
Multi-Agent Reinforcement Learning-Based Computation Offloading for Unmanned Aerial Vehicle Post-Disaster Rescue


Abstract
:1. Introduction
- The UAV swarm makes joint offloading decisions by modeling the offloading environment, delegating offloading decision-making to UAVs, and considering the random mobility of edge server clusters, time-varying nature of channels, and signal blockage of UAVs. To avoid wasting server computing resources while ensuring the successful execution of user tasks, the system is modeled as an optimization problem that minimizes the system overhead using the weighted average of the task execution time and server energy consumption as the system overhead.
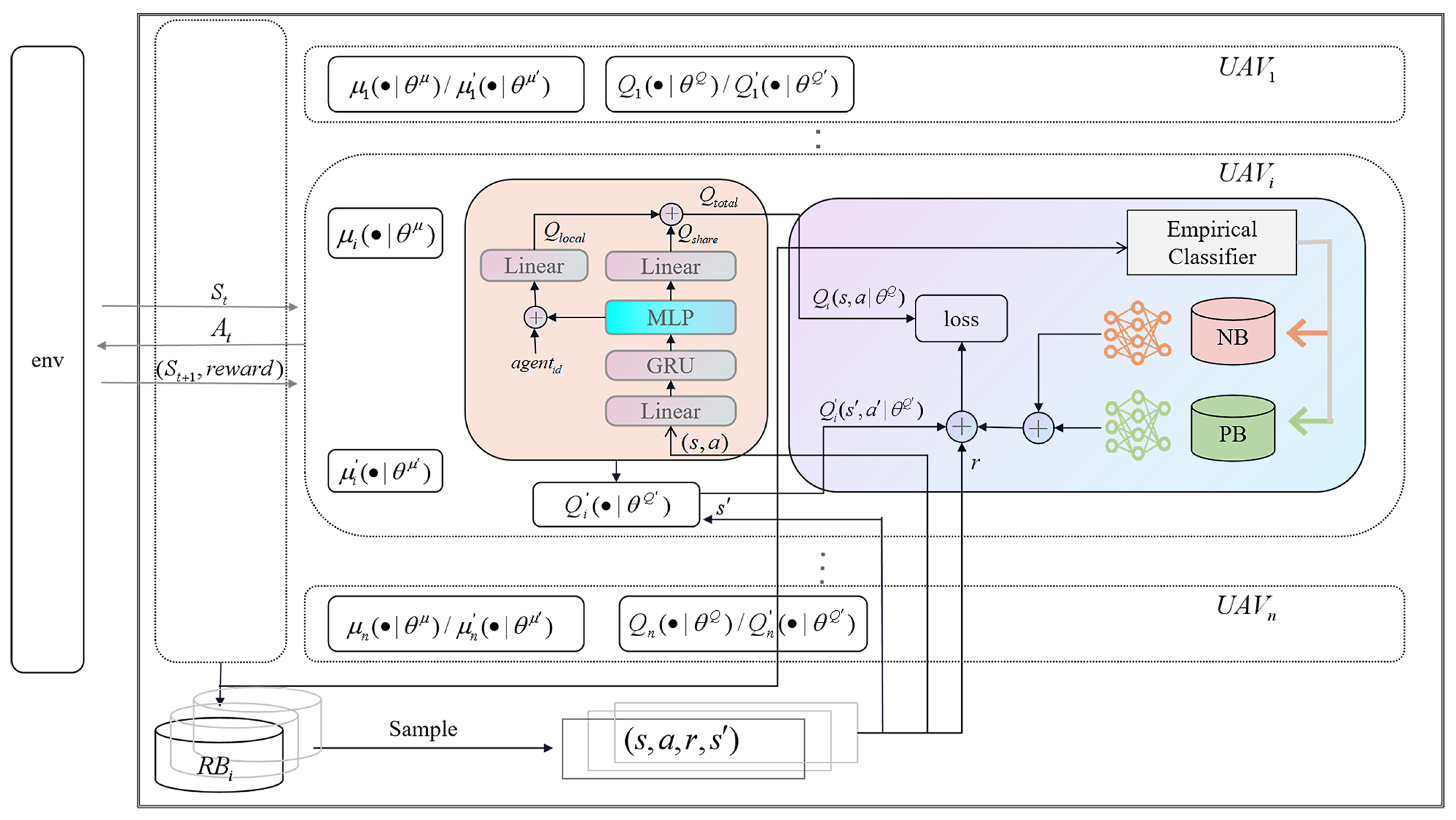
- The CER-MADDPG algorithm based on multi-agent reinforcement learning is proposed. The UAVs use this algorithm to obtain their next coordinates, select edge servers, and determine the task offloading ratios. The algorithm enhances the collaborative decisions between agents by considering both global and individual information. Additionally, the algorithm classifies historical experiences and learns according to different categories of experiences, allowing UAVs to fully utilize historical experiences in continuous decision-making, cooperation, and optimal joint decisions.
