1. Introduction
Motors, with the high-efficiency conversion characteristics, can increase the efficiency of converting electrical energy into mechanical energy by over 90% [
1]. Through intelligent control technologies such as variable frequency speed regulation and energy recovery, it can achieve precise speed and torque adjustment. The low-noise operation (<50 decibels) and zero-emission features significantly reduce noise and air pollution in industrial and living scenarios. Meanwhile, the brushless design and corrosion-resistant sealing structures (such as O-rings and stainless-steel housings) ensure stable and durable operation in harsh environments. In addition, motors have a compact structure and low maintenance costs (such as no need for carbon brushes and simplified mechanical components), and strong adaptability. Motors are widely used in fields such as electric vehicles, humanoid robots, drones, eVTOL, medical equipment, smart home appliances, and industrial automation as
Figure 1 shows [
2]. These advantages not only reduce dependence on fossil fuels but also contribute to reducing billions of tons of carbon emissions annually, promoting the global carbon neutrality process and sustainable development. Motors provide core support for humanity to achieve green energy transformation and intelligent production.
A good sealing performance is the foundation for the reliable operation of motors. By preventing the intrusion of external dust, water vapor, and chemicals, it protects internal electrical components and mechanical parts, prolongs the service life of equipment, and maintains stable operation. In harsh environments such as humid, dusty, or underwater conditions, motors need to adopt special sealing designs (such as rubber O-rings, corrosion-resistant stainless steel housings or bellows seals) to isolate environmental erosion and adapt to temperature and pressure changes. A good sealing protection system not only improves the environmental adaptability of motors, but also reduces maintenance costs, providing technical support for the wide applications in fields such as industrial automation, spacecraft, and underwater equipment.
There are several aspects to the design of the sealing structure, which are experiments [
3,
4,
5,
6], theoretical calculations [
7,
8,
9], and finite element analysis [
10,
11].
Finite element analysis has emerged with the development of computer technology [
12,
13]. The advantages of finite element analysis are reflected in the following aspects: Firstly, its powerful ability to model complex structures allows irregular geometries to be decomposed into simple elements. By combining and analyzing the overall behavior, it can effectively handle complex boundary conditions and predict fluid mechanics that are difficult to analyze in engineering [
14,
15,
16]. Secondly, high-precision calculations based on the equations of continuum mechanics can accurately predict parameters such as stress, strain, and displacement. It could also support multi-physics field coupling analysis (such as thermal–mechanical and fluid–structure coupling), providing comprehensive solutions for interdisciplinary problems. Thirdly, this method can replace a large number of physical experiments with virtual simulations, significantly reducing design costs and shortening the development cycle. At the same time, it enables multi-scheme optimization and comparison in the design stage, improving product reliability and performance.
Figure 2 shows the comparison between traditional product design and simulation-driven product design, which can save time and costs in the design phase. In addition, a flexible meshing strategy balances efficiency while ensuring calculation accuracy, making it suitable for various problems from simple rods to three-dimensional solids. Finally, its wide range of application scenarios covers fields such as mechanics, civil engineering, aerospace, and biomedical engineering, making it a core technical support for modern engineering design and optimization [
17,
18].
However, as the finite element models and the physical situations to be simulated become increasingly complex, this method has gradually revealed its unique limitations. For example, in the case of material nonlinearity problems, its computation time and model convergence stability are very poor, requiring very precise adjustment of the quality of mesh division. Another example is that, for multi-contact pair problems, the mesh penetration problem has occurred frequently and it always take a very long convergence time. The current solution is to increase computing resources, such as using more CPUs for parallel computing. But this also leads to a rapid increase in simulation costs. Its timeliness and the consumption of computing resources seriously hinder the speed of product development. Simply increasing the computation time and the number of CPUs cannot solve the bottleneck problems of the finite element method.
With the explosive growth and development of artificial intelligence technology, a new solution is provided to solve this problem.
