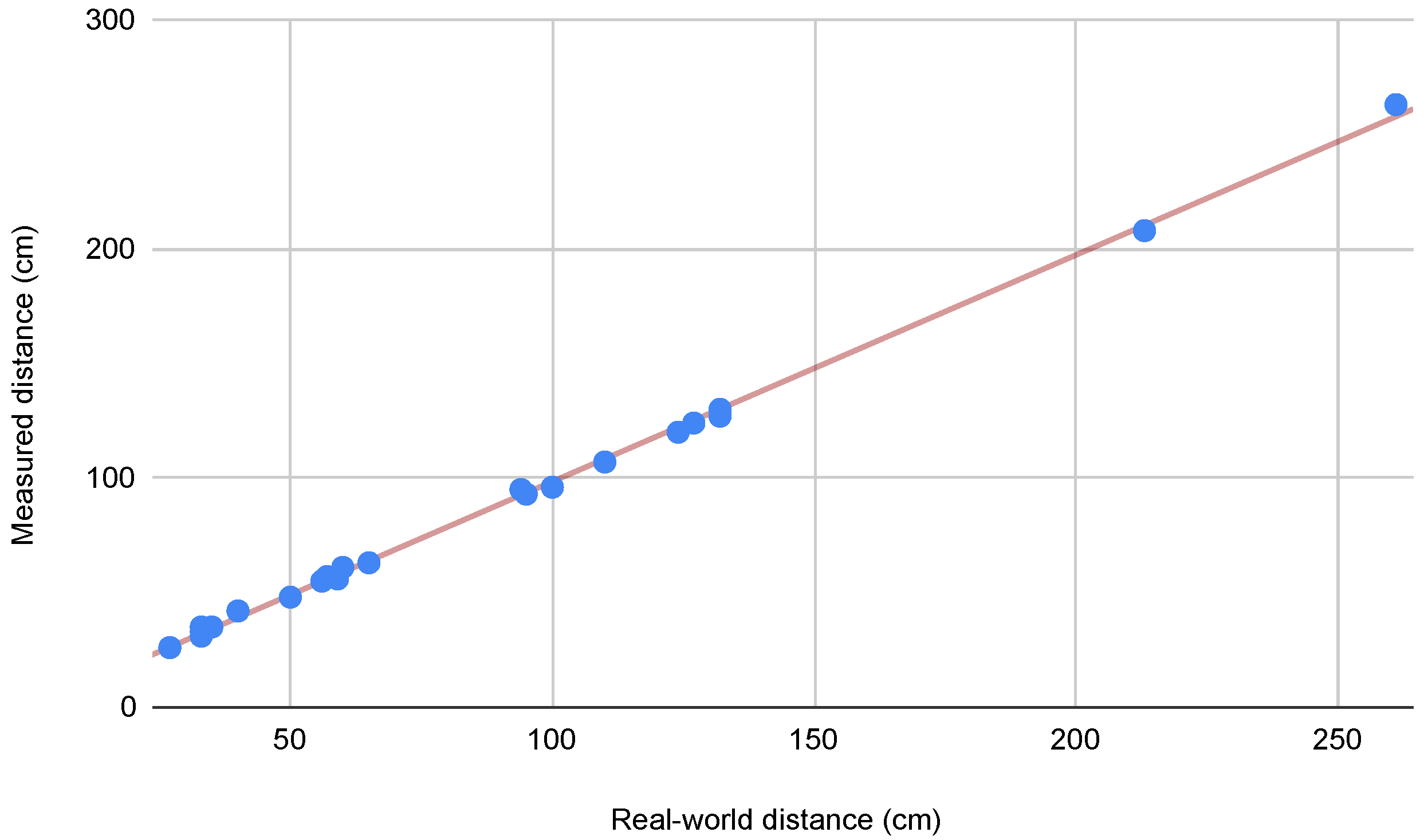
3.3. Ground Truth
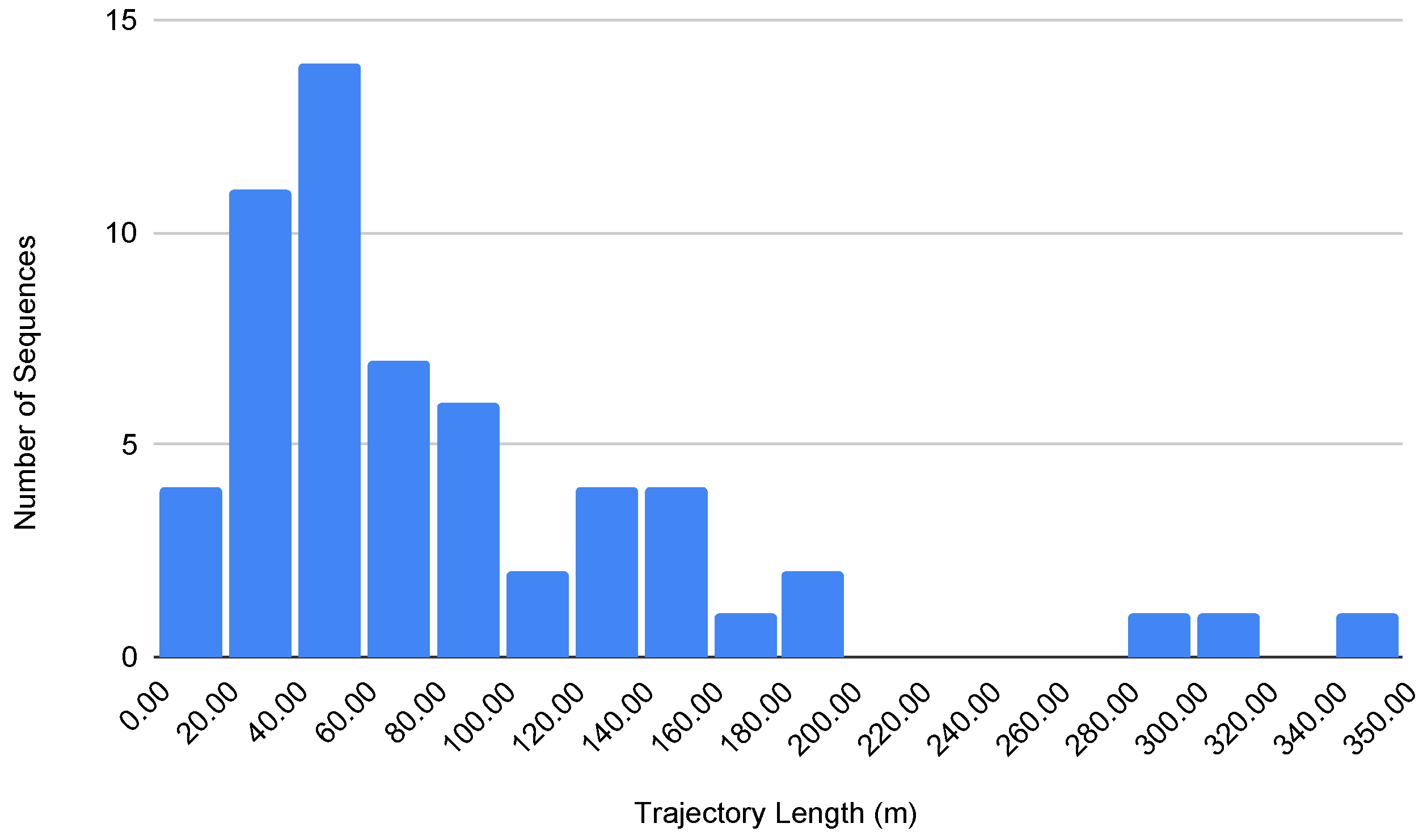
3.4. Sequences and Captured Challenges
- Dynamic obstacles: InCrowd-VI features sequences with moving pedestrians, capturing scenarios of crossing paths with groups and maneuvering around individuals moving in different directions. These sequences test the ability of the SLAM systems to handle unpredictable dynamic elements in real-world environments.
- Crowd density variation: Sequences capture a range of crowd densities, from static to densely populated areas, testing the adaptability of SLAM systems to different levels of human activity.
- Frequent occlusions: The dataset includes sequences with frequent occlusions caused by moving pedestrians, luggage, and infrastructure, thereby creating significant challenges for maintaining accurate mapping and tracking.
- Reflective and transparent surfaces: The dataset includes scenes with glass and other reflective surfaces that can distort sensor readings and complicate the visual SLAM algorithms.
- Texture-poor areas: Scenes with minimal visual features, such as plain walls, challenge feature-based SLAM systems.
- Large-scale and complex environments: The dataset covers diverse architectural layouts, including open spaces, corridors, ramps, staircases, and escalators, to test the adaptability of SLAM to various spatial configurations.
- Lighting variations: Sequences incorporate sequences with varying lighting conditions, from well-lit atriums to dimly lit corridors or areas with flickering lights, to test the SLAM robustness under varying illumination conditions.
- Sudden viewpoint changes: Sequences capture user perspective shifts during corner turns and level transitions, thereby challenging SLAM tracking consistency.
- Motion transitions: Sequences include transitions between moving environments (escalators, moving ramps, and trains) and stationary areas, to test SLAM’s ability to distinguish ego-motion from environmental motion.
