1. Introduction
With growing interest in embodied intelligence [
1], emotion recognition has gained renewed attention as a core mechanism for enabling machines to perceive and respond to human affective states [
2]. It supports a range of applications, from personalized education [
3] to emotion-aware intelligent systems [
4], ultimately contributing to more human-centered technologies [
5]. Most existing emotion recognition systems rely on non-physiological cues such as facial expressions, speech, or text [
6]. While effective in controlled environments, these signals are often susceptible to environmental noise, voluntary masking, and cultural variability, limiting their robustness and generalizability in real-world scenarios. In contrast, physiological signals—such as EEG and EDA—offer a direct, unconscious reflection of emotional states, and demonstrate advantages in real-time responsiveness, data richness, and sensitivity to individual differences [
7], making them promising for emotion-aware systems in practice [
8,
9].
However, most existing physiological approaches rely on single-modal signals, which are insufficient to capture the complexity and dynamics of human emotions [
10,
11]. Multimodal physiological emotion recognition has thus gained increasing attention for its potential to leverage complementary information across modalities, enhancing recognition accuracy and improving generalization, especially in cross-subject scenarios. However, naive fusion strategies often introduce alignment mismatches, redundant information, and noise-induced distortions, ultimately degrading system performance [
12].
Recent progress in deep learning, particularly the development of Transformer architectures, has introduced new opportunities for multimodal physiological emotion recognition. With powerful capabilities in feature extraction and interaction modeling, Transformers effectively capture complex dependencies across modalities and have demonstrated significant improvements in recognition accuracy [
13,
14,
15]. Among these efforts, Wang et al. [
16] proposed the Cross-modal Transformer (CT), a representative architecture that models both intra- and inter-modal relationships to enhance feature representation. However, CT does not explicitly address inter-subject variability—where physiological responses to identical emotional stimuli may differ substantially across individuals—limiting its generalization in cross-subject scenarios, which remains a key challenge in physiological emotion recognition.
To address the limitations of existing cross-modal models in handling subject variability and semantic misalignment, we propose CT-ELCAN, a novel end-to-end architecture designed to learn emotionally meaningful, modality-invariant, and subject-independent representations. The core idea of CT-ELCAN is to shift the focus from direct multimodal feature fusion to the alignment of emotionally meaningful, modality-invariant, and subject-independent representations. This perspective treats multimodal emotion recognition as a problem of semantic-level alignment across heterogeneous physiological inputs and individual differences, rather than a simple signal integration task.
CT-ELCAN consists of two major components: a cross-modal Transformer module and an Enhanced Learning-Classifying Adversarial Network (ELCAN). While the Transformer is responsible for modeling contextual interactions across heterogeneous physiological modalities, ELCAN plays the central role in improving model robustness and generalization. ELCAN is designed to extract emotion-discriminative yet subject-invariant representations through adversarial alignment, aligning feature distributions at the semantic level while preserving classification performance. Together, both modules enable CT-ELCAN to effectively capture shared emotional representations while resisting overfitting and identity bias. Despite its integrated design, CT-ELCAN must address the following technical challenges:
Multimodal feature heterogeneity. This challenge refers to the difficulty of effectively integrating features derived from different physiological modalities. It arises from inconsistencies in sampling rates, temporal resolution, and data format across modalities. Such heterogeneity disrupts feature compatibility and hampers the model’s ability to extract semantically aligned emotional representations.
Inter-subject variability. This challenge involves the inconsistency of emotional patterns across individuals, even under the same stimulus conditions. It stems from individual differences in physiological structure, emotional expression style, and sensor sensitivity. These variations hinder the model’s ability to learn generalized representations, limiting its performance on unseen subjects.
Adversarial training instability. This challenge reflects the inherent tension between learning features that are both emotion-discriminative and subject-invariant. It emerges from the conflicting optimization goals of the emotion classifier and the subject discriminator during adversarial training. Such conflict can destabilize gradient updates, leading to convergence difficulties and degraded performance.