The origin of artificial intelligence can be traced back to the 1950s. The concept of “artificial intelligence” was first proposed and the discipline framework was established at the Dartmouth Conference in 1956. The early development focused on symbolism and expert systems, simulating human decision-making through rules. The proposal of the deep learning concept in 2006 and the improvement in computing power promoted the technological renaissance [
19,
20,
21]. Landmark applications such as AlphaGo have verified the ability to solve complex tasks. Recently, artificial intelligence has penetrated into medical care (precise diagnosis and drug research and development), intelligent manufacturing (smart factories and predictive maintenance of equipment), smart cities (traffic flow optimization and AI services for government affairs), and cross-domain innovation driven by large models (such as financial risk control and educational assistance).
The development of artificial intelligence depends on three elements: data, algorithms, and computing power. Artificial intelligence is based on two major theoretical cornerstones: symbolism (logical reasoning and expert systems) and connectionism (bionic neural networks). In recent years, machine learning (especially deep learning) has become the mainstream paradigm, achieving pattern recognition and decision optimization through data-driven model training.
Machine learning is an interdisciplinary field that aims to simulate human learning behaviors in a data-driven manner and optimize the performance standards of computer programs [
22]. Its theoretical roots can be traced back to the 17th century statistical foundations such as Bayes’ theorem and the least squares method, while the modern discipline framework was officially established at the Dartmouth Conference in 1956. Early development went through the exploration of symbolism and connectionism. In 1959, the self-learning checkers program designed by Samuel first verified the feasibility of machines improving the capabilities through experience, marking the transition of machine learning from theory to practice. Subsequently, during the revival period in the 1980s, expert systems and example induction learning promoted breakthroughs in automatic knowledge acquisition technology. Since the 21st century, deep learning has witnessed an explosion due to the leap in computing power and data scale. The breakthrough of AlexNet in the ImageNet competition in 2012 and the milestone event of AlphaGo demonstrated the potential of neural networks in complex pattern recognition and decision optimization. Currently, machine learning has penetrated core areas such as healthcare (e.g., imaging diagnosis and drug research and development), finance (risk prediction), transportation (autonomous driving and route planning), intelligent manufacturing (industrial robot control and predictive maintenance of equipment), and natural language processing (text generation and sentiment analysis driven by large models). It continues to expand the application boundaries through technologies such as federated learning and reinforcement learning. This technological evolution has not only reshaped the industrial ecosystem but also become the core driving force for global intelligent transformation and sustainable development, with practical effects such as reducing industrial energy consumption by an average of 15% per year.
This paper proposes hybrid models of machine learning that contain polynomial regression [
23,
24] and optimization XGBOOST models to rapidly and accurately predict the sealing performance of motors [
25,
26,
27]. Then, the hybrid model is combined with the simulated annealing algorithm [
28,
29,
30] and multi-objective particle swarm optimization algorithm for optimization. The reliability of the results is verified by the mutual verification of the results of the simulated annealing algorithm and the particle swarm optimization algorithm [
31,
32,
33].
There is little research on the sealing structure design of motors. Most of the research focuses on the design of sealing structures.
Rubber sealing structures are sealing devices based on the elastic deformation characteristics of rubber materials [
34]. The core function is to achieve fluid isolation and shock absorption protection by filling gaps or compensating for deformations [
35,
36]. Rubber seal origin can be traced back to the commercial application of natural rubber in the 19th century. The embryonic form of modern sealing technology was formed during the Industrial Revolution in the early 20th century. In the 1900s, engineers used annular rubber parts to solve mechanical leakage problems. Subsequently, the O-ring became a standardized product because its circular cross-section optimized the mechanical properties. Through material innovation and process iteration, rubber sealing structures achieved a technological leap in the mid-20th century. This thriving development is mainly reflected in several aspects. Breakthroughs in the research and development of synthetic rubber (such as nitrile rubber and acrylonitrile butadiene rubber) [
37], multi-layer composites [
38,
39,
40], and metal support designs significantly improved the temperature resistance and pressure-bearing capacity [
41]. This promoted the application from traditional industries to high-precision fields such as aerospace [
42,
43] and industrial equipment [
44,
45,
46] and even hydrogen environments [
47,
48,
49].
