On-Body Sensor Positions Hierarchical Classification


Abstract
1. Introduction
- We address the importance of feature selection for sensor position classification. Good features have a high impact on the final performance of a model and vice versa. However, selecting a list of features for a classification task is complicated because of the large number of possibilities in combination. Therefore, the features should be selected following a certain procedure for not only reducing dimensionality but also increasing the final performance.
- This research investigates the impact of fractal dimension (FD) as a feature for classification. The FD is known as a feature that highlights the chaotic characteristic of data. In this paper, the usefulness of FD has been proven for discriminating different signals.
- We also consider the impact of data scaling and feature scaling in this research. Performing good prepossessing techniques is a prerequisite for great and interpretive results.
- We perform optimization of classifiers for each local discrimination. These discriminations provide a better solution for practical applications. For example, the classifications of arm- and hand- sides are necessary for human–computer interaction using arm movements.
2. Related Works
3. Methodology
3.1. Experimental Setups
3.1.1. Inertial Measurement Unit
3.1.2. Motion Planes and Directions
3.1.3. Target Positions
3.1.4. Data Acquisition
3.2. Preprocessing
3.2.1. Moving Average
3.2.2. Offset Removal
3.2.3. Min-Max Normalization
3.3. Feature Computation
3.3.1. Sliding Window
3.3.2. Signal Characteristic Measures
- Entropy: Entropy refers to the disordered behavior of a system and originates from the second law of thermodynamics. The entropy of a system is always increasing as the system evolves and becomes constant when the system reaches its equilibrium. However, when the entropy of a system decreases, that means the system is affected by external factors. The Shannon entropy expresses the average information content when the value of the random variables is unknown.where m is the number of bins of the histogram and p is the probability mass function of ith bin.The data from motion sensors is a continuous signal, which needs to be converted into a histogram for calculating Shannon entropy. For each window, the entropy is calculated using different bin sizes of the histogram such as 10, 20, 30, 40, 50 and denoted as ‘entro10’, ‘entro20’, ‘entro30’, ‘entro40’, ‘entro50’, respectively.
- Fractal Dimension (FD): Fractal is an object or a signal that has repeating patterns and a similar display at both the micro-scale and the macro-scale. A FD is used to measure the fractal characteristics and considered as the number of axes needed to represent an object or a signal. In Euclidean space, a line has one dimension while a square has two dimensions. However, a curved line in a plane is neither one- nor two-dimensional because it is not a line and does not move in two directions. The FD of a curved line is an integer between 1 and 2. If the FD is approaching 1, it means that the curved line is becoming a straight line. In contrast, if FD is approaching 2, it illustrates the ability to cover a square of the curved line. Higuchi’s algorithm [42] is often used to estimate the FD. Although this algorithm sensitive to noise, it yields the most accurate estimation for FD [43].
3.4. Feature Selection
3.5. Classification
- Logistic Regression (LR): The LR is a machine learning classification algorithm that is used to predict the probability of a categorical dependent variable. To generate probabilities, logistic regression uses a sigmoid function that gives outputs between 0 and 1 for all values. In multi-class classification, the algorithm uses the one-vs-rest scheme.
- k-Nearest Neighbor (kNN): The kNN is a machine learning approach that uses distance measures between data for classification. Particularly, given a new sample, the approach takes the major votes of the k closest samples from the training set to assign a class to the unknown sample. The parameters that affect the algorithm performance are the number of nearest neighbors, the weights of each value and the distance calculation methods. The number of nearest neighbors is varied from one to ten samples. The weight is alternated between ‘uniform’ and ‘distance’: ‘uniform’ means that all samples are weighted equally and ‘distance’ means that the sample weights are calculated to be the inverse of their distances. The parameter ‘p’ has two values 1 and 2, which are equivalent Manhattan distance and Euclidean distance, correspondingly. Additionally, the ‘algorithm’ parameter refers to computing methods of the nearest neighbors and has several options such as ‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’.
- Decision Tree (DT): The DT is a predictive model based on a set of hierarchical rules to generate outputs. It is a common approach for classification because it has high interpretability for human understanding.
- Support Vector Machine (SVM): The SVM classifier is one of the most popular machine learning algorithms used in classifications. It is based on finding a hyperplane that best divides a dataset into two classes. The SVM classifier has the key parameters of ‘C’, ‘gamma’ and ‘kernel’. The parameter ‘C’ indicates the large margin for splitting the data into two parts, and vice versa. The parameter ‘gamma’ defines how far the influence of a single training example reaches. In this experiment, both the ‘C’ and ‘gamma’ parameters are varied from 0.1 to 5 in steps of 0.1. The parameter ‘kernel’ has several options such as ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’ corresponding to different activation functions.