CT-ELCAN addresses these challenges through three targeted strategies. Firstly, the cross-modal Transformer employs modality-aware attention mechanisms to reduce inter-modality discrepancies and improve semantic alignment across heterogeneous features. Secondly, adversarial learning in ELCAN is applied to minimize subject-related variance while maintaining emotion-discriminative capability, thus enhancing the generalization across individuals. Lastly, to mitigate the instability of adversarial training, CT-ELCAN integrates two complementary mechanisms: a Gradient Reversal Layer (GRL) combined with a triplet adversarial loss to balance competing optimization objectives, and a conditional Signal-Adaptive GAN (c-SAGAN) to generate subject-aware augmented samples that improve distributional robustness and training stability.
The main contributions of this paper are summarized as follows:
We propose ELCAN, an enhanced adversarial learning-classifying network that integrates gradient-based feature alignment and conditional data augmentation. By jointly optimizing classification and invariance objectives, ELCAN effectively learns modality-invariant and subject-independent emotional representations, thereby improving generalization across subjects and modalities.
Based on ELCAN, we develop CT-ELCAN, an end-to-end multimodal emotion recognition framework that combines a cross-modal Transformer for contextual feature modeling with ELCAN for robust, invariant representation learning. This unified design enables effective semantic alignment across heterogeneous signals while maintaining emotional discriminability.
The remainder of this paper is organized as follows:
Section 2 reviews the related work;
Section 3 introduces the preliminary knowledge;
Section 4 presents the detailed architecture and training strategy of CT-ELCAN;
Section 5 reports the experimental results and performance comparison; we discuss some limitation of CT-ELCAN in
Section 6 and concludes this paper in
Section 7.
This article is a revised and expanded version of a paper entitled “CAT-LCAN: A Multimodal Physiological Signal Fusion Framework for Emotion Recognition [
17]”, which was presented at BICS 2024 (The 14th International Conference on Advances in Brain Inspired Cognitive Systems (Heifei, Anhui, China in 6 December 2024–28 January 2025)).
4. Methodology
4.1. Algorithm Overview
This section presents the overall architecture and module designs of the proposed CT-ELCAN framework. CT-ELCAN is developed to address three key challenges in multimodal physiological emotion recognition: (i) heterogeneity across signal modalities, (ii) individual variability among subjects, and (iii) instability in adversarial training. As shown in
Figure 2, the entire system consists of two main components: the Cross-modal Transformer (CT) and the Enhanced Learning-Classifying Adversarial Network (ELCAN).
In the first stage, raw physiological signals from different modalities (e.g., EEG, EOG, EMG, and GSR) are independently projected into a unified feature space via 1D pointwise convolution, followed by positional encoding. These signals are then processed by a multi-layer cross-modal Transformer encoder to obtain contextualized unimodal features and a fused multimodal representation. Benefiting from the cross-modal attention mechanism of the Transformer, each modality-specific feature captures not only its own long-term information but also integrates semantically aligned signals from other modalities. This facilitates cross-modal feature complementarity and improves the consistency of representations across modalities.
In the second stage, these enhanced modality-specific features are forwarded to the ELCAN module, which comprises two submodules: LCAN and c-SAGAN. LCAN performs adversarial training to encourage the learning of modality and subject-invariant features, thus enhancing model generalization across unseen individuals and conditions. Meanwhile, c-SAGAN introduces a category-aware adversarial generation mechanism to assist feature alignment and promote training stability. The full system is trained end-to-end with jointly optimized classification and adversarial objectives. The following subsections describe the individual components of CT-ELCAN in detail.
4.2. Cross-Modal Transformer Module
To address the heterogeneity of multimodal physiological signals, CT-ELCAN adopts a Cross-modal Transformer (CT) module as its backbone feature extractor. Since CT is a well-studied approach and has already been introduced in detail in
Section 3, we do not revisit the underlying model here. Instead, we briefly outline its configuration and role within the CT-ELCAN framework.
As illustrated in the upper portion of
Figure 2, each input modality (e.g., EEG, EOG, EMG, and GSR) is first projected into a unified feature space using one-dimensional pointwise convolution. Positional encodings are then added to preserve the temporal structure of the sequences. The resulting representations are processed by a Transformer encoder consisting of 3 layers, each with 4 attention heads and a hidden size of 128. This yields modality-specific features that are complementary, semantically enriched, and mutually informed through cross-modal attention, which are subsequently forwarded to the ELCAN module for adversarial alignment and downstream emotion recognition.