Recent applications have exhibited multi-dimensional innovations. In new energy vehicles, ethylene propylene diene monomer (EPDM) sealing strips ensure the airtightness of battery packs. In the submarine field, silicone sealing rings are adopted to meet submarine pipeline maintenance dry cabin requirements [
50]. In the large diameter shield machine industry, the seal is utilized to enhance the waterproof life of high-pressure and high-humidity environments [
51]. According to statistics, the global rubber sealing parts market scale will surpass 100 billion US dollars by 2025. China promotes the research and development of bio–based rubber through the 14th Five-Year Plan, which verifies that this structure has become an indispensable core component in the modern industrial system.
2. Methodology
Polynomial regression extends linear regression by introducing high-order terms of predictor variables, enabling it to model non-linear relationships without relying on complex models. Unlike “black-box” models such as neural networks, polynomial regression provides transparent coefficients, clearly showing the contribution of each term to the prediction. Compared with support vector regression (SVR) or neural networks, it has lower requirements for computing resources and is especially suitable for datasets of medium complexity [
24,
52].
XGBoost outperforms SVR and random forests in terms of performance, while polynomial regression remains the preferred tool for simple non-linear modeling, considering polynomial regression and XGBoost characteristics of accuracy, efficiency, and interpretability. Therefore, polynomial regression is preferentially selected in this study, and when the prediction accuracy is poor, the XGBoost model is used for the data [
53,
54,
55].
Import a CSV file with 119 data entries into PyCharm 2024.2.1 (Community Edition) and establish a relationship between the independent variables and the dependent variable in the finite element model of the motor sealing structure. In this study, the independent variables are preload and H (groove depth), the dependent variables are CP (contact pressure), CA (contact area), and σ (stress).
In the traditional way, the dependent variables are calculated with the FEA method through software platforms such as ANSYS workbench 2023R2. The different structure size such as H and different boundary condition such as preload are independent variables which define different FEA models and simulate through ANSYS so as to obtain the dependent variables like CP, CA, and σ. For the material non-linear problems and multi-contact problems, it usually takes a significant amount of time and occupies high CPU and RAM computing resources. Furthermore, the finite element model constructed usually has a relatively high risk of crashing during the calculation process. This risk is caused by various situations, and the most important factor is that, for material non-linearity problems, mesh distortion leads to local stress singularity, which in turn causes the calculation to crash.
In this study, by constructing the association between independent variables and dependent variables using the fitting algorithm of machine learning, two aspects of problems can be solved. On the one hand, it can address the issue of excessively long-time consumption in the finite element analysis of material non-linearity problems. On the other hand, it can solve the stability problems of the finite element simulation analysis model, such as crashes or convergence issues during the calculation process.
The flowchart about the method in this study is shown in
Figure 3.
2.1. Physical Model
Figure 4 shows the simple motor 3D model with the O-ring, base, and shell. The section plan shows that there are three contact surfaces of the O-ring among the sealing structure, which has five contact surfaces. It also shows the FEA model, which contains the mesh element.
The FEA boundary condition implies to fix the blue surface using the beam element to apply preload, which is shown in
Figure 5. The FEA model is the same as in the previous study [
56].
2.2. Polynomial Regression
Polynomial regression is a specific algorithm in machine learning. It is an extension of linear regression and is used to handle non-linear data relationships. As a non-linear relationship modeling method, polynomial regression has its historical origins tracing back to the early 19th century when Gauss and Legendre proposed the theory of least squares parameter estimation. Even earlier, the idea of nonlinear analysis stemmed from the Babylonians’ practice of using geometric methods to solve quadratic equations around 2000 BCE. The core of this algorithm lies in extending linear models into polynomial forms by introducing higher-order terms of independent variables, thereby fitting complex data patterns while maintaining the linear characteristics of parameter estimation. Its flexibility is reflected in its ability to adapt to varying data complexities through adjustments in the polynomial degree. However, high-degree models are prone to overfitting, necessitating the use of cross-validation and regularization techniques to balance the model’s generalization ability. In modern applications, polynomial regression has been extensively utilized in industrial scenarios such as semiconductor chip performance modeling, new energy battery life prediction, and automotive component reliability analysis. In terms of technical evolution, by integrating feature engineering methods such as orthogonal polynomials and spline functions, as well as machine learning frameworks like scikit-learn, the algorithm has significantly enhanced high-dimensional data processing and large-scale computational efficiency while retaining the advantages of classical statistics.
