
Synergies vs. Clustering Only of Depressive Symptoms in Diabetes and Co-Occurring Conditions: Symmetric Indicators with Asymmetric, Bidirectional Influences in MIMIC Models


Abstract
1. Introduction
1.1. Limitations of Research on Symptom Clusters and the Call for the Current Study
1.2. The Evolution of Regression-Based MIMIC Modeling in Symptom Clusters Research
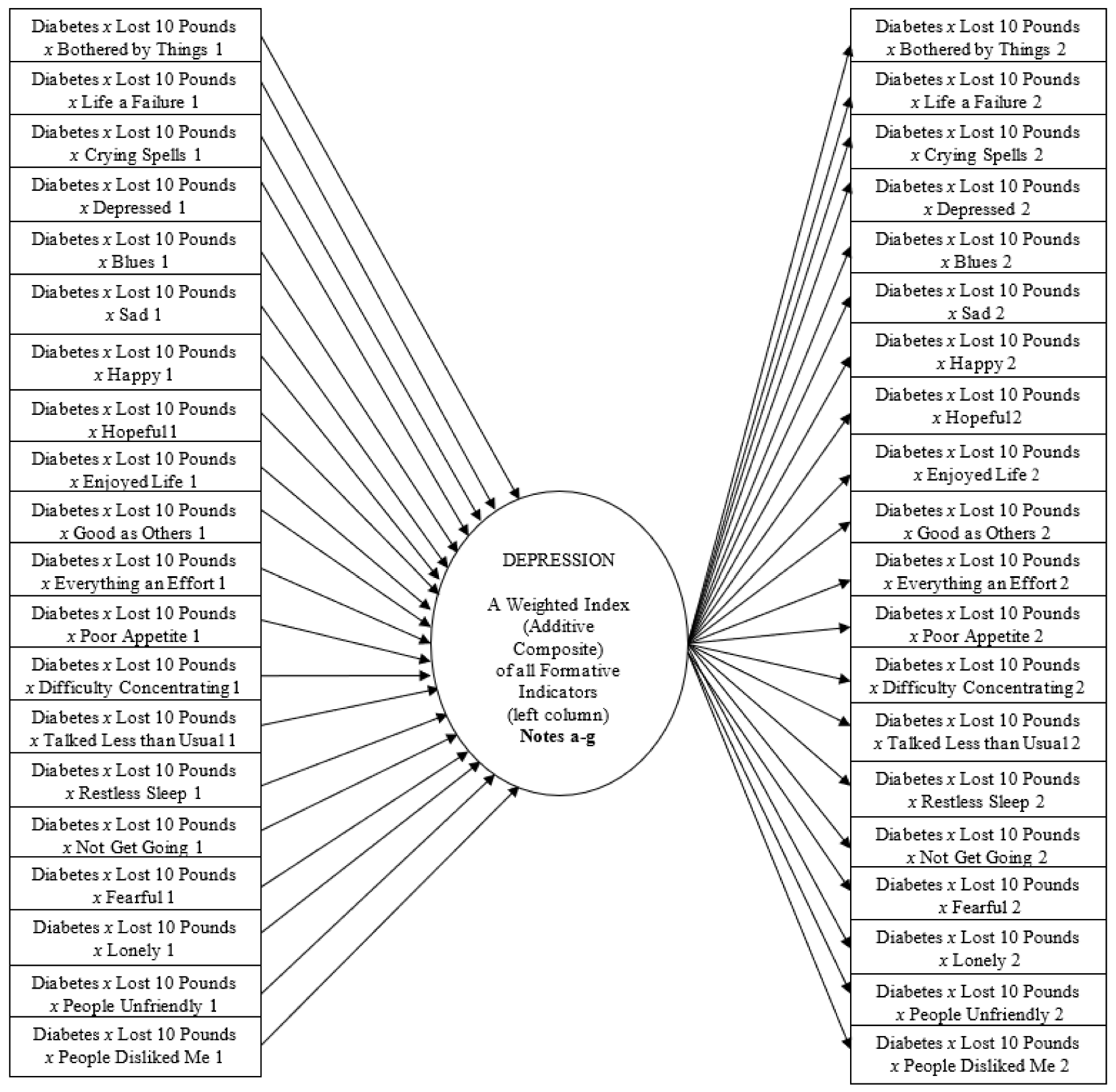
1.3. Using MIMIC Symmetry/Asymmetry to Screen Depression in Diabetes Comorbidities
- The dichotomous predictors (Diabetes, Lost 10 Pounds) represent the presence/absence of the condition. The CES-D indicators are ordinal with five categories. The same variables are components of the three-way interaction terms in the far-left column (estimated using moderated regression) and the symmetric multiplicative terms in the far-right column (estimated using confirmatory factor analysis). The MIMIC model also specifies the derivative one-way terms of these component variables in the structural portion of the model (estimated using moderated regression), and all two-way combinations among them, as both interaction and multiplicative terms, but the figure excludes them to simplify the presentation.
- Each three-way interaction term reveals the additional effect of synergy when all three components co-occur (i.e., the specific depressive symptom in participants with diabetes who lost ten pounds over the past three months).
- The symmetric multiplicative term reveals the correlation of those three co-occurring components (in b) to the nonreactive clustering across the depressive symptoms, either targeted only within this overall disease subgroup (even when participants report no depression symptoms), or assessed more broadly across the sample. [In the latter, although the figure excludes the one- and two-way terms to simplify the presentation, the two-way interaction term representing the disease group (Diabetes x Lost Ten Pounds) predicts each one-way non-multiplicative depressive symptom across the sample (later reported in the first footnote of each table)].
- Synergies and clustering occur after adjusting for endorsement attributed to the overall level of the weighted index (additive composite) of Depression.
- If we drop the component terms representing the two disease conditions, and the interactions and multiplicative terms involving them, estimates will be for participants across the entire panel sample rather than within the targeted disease subgroup (later reported as the first entry in the initial table).
- The residual term of the structural model is equal to zero since the weighted index (additive composite) of Depression is perfectly predicted and determinate (non-stochastic). I also exclude arrows to reflect the measurement error terms from each of the CES-D items in order to simplify the presentation.
- See Figure S1 (in Supplementary Materials) for the appropriate portion of the syntax to run this regression-based MIMIC model in the Mplus software program.
2. Materials and Methods
2.1. The Sample, Variables, and Estimator
2.2. Specifying, Targeting, and Reporting the MIMIC Models
2.3. Asymmetry and Symptom Clusters
2.4. Asymmetric, Complementary Variation in Symmetrically Specified MIMIC Models
2.5. Properties and Superiority of MIMIC Models for Internal and External Validity
3. Results
4. Discussion
4.1. Interpreting Findings to Improve Screening
- In the full sample (Table 1): Diabetes x Hypertension with Medication; Diabetes x Lost Ten Pounds; Stroke/Post-Stroke Cognitive Impairment mediated by Diabetes; Vascular Cognitive Impairment mediated by Diabetes; and Alcohol Consumption mediated by Diabetes;
- By gender (Table 2): Diabetes x Silent Cerebrovascular Disease (Males); Diabetes x Excess Weight (Males); Diabetes x Heart Failure (Females); Diabetes x Smoking (Females); and Heart Attack mediated by Diabetes (Males);
- By age group (Table 3): Diabetes x Hypertension (Over Age 74); Diabetes x Hypertension with No Medication (Over Age 74); Diabetes x Silent Cerebrovascular Disease (Ages 65–74); Diabetes x Heart Attack (Over Age 74); Diabetes x Excess Weight (Ages 65–74); Diabetes x Heart Failure (Over Age 74); Diabetes x Smoking (Ages 65–74); Diabetes x Lost Ten Pounds (Ages 65–74); Stroke mediated by Diabetes (Ages 65–74); and Stroke or Post-Stroke Cognitive Impairment (Ages 65–74).
- Within the full sample (Table A1): Emaciated mediated by Diabetes;
- By gender (Table 2): Diabetes x Hypertension (Males); Diabetes x Heart Attack (Females); and Diabetes x Smoking (Males);
- By age group (Table 3): Diabetes x Hypertension (Ages 65–74); Diabetes x Hypertension with No Medication (Ages 65–74); Stroke with No Diabetes (Over Age 74); Vascular Cognitive Impairment (Over Age 74); and Vascular Cognitive Impairment (Over Age 74) mediated by Diabetes.
4.2. Modeling and Measurement Insights
4.3. Extensions and Applications
Supplementary Materials
Funding
Data Availability Statement
Conflicts of Interest
Appendix A (Introduction)
- 1.
- “When the (additive composite or weighted index) is controlled, only variation unique to each observed indicator remains. Predictor effects to the observed indicators have ‘local independence’ in that the observed items are conditionally independent of each other because the (additive composite or weighted index) accounts for the shared variation across the observed indicators. The addition of the structural model to CFA [confirmatory factor analysis] permits more valid modeling than CFA alone when symptoms, biomarkers, or metabolites may not all stem from a single biological pathway and confounding influences are more likely” [7] (pp. 1–2). “The simultaneous control for the level of the total panel allows estimation of more valid specific effects for individual metabolites, biomarkers, or symptoms” [7] (p. 6).A symmetric regression-based MIMIC model with duplicate items in the structural and measurement portions “…enables CFA either to be conducted across the sample or to be targeted within an overall group or interacting subgroup, while providing extensive and comprehensive control of confounding factors” [7] (p. 3). “[I]t can provide more extensive and comprehensive control of confounders than trying to specify each of them directly. Each unspecified confounder operates through its effect on each of the specified formative indicators that predict the (additive composite or weighted index)” [7] (p. 6).This symmetric MIMIC model adjusts formative indicators for confounding factors while modeling unique variation by the item that predicts the weighted index/additive composite. “[S]ymptoms that predict different portions of nonshared variation… may or may not also co-occur (leading, if they do, to multicollinearity and heteroscedasticity from the data for the particular observations concerned), but are dissimilar in their effects (i.e., they are not also based on common variation detected through factor analysis). The formative indicators approach is unique in modeling these multiple influences” [7], (p. 27).“Formative indicators tap the extent to which specific individual symptoms differ in their relationships to other symptoms. The formative indicators factor away biases from uncontrolled confounding factors, which could include differences in symptom expression in only some of the symptom items, or in smaller clusters with fewer symptoms, within the disease group or subgroup of interest. This strategy leaves the reflective indicators and the latent trait to tap the common or shared symptom expression across the full range of symptoms in the disease group or subgroup. It sidesteps the controversial issue as to whether symptoms should contribute variation to more than one symptom cluster because the formative indicators automatically factor out the influence of uncontrolled confounding factors, which may otherwise lead to heterogeneity in the effects of individual symptoms or across smaller subsets of symptoms” [7], (p. 27).See Francoeur [7] for a mathematical derivation of the regression-based MIMIC model.