4. Experimental Evaluation
4.1. Evaluation Metrics
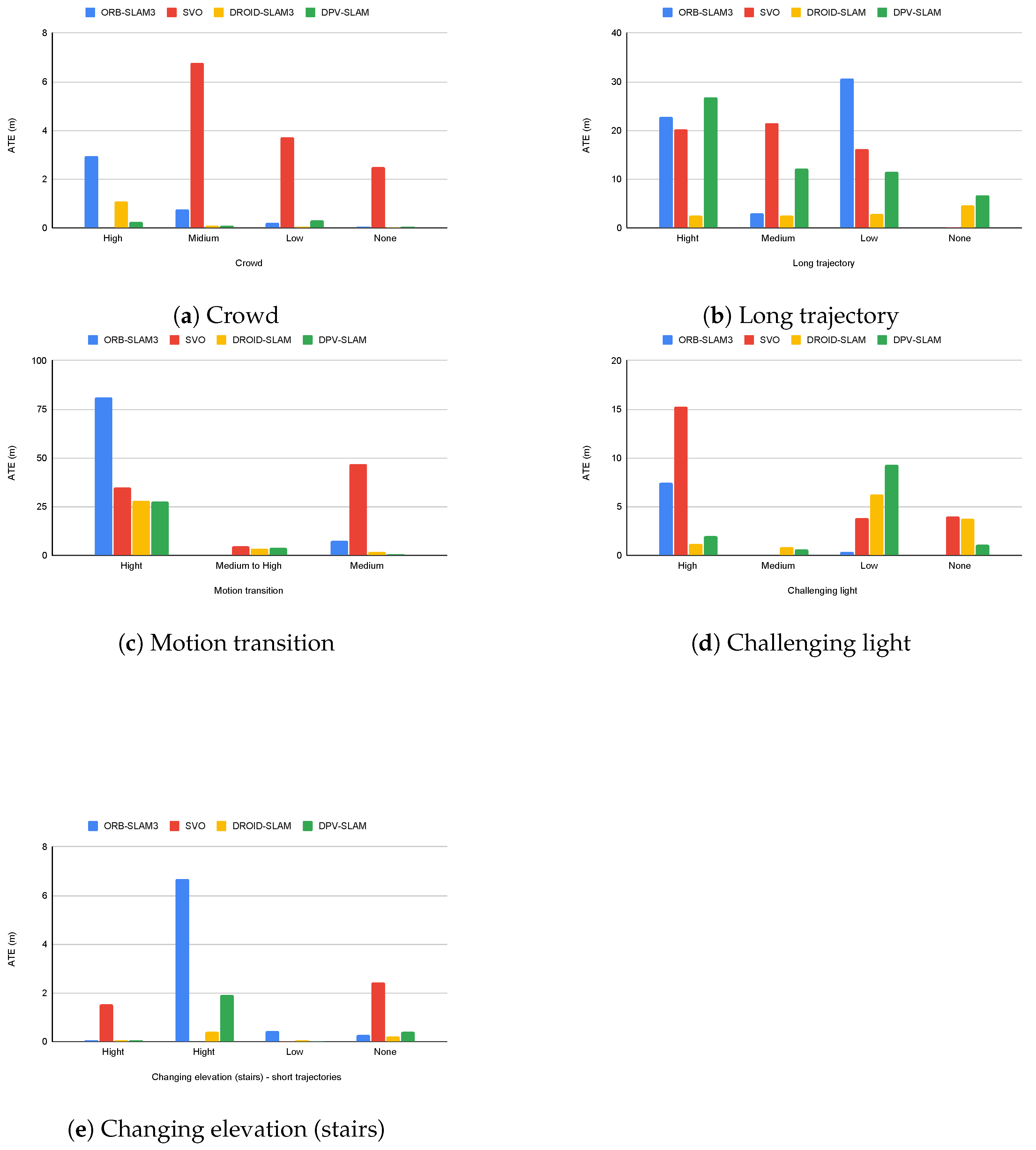
4.2. Evaluation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Pellerito, R.; Cannici, M.; Gehrig, D.; Belhadj, J.; Dubois-Matra, O.; Casasco, M.; Scaramuzza, D. Deep Visual Odometry with Events and Frames. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024. [Google Scholar]
- Bresson, G.; Alsayed, Z.; Yu, L.; Glaser, S. Simultaneous localization and mapping: A survey of current trends in autonomous driving. IEEE Trans. Intell. Veh. 2017, 2, 194–220. [Google Scholar] [CrossRef]
- Hanover, D.; Loquercio, A.; Bauersfeld, L.; Romero, A.; Penicka, R.; Song, Y.; Cioffi, G.; Kaufmann, E.; Scaramuzza, D. Autonomous drone racing: A survey. IEEE Trans. Robot. 2024, 40, 3044–3067. [Google Scholar] [CrossRef]
- Alberico, I.; Delaune, J.; Cioffi, G.; Scaramuzza, D. Structure-Invariant Range-Visual-Inertial Odometry. arXiv 2024, arXiv:2409.04633. [Google Scholar]
- Somasundaram, K.; Dong, J.; Tang, H.; Straub, J.; Yan, M.; Goesele, M.; Engel, J.J.; De Nardi, R.; Newcombe, R. Project Aria: A new tool for egocentric multi-modal AI research. arXiv 2023, arXiv:2308.13561. [Google Scholar]
- Zhang, L.; Helmberger, M.; Fu, L.F.T.; Wisth, D.; Camurri, M.; Scaramuzza, D.; Fallon, M. Hilti-oxford dataset: A millimeter-accurate benchmark for simultaneous localization and mapping. IEEE Robot. Autom. Lett. 2022, 8, 408–415. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE conference on computer vision and pattern recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Pfrommer, B.; Sanket, N.; Daniilidis, K.; Cleveland, J. Penncosyvio: A challenging visual inertial odometry benchmark. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3847–3854. [Google Scholar]
- Majdik, A.L.; Till, C.; Scaramuzza, D. The Zurich urban micro aerial vehicle dataset. Int. J. Robot. Res. 2017, 36, 269–273. [Google Scholar] [CrossRef]
- Li, W.; Saeedi, S.; McCormac, J.; Clark, R.; Tzoumanikas, D.; Ye, Q.; Huang, Y.; Tang, R.; Leutenegger, S. Interiornet: Mega-scale multi-sensor photo-realistic indoor scenes dataset. arXiv 2018, arXiv:1809.00716. [Google Scholar]
- Schubert, D.; Goll, T.; Demmel, N.; Usenko, V.; Stückler, J.; Cremers, D. The TUM VI benchmark for evaluating visual-inertial odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1680–1687. [Google Scholar]
- Delmerico, J.; Cieslewski, T.; Rebecq, H.; Faessler, M.; Scaramuzza, D. Are we ready for autonomous drone racing? the UZH-FPV drone racing dataset. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6713–6719. [Google Scholar]
- Ramezani, M.; Wang, Y.; Camurri, M.; Wisth, D.; Mattamala, M.; Fallon, M. The newer college dataset: Handheld lidar, inertial and vision with ground truth. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 4353–4360. [Google Scholar]
- Minoda, K.; Schilling, F.; Wüest, V.; Floreano, D.; Yairi, T. Viode: A simulated dataset to address the challenges of visual-inertial odometry in dynamic environments. IEEE Robot. Autom. Lett. 2021, 6, 1343–1350. [Google Scholar] [CrossRef]
- Lee, D.; Ryu, S.; Yeon, S.; Lee, Y.; Kim, D.; Han, C.; Cabon, Y.; Weinzaepfel, P.; Guérin, N.; Csurka, G.; et al. Large-scale localization datasets in crowded indoor spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3227–3236. [Google Scholar]