To enhance cross-subject generalization and mitigate overfitting, we propose a novel adversarial alignment module: the Enhanced Learning-Classifying Adversarial Network (ELCAN). As illustrated by the cyan-colored components in
Figure 2, ELCAN is positioned downstream of the Cross-modal Transformer and consists of two sequentially connected sub-modules: c-SAGAN and LCAN. The c-SAGAN module performs conditional data augmentation by generating diverse, label-consistent training samples across modalities. Its outputs are then fed into the LCAN module, which applies adversarial training to extract modality-invariant and subject-invariant features. Together, these modules form an integrated pipeline that strengthens the generalization and robustness of the overall framework. In the following sections, we describe c-SAGAN and LCAN in the order they appear in the data processing pipeline.
c-SAGAN Submodule
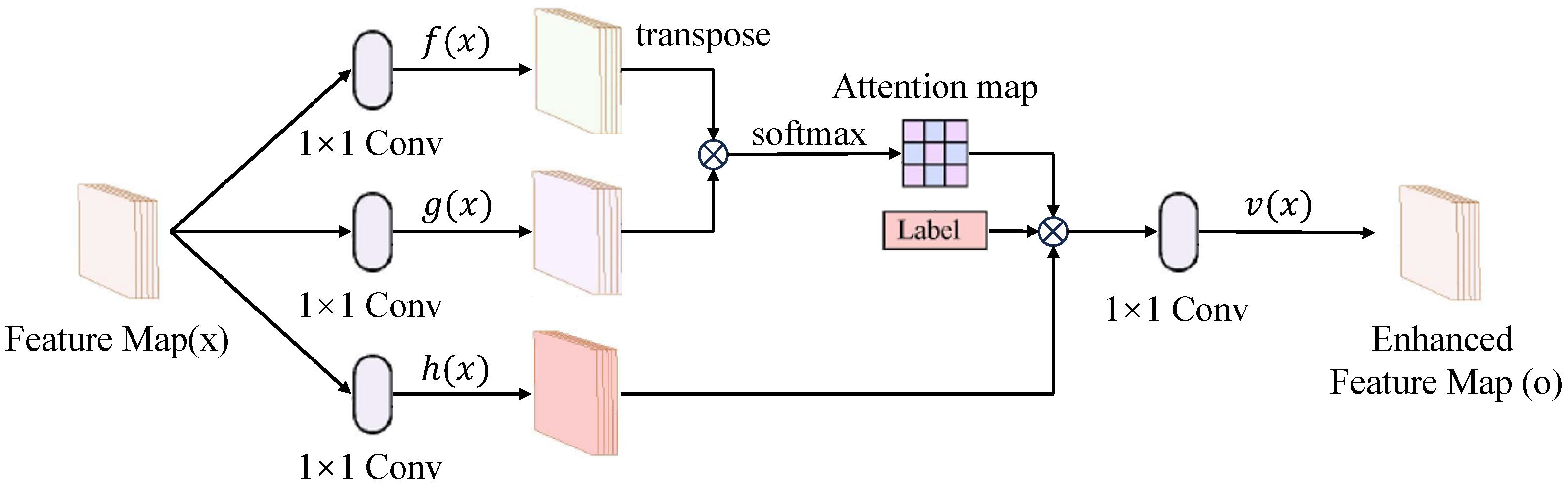
To overcome the limitations of conventional emotional data generation methods, including insufficient sample diversity and inadequate alignment with target emotional categories, we propose a conditional self-attention GAN (c-SAGAN). The core idea of c-SAGAN is to enhance both the realism and label consistency of generated data by incorporating auxiliary emotional labels and self-attention mechanisms into the classical SAGAN framework. This design allows the model to better capture global dependencies and category-specific features within multimodal physiological signals.
As illustrated in
Figure 3, the generator in c-SAGAN takes modality-specific feature maps
x extracted from the Cross-modal Transformer as its primary input. During training, it also incorporates random noise
z sampled from a prior distribution and an auxiliary emotional label
drawn from the target label space. These additional components guide the conditional generation process and ensure that the synthesized outputs are aligned with specific emotional categories. The discriminator then evaluates both real samples
and generated samples
, assessing their authenticity and semantic consistency conditioned on
.
4.3. ELCAN Module
To capture long-range dependencies within each modality, the generator integrates a self-attention mechanism. The input x is projected into three latent representations , , and using convolutional layers. Here, and act as the query and key embeddings, respectively, and their inner product determines the attention score . These scores are normalized to compute the attention weights , which determine the influence of the i-th feature on the j-th position. A weighted sum over is then computed and transformed by , scaled by a learnable parameter , and added to the original input x via a residual connection. This process yields a globally contextualized and label-conditioned feature representation that is subsequently passed to the discriminator.
