A Review of Emotion Recognition Methods Based on Data Acquired via Smartphone Sensors



Abstract
1. Introduction
2. Emotion Recognition
3. Smartphone Sensors and Input Channels for Emotion Recognition
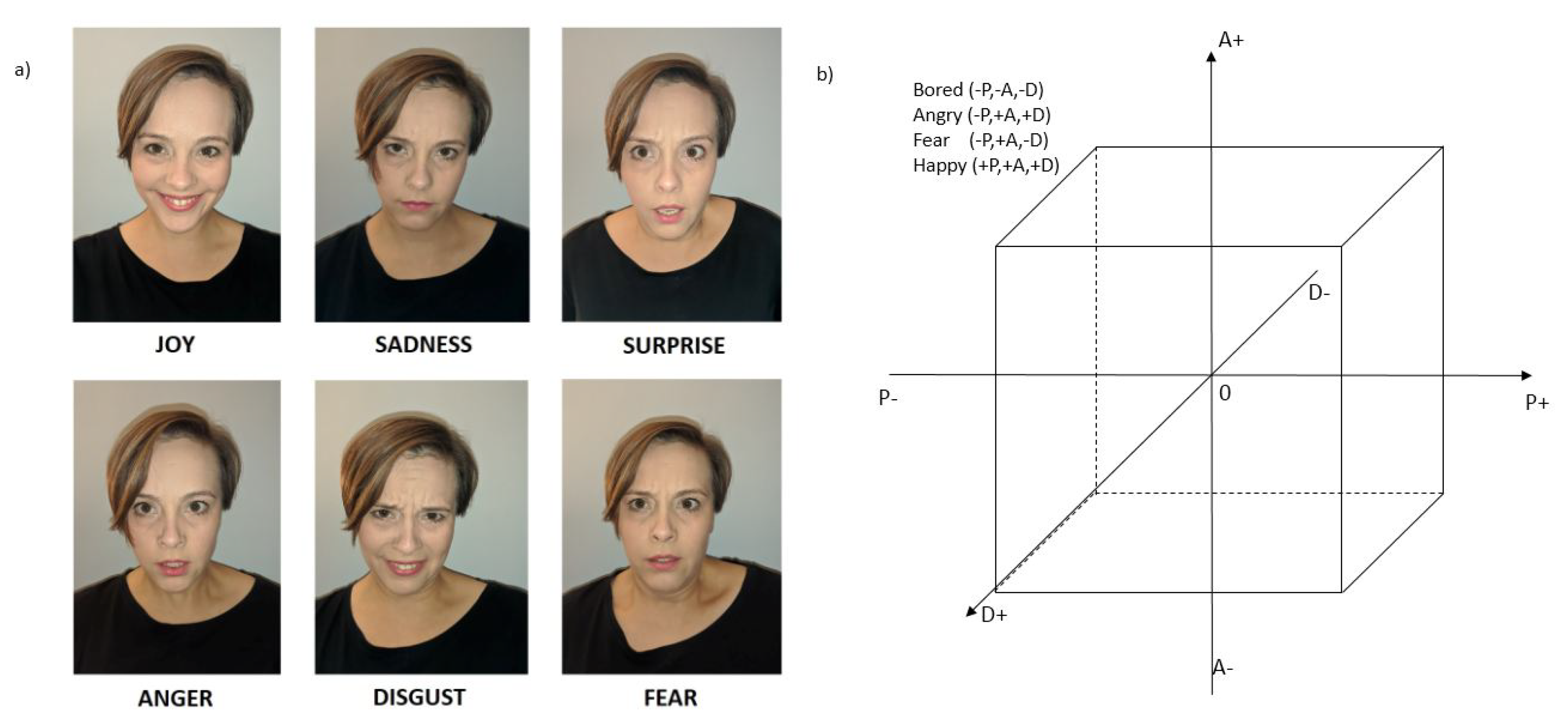
3.1. Camera
3.2. Microphone
3.3. Keyboard and Touch Screen
3.4. Depth Sensors
3.5. Accelerometer and Gyroscope
3.6. Geolocation Sensor, Barometer, and Compass
3.7. Other Sensors
4. The State of the Art
4.1. Experiment Design
4.2. Data Collection
4.2.1. Limitations
4.2.2. Data Labelling
4.3. Data Representation
4.3.1. Touch Dynamics
4.3.2. Movements
Low-Level Features
Mid-Level Features
High-Level Features
4.3.3. Location
4.3.4. Social Interactions
4.3.5. Ambient Light
4.3.6. Additional Information
4.4. Feature Evaluation
4.5. Model Training
5. Conclusions
5.1. Design Guidelines
- Selection of input channels. One of the first decisions a designer has to make up is the selection of input channels. This decision mainly depends on the type of application. If data is supposed to be recorded while user interacts with a specific application designed for this purpose, then touchscreen and inertial sensors should be considered. Otherwise, i.e., if it is supposed to be a continuous sensing application recording data in the background, then inertial sensors, GPS, and Bluetooth might be taken into account.
- Sensing schedule design. In the case of continuous sensing, devising a compromise between accuracy and energy cost is a challenge. A higher sampling rate obviously leads to more accurate data series, but it drains the battery. It is especially troublesome in the case of GPS sensing. Therefore, an optimal sampling schedule should be applied. It may be based on time of day or events detected, e.g., GPS recording may start when movement is detected [111] or the resource allocation may be adaptive depending on a user’s current priorities [113].
- ESM schedule design. Much attention should also be paid to interface design to make the data collection process as unobtrusive as possible. This mainly applies to data labelling, which should ensure a compromise between the amounts of obtained labelled samples and possible user fatigue. Several ESM scheduling techniques are presented in Section 4.2.2. A user should always have an option not to send a self-report or even the possibility to initialise the report himself.
- Data preprocessing. One of the first steps of raw data preprocessing is the removal of incomplete or inaccurate samples, e.g., a session shorter than a predefined minimum time, a sample containing too little data, e.g., a text message shorter than a specified minimum length. Unlabelled samples should be deleted as well if data are collected for training and supervised techniques are to be applied. Another preprocessing step is normalisation, e.g., in the case of spacial touchscreen data, normalisation should be performed if the system if the application is supposed to be independent of different screen sizes. For time-series data, e.g., obtained from accelerometer or gyroscope, noise reduction is usually performed, e.g., by applying a moving average filter to each of the three axes. GPS locations are often clustered to identify a set of regions.
- Data segmentation. Raw data need to be split into frames. In the case of time series data, they are split using a sliding window of a predefined length. They may be also split into frames of different length by identifying characteristic points in the series, e.g., it is possible to split a sequence of accelerometer values into subsequences of single steps. In some cases data frames are determined by activities performed within a specified application, e.g., data recorded during a typing session may be treated as a sample.
- Feature extraction. Depending on the input channel, various features may be extracted as it is described in detail in Section 4.3. The selection of features to be implemented also depends on the type of emotional states, that are going to be recognised. A number of insights on the discriminative power of features in the case of different emotions are given in Section 4.4. In general, touchscreen and accelerometer usually provide valuable information on valence and arousal, whereas GPS on valence, e.g., pleasure is positively correlated with location variance. Touch pressure and some gesture characteristics are good predictors of arousal and valence and they turn especially useful in the case of stress detection when motor behaviour becomes less accurate. Bluetooth is especially useful when social interactions, which also correlate with valence, are to be analysed. At this stage, one should not bother on the number of implemented hand-crafted features, because the next stage would reduce their number. However, the complexity of data extraction should be taken into account if inference on new samples is to be performed in real-time.