- Bojko, A.; Dupont, R.; Tamaazousti, M.; Borgne, H.L. Self-improving SLAM in dynamic environments: Learning when to mask. arXiv 2022, arXiv:2210.08350. [Google Scholar]
- Zhang, Y.; An, N.; Shi, C.; Wang, S.; Wei, H.; Zhang, P.; Meng, X.; Sun, Z.; Wang, J.; Liang, W.; et al. CID-SIMS: Complex indoor dataset with semantic information and multi-sensor data from a ground wheeled robot viewpoint. Int. J. Robot. Res. 2023, 43, 899–917. [Google Scholar] [CrossRef]
- Recchiuto, C.T.; Scalmato, A.; Sgorbissa, A. A dataset for human localization and mapping with wearable sensors. Robot. Auton. Syst. 2017, 97, 136–143. [Google Scholar] [CrossRef]
- Cortés, S.; Solin, A.; Rahtu, E.; Kannala, J. ADVIO: An authentic dataset for visual-inertial odometry. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 419–434. [Google Scholar]
- Charatan, D.; Fan, H.; Kimia, B. Benchmarking Pedestrian Odometry: The Brown Pedestrian Odometry Dataset (BPOD). In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–15 September 2022; pp. 1–11. [Google Scholar]
- Liu, Y.; Fu, Y.; Chen, F.; Goossens, B.; Tao, W.; Zhao, H. Simultaneous localization and mapping related datasets: A comprehensive survey. arXiv 2021, arXiv:2102.04036. [Google Scholar]
- Tosi, F.; Zhang, Y.; Gong, Z.; Sandström, E.; Mattoccia, S.; Oswald, M.R.; Poggi, M. How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: A Survey. arXiv 2024, arXiv:2402.13255. [Google Scholar]
- Meta AI Research. Project Aria Hardware Specifications. 2024. Available online: https://facebookresearch.github.io/projectaria_tools/docs/tech_spec/hardware_spec (accessed on 4 September 2024).
- Meta AI Research. Camera Intrinsic Models for Project Aria Devices. Available online: https://facebookresearch.github.io/projectaria_tools/docs/tech_insights/camera_intrinsic_models (accessed on 4 September 2024).
- Meta AI Research. Camera Intrinsic Models for Project Aria Devices. Available online: https://facebookresearch.github.io/projectaria_tools/docs/tech_insights/sensor_measurement_model (accessed on 4 September 2024).
- Meta AI Research. 3D Coordinate Frame Conventions for Project Aria Glasses. Available online: https://facebookresearch.github.io/projectaria_tools/docs/data_formats/coordinate_convention/3d_coordinate_frame_convention (accessed on 4 September 2024).
- Schops, T.; Sattler, T.; Pollefeys, M. Bad slam: Bundle adjusted direct rgb-d slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 134–144. [Google Scholar]
- Bennett, H.J.; Valenzuela, K.A.; Fleenor, K.; Morrison, S.; Haegele, J.A. Walking biomechanics and energetics of individuals with a visual impairment: A preliminary report. Hum. Mov. 2019, 20, 8–18. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. Adv. Neural Inf. Process. Syst. 2021, 34, 16558–16569. [Google Scholar]
- Lipson, L.; Teed, Z.; Deng, J. Deep Patch Visual SLAM. arXiv 2024, arXiv:2408.01654. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2016, 33, 249–265. [Google Scholar] [CrossRef]
- Teed, Z.; Lipson, L.; Deng, J. Deep patch visual odometry. Adv. Neural Inf. Process. Syst. 2024, 36, 39033–39051. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Computer Vision Group, TUM School of Computation, Information and Technology, Technical University of Munich Useful Tools for the RGB-D Benchmark. Available online: https://cvg.cit.tum.de/data/datasets/rgbd-dataset/tools (accessed on 4 September 2024).
