
Hardware-Assisted Low-Latency NPU Virtualization Method for Multi-Sensor AI Systems


Abstract
1. Introduction
2. Simulation Environment and Methodology
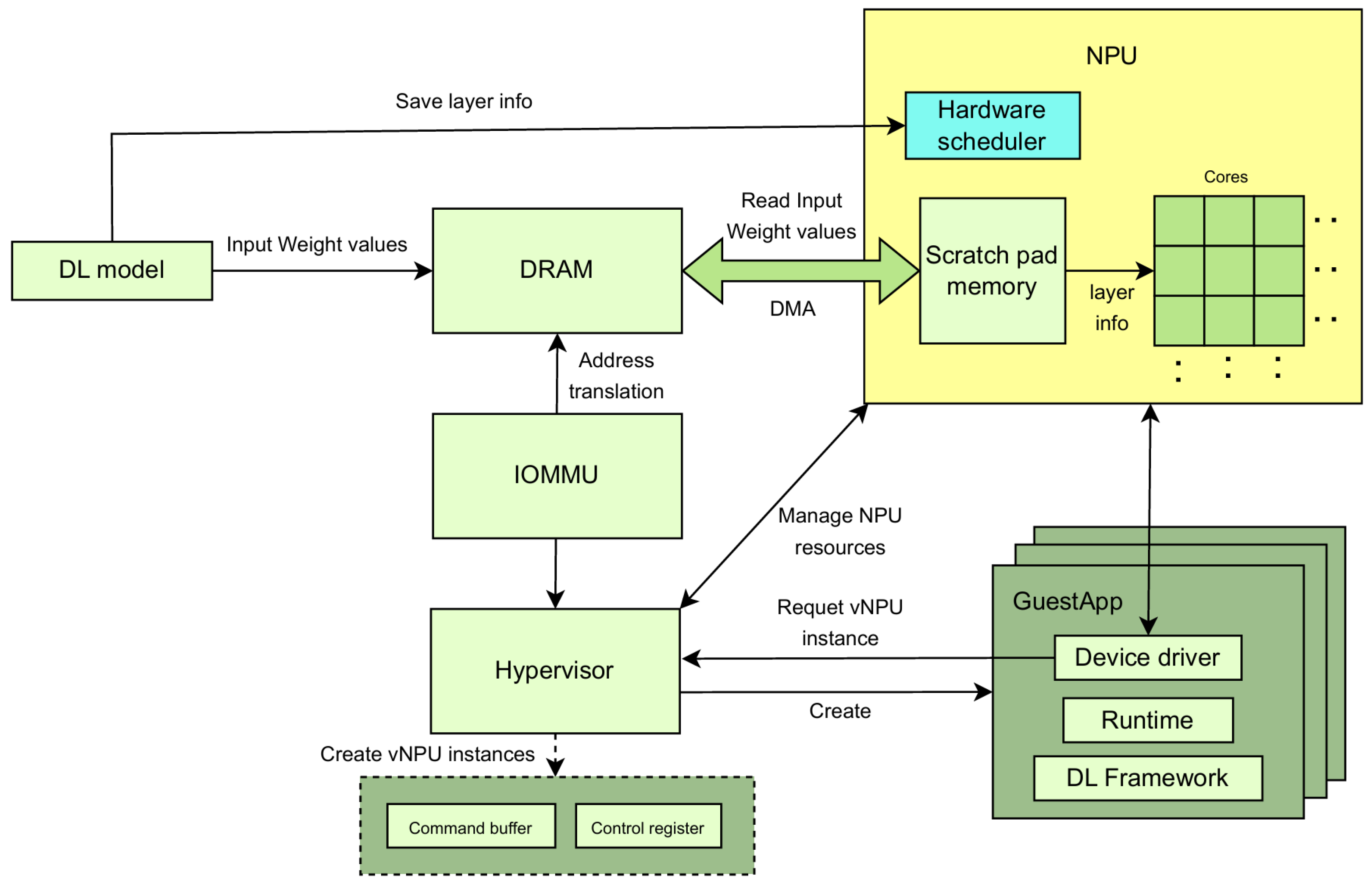
2.1. NPU Virtualization Operation Flow
2.2. Experimental Setup
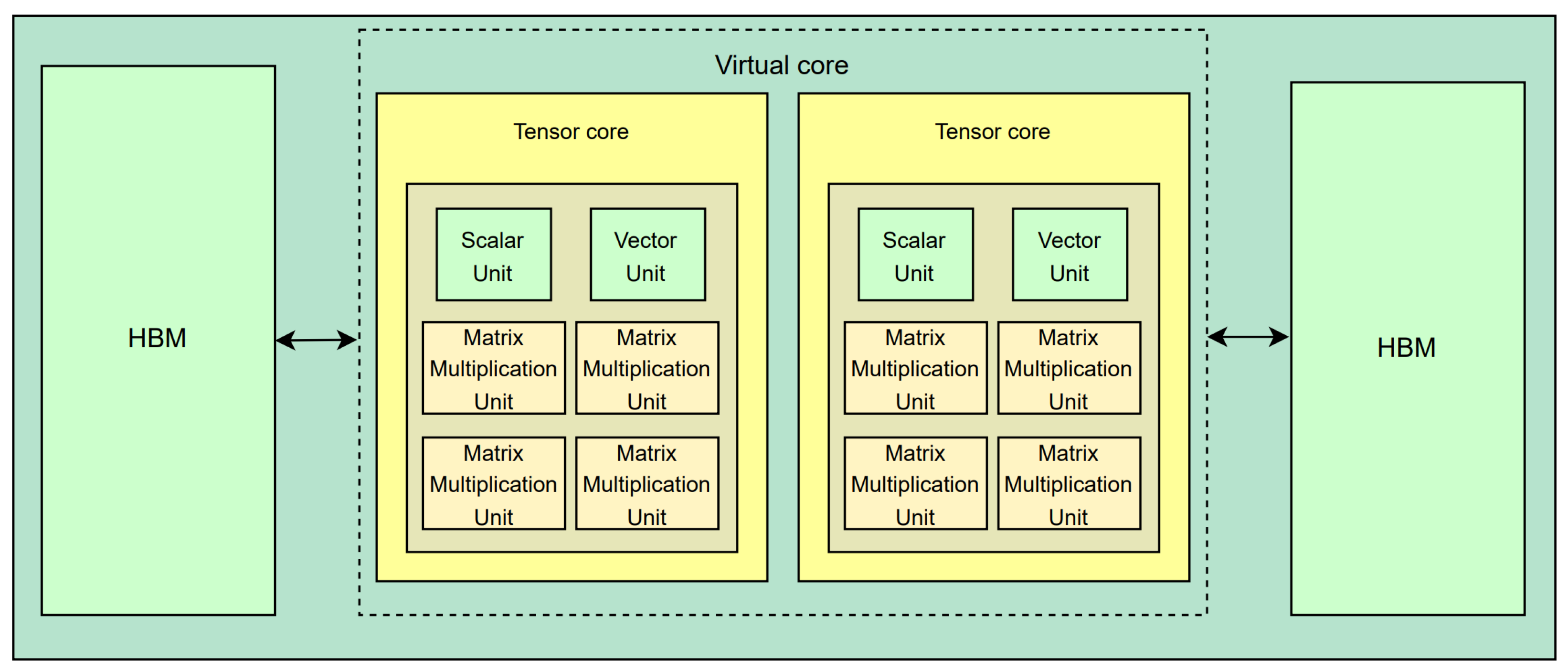
2.2.1. Neural Processing Unit (NPU) Architecture
2.2.2. SPM and DRAM Configuration
2.2.3. Deep-Learning Models Used
2.3. NPU Virtualization System
2.3.1. Hypervisor Design and Implementation
2.3.2. Data Prefetching Algorithms via Hardware Scheduler
| Algorithm 1: Data Prefetching for Hardware-Assisted NPU Virtualization |
 |
3. Results
3.1. Memory Access Cycles Under Different Burst Sizes and SA Counts
3.1.1. Effect of the Hardware Scheduler by Changing Burst Size
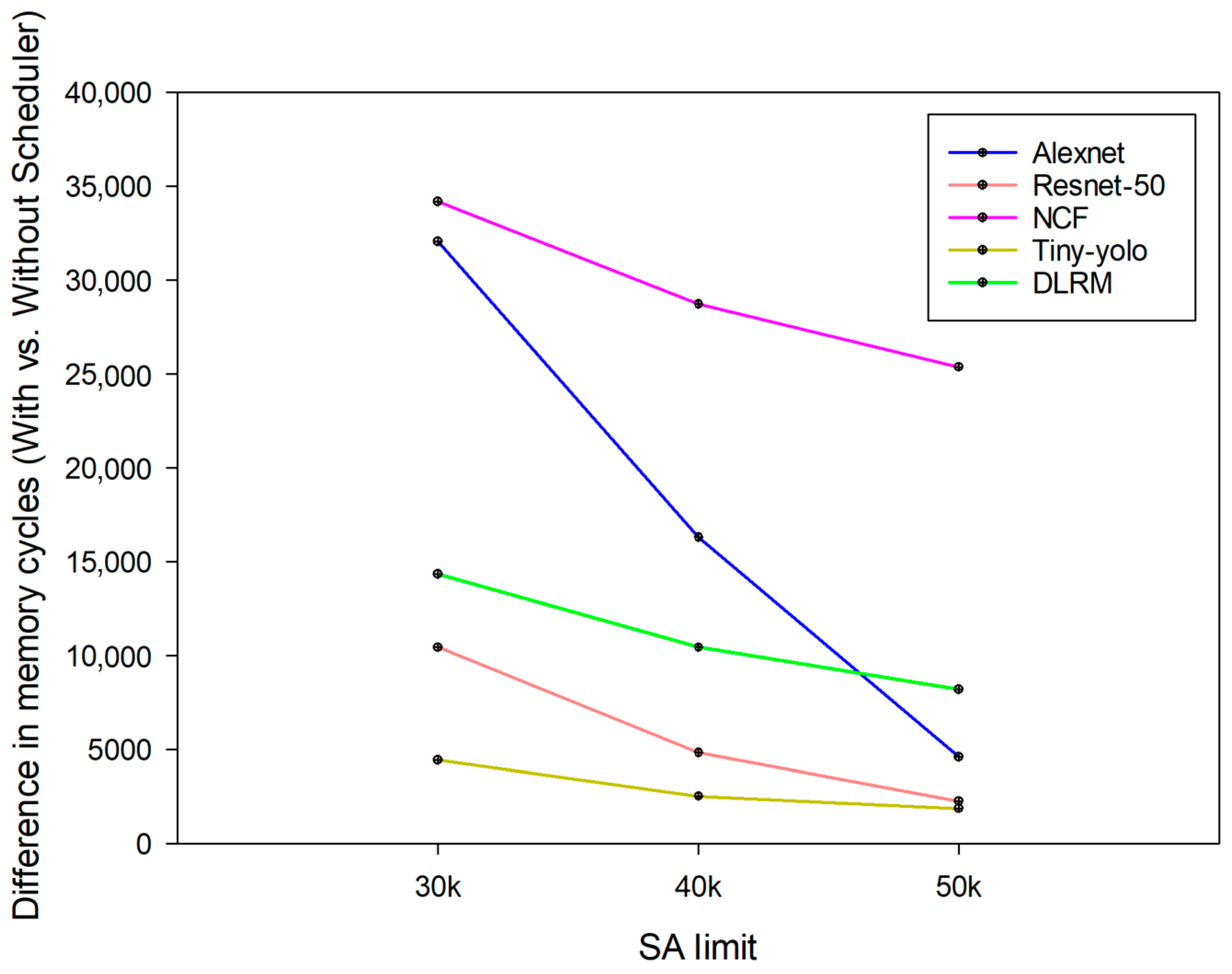
3.1.2. Effect of Hardware Scheduler by Changing a Limited Number of SA Resources
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, T.; Feng, B.; Huo, J.; Xiao, Y.; Wang, W.; Peng, J.; Li, Z.; Du, C.; Wang, W.; Zou, G.; et al. Artificial Intelligence Meets Flexible Sensors: Emerging Smart Flexible Sensing Systems Driven by Machine Learning and Artificial Synapses. Nano-Micro Lett. 2024, 16, 14. [Google Scholar] [CrossRef] [PubMed]
- Javaid, M.; Haleem, A.; Rab, S.; Singh, R.P.; Suman, R. Sensors for Daily Life: A Review. Sens. Int. 2021, 2, 100121. [Google Scholar] [CrossRef]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and smartwatch-based biometrics using activities of daily living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Méndez Gómez, J. Efficient Sensor Fusion of LiDAR and Radar for Autonomous Vehicles. Ph.D. Thesis, Universidad de Granada, Granada, Spain, 2022. [Google Scholar]