- Dimensionality reduction. Among features extracted in the previous stage, there might be a number of irrelevant ones. Moreover, high number of features increase the computational complexity of applied algorithms and the complexity of the models. Therefore, a feature selection procedure should be performed. Features may be filtered independently using information gain of Gini coefficient. However, a better subset of features could be identified if feature dependence was taken into account, e.g., by applying a sequential feature selection procedure. In both cases, one may assign a threshold value for the number of selected parameters. In the case of sequential selection, another criterion applied may be the recognition accuracy of a model trained on the basis of analysed feature subsets. In the case of large amounts of training data, a proper choice is to find personalised feature subsets, as different features prove to have discriminative power for different users [56,57,60,61].
- Model training. First of all, personal models adjusted for individual users are preferred [41,61,69,75]. Although they require large amounts of data from one user to be trained with high accuracy, it is possible to start with a general model and improve it when more personal samples are collected [72] or to use the knowledge contained among similar users [63,64]. Possible feedback from users on system accuracy is advisable even if the personalised model has already been trained and deployed. This is a good way to continuously validate the system and retrain the models to reduce the error rate.
5.2. Privacy
5.3. Applications
5.4. Future Trends
Author Contributions
Funding
Conflicts of Interest
References
- Ali, S.; Khusro, S.; Rauf, A.; Mahfooz, S. Sensors and Mobile Phones: Evolution and State-of-the-Art. Pak. J. Sci. 2014, 66, 386–400. [Google Scholar]
- Khan, W.Z.; Xiang, Y.; Aalsalem, M.Y.; Arshad, Q. Mobile Phone Sensing Systems: A Survey. IEEE Commun. Surv. Tutor. 2013, 15, 402–427. [Google Scholar] [CrossRef]
- Muaremi, A.; Arnrich, B.; Tröster, G. A Survey on Measuring Happiness with Smart Phones. In Proceedings of the 6th International Workshop on Ubiquitous Health and Wellness (Part of Pervasive 2012 Conference), Newcastle, UK, 18 June 2012. [Google Scholar]
- Rana, R.; Hume, M.; Reilly, J.; Jurdak, R.; Soar, J. Opportunistic and Context-Aware Affect Sensing on Smartphones. IEEE Pervasive Comput. 2016, 15, 60–69. [Google Scholar] [CrossRef]
- Politou, E.; Alepis, E.; Patsakis, C. A survey on mobile affective computing. Comput. Sci. Rev. 2017, 25, 79–100. [Google Scholar] [CrossRef]
- Szwoch, M. Evaluation of affective intervention process in development of affect-aware educational video games. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; pp. 1675–1679. [Google Scholar]
- Szwoch, M.; Szwoch, W. Using Different Information Channels for Affect-Aware Video Games—A Case Study. In Image Processing and Communications Challenges 10; Springer: Cham, Switzerland, 2019; Volume 892, pp. 104–113. [Google Scholar]
- Landowska, A.; Szwoch, M.; Szwoch, W. Methodology of Affective Intervention Design for Intelligent Systems. Interact. Comput. 2016, 28. [Google Scholar] [CrossRef]
- Kołakowska, A.; Landowska, A.; Szwoch, M.; Szwoch, W.; Wróbel, M.R. Emotion recognition and its application in software engineering. In Proceedings of the 2013 6th International Conference on Human System Interactions (HSI), Gdansk, Poland, 6–8 June 2013; pp. 532–539. [Google Scholar]
- Kołakowska, A. Towards detecting programmers’ stress on the basis of keystroke dynamics. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; pp. 1621–1626. [Google Scholar]
- Ekman, W.V.F.P. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Wu, T.; Fu, S.; Yang, G. Survey of the Facial Expression Recognition Research. In Advances in Brain Inspired Cognitive Systems; Zhang, H., Hussain, A., Liu, D., Wang, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 392–402. [Google Scholar]
- Sariyanidi, E.; Gunes, H.; Cavallaro, A. Automatic Analysis of Facial Affect: A Survey of Registration, Representation, and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1113–1133. [Google Scholar] [CrossRef]
- Mehta, D.; Siddiqui, M.F.H.; Javaid, A. Facial Emotion Recognition: A Survey and Real-World User Experiences in Mixed Reality. Sensors 2018, 18, 416. [Google Scholar] [CrossRef]
- Zhang, T. Facial Expression Recognition Based on Deep Learning: A Survey. In Advances in Intelligent Systems and Interactive Applications; Xhafa, F., Patnaik, S., Zomaya, A.Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 345–352. [Google Scholar]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Mitra, S.; Acharya, T. Gesture Recognition: A Survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Stephens-Fripp, B.; Naghdy, F.; Stirling, D.; Naghdy, G. Automatic Affect Perception Based on Body Gait and Posture: A Survey. Int. J. Soc. Robot. 2017, 9, 1–25. [Google Scholar] [CrossRef]
- Noroozi, F.; Kaminska, D.; Corneanu, C.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on Emotional Body Gesture Recognition. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Xu, S.; Fang, J.; Hu, X.; Ngai, E.; Guo, Y.; Leung, V.C.M.; Cheng, J.; Hu, B. Emotion Recognition From Gait Analyses: Current Research and Future Directions. arXiv 2020, arXiv:cs.HC/2003.11461. [Google Scholar]
- Furey, E.; Blue, J. The Emotographic Iceberg: Modelling Deep Emotional Affects Utilizing Intelligent Assistants and the IoT. In Proceedings of the 2019 19th International Conference on Computational Science and Its Applications (ICCSA), Saint Petersburg, Russia, 1–4 July 2019. [Google Scholar] [CrossRef]
- Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Aeluri, P.; Vijayarajan, V. Extraction of Emotions from Speech—A Survey. Int. J. Appl. Eng. Res. 2017, 12, 5760–5767. [Google Scholar]
- Sailunaz, K.; Dhaliwal, M.; Rokne, J.; Alhajj, R. Emotion Detection from Text and Speech—A Survey. Soc. Netw. Anal. Min. SNAM 2018, 8, 28. [Google Scholar] [CrossRef]
- Sebe, N.; Cohen, I.; Gevers, T.; Huang, T. Multimodal approaches for emotion recognition: A survey. Proc. SPIE Int. Soc. Opt. Eng. 2004, 5670. [Google Scholar] [CrossRef]
- Kessous, L.; Castellano, G.; Caridakis, G. Multimodal Emotion Recognition in Speech-based Interaction Using Facial Expression, Body Gesture and Acoustic Analysis. J. Multimodal User Interfaces 2009, 3, 33–48. [Google Scholar] [CrossRef]
- Sharma, G.; Dhall, A. A Survey on Automatic Multimodal Emotion Recognition in the Wild; Springer: Cham, Switzerland, 2020; pp. 35–64. [Google Scholar] [CrossRef]
- Kreibig, S. Autonomic Nervous System Activity in Emotion: A Review. Biol. Psychol. 2010, 84, 394–421. [Google Scholar] [CrossRef]
- Kołakowska, A.; Landowska, A.; Szwoch, M.; Szwoch, W.; Wróbel, M. Modeling Emotions for Affect-Aware Applications; Faculty of Management University of Gdansk: Gdansk, Poland, 2015; pp. 55–67. [Google Scholar]
- Landowska, A. Towards New Mappings between Emotion Representation Models. Appl. Sci. 2018, 8, 274. [Google Scholar] [CrossRef]
- Liu, M. A Study of Mobile Sensing Using Smartphones. Int. J. Distrib. Sens. Netw. 2013, 2013, 272916. [Google Scholar] [CrossRef]
- Grossi, M. A sensor-centric survey on the development of smartphone measurement and sensing systems. Measurement 2019, 135, 572–592. [Google Scholar] [CrossRef]
- Sensors Overview. Available online: developer.android.com (accessed on 30 September 2020).