- 2.
- There is a qualification to make when the MIMIC model with duplicate items does not specify interactions of the disease group or subgroup across the formative indicators. In these specifications, “… the statistical significance of two formative indicators does not mean that they constitute a symptom cluster within the same disease group or subgroup, only that these two formative indicators are significant in the sample at large” [3] (p. 30). However, the significance of interactions of the disease group or subgroup across the symptoms implies that they constitute a symptom cluster within the same disease group or subgroup, one with differential synergistic effects across the formative indicators.
Appendix B (Materials and Methods)
- 1.
- “The non-normality (skewness, kurtosis) captured in the structural (regression) portion of the MIMIC model engenders non-normality in the estimated ordinal probit latent variables “behind” each of the observed or manifest reflective indicators in the endogenous CFA portion. This non-normality would be absent in a pure CFA model with ordinal probit variables generated as normal. The non-normality improves detection of interaction terms (e.g., reflecting disease subgroups of coexisting conditions), which tap non-normal variation [5,6,7,8,9]” [7] (p. 28).
- 2.
- As described later in the main text, the current study involves ordinal logit, and not ordinal probit, latent variables generated by the maximum likelihood procedure (MLR) to estimate the MIMIC model parameters. MLR estimation is appropriate for non-independent data comprising a census of observations from participants living in either public or private residences for the elderly. MLR estimation is also appropriate for clustered random sampling, and therefore for non-independent data from participants living in their own homes. The ordinal logit estimates are for the latent variables “behind” the observed or manifest reflective indicators. The structural regression portion of the MIMIC model taps skewness and kurtosis that influence and shape the generated distributions of these latent variables in the measurement model portion, which incorporate this non-normality. These logit estimates also result in a logit distribution for the weighted index.
- 3.
- “Just because a latent trait can be postulated and estimated using confirmatory factor analysis (CFA) does not necessarily mean the derived latent trait is the most valid estimate of the true latent trait. A true latent trait should have the property that allows it to be modeled by dissimilar variation across formative symptoms that do not in themselves constitute a symptom cluster of reflective indicators” [7] (pp. 32–33).
- 4.
- Rather, they “… provide additional, exogenous modeling information to reveal statistically significant reflective symptoms and symptom clusters by identifying this more plausible latent trait equivalent to the additive composite of the formative indicators. By capturing all of the variation across these formative indicators (i.e., R2 = 1), this modeling provides determinacy of latent factor scores at the level of the individual observations because they are equivalent to the additive composite (weighted index) scores, in contrast to the indeterminacy of factor scores for individual observations from CFA outside of this MIMIC framework” [7] (p. 22).
- 5.
- Depending on the vantage point of observation, we can perceive the MIMIC model with identical formative and reflective indicators to have translation or reflection symmetries [35]. Disregarding the directional arrows of causation for the moment, we can perceive the two objects of the exogenous and endogenous portions of the MIMIC model to reflect translation symmetry because we can simply slide the name of each formative indicator to the right side where it becomes the reflective indicator for the same item. Rather than focusing on the two separate objects, the incorporation of the directional arrows within each object either to or from the weighted composite would reveal the existence of reflection symmetry across a hypothetical vertical line that bisects the weighted composite circle in the MIMIC model. Flipping over either half of the MIMIC model about the line (180 degrees) reveals a reflection or mirror image of the other half. However, as with objects in a mirror, this reflection of the name for each formative indicator (or data it incorporates) reads backwards for its corresponding reflective indicator, in contrast to the sliding of the name (or data) from left to right in translation symmetry. The MIMIC model does not share this feature of reflection symmetry because the name and data appear in a forward direction in the formative and reflective indicators. Despite the properties of translation and reflection symmetries, the use of moderated regression in the formative indicators (to assess independent variation in each predictor) and confirmatory factor analysis in the reflective indicators (to assess shared variation across predictors) reveal these two procedures to be asymmetric. They are also mutually exclusive and complementary in the portion of the overall variation that they model within and across the same survey or panel items.In the structure of the MIMIC model, there is reflection symmetry between the variables reflected as formative indicators and their respective reflective indicators. However, the use of different statistical analysis methods results in an asymmetric assessment of the total variation within each item (i.e., unique versus shared), specified as a formative versus a corresponding reflective indicator. What becomes a “mirror image” based on rotation about the line through the center of the weighted composite is the direction of the arrow of causation when rotating a formative indicator to become a reflective indicator (or vice versa). The item represented by the indicator remains identical to the formative and reflective indicators, but its causal direction changes from causing to reflecting the effect of the weighted composite. Thus, the symmetry (mirror-image quality) depends only on the change in direction of the arrow of causation. The item itself remains unchanged. The reflective indicator is not the mirror image of the formative indicator; it is a duplicated image, rather than symmetrical one, and therefore it only represents a symmetrical relation. In set theory, a = b means b = a, or in the CES-D depression inventory, two different variable names (e.g., sad = sad2 means sad2 = sad) reflect the same item (see [36]). The symmetrical relation is necessary to identify duplicate variables because a (or sad) is endogenous (estimated by the MIMIC model) and b (or sad2) is exogenous (information from outside the MIMIC model [3]. In addition, ordinal regression predicts b (or sad2) as a categorical outcome variable in the measurement (confirmatory factor analysis) portion of the MIMIC model while a (or sad) operates as a continuous (strictly speaking, as a “countably” continuous) variable predictor in the structural (regression) portion of the MIMIC model, although estimates would result even if the outcome variable was continuous.
- 6.
- Outside of this bidirectional MIMIC model, a process of leveraging would assume an indeterminate latent construct or latent trait rather than a determinate weighted index or additive composite, and it would involve separate, and not simultaneous, use of moderated regression and confirmatory factor analysis in order to reveal synergies and clustering. Because these two sources of variation would not compete with each other, the variation they each capture would not be distinct and mutually exclusive but rather overlapping, which may inflate standard errors and bias estimates and inferences. Although clustering may still occur across symptoms in the measurement model, biases may afflict the clustering in terms of not only the accuracy and magnitude of symptom loadings on the latent trait or construct, but also because it inappropriately includes or excludes certain symptoms (i.e., a biased reflective symptom cluster). This clustering bias in the reflective indicators of the measurement model signals the likelihood of counteracting bias in the formative indicators of the structural model. Furthermore, the structural model may not detect actual symptom interactions due to their inflated standard errors (i.e., a biased formative symptom cluster). In contrast to leveraging performed in the context of an imperfectly estimated indeterminate latent trait/construct in a restrictive unidirectional model, the determinacy of a perfectly estimated weighted index/additive composite in a more valid and flexible bidirectional model avoids the possibility of committing ecological fallacies in deriving predicted values for individual observations, such as when screening individuals at risk.
- 7.
- Outliers may become problematic when conducting a confirmatory factor analysis separately and outside the framework of a regression-based MIMIC model. Using boxplots and scatterplots to identify influential univariate and bivariate outliers, analysts may condition the correlation matrix used in confirmatory factor analysis, which would provide valid estimates of the reflective symptom cluster but not of the formative symptom cluster. However, the purpose of screening is to identify influential observations representing people at risk for symptoms of a condition or as a response to an intervention. Removing influential observations altogether is undesirable compared to modeling their synergies as formative indicators and formative symptom clusters. There also may be multiple influential outliers across the variables in a correlation matrix such that their removal would lead the results of a confirmatory factor analysis to be artifacts and no longer representative of the sample.
- 8.
- Time complexity may be problematic in some models that require many iterations and a very long time to converge to a final solution, assuming it even exists. In these situations, the analyst may try a different type of estimator when this is appropriate (e.g., when data are independent and not derived from cluster random sampling, a weighted least squares estimator, such as WLSMV, may be used with binary or ordinal data instead of a maximum likelihood estimator such as MLR).As a confirmatory procedure, the regression-based MIMIC model includes a weighted index/additive composite that may reveal (1) a single formative indicators symptom cluster based on multiple symptoms with synergistic effects within a disease subgroup and (2) a single reflective indicator symptom cluster of multiple symptoms without synergistic effects that cluster together within the disease subgroup. The structural model estimated using moderated regression analysis and the measurement model estimated using confirmatory factor analysis do not replace the need for exploratory procedures involving just the one-way items and not their multiplicative indicators, such as exploratory factor analysis, exploratory principal components factor analysis, or cluster analysis. These exploratory procedures may reveal whether overall clustering actually consists of more than one separate and distinct subcluster of reflective indicators. They can inform whether a bidirectional MIMIC model may target a separate and distinct subcluster of reflective indicators to explore the extent to which it actually comprises a separate formative indicator (i.e., synergistic) symptom subcluster and a separate reflective-indicator (i.e., non-synergistic) symptom subcluster. This approach may be valuable for providing a direction to collapsing bidirectional MIMIC models to comprise only a subcluster of fewer symptoms in situations where time complexity is problematic and the iterations do not converge to yield final valid estimates for the MIMIC model parameters.When variables are ordinal and non-normally distributed, a correlation matrix based on Spearman rank-order correlation coefficients is appropriate for analysis in covariance-based MIMIC models. However, we should not expect these models to yield unique solutions in bidirectional MIMIC models, whether or not they include complex specifications of multiple two- and three-way interaction terms in the structural model portion and parallel multiplicative terms in the symmetrical measurement model portion. The fact that the corresponding formative and reflective indicators derive from the same items leads them to be perfectly correlated as off-diagonal elements of the correlation matrix, which means that the matrix is singular (non-invertible) and does not yield valid estimates. In contrast to regression-based MIMIC modeling, covariance-based MIMIC modeling does not employ moderated regression and confirmatory factor analysis as separate exogenous and endogenous procedures with different assumptions that accommodate asymmetric modeling of unique versus shared variation within the same symptom or item. Because all variables are endogenous (y) outcomes in a correlational framework, the structural model portion does not condition or influence the estimates derived from the measurement model portion of the covariance-based MIMIC model. Although analysts may screen out influential outliers prior to calculating correlation coefficients, the covariance-based MIMIC model may not adjust for outliers due to the lack of influence of the structural model on the measurement model. Furthermore, because the modeling does not occur at the level of individual participants, but rather on correlation matrix relationships across the sample or disease groups, ecological fallacies may be a threat for the purpose of screening individuals.