- Experiments were conducted using the PyTorch platform to simulate the proposed algorithm and compare it with MADDPG and stochastic game-based resource allocation with prioritized experience replays (SGRA-PERs), thereby verifying that the proposed algorithm is superior to other algorithms in terms of optimality, stability, and scalability.
2. Related Work
- 1.
- Most current works consider scenarios with a single server and multiple UAVs, whereas real scenarios often involve multiple servers and multiple UAVs.
- 2.
- Existing research does not fully consider cooperative decision-making between UAVs. For example, when multiple UAVs observe the same environmental state in the same time slot, they make the same decisions. This homogenized decision-making is not necessarily a joint optimal decision, which may lead to joint offloading decisions made by a group of UAVs to fall into local optima.
- 3.
- Existing studies have not sufficiently considered the utilization of historical UAV decision-making experiences. Current research focuses on prioritizing historical UAV experiences or introducing external knowledge bases. The UAV group cannot learn quickly from high-quality historical decision-making experiences and avoid poor experiences. This can also lead to joint offloading decisions made by a group of UAVs to fall into local optima.
3. Problem Description
3.1. MEC Environment Model
3.1.1. UAV Mobility Model
3.1.2. Edge Server Mobility Model
3.1.3. UAV Task Generation Model
3.2. Communication Model
3.3. Computation Offloading Model
3.3.1. Local Model
3.3.2. Server Model
4. Multi-Agent Deep Deterministic Policy Gradient Considering Collaboration and Experience Utilization
4.1. Partially Observable Markov Decision Process
4.2. Multi-Agent Deep Deterministic Policy Gradient Considering Collaboration and Experience Utilization
4.2.1. General Description
4.2.2. Critic Networks That Consider Both Global and Local Information
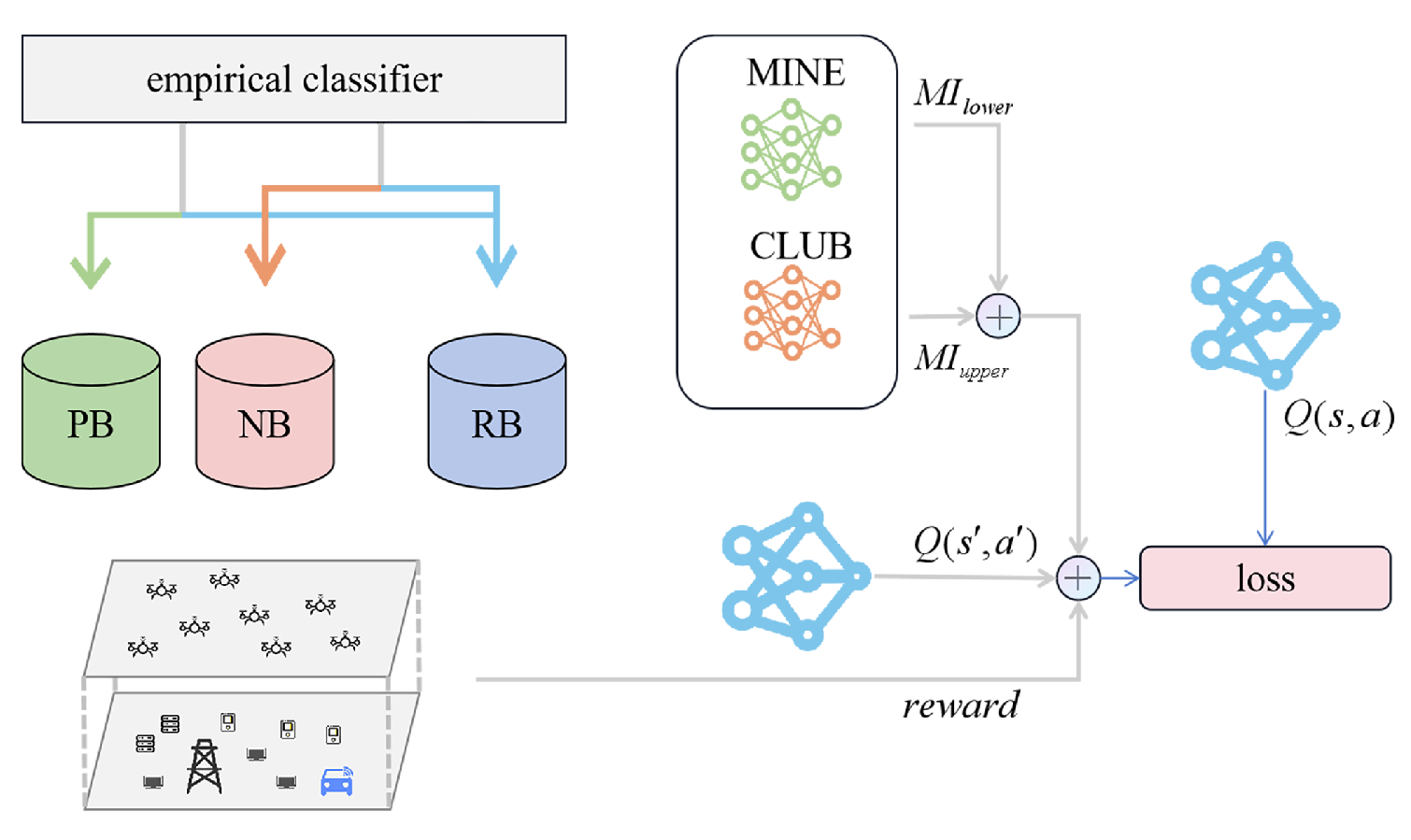
4.2.3. Utilization of Categorized Experience
4.3. Training Process
| Algorithm 1 The CER-MADDPG Training Procedure in the UAV Computation Offloading System |
| Require: Replay buffer , positive buffer , negative buffer , time budget T, exploration probability , discount factor , update step Ensure: The optimal policy
|
5. Simulation, Results and Analysis
5.1. Simulation Environment and Parameter Setting
5.2. Results and Analysis
5.2.1. Selection of Hyperparameters
5.2.2. Performance Comparison and Analysis
- MADDPG: A policy gradient algorithm in which each agent has actor and critic networks. The critic network can access the states and actions of other agents during training, whereas the actor network requires only its own information. Consequently, the critic network is trained centrally, whereas the actor network is executed in a distributed manner.
- SGRA-PERs: Utilizes a prioritized experience replay mechanism for each UAV’s experience buffer, allowing important but infrequent experiences to be repeatedly utilized for learning, thereby enhancing system utility.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bucknell, A.; Bassindale, T. An investigation into the effect of surveillance drones on textile evidence at crime scenes. Sci. Justice 2017, 57, 373–375. [Google Scholar] [CrossRef] [PubMed]