- Compare iPhone Models. Available online: www.apple.com (accessed on 30 September 2020).
- Szwoch, M.; Pieniazek, P. Facial emotion recognition using depth data. In Proceedings of the 2015 8th International Conference on Human System Interaction (HSI), Warsaw, Poland, 25–27 June 2015; pp. 271–277. [Google Scholar] [CrossRef]
- Carneiro, D.; Castillo, J.C.; Novais, P.; FernáNdez-Caballero, A.; Neves, J. Multimodal Behavioral Analysis for Non-Invasive Stress Detection. Expert Syst. Appl. 2012, 39, 13376–13389. [Google Scholar] [CrossRef]
- Trojahn, M.; Arndt, F.; Weinmann, M.; Ortmeier, F. Emotion Recognition through Keystroke Dynamics on Touchscreen Keyboards. In Proceedings of the ICEIS, Angers, France, 4–7 July 2013. [Google Scholar]
- Hossain, R.B.; Sadat, M.; Mahmud, H. Recognition of human affection in Smartphone perspective based on accelerometer and user’s sitting position. In Proceedings of the 2014 17th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–23 December 2014; pp. 87–91. [Google Scholar]
- Cui, L.; Li, S.; Zhu, T. Emotion Detection from Natural Walking. In Revised Selected Papers of the Second International Conference on Human Centered Computing; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9567, pp. 23–33. [Google Scholar] [CrossRef]
- Dai, D.; Liu, Q.; Meng, H. Can your smartphone detect your emotion? In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; pp. 1704–1709. [Google Scholar]
- Exposito, M.; Hernandez, J.; Picard, R.W. Affective Keys: Towards Unobtrusive Stress Sensing of Smartphone Users. In Proceedings of the 20th International Conference on Human-Computer Interaction with Mobile Devices and Services Adjunct, Barcelona, Spain, 3–6 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 139–145. [Google Scholar] [CrossRef]
- Ruensuk, M.; Oh, H.; Cheon, E.; Oakley, I.; Hong, H. Detecting Negative Emotions during Social Media Use on Smartphones. In Proceedings of the Asian CHI Symposium 2019: Emerging HCI Research Collection, Glasgow, UK, 5 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 73–79. [Google Scholar] [CrossRef]
- Tikadar, S.; Kazipeta, S.; Ganji, C.; Bhattacharya, S. A Minimalist Approach for Identifying Affective States for Mobile Interaction Design. In Human-Computer Interaction—INTERACT 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 3–12. [Google Scholar]
- Maramis, C.; Stefanopoulos, L.; Chouvarda, I.; Maglaveras, N. Emotion Recognition from Haptic Touch on Android Device Screens. In Precision Medicine Powered by pHealth and Connected Health; Springer: Singapore, 2018; pp. 205–209. [Google Scholar]
- Tikadar, S.; Bhattacharya, S. A Novel Method to Build and Validate an Affective State Prediction Model from Touch-Typing. In Human-Computer Interaction–INTERACT 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 99–119. [Google Scholar]
- Sarsenbayeva, Z.; van Berkel, N.; Hettiachchi, D.; Jiang, W.; Dingler, T.; Velloso, E.; Kostakos, V.; Goncalves, J. Measuring the Effects of Stress on Mobile Interaction. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3. [Google Scholar] [CrossRef]
- Hashmi, M.A.; Riaz, Q.; Zeeshan, M.; Shahzad, M.; Fraz, M.M. Motion Reveal Emotions: Identifying Emotions from Human Walk Using Chest Mounted Smartphone. IEEE Sens. J. 2020, 20, 13511–13522. [Google Scholar] [CrossRef]
- Wampfler, R.; Klingler, S.; Solenthaler, B.; Schinazi, V.R.; Gross, M. Affective State Prediction Based on Semi-Supervised Learning from Smartphone Touch Data. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar] [CrossRef]
- Bachmann, A.; Klebsattel, C.; Budde, M.; Riedel, T.; Beigl, M.; Reichert, M.; Santangelo, P.; Ebner-Priemer, U. How to Use Smartphones for Less Obtrusive Ambulatory Mood Assessment and Mood Recognition. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Association for Computing, Osaka, Japan, 9–11 September 2015; pp. 693–702. [Google Scholar] [CrossRef]
- Lee, H.; Choi, Y.S.; Lee, S.; Park, I.P. Towards unobtrusive emotion recognition for affective social communication. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 260–264. [Google Scholar]
- Stütz, T.; Kowar, T.; Kager, M.; Tiefengrabner, M.; Stuppner, M.; Blechert, J.; Wilhelm, F.H.; Ginzinger, S. Smartphone Based Stress Prediction. In User Modeling, Adaptation and Personalization; Ricci, F., Bontcheva, K., Conlan, O., Lawless, S., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 240–251. [Google Scholar]
- Pielot, M.; Dingler, T.; Pedro, J.S.; Oliver, N. When Attention is Not Scarce—Detecting Boredom from Mobile Phone Usage. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 825–836. [Google Scholar] [CrossRef]
- Sasaki, W.; Nakazawa, J.; Okoshi, T. Comparing ESM Timings for Emotional Estimation Model with Fine Temporal Granularity. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 722–725. [Google Scholar] [CrossRef]
- Ghosh, S.; Hiware, K.; Ganguly, N.; Mitra, B.; De, P. Emotion detection from touch interactions during text entry on smartphones. Int. J. Hum. Comput. Stud. 2019, 130, 47–57. [Google Scholar] [CrossRef]
- Bauer, G.; Lukowicz, P. Can smartphones detect stress-related changes in the behaviour of individuals? In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, Lugano, Switzerland, 19–23 March 2012; pp. 423–426. [Google Scholar]
- LiKamWa, R.; Liu, Y.; Lane, N.D.; Zhong, L. Can your smartphone infer your mood. In Proceedings of the PhoneSense Workshop, Seattle, WA, USA, 1 November 2011; pp. 1–5. [Google Scholar]
- Ma, Y.; Xu, B.; Bai, Y.; Sun, G.; Zhu, R. Daily Mood Assessment Based on Mobile Phone Sensing. In Proceedings of the 2012 Ninth International Conference on Wearable and Implantable Body Sensor Networks, London, UK, 9–12 May 2012; pp. 142–147. [Google Scholar]
- Moturu, S.; Khayal, I.; Aharony, N.; Pan, W.; Pentland, A. Using social sensing to understand the links between sleep, mood and sociability. In Proceedings of the IEEE International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011. [Google Scholar]
- Zhang, X.; Li, W.; Chen, X.; Lu, S. MoodExplorer: Towards Compound Emotion Detection via Smartphone Sensing. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1. [Google Scholar] [CrossRef]
- LiKamWa, R.; Liu, Y.; Lane, N.D.; Zhong, L. MoodScope: Building a Mood Sensor from Smartphone Usage Patterns. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 389–402. [Google Scholar] [CrossRef]
- Wang, R.; Chen, F.; Chen, Z.; Li, T.; Harari, G.; Tignor, S.; Zhou, X.; Ben-Zeev, D.; Campbell, A.T. StudentLife: Assessing Mental Health, Academic Performance and Behavioral Trends of College Students Using Smartphones. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 3–14. [Google Scholar] [CrossRef]
- Garcia-Ceja, E.; Osmani, V.; Mayora-Ibarra, O. Automatic Stress Detection in Working Environments From Smartphones’ Accelerometer Data: A First Step. IEEE J. Biomed. Health Inform. 2016, 20, 1053–1060. [Google Scholar] [CrossRef]