- Qureshi, S.A.; Hsiao, W.W.-W.; Hussain, L.; Aman, H.; Le, T.-N.; Rafique, M. Recent development of fluorescent nanodiamonds for optical biosensing and disease diagnosis. Biosensors 2022, 12, 1181. [Google Scholar] [CrossRef] [PubMed]
- Kadian, S.; Kumari, P.; Shukla, S.; Narayan, R. Recent advancements in machine learning enabled portable and wearable biosensors. Talanta Open 2023, 8, 100267. [Google Scholar] [CrossRef]
- Flynn, C.D.; Chang, D. Artificial Intelligence in Point-of-Care Biosensing: Challenges and Opportunities. Diagnostics 2024, 14, 1100. [Google Scholar] [CrossRef] [PubMed]
- Samsung Electronics. Samsung Electronics Introduces A High-Speed, Low-Power NPU Solution for AI Deep Learning. Samsung Semiconductor. Available online: https://semiconductor.samsung.com/news-events/tech-blog/samsung-electronics-introduces-a-high-speed-low-power-npu-solution-for-ai-deep-learning/ (accessed on 22 September 2024).
- Xue, Y.; Liu, Y.; Nai, L.; Huang, J. V10: Hardware-Assisted NPU Multi-tenancy for Improved Resource Utilization and Fairness. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Orlando, FL, USA, 17–21 June 2023; pp. 1–15. [Google Scholar]
- Xue, Y.; Liu, Y.; Huang, J. System Virtualization for Neural Processing Units. In Proceedings of the 19th Workshop on Hot Topics in Operating Systems, Providence, RI, USA, 22–24 June 2023; pp. 80–86. [Google Scholar]
- Xue, Y.; Liu, Y.; Nai, L.; Huang, J. Hardware-Assisted Virtualization of Neural Processing Units for Cloud Platforms. arXiv 2024, arXiv:2408.04104. [Google Scholar]
- Yoo, H.J. Deep learning processors for on-device intelligence. In Proceedings of the 2020 on Great Lakes Symposium on VLSI, Virtual Event, China, 7–9 September 2020; pp. 1–8. [Google Scholar]