- Barnas, A.F.; Darby, B.J.; Vandeberg, G.S.; Rockwell, R.F.; Ellis-Felege, S.N. A comparison of drone imagery and ground-based methods for estimating the extent of habitat destruction by lesser snow geese (Anser caerulescens caerulescens) in La Pérouse Bay. PLoS ONE 2019, 14, e0217049. [Google Scholar] [CrossRef] [PubMed]
- Bendig, J.; Bolten, A.; Bennertz, S.; Broscheit, J.; Eichfuss, S.; Bareth, G. Estimating biomass of barley using crop surface models (CSMs) derived from UAV-based RGB imaging. Remote Sens. 2014, 6, 10395–10412. [Google Scholar] [CrossRef]
- Díaz-Varela, R.A.; De la Rosa, R.; León, L.; Zarco-Tejada, P.J. High-resolution airborne UAV imagery to assess olive tree crown parameters using 3D photo reconstruction: Application in breeding trials. Remote Sens. 2015, 7, 4213–4232. [Google Scholar] [CrossRef]
- Daud, S.M.S.M.; Yusof, M.Y.P.M.; Heo, C.C.; Khoo, L.S.; Singh, M.K.C.; Mahmood, M.S.; Nawawi, H. Applications of drone in disaster management: A scoping review. Sci. Justice 2022, 62, 30–42. [Google Scholar] [CrossRef]
- Yin, S.; Zhao, Y.; Li, L.; Yu, R.F. UAV-assisted cooperative communications with time-sharing information and power transfer. IEEE Trans. Veh. Technol. 2019, 69, 1554–1567. [Google Scholar] [CrossRef]
- Su, Z.; Wang, Y.; Xu, Q.; Zhang, N. LVBS: Lightweight vehicular blockchain for secure data sharing in disaster rescue. IEEE Trans. Dependable Secure Comput. 2020, 19, 19–32. [Google Scholar] [CrossRef]
- Liu, X.; Liu, H.; Zheng, K.; Liu, J.; Taleb, T.; Shiratori, N. AoI-minimal clustering, transmission and trajectory co-design for UAV-assisted WPCNs. IEEE Trans. Veh. Technol. 2024, 1–16. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, R. Energy-efficient UAV communication with trajectory optimization. IEEE Trans. Wireless Commun. 2017, 16, 3747–3760. [Google Scholar] [CrossRef]
- Yadav, P.; Mishra, A.; Kim, S. A Comprehensive Survey on Multi-Agent Reinforcement Learning for Connected and Automated Vehicles. Sensors 2023, 23, 4710. [Google Scholar] [CrossRef]
- Zhang, J.; Letaief, K.B. Mobile edge intelligence and computing for the internet of vehicles. Proc. IEEE 2019, 108, 246–261. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, Q. Genetic algorithm-based optimization of offloading and resource allocation in mobile-edge computing. Information 2020, 11, 83. [Google Scholar] [CrossRef]
- Al-Habob, A.A.; Dobre, O.A.; Armada, A.G. Sequential task scheduling for mobile edge computing using genetic algorithm. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Hu, X.; Huang, Y. Deep reinforcement learning based offloading decision algorithm for vehicular edge computing. PeerJ Comput. Sci. 2022, 8, e1126. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep reinforcement learning for online computation offloading in wireless powered mobile-edge computing networks. IEEE Trans. Mob. Comput. 2019, 19, 2581–2593. [Google Scholar] [CrossRef]
