Precision Telemedicine through Crowdsourced Machine Learning: Testing Variability of Crowd Workers for Video-Based Autism Feature Recognition

 ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Clinically Representative Video Set
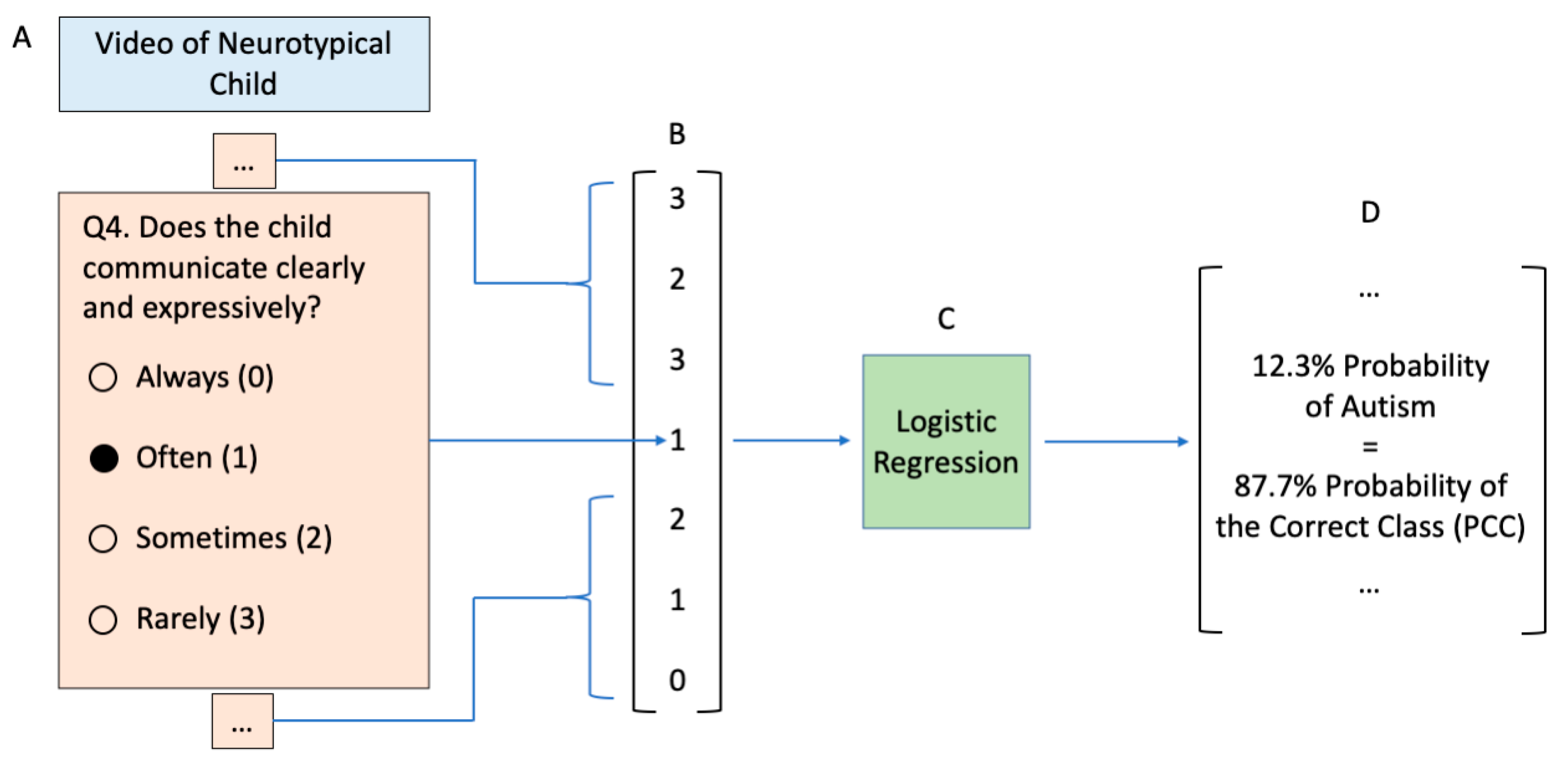
2.2. Video Observation Classifier
2.3. Video Rating Tasks
3. Results
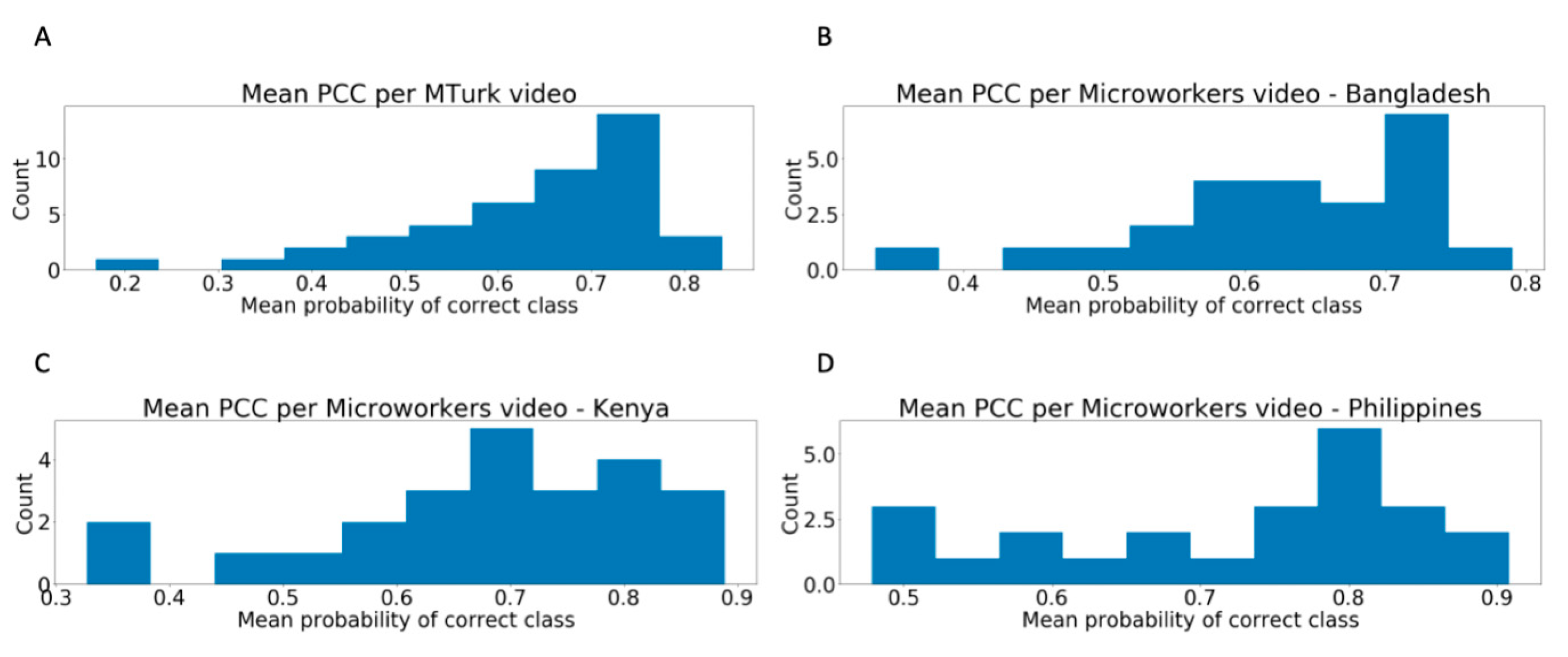