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for ai-enabled iot devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Peters, A.M.; Akshintala, A.; Rossbach, C.J. AvA: Accelerated virtualization of accelerators. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 807–825. [Google Scholar]
- Jouppi, N.; Kurian, G.; Li, S.; Ma, P.; Nagarajan, R.; Nai, L.; Patil, N.; Subramanian, S.; Swing, A.; Towles, B.; et al. Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Orlando, FL, USA, 17–21 June 2023; pp. 1–14. [Google Scholar]
- Milovanovic, I.Z.; Tokic, T.I.; Milovanovic, E.I.; Stojcev, M.K. Determining the number of processing elements in systolic arrays. Facta Univ. Ser. Math. Inform. 2000, 15, 123–132. [Google Scholar]
- Chen, Y.X.; Ruan, S.J. A throughput-optimized channel-oriented processing element array for convolutional neural networks. IEEE Trans. Circuits Syst. II Express Briefs 2020, 68, 752–756. [Google Scholar] [CrossRef]
- Avissar, O.; Barua, R.; Stewart, D. An optimal memory allocation scheme for scratch-pad-based embedded systems. ACM Trans. Embed. Comput. Syst. (TECS) 2002, 1, 6–26. [Google Scholar] [CrossRef]
- Hwang, S.; Lee, S.; Kim, J.; Kim, H.; Huh, J. mnpusim: Evaluating the effect of sharing resources in multi-core npus. In Proceedings of the 2023 IEEE International Symposium on Workload Characterization (IISWC), Ghent, Belgium, 1–3 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 167–179. [Google Scholar]
- Kao, S.C.; Kwon, H.; Pellauer, M.; Parashar, A.; Krishna, T. A Formalism of DNN Accelerator Flexibility. Proc. ACM Meas. Anal. Comput. Syst. 2022, 6, 1–23. [Google Scholar] [CrossRef]
- Lozano, S.; Lugo, T.; Carretero, J. A Comprehensive Survey on the Use of Hypervisors in Safety-Critical Systems. IEEE Access 2023, 11, 36244–36263. [Google Scholar] [CrossRef]