- Yan, K.; Shan, H.; Sun, T.; Hu, H.; Wu, Y.; Yu, L. Reinforcement learning-based mobile edge computing and transmission scheduling for video surveillance. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1142–1156. [Google Scholar]
- Nguyen, D.; Ding, M.; Pathirana, P.; Seneviratne, A.; Li, J.; Vincent Poor, H. Cooperative task offloading and block mining in blockchain-based edge computing with multi-agent deep reinforcement learning. IEEE Trans. Mob. Comput. 2021, 22, 2021–2037. [Google Scholar] [CrossRef]
- Peng, H.; Shen, X. Multi-agent reinforcement learning based resource management in MEC-and UAV-assisted vehicular networks. IEEE J. Sel. Areas Commun. 2020, 39, 131–141. [Google Scholar] [CrossRef]
- Lu, K.; Li, R.D.; Li, M.C.; Xu, G.R. MADDPG-based joint optimization of task partitioning and computation resource allocation in mobile edge computing. Neural Comput. Appl. 2023, 35, 16559–16576. [Google Scholar] [CrossRef]
- Huang, B.; Liu, X.; Wang, S.; Pan, L.; Chang, V. Multi-agent reinforcement learning for cost-aware collaborative task execution in energy-harvesting D2D networks. Comput. Netw. 2021, 195, 108176. [Google Scholar] [CrossRef]
- Kumar, A.S.; Zhao, L.; Fernando, X. Task Offloading and Resource Allocation in Vehicular Networks: A Lyapunov-based Deep Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2023, 72, 13360–13373. [Google Scholar] [CrossRef]
- Argerich, M.F.; Fürst, J.; Cheng, B. Tutor4RL: Guiding Reinforcement Learning with External Knowledge. In Proceedings of the AAAI Spring Symposium on Combining Machine Learning and Knowledge Engineering, Palo Alto, CA, USA, 23–25 March 2020. [Google Scholar]
- Chen, N.; Zhang, S.; Qian, Z.; Wu, J.; Lu, S. When learning joins edge: Real-time proportional computation offloading via deep reinforcement learning. In Proceedings of the IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 4–6 December 2019; pp. 414–421. [Google Scholar]
- Wu, G.; Wang, H.; Zhang, H.; Zhao, Y.; Yu, S.; Shen, S. Computation Offloading Method Using Stochastic Games for Software Defined Network-based Multi-Agent Mobile Edge Computing. IEEE Internet Things J. 2023, 10, 17620–17634. [Google Scholar] [CrossRef]
- Raivi, A.M.; Moh, S. JDACO: Joint Data Aggregation and Computation Offloading in UAV-Enabled Internet of Things for Post-Disaster Scenarios. IEEE Internet Things J. 2024, 11, 16529–16544. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, R.; Zhang, Y.; Peng, J.; Liu, J.; Li, K. UAV-assisted Dependency-aware Computation Offloading in Device–Edge–Cloud Collaborative Computing Based on Improved Actor–Critic DRL. J. Syst. Archit. 2024, 154, 103215. [Google Scholar] [CrossRef]
- Wang, S.; Song, X.; Song, T.; Yang, Y. Fairness-aware Computation Offloading with Trajectory Optimization and Phase-shift Design in RIS-assisted Multi-UAV MEC Network. IEEE Internet Things J. 2024, 11, 20547–20561. [Google Scholar] [CrossRef]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Cheng, P.; Hao, W.; Dai, S.; Liu, J.; Gan, Z.; Carin, L. Club: A contrastive log-ratio upper bound of mutual information. In Proceedings of the International Conference on Machine Learning (ICML), Vienna, Austria, 12–18 July 2020; pp. 1779–1788. [Google Scholar]