Appendix C (Results)

{kind=link}
| Chronic Conditions & Subgroups | (A) Formative Indicators (Synergies) | (B) Reflective Indicators (Clustering Only) | ||||
|---|---|---|---|---|---|---|
| CES-D Depression Items | b | S.E. | z 2,3 | λ | S.E. | z 2,3 |
| 1. Stroke (n = 115) | ||||||
| Stroke | 56.353 | 19.518 | 2.887 | |||
| x Talked Less than Usual | 0.269 | 0.099 | 2.709 | |||
| 2. Stroke (n = 115) Mediated by Diabetes (n = 371) | ||||||
| Stroke | 7.302 | 1.785 | 4.092 | |||
| Diabetes | 12.414 | 1.148 | 10.815 | |||
| Stroke x Enjoyed Life | 0.398 | 0.199 | 2.006 | |||
| Stroke x Talked Less than Usual | 0.764 | 0.186 | 4.115 | |||
| Diabetes x Everything an Effort | 0.155 | 0.078 | 1.991 | |||
| Diabetes x Restless Sleep | 0.218 | 0.069 | 3.142 | |||
| 3. Stroke or Post-Stroke Cognitive Impairment (PSCI, n = 139) | ||||||
| Stroke or Post Stroke Cognitive Impairment | 69.559 | 16.652 | 4.177 | |||
| x Difficulty Concentrating | 0.302 | 0.107 | 2.830 | |||
| x Talked Less than Usual | 0.213 | 0.093 | 2.282 | |||
| 4. Stroke or Post-Stroke Cognitive Impairment (PSCI, n = 139) Mediated by Diabetes (n = 371) | ||||||
| Stroke or Post-Stroke Cognitive Impairment | 6.897 | 1.420 | 4.859 | |||
| Diabetes | 11.434 | 0.914 | 12.516 | |||
| Stroke or PSCI x Sad | 0.637 | 0.283 | 2.248 | |||
| Stroke or PSCI x Enjoyed Life | 0.408 | 0.188 | 2.166 | |||
| Stroke or PSCI x Talked Less than Usual | 0.655 | 0.173 | 3.792 | |||
| Diabetes x Restless Sleep | 0.248 | 0.068 | 3.628 | |||
| 5. Vascular Cognitive Impairment (VCI, n = 42) | ||||||
| Vascular Cognitive Impairment (VCI) | 61.420 | 24.650 | 2.492 | 0.721 | 0.310 | 2.323 |
| x Bothered by Things | 1.241 | 0.401 | 3.092 | 0.405 | 0.078 | 5.157 |
| x Life a Failure | 0.516 | 0.137 | 3.775 | |||
| x Crying Spells | 0.738 | 0.272 | 2.716 | |||
| x Depressed | 0.696 | 0.185 | 3.751 | |||
| x Blues | 0.770 | 0.279 | 2.758 | |||
| x Sad | 0.788 | 0.383 | 2.056 | 0.402 | 0.155 | 2.587 |
| x Happy | 1.540 | 0.560 | 2.749 | 0.568 | 0.222 | 2.556 |
| x Hopeful | 0.457 | 0.121 | 3.770 | 0.429 | 0.204 | 2.106 |
| x Enjoyed Life | 0.644 | 0.272 | 2.371 | |||
| x Good as Others | 0.937 | 0.368 | 2.548 | |||
| x Everything an Effort | 0.431 | 0.139 | 3.110 | |||
| x Poor Appetite | 0.715 | 0.342 | 2.093 | 0.463 | 0.128 | 3.629 |
| x Difficulty Concentrating | ||||||
| x Talked Less than Usual | 1.711 | 0.562 | 3.045 | 0.508 | 0.150 | 3.390 |
| x Restless Sleep | 0.322 | 0.116 | 2.771 | |||
| x Not Get Going | 1.067 | 0.457 | 2.333 | 0.368 | 0.123 | 2.985 |
| x Fearful | 0.702 | 0.164 | 4.272 | |||
| x Lonely | 0.511 | 0.255 | 2.003 | |||
| x People Unfriendly | 1.603 | 0.612 | 2.619 | 0.559 | 0.199 | 2.813 |
| x People Disliked Me | ||||||
| 6. Vascular Cognitive Impairment (VCI, n = 42) | ||||||
| Mediated by Diabetes (n = 371) | ||||||
| Vascular Cognitive Impairment (VCI) | 0.259 | 1.487 | 0.174 | |||
| Diabetes | 14.927 | 1.230 | 12.133 | |||
| VCI x Crying Spells | 1.452 | 0.466 | 3.118 | |||
| VCI x Sad | 0.734 | 0.341 | 2.150 | |||
| VCI x Happy | 1.245 | 0.719 | 1.732 | |||
| VCI x Hopeful | 0.824 | 0.419 | 1.966 | |||
| 7. Vascular Cognitive Impairment without Diabetes (n = 29) | ||||||
| Vascular Cognitive Impairment without Diabetes | 16.262 | 3.216 | 5.056 | |||
| x Bothered by Things | ||||||
| x Life a Failure | 0.338 | 0.039 | 8.568 | |||
| x Crying Spells | 0.560 | 0.186 | 3.007 | |||
| x Depressed | ||||||
| x Blues | 7.727 | 1.767 | 4.374 | 0.707 | 0.225 | 3.147 |
| x Sad | 0.631 | 0.287 | 2.197 | |||
| x Happy | 4.792 | 1.344 | 3.567 | 0.464 | 0.207 | 2.236 |
| x Hopeful | 0.505 | 0.221 | 2.285 | |||
| x Enjoyed Life | 0.434 | 0.147 | 2.948 | |||
| x Good as Others | ||||||
| x Everything an Effort | 0.756 | 0.344 | 2.200 | |||
| x Poor Appetite | 2.903 | 0.911 | 3.185 | 0.467 | 0.146 | 3.201 |
| x Difficulty Concentrating | 0.526 | 0.128 | 4.110 | |||
| x Talked Less than Usual | 3.816 | 0.854 | 4.467 | 0.377 | 0.085 | 4.463 |
| x Restless Sleep | 2.729 | 0.957 | 2.851 | 0.471 | 0.137 | 3.444 |
| x Not Get Going | 0.437 | 0.109 | 4.006 | |||
| x Fearful | 5.936 | 1.440 | 4.121 | 0.465 | 0.148 | 3.132 |
| x Lonely | 0.595 | 0.146 | 4.073 | |||
| x People Unfriendly | 2.022 | 0.776 | 2.606 | 0.428 | 0.169 | 2.529 |
| x People Disliked Me | ||||||
| 8. Emaciated (n = 89) | ||||||
| Emaciated | 22.244 | 1.990 | 11.175 | |||
| 9. Emaciated Mediated by Diabetes (n = 371) | ||||||
| Emaciated | 3.994 | 1.071 | 3.730 | |||
| Diabetes | 11.616 | 1.063 | 10.929 | |||
| Emaciated x Hopeful | 0.537 | 0.181 | 2.974 | |||
| Emaciated x People Disliked Me | 0.731 | 0.350 | 2.091 | |||
| Diabetes x Restless Sleep | 0.238 | 0.077 | 3.099 | |||
| 10. Alcohol Consumption (n = 272) | ||||||
| Alcohol Consumption | 62.670 | 21.899 | 2.862 | |||
| x Bothered by Things | 0.248 | 0.111 | 2.234 | 0.428 | 0.098 | 4.379 |
| x Life a Failure | 0.500 | 0.073 | 6.867 | |||
| x Crying Spells | 0.444 | 0.128 | 3.475 | |||
| x Depressed | 0.984 | 0.165 | 5.969 | |||
| x Blues | 0.645 | 0.072 | 9.002 | |||
| x Sad | 0.779 | 0.123 | 6.331 | |||
| x Happy | 0.609 | 0.118 | 5.144 | |||
| x Hopeful | 0.362 | 0.070 | 5.170 | |||
| x Enjoyed Life | 0.237 | 0.084 | 2.829 | 0.553 | 0.093 | 5.967 |
| x Good as Others | 0.324 | 0.122 | 2.654 | |||
| x Everything an Effort | 0.439 | 0.076 | 5.781 | |||
| x Poor Appetite | 0.408 | 0.082 | 4.971 | |||
| x Difficulty Concentrating | 0.538 | 0.091 | 5.923 | |||
| x Talked Less than Usual | 0.435 | 0.083 | 5.272 | |||
| x Restless Sleep | 0.133 | 0.067 | 1.977 | 0.393 | 0.096 | 4.095 |
| x Not Get Going | 0.359 | 0.108 | 3.314 | |||
| x Fearful | 0.232 | 0.103 | 2.241 | 0.506 | 0.120 | 4.224 |
| x Lonely | 0.545 | 0.081 | 6.687 | |||
| x People Unfriendly | 0.343 | 0.137 | 2.512 | |||
| x People Disliked Me | 0.269 | 0.093 | 2.889 | |||
| 11. Alcohol Consumption (n = 272) | ||||||
| Mediated by Diabetes (n = 371) | ||||||
| Alcohol Consumption | 6.421 | 0.863 | 7.437 | |||
| Diabetes | 9.855 | 1.172 | 8.412 | |||
| Alcohol Consumption x Bothered by Things | 0.401 | 0.184 | 2.183 | |||
| Alcohol Consumption x Hopeful | 0.386 | 0.093 | 4.170 | |||
| Alcohol Consumption x Restless Sleep | 0.317 | 0.128 | 2.474 | |||
| Alcohol Consumption x Fearful | 0.603 | 0.248 | 2.435 | |||
| Diabetes x Difficulty Concentrating | 0.234 | 0.115 | 2.025 | |||
| Diabetes x Restless Sleep | 0.277 | 0.093 | 2.982 | |||
| Chronic Conditions & Subgroups | (A) Formative Indicators (Synergies) | (B) Reflective Indicators (Clustering Only) | ||||
|---|---|---|---|---|---|---|
| CES-D Depression Items | B | S.E. | z 2,3 | λ | S.E. | z 2,3 |
| 1. Heart Attack (Males, n = 202) | ||||||
| Heart Attack (Males) | 16.846 | 1.934 | 8.712 | |||
| x Enjoyed Life | 0.129 | 0.063 | 2.051 | |||
| x Fearful | 0.276 | 0.098 | 2.805 | |||
| 2. Heart Attack (Males, n = 202) | ||||||
| Mediated by Diabetes (Males, n = 131) | ||||||
| Heart Attack (Males) | 10.546 | 1.930 | 5.464 | |||
| Diabetes (Males) | 0.802 | 0.762 | 1.052 | |||
| Heart Attack x Enjoyed Life | 0.211 | 0.088 | 2.405 | |||