- Paolino, M.; Pinneterre, S.; Raho, D. FPGA virtualization with accelerators overcommitment for network function virtualization. In Proceedings of the 2017 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 4–6 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Doddamani, S.; Sinha, P.; Lu, H.; Cheng, T.H.K.; Bagdi, H.H.; Gopalan, K. Fast and live hypervisor replacement. In Proceedings of the 15th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, Providence, RI, USA, 13–14 April 2019; pp. 45–58. [Google Scholar]
- Patel, A.; Daftedar, M.; Shalan, M.; El-Kharashi, M.W. Embedded hypervisor xvisor: A comparative analysis. In Proceedings of the 2015 23rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Turku, Finland, 4–5 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 682–691. [Google Scholar]
- Dummler, J.; Kunis, R.; Runger, G. Layer-based scheduling algorithms for multiprocessor-tasks with precedence constraints. In Proceedings of the International Conference on Parallel Computing: Architectures, Algorithms and Applications (ParCo 2007), Advances in Parallel Computing; IOS Press: Amsterdam, The Netherlands, 2007; Volume 5, pp. 321–328. [Google Scholar]
- Jiang, W.; Liu, P.; Jin, H.; Peng, J. An Efficient Data Prefetch Strategy for Deep Learning Based on Non-volatile Memory. In Green, Pervasive, and Cloud Computing: 15th International Conference, GPC 2020, Xi’an, China, 13–15 November 2020; Proceedings 15; Springer International Publishing: Cham, Switzerland, 2020; pp. 101–114. [Google Scholar]
- Aivaliotis, V.; Tsantikidou, K.; Sklavos, N. IoT-based multi-sensor healthcare architectures and a lightweight-based privacy scheme. Sensors 2022, 22, 4269. [Google Scholar] [CrossRef]
- El-Hajj, M.; Mousawi, H.; Fadlallah, A. Analysis of lightweight cryptographic algorithms on iot hardware platform. Future Internet 2023, 15, 54. [Google Scholar] [CrossRef]