- Li, J.; Gao, H.; Lv, T.; Lu, Y. Deep reinforcement learning based computation offloading and resource allocation for MEC. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Tran, T.X.; Pompili, D. Joint task offloading and resource allocation for multi-server mobile-edge computing networks. IEEE Trans. Veh. Technol. 2018, 68, 856–868. [Google Scholar] [CrossRef]
- Wang, J.; Feng, D.; Zhang, S.; Tang, J. Computation offloading for mobile edge computing enabled vehicular networks. IEEE Access 2019, 7, 62624–62632. [Google Scholar] [CrossRef]
- Wang, K.; Wang, X.; Liu, X. A high reliable computing offloading strategy using deep reinforcement learning for IOVs in edge computing. J. Grid Comput. 2021, 19, 15. [Google Scholar] [CrossRef]
- Cai, T.; Yang, Z.; Chen, Y.; Zhang, Y.; Wang, Z. Cooperative Data Sensing and Computation Offloading in UAV-assisted Crowdsensing with Multi-agent Deep Reinforcement Learning. IEEE Trans. Netw. Sci. Eng. 2021, 9, 3197–3211. [Google Scholar] [CrossRef]
- Bosilca, G.; Bouteiller, A.; Guermouche, A.; Herault, T.; Robert, Y.; Sens, P. Failure detection and propagation in HPC systems. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’16), Salt Lake City, UT, USA, 13–18 November 2016; pp. 312–322. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| groundHeight | 100 m |
| groundLength | 100 m |
| groundWidth | 100 m |
| 5 GHz | |
| GHz | |
| s | 1000 cycles/bit |
| 1 m/s | |
| battery | 500,000 |
| 30–40 Mbits |
| Parameters | Values |
|---|---|
| Critical neural network structure | GRU, MLP |
| GRU network layers | 1 |
| MLP network layers | The number of UAVs |
| Batch size | 128 |
| Positive buffer size | |
| Negative buffer size | |
| Soft update factor | 0.1 |
| Epsilon | 0.1 |
| 1 | |
| 1 |
| Parameters | Values |
|---|---|
| Replay buffer size | |
| Actor network learning rate | |
| Critic network learning rate | |
| 0.5 | |
| 0.5 |
| Name | CER-MADDPG | SGRA-PERs | MADDPG |
|---|---|---|---|
| System overhead (2 UAVs) | 232 | 257 | 282 |
| System overhead (20 UAVs) | 2554 | 2847 | 3250 |
| Average task completion time of UAV (task size 30 Mbits) | 33 | 34 | 36 |
| Average task completion time of UAV (task size 1000 Mbits) | 354 | 386 | 398 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Jiao, H. Multi-Agent Reinforcement Learning-Based Computation Offloading for Unmanned Aerial Vehicle Post-Disaster Rescue. Sensors 2024, 24, 8014. https://doi.org/10.3390/s24248014
Wang L, Jiao H. Multi-Agent Reinforcement Learning-Based Computation Offloading for Unmanned Aerial Vehicle Post-Disaster Rescue. Sensors. 2024; 24(24):8014. https://doi.org/10.3390/s24248014
Chicago/Turabian StyleWang, Lixing, and Huirong Jiao. 2024. "Multi-Agent Reinforcement Learning-Based Computation Offloading for Unmanned Aerial Vehicle Post-Disaster Rescue" Sensors 24, no. 24: 8014. https://doi.org/10.3390/s24248014
APA StyleWang, L., & Jiao, H. (2024). Multi-Agent Reinforcement Learning-Based Computation Offloading for Unmanned Aerial Vehicle Post-Disaster Rescue. Sensors, 24(24), 8014. https://doi.org/10.3390/s24248014