- Zhang, Z.; Scaramuzza, D. A tutorial on quantitative trajectory evaluation for visual (-inertial) odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7244–7251. [Google Scholar]
- Grupp, M. evo: Python Package for the Evaluation of Odometry and SLAM. 2017. Available online: https://github.com/MichaelGrupp/evo (accessed on 20 December 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Environment | Carrier | Sensors | Crowd Density | Ground Truth | # Sequence |
|---|---|---|---|---|---|---|
| Robotics and autonomous systems | ||||||
| KITTI [9] | Outdoor | Car | High-resolution cameras, LiDAR, GPS/IMU | Low | GPS/IMU | 22 |
| EuRoC MAV [10] | Indoor | Drone | Stereo cameras, IMU | Static | Motion capture | 11 |
| PennCOSYVIO [11] | Indoor/Outdoor | Handheld | Stereo cameras, IMU | Low | Fiducial markers | 4 |
| Zurich Urban [12] | Outdoor | Quadrotor | High-resolution camera, GPS, and IMU | Not mentioned | Photogrammetric 3D reconstruction | 2 km |
| InteriorNet [13] | Indoor | Simulated cameras | Synthetic images, IMU | None | Synthetic | 15K |
| TUM VI [14] | Indoor/Outdoor | Handheld | Stereo cameras, IMU | Low | Partial motion capture | 28 |
| UZH-FPV [15] | Indoor/Outdoor | Quadrotor | Event and RGB cameras, IMU | None | Leica Nova MS60 TotalStation | 27+ |
| Newer College [16] | Outdoor | Handheld | Stereoscopic–inertial camera, LiDAR | None | 6DOF ICP localization | 4 |
| VIODE [17] | Indoor/Outdoor | Simulated quadrotor UAV | Synthetic RGB cameras, IMU | High | Synthetic | 12 |
| NAVER LABS [18] | Indoor | A dedicated mapping platform | Cameras, laser scanners | Medium | LiDAR SLAM & SFM | 5 datasets |
| ConsInv [19] | Indoor/Outdoor | Not mentioned | Monocular and stereo camera | Low | ORB-SLAM2 | 159 |
| Hilti-Oxford [8] | Indoor/Outdoor | Handheld | Stereo cameras, IMU, LiDAR | Low | survey-grade scanner | 16 |
| CID-SIMS [20] | Indoor | Robot/ Handheld | RGB-D camera, IMU, wheel odometry | Low | GeoSLAM | 22 |
| Pedestrian odometry dataset | ||||||
| Zena [21] | Outdoor | Head-mounted | 2D laser scanner, IMU | High | Step estimation process using IMU | a 35 min dataset |
| ADVIO [22] | Indoor/Outdoor | Handheld | Smartphone cameras, IMU | High | IMU-based + manual position fixes | 23 |
| BPOD [23] | Indoor/Outdoor | Head-mounted | Stereo cameras, laser distance meter | Not mentioned | Marker-based | 48 |
| InCrowd-VI (ours) | Indoor | Head-worn | RGB and stereo cameras, IMU | High | Meta Aria Project SLAM service | 58 |
| Camera | HFOV | VFOV | IFOV | Max Resolution | FPS | Shutter |
|---|---|---|---|---|---|---|
| Mono (×2) | 150 | 120 | 0.26 | 640 × 480 | 30 | global |
| RGB (×1) | 110 | 110 | 0.038 | 2880 × 2880 | 30 | rolling |
| ET (×2) | 64 | 48 | 0.2 | 640 × 480 | 90 | global |
| Density | Sequence Name | Venue | Length (m) | Span (mm:ss) | Main Challenges |
|---|---|---|---|---|---|
| High | Oerlikon_G7 | Train station | 133.36 | 02:04 | Challenging light, ramp |
| G6_exit | Train station | 60.21 | 01:27 | Stairs, flickering light | |
| G6_loop * | Train station | 103.74 | 02:07 | Challenging light | |
| Getoff_pharmacy * | Train station | 159.50 | 03:06 | Motion transition | |
| Service_center | Airport | 131.89 | 02:18 | Reflection, open area | |
| Ochsner_sport * | Airport | 70.57 | 01:14 | Reflection | |
| Toward_gates | Airport | 165.46 | 02:57 | Reflection, open area | |
| Arrival2 * | Airport | 74.96 | 01:23 | Crowd | |
| Checkin2_loop | Airport | 348.84 | 05:22 | Long trajectory | |
| Shopping_open * | Shopping mall | 182.51 | 03:10 | Challenging light, open area | |
| Turn180 | Airport | 41.95 | 00:46 | Reflection | |
| Cafe_exit * | Main train station | 121.40 | 01:51 | Reflection, open area | |