- Extreme Gradient Boosting (XGB): The XGB classifier is a highly flexible and versatile technique that works through most classifications. In the classification area, weak and strong classifiers refer to the correlations of outputs and targets. Boosting is an ensemble method that seeks to create a strong classifier based on weak classifiers. By adding classifiers on top of each other iteratively, the next classifier can correct the errors of the previous one. The process is repeated until the training data is accurately predicted. This approach minimizes the loss when adding the latest classifier, and the models are updated using gradient descent, leading to the name “gradient boosting”.
3.6. Validation
3.7. Hierarchical Classification
3.7.1. Node Classification
3.7.2. Body-Segment top-down Approach
3.7.3. Body-Side top-down Approach
4. Results
4.1. Body Part Classification
4.2. Body Segment Classification
4.3. Body Side Classification
4.4. Tuning Parameters of Classifiers
4.5. Hierarchical Classification
5. Discussions
6. Conclusions
- Together with data scaling, features scaling should be executed to normalize selected features for better classification results.
- For representing the chaotic characteristic of data, FD has outperformed entropy feature in most of particularly classifications.
- It is possible for several classifiers to have same performance. Nevertheless, these classifiers requires a different amount of time for processing data. Therefore, the system performance and processing time should be examined together for a robust implementation.
- Local information can be used to solve specific problems: for example, discriminating between arm-side and thigh-side positions gives a better performance with F1-scores of 0.99 and 0.88, respectively. This indicates that the popular features of well preprocessed data are enough to discriminate among these classifications.
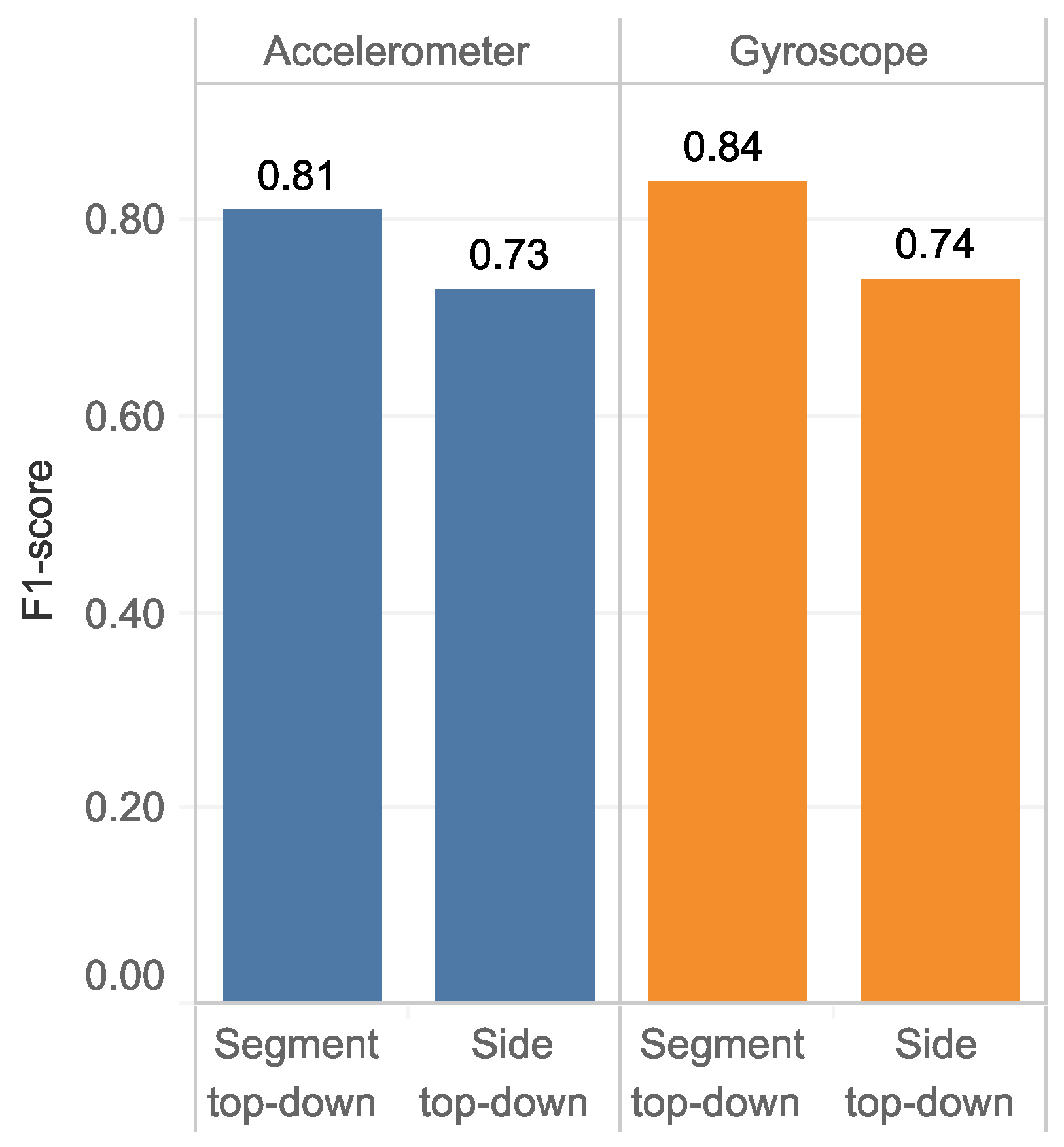
- It was found that, the body-side top-down approaches have a relative performance for both the accelerometer (0.73) and the gyroscope (0.74) for the 6-class classification. However, in body-segment top-down approach, the average F1-score increases to 0.81 and 0.84 for the accelerometer and the gyroscope, respectively. However, since the gyroscope is energy-hunger than the accelerometer [21], for long-time operation, we recommend using the accelerometer.