| Heart Attack x Fearful | 0.486 | 0.143 | 3.390 | |||
| Diabetes x Good as Others | 0.604 | 0.278 | 2.176 | |||
| Diabetes x Difficulty Concentrating | 0.482 | 0.197 | 2.449 | |||
| Diabetes x Not Get Going | 0.564 | 0.186 | 3.030 | |||
| Chronic Conditions & Subgroups | (A) Formative Indicators (Synergies) | (B) Reflective Indicators (Clustering Only) | ||||
|---|---|---|---|---|---|---|
| CES-D Depression Items | B | S.E. | z 2,3 | λ | S.E. | z 2,3 |
| 1. Stroke (Ages 65–74, n = 72) | ||||||
| Stroke (Ages 65–74) | 15.986 | 2.196 | 7.281 | |||
| x Enjoyed Life | 0.334 | 0.142 | 2.351 | |||
| x Everything an Effort | 0.384 | 0.161 | 2.387 | |||
| x Poor Appetite | 0.235 | 0.077 | 3.065 | |||
| x Difficulty Concentrating | 0.408 | 0.162 | 2.526 | |||
| x Talked Less than Usual | 0.819 | 0.180 | 4.551 | |||
| 2. Stroke (Ages 65–74, n = 72) | ||||||
| Mediated by Diabetes | ||||||
| (Ages 65–74, n = 131) | ||||||
| Stroke (Ages 65–74) | 6.873 | 1.952 | 3.521 | |||
| Diabetes (Ages 65–74) | 11.700 | 0.842 | 13.898 | |||
| Stroke x Depressed | 0.367 | 0.102 | 3.602 | |||
| Stroke x Everything an Effort | 1.231 | 0.491 | 2.508 | |||
| Stroke x Difficulty Concentrating | 1.558 | 0.725 | 2.150 | |||
| Stroke x Talked Less than Usual | 1.829 | 0.727 | 2.516 | |||
| Stroke x Not Get Going | 1.917 | 0.864 | 2.220 | |||
| Stroke x Fearful | 1.001 | 0.368 | 2.722 | |||
| Stroke x People Unfriendly | 0.778 | 0.272 | 2.864 | |||
| Diabetes x Restless Sleep | 0.297 | 0.135 | 2.199 | |||
| Diabetes x Lonely | 0.316 | 0.159 | 1.984 | |||
| Diabetes x People Unfriendly | 0.392 | 0.092 | 4.250 | |||
| 3. Stroke (Over Age 74, n = 43) | ||||||
| Stroke (Over Age 74) | 15.790 | 1.308 | 12.073 | |||
| x Sad | 0.678 | 0.332 | 2.044 | |||
| x Poor Appetite | 0.354 | 0.168 | 2.108 | |||
| x Difficulty Concentrating | 1.150 | 0.451 | 2.549 | |||
| x Talked Less than Usual | 0.763 | 0.339 | 2.254 | |||
| x People Unfriendly | 0.646 | 0.247 | 2.620 | |||
| 4. Stroke (Over Age 74, n = 43) | ||||||
| Mediated by Diabetes | ||||||
| (Over Age 74, n = 194) | ||||||
| Stroke (Over Age 74) | 4.942 | 3.203 | 1.543 | |||
| Diabetes (Over Age 74) | 12.260 | 1.002 | 12.232 | |||
| Stroke x Talked Less than Usual | 1.842 | 0.917 | 2.008 | |||
| Diabetes x Poor Appetite | 0.277 | 0.112 | 2.478 | |||
| 5. Stroke or Post-Stroke Cognitive Impairment (PSCI) | ||||||
| (Ages 65–74, n = 81) | ||||||
| Stroke or Post-Stroke Cognitive Impairment | ||||||
| (PSCI, Ages 65–74) | 16.016 | 2.068 | 7.744 | |||
| x Depressed | 0.309 | 0.120 | 2.576 | |||
| x Enjoyed Life | 0.291 | 0.090 | 3.239 | |||
| x Talked Less than Usual | 0.569 | 0.166 | 3.425 | |||
| 6. Stroke or Post-Stroke Cognitive Impairment (PSCI, Ages 65–74, n = 81) Mediated by Diabetes | ||||||
| (Ages 65–74, n = 177) | ||||||
| Stroke or Post-Stroke Cognitive Impairment | ||||||
| (PSCI, Ages 65–74) | 6.790 | 2.004 | 3.389 | |||
| Diabetes (Ages 65–74) | 10.611 | 1.912 | 5.549 | |||
| Stroke or PSCI x Depressed | 0.555 | 0.238 | 2.332 | |||
| Stroke or PSCI x Difficulty Concentrating | 0.904 | 0.415 | 2.177 | |||
| Stroke or PSCI x Talked Less than Usual | 1.302 | 0.486 | 2.680 | |||
| Stroke or PSCI x Fearful | 1.180 | 0.550 | 2.145 | |||
| Diabetes x Restless Sleep | 0.335 | 0.145 | 2.310 | |||
| Diabetes x Lonely | 0.358 | 0.181 | 1.980 | |||
| Diabetes x People Unfriendly | 0.463 | 0.110 | 4.205 | |||
| 7. Stroke or Post-Stroke Cognitive Impairment (PSCI, Over Age 74, n = 58) | ||||||
| Stroke or Post-Stroke Cognitive Impairment (Over Age 74) | 16.864 | 1.420 | 11.874 | |||
| x Difficulty Concentrating | 0.603 | 0.269 | 2.244 | |||
| 8. Stroke or Post-Stroke Cognitive Impairment (PSCI, Over Age 74, n = 58) Mediated by Diabetes | ||||||
| (Over Age 74, n = 194) | ||||||
| Stroke or Post-Stroke Cognitive Impairment (Over Age 74) | 7.525 | 3.157 | 2.383 | |||
| Diabetes (Over Age 74) | 12.265 | 1.246 | 9.847 | |||
| Diabetes x Good as Others | 0.147 | 0.071 | 2.056 | |||
| Diabetes x Poor Appetite | 0.305 | 0.138 | 2.218 | |||
| Diabetes x Restless Sleep | 0.230 | 0.107 | 2.148 | |||
| 9. Vascular Cognitive Impairment (Over Age 74, n = 29) | ||||||
| Vascular Cognitive Impairment (Over Age 74) | 10.310 | 2.322 | 4.440 | |||
| x Bothered by Things | 0.449 | 0.089 | 5.018 | |||
| x Life a Failure | 2.093 | 0.688 | 3.042 | 0.376 | 0.095 | 3.976 |
| x Crying Spells | 0.488 | 0.075 | 6.494 | |||
| x Depressed | 0.492 | 0.079 | 6.189 | |||
| x Blues | 0.463 | 0.080 | 5.803 | |||
| x Sad | 0.508 | 0.114 | 4.466 | |||
| x Happy | 3.170 | 1.003 | 3.160 | 0.421 | 0.077 | 5.480 |
| x Hopeful | 0.515 | 0.079 | 6.547 | |||
| x Enjoyed Life | 0.431 | 0.088 | 4.891 | |||
| x Good as Others | 0.391 | 0.081 | 4.817 | |||
| x Everything an Effort | 1.900 | 0.511 | 3.718 | 0.568 | 0.146 | 3.895 |
| x Poor Appetite | 0.482 | 0.094 | 5.103 | |||
| x Difficulty Concentrating | 1.050 | 0.422 | 2.489 | 0.473 | 0.065 | 7.293 |
| x Talked Less than Usual | 5.422 | 1.528 | 3.548 | 0.362 | 0.061 | 5.895 |
| x Restless Sleep | 0.504 | 0.062 | 8.156 | |||
| x Not Get Going | 2.096 | 0.695 | 3.015 | 0.468 | 0.066 | 7.126 |
| x Fearful | 0.465 | 0.077 | 6.044 | |||
| x Lonely | 0.446 | 0.099 | 4.483 | |||
| x People Unfriendly | 5.537 | 1.575 | 3.516 | 0.360 | 0.116 | 3.104 |
| x People Disliked Me | 0.293 | 0.089 | 3.296 | |||
| 10. Vascular Cognitive Impairment (VCI, Over Age 74 n = 29) Mediated by Diabetes (Over Age 74, n = 194) | ||||||
| Vascular Cognitive Impairment (Over Age 74) | –2.151 | 1.611 | –1.335 | |||
| Diabetes (Over Age 74) | 13.111 | 1.462 | 8.969 | |||
| VCI x Life a Failure | 5.403 | 2.142 | 2.522 | |||
| VCI x Happy | 3.032 | 1.434 | 2.115 | |||
| VCI x Everything an Effort | 3.394 | 0.968 | 3.508 | |||
| VCI x Difficulty Concentrating | 1.806 | 0.779 | 2.319 | |||
| VCI x Talked Less than Usual | 8.718 | 2.441 | 3.571 | |||
| VCI x Not Get Going | 1.057 | 0.413 | 2.559 | |||
| VCI x People Unfriendly | 6.840 | 1.727 | 3.961 | |||
| Diabetes x Poor Appetite | 0.157 | 0.061 | 2.586 | |||
| 11. Cancer (Over Age 74, n = 182) | ||||||
| Cancer (Over Age 74) | 16.263 | 1.332 | 12.209 | |||
| x Bothered by Things | 0.090 | 0.046 | 1.958 | |||
| x Hopeful | 0.138 | 0.058 | 2.399 | |||
| 12. Cancer (Over Age 74, n = 182) | ||||||
| Mediated by Diabetes (Over Age 74, n = 194) | ||||||
| Cancer (Over Age 74) | 7.525 | 1.554 | 4.841 | |||
| Diabetes (Over Age 74) | 6.443 | 1.415 | 4.554 | |||
| Cancer x Talked Less than Usual | 0.293 | 0.148 | 1.981 | |||
| Cancer x Lonely | 0.221 | 0.092 | 2.398 | |||
| Diabetes x Difficulty Concentrating | 0.276 | 0.139 | 1.989 | |||
Appendix D (Discussion)
- 1.
- “The formative (causal) indicator effect consists of both the confounding effects associated with the formative (causal) indicator, along with the unbiased effects of the formative (causal) indicator itself. This adaptive conditioning and modeling with formative (causal) indicators leads to expected unbiased reflective (effect) indicators” [7] (p. 26).
- 2.