| G8_cafe * | Main train station | 294.05 | 04:14 | Long trajectory | |
| Ground_53 * | Main train station | 32.40 | 01:01 | Escalator (motion transition) | |
| Kiko_loop * | Shopping mall | 314.68 | 05:50 | Long trajectory | |
| Reservation_office | Main train station | 95.15 | 01:28 | Reflection, open area | |
| Orell_fussli * | Shopping mall | 57.98 | 01:16 | Crowd | |
| Reservation_G17 * | Main train station | 97.30 | 01:50 | Challenging light, open area | |
| Short_Loop_BH * | Main train station | 104.94 | 02:29 | Reflection, open area | |
| Shopping_loop * | Shopping mall | 151.91 | 02:36 | Challenging light | |
| Medium | UZH_stairs * | Museum | 13.16 | 00:41 | Stairs |
| Migros | Shopping mall | 84.18 | 01:40 | Reflection, open area | |
| TS_exam_loop | Exam location | 28.81 | 01:34 | Glass wall, stationary people | |
| Museum_loop | Museum | 66.99 | 02:02 | Challenging light | |
| Ramp_checkin2 | Airport | 191.77 | 03:40 | Moving ramp, open area | |
| Airport_shop | Shopping mall | 99.49 | 01:46 | Reflection, open area | |
| Towards_checkin1 | Airport | 55.89 | 01:02 | Reflection, open area, glass wall | |
| Entrance_checkin1 | Airport | 35.70 | 00:39 | Reflection | |
| Towards_circle | Airport | 127.46 | 02:06 | Challenging light, repetitive structure | |
| Low | AND_floor51 | Library | 40.23 | 00:53 | Narrow aisle, stationary people |
| AND_floor52 | Library | 39.13 | 01:10 | Narrow aisle, stationary people | |
| AND_liftAC | University building | 71.15 | 01:33 | Open area, glass wall | |
| ETH_HG | University building | 99.00 | 01:56 | Repetitive structure | |
| ETH_lab | Laboratory | 56.70 | 01:24 | Reflection | |
| Kriegsstr_pedestrian | Public building | 31.97 | 00:59 | Texture-poor | |
| Kriegsstr_same_dir | Public building | 31.17 | 00:56 | Texture-poor | |
| TH_entrance | University building | 41.85 | 00:53 | Challenging light, stationary people | |
| TS_entrance | University building | 32.06 | 00:42 | Reflection | |
| TS_exam | University building | 44.93 | 01:01 | Narrow corridor, texture-poor | |
| UZH_HG | University building | 142.12 | 03:09 | Long trajectory, repetitive structure | |
| Museum_1 | Museum | 69.30 | 01:51 | Challenging light | |
| Museum_dinosaur | Museum | 44.62 | 01:16 | Challenging light | |
| Museum_up | Museum | 12.20 | 00:34 | Stairs | |
| Short_loop | Airport | 36.92 | 00:46 | Open area | |
| None | AND_Lib | Office building | 52.19 | 01:18 | Reflection, narrow corridor |
| Hrsaal1B01 | Academic building | 74.55 | 01:50 | Challenging light, narrow corridor | |
| ETH_FT2 | Museum | 40.97 | 00:56 | Challenging light, reflection | |
| ETH_FTE | Museum | 59.00 | 01:35 | Challenging light, open area | |
| ETH_lab2 | Laboratory | 58.08 | 01:26 | Texture-poor, reflection | |
| Habsburgstr_dark | Public building | 36.08 | 01:05 | Stairs, dimly lit | |
| Habsburgstr_light | Public building | 87.99 | 02:46 | Stairs | |
| IMS_lab | Laboratory | 15.23 | 00:43 | Cluttered scene | |
| IMS_TE21 | Laboratory | 42.43 | 01:23 | Cluttered scene, challenging light | |
| IMS_LEA | Laboratory | 19.35 | 00:43 | Cluttered scene | |
| Kriegsstr | Public building | 31.18 | 00:54 | Texture-poor | |
| TH_loop | Office building | 154.74 | 03:55 | Reflection | |
| TS116 | University building | 59.11 | 01:24 | Challenging light, reflection, glass wall | |
| TS_stairs | University building | 27.67 | 00:52 | Stairs, challenging light, glass wall |
| Density | Sequence | Overcrowding | Challenging Light | Ramp/Stairs | Motion Transition | Reflection | Open Area | Glass Wall | Stationary People | Narrow Aisle/Corridor | Repetitive Structure | Texture-Poor | Cluttered Scene | Long Trajectory |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| High | Oerlikon_G7 | ✓ | ✓ | ✓ | ||||||||||