Author Contributions
Funding
Conflicts of Interest
References
- Shi, D.; Wang, R.; Wu, Y.; Mo, X.; Wei, J. A novel orientation- and location-independent activity recognition method. Pers. Ubiquitous Comput. 2017, 21, 427–441. [Google Scholar] [CrossRef]
- Godfrey, A. Wearables for independent living in older adults: Gait and falls. Maturitas 2017, 100, 16–26. [Google Scholar] [CrossRef] [PubMed]
- Morales, J.; Akopian, D. Physical activity recognition by smartphones, a survey. Biocybern. Biomed. Eng. 2017, 37, 388–400. [Google Scholar] [CrossRef]
- Pannurat, N.; Thiemjarus, S.; Nantajeewarawat, E.; Anantavrasilp, I. Analysis of Optimal Sensor Positions for Activity Classification and Application on a Different Data Collection Scenario. Sensors 2017, 17, 774. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. A Survey of Online Activity Recognition Using Mobile Phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.C.; Hsu, Y.L. A review of accelerometry-based wearable motion detectors for physical activity monitoring. Sensors 2010, 10, 7772–7788. [Google Scholar] [CrossRef] [PubMed]
- Tunca, C.; Pehlivan, N.; Ak, N.; Arnrich, B.; Salur, G.; Ersoy, C. Inertial sensor-based robust gait analysis in non-hospital settings for neurological disorders. Sensors 2017, 17, 825. [Google Scholar] [CrossRef] [PubMed]
- Samé, A.; Oukhellou, L.; Kong, K.; Huo, W. Recognition of gait cycle phases using wearable sensors. Robot. Auton. Syst. 2016, 75, 50–59. [Google Scholar]
- Arora, S.; Venkataraman, V.; Zhan, A.; Donohue, S.; Biglan, K.M.; Dorsey, E.R.; Little, M.A. Detecting and monitoring the symptoms of Parkinson’s disease using smartphones: A pilot study. Parkinsonism Relat. Disord. 2015, 21, 650–653. [Google Scholar] [CrossRef] [PubMed]
- Cornet, V.P.; Holden, R.J. Systematic review of smartphone-based passive sensing for health and wellbeing. J. Biomed. Inform. 2017, 77, 120–132. [Google Scholar] [CrossRef] [PubMed]
- Jalloul, N.; Porée, F.; Viardot, G.; L’Hostis, P.; Carrault, G. Activity Recognition Using Multiple Inertial Measurement Units. IRBM 2016, 37, 180–186. [Google Scholar] [CrossRef]
- Garcia-Ceja, E.; Brena, R. Long-term activity recognition from accelerometer data. Procedia Technol. 2013, 7, 248–256. [Google Scholar] [CrossRef]
- Wang, J.; Chen, R.; Sun, X.; She, M.F.; Wu, Y. Recognizing human daily activities from accelerometer signal. Procedia Eng. 2011, 15, 1780–1786. [Google Scholar] [CrossRef]
- Banos, O.; Toth, M.A.; Damas, M.; Pomares, H.; Rojas, I. Dealing with the effects of sensor displacement in wearable activity recognition. Sensors 2014, 14, 9995–10023. [Google Scholar] [CrossRef] [PubMed]
- Reddy, S.; Mun, M.; Burke, J.; Estrin, D.; Hansen, M.; Srivastava, M. Using mobile phones to determine transportation modes. ACM Trans. Sens. Netw. (TOSN) 2010, 6, 13. [Google Scholar] [CrossRef]
- Siirtola, P.; Röning, J. Ready-to-use activity recognition for smartphones. In Proceedings of the 2013 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Singapore, 16–19 April 2013; pp. 59–64. [Google Scholar]
- Bergamini, E.; Ligorio, G.; Summa, A.; Vannozzi, G.; Cappozzo, A.; Sabatini, A.M. Estimating orientation using magnetic and inertial sensors and different sensor fusion approaches: Accuracy assessment in manual and locomotion tasks. Sensors 2014, 14, 18625–18649. [Google Scholar] [CrossRef] [PubMed]
- Seel, T.; Ruppin, S. Eliminating the effect of magnetic disturbances on the inclination estimates of inertial sensors. IFAC-PapersOnLine 2017, 50, 8798–8803. [Google Scholar] [CrossRef]