- Kim, K.; Jang, S.J.; Park, J.; Lee, E.; Lee, S.S. Lightweight and energy-efficient deep learning accelerator for real-time object detection on edge devices. Sensors 2023, 23, 1185. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Data flow type | Output stationary |
| Systolic height | 128 |
| Systolic width | 128 |
| Tile ifmap size (byte) | 786,432 |
| Tile filter size (byte) | 786,432 |
| Tile ofmap size (byte) | 786,432 |
| Parameter | Value |
|---|---|
| Tlb assoc | 8 |
| Tlb entrynum | 2048 |
| Npu clock speed (GHz) | 2 |
| Dram clock speed (GHz) | 2 |
| SPM size (bytes) | 37,748,736 |
| SPM latency | 1 |
| Data block size (bytes) | 64 |
| Parameter | Value |
|---|---|
| Channels | 8 |
| Bus Width (bit) | 128 |
| Bank Groups | 4 |
| Banks per Group | 4 |
| Rows per Bank | 32,768 |
| Columns per Row | 64 |
| Device Width (bit) | 128 |
| Burst Length (BL) | 4 |
| tCK (ns) | 1 |
| CL (CAS Latency) | 14 |
| tRCD (Row-to-Column Delay) | 14 |
| tRP (Row Precharge Time) | 14 |
| tRAS (Row Active Time) | 34 |
| tRFC (Refresh Cycle Time) | 260 |
| tWR (Write Recovery Time) | 16 |
| VDD (V) | 1.2 |
| IDD0 (Active Power) | 65 mA |
| IDD4R (Read Power) | 390 mA |
| Channel Size (MB) | 1024 |
| Row Buffer Policy | Open Page |
| Model | 1-Before | 2-After | Reduction (%) |
|---|---|---|---|
| Alexnet | 253,764.0000 | 221,712.0000 | 12.63% |
| Resnet-50 | 73,282.0000 | 62,847.0000 | 14.24% |
| NCF | 93,940.0000 | 59,763.0000 | 36.38% |
| Yolo-tiny | 25,996.0000 | 21,558.0000 | 17.07% |
| DLRM | 18,656.0000 | 4324.0000 | 76.82% |
| Model | 1-Before | 2-After | Reduction (%) |
|---|---|---|---|
| Alexnet | 239,652.0000 | 206,201.0000 | 13.96% |
| Resnet-50 | 71,220.0000 | 60,198.0000 | 15.48% |
| NCF | 91,020.0000 | 57,837.0000 | 36.46% |
| Yolo-tiny | 24,046.0000 | 20,211.0000 | 15.95% |