In this study, the independent variables are H (groove depth) in
Figure 4 and preload. Therefore, a bivariate
n-degree polynomial is adopted. The formula could be described as follows:
x1 and
x2 are independent variables (e.g., groove depth, preload).
is the intercept term (baseline value of
y when all
x-values are zero).
is the coefficient for interaction terms, representing the combined effect of
and
.
n is maximum polynomial degree (e.g.,
n = 2 for quadratic terms).
is error term.
i and
j are non-negative integers representing the power exponents of two independent variables
x1 and
x2.
To evaluate the predictive performance of artificial intelligence models, the following metrics are used: mean absolute error (MAE), mean squared error (MSE), and mean absolute percentage error (MAPE).
The mean absolute error (MAE) is a metric used to evaluate the accuracy of predictive models, defined as the average of the absolute deviations between observed values and predicted values. Its mathematical formula is as follows:
where
represents the true value,
denotes the predicted value, and
n is the number of samples.
A key advantage of MAE is its robustness: by utilizing absolute errors rather than squared errors, it avoids cancellation of positive and negative deviations and exhibits lower sensitivity to outliers. Compared to the mean squared error (MSE), MAE preserves the same unit as the original data, providing an intuitive measure of prediction error magnitude.
Mean squared error (MSE) is a fundamental metric in statistics and machine learning for quantifying the discrepancy between predicted values and true values.
Its mathematical formula is as follows:
Mean absolute percentage error (MAPE) is an important indicator to measure the accuracy of a prediction model. It is used to reflect the relative error level between the predicted value and the true value. The calculation of MAPE is based on the absolute error of each sample relative to the true value. The percentage is then averaged. Its mathematical expression is as follows:
The results of using polynomial regression simulation analysis on the database are shown in
Figure 6.
By comparing the data in the figure, three evaluation methods are introduced into the data to assess the accuracy of the model. The compared results are shown in
Table 1.
Figure 7 shows the results of polynomial regression and the true data. For the data about CA1 and CA2, the predicted results are highly reliable while CA3 is not satisfactory. The MES of CA3 reaches 39.82, which is the highest value among all the CA results in
Table 2.
Figure 8 shows the results of polynomial regression and the true data. For the data about O-ring stress, the predicted results are highly reliable. The MAPE is 0.1257% in
Table 3.
The above analysis shows that, except for the CA3 indicator, the fitting performance of other metrics is satisfactory. In order to improve the fitting accuracy and make subsequent parameter optimization more reliable, the advanced model XGBOOST in machine learning will be used.
2.3. XGBOOST
XGBoost (eXtreme Gradient Boosting) is an ensemble learning algorithm based on gradient boosting decision trees. It iteratively optimizes model performance by combining the prediction results of weak learners. Its core improvement lies in the introduction of second-order Taylor expansion and regularization terms to balance model complexity and generalization ability. This algorithm supports parallel computing and distributed processing, and adopts greedy splitting strategy and cache-aware optimization technology, which significantly improves the training efficiency on large-scale data. At the same time, it realizes feature importance analysis through interpretable frameworks such as SHAP (Shapley Additive Explanations). The flexibility and scalability of XGBoost enable it to support custom loss functions and evaluation metrics, providing a general solution for machine learning tasks in complex scenarios.
After fitting with polynomials, the fitting effect on the physical quantity CA3 is not satisfactory. In this section, another machine learning algorithm is introduced. XGBOOST is used to improve the accuracy. The trained XGBOOST is compared with the polynomial model in the same test set. Calculate the error metrics for the XGBOOST model that are MSE, MAE, and MAPE. The calculation results of the error metrics for the XGBOOST model are in
Table 4.