- Maxhuni, A.; Hernandez-Leal, P.; Sucar, L.E.; Osmani, V.; Morales, E.F.; Mayora, O. Stress Modelling and Prediction in Presence of Scarce Data. J. Biomed. Inform. 2016, 63, 344–356. [Google Scholar] [CrossRef] [PubMed]
- Roshanaei, M.; Han, R.; Mishra, S. EmotionSensing: Predicting Mobile User Emotion. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, Sydney, Australia, 31 July–3 August 2017; pp. 325–330. [Google Scholar] [CrossRef]
- Sandstrom, G.M.; Lathia, N.; Mascolo, C.; Rentfrow, P.J. Putting mood in context: Using smartphones to examine how people feel in different locations. J. Res. Personal. 2017, 69, 96–101. [Google Scholar] [CrossRef]
- Servia-Rodríguez, S.; Rachuri, K.; Mascolo, C.; Rentfrow, P.; Lathia, N.; Sandstrom, G. Mobile Sensing at the Service of Mental Well-being: A Large-scale Longitudinal Study. In Proceedings of the 26 International World Wide Web Conference, Perth, Australia, 3–7 April 2017; pp. 103–112. [Google Scholar] [CrossRef]
- Mottelson, A.; Hornbæk, K. An Affect Detection Technique Using Mobile Commodity Sensors in the Wild. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 781–792. [Google Scholar] [CrossRef]
- Ciman, M.; Wac, K. Individuals’ Stress Assessment Using Human-Smartphone Interaction Analysis. IEEE Trans. Affect. Comput. 2018, 9, 51–65. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, Y.; Sun, J.; Rao, J.; Yu, W.; Chen, Y.; Fong, A.C.M. Quantitative Study of Individual Emotional States in Social Networks. IEEE Trans. Affect. Comput. 2012, 3, 132–144. [Google Scholar] [CrossRef]
- Macias, E.; Suarez, A.; Lloret, J. Mobile sensing systems. Sensors 2013, 13, 17292–17321. [Google Scholar] [CrossRef]
- Sun, B.; Ma, Q.; Zhang, S.; Liu, K.; Liu, Y. iSelf: Towards cold-start emotion labeling using transfer learning with smartphones. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; pp. 1203–1211. [Google Scholar]
- Olsen, A.F.; Torresen, J. Smartphone accelerometer data used for detecting human emotions. In Proceedings of the 2016 3rd International Conference on Systems and Informatics (ICSAI), Shanghai, China, 19–21 November 2016; pp. 410–415. [Google Scholar]
- Zualkernan, I.; Aloul, F.; Shapsough, S.; Hesham, A.; El-Khorzaty, Y. Emotion recognition using mobile phones. Comput. Electr. Eng. 2017, 60, 1–13. [Google Scholar] [CrossRef]
- Ghandeharioun, A.; McDuff, D.; Czerwinski, M.; Rowan, K. EMMA: An Emotion-Aware Wellbeing Chatbot. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 1–7. [Google Scholar]
- Bogomolov, A.; Lepri, B.; Ferron, M.; Pianesi, F.; Pentland, A.S. Pervasive stress recognition for sustainable living. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communication Workshops, Budapest, Hungary, 24–28 March 2014; pp. 345–350. [Google Scholar]
- Lane, N.D.; Mohammod, M.; Lin, M.; Yang, X.; Lu, H.; Ali, S.; Doryab, A.; Berke, E.; Choudhury, T.; Campbell, A. Bewell: A smartphone application to monitor, model and promote wellbeing. In Proceedings of the 5th International Conference on Pervasive Computing Technologies for Healthcare, Dublin, Ireland, 23–26 May 2011. [Google Scholar]
- Ghosh, S.; Sahu, S.; Ganguly, N.; Mitra, B.; De, P. EmoKey: An Emotion-aware Smartphone Keyboard for Mental Health Monitoring. In Proceedings of the 2019 11th International Conference on Communication Systems Networks (COMSNETS), Bengaluru, India, 7–11 January 2019; pp. 496–499. [Google Scholar]
- Ghosh, S.; Ganguly, N.; Mitra, B.; De, P. Effectiveness of Deep Neural Network Model in Typing-Based Emotion Detection on Smartphones. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 750–752. [Google Scholar] [CrossRef]
- Wang, P.; Dong, L.; Liu, W.; Jing, N. Clustering-Based Emotion Recognition Micro-Service Cloud Framework for Mobile Computing. IEEE Access 2020, 8, 49695–49704. [Google Scholar] [CrossRef]
- Conner, T.S.; Tennen, H.; Fleeson, W.; Barrett, L.F. Experience Sampling Methods: A Modern Idiographic Approach to Personality Research. Soc. Personal. Psychol. Compass 2009, 3, 292–313. [Google Scholar] [CrossRef]
- Shi, D.; Chen, X.; Wei, J.; Yang, R. User Emotion Recognition Based on Multi-class Sensors of Smartphone. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 478–485. [Google Scholar]
- Lee, H.; Cho, A.; Jo, Y.; Whang, M. The Relationships Between Behavioral Patterns and Emotions in Daily Life. In Advances in Computer Science and Ubiquitous Computing; Springer: Singapore, 2018; pp. 1332–1339. [Google Scholar]
- Saadatian, E.; Salafi, T.; Samani, H.; Lim, Y.D.; Nakatsu, R. An Affective Telepresence System Using Smartphone High Level Sensing and Intelligent Behavior Generation. In Proceedings of the Second International Conference on Human-Agent Interaction, Tsukuba, Japan, 28–31 October 2014; pp. 75–82. [Google Scholar] [CrossRef]
- Ghosh, S.; Chauhan, V.; Ganguly, N.; Mitra, B.; De, P. Impact of Experience Sampling Methods on Tap Pattern Based Emotion Recognition. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 7–11 September 2015; pp. 713–722. [Google Scholar] [CrossRef]
- Gao, Y.; Bianchi-Berthouze, N.; Meng, H. What Does Touch Tell Us about Emotions in Touchscreen-Based Gameplay? ACM Trans. Comput. Hum. Interact. 2012, 19. [Google Scholar] [CrossRef]
- Ghosh, S.; Ganguly, N.; Mitra, B.; De, P. Evaluating effectiveness of smartphone typing as an indicator of user emotion. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 146–151. [Google Scholar]
- Ghosh, S.; Ganguly, N.; Mitra, B.; De, P. TapSense: Combining Self-Report Patterns and Typing Characteristics for Smartphone Based Emotion Detection. In Proceedings of the 19th International Conference on Human-Computer Interaction with Mobile Devices and Services, Vienna, Austria, 4–7 September 2017. MobileHCI ’17. [Google Scholar] [CrossRef]
- Gonçalves, V.; Giancristofaro, G.T.; Filho, G.P.R.; Johnson, T.M.; Carvalho, V.; Pessin, G.; Néris, V.; Ueyama, J. Assessing users’ emotion at interaction time: A multimodal approach with multiple sensors. Soft Comput. 2017, 21, 5309–5323. [Google Scholar] [CrossRef]
- Ghosh, S.; Ganguly, N.; Mitra, B.; De, P. Towards designing an intelligent experience sampling method for emotion detection. In Proceedings of the 2017 14th IEEE Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2017; pp. 401–406. [Google Scholar]
- Ghosh, S.; Ganguly, N.; Mitra, B.; De, P. Designing An Experience Sampling Method for Smartphone based Emotion Detection. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Likert, R. A technique for the measurement of attitudes. Arch. Psychol. 1932, 22, 1–55. [Google Scholar]
- Cai, L.; Boukhechba, M.; Gerber, M.S.; Barnes, L.E.; Showalter, S.L.; Cohn, W.F.; Chow, P.I. An integrated framework for using mobile sensing to understand response to mobile interventions among breast cancer patients. Smart Health 2020, 15, 100086. [Google Scholar] [CrossRef]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Watson, D.; Clark, L.A.; Tellegen, A. Development and validation of brief measures of positive and negative affect: The PANAS scales. J. Personal. Soc. Psychol. 1988, 54, 1063–1070. [Google Scholar] [CrossRef]