- Madgwick, S.O.; Harrison, A.J.; Vaidyanathan, R. Estimation of IMU and MARG orientation using a gradient descent algorithm. In Proceedings of the 2011 IEEE International Conference on Rehabilitation Robotics (ICORR), Zurich, Switzerland, 29 June–1 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–7. [Google Scholar]
- Lambrecht, S.; Romero, J.; Benito-León, J.; Rocon, E.; Pons, J. Task independent identification of sensor location on upper limb from orientation data. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Chicago, IL, USA, 26–30 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 6627–6630. [Google Scholar]
- Fujinami, K. On-body smartphone localization with an accelerometer. Information 2016, 7. [Google Scholar] [CrossRef]
- Mannini, A.; Sabatini, A.M.; Intille, S.S. Accelerometry-based recognition of the placement sites of a wearable sensor. Pervasive Mobile Comput. 2015, 21, 62–74. [Google Scholar] [CrossRef] [PubMed]
- Incel, O.D. Analysis of movement, orientation and rotation-based sensing for phone placement recognition. Sensors 2015, 15, 25474–25506. [Google Scholar] [CrossRef] [PubMed]
- Alanezi, K.; Mishra, S. Design, implementation and evaluation of a smartphone position discovery service for accurate context sensing. Comput. Electr. Eng. 2015, 44, 307–323. [Google Scholar] [CrossRef]
- Amini, N.; Sarrafzadeh, M.; Vahdatpour, A.; Xu, W. Accelerometer-based on-body sensor localization for health and medical monitoring applications. Pervasive Mobile Comput. 2011, 7, 746–760. [Google Scholar] [CrossRef] [PubMed]
- Kunze, K.; Lukowicz, P. Sensor placement variations in wearable activity recognition. IEEE Pervasive Comput. 2014, 13, 32–41. [Google Scholar] [CrossRef]
- Weenk, D.; Van Beijnum, B.J.F.; Baten, C.T.; Hermens, H.J.; Veltink, P.H. Automatic identification of inertial sensor placement on human body segments during walking. J. NeuroEng. Rehabil. 2013, 10, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Noitom, Neuron Motion Capture System. Available online: https://neuronmocap.com/ (accessed on 17 September 2018).
- Whittle, M.W. Gait analysis: An introduction. Library 2002, 3, 1–220. [Google Scholar]
- Redmayne, M. Where’s your phone? A survey of where women aged 15–40 carry their smartphone and related risk perception: A survey and pilot study. PLoS ONE 2017, 12, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Birch, I.; Vernon, W.; Walker, J.; Young, M. Terminology and forensic gait analysis. Sci. Justice 2015, 55, 279–284. [Google Scholar] [CrossRef] [PubMed]
- Armstrong, C.; Oldham, J. A comparison of dominant and non-dominant hand strengths. J. Hand Surg. 1999, 24, 421–425. [Google Scholar] [CrossRef] [PubMed]
- Arjunan, S.P.; Kumar, D.; Aliahmad, B. Fractals: Applications in Biological Signalling and Image Processing; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Al-Ghannam, R.; Al-Dossari, H. Prayer activity monitoring and recognition using acceleration features with mobile phone. Arab. J. Sci. Eng. 2016, 41, 4967–4979. [Google Scholar] [CrossRef]
- Similä, H.; Immonen, M.; Ermes, M. Accelerometry-based assessment and detection of early signs of balance deficits. Comput. Biol. Med. 2017, 85, 25–32. [Google Scholar] [CrossRef] [PubMed]
- Cao, L.; Wang, Y.; Zhang, B.; Jin, Q.; Vasilakos, A.V. GCHAR: An efficient Group-based Context—Aware human activity recognition on smartphone. J. Parallel Distrib. Comput. 2018, 118, 67–80. [Google Scholar] [CrossRef]
- Little, C.; Lee, J.B.; James, D.A.; Davison, K. An evaluation of inertial sensor technology in the discrimination of human gait. J. Sports Sci. 2013, 31, 1312–1318. [Google Scholar] [CrossRef] [PubMed]