| G6_exit | ✓ | ✓ | ||||||||||||
| G6_loop | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Getoff_pharmacy | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| Service_center | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Ochsner_sport | ✓ | ✓ | ✓ | |||||||||||
| Toward_gates | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Arrival2 | ✓ | ✓ | ✓ | |||||||||||
| Checkin2_loop | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Shopping_open | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Turn180 | ✓ | |||||||||||||
| Cafe_exit | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| G8_cafe | ✓ | ✓ | ✓ | |||||||||||
| Ground_53 | ✓ | ✓ | ||||||||||||
| Kiko_loop | ✓ | ✓ | ||||||||||||
| Reservation_office | ✓ | ✓ | ||||||||||||
| Orell_fussli | ✓ | |||||||||||||
| Reservation_G17 | ✓ | ✓ | ✓ | |||||||||||
| Short_Loop_BH | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| Shopping_loop | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| Medium | UZH_stairs | ✓ | ✓ | |||||||||||
| Migros | ✓ | ✓ | ✓ | |||||||||||
| TS_exam_loop | ✓ | ✓ | ||||||||||||
| Museum_loop | ✓ | ✓ | ||||||||||||
| Ramp_checkin2 | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Airport_shop | ✓ | ✓ | ||||||||||||
| Towards_checkin1 | ✓ | ✓ | ✓ | |||||||||||
| Entrance_checkin1 | ✓ | |||||||||||||
| Towards_circle | ✓ | ✓ | ✓ | |||||||||||
| Low | AND_floor51 | ✓ | ✓ | |||||||||||
| AND_floor52 | ✓ | ✓ | ||||||||||||
| AND_liftAC | ✓ | ✓ | ||||||||||||
| ETH_HG | ✓ | |||||||||||||
| ETH_lab | ✓ | ✓ | ||||||||||||
| Kriegsstr_pedestrian | ✓ | ✓ | ||||||||||||
| Kriegsstr_same_dir | ✓ | ✓ | ||||||||||||
| TH_entrance | ✓ | ✓ | ✓ | |||||||||||
| TS_entrance | ✓ | ✓ | ||||||||||||
| TS_exam | ✓ | ✓ | ✓ | |||||||||||
| UZH_HG | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Museum_1 | ✓ | ✓ | ||||||||||||
| Museum_dinosaur | ✓ | ✓ | ||||||||||||
| Museum_up | ✓ | |||||||||||||
| Short_loop | ✓ | |||||||||||||
| None | AND_Lib | ✓ | ✓ | |||||||||||
| Hrsaal1B01 | ✓ | ✓ | ✓ | ✓ | ||||||||||
| ETH_FT2 | ✓ | ✓ | ✓ | |||||||||||
| ETH_FTE | ✓ | ✓ | ||||||||||||
| ETH_lab2 | ✓ | ✓ | ✓ | |||||||||||
| Habsburgstr_dark | ✓ | ✓ | ✓ | |||||||||||
| Habsburgstr_light | ✓ | ✓ | ✓ | |||||||||||
| IMS_lab | ✓ | |||||||||||||
| IMS_TE21 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| IMS_LEA | ✓ | |||||||||||||
| Kriegsstr | ✓ | ✓ | ||||||||||||
| TH_loop | ✓ | ✓ | ✓ | |||||||||||
| TS116 | ✓ | ✓ | ✓ | ✓ | ||||||||||
| TS_stairs | ✓ | ✓ | ✓ | ✓ |
| SLAM System | Matching Approach | Approach |
|---|---|---|
| DROID-SLAM | Dense optical flow-based | End-to-end |
| DPV-SLAM | Sparse patch-based | End-to-end |
| ORB-SLAM3 | Feature-based | Classical SLAM |
| SVO | Semi-direct | Classical VO |
| Sequence | Trj Len (m) | AWS (m/s) | Classical Systems | Deep Learning-Based Systems | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ORB-SLAM3 | SVO | DROID-SLAM | DPV-SLAM | |||||||||||||||||||
| ATE (m) | DP (%) | PEC (%) | FPS | RTF | ATE (m) | DP (%) | PEC (%) | FPS | RTF | ATE (m) | DP (%) | PEC (%) | FPS | RTF | ATE (m) | DP (%) | PEC (%) | FPS | RTF | |||
| Crowd Density | ||||||||||||||||||||||
| Orell_fussli | 57.98 | 0.76 | 2.95 | 5.08 | 90 | 23 | 0.80 | × | × | × | 174 | 5.82 | 1.07 | 1.84 | 100 | 16 | 0.53 | 0.21 | 0.36 | 98 | 10 | 0.36 |
| Entrance_checkin1 | 35.70 | 0.92 | 0.77 | 2.15 | 92 | 25 | 0.82 | 6.78 | 18.99 | 80 | 128 | 4.27 | 0.08 | 0.22 | 100 | 16 | 0.53 | 0.08 | 0.22 | 97 | 11 | 0.39 |
| Short_loop | 36.92 | 0.80 | 0.22 | 0.59 | 96 | 24 | 0.83 | 3.71 | 10.04 | 70 | 134 | 4.51 | 0.04 | 0.10 | 100 | 15 | 0.51 | 0.32 | 0.86 | 97 | 11 | 0.38 |
| IMS_lab | 15.23 | 0.35 | 0.06 | 0.39 | 94 | 24 | 0.82 | 2.49 | 16.34 | 71 | 149 | 5.05 | 0.02 | 0.13 | 100 | 16 | 0.54 | 0.04 | 0.26 | 97 | 14 | 0.48 |