- Using the same EPESE disease group and depressive symptom data, Francoeur [7] conducted MIMIC analyses involving main-effects (i.e., one-way) formative indicators and their parallel one-way reflective indicators. Across analyses, the number of positive, one-way, statistically significant formative indicators was limited, leading to the overall observation that symptom clusters tended to be a feature of reflective indicators. However, this observation could be an artifact of the lack of inclusion of multiple formative indicator interactions and their mirror-image multiplicative reflective indicators in these models.This suspicion arises because the lack of significance of formative indicators in [3] occurred despite the fact that the slope for overall depression was often prominent and statistically significant, for instance, in the MIMIC model involving the main-effect terms for Diabetes and Heart Failure. However, in the extended specification within older women tested in the current study (Figure 1), the slope of the additive composite or weighted index of overall depression deteriorated drastically and became negative (b = −16.076, s.e. = 1.906, z = −8.435) while formative indicator interactions of several depression symptoms within this disease subgroup became positive and statistically significant (see Table 1). Thus, formative indicator interaction terms may become statistically significant by accounting for variation previously captured by overall depression. It does this through the inclusion of multiple interactions that target the formative indicators further so that they retain only the disease subgroup participants that endorse each of the formative indicators of depressive symptoms.
- 3.
- In this section, I target the comorbid disease context of diabetes and heart failure in order to illustrate how we may use this MIMIC model to analyze cross-sectional, heterogeneous data more efficiently and with greater utility in the absence of longitudinal data. Branched-chain amino acids (BCAAs) are important concerns in diabetes and in heart failure, and may be more prevalent as metabolites when these disease conditions occur together. They may be associated with depression symptoms in the MIMIC models of (1) Diabetes x Heart Failure; (2) Diabetes x Lost 10 Pounds; and (3) the related diabetes co-morbid conditions reported in Table 1, Table 2 and Table 3 and Table A1, Table A2 and Table A3. This requires some explanation.A review of cardiovascular metabolomics [37] reveals consistent observations of branched-chain amino acids (BCAAs) and related metabolites (such as their catabolic intermediates and other amino acids phenylalanine and tyrosine) in rats and humans to occur as part of insulin resistance and diabetes. It reports that “… supplementation of a high-fat diet with BCAA promoted insulin resistance in rats, independent of weight gain, suggesting a causal effect of BCAA in mediating this process [38], whereas BCAA in a genetic rat model of obesity improved insulin sensitivity [39]. Because of this observation, several additional studies using metabolomics platforms in different human cohorts, have not only confirmed the association of BCAA with insulin resistance [40,41,42,43] but have also shown that BCAA predicts the development of diabetes mellitus [44] and predict improvement in insulin sensitivity and weight loss [45,46]. The mechanisms underlying the association of BCAA with obesity-related metabolic disorders remain unclear” [37] (p. 1252).Newgard and colleagues [38] discovered that “… the clustering of glutamate and C3 and C5 acylcarnitines with BCAAs defined a signature comprising metabolites generated during BCAA catabolism, suggesting fundamental alteration of BCAA metabolism in insulin-resistant states” [47] (p. 44). One could test this cluster further by specifying these metabolites as main effects and interactions within the regression portion of a MIMIC model targeted to insulin-resistant subgroups in order to determine whether the components of the cluster are synergistic. The main effects would comprise formative (causal) indicators to adjust for unspecified confounders in order to condition bias from the parallel reflective (effect) indicators.Heart failure also implicates the involvement of BCAAs. In one recent study, mass spectrometry revealed twenty-three cardiac metabolites in an untargeted metabolomics study of rats with chronic heart failure induced by myocardial infarction [48]. Follow-up analyses of these metabolites revealed that certain BCAAs in serum, especially leucine and valine, were superior in distinguishing rats with chronic heart failure from rats that received a sham operation, in which these BCAAs accounted for more than three quarters of the area under the receiver operating characteristic curve. Targeted metabolomics confirmed that the BCAA metabolic pathway with related proteins and genes was impaired in rats with chronic heart failure, and time series evidence of dynamic changes in these BCAAs within three weeks after surgery were highly accurate (93.75%) in classifying rats with chronic heart failure. While other chronic heart failure studies have also reported increases in the levels of circulating BCAAs [49,50], there are also reports of decreased or unchanged levels of circulating BCAAs [51,52,53]. The study authors attribute these inconsistencies to dynamic changes in the levels of circulating BCAAs that analysts cannot capture at a single time point. When relying on a single time point, pernicious confounding related to baseline health status, lifestyle, or socioeconomic factors may undermine findings [54]. Substantively meaningful yet also uncontrolled confounding factors and interactions such as diet, the gut microbiome, and physical activity may in turn mediate these more basic confounding factors and interactions.However, this explanation may be premature. A somewhat crude main-effects model perhaps not well adjusted for confounders across the full sample of rats is the basis for this time series study. There could be different dynamic changes across subgroups of rats while also adjusting for confounders, depending on their cross-sectional curvilinear and interactive effects. Because the precipitation of circulating BCAAs may occur at different rates across the sample of rats with chronic heart failure, a cross-sectional sample at a single point in time may become increasingly heterogeneous in regard to the levels of circulating BCAAs within the three-week period. However, it may then become more consistent again (reflecting increases in circulating BCAAs in most of the rats) toward the end of that period. As long as the researcher does not select the cross-sectional sample too soon, before the dynamic changes have had a chance to occur in some reasonable portion of the sample (resulting in sample heterogeneity), there should be evidence of increasing levels of circulating BCAAs. However, the researcher may detect the evidence as curvilinear and/or interaction effects among the circulating BCAAs and not as linear or main effects, which serves to reflect that these dynamic effects are occurring within the targeted subgroup(s) of the sample. Still, as increasingly more of the rats with chronic heart failure come to experience a dynamic increase in circulating BCAAs, evidence for this dynamic increase may nonetheless be detected as linear or main effects in this cruder main-effects model (even as curvilinear and interactive effects are occurring).An analyst may use epidemiological data to specify and test the three BCAAs (leucine, isoleucine, and valine) both as formative (causal) indicators in the structural regression portion of a cross-sectional MIMIC model and as reflective (effect) indicators in the confirmatory factor analysis portion. Furthermore, the analyst could extend the main-effects regression portion into a curvilinear and moderated regression. In this extended specification, the three BCAAs (leucine, isoleucine, and valine), along with their curvilinear effects (if based on ordinal but not binary data) and four two- and three-way interactions, could be specified as exogenous effects in the MIMIC model (with the latent trait capturing the overall level of these three circulating BCAAs). This extended specification would model the diagnostic accuracy of these circulating BCAAs more precisely and with less bias. It would provide an analysis of the BCAAs across the full sample. Another option retains the three BCAAs as formative (causal) and reflective (effect) indicators while specifying exogenous terms to target a specific diagnostic subgroup (for instance, terms for diabetes, heart failure, and their interaction).In either type of specification, greater precision is possible because the three main-effect terms reveal their additive impacts, any curvilinear terms reveal more targeted additive impacts at more pronounced levels, and the interaction term(s) reveal multiplicative or synergistic impacts between all combinations of the main-effect terms. The inclusion of curvilinear and interaction terms may further reduce bias because they also enable more targeted conditioning for confounding influences within more targeted subgroups of BCAAs or diagnoses. Finally, the researcher may incorporate other metabolites with lower diagnostic accuracy (such as ejection fraction or brain natriuretic peptide) in the time series study [48], and as suggested by others (e.g., ketone metabolism [55,56,57]), into the panel of metabolites and biomarkers or within the regression portion of the MIMIC model. Their incorporation would be included as curvilinear terms and as components of interaction terms with BCAAs and with each other. Greater attention to testing these more targeted, exogenous effects in MIMIC models would allow for more comprehensive testing of diagnostic accuracy within subgroups by also considering curvilinear terms and/or the additional synergistic effects that emerge when metabolites and biomarkers co-occur in the same individuals.
References
- Kirkova, J.; Walsh, D. Cancer symptom clusters–A dynamic construct. Support Care Cancer 2007, 15, 1011–1013. [Google Scholar] [CrossRef] [PubMed]
- Francoeur, R.B. The relationship of cancer symptom clusters to depressive affect in the initial phase of palliative radiation. J. Pain Symptom. Manag. 2005, 29, 130–155. [Google Scholar] [CrossRef] [PubMed]
- Francoeur, R.B. Using an innovative multiple regression procedure in a cancer population (Part I): Detecting and probing relationships of common interacting symptoms (pain, fatigue/weakness, sleep problems) as a strategy to discover influential symptom pairs and clusters. OncoTargets Ther. 2015, 8, 45–56. [Google Scholar] [CrossRef] [PubMed]
- Francoeur, R.B. Using an innovative multiple regression procedure in a cancer population (Part II): Fever, depressive affect, and mobility problems clarify an influential symptom pair (pain-fatigue/weakness) and cluster (pain-fatigue/weakness-sleep problems). OncoTargets Ther. 2015, 8, 57–72. [Google Scholar] [CrossRef] [PubMed]
- Reyes-Gibby, C.C.; Lu, A.A.; Anderson, K.O.; Mendoza, T.R.; Cleeland, C.S. Pain, depression, and fatigue in community-dwelling adults with and without a history of cancer. J. Pain Symptom. Manag. 2006, 32, 118–128. [Google Scholar] [CrossRef] [PubMed]
- Francoeur, R.B. Symptom profiles of subsyndromal depression in disease clusters of diabetes, excess weight, and progressive cerebrovascular conditions: A promising new type of finding from a reliable innovation to estimate exhaustively specified multiple indicators-multiple causes (MIMIC) models. Diabetes Metab. Syndr. Obes. Targets Ther. 2016, 9, 391–416. [Google Scholar] [CrossRef]
- Francoeur, R.B. Multimorbidity from diabetes, heart failure, and related conditions: Assessing a panel of depressive symptoms as both formative and reflective indicators of a latent trait. Mathematics 2021, 9, 2715. [Google Scholar] [CrossRef]
- Zhu, M.; Li, Y.; Luo, B.; Cui, J.; Liu, Y.; Liu, Y. Comorbidity of type 2 diabetes mellitus and depression: Clinical evidence and rationale for the exacerbation of cardiovascular disease. Front. Cardiovasc. Med. 2022, 9, 861110. [Google Scholar] [CrossRef]
- Shin, M.; Sohn, M.K.; Lee, J.; Kim, D.Y.; Shin, Y.-I.; Oh, G.-J.; Lee, Y.-S.; Joo, M.C.; Lee, S.Y.; Song, M.-K.; et al. Post-stroke depression and cognitive aging: A multicenter, prospective cohort study. J. Pers. Med. 2022, 12, 389. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, P. A Guide to Econometrics, 4th ed.; MIT Press: Cambridge, MA, USA, 1998; pp. 42–53. [Google Scholar]
- National Archive of Computerized Data on Aging. Established Populations for Epidemiologic Studies of the Elderly, 1981–1993: {East Boston, Massachusetts, Iowa and Washington Counties, Iowa, New Haven, Connecticut, and North Central North Carolina} (ICPSR 9915). 2021. Available online: http://www.icpsr.umich.edu/NACDA/studies/9915 (accessed on 1 June 2021).