- Pollak, J.P.; Adams, P.; Gay, G. PAM: A photographic affect meter for frequent, in situ measurement of affect. In Proceedings of the 29th ACM SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 725–734. [Google Scholar] [CrossRef]
- Cohen, S.; Kamarck, T.; Mermelstein, R. A Global Measure of Perceived Stress. J. Health Soc. Behav. 1983, 24, 385–396. [Google Scholar] [CrossRef]
- Lovibond, P.; Lovibond, S. The structure of negative emotional states: Comparison of the Depression Anxiety Stress Scales (DASS) with the Beck Depression and Anxiety Inventories. Behav. Res. Ther. 1995, 33, 335–343. [Google Scholar] [CrossRef]
- Balducci, F.; Impedovo, D.; Macchiarulo, N.; Pirlo, G. Affective states recognition through touch dynamics. Multimed. Tools Appl. 2020. [Google Scholar] [CrossRef]
- Ghosh, S.; Mitra, B.; De, P. Towards Improving Emotion Self-Report Collection Using Self-Reflection. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Frank, M.; Biedert, R.; Ma, E.; Martinovic, I.; Song, D. Touchalytics: On the Applicability of Touchscreen Input as a Behavioral Biometric for Continuous Authentication. IEEE Trans. Inf. Forensics Secur. 2013, 8, 136–148. [Google Scholar] [CrossRef]
- Serwadda, A.; Phoha, V.V.; Wang, Z. Which verifiers work?: A benchmark evaluation of touch-based authentication algorithms. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Teh, P.S.; Zhang, N.; Tan, S.Y.; Shi, Q.; Khoh, W.H.; Nawaz, R. Strengthen user authentication on mobile devices by using user’s touch dynamics pattern. Sens. J. Ambient. Intell. Humaniz. Comput. 2019. [Google Scholar] [CrossRef]
- Epp, C.; Lippold, M.; Mandryk, R.L. Identifying Emotional States Using Keystroke Dynamics. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 715–724. [Google Scholar] [CrossRef]
- Kołakowska, A. A review of emotion recognition methods based on keystroke dynamics and mouse movements. In Proceedings of the 2013 6th International Conference on Human System Interactions (HSI), Gdansk, Poland, 6–8 June 2013; pp. 548–555. [Google Scholar] [CrossRef]
- Kołakowska, A. Recognizing emotions on the basis of keystroke dynamics. In Proceedings of the 8th International Conference on Human System Interaction, Warsaw, Poland, 25–27 June 2015; pp. 667–675. [Google Scholar] [CrossRef]
- Ciman, M.; Wac, K.; Gaggi, O. iSensestress: Assessing stress through human-smartphone interaction analysis. In Proceedings of the 2015 9th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Istanbul, Turkey, 20–23 May 2015; pp. 84–91. [Google Scholar]
- Sneha, H.R.; Rafi, M.; Manoj Kumar, M.V.; Thomas, L.; Annappa, B. Smartphone based emotion recognition and classification. In Proceedings of the 2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 22–24 February 2017; pp. 1–7. [Google Scholar]
- Ghosh, S.; Goenka, S.; Ganguly, N.; Mitra, B.; De, P. Representation Learning for Emotion Recognition from Smartphone Keyboard Interactions. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 704–710. [Google Scholar]
- Olsen, A.F. Detecting Human Emotions Using Smartphone Accelerometer Data. Master’s Thesis, Department of Informatics, University of Oslo, Oslo, Norway, 2016. [Google Scholar]
- Lu, H.; Yang, J.; Liu, Z.; Lane, N.D.; Choudhury, T.; Campbell, A.T. The Jigsaw Continuous Sensing Engine for Mobile Phone Applications. In Proceedings of the 8th ACM Conference on Embedded Networked Sensor Systems, Zurich, Switzerland, 3–5 November 2010; pp. 71–84. [Google Scholar] [CrossRef]
- Dong, L.; Xu, Y.; Wang, P.; He, S. Classifier Fusion Method Based Emotion Recognition for Mobile Phone Users. In Broadband Communications, Networks, and Systems; Li, Q., Song, S., Li, R., Xu, Y., Xi, W., Gao, H., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 216–226. [Google Scholar]
- Lane, N.D.; Lin, M.; Mohammod, M.; Yang, X.; Lu, H.; Cardone, G.; Ali, S.; Doryab, A.; Berke, E.; Campbell, A.T.; et al. BeWell: Sensing Sleep, Physical Activities and Social Interactions to Promote Wellbeing. Mob. Netw. Appl. 2014, 19, 345–359. [Google Scholar] [CrossRef]
- Oh, K.; Park, H.; Cho, S. A Mobile Context Sharing System Using Activity and Emotion Recognition with Bayesian Networks. In Proceedings of the 2010 7th International Conference on Ubiquitous Intelligence Computing and 7th International Conference on Autonomic Trusted Computing, Xi’an, China, 26–29 October 2010; pp. 244–249. [Google Scholar]
- Bogomolov, A.; Lepri, B.; Pianesi, F. Happiness Recognition from Mobile Phone Data. In Proceedings of the 2013 International Conference on Social Computing, Alexandria, VA, USA, 8–14 September 2013; pp. 790–795. [Google Scholar]
- Bogomolov, A.; Lepri, B.; Ferron, M.; Pianesi, F.; Pentland, A.S. Daily Stress Recognition from Mobile Phone Data, Weather Conditions and Individual Traits. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 477–486. [Google Scholar] [CrossRef]
- Kołakowska, A. Usefulness of Keystroke Dynamics Features in User Authentication and Emotion Recognition. In Human-Computer Systems Interaction: Backgrounds and Applications 4; Springer: Cham, Switzerland, 2018; pp. 42–52. [Google Scholar] [CrossRef]
- Kim, M.; Kim, H.; Lee, S.; Choi, Y.S. A touch based affective user interface for smartphone. In Proceedings of the 2013 IEEE International Conference on Consumer Electronics (ICCE), Berlin, Germany, 8–11 September 2013; pp. 606–607. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Lietz, R.; Harraghy, M.; Calderon, D.; Brady, J.; Becker, E.; Makedon, F. Survey of Mood Detection through Various Input Modes. In Proceedings of the 12th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 5–7 June 2019; PETRA’19. pp. 28–31. [Google Scholar] [CrossRef]
- Mastoras, R.E.; Iakovakis, D.; Hadjidimitriou, S.; Charisis, V.; Kassie, S.; Alsaadi, T.; Khandoker, A.; Hadjileontiadis, L.J. Touchscreen typing pattern analysis for remote detection of the depressive tendency. Sci. Rep. 2019, 9, 13414. [Google Scholar] [CrossRef]
- Cao, B.; Zheng, L.; Zhang, C.; Yu, P.S.; Piscitello, A.; Zulueta, J.; Ajilore, O.; Ryan, K.; Leow, A.D. DeepMood: Modeling Mobile Phone Typing Dynamics for Mood Detection. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 747–755. [Google Scholar] [CrossRef]
- Dubad, M.; Winsper, C.; Meyer, C.; Livanou, M.; Marwaha, S. A systematic review of the psychometric properties, usability and clinical impacts of mobile mood-monitoring applications in young people. Psychol. Med. 2018, 48, 208–228. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Feature | Equation | References |
| mean | [43,48,60,63,68,73,74,82] | |
| median | [48,63,68] | |
| maximum, minimum | , | [43,48,63,68,82] |
| range | [63] | |
| interquartile range | , where and are the third and the first quartiles | [48] |
| variance | [60,63] | |
| standard deviation | [40,43,48,63,68,73,82] | |
| mean absolute deviation | [48] | |
| skewness | [40,48,73] | |