| Lighting Variations | ||||||||||||||||||||||
| Reservation_G17 | 97.30 | 0.88 | 7.45 | 7.65 | 95 | 26 | 0.87 | 15.23 | 15.65 | 74 | 156 | 5.25 | 1.14 | 1.17 | 100 | 19 | 0.65 | 1.95 | 2.00 | 99 | 12 | 0.40 |
| Toward_circle | 127.46 | 1.01 | × | × | 97 | 25 | 0.86 | × | × | × | 175 | 5.86 | 0.88 | 0.69 | 100 | 15 | 0.50 | 0.59 | 0.46 | 99 | 10 | 0.29 |
| Museum_1 | 69.30 | 0.62 | 0.34 | 0.49 | 98 | 25 | 0.87 | 3.82 | 5.51 | 36 | 171 | 5.75 | 6.21 | 8.96 | 100 | 18 | 0.61 | 8.06 | 11.63 | 99 | 10 | 0.34 |
| TS116 | 59.11 | 0.70 | × | × | 57 | 21 | 0.71 | 3.99 | 6.75 | 31 | 159 | 5.32 | 3.77 | 6.37 | 100 | 15 | 0.52 | 1.08 | 1.82 | 98 | 10 | 0.34 |
| Long Trajectory | ||||||||||||||||||||||
| Kiko_loop | 314.68 | 0.90 | 22.81 | 7.24 | 98 | 26 | 0.87 | 20.12 | 6.39 | 59 | 153 | 5.11 | 2.51 | 0.79 | 100 | 17 | 0.56 | 26.79 | 8.51 | 99 | 8 | 0.28 |
| Shopping_loop | 151.91 | 0.97 | 3.02 | 1.98 | 97 | 25 | 0.85 | 21.41 | 14.09 | 89 | 138 | 4.63 | 2.52 | 1.65 | 100 | 16 | 0.55 | 12.21 | 8.03 | 99 | 9 | 0.31 |
| UZH_HG | 142.12 | 0.75 | 30.60 | 21.53 | 94 | 26 | 0.88 | 16.11 | 11.33 | 47 | 170 | 5.70 | 2.86 | 2.01 | 100 | 17 | 0.58 | 11.45 | 8.05 | 99 | 9 | 0.32 |
| TH_loop | 154.74 | 0.66 | × | × | 88 | 22 | 0.72 | 0.01 | 0.006 | 0.9 | 131 | 4.37 | 4.53 | 2.92 | 100 | 18 | 0.62 | 6.71 | 4.33 | 99 | 9 | 0.33 |
| Changing Elevation (stairs)—Short Trajectories | ||||||||||||||||||||||
| UZH_stairs | 13.16 | 0.32 | 0.06 | 0.45 | 77 | 23 | 0.78 | 1.52 | 11.55 | 37 | 138 | 4.62 | 0.04 | 0.30 | 100 | 22 | 0.78 | 0.05 | 0.37 | 97 | 15 | 0.5 |
| G6_exit | 60.21 | 0.69 | 6.67 | 11.07 | 97 | 26 | 0.86 | × | × | × | 153 | 5.11 | 0.41 | 0.68 | 100 | 17 | 0.57 | 1.91 | 3.17 | 97 | 12 | 0.40 |
| Museum_up | 12.20 | 0.36 | 0.42 | 3.44 | 82 | 22 | 0.75 | 0.03 | 0.24 | 6.2 | 164 | 5.44 | 0.03 | 0.24 | 100 | 18 | 0.61 | 0.02 | 0.16 | 98 | 12 | 0.41 |
| TS_stairs | 27.67 | 0.53 | 0.26 | 0.93 | 94 | 25 | 0.84 | 2.43 | 8.78 | 41 | 158 | 5.30 | 0.21 | 0.75 | 100 | 16 | 0.56 | 0.41 | 1.48 | 96 | 12 | 0.39 |
| Motion Transition | ||||||||||||||||||||||
| Getoff_pharmacy | 159.50 | 0.86 | 81.01 | 50.78 | 85 | 25 | 0.83 | 34.91 | 21.88 | 48 | 153 | 5.10 | 27.95 | 17.52 | 100 | 17 | 0.59 | 27.55 | 17.27 | 98 | 10 | 0.33 |
| Ground_53 | 32.40 | 0.53 | × | × | 96 | 25 | 0.84 | 4.54 | 14.01 | 79 | 136 | 4.54 | 3.30 | 10.18 | 100 | 19 | 0.64 | 3.84 | 11.85 | 98 | 13 | 0.45 |
| Ramp_checkin2 | 191.77 | 0.87 | 7.31 | 3.81 | 98 | 26 | 0.87 | 46.95 | 24.48 | 97 | 142 | 4.74 | 1.82 | 0.94 | 100 | 20 | 0.67 | 0.77 | 0.40 | 99 | 10 | 0.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bamdad, M.; Hutter, H.-P.; Darvishy, A. InCrowd-VI: A Realistic Visual–Inertial Dataset for Evaluating Simultaneous Localization and Mapping in Indoor Pedestrian-Rich Spaces for Human Navigation. Sensors 2024, 24, 8164. https://doi.org/10.3390/s24248164
Bamdad M, Hutter H-P, Darvishy A. InCrowd-VI: A Realistic Visual–Inertial Dataset for Evaluating Simultaneous Localization and Mapping in Indoor Pedestrian-Rich Spaces for Human Navigation. Sensors. 2024; 24(24):8164. https://doi.org/10.3390/s24248164
Chicago/Turabian StyleBamdad, Marziyeh, Hans-Peter Hutter, and Alireza Darvishy. 2024. "InCrowd-VI: A Realistic Visual–Inertial Dataset for Evaluating Simultaneous Localization and Mapping in Indoor Pedestrian-Rich Spaces for Human Navigation" Sensors 24, no. 24: 8164. https://doi.org/10.3390/s24248164
APA StyleBamdad, M., Hutter, H.-P., & Darvishy, A. (2024). InCrowd-VI: A Realistic Visual–Inertial Dataset for Evaluating Simultaneous Localization and Mapping in Indoor Pedestrian-Rich Spaces for Human Navigation. Sensors, 24(24), 8164. https://doi.org/10.3390/s24248164