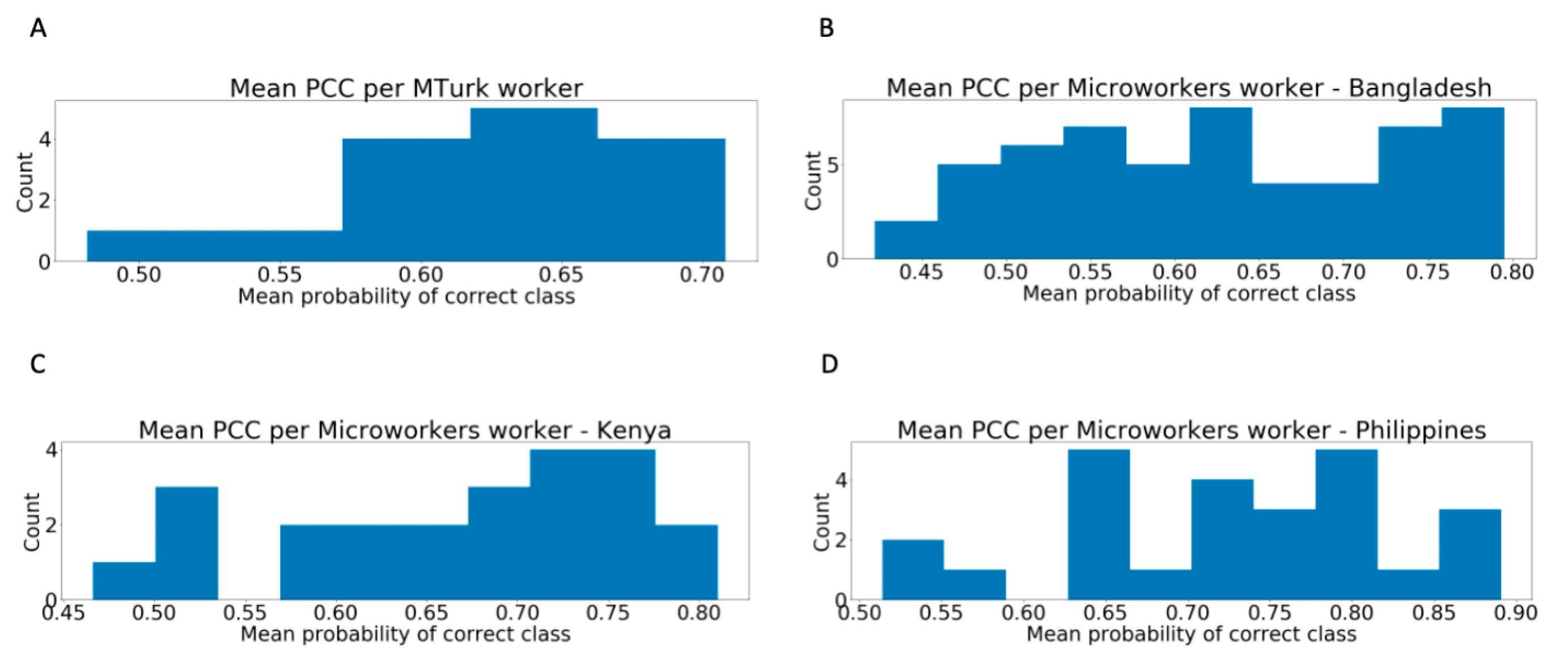
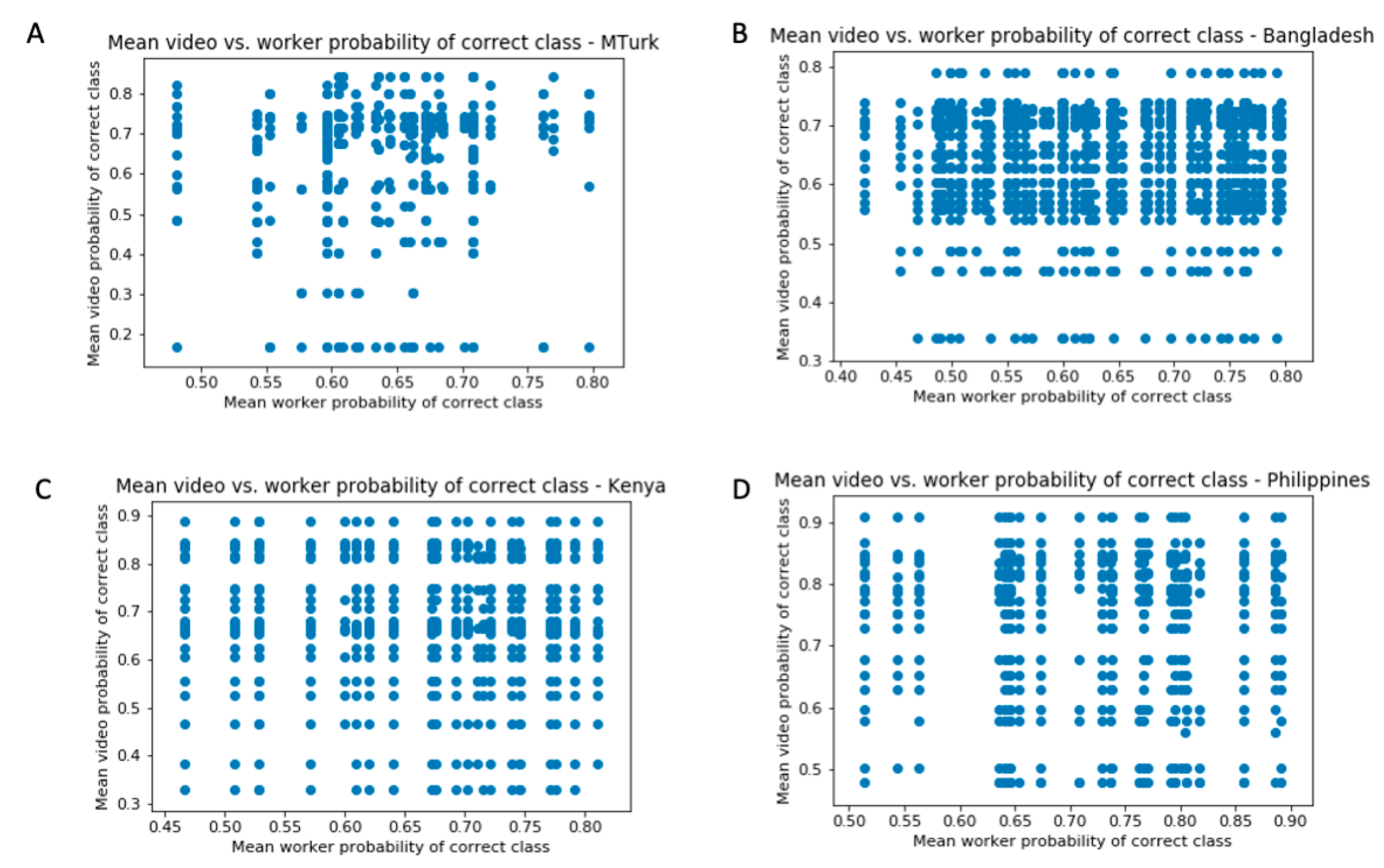
3.1. Distribution of Worker Performance
3.2. Super Recognizers
3.3. Effect of Time Spent Rating
4. Discussion
4.1. General Implications
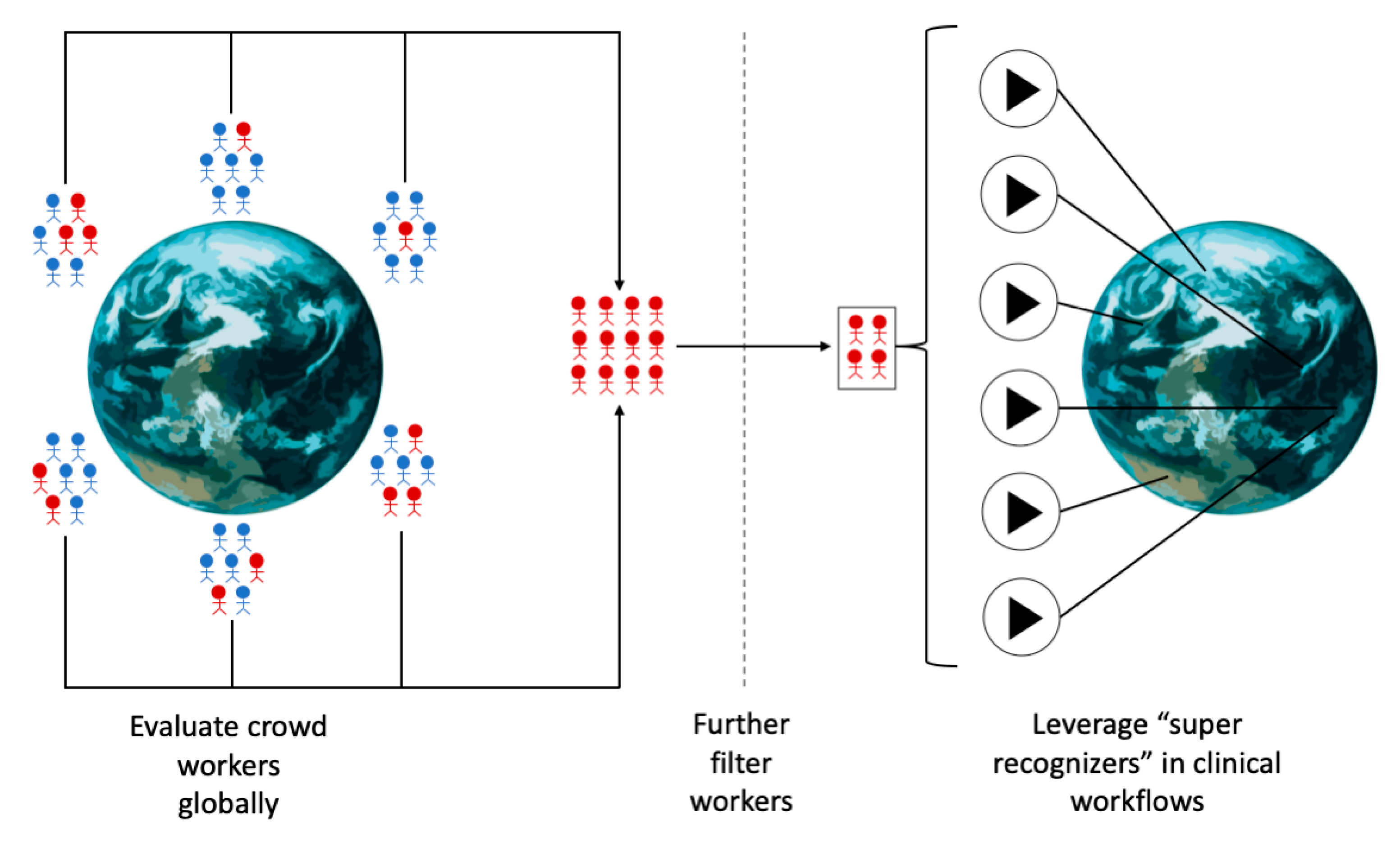
4.2. Formalization of a Crowd Filtration Process
- Train one or more machine learning classifiers using data accumulated by domain expert clinicians. These data may be actively acquired or mined from existing data sources. It is crucial that the gold standard data are representative of the target pediatric population.
- Define a target performance metric for worker evaluation and a target number of workers to recruit.
- Collect labels from a massive and distributed set of crowd workers (Figure 5).
- Filter the crowd workers progressively and repeatedly until the target number of workers have reached or surpassed the target performance metric.
- The final set of globally recruited “super recognizers” can be leveraged in precision health and precision medicine clinical workflows toward rating a worldwide pediatric population (Figure 5).