- Takeda, R.; Lisco, G.; Fujisawa, T.; Gastaldi, L.; Tohyama, H.; Tadano, S. Drift removal for improving the accuracy of gait parameters using wearable sensor systems. Sensors 2014, 14, 23230–23247. [Google Scholar] [CrossRef] [PubMed]
- Ilyas, M.; Cho, K.; Baeg, S.H.; Park, S. Drift reduction in pedestrian navigation system by exploiting motion constraints and magnetic field. Sensors 2016, 16, 1455. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window Size Impact in Human Activity Recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [PubMed]
- Janidarmian, M.; Roshan Fekr, A.; Radecka, K.; Zilic, Z.; Ross, L. Analysis of Motion Patterns for Recognition of Human Activities. In Proceedings of the 5th EAI International Conference on Wireless Mobile Communication and Healthcare—“Transforming healthcare through innovations in mobile and wireless technologies”, London, UK, 14–16 October 2015; pp. 1–5. [Google Scholar]
- Higuchi, T. Approach to an irregular time series on the basis of the fractal theory. Phys. D Nonlinear Phenom. 1988, 31, 277–283. [Google Scholar] [CrossRef]
- Raghavendra, B.; Dutt, D.N. A note on fractal dimensions of biomedical waveforms. Comput. Biol. Med. 2009, 39, 1006–1012. [Google Scholar] [CrossRef] [PubMed]
- Ortiz-Catalan, M. Cardinality as a highly descriptive feature in myoelectric pattern recognition for decoding motor volition. Front. Neurosci. 2015, 9, 416. [Google Scholar] [CrossRef] [PubMed]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- González, S.; Sedano, J.; Villar, J.R.; Corchado, E.; Herrero, Á.; Baruque, B. Features and models for human activity recognition. Neurocomputing 2015, 167, 52–60. [Google Scholar] [CrossRef]
- Silla, C.N.; Freitas, A.A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2011, 22, 31–72. [Google Scholar] [CrossRef]
- Cutti, A.G.; Ferrari, A.; Garofalo, P.; Raggi, M.; Cappello, A.; Ferrari, A. ‘Outwalk’: A protocol for clinical gait analysis based on inertial and magnetic sensors. Med. Biol. Eng. Comput. 2010, 48, 17–25. [Google Scholar] [CrossRef] [PubMed]
- Ferrari, A.; Cutti, A.G.; Garofalo, P.; Raggi, M.; Heijboer, M.; Cappello, A.; Davalli, A. First in vivo assessment of “Outwalk”: A novel protocol for clinical gait analysis based on inertial and magnetic sensors. Med. Biol. Eng. Comput. 2010, 48, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Rowlands, A.V.; Olds, T.S.; Bakrania, K.; Stanley, R.M.; Parfitt, G.; Eston, R.G.; Yates, T.; Fraysse, F. Accelerometer wear-site detection: When one site does not suit all, all of the time. J. Sci. Med. Sport 2017, 20, 368–372. [Google Scholar] [CrossRef] [PubMed]
- Graurock, D.; Schauer, T.; Seel, T. Automatic pairing of inertial sensors to lower limb segments—A plug-and-play approach. Curr. Dir. Biomed. Eng. 2016, 2, 715–718. [Google Scholar] [CrossRef]
- Zimmermann, T.; Taetz, B.; Bleser, G. IMU-to-Segment Assignment and Orientation Alignment for the Lower Body Using Deep Learning. Sensors 2018, 18, 302. [Google Scholar] [CrossRef] [PubMed]
- Seel, T.; Graurock, D.; Schauer, T. Realtime assessment of foot orientation by accelerometers and gyroscopes. Curr. Dir. Biomed. Eng. 2015, 1, 446–469. [Google Scholar] [CrossRef]
- Salehi, S.; Bleser, G.; Reiss, A.; Stricker, D. Body-IMU autocalibration for inertial hip and knee joint tracking. In Proceedings of the 10th EAI International Conference on Body Area Networks. ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), Sydney, Australia, 28–30 September 2015; pp. 51–57. [Google Scholar]
- Laidig, D.; Müller, P.; Seel, T. Automatic anatomical calibration for IMU-based elbow angle measurement in disturbed magnetic fields. Curr. Dir. Biomed. Eng. 2017, 3, 167–170. [Google Scholar] [CrossRef]