| DLRM | 16,521.0000 | 2762.0000 | 83.28% |
| Model | 30,000 SA Before | 30,000 SA After | Reduction (%) |
|---|---|---|---|
| Alexnet | 253,764.0000 | 221,712.0000 | 12.63% |
| Resnet-50 | 73,282.0000 | 62,847.0000 | 14.24% |
| NCF | 93,940.0000 | 59,763.0000 | 36.38% |
| Yolo-tiny | 25,996.0000 | 21,558.0000 | 17.07% |
| DLRM | 18,656.0000 | 4324.0000 | 76.82% |
| Model | 40,000 SA Before | 40,000 SA After | Reduction (%) |
|---|---|---|---|
| Alexnet | 195,700.0000 | 179,400.0000 | 8.33% |
| Resnet-50 | 40,473.0000 | 35,650.0000 | 11.92% |
| NCF | 86,524.0000 | 57,811.0000 | 33.19% |
| Yolo-tiny | 22,326.0000 | 19,802.0000 | 11.31% |
| DLRM | 14,254.0000 | 3816.0000 | 73.22% |
| Model | 50,000 SA Before | 50,000 SA After | Reduction (%) |
|---|---|---|---|
| Alexnet | 145,632.0000 | 141,027.0000 | 3.16% |
| Resnet-50 | 27,889.0000 | 25,620.0000 | 8.14% |
| NCF | 82,242.0000 | 56,864.0000 | 30.86% |
| Yolo-tiny | 19,124.0000 | 17,256.0000 | 9.77% |
| DLRM | 11,412.0000 | 3224.0000 | 71.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jean, J.-H.; Kim, D.-S. Hardware-Assisted Low-Latency NPU Virtualization Method for Multi-Sensor AI Systems. Sensors 2024, 24, 8012. https://doi.org/10.3390/s24248012
Jean J-H, Kim D-S. Hardware-Assisted Low-Latency NPU Virtualization Method for Multi-Sensor AI Systems. Sensors. 2024; 24(24):8012. https://doi.org/10.3390/s24248012
Chicago/Turabian StyleJean, Jong-Hwan, and Dong-Sun Kim. 2024. "Hardware-Assisted Low-Latency NPU Virtualization Method for Multi-Sensor AI Systems" Sensors 24, no. 24: 8012. https://doi.org/10.3390/s24248012
APA StyleJean, J.-H., & Kim, D.-S. (2024). Hardware-Assisted Low-Latency NPU Virtualization Method for Multi-Sensor AI Systems. Sensors, 24(24), 8012. https://doi.org/10.3390/s24248012