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fombonne, E. The rising prevalence of autism. J. Child Psychol. Psychiatry 2018, 59, 717–720. [Google Scholar] [CrossRef]
- Matson, J.L.; Kozlowski, A.M. The increasing prevalence of autism spectrum disorders. Res. Autism Spectr. Disord. 2011, 5, 418–425. [Google Scholar] [CrossRef]
- Gordon-Lipkin, E.; Jessica, F.; Georgina, P. Whittling down the wait time: Exploring models to minimize the delay from initial concern to diagnosis and treatment of autism spectrum disorder. Pediatric Clin. 2016, 63, 851–859. [Google Scholar]
- Ning, M.; Daniels, J.; Schwartz, J.; Dunlap, K.; Washington, P.; Kalantarian, H.; Du, M.; Wall, D.P.; Cao, Y.; Antoniou, P. Identification and Quantification of Gaps in Access to Autism Resources in the United States: An Infodemiological Study. J. Med. Internet Res. 2019, 21, e13094. [Google Scholar] [CrossRef]
- Tariq, Q.; Fleming, S.L.; Schwartz, J.; Dunlap, K.; Corbin, C.; Washington, P.; Kalantarian, H.; Khan, N.Z.; Darmstadt, G.L.; Wall, D.P.; et al. Detecting Developmental Delay and Autism Through Machine Learning Models Using Home Videos of Bangladeshi Children: Development and Validation Study. J. Med. Internet Res. 2019, 21, e13822. [Google Scholar] [CrossRef]
- Washington, P.; Kalantarian, H.; Tariq, Q.; Schwartz, J.; Dunlap, K.; Chrisman, B.; Varma, M.; Ning, M.; Kline, A.; Stockham, N.; et al. Validity of Online Screening for Autism: Crowdsourcing Study Comparing Paid and Unpaid Diagnostic Tasks. J. Med. Internet Res. 2019, 21, e13668. [Google Scholar] [CrossRef]
- Washington, P.; Park, N.; Srivastava, P.; Voss, C.; Kline, A.; Varma, M.; Tariq, Q.; Kalantarian, H.; Schwartz, J.; Patnaik, R.; et al. Data-Driven Diagnostics and the Potential of Mobile Artificial Intelligence for Digital Therapeutic Phenotyping in Computational Psychiatry. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2019. [Google Scholar] [CrossRef]
- Kosmicki, J.A.; Sochat, V.V.; Duda, M.; Wall, D.P. Searching for a minimal set of behaviors for autism detection through feature selection-based machine learning. Transl. Psychiatry 2015, 5, e514. [Google Scholar] [CrossRef]
- Wall, D.P.; Kosmicki, J.; DeLuca, T.F.; Harstad, E.; Fusaro, V.A. Use of machine learning to shorten observation-based screening and diagnosis of autism. Transl. Psychiatry 2012, 2, e100. [Google Scholar] [CrossRef]
- Abbas, H.; Garberson, F.; Liu-Mayo, S.; Glover, E.; Wall, D.P. Multi-modular Ai Approach to Streamline Autism Diagnosis in Young children. Sci. Rep. 2020, 10, 1–8. [Google Scholar] [CrossRef]
- Voss, C.; Schwartz, J.; Daniels, J.; Kline, A.; Haber, N.; Washington, P.; Tariq, Q.; Robinson, T.N.; Desai, M.; Phillips, J.M.; et al. Effect of Wearable Digital Intervention for Improving Socialization in Children with Autism Spectrum Disorder: A Randomized Clinical Trial. JAMA Pediatr. 2019, 173, 446–454. [Google Scholar] [CrossRef]
- Kline, A.; Voss, C.; Washington, P.; Haber, N.; Schwartz, H.; Tariq, Q.; Winograd, T.; Feinstein, C.; Wall, D.P. Superpower Glass. GetMobile Mob. Comput. Commun. 2019, 23, 35–38. [Google Scholar] [CrossRef]
- Washington, P.; Catalin, V.; Aaron, K.; Nick, H.; Jena, D.; Azar, F.; Titas, D.; Carl, F.; Terry, W.; Dennis, W. Superpowerglass: A wearable aid for the at-home therapy of children with autism. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 112. [Google Scholar] [CrossRef]
- Daniels, J.; Schwartz, J.N.; Voss, C.; Haber, N.; Fazel, A.; Kline, A.; Washington, P.; Feinstein, C.; Winograd, T.; Wall, D.P. Exploratory study examining the at-home feasibility of a wearable tool for social-affective learning in children with autism. NPJ Digit. Med. 2018, 1, 32. [Google Scholar] [CrossRef]
- Kalantarian, H.; Jedoui, K.; Washington, P.; Tariq, Q.; Dunlap, K.; Schwartz, J.; Wall, D.P. Labeling images with facial emotion and the potential for pediatric healthcare. Artif. Intell. Med. 2019, 98, 77–86. [Google Scholar] [CrossRef]