- Muthén, L.K.; Muthén, B.O. Mplus User’s Guide, 5th ed.; Muthén and Muthén: Los Angeles, CA, USA, 1998–2007. [Google Scholar]
- How to Find the Time Complexity of an MLE Algorithm. 2020. Available online: https://stats.stackexchange.com/questions/497523/how-to-find-the-time-complexity-of-an-mle-based-algorithm (accessed on 4 August 2022).
- McNeish, D.; Wolf, M.G. Thinking twice about sum scores. Behav. Res. 2020, 52, 2287–2305. [Google Scholar] [CrossRef] [PubMed]
- Muthén, B. A structural probit model with latent variables. J. Am. Stat. Assoc. 1979, 74, 807–811. [Google Scholar]
- Muthén, B. Latent variable structural equation modeling with categorical data. J. Econom. 1983, 22, 48–65. [Google Scholar] [CrossRef]
- Muthén, B. A general structural equation model with dichotomous, ordered categorical, and continuous latent variable indicators. Psychometrika 1984, 49, 115–132. [Google Scholar] [CrossRef]
- Muthén, B. Latent variable modeling in heterogeneous populations. Presidential address to the Psychometric Society, July 1989. Psychometrika 1989, 54, 557–585. [Google Scholar] [CrossRef]
- Stevens, J.P. Outliers and influential data points in regression analysis. Psychol. Bull. 1984, 95, 334–344. [Google Scholar] [CrossRef]
- Zygmont, C.; Smith, M.R. Robust factor analysis in the presence of normality violations, missing data, and outliers: Empirical questions and possible solutions. Quant. Meth. Psych. 2014, 10, 40–55. [Google Scholar] [CrossRef]
- Gao, S.; Mokhtarian, P.L.; Johnston, R.A. Nonnormality of data in structural equation models. Transp. Res. J. 2008, 2082, 116–124. [Google Scholar] [CrossRef]
- Fischer, J.; Gödecke, A.; Kelm, M.; Heusch, G. Master switches in cardiac ischemia: The Collaborative Research Center (CRC) 1116 of the German Research Foundation. Eur. Heart J. 2022, 43, 2350–2351. [Google Scholar] [CrossRef] [PubMed]
- U.S. Department of Health and Human Services. The Health Consequences of Smoking-50 Years of Progress: A Report of the Surgeon General. Atlanta: U.S. Department of Health and Human Services, Centers for Disease Control and Prevention, National Center for Chronic Disease Prevention and Health Promotion, Office on Smoking and Health. 2014. Available online: https://www.ncbi.nlm.nih.gov/books/NBK179276/pdf/Bookshelf_NBK179276.pdf#page=592 (accessed on 4 August 2022).
- U.S. Department of Health and Human Services. A Report of the Surgeon General: How Tobacco Smoke Causes Disease: What It Means to You. Atlanta: U.S. Department of Health and Human Services, Centers for Disease Control and Prevention, National Center for Chronic Disease Prevention and Health Promotion, Office on Smoking and Health. 2010. Available online: https://www.cdc.gov/tobacco/data_statistics/sgr/2010/consumer_booklet/pdfs/consumer.pdf (accessed on 4 August 2022).
- American Diabetes Association. Medication & Treatments: Alcohol and Diabetes. 2022. Available online: https://www.diabetes.org/healthy-living/medication-treatments/alcohol-diabetes (accessed on 4 August 2022).
- Rajpathak, S.N.; Gunter, M.J.; Wylie-Rosett, J.; Ho, G.Y.; Kaplan, R.C.; Muzumdar, R.; Rohan, T.E.; Strickler, H.D. The role of insulin-like growth factor-I and its binding proteins in glucose homeostasis and type 2 diabetes. Diabetes Metab. Res. Rev. 2009, 25, 3–12. [Google Scholar] [CrossRef] [PubMed]
- Brahmkhatri, V.P.; Prasanna, C.; Atreya, H.S. Insulin-like growth factor system in cancer: Novel targeted therapies. Biomed. Res. Int. 2015, 2015, 538019. [Google Scholar] [CrossRef] [PubMed]
- Miaskowski, C.; Aouizerat, B.E. Is there a biological basis for the clustering of symptoms? Semin. Oncol. Nurs. 2007, 23, 99–105. [Google Scholar] [CrossRef]
- Schwartz, N.S.; Clutter, W.E.; Shah, S.D.; Cryer, P.E. Glycemic thresholds for activation of glucose counterregulatory systems are higher than the threshold for symptoms. J. Clin. Investig. 1987, 79, 777–781. [Google Scholar] [CrossRef] [PubMed]
- Gonder-Frederick, L.A.; Cox, D.J.; Bobbit, S.A.; Pennebaker, J.W. Mood changes associated with blood glucose fluctuations in insulin-dependent diabetes mellitus. Health Psychol. 1989, 8, 45–59. [Google Scholar] [CrossRef]
- Francoeur, R.B. Could sequential residual centering resolve low sensitivity in moderated regression? Simulations and cancer symptom clusters. Open J. Stat. 2013, 3, 24–44. [Google Scholar] [CrossRef]
- Landewé, R.B.M.; der Heijde, D. Use of multidimensional composite scores in rheumatology: Parsimony versus subtlety. Ann. Rheum. Dis. 2021, 80, 280–285. [Google Scholar] [CrossRef] [PubMed]
- Fearnley, L.G.; Inouye, M. Metabolomics in epidemiology: From metabolite concentrations to integrative reaction networks. Int. J. Epidemiol. 2016, 45, 1319–1328. [Google Scholar] [CrossRef] [PubMed]
- Special Issue “An Innovative Mathematical Universe of Instruments and Techniques Based on the Statistical Indices Method”. Mathematics, 2020. Available online: https://www.mdpi.com/journal/mathematics/special_issues/Statistical_Indices_Method (accessed on 16 September 2022).
- Katsampoxaki-Hodgetts, K. The Four Planes of Symmetry; University of Crete: Heraklion, Greek; Automattic, Inc.: San Francisco, CA, USA, 2012; Available online: https://englishformaths.files.wordpress.com/2012/09/the-four-planes-of-symmetry.ppt (accessed on 17 August 2022).
- Symmetry in Mathematics. Wikipedia. Available online: https://en.wikipedia.org/wiki/Symmetry_in_mathematics (accessed on 17 August 2022).
- McGarrah, R.W.; Crown, S.B.; Zhang, G.-F.; Shah, S.H.; Newgard, C.B. Cardiovascular metabolomics. Circ. Res. 2018, 122, 1238–1258. [Google Scholar] [CrossRef] [PubMed]
- Newgard, C.B.; An, J.; Bain, J.R.; Muehlbauer, M.J.; Stevens, R.D.; Lien, L.F.; Hagg, A.M.; Shah, S.H.; Arlotto, M.; Slentz, C.A.; et al. A branched-chain amino acid-related metabolic signature that differentiates obese and lean humans and contributes to insulin resistance. Cell Metab. 2009, 9, 311–326. [Google Scholar] [CrossRef] [PubMed]
- White, P.J.; Lapworth, A.L.; An, J.; Wang, L.; McGarrah, R.W.; Stevens, R.D.; Ilkayeva, O.; George, T.; Muehlbauer, M.J.; Bain, J.R.; et al. Branched-chain amino acid restriction in Zucker-fatty rats improves muscle insulin sensitivity by enhancing efficiency of fatty acid oxidation and acyl-glycine export. Mol. Metab. 2016, 5, 538–551. [Google Scholar] [CrossRef] [PubMed]
- Shaham, O.; Wei, R.; Wang, T.J.; Ricciardi, C.; Lewis, G.D.; Vasan, R.S.; Carr, S.A.; Thadhani, R.; Gerszten, R.E.; Mootha, V.K. Metabolic profiling of the human response to a glucose challenge reveals distinct axes of insulin sensitivity. Mol. Syst. Biol. 2008, 4, 214. [Google Scholar] [CrossRef]
- Huffman, K.M.; Shah, S.H.; Stevens, R.D.; Bain, J.R.; Muehlbauer, M.; Slentz, C.A.; Tanner, C.J.; Kuchibhatla, M.; Houmard, J.A.; Newgard, C.B.; et al. Relationships between circulating metabolic intermediates and insulin action in overweight to obese, inactive men and women. Diab. Care 2009, 32, 1678–1683. [Google Scholar] [CrossRef]
- Tai, E.S.; Tan, M.L.; Stevens, R.D.; Low, Y.L.; Muehlbauer, M.J.; Goh, D.L.; Ilkayeva, O.R.; Wenner, B.R.; Bain, J.R.; Lee, J.J.; et al. Insulin resistance is associated with a metabolic profile of altered protein metabolism in Chinese and Asian-Indian men. Diabetologia 2010, 53, 757–767. [Google Scholar] [CrossRef] [PubMed]