- Young, A.J.; Simon, A.M.; Fey, N.P.; Hargrove, L.J. Intent recognition in a powered lower limb prosthesis using time history information. Ann. Biomed. Eng. 2014, 42, 631–641. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Zhang, F.; Hargrove, L.J.; Dou, Z.; Rogers, D.R.; Englehart, K.B. Continuous locomotion-mode identification for prosthetic legs based on neuromuscular—Mechanical fusion. IEEE Trans. Biomed. Eng. 2011, 58, 2867–2875. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Hernandez, U.; Dehghani-Sanij, A.A. Adaptive Bayesian inference system for recognition of walking activities and prediction of gait events using wearable sensors. Neural Netw. 2018, 102, 107–119. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Hernandez, U.; Mahmood, I.; Dehghani-Sanij, A.A. Simultaneous Bayesian recognition of locomotion and gait phases with wearable sensors. IEEE Sens. J. 2017, 18, 1282–1290. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Target Positions (Total Number) | Activities (Total Number) | Sensor(s) | Subjects | Feature Selection | Classifier(s) | Evaluation | Performance |
|---|---|---|---|---|---|---|---|---|
| [1] | Chest, coat pocket, thigh pocket, and hand (4) | Walking, standing and other activities (6) | Linear Accelerometer Accelerometer Gravity Gyroscope | 15 | 3D to 2D projection | DT SVM NB | n-fold | 93.76 (DT) 94.22(SVM) 84.71(NB) |
| [21] | Neck, chest, jacket, trouser front/back, 4 types of bags (9) Merged: “trousers”, “bags” (5) | Walking, standing and other activities (7) | Accelerometer | 20 | Correlation-based | DT NB SVM MLP | LOSO n-fold | 80.5 99.9 85.9 (merged) |
| [22] | Ankle, thigh, hip, upper arm, wrist (5) Ankle, hip, wrist (3) Ankle, wrist (2) | Walking, standing and other activities (28) | Accelerometer | 33 | none | SVM | LOSO | 81.0 (5-class) 92.4 (3-class) 99.2 (2-class) |
| [23] | Dataset 1: backpack, messenger bag, jacket pocket, trouser pocket (4) | Walking, standing and other activities (5) | Linear Accelerometer Accelerometer Gravity | 10 | WEKA machine learning tool-kits | kNN DT RF MLP | LOSO | 76.0 (Dataset1) |
| Dataset 2: trouser pocket, upper arm, belt, wrist (4) | Walking, standing and other activities (6) | Linear Accelerometer Accelerometer Gravity Gyroscope Magnetic | 10 | 93.0 (Dataset 2) | ||||
| Dataset 3: backpack, hand, trouser pocket (3) | Walking, standing and other activities (9) | Accelerometer | 15 | 88.0 (Dataset 3) | ||||
| [24] | Hand holding, talking on phone, watching a video, pants pocket, hip pocket, jacket pocket and on-table (7) | Walking, standing and other activities (3) | Accelerometer Gyroscope Microphone Magnetic | 10 | none | DT NB MLP LR | n-fold | 88.5 (Accelerometer) 74.0 (Gyroscope) 89.3 (fused) |
| [25] | Head, upper arm, forearm, waist, thigh, shin (6) | Walking and non-walking (2) | Accelerometer | 25 | none | SVM | n-fold | 89.0 |
| [26] | Head, torso, wrist, front pocket, back pocket (5) | Walking and non-walking (2) | Accelerometer | 6 | none | HMM | n-fold | 73.5 |
| [27] | Pelvis, sternum, head, right shoulder, right upper arm, right forearm, right hand, left shoulder, left upper arm, left forearm, left hand, right upper leg, right lower leg, right foot, left upper leg, left lower leg and left foot (17) | Walking and non-walking (2) | Accelerometer Gyroscope | 10 | none | DT | n-fold | 97.5 |
| Feature | References | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| [21] | [1] | [22] | [23] | [24] | [25] | [26] | [27] | This Work | |
| Mean | x | x | x | x | x | x | x | ||
| Standard deviation | x | x | x | x | x | x | x | ||
| Variance | x | x | x | x | |||||