- Kalantarian, H.; Washington, P.; Schwartz, J.; Daniels, J.; Haber, N.; Wall, D. A Gamified Mobile System for Crowdsourcing Video for Autism Research. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; pp. 350–352. [Google Scholar]
- Kalantarian, H.; Washington, P.; Schwartz, J.; Daniels, J.; Haber, N.; Wall, D.P. Guess What? J. Healthc. Informatics Res. 2018, 3, 43–66. [Google Scholar] [CrossRef]
- Kalantarian, H.; Jedoui, K.; Washington, P.; Wall, D.P. A Mobile Game for Automatic Emotion-Labeling of Images. IEEE Trans. Games 2018, 1. [Google Scholar] [CrossRef]
- Kalantarian, H.; Jedoui, K.; Dunlap, K.; Schwartz, J.; Washington, P.; Husic, A.; Tariq, Q.; Ning, M.; et al. The Performance of Emotion Classifiers for Children with Parent-Reported Autism: Quantitative Feasibility Study. JMIR Ment. Health 2020, 7, e13174. [Google Scholar] [CrossRef]
- Rudovic, O.; Lee, J.; Dai, M.; Schuller, B.W.; Picard, R.W. Personalized machine learning for robot perception of affect and engagement in autism therapy. Sci. Robot. 2018, 3, eaao6760. [Google Scholar] [CrossRef]
- Egger, H.L.; Dawson, G.; Hashemi, J.; Carpenter, K.L.; Espinosa, S.; Campbell, K.; Brotkin, S.; Schaich-Borg, J.; Qiu, Q.; Tepper, M.; et al. Automatic emotion and attention analysis of young children at home: A ResearchKit autism feasibility study. NPJ Digit. Med. 2018, 1, 20. [Google Scholar] [CrossRef]
- Kolakowska, A.; Landowska, A.; Anzulewicz, A.; Sobota, K. Automatic recognition of therapy progress among children with autism. Sci. Rep. 2017, 7, 13863. [Google Scholar] [CrossRef]
- Chang, C.-H.; Saravia, E.; Chen, Y.-S. Subconscious Crowdsourcing: A feasible data collection mechanism for mental disorder detection on social media. In Proceedings of the2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 374–379. [Google Scholar]
- Van Der Krieke, L.; Jeronimus, B.; Blaauw, F.J.; Wanders, R.B.; Emerencia, A.C.; Schenk, H.M.; De Vos, S.; Snippe, E.; Wichers, M.; Wigman, J.T.; et al. HowNutsAreTheDutch (HoeGekIsNL): A crowdsourcing study of mental symptoms and strengths. Int. J. Methods Psychiatr. Res. 2015, 25, 123–144. [Google Scholar] [CrossRef]
- Weber, I.; Mejova, Y. Crowdsourcing health labels: Inferring body weight from profile pictures. In Proceedings of the 6th International Conference on Digital Health Conference, Montreal, QC, Canada, 11–13 April 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 105–109. [Google Scholar]
- Alvaro, N.; Conway, M.; Doan, S.; Lofi, C.; Overington, J.; Collier, N. Crowdsourcing Twitter annotations to identify first-hand experiences of prescription drug use. J. Biomed. Informatics 2015, 58, 280–287. [Google Scholar] [CrossRef]
- Gottlieb, A.; Hoehndorf, R.; Dumontier, M.; Altman, R.B.; Johnson, K. Ranking Adverse Drug Reactions with Crowdsourcing. J. Med. Internet Res. 2015, 17, e80. [Google Scholar] [CrossRef]
- Ariffin, I.; Solemon, B.; Abu Bakar, W.M.L.W. An evaluative study on mobile crowdsourcing applications for crime watch. In Proceedings of the 6th International Conference on Information Technology and Multimedia, Putrajaya, Malaysia, 18–20 November 2014; IEEE: Piscataway, NJ, USA, 2015; pp. 335–340. [Google Scholar]
- Evans, M.B.; O’Hara, K.; Tiropanis, T.; Webber, C. Crime applications and social machines: Crowdsourcing sensitive data. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 891–896. [Google Scholar]
- Williams, C. Crowdsourcing Research: A Methodology for Investigating State Crime. State Crime J. 2013, 2, 30–51. [Google Scholar] [CrossRef]
- Choy, G.; Khalilzadeh, O.; Michalski, M.; Synho, D.; Samir, A.E.; Pianykh, O.S.; Geis, J.R.; Pandharipande, P.V.; Brink, J.A.; Dreyer, K.J. Current Applications and Future Impact of Machine Learning in Radiology. Radiology 2018, 288, 318–328. [Google Scholar] [CrossRef]
- Gargeya, R.; Leng, T. Automated Identification of Diabetic Retinopathy Using Deep Learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef]