| kurtosis | [40,48,73] | |
| root mean square | [48,63,110] | |
| energy | [48] | |
| power | [48] | |
| magnitude | [63] | |
| signal magnitude area | [48,63] |
| Reference, Year | Emotions Recognized | Elicitation | Participants | Input Channel | Methods | Results | ||||||||
| Num (m/f) | Age | T | A | G | M | P | B | L | O | |||||
| [49], 2020 | valence, arousal, dominance (3 levels); stress, anger, happiness, sadness, surprise (binary) | yes | 70 (35/35) | 18–31 | x | deep learning (variational auto-encoder + fully connected layers); general model | ACC/AUC 67%/0.84 (valence), 63%/0.82 (arousal), 65%/0.82 (dominance); AUC: stress 0.8, anger 0.84, happiness 0.88, sadness 0.87, surprise 0.76 | |||||||
| [48], 2020 | sadness, happiness, anger, surprise, disgust, fear | no | 40 (26/14) | avg 25.2 | x | x | SVM | 95% (pair-wise), 86.45% (multiclass) | ||||||
| [99], 2020 | stress, anxiety, depression (5 levels) | no | 115 (100/15) | avg 19.8 | x | random forest (general) | stress and anxiety 73.4%, depression 74.1% | |||||||
| [112], 2019; [80], 2020 | valence, arousal (5 levels) | no | 50 | x | x | x | x | x | classifier fusion (neural networks, decision trees) | 71.67%, 72.37% | ||||
| [43], 2019 | valence, arousal (binary); affect (positive/negative) | yes | 41 (33/17) | avg 24.42 | x | x | x | x | SVM, personalised | browsing: 81% valence, 85% arousal, 81% affect; chatting: 69% valence, 72% arousal, 62% affect | ||||
| [46], 2019 | valence, arousal (binary) | yes | 33 (17/16) | avg 24.19 | x | x | naive Bayes, SVM (general, 4 classes as 4 combinations of valence/arousal) | 86.6% (naive Bayes), 83.21% (SVM) | ||||||
| [75], 2019 | valence, arousal (continuous) | no | 39 (32/7) | x | x | personalised regression (random forest for valence, Ada boost for arousal) | pleasure: 82.2%, arousal: 65.7% | |||||||
| [109], 2019 | happy, sad, stressed, relaxed | no | 24 (20/4) | avg 23.3 | x | multitask neural network (multiclass, first layers shared, then personalised layer) | AUC 84% | |||||||
| [78], 2019; [55], 2019 | happy, sad, stressed, relaxed | no | 22 (20/2) | 24-33 | x | random forest (personalised, multiclass) | AUC 78%, 73% | |||||||
| [79], 2018 | happy, sad, stressed, relaxed | no | 15 (12/3) | 24–33 | x | deep neural network (personalised, multiclass) | 80% | |||||||
| [69], 2018 | stress (5 levels) | yes | 13 (7/6) | 22–32 | x | decision tree, k-NN, Bayesian network, SVM, neural network | F-measure, 5-class: individual 79–87% (swipe), 77–81% (scroll); global 75–92% (swipe), 67–78% (scroll) | |||||||
| no | 25 | x | x | x | F-measure, 3-class: individual 86–88%, global 63-83% | |||||||||
| [54], 2018 | excited, cheerful, relaxed, calm, bored, sad, irritated, tense, neutral | no | 8 (2/6) | x | x | x | x | random forest | pleasant(excited, cheerful, relaxed, calm)/unpleasant(bored, sad, irritated and tense) 71%, activated(excited, cheerful, irritated, tense)/deactivated(relaxed, calm, bored, sad) 78.3% | |||||
| [60], 2018 | compound emotions (combination of sadness, anger, surprise, fear and disgust) | no | 30 (13/17) | 18–30 | x | x | x | x | x | x | personalised factor graph | 76% | ||
| [45], 2018 | excitement, relaxation, boredom, frustration | yes | 20 (10/10) | avg 34 | x | SVM, naive Bayes, random forest, logistic regression | 4-classes: 67.5% (svm, naive Bayes); 2-classes (excitement + relaxation vs. boredom+frustration): 78.75% (logistic regression), 77.5 (random forest) | |||||||
| [88], 2017 | happy, stressed, sad, relaxed | no | 22 (20/2) | 24–33 | x | x | random forest (personalised, multiclass) | AUC 84% | ||||||
| [87], 2017 | happy, stressed, sad, relaxed | no | 22 (20/2) | 24–33 | x | random forest (personalised, multiclass) | AUC 73% | |||||||
| [108], 2017 | anger, disgust, happy, sad, surprised, fear, neutral | no | x | x | x | x | x | naive Bayes (multiclass) | 72% | |||||
| [67], 2017 | valence, arousal (binary) | no | 18000 | x | x | deep neural network of stacked restricted Boltzmann machines | 68% (valence) | |||||||
| [44], 2017 | valence, arousal (binary) | yes | 29 (29/0) | 19–24 | x | k-NN, SVM, naive Bayes, decision tree | kNN 94.57%, SVM 96.75%, decision tree 96.4%, naive Bayes 88.4%, | |||||||
| [74], 2017 | happy, sad, angry, neutral | no | 3 | x | x | decision tree (multiclass, general), multi-response linear regression (binary, general) | decision tree: F-measure 0.902, AUC 0.954; regression: F-measure 0.896, AUC 0.851 | |||||||
| [73], 2016 | valence, arousal (3 levels) | no | 10 (3 provided enough data) | x | multilayer perceptron, SVM | arousal 75% SVM, valence 50.9% MLP | ||||||||
| [64], 2016 | stress (3 levels) | no | 30 (18/12) | avg 37.46 | x | x | decision trees + transfer learning (personalized) | 71.58% | ||||||
| [68], 2016 | affect (positive, neutral) | yes | 55 | x | x | x | SVM (general) for classification and regression | regression (7 point scale): RMSE 1.33; classification (binary): 87.3% (labels on the basis of two elicited states), 89.1% (labels from self reports) | ||||||
| valence, arousal, affect | no | 120 | x | x | x | SVM (general) for classification and regression | regression (7 point scale): affect RMSE 1.32, valence RMSE 1.61, arousal RMSE 1.88; classification (binary): affect 69%, valence 81.7%, arousal: 67.5% | |||||||
| [40], 2016 | happy, angry, neutral | yes | 59 (27/32) | x | SVM (general) | anger(binary): 90.03% (wrist), 90.31% (ankle); happiness(binary): 89.76% (wrist), 87.65% (ankle); happy/angry: 87.1% (ankle); happy/angry/neutral: 85/78/78% (ankle) | ||||||||
| [41], 2016 | positive, negative, neutral | yes | 24 (12/12) | 21–25 | x | random forest | 85.1% (personalised), 78.8% (general) | |||||||
| [63], 2016 | stress (3 levels) | no | 30 (18/12) | 37.46 | x | naive Bayes, decision tree (general, personalised, based on similar users data) | general: 52% (naive Bayes), 50% (decision tree); personalised 71%; based on similar users: 60% (naive Bayes), 55% (decision tree) | |||||||
| [72], 2015 | sad, happy, angry, content, energetic, tense | no | 10 (6/4) | 20-40 | x | x | x | x | transfer learning (general) + SVM (personalised) | 75% (general), accuracy rises after a few days due to validation and re-training | ||||
| [82], 2015 | (1) valence, arousal (5 levels); (2) happiness, sadness, fear, anger, neutral | no | 12 (7/5) | x | x | x | x | x | x | x | random forest | general: 65.91% (discrete emotions), 72.73% (pleasure); personalised (one user only): 70.00% (discrete emotions), 79.78% (pleasure) | ||
| [53], 2015 | boredom (binary) | no | 54 | 21–57 | x | x | random forest (general) | 82.9% | ||||||
| [50], 2015 | mood (5 levels) | no | 9 (5/4) | 21–27 | x | x | x | naive Bayes (personalised) | 76% | |||||
| [39], 2014 | stressed, excited, neutral | no | 20 (15/5) | 21–30 | x | decision trees (multiclass) | 71% (cross validation), 58% (test set) | |||||||
| [76,116], 2014 | stress (binary) | no | 117 | x | x | random forest, GBM—generalised boosted model (general) | 72.51, 72.28% (random forest)%, 71.35% GBM | |||||||