| Minimum | x | x | x | x | |||||
| Maximum | x | x | x | x | |||||
| Range | x | ||||||||
| Percentile | x | x | |||||||
| Inter quartile range | x | ||||||||
| Root-mean-square | x | x | |||||||
| Number of peaks | x | x | |||||||
| Zero-crossing rate | x | x | |||||||
| Skewness | x | ||||||||
| Kurtosis | x | ||||||||
| Entropy | x | ||||||||
| Fractal dimension | x | ||||||||
| Energy | x | x | |||||||
| Clasification | Sensor | LR | kNN | SVM | DT | XGB | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| D | T | D | T | D | T | D | T | D | T | ||
| Body-segment | A | 0.86 | 0.88 | 0.80 | 0.81 | 0.86 | 0.88 | 0.84 | 0.76 | 0.88 | 0.89 |
| G | 0.89 | 0.90 | 0.96 | 0.96 | 0.93 | 0.96 | 0.89 | 0.81 | 0.95 | 0.96 | |
| Body-side | A | 0.80 | 0.80 | 0.64 | 0.66 | 0.79 | 0.80 | 0.82 | 0.78 | 0.68 | 0.68 |
| G | 0.84 | 0.84 | 0.86 | 0.86 | 0.81 | 0.83 | 0.83 | 0.81 | 0.81 | 0.81 | |
| Clasification | Sensor | LR | kNN | SVM | DT | XGB | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| D | T | D | T | D | T | D | T | D | T | ||
| Left-segment | A | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 0.92 | 0.93 | 0.96 | 0.96 |
| G | 0.95 | 0.96 | 0.98 | 0.99 | 0.98 | 1.00 | 0.95 | 0.93 | 0.95 | 0.96 | |
| Right-segment | A | 0.95 | 0.95 | 0.93 | 0.93 | 0.93 | 0.94 | 0.84 | 0.86 | 0.90 | 0.91 |
| G | 0.97 | 0.97 | 0.95 | 0.95 | 0.97 | 0.97 | 0.89 | 0.78 | 0.95 | 0.97 | |
| Clasification | Sensor | LR | kNN | SVM | DT | XGB | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| D | T | D | T | D | T | D | T | D | T | ||
| Arm-side | A | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.95 | 0.95 | 0.99 | 0.99 |
| G | 0.70 | 0.71 | 0.81 | 0.81 | 0.66 | 0.75 | 0.70 | 0.79 | 0.53 | 0.62 | |
| Hand-side | A | 0.99 | 1.00 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| G | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| Thigh-side | A | 0.62 | 0.62 | 0.51 | 0.54 | 0.60 | 0.67 | 0.54 | 0.70 | 0.88 | 0.88 |
| G | 0.82 | 0.88 | 0.86 | 0.88 | 0.84 | 0.89 | 0.82 | 0.88 | 0.88 | 0.88 | |
| Classification | Sensor | Classifier | Samples | Number of Features | Processing Time | ||
|---|---|---|---|---|---|---|---|
| Train | Test | Mean (ms) | Std (ms) | ||||
| Body-segment | A | LR | 2500 | 300 | 8 | 603.0 | 14.1 |
| SVM | 2500 | 300 | 10 | 475.0 | 26.6 | ||
| XGB | 2500 | 300 | 10 | 4630.0 | 113.0 | ||
| G | kNN | 2500 | 300 | 8 | 142.0 | 4.9 | |
| XGB | 2500 | 300 | 4 | 2530.0 | 16.0 | ||
| Left-segment | A | LR | 1250 | 150 | 7 | 78.0 | 0.5 |
| kNN | 1250 | 150 | 4 | 74.5 | 10.7 | ||
| SVM | 1250 | 150 | 6 | 272.0 | 14.8 | ||
| Right-segment | G | LR | 1250 | 150 | 6 | 79.3 | 0.7 |
| SVM | 1250 | 150 | 6 | 268.0 | 11.2 | ||
| XGB | 1250 | 150 | 6 | 1210.0 | 87.0 | ||
| Arm-side | A | LR | 800 | 100 | 4 | 56.0 | 0.7 |
| kNN | 800 | 100 | 4 | 59.1 | 0.2 | ||
| SVM | 800 | 100 | 3 | 91.7 | 0.6 | ||
| XGB | 800 | 100 | 4 | 333.0 | 2.2 | ||
| Hand-side | A | LR | 800 | 100 | 1 | 84.2 | 0.1 |
| kNN | 800 | 100 | 1 | 62.1 | 6.3 | ||
| SVM | 800 | 100 | 1 | 86.1 | 7.5 | ||
| DT | 800 | 100 | 1 | 74.7 | 19.3 | ||
| XGB | 800 | 100 | 1 | 186.0 | 18.2 | ||
| G | LR | 800 | 100 | 1 | 64.4 | 8.24 | |
| kNN | 800 | 100 | 1 | 79.0 | 9.5 | ||
| SVM | 800 | 100 | 1 | 71.1 | 7.4 | ||
| DT | 800 | 100 | 1 | 61.2 | 4.8 | ||
| XGB | 800 | 100 | 1 | 197.0 | 12.0 | ||
| Classification | Classifier | Feature Types | P | R | F1 | Processing Time | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Centrality | Position | Dispersion | Distribution | Chaotic | Energy | # | Mean (ms) | Std (ms) | |||||
| Body-segment | SVM | mean-FB mean-TA | std max-TA | kurt-FB skew skew-ML | k-2 k-4-TA k-8-TA | 10 | 0.90 | 0.88 | 0.88 | 475.0 | 26.6 | ||