Compared with
Table 2, for the error metrics of quantity CA3, the XGBOOST model has a better performance than the polynomial regression model. For the model accuracy purpose, although the XGBOOST model is better, it still needs to improve the accuracy. To improve the fitting effect of XGBOOST, use Grid Search to optimize its parameters. Grid Search works by providing several sets of model parameters, aiming to find the optimal parameter combination so that the model performs better on the test set. Grid Search in XGBoost is a systematic hyper-parameter optimization method. Its core is to traverse the pre-defined hyper-parameter combinations through exhaustive search, and combine cross-validation to evaluate model performance, so as to select the optimal parameter configuration. This method requires pre-defining the parameter search space (such as learning rate, tree depth, etc.), generating all possible parameter combinations, and calculating the average performance metrics (such as log loss, accuracy) through cross-validation to determine the best parameters. The advantage of grid search lies in its global optimality, ensuring that the best parameters are found within the given search space. Perform grid search and cross-validation using Grid Search on the training set to find the optimal parameters and the corresponding model, and calculate the error metrics on the test set. The optimization process culminated in the successful identification of the relevant parameters following a 43 min exploration. The error metrics of the optimized XGBOOST model are listed in
Table 5. Compared to the data in
Table 4, for the error metric results of the optimized XGBOOST model, there has been a certain improvement for each physical quantity, indicating that the optimized model is effective. According to Occam’s Razor, which is a philosophical and scientific principle advocating for simplicity, among competing hypotheses explaining the same phenomenon, the one with the fewest assumptions should be prioritized. For cases wherein the accuracy of polynomial fitting is not significantly different from that of OP-XGBOOST, polynomial regression is still used. For cases with significant improvement, OP-XGBOOST is employed.
Analyze the data from
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 to obtain the bar chart from
Figure 9,
Figure 10 and
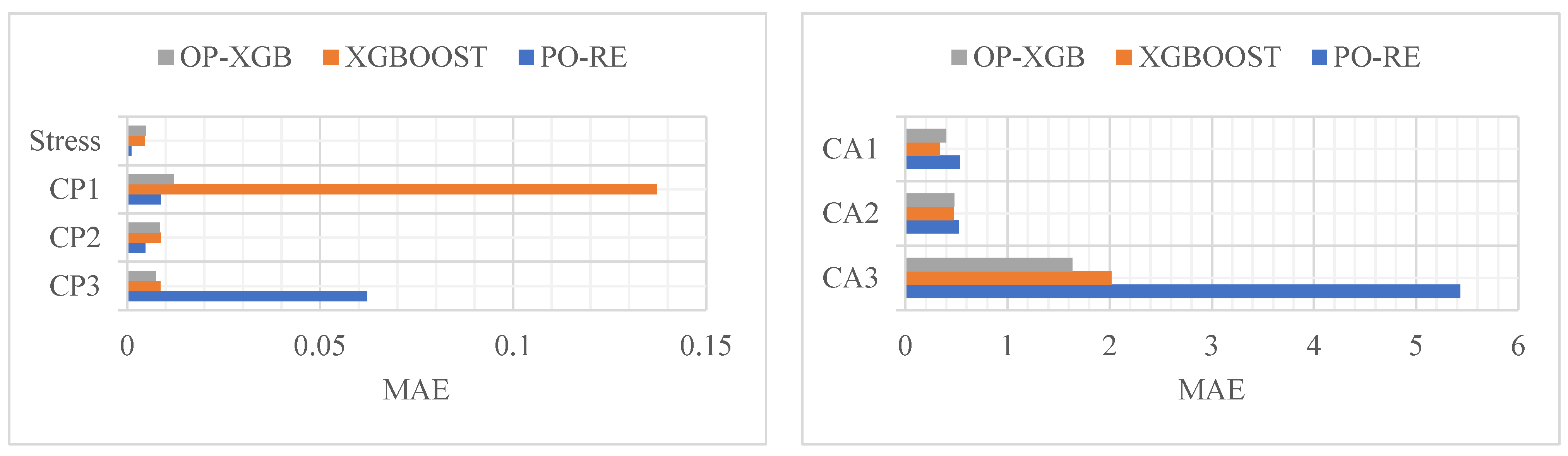
Figure 11. The comparison of the prediction results of CP and stress reveals that PO-RE has a better performance than the other comparative models of MSE. While CA has a better performance of OP-XGB, the PO-RE model’s MSE reaches 39.82. The comparison of MAE and MAPE of CP and stress indicate that the PO-RE model is better than the OP-XGB model besides the MAE of CP3. For the CP3, the MAE of the PO-RE model is 0.06223 while that of OP-XGB is 0.00744. The comparison of the prediction results of CA reveals that OP-XGB has a better performance than the PO-RE models.