The model is trained using a hinge loss formulation. The discriminator aims to distinguish real from generated samples while ensuring that emotional semantics are preserved:
The generator is optimized to fool the discriminator while maintaining label consistency:
By combining conditional adversarial training with global self-attention, c-SAGAN enhances the representational quality of synthesized data, supporting more robust and generalizable downstream emotion recognition.
LCAN Submodule
Following c-SAGAN, the Learning-Classifying Adversarial Network (LCAN) is employed to align cross-modal and cross-subject feature distributions. As illustrated in
Figure 4, LCAN takes as input both the real multimodal features and the synthetic samples generated by c-SAGAN. Its objective is to learn modality-invariant and subject-independent representations that support robust emotion recognition.
LCAN consists of five functional components: the Feature Learning Module, Modality Classifier, Subject Classifier, Multimodal Fusion Module, and Emotion Classifier. The Feature Learning Module receives the enhanced intermediate unimodal features
and transforms them into high-level representations
using a convolutional block:
where
includes a sequence of convolution, normalization, activation, and pooling layers. Here,
L denotes the temporal length of the feature sequence, and
D is the feature dimension.
The outputs from all modalities are concatenated to form a multimodal representation
:
where
denotes the total temporal length after concatenating all modalities.
To encourage modality- and subject-invariant representations, we use two auxiliary classifiers. The Modality Classifier receives
and predicts the modality label:
The Subject Classifier takes
as input and predicts the subject label:
where
and
denote the classifier mapping functions, and
and
are the true modality and subject labels. Here,
and
denote the cross-entropy losses for modality and subject classification, respectively, which are used in adversarial training to enforce modality- and subject-invariant representations.
The Feature Learning Module is trained adversarially against these classifiers. While the classifiers aim to minimize their respective losses, the feature extractor seeks to maximize them to eliminate modality- and subject-specific signals:
The fused multimodal feature
is further passed to the emotion classifier, composed of two fully connected layers:
where
is the mapping function of the classifier and
is the ground-truth emotion label. Here,
represents the standard cross-entropy loss for emotion prediction.
To align the opposing training objectives and enable joint optimization, a Gradient Reversal Layer (GRL) is introduced between the feature extractor and both auxiliary classifiers. During backpropagation, GRL inverts the gradients of adversarial losses, allowing the overall network to be trained end-to-end.
The final objective integrates all components:
where
,
,
, and
are scalar weights to balance the contributions of the respective losses. Here,
is the combined hinge loss derived from the c-SAGAN generator and discriminator. All components are trained jointly in an end-to-end manner using the aggregated loss
.
Through this iterative adversarial training process, LCAN effectively disentangles modality and subject biases, yielding more robust and generalizable emotional representations for downstream recognition.
5. Performance Evaluation
5.1. Dataset and Experimental Setup
We evaluated the proposed CT-ELCAN model on two widely used public datasets of multimodal physiological signals: the DEAP dataset [
25] and the WESAD dataset [
32]. For the DEAP dataset, we performed binary classification tasks based on the valence and arousal dimensions of emotion. For the WESAD dataset, a three-class classification task was conducted to distinguish among neutral, stressed, and amused emotional states.
To ensure fairness and robustness in evaluation, we adopted a Leave-One-Subject-Out (LOSO) cross-validation strategy. In each iteration, one subject’s data were held out as the test set, while the remaining data were used for training. This process was repeated until every subject had been used once for testing, and the final performance was reported as the average accuracy across all subjects.
For model training, we adopted the Adam optimizer [
33] with a fixed learning rate of
, and applied gradient clipping when the gradient norm exceeded 10 to ensure training stability. All models were trained for 50 epochs with a batch size of 128 using the PyTorch (Version 2.0) framework [
34], executed on a GeForce GTX 1080Ti GPU. Task-level parallelism was optimized to accommodate hardware constraints. To further improve performance across training rounds, we employed a grid search strategy to comprehensively explore the hyperparameter space and identify the optimal configuration that maximizes model performance. The final parameter settings are summarized in
Table 1.