| Body-side | DT | mean mean-FB RMS | std std-TA | skew-ML | k-4 | 7 | 0.83 | 0.82 | 0.82 | 204.0 | 17.3 | ||
| Left-segment | kNN | mean mean-TA | std | k-4-TA | 4 | 1.00 | 1.00 | 1.00 | 74.5 | 10.7 | |||
| Right-segment | LR | mean-ML mean-TA | std max-ML | skew-FB | k-2-FB k-4-FB | 7 | 0.95 | 0.95 | 0.95 | 91.5 | 12.5 | ||
| Arm-side | LR | mean-FB mean-ML mean-TA | skew-FB | 4 | 0.99 | 0.99 | 0.99 | 67.4 | 4.1 | ||||
| Hand-side | LR | mean | 1 | 1.00 | 1.00 | 1.00 | 73.1 | 13.1 | |||||
| Thigh-side | XGB | mean mean-ML | std-TA | kurt-FB | 4 | 0.91 | 0.89 | 0.88 | 468.0 | 30.8 | |||
| Classification | Classifier | Feature Types | P | R | F1 | Processing Time | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Centrality | Position | Dispersion | Distribution | Chaotic | Energy | # | Mean (ms) | Std (ms) | |||||
| Body-segment | kNN | mean mean-ML | IQR min std-FB std-TA | kurt-FB | k-8-TA | 8 | 0.96 | 0.96 | 0.96 | 158.0 | 17.8 | ||
| Body-side | kNN | mean mean-FB mean-TA | per25-FB per75-ML | kurt-FB | entro20 | 7 | 0.87 | 0.86 | 0.86 | 146.0 | 15.3 | ||
| Left-segment | SVM | mean | per50-FB | std-FB | skew-FB | k-8-TA | 5 | 1.00 | 1.00 | 1.00 | 90.5 | 7.4 | |
| Right-segment | LR | mean mean-TA | min-FB std-TA | skew-ML | k-2-ML | 6 | 0.97 | 0.97 | 0.97 | 84.5 | 5.0 | ||
| Arm-side | kNN | mean-FB | per50-ML | min | kurt-TA | k-4-FB entro-50 | 6 | 0.84 | 0.82 | 0.81 | 73.5 | 3.3 | |
| Hand-side | DT | mean | 1 | 1.00 | 1.00 | 1.00 | 58.9 | 7.2 | |||||
| Thigh-side | SVM | skew-FB | 1 | 0.94 | 0.91 | 0.89 | 167.0 | 6.6 | |||||
| Classification | Classifier | Parameters | Note |
|---|---|---|---|
| Body-segment | SVM | C = 2.0, gamma = 0.5, kernel = ’poly’ | Tuned |
| Body-side | DT | criterion = ’gini’, max_depth = None, min_samples_leaf = 1, min_samples_split = 2, splitter = ’best’ | Default |
| Left-segment | kNN | n_neighbors=5, weights=’uniform’, p=1 | Tuned |
| Right-segment | LR | C = 1.0, penalty = ’l2’ | Default |
| Arm-side | LR | C = 1.0, penalty = ’l2’ | Default |
| Hand-side | LR | C = 1.0, penalty = ’l2’ | Default |
| Thigh-side | XGB | learning_rate = 0.1, max_delta_step = 0, objective = ’binary:logistic’, subsample = 1 | Default |
| Classification | Classifier | Paramters | Note |
|---|---|---|---|
| Body-segment | kNN | n_neighbors = 5, p = 2, weights = ’uniform’, algorithm = ’auto’ | Default |
| Body-side | kNN | n_neighbors = 5, p = 2, weights = ’uniform’, algorithm = ’auto’ | Default |
| Left-segment | SVM | C = 3.5, gamma = 4.0, kernel = ’rbf’ | Tuned |
| Right-segment | LR | C = 1.0, penalty = ’l2’ | Default |
| Arm-side | kNN | n_neighbors = 5, p = 2, weights = ’uniform’, algorithm = ’auto’ | Default |
| Hand-side | DT | criterion = ’gini’, max_depth = None, min_samples_leaf = 1, min_samples_split = 2, splitter = ’best’ | Default |
| Thigh-side | SVM | C=0.5, gamma = 2.0, kernel = ’sigmoid’ | Tuned |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sang, V.N.T.; Yano, S.; Kondo, T. On-Body Sensor Positions Hierarchical Classification. Sensors 2018, 18, 3612. https://doi.org/10.3390/s18113612
Sang VNT, Yano S, Kondo T. On-Body Sensor Positions Hierarchical Classification. Sensors. 2018; 18(11):3612. https://doi.org/10.3390/s18113612
Chicago/Turabian StyleSang, Vu Ngoc Thanh, Shiro Yano, and Toshiyuki Kondo. 2018. "On-Body Sensor Positions Hierarchical Classification" Sensors 18, no. 11: 3612. https://doi.org/10.3390/s18113612
APA StyleSang, V. N. T., Yano, S., & Kondo, T. (2018). On-Body Sensor Positions Hierarchical Classification. Sensors, 18(11), 3612. https://doi.org/10.3390/s18113612