- Iwabuchi, S.J.; Liddle, P.F.; Palaniyappan, L. Clinical Utility of Machine-Learning Approaches in Schizophrenia: Improving Diagnostic Confidence for Translational Neuroimaging. Front. Psychol. 2013, 4, 95. [Google Scholar] [CrossRef]
- Yu, K.-H.; Beam, A.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- Hsueh, P.-Y.; Melville, P.; Sindhwani, V. Data quality from crowdsourcing: A study of annotation selection criteria. In Proceedings of the NAACL HLT 2009 Workshop on Active Learning for Natural Language Processing, Yorktown Heights, NY, USA, 5 June 2009; pp. 27–35. [Google Scholar]
- Welinder, P.; Perona, P. Online crowdsourcing: Rating annotators and obtaining cost-effective labels. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 25–32. [Google Scholar]
- Kittur, A.; Chi, E.H.; Bongwon, S. Crowdsourcing user studies with Mechanical Turk. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 5–10 April 2008; pp. 453–456. [Google Scholar]
- Paolacci, G.; Jesse, C.; Panagiotis, G.I. Running experiments on amazon mechanical turk. Judgm. Decis. Mak. 2010, 5, 411–419. [Google Scholar]
- Gardlo, B.; Ries, M.; Hossfeld, T.; Schatz, R. Microworkers vs. facebook: The impact of crowdsourcing platform choice on experimental results. In Proceedings of the 2012 Fourth International Workshop on Quality of Multimedia Experience, Yarra Valley, Australia, 5–7 July 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 35–36. [Google Scholar]
- Nguyen, N. Microworkers Crowdsourcing Approach, Challenges and Solutions. In Proceedings of the 2014 International ACM Workshop on Crowdsourcing for Multimedia, Orlando, FL, USA, 7 November 2014; p. 1. [Google Scholar]
- Hirth, M.; Hossfeld, T.; Tran-Gia, P. Anatomy of a crowdsourcing platform-using the example of microworkers. com. In Proceedings of the 2011 Fifth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Korean Bible University, Seoul, Korea, 30 June–2 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 322–329. [Google Scholar]
- Levy, S.; Duda, M.; Haber, N.; Wall, D.P. Sparsifying machine learning models identify stable subsets of predictive features for behavioral detection of autism. Mol. Autism 2017, 8, 65. [Google Scholar] [CrossRef]
- Tariq, Q.; Daniels, J.; Schwartz, J.; Washington, P.; Kalantarian, H.; Wall, D.P. Mobile detection of autism through machine learning on home video: A development and prospective validation study. PLoS Med. 2018, 15, e1002705. [Google Scholar] [CrossRef]
- Guy, W. ECDEU Assessment Manual for Psychopharmacology; US Department of Health, Education, and Welfare, Public Health Service, Alcohol, Drug Abuse, and Mental Health Administration, National Institute of Mental Health, Psychopharmacology Research Branch, Division of Extramural Research Programs: Rockville, MD, USA, 1976.
- Lord, C.; Rutter, M.; Goode, S.; Heemsbergen, J.; Jordan, H.; Mawhood, L.; Schopler, E. Austism diagnostic observation schedule: A standardized observation of communicative and social behavior. J. Autism Dev. Disord. 1989, 19, 185–212. [Google Scholar] [CrossRef]
- Ahmed, N.; Raheem, E.; Rahman, N.; Khan, M.Z.R.; Al Mosabbir, A.; Hossain, M.S. Managing autism spectrum disorder in developing countries by utilizing existing resources: A perspective from Bangladesh. Autism 2018, 23, 801–803. [Google Scholar] [CrossRef]
- Ehsan, U.; Sakib, N.; Haque, M.; Soron, T.; Saxena, D.; Ahamed, S.; Schwichtenberg, A.; Rabbani, G.; Akter, S.; Alam, F.; et al. Confronting Autism in Urban Bangladesh: Unpacking Infrastructural and Cultural Challenges. EAI Endorsed Trans. Pervasive Health Technol. 2018, 4. [Google Scholar] [CrossRef]
- Gona, J.K.; Newton, C.R.; Rimba, K.K.; Mapenzi, R.; Kihara, M.; Van De Vijver, F.J.R.; Abubakar, A. Challenges and coping strategies of parents of children with autism on the Kenyan coast. Rural. Remote Health 2016, 16, 3517. [Google Scholar]
- Ryan, C.M.M.; Diana, M.; Jumadiao, J.J.S.U.; Angel, J.J.Q.; Leonard, J.P.R.; Yoshiki, B.K. Awetism: A User Ergonomic Learning Management System Intended for Autism Diagnosed Students in the Philippines. In Proceedings of the International Conference on Industrial Engineering and Operations Management, Bandung, Indonesia, 6–8 March 2018. [Google Scholar]