5.2. Experimental Results and Analysis
To evaluate the effectiveness and generalization ability of the proposed CT-ELCAN framework, we conducted comprehensive cross-subject comparative experiments under the Leave-One-Subject-Out (LOSO) cross-validation setting. We first compared CT-ELCAN with several widely adopted deep learning models, including CNN, LSTM, GRU, and Transformer. As shown in the upper part of
Table 2, these classical architectures exhibit limited ability to handle modality heterogeneity and inter-subject variability. Among them, the Transformer model achieves the highest accuracy, benefiting from its attention mechanism; however, it still falls short in terms of generalization.
To further assess performance, we compared CT-ELCAN against recent state-of-the-art methods, including single-modal EEG-based models such as TARDGCN [
35] and DSSN [
36], as well as multimodal physiological signal-based models such as RDFKM [
37], MCMT [
38], and DGR-ERPS [
39]. All models were trained and evaluated under identical experimental conditions to ensure fairness and comparability. The corresponding results are summarized in the lower part of
Table 2.
As shown in
Table 2, CT-ELCAN consistently outperforms all competing methods across four classification tasks. On the DEAP dataset, it achieves average accuracies of 70.82% and 71.34% for valence and arousal classification, respectively, surpassing the best-performing baseline RDFKM by over 7%. In the more challenging four-class classification task on DEAP, it also achieves the highest accuracy of 63.07%. On the WESAD dataset, CT-ELCAN reaches an accuracy of 73.93%, outperforming RDFKM by over 5%.
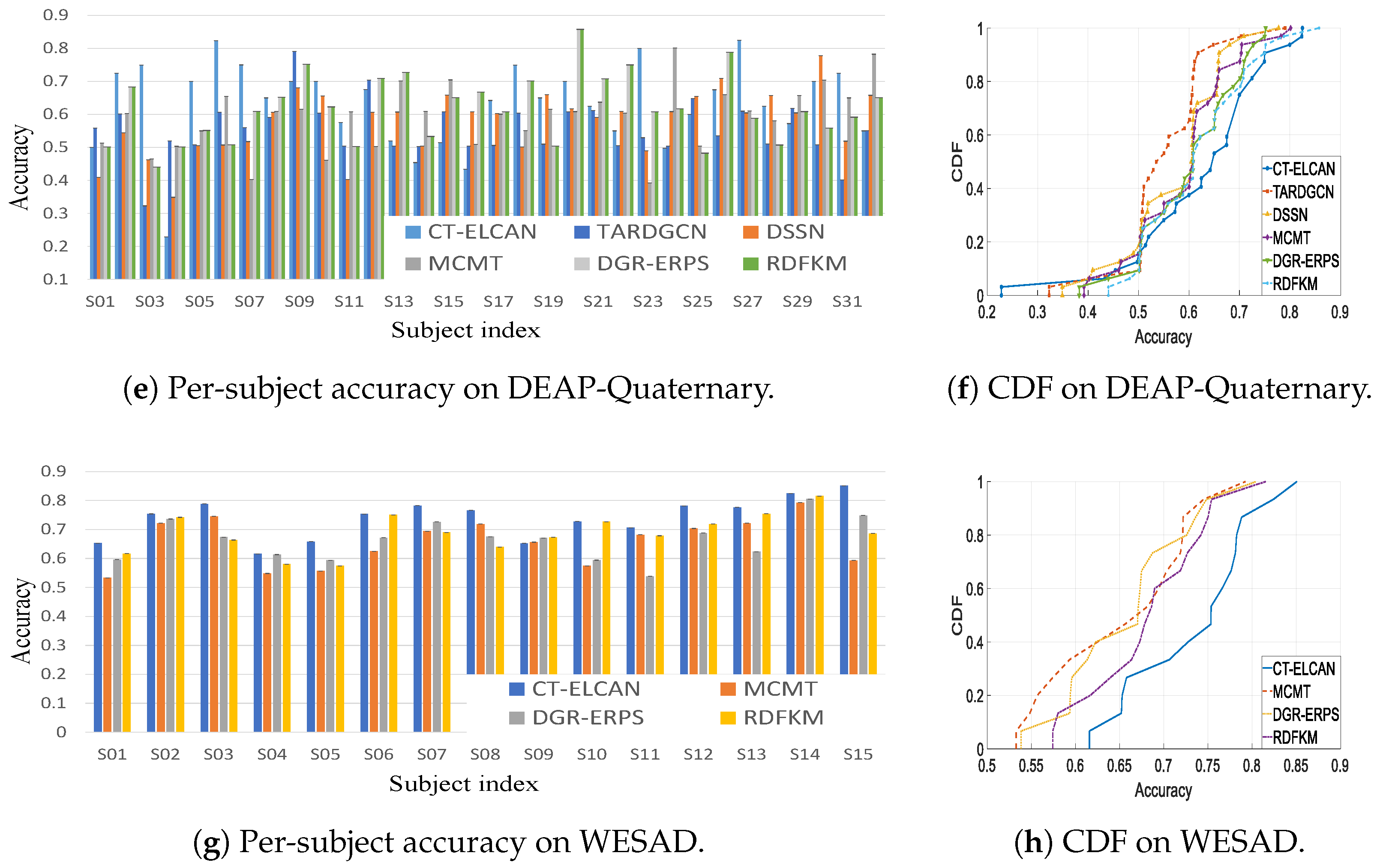
To better examine the model’s cross-subject generalization,
Figure 5 visualizes both the individual-level accuracy distribution (left) and the corresponding cumulative distribution function (CDF, right) for each classification task. The bar plots on the left side reflect how the model performs on each subject, showing CT-ELCAN’s stability across diverse individuals. The CDF curves on the right help quantify this stability by showing the proportion of subjects achieving a given accuracy threshold.
Across all tasks, CT-ELCAN shows consistently better CDF performance. On the DEAP-Valence task, 50% of subjects achieve at least 70.82% accuracy, compared to 62% for RDFKM. At the 90% percentile, CT-ELCAN reaches 78%, whereas RDFKM only reaches 74%. On DEAP-Arousal, CT-ELCAN surpasses RDFKM by 7.3% at the 90% mark. On DEAP-Quaternary and WESAD tasks, the advantage at the 90% percentile is also evident, with CT-ELCAN outperforming RDFKM by around 3% to 5%. These results confirm that CT-ELCAN not only improves average accuracy but also provides more stable performance across subjects.