| [115], 2013 | happiness (3 levels) | no | 117 | x | x | random forest (general) | 80.81% | |||||||
| [61], 2013 | valence, arousal (5 levels) | no | 32 (21/11) | 18–29 | x | x | multi-linear regression (personalised, general, hybrid) | 93% personalised, 66% (general), 75% (hybrid, after 30 days) | ||||||
| [51], 2012 | happiness, surprise, anger, disgust, sadness, fear, neutral | no | 1 (1/0) | 30 | x | x | x | x | x | Bayesian network (multiclass) | 67.52% | |||
| [58], 2012 | displeasure, tiredness, tensity (5 levels) | no | 15 | x | x | x | factor graph (personalised) | 52.58% (displeasure), 45.36% (tiredness), 47.42% (tensity) | ||||||
| [86], 2012 | excited, relaxed, frustrated, bored; arousal, valence (2 levels) | no | 15 (9/6) | 18-40 | x | SVM (general), discriminant analysis (personalised) | general: 88.7% (arousal), 86% (valence), 77% (4 emotions); personalised: 89% (arousal), 83% (valence), 76.4% (4 emotions) | |||||||
| [70], 2012 | positive, negative, neutral | no | 30 | x | x | dynamic continuous factor graph | F-measure 53.31% | |||||||
| [37], 2012 | stress (binary) | yes | 19 | 20-57 | x | x | x | decision tree (general) | 78% | |||||
| Reference, Year | Input Channel | Features |
| [49], 2020 | Touchscreen | heat maps of pressure, down-down speed, up-down speed |
| [48], 2020 | Accelerometer Gyroscope | features calculated on the basis of x, y and z sequences: mean, median, standard deviation, max, min, index of max/min, skewness, kurtosis, entropy, root mean square, energy, power, mean absolute deviation, interquartile range, signal magnitude area, zero crossing rate, slope sign change, waveform length; FFT coefficients and their, mean, max, magnitude, energy, band power of signal; sum of squares and sum of absolute values of wavelet transform coefficients; additionally step length and step duration calculated on the basis of accelerometer x series |
| [99], 2020 | Touchscreen | features describing swipes: length, speed, relation between distance and displacement, pressure variance, touch area variance, direction, variance of the angle between points and axes; features calculated for all pairs of consecutive points or all pairs between the starting/ending point of a swipe and any other extracted for eight predefined directions: percentage of touches in each direction, variance of the direction of the vector determined by the mentioned pairs of points |
| [112], 2019; [80], 2020 | Accelerometer | shaking time, severity of shaking, times of shaking, time of portrait orientation, landscape orientation, times of exchanging orientation, step count, difference between average and largest speed |
| Gyroscope | rotation time, mean angular velocity | |
| GPS | entropy | |
| Light | state (no use/indoor/outdoor) | |
| Other | network speed, strength of signal | |
| [43], 2019 | Touchscreen | touch area, maximum pressure, pressure, hold-time, distance between start and end position, speed, number of touches outside/inside keyboard layout, number of spacebar/send/change language/change number, duration since last press |
| Accelerometer | values of x, y, z | |
| Gyroscope | values of x, y, z | |
| Other | response time | |
| [46], 2019 | Touchscreen | typing speed, backspace frequency, max number of characters without pressing delete for a second, touch count |
| Accelerometer | device shake frequency | |
| [75], 2019 | GPS | mean an standard deviation of latitude and longitude |
| Other | average distance from work, distance from home, time of the day, day of week | |
| [109], 2019 | Touchscreen | sequence of vectors containing: intertap duration, alphanumeric (1/0), special characters (1/0), backspace (1/0), touch pressure, touch speed, touch time |
| [78], 2019; [55], 2019 | Touchscreen | see[87] |
| Other | last ESM response | |
| [79], 2018 | Touchscreen | mean ITD (intertap distance), mean nonoutlier ITD, i-th percentiles of ITD (i = 25, 50, 75, 90), mean and standard deviation of word completion time, session duration, sum and number of ITDs greater than 30s, session duration-pause time, session duration/number of characters, session duration/number of words, percentage of backspace, percentage of nonalphanumeric characters |
| [69], 2018, solution 1 | Touchscreen | tap features: mean pressure, size, movement; scroll/swipe features: mean pressure, size, delta, length; typing features: pressure, tap size, tap movement, tap duration, pressure/size, tap distance, wrong words/all words, back/all digits |
| [69], 2018, solution 2 | Touchscreen | number of touches; minimum, maximum, range, mean, median, variance, standard deviation of touch intervals; session duration |
| Accelerometer | scores for various activities (Google API) | |
| Other | frequency and percentage of time of different application categories, screen features (duration and number of events for differents states: on, off, unlocked) | |
| [60], 2018 | Accelerometer | mean and variance of x,y,z; step count |
| Gyroscope | mean and variance of x,y,z | |
| Magnetometer | mean and variance of x,y,z | |
| GPS | longitude, latitude, altitude | |
| Light | mean, variance, dark ratio, bright ratio, dark to bright ratio | |
| Other | application usage (duration for various categories), screen (on ratio, off ratio, Sleeping Duration, Usage Amount), call frequency and duration for each contact person, sms frequency of each contact person, microphone (mean, variance, noise ratio, silence ratio, noise to silence ratio), WiFi (frequency of the top N occurred IDs) | |
| [45], 2018 | Touchscreen | touch pressure, touch duration, time between subsequent touches |
| [88], 2017 | Touchscreen | see[87] |
| Other | working hour indicator, persistent emotion | |
| [87], 2017 | Touchscreen | mean session ITD (intertap distance), refined mean session ITD, percentage of special characters (nonalphanumeric), number of backspace or delete, session duration, session text length |
| [108], 2017 | Touchscreen | typing time, typing speed, key press count, touch count, backspace count |
| Accelerometer | device shake count | |
| GPS | latitude, longitude | |
| Light | illuminance | |
| Other | time zone, discomfort index, weather attributes from OpenWeatherMap API | |
| [67], 2017 | Accelerometer | DTW distance between the accelerometer readings during the observation interval and the average readings |
| Other | DTW distance between microphone readings during the observation interval and the average microphone readings, difference between the number of messages (calls) exchanged during the observation intervals and the average number of messages (calls) | |
| [44], 2017 | Touchscreen | number of touch events (down, up, move), average pressure of events |
| [74], 2017 | Touchscreen | average time delay between typed letters, number of backspaces, number of letters |
| Accelerometer | average acceleration | |