According to the above analysis, the final model is established in
Table 6. That is, for CP and stress, polynomial regression is better, while for CA, OP-XGBOOST is preferred.
Validate the above models on the validation set. Save the above-generated models as DAT files, and then applied the models to fit the data on the validation set. The performance of the different models is shown in
Figure 12,
Figure 13 and
Figure 14.
The red line is original data from the test set. The blue line, named PO-RE, is polynomial regression. The green line, named OP-XGB, is Optimized-XGBOOST.
From the comparison of CP in
Figure 13, it indicates that the accuracy difference between the models using OP-XGBOOST and polynomial regression is small. The performance of the polynomial regression model is slightly better than that of OP-XGBOOST, and it is generally closer to the original data. Therefore, the polynomial regression model is used for the CP physical quantity.
From the fitting effect of CA in
Figure 12, it indicates that the error of fitting CA using polynomial fitting is relatively large, which is obvious in CA2 and CA3. However, the fitting error of using OP-XGBOOST is smaller, and the fitting curve is closer to the original data curve. Therefore, for the CA physical quantity, OP-XGBOOST is used for fitting.
By comparing the performance of two different machine learning models in fitting stress in
Figure 14, it can be concluded that both polynomial fitting and XGBOOST perform well. However, the polynomial fitting result is closer to the original data. Therefore, for this physical quantity, the polynomial regression model is adopted.
The OP-XGBOOST confidence intervals and residual plots are shown in
Figure 15. In
Figure 15a, the red dots represent the actual values, the blue dashed line represents the sequence of predicted values of the model for the test set, and the orange confidence band is the 95% prediction interval calculated based on the standard deviation of the residuals. It can be seen from the figure that the red dots are evenly distributed around the blue line, and most (≥95%) of the red dots are located within the orange band. Moreover, the confidence band is narrow and uniform. In
Figure 15b, the data points are randomly distributed around the red line of y = 0 without any regular pattern.
The PO-RE confidence intervals and residual plots are shown in
Figure 16. In
Figure 16a, the red dots represent the actual values, the blue dashed line represents the sequence of predicted values of the model for the test set, and the orange confidence band is the 95% prediction interval calculated based on the standard deviation of the residuals. It can be seen from the figure that the red dots are evenly distributed around the blue line, and most (≥95%) of the red dots are located within the orange band. Moreover, the confidence band is narrow and uniform. In
Figure 16b, the data points are randomly distributed around the red line of y = 0 without any regular pattern.
The PO-RE confidence intervals and residual plots are shown in
Figure 17. In
Figure 17a, the red dots represent the actual values, the blue dashed line represents the sequence of predicted values of the model for the test set, and the orange confidence band is the 95% prediction interval calculated based on the standard deviation of the residuals. It can be seen from the figure that the red dots are evenly distributed around the blue line, and most (≥95%) of the red dots are located within the orange band. Moreover, the confidence band is narrow and uniform. In
Figure 17b, the data points are randomly distributed around the red line of y = 0 without any regular pattern.
2.4. Simulated Annealing Algorithm
The simulated annealing algorithm is a global optimization algorithm based on the principle of solid annealing. By simulating the process of a substance being heated and then slowly cooled, it randomly searches for the global optimal solution of the objective function in the solution space. Its core idea is to use the Metropolis criterion to accept inferior solutions with a certain probability at each temperature, so as to jump out of the local optimal trap and finally converge to an approximately optimal solution at low temperatures. The algorithm includes five key steps: initialization, neighborhood search, objective function evaluation, acceptance criterion judgment, and temperature attenuation. By controlling parameters (such as initial temperature and cooling rate), it balances exploration and exploitation.