- Batch, B.C.; Shah, S.H.; Newgard, C.B.; Turer, C.B.; Haynes, C.; Bain, J.R.; Muehlbauer, M.; Patel, M.J.; Stevens, R.D.; Appel, L.J.; et al. Branched chain amino acids are novel biomarkers for discrimination of metabolic wellness. Metabolism 2013, 62, 961–969. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.J.; Larson, M.G.; Vasan, R.S.; Cheng, S.; Rhee, E.P.; McCabe, E.; Lewis, G.D.; Fox, C.S.; Jacques, P.F.; Fernandez, C.; et al. Metabolite profiles and the risk of developing diabetes. Nat. Med. 2011, 17, 448–453. [Google Scholar] [CrossRef] [PubMed]
- Shah, S.H.; Crosslin, D.R.; Haynes, C.S.; Nelson, S.; Turer, C.B.; Stevens, R.D.; Muehlbauer, M.J.; Wenner, B.R.; Bain, J.R.; Laferrère, B.; et al. Branched-chain amino acid levels are associated with improvement in insulin resistance with weight loss. Diabetologia 2012, 55, 321–330. [Google Scholar] [CrossRef]
- Laferrère, B.; Reilly, D.; Arias, S.; Swerdlow, N.; Gorroochurn, P.; Bawa, B.; Bose, M.; Teixeira, J.; Stevens, R.D.; Wenner, B.R.; et al. Differential metabolic impact of gastric bypass surgery versus dietary intervention in obese diabetic subjects despite identical weight loss. Sci. Transl. Med. 2011, 3, 80re2. [Google Scholar] [CrossRef]
- Newgard, C.B. Metabolomics and metabolic diseases: Where do we stand? Cell Metab. 2017, 25, 42–56. [Google Scholar] [CrossRef]
- Li, R.; He, H.; Fang, S.; Hua, Y.; Yang, X.; Yuan, Y.; Liang, S.; Liu, P.; Tian, Y.; Xu, F.; et al. Time series characteristics of serum branched-chain amino acids for early diagnosis of chronic heart failure. J. Proteome Res. 2019, 18, 2121–2128. [Google Scholar] [CrossRef]
- Cheng, M.L.; Wang, C.H.; Shiao, M.S.; Liu, M.H.; Huang, Y.Y.; Huang, C.Y.; Mao, C.T.; Lin, J.F.; Ho, H.Y.; Yang, N.I. Metabolic disturbances identified in plasma are associated with outcomes in patients with heart failure: Diagnostic and prognostic value of metabolomics. J. Am. Coll. Cardiol. 2015, 65, 1509–1520. [Google Scholar] [CrossRef]
- Guo, N.; Yang, D.; Wang, X.; Dai, J.; Wang, M.; Lei, Y. Metabolomic study of chronic heart failure and effects of Chinese herbal decoction in rats. J. Chromatogr. A 2014, 1362, 89–101. [Google Scholar] [CrossRef]
- Wang, J.; Li, Z.; Chen, J.; Zhao, H.; Luo, L.; Chen, C.; Xu, X.; Zhang, W.; Gao, K.; Li, B.; et al. Metabolomic identification of diagnostic plasma biomarkers in humans with chronic heart failure. Mol. BioSyst. 2013, 9, 2618–2626. [Google Scholar] [CrossRef]
- Sun, H.; Olson, K.C.; Gao, C.; Prosdocimo, D.A.; Zhou, M.; Wang, Z.; Jeyaraj, D.; Youn, J.Y.; Ren, S.; Liu, Y.; et al. Catabolic defect of branched-chain amino acids promotes heart failure. Circulation 2016, 133, 2038–2049. [Google Scholar] [CrossRef]
- Tsuji, S.; Koyama, S.; Taniguchi, R.; Fujiwara, T.; Fujiwara, H.; Sato, Y. Nutritional status of outpatients with chronic stable heart failure based on serum amino acid concentration. J. Cardiol. 2018, 72, 458–465. [Google Scholar] [CrossRef]
- Iida, M.; Harada, S.; Takebavashi, T. Application of metabolomics to epidemiological studies of atherosclerosis and cardiovascular disease. J. Atheroscler. Thromb. 2019, 26, 747–757. [Google Scholar] [CrossRef]
- Aubert, G.; Martin, O.J.; Horton, J.L.; Lai, L.; Vega, R.B.; Leone, T.C.; Koves, T.; Gardell, S.J.; Kruger, M.; Hoppel, C.L.; et al. The failing heart relies on ketone bodies as fuel. Circulation 2016, 133, 698–705. [Google Scholar] [CrossRef]
- Bedi, K.C., Jr.; Snyder, N.W.; Brandimarto, J.; Aziz, M.; Mesaros, C.; Worth, A.J.; Wang, L.L.; Javaheri, A.; Blair, I.A.; Margulies, K.B.; et al. Evidence for intramyocardial disruption of lipid metabolism and increased myocardial ketone utilization in advanced human heart failure. Circulation 2016, 133, 707–716. [Google Scholar] [CrossRef]
- Lopaschuk, G.D.; Ussher, J.R. Evolving concepts of myocardial energy metabolism: More than just fats and carbohydrates. Circ. Res. 2016, 119, 1173–1176. [Google Scholar] [CrossRef]

| Chronic Conditions & Subgroups | (A) Formative Indicators (Synergies) | (B) Reflective Indicators (Clustering Only) | ||||
|---|---|---|---|---|---|---|
| CES-D Depression Items | b | S.E. | z 2 | λ | S.E. | z 2 |
| I. Synergies and Clustering across the New Haven EPESE Community Sample of Older Adults (n = 2812) | ||||||
| Bothered by Things | 0.290 | 0.033 | 8.752 | 0.434 | 0.047 | 10.890 |
| Life a Failure | 0.135 | 0.046 | 2.934 | 0.436 | 0.039 | 11.049 |
| Crying Spells | 0.157 | 0.036 | 4.345 | 0.491 | 0.037 | 13.448 |
| Depressed | 0.724 | 0.092 | 7.882 | 1.000 | 0.000 | NA |
| Blues | 0.221 | 0.047 | 4.683 | 0.646 | 0.033 | 9.320 |
| Sad | 0.671 | 0.059 | 11.306 | 0.803 | 0.063 | 19.723 |
| Happy | 0.385 | 0.040 | 9.641 | 0.616 | 0.063 | 12.691 |
| Hopeful | 0.236 | 0.029 | 8.024 | 0.384 | 0.038 | 9.844 |
| Enjoyed Life | 0.185 | 0.031 | 6.068 | 0.550 | 0.039 | 10.021 |
| Good as Others | 0.146 | 0.031 | 4.698 | 0.301 | 0.039 | 14.115 |
| Everything an Effort | 0.245 | 0.027 | 9.059 | 0.527 | 0.032 | 7.691 |
| Poor Appetite | 0.181 | 0.033 | 5.485 | 0.384 | 0.037 | 16.535 |
| Difficulty Concentrating | 0.319 | 0.041 | 7.798 | 0.411 | 0.035 | 10.300 |
| Talked Less than Usual | 0.197 | 0.033 | 6.008 | 0.360 | 0.032 | 11.661 |
| Restless Sleep | 0.244 | 0.027 | 8.973 | 0.458 | 0.042 | 11.097 |
| Not Get Going | 0.262 | 0.042 | 6.208 | 0.490 | 0.041 | 11.858 |
| Fearful | 0.243 | 0.038 | 6.392 | 0.463 | 0.047 | 9.808 |
| Lonely | 0.353 | 0.029 | 12.134 | 0.590 | 0.058 | 10.147 |
| People Unfriendly | 0.195 | 0.036 | 5.353 | 0.274 | 0.028 | 9.845 |
| People Disliked Me | 0.249 | 0.047 | 5.318 | 0.317 | 0.034 | 9.426 |
| II. Synergies and Clustering in Chronic Conditions | ||||||
| 1. Diabetes x Hypertension with Medication (n = 77) | ||||||
| x Bothered by Things | 0.678 | 0.282 | 2.409 | |||
| x Life a Failure | 2.222 | 0.910 | 2.441 | 0.453 | 0.138 | 3.280 |
| x Crying Spells | 0.711 | 0.229 | 3.112 | |||
| x Depressed | ||||||
| x Blues | 0.689 | 0.259 | 2.663 | |||
| x Sad | 1.100 | 0.483 | 2.280 | 0.762 | 0.386 | 1.976 |
| x Happy | 0.670 | 0.320 | 2.097 | |||
| x Hopeful | 0.558 | 0.178 | 3.132 | |||
| x Enjoyed Life | 0.714 | 0.286 | 2.493 | |||
| x Good as Others | 0.502 | 0.187 | 2.684 | |||
| x Everything an Effort | 0.719 | 0.292 | 2.464 | |||
| x Poor Appetite | 0.586 | 0.192 | 3.054 | |||
| x Difficulty Concentrating | 0.728 | 0.311 | 2.340 | |||
| x Talked Less than Usual | 0.599 | 0.204 | 2.932 | |||
| x Restless Sleep | 0.576 | 0.236 | 2.437 | |||
| x Not Get Going | 0.419 | 0.176 | 2.384 | |||
| x Fearful | 0.647 | 0.244 | 2.651 | 0.491 | 0.213 | 2.301 |
| x Lonely | 0.694 | 0.314 | 2.209 | |||
| x People Unfriendly | 0.485 | 0.216 | 2.243 | |||
| x People Disliked Me | 1.373 | 0.606 | 2.266 | 0.383 | 0.136 | 2.811 |
| 2. Diabetes x Lost ten Pounds (n = 71) | ||||||
| x Bothered by Things | 0.700 | 0.189 | 3.706 | |||
| x Life a Failure | 0.570 | 0.214 | 2.665 | |||
| x Crying Spells | 0.661 | 0.205 | 3.226 | |||
| x Depressed | 0.702 | 0.179 | 3.928 | |||
| x Blues | 0.692 | 0.217 | 3.194 | |||
| x Sad | 1.877 | 0.322 | 5.830 | 0.692 | 0.179 | 3.855 |
| x Happy | 0.495 | 0.103 | 4.789 | |||
| x Hopeful | 0.544 | 0.113 | 4.803 | |||
| x Enjoyed Life | 0.390 | 0.090 | 4.335 | |||
| x Good as Others | 0.548 | 0.226 | 2.427 | 0.610 | 0.191 | 3.200 |
| x Everything an Effort | 0.568 | 0.086 | 6.615 | |||
| x Poor Appetite | 0.578 | 0.166 | 3.470 | |||
| x Difficulty Concentrating | 0.485 | 0.180 | 2.700 | 0.556 | 0.189 | 2.939 |