| [73], 2016 | Accelerometer | mean, standard deviation, standard deviation of mean peak, mean jerk, mean step duration, skewness, kurtosis, standard deviation of power spectral density |
| [64], 2016 | Accelerometer | percentage of high activity periods |
| Other | location changes (on the basis of WiFi access points, google map locations, cellular towers), conversation time (microphone), parameters form call and sms logs, number of applications used and duration for selected categories of applications | |
| [68], 2016 | Touchscreen | finger speed, speed normalised by task difficulty, precision precision normalised by task difficulty, pressure, pressure decline, difference in angle between fingers and centroid at the beginning and end of interaction, angle between horizontal line and line intersecting centroid and tap, approach direction, tap movement, distance between two fingers |
| Accelerometer | horizontal and vertical acceleration, difference in aggregated acceleration | |
| Gyroscope | rotation around x, y, z axis, difference in aggregated rotation | |
| [40], 2016 | Accelerometer | standard deviation, kurtosis, skewness, correlation coefficient (for every two axes), FFT coefficients, power spectral density |
| [41], 2016 | Touchscreen | features describing strokes: mean, median, max, min, variance of length, time, pressure and speed of strokes |
| [63], 2016 | Accelerometer | for x, y, z: mean, std, max, min, median, range, absolute value, variance; variance sum, magnitude, signal magnitude area, root mean squared, curve length, non linear energy, entropy, energy, mean energy, standard deviation of energy, DFT (Discrete Fourier Transform), peak magnitude, peak magnitude frequency, peak power, peak power frequency, magnitude entropy, power entropy (for each parameter min, max and mean calculated on the basis of 2 h period) |
| [72], 2015 | Accelerometer | series of state values (run/walk/silence) |
| GPS | visited locations, time at locations | |
| Bluetooth | number of Bluetooth IDs, IDs seen for more than a predefined time, maximum time for an ID seen | |
| Other | parameters from call and sms logs, number of Wifi signals, content features extracted from text and emoticons | |
| [82], 2015 | Accelerometer Gyroscope Magnetometer | for each axis: maximum, minimum, mean, standard deviation, wave number, crest mean, trough mean, the maximum difference between the crest and trough, the minimum difference between the crest and trough; additionally periods of steady/slow/fast on the basis of accelerometer |
| GPS | number of locations, entropy (time in different locations) | |
| Bluetooth | number of connections | |
| Light | proportion of time for not used, used indoors, used outdoors | |
| Other | call and message log parameters, number of WiFi connections, application usage time, time of light and dark screen, times of unlocking screen, number of photos, proportion of time in various modes | |
| [53], 2015 | Light | ambient light |
| Other | connected to headphone or bluetooth, charging, day of week, hour, screen covered or not, ringer mode, average battery drain, battery change during the last session, bytes received/transmitted, time spent in selected applications or sessions, number of notifications, name/category of app that created last notification, number of apps used, number of phone unlocks, time since user last opened notification centre, time since last phone unlock, screen orientation changes, category/name of app in focus prior to probe and name of the previous app, name/category of app used most often | |
| [50], 2015 | Accelerometer | activity from Google Activity Recognition Api |
| Light | ambient light | |
| Other | noise, message history, call history, connectivity type (WiFi, mobile, none), calendar (number and type of appointments), daytime, day type (weekday/weekend), location (cell ID) | |
| [39], 2014 | Accelerometer | raw values of x, y, z |
| [115], 2013;[76], 2014; [116], 2014 | Bluetooth | general proximity information, diversity (entropy of proximity contacts, the ratio of unique contacts to interactions, the number of unique contacts), regularity (mean and variance of time elapsed between two interaction events) |
| Other | general phone usage (number of outgoing, incoming and missed calls, number of sent and received sms), diversity (entropy of contacts, unique contacts to interactions ratio, number of unique contacts), regularity (average and variance of time elapsed between two calls or two sms or call and sms); second order features (selected statistics calculated for each basic feature); weather parameters (mean temperature, pressure, total precipitation, humidity, visibility, wind speed metrics) | |
| [61], 2013 | GPS | number of visits in selected locations |
| Other | emails (number of emails, number of characters), sms (number of messages, number of characters), calls (number of calls, call duration); number of visits on website domains; application usage (categories, number of launches, duration) | |
| [51], 2012 | Touchscreen | typing speed, maximum text length, erased text length, touch count, long touch count, frequency of backspace, enter and special symbol |
| Accelerometer | device shake count | |
| GPS | location (home, work, commute, entertain etc.) | |
| Light | illuminance | |
| Other | time, weather, discomfort index calculated as 0.4(Ta+Tw)+15, where Ta is dry-bulb temp., Tw is wet-bulb temp. | |
| [58], 2012 | Accelerometer | activity (proportion of sitting, walking, standing, running), micromotion (picking a phone and doing nothing for longer than a few seconds) |
| GPS | location | |
| Other | communication frequency (sms, calls) | |
| [86], 2012 | Touchscreen | features describing strokes: mean, median, maximum and minimum values of the length, speed, directionality index (distance between the first and the last point of a stroke), contact area |
| [70], 2012 | GPS | location (region id) |
| Other | sms text, calling log | |
| [37], 2012 | Touchscreen | mean and maximum intensity of touch, accuracy of touches-relation between the touches on active versus passive areas |
| Accelerometer | acceleration | |
| Other | amount of movement (taken from camera) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kołakowska, A.; Szwoch, W.; Szwoch, M. A Review of Emotion Recognition Methods Based on Data Acquired via Smartphone Sensors. Sensors 2020, 20, 6367. https://doi.org/10.3390/s20216367
Kołakowska A, Szwoch W, Szwoch M. A Review of Emotion Recognition Methods Based on Data Acquired via Smartphone Sensors. Sensors. 2020; 20(21):6367. https://doi.org/10.3390/s20216367
Chicago/Turabian StyleKołakowska, Agata, Wioleta Szwoch, and Mariusz Szwoch. 2020. "A Review of Emotion Recognition Methods Based on Data Acquired via Smartphone Sensors" Sensors 20, no. 21: 6367. https://doi.org/10.3390/s20216367
APA StyleKołakowska, A., Szwoch, W., & Szwoch, M. (2020). A Review of Emotion Recognition Methods Based on Data Acquired via Smartphone Sensors. Sensors, 20(21), 6367. https://doi.org/10.3390/s20216367