- Mazefsky, C.A.; Oswald, D. The discriminative ability and diagnostic utility of the ADOS-G, ADI-R, and GARS for children in a clinical setting. Autism 2006, 10, 533–549. [Google Scholar] [CrossRef]
- James, E.G. Gilliam Autism Rating Scale: Examiner’s Manual; Pro-Ed: Austin, TX, USA, 1995. [Google Scholar]
- Zander, E.; Willfors, C.; Berggren, S.; Choque-Olsson, N.; Coco, C.; Elmund, A.; Moretti, Å.H.; Holm, A.; Jifält, I.; Kosieradzki, R.; et al. The objectivity of the Autism Diagnostic Observation Schedule (ADOS) in naturalistic clinical settings. Eur. Child Adolesc. Psychiatry 2015, 25, 769–780. [Google Scholar] [CrossRef]
- Brawley, A.M.; Pury, C.L.S. Work experiences on MTurk: Job satisfaction, turnover, and information sharing. Comput. Hum. Behav. 2016, 54, 531–546. [Google Scholar] [CrossRef]
- Necka, E.A.; Cacioppo, S.; Norman, G.J.; Cacioppo, J.T. Measuring the Prevalence of Problematic Respondent Behaviors among MTurk, Campus, and Community Participants. PLoS ONE 2016, 11, e0157732. [Google Scholar] [CrossRef]
- Washington, P.; Paskov, K.M.; Kalantarian, H.; Stockham, N.; Voss, C.; Kline, A.; Patnaik, R.; Chrisman, B.; Varma, M.; Tariq, Q.; et al. Feature Selection and Dimension Reduction of Social Autism Data. Pac. Symp. Biocomput. 2020, 25, 707–718. [Google Scholar] [PubMed]
- Lord, C.; Rutter, M.; Le Couteur, A. Autism Diagnostic Interview-Revised: A revised version of a diagnostic interview for caregivers of individuals with possible pervasive developmental disorders. J. Autism Dev. Disord. 1994, 24, 659–685. [Google Scholar] [CrossRef] [PubMed]
- Rutter, M.; Bailey, A.; Lord, C.; Cianchetti, C.; Fancelli, G.S. Social Communication Questionnaire; Western Psychological Services: Los Angeles, CA, USA, 2003. [Google Scholar]
- Sparrow, S.S.; Cicchetti, D.; Balla, D.A. Vineland Adaptive Behavior Scales, 2nd ed.; NCS Pearson Inc.: Minneapolis, MN, USA, 2005. [Google Scholar]
- Carrow-Woolfolk, E. Oral and Written Language Scales; American Guidance Service: Circle Pines, MN, USA, 1995; Volume 93, pp. 947–964. [Google Scholar]
- Phelps-Terasaki, D.; Phelsp-Gunn, T. Test of Pragmatic Language (TOPL-2); Pro-Ed: Austin, TX, USA, 2007. [Google Scholar]
- Wechsler, D. WISC-V: Technical and Interpretive Manual; NCS Pearson, Incorporated: Bloomington, MN, USA, 2014. [Google Scholar]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Washington, P.; Leblanc, E.; Dunlap, K.; Penev, Y.; Kline, A.; Paskov, K.; Sun, M.W.; Chrisman, B.; Stockham, N.; Varma, M.; et al. Precision Telemedicine through Crowdsourced Machine Learning: Testing Variability of Crowd Workers for Video-Based Autism Feature Recognition. J. Pers. Med. 2020, 10, 86. https://doi.org/10.3390/jpm10030086
Washington P, Leblanc E, Dunlap K, Penev Y, Kline A, Paskov K, Sun MW, Chrisman B, Stockham N, Varma M, et al. Precision Telemedicine through Crowdsourced Machine Learning: Testing Variability of Crowd Workers for Video-Based Autism Feature Recognition. Journal of Personalized Medicine. 2020; 10(3):86. https://doi.org/10.3390/jpm10030086
Chicago/Turabian StyleWashington, Peter, Emilie Leblanc, Kaitlyn Dunlap, Yordan Penev, Aaron Kline, Kelley Paskov, Min Woo Sun, Brianna Chrisman, Nathaniel Stockham, Maya Varma, and et al. 2020. "Precision Telemedicine through Crowdsourced Machine Learning: Testing Variability of Crowd Workers for Video-Based Autism Feature Recognition" Journal of Personalized Medicine 10, no. 3: 86. https://doi.org/10.3390/jpm10030086
APA StyleWashington, P., Leblanc, E., Dunlap, K., Penev, Y., Kline, A., Paskov, K., Sun, M. W., Chrisman, B., Stockham, N., Varma, M., Voss, C., Haber, N., & Wall, D. P. (2020). Precision Telemedicine through Crowdsourced Machine Learning: Testing Variability of Crowd Workers for Video-Based Autism Feature Recognition. Journal of Personalized Medicine, 10(3), 86. https://doi.org/10.3390/jpm10030086