5.3. Ablation Experiments
To comprehensively assess the contribution of each core module in the CT-ELCAN framework—namely the Cross-modal Transformer (CT), the Conditional Self-Attention Generative Adversarial Network (c-SAGAN), and the Learning-Classifying Adversarial Network (LCAN)—we conducted a series of ablation experiments. These experiments aim to reveal the individual roles and effectiveness of each component in improving overall model performance.
We first evaluated the impact of the data augmentation module c-SAGAN by conducting two comparative experiments: one in which c-SAGAN was completely removed (i.e., no augmentation), and another where it was replaced by a classic conditional Wasserstein GAN (c-WGAN). This setup allows us to verify the necessity of self-attention-based augmentation and compare different generation strategies. As shown in
Table 3, removing c-SAGAN leads to a significant drop in recognition accuracy on all tasks. For instance, the DEAP-Valence accuracy dropped from 70.82% (with c-SAGAN) to 65.11% without augmentation. Moreover, c-WGAN performed worse than both c-SAGAN and the non-augmentation baseline, highlighting the superiority of c-SAGAN in modeling complex multimodal patterns.
Next, we examined the effectiveness of adversarial learning in LCAN. As shown in
Table 4, removing the adversarial training process resulted in noticeable performance degradation across all tasks. For example, on the DEAP-Arousal task, accuracy dropped from 71.34% to 62.09%. Similarly, performance decreased by over 8% on the WESAD dataset. These results demonstrate the crucial role of LCAN in promoting cross-modal and cross-subject feature alignment and enhancing generalization.
Finally, we investigated the structural design of the CT module by varying the number of Transformer layers from 1 to 5 and introducing a baseline (CT-0) in which the Transformer was completely removed. As illustrated in
Table 5, model performance improves as the number of layers increases from 1 to 4, peaking at 70.82% (Valence) and 71.34% (Arousal). Adding a fifth layer slightly reduces performance, indicating potential overfitting. The CT-0 variant shows a drastic performance drop to 52.45% (Valence) and 50.23% (Arousal), confirming that the Transformer is indispensable for effectively modeling cross-modal dependencies.