This study references the previous research, empirical data, and GB/T 3452.3-2005 [
56,
57]. The upper and lower limits of groove depth and preload are set to [0.6, 0.9] and [70, 80], respectively. The initial solution is set to [0.75, 75], where the groove depth is 0.75 mm and the preload is 75 N. Since the principle of the simulated annealing algorithm is to find the minimum value, the object is set to
Three objective functions are set, namely Object1, Object2, and Object3; that is,
For the SA algorithm, it uses the model generated by the machine learning algorithm to optimize data. The list of the results of data optimization is found in
Table 7. The optimal solutions are all close to point (0.8, 80), with the groove depth near 0.8 mm and the preload from 79 N to 80 N.
2.5. Multi-Objective Particle Swarm Optimization
Multi-objective particle swarm optimization (MOPSO) is an extension of the classic particle swarm optimization (PSO) algorithm, designed to address multi-objective optimization problems where conflicting objectives need to be simultaneously optimized. Originating from the social behavior of bird flocks, MOPSO simulates the collective movement of particles to explore the solution space, guided by both individual and global best position.
The particle swarm optimization (PSO) algorithm simulates the process of birds searching for food in the forest. During the food-searching process, the velocity of a bird is determined by three aspects: its own inertia, self-cognition, and group-cognition. These three aspects determine the magnitude and direction of the velocity.
Among them,
is Inertia weight,
r1 and
r2 are random numbers between [0, 1],
and
are the cognitive and social acceleration coefficients,
Pbest is the particle’s own historical optimal solution, and
Gbest is the best position that has been found by the whole swarm [
58].
Particle swarm optimization is commonly used to deal with single-objective functions. The magnitude of the function value is represented by fitness. Different positions of the small bird correspond to different fitness values; that is, different function values. Since it is a single-objective function, it is very easy to judge the quality of the particle’s position and determine whether to perform this update according to the magnitude of the updated function value.
In multi–objective particle swarm optimization (MOPSO), a simple approach is that, each time the particle position is updated, if the updated solution dominates the original solution, the replacement is carried out; otherwise, the updated solution is added to the non-dominated solution set, and one is randomly selected as Pbest and gbest.
In this study, the objective function is Object1, Object2, and Object3. Define the initial population set to 300, and the final obtained Pareto front is shown in
Figure 18.
The points on the Pareto front are all non-dominated relationships; that is, there is no absolute superiority or inferiority relationship, which can provide multiple choices rather than being completely based on the weighted sum value. It can also be seen from the figure that, when Object1 and Object2 are larger, the stress is also large; if the stress were to be smaller, Object1 and Object2 would also become smaller. Pareto front database is listed in
Table 8.
Construct scatter plots of preload with Object1, Object2, and Object3 for further analysis in
Figure 19. A good linear relationship is shown between preload and Object1. At the same time, a good linear relationship is also shown between preload and Object3. A synchronous increasing relationship is shown between preload and Object2. On the contrary, groove depth with Object1, Object2, and Object3 display a random distribution, with data points disorderly scattered and no obvious correlation between variables.
From the relationship graph among preload, groove depth, and Object, it can be concluded that the magnitude of Object is determined by the magnitude of preload, and the influence of groove depth on Object is randomly distributed without any regular pattern.
According to the GB/T 3452.3-2005 and SA result, screen out the points from the Pareto front wherein the Groove depth is between [0.8, 0.85]. There is a total of 26 design schemes after screen out. Conduct a comprehensive evaluation of these 26 design schemes again. The top five results after evaluation using principal component analysis (PCA) are shown in
Table 9. The main steps of principal component analysis (PCA) include data standardization, calculation of the covariance matrix, eigenvalue decomposition, selection of principal components, allocate weights based on the variance contribution rate of principal components, project the data into the principal component space, calculate the comprehensive scores, and then obtain rank [
59,
60,
61].



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}