In summary, the ablation study confirms that all three modules—CT, c-SAGAN, and LCAN—play essential roles in the CT-ELCAN framework. Each component contributes to performance gains in different but complementary ways. The Transformer captures complex inter-modal relationships, c-SAGAN enriches the training distribution with label-aware samples, and LCAN enforces feature invariance through adversarial training. Together, these modules collectively elevate the model’s accuracy, robustness, and generalizability in multimodal emotion recognition tasks.
5.4. Other Impact Factors
In the preceding experiments, we focused on multimodal emotion recognition tasks using the DEAP and WESAD datasets under ideal conditions with all four physiological modalities available. However, in real-world applications, collecting all modalities simultaneously is often impractical due to equipment limitations and high acquisition costs. Moreover, environmental factors during signal collection—such as noise interference or electrode displacement—may severely affect signal quality. To evaluate the practical robustness of the proposed CT-ELCAN model, we conducted additional experiments simulating two common scenarios: modality loss and signal degradation due to noise.
Using the DEAP dataset as an example, two evaluations were conducted: (1) Modality Loss Experiments, where each modality (EEG, EMG, EOG, and GSR) was individually removed to observe the resulting impact on recognition performance; and (2) Noise Interference Experiments, where Gaussian noise was artificially added to the full multimodal input to test the model’s tolerance to signal corruption.
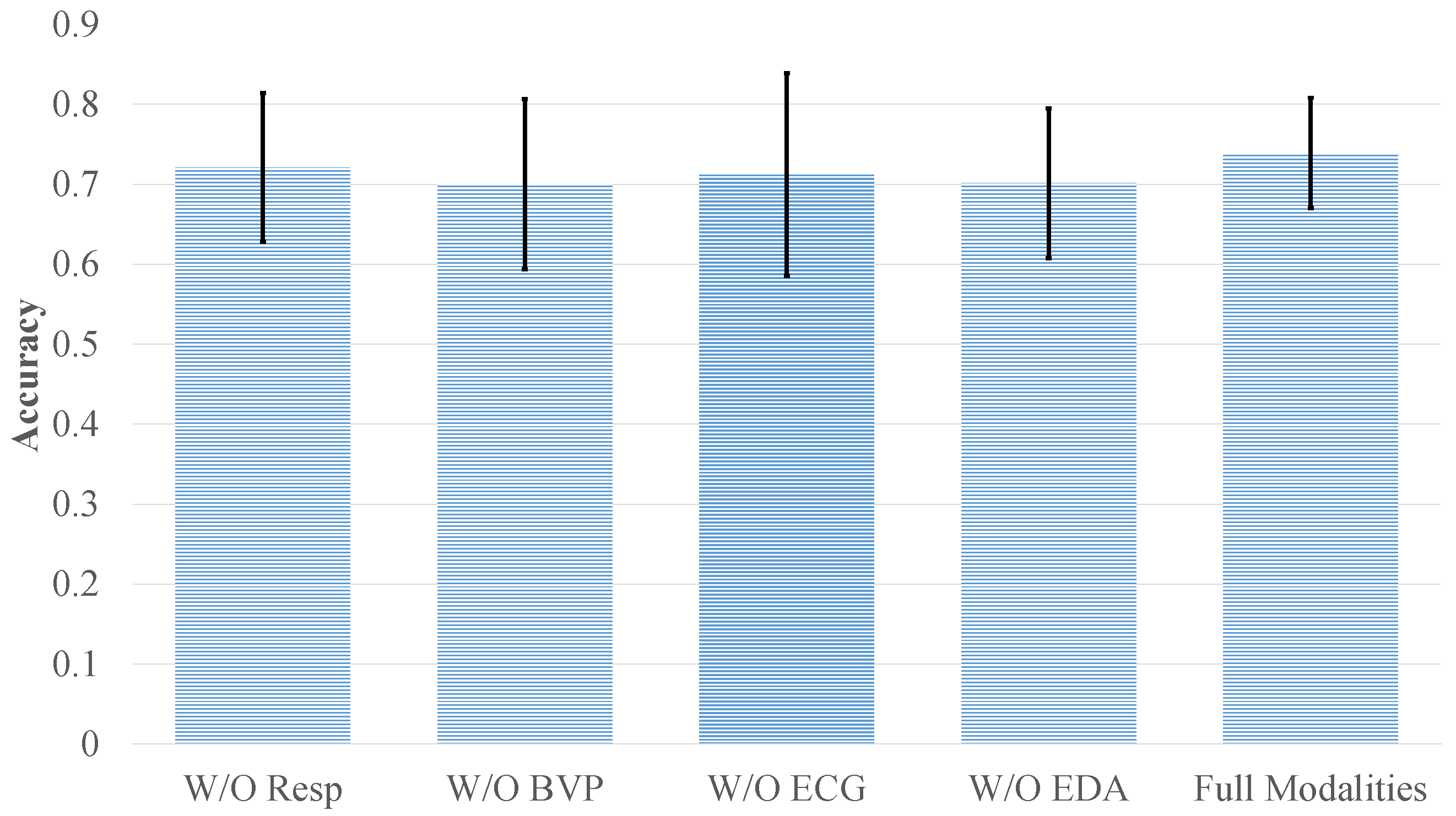
As shown in
Figure 6 and
Figure 7, removing modalities resulted in performance degradation of varying degrees for both datasets. On DEAP, removing EEG caused the largest accuracy drop—valence classification decreased to 51.18% (from 70.82%), and arousal dropped to 52.69% (from 71.34%). This confirms EEG’s primary contribution, as it encodes the most emotion-relevant information among the modalities. In contrast, the removal of EMG, EOG, or GSR led to moderate accuracy reductions: the four-category task dropped to 58.36%, 58.92%, and 55.89%, respectively, compared to 63.07% with all modalities.
Noise robustness was also verified, as shown in
Figure 8. Even after introducing Gaussian noise, the model retained relatively high accuracy on DEAP, with valence and arousal scores dropping only slightly to 67.08% and 66.88%, respectively—indicating just a 3–4% decline. Likewise, the quaternary classification task on DEAP and the three-class task on WESAD saw accuracy reductions of approximately 3% and 2%, respectively. These minor performance losses highlight CT-ELCAN’s strong resilience, which can be attributed to the internal data augmentation provided by c-SAGAN.
In summary, while the CT-ELCAN model exhibits sensitivity to modality absence—particularly EEG—it remains stable and effective under partial signal loss and noise interference. These findings confirm the model’s robustness and practical value, and they provide useful guidance for deployment in real-world environments where data incompleteness and signal artifacts are common.
6. Discussion
Although CT-ELCAN achieves strong performance in cross-subject emotion recognition, its applicability remains subject to several objective constraints.
First, the model relies on uniformly labeled data for supervised training, whereas emotional responses are inherently subjective. Different individuals may react differently to the same stimulus, and a single label may not accurately capture the true emotional state of each subject. This label uncertainty can limit the model’s ability to generalize across individuals. In our future work, we plan to incorporate label confidence modeling, soft supervision, or multi-annotator fusion strategies to improve robustness to subjective variability.
Second, the current model assumes that multimodal physiological signals are complete and temporally aligned. In real-world applications, however, signal dropout, modality loss, or desynchronization are common. The model’s robustness under such conditions remains limited. To address this, we intend to explore modality completion networks, uncertainty-aware fusion, and adaptive inference strategies based on available modalities.
Finally, while CT-ELCAN currently focuses on physiological modalities, we aim to extend our framework by integrating non-physiological signals such as speech, facial expressions, and text. These heterogeneous sources may enhance affective perception, but also introduce challenges such as modality alignment, temporal synchronization, and semantic fusion. Addressing these issues will be an important direction in our future research.
7. Conclusions
In this study, we proposed a novel framework for multimodal emotion recognition, termed CT-ELCAN, which integrates a Cross-modal Transformer (CT) with an Enhanced Learning-Classifying Adversarial Network (ELCAN). This design effectively addresses key challenges in multimodal physiological signal analysis, including inter-modality heterogeneity, subject variability, and training instability. Extensive experiments on two benchmark datasets, DEAP and WESAD, demonstrate that CT-ELCAN achieves substantial improvements in cross-subject recognition accuracy—surpassing existing state-of-the-art methods by approximately 7% and 5%, respectively. In addition, the model exhibits strong robustness and stability under challenging conditions such as modality loss and signal degradation, validating its practical applicability. Overall, the experimental results confirm the effectiveness of CT-ELCAN in extracting modality-invariant and subject-invariant representations, offering a promising solution for robust and generalizable multimodal emotion recognition.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}