| x Talked Less than Usual | 0.333 | 0.085 | 3.925 | |||
| x Restless Sleep | 0.978 | 0.289 | 3.382 | 0.543 | 0.125 | 4.361 |
| x Not Get Going | 1.153 | 0.392 | 2.941 | 0.424 | 0.078 | 5.443 |
| x Fearful | 0.479 | 0.092 | 5.192 | |||
| x Lonely | 0.629 | 0.194 | 3.242 | |||
| x People Unfriendly | 0.385 | 0.087 | 4.408 | |||
| x People Disliked Me | 0.498 | 0.131 | 3.799 | |||
| Chronic Conditions & Subgroups | (A) Formative Indicators (Synergies) | (B) Reflective Indicators (Clustering Only) | ||||
|---|---|---|---|---|---|---|
| CES-D Depression Items | b | S.E. | z 2 | λ | S.E. | z 2 |
| 1. Diabetes x Hypertension (Males, n = 36) | ||||||
| x Bothered by Things | 2.536 | 0.873 | 2.906 | 0.624 | 0.126 | 4.956 |
| x Life a Failure | 0.711 | 0.190 | 3.746 | |||
| x Crying Spells | 0.550 | 0.219 | 2.517 | |||
| x Depressed | 0.798 | 0.116 | 6.886 | |||
| x Blues | 0.633 | 0.130 | 4.886 | |||
| x Sad | 0.659 | 0.101 | 6.534 | |||
| x Happy | 0.640 | 0.142 | 4.492 | |||
| x Hopeful | 0.586 | 0.102 | 5.753 | |||
| x Enjoyed Life | 3.126 | 0.895 | 3.492 | 0.648 | 0.213 | 3.043 |
| x Good as Others | 0.384 | 0.084 | 4.580 | |||
| x Everything an Effort | 0.797 | 0.161 | 4.951 | |||
| x Poor Appetite | 0.523 | 0.136 | 3.843 | |||
| x Difficulty Concentrating | 0.649 | 0.132 | 4.923 | |||
| x Talked Less than Usual | 0.649 | 0.157 | 4.130 | |||
| x Restless Sleep | 0.651 | 0.142 | 4.579 | |||
| x Not Get Going | 0.644 | 0.138 | 4.682 | |||
| x Fearful | 0.601 | 0.129 | 4.654 | |||
| x Lonely | 0.662 | 0.127 | 5.234 | |||
| x People Unfriendly | 1.023 | 0.326 | 3.139 | 0.454 | 0.097 | 4.661 |
| x People Disliked Me | 0.512 | 0.097 | 5.258 | |||
| 2. Diabetes x Silent Cerebrovascular Disease (Males, n = 31) | ||||||
| x Bothered by Things | 0.435 | 0.194 | 3.706 | |||
| x Life a Failure | 0.283 | 0.072 | 2.665 | |||
| x Depressed | 1.173 | 0.502 | 2.339 | 0.371 | 0.122 | 3.226 |
| x Blues | 2.564 | 0.647 | 3.961 | 0.142 | 0.052 | 3.928 |
| x Sad | 0.263 | 0.073 | 3.194 | |||
| x Happy | 1.360 | 0.400 | 3.400 | 0.415 | 0.161 | 3.855 |
| x Hopeful | 0.415 | 0.173 | 4.789 | |||
| x Enjoyed Life | 0.204 | 0.101 | 4.803 | |||
| x Good as Others | 0.134 | 0.038 | 4.335 | |||
| x Everything an Effort | 0.442 | 0.189 | 3.200 | |||
| x Poor Appetite | 0.281 | 0.076 | 6.615 | |||
| x Difficulty Concentrating | 0.457 | 0.212 | 3.470 | |||
| x Talked Less than Usual | 0.365 | 0.132 | 2.939 | |||
| x Restless Sleep | 0.391 | 0.162 | 3.925 | |||
| x Not Get Going | 0.344 | 0.107 | 4.361 | |||
| x Fearful | 1.092 | 0.494 | 2.211 | 0.323 | 0.112 | 5.443 |
| x Lonely | 0.485 | 0.235 | 5.192 | |||
| x People Unfriendly | 1.330 | 0.555 | 2.395 | 0.354 | 0.128 | 3.242 |
| x People Disliked Me | 0.402 | 0.229 | 4.408 | |||
| 3. Diabetes x Excess Weight (Males, n = 70) | ||||||
| x Bothered by Things | 0.700 | 0.190 | 3.695 | |||
| x Life a Failure | 0.716 | 0.264 | 2.709 | |||
| x Crying Spells | 0.562 | 0.156 | 3.609 | |||
| x Depressed | 0.824 | 0.226 | 3.650 | |||
| x Blues | 2.082 | 1.029 | 2.022 | 0.659 | 0.185 | 3.554 |
| x Sad | 0.700 | 0.175 | 4.006 | |||
| x Happy | 0.727 | 0.206 | 3.522 | |||
| x Hopeful | 0.553 | 0.148 | 3.725 | |||
| x Enjoyed Life | 0.687 | 0.262 | 2.620 | |||
| x Good as Others | 0.386 | 0.092 | 4.213 | |||
| x Everything an Effort | 0.695 | 0.208 | 3.343 | |||
| x Poor Appetite | 0.317 | 0.117 | 2.712 | |||
| x Difficulty Concentrating | 0.705 | 0.192 | 3.671 | |||
| x Talked Less than Usual | 0.694 | 0.211 | 3.29 | |||
| x Restless Sleep | 0.517 | 0.165 | 3.140 | |||
| x Not Get Going | 0.676 | 0.192 | 3.530 | |||
| x Fearful | 0.610 | 0.241 | 2.533 | |||
| x Lonely | 0.956 | 0.416 | 2.297 | 0.730 | 0.215 | 3.393 |
| x People Unfriendly | 0.558 | 0.137 | 4.075 | |||
| x People Disliked Me | 0.584 | 0.126 | 4.629 | |||
| 4. Diabetes x Heart Attack (Females, n = 34) | ||||||
| x Bothered by Things | 0.495 | 0.136 | 3.626 | |||
| x Life a Failure | 0.360 | 0.123 | 2.935 | |||
| x Crying Spells | 0.332 | 0.142 | 2.329 | |||
| x Depressed | 0.587 | 0.115 | 5.081 | |||
| x Blues | 0.452 | 0.098 | 4.604 | |||
| x Sad | 0.520 | 0.109 | 4.774 | |||
| x Happy | 0.598 | 0.105 | 5.699 | |||
| x Hopeful | 2.082 | 0.334 | 6.230 | 0.479 | 0.069 | 6.964 |
| x Enjoyed Life | 0.438 | 0.127 | 3.448 | |||
| x Good as Others | ||||||
| x Everything an Effort | 0.489 | 0.073 | 6.651 | |||
| x Poor Appetite | 0.863 | 0.440 | 1.964 | 0.486 | 0.108 | 4.517 |
| x Difficulty Concentrating | 0.934 | 0.386 | 2.419 | 0.490 | 0.120 | 4.089 |
| x Talked Less than Usual | 0.376 | 0.136 | 2.756 | |||
| x Restless Sleep | 2.261 | 0.641 | 3.526 | 0.489 | 0.070 | 6.945 |
| x Not Get Going | 1.365 | 0.566 | 2.413 | 0.517 | 0.077 | 6.742 |
| x Fearful | 0.503 | 0.104 | 4.856 | |||
| x Lonely | 0.421 | 0.131 | 3.221 | |||
| x People Unfriendly | 10.897 | 1.907 | 5.713 | 0.245 | 0.035 | 6.909 |
| x People Disliked Me | 0.306 | 0.060 | 5.073 | |||
| 5. Diabetes x Heart Failure (Females, n = 39) | ||||||
| x Bothered by Things | 0.489 | 0.074 | 6.609 | |||
| x Life a Failure | 0.336 | 0.115 | 2.926 | |||
| x Crying Spells | 0.450 | 0.110 | 4.087 | |||
| x Depressed | 0.555 | 0.090 | 6.189 | |||
| x Blues | 1.327 | 0.566 | 2.346 | 0.501 | 0.059 | 8.539 |
| x Sad | 0.553 | 0.078 | 7.072 | |||
| x Happy | 1.309 | 0.366 | 3.578 | 0.468 | 0.114 | 4.111 |
| x Hopeful | 0.452 | 0.085 | 5.330 | |||
| x Enjoyed Life | 0.497 | 0.085 | 5.851 | |||
| x Good as Others | 0.332 | 0.093 | 3.580 | |||
| x Everything an Effort | 1.186 | 0.446 | 2.659 | 0.464 | 0.058 | 8.059 |
| x Poor Appetite | 0.509 | 0.060 | 8.445 | |||
| x Difficulty Concentrating | 0.946 | 0.473 | 1.998 | 0.474 | 0.088 | 5.354 |
| x Talked Less than Usual | 0.762 | 0.253 | 3.012 | 0.399 | 0.049 | 8.132 |
| x Restless Sleep | 0.409 | 0.099 | 4.111 | |||
| x Not Get Going | 0.424 | 0.107 | 3.954 | |||
| x Fearful | 0.360 | 0.085 | 4.250 | |||
| x Lonely | 0.496 | 0.058 | 8.620 | |||
| x People Unfriendly | 2.717 | 1.333 | 2.039 | 0.272 | 0.049 | 5.493 |
| x People Disliked Me | 0.230 | 0.037 | 6.249 | |||
| 6. Diabetes x Cancer (Females, n = 35) | ||||||
| x Bothered by Things | 1.154 | 0.341 | 3.380 | 0.452 | 0.188 | 2.409 |
| x Life a Failure | 0.359 | 0.119 | 3.021 | |||
| x Crying Spells | 1.763 | 0.470 | 3.750 | 0.516 | 0.219 | 2.360 |
| x Depressed | 0.630 | 0.216 | 2.920 | |||
| x Blues | 2.392 | 0.526 | 4.549 | 0.488 | 0.247 | 1.975 |
| x Sad | ||||||
| x Happy | ||||||
| x Hopeful | ||||||
| x Enjoyed Life | 1.133 | 0.423 | 2.682 | |||
| x Good as Others | 0.326 | 0.163 | 2.005 | |||
| x Everything an Effort | 0.518 | 0.225 | 2.305 | |||
| x Poor Appetite | 0.487 | 0.239 | 2.039 | |||
| x Difficulty Concentrating | ||||||
| x Talked Less than Usual | ||||||
| x Restless Sleep | ||||||
| x Not Get Going | 0.410 | 0.189 | 2.171 | |||
| x Fearful | 0.439 | 0.214 | 2.057 | |||
| x Lonely | 0.454 | 0.195 | 2.327 | |||
| x People Unfriendly | ||||||
| x People Disliked Me | 1.713 | 0.264 | 6.495 | 0.284 | 0.096 | 2.954 |
| 7. Diabetes x Smoking (Males, n = 31) | ||||||
| x Bothered by Things | 1.706 | 0.851 | 2.004 | 0.363 | 0.099 | 3.674 |
| x Life a Failure | ||||||
| x Crying Spells | ||||||
| x Depressed | 0.472 | 0.164 | 2.874 | |||
| x Blues | 0.426 | 0.121 | 3.518 | |||
| x Sad | 0.436 | 0.125 | 3.478 | |||
| x Happy | 0.362 | 0.108 | 3.361 | |||
| x Hopeful | 0.400 | 0.122 | 3.292 | |||
| x Enjoyed Life | 0.236 | 0.048 | 4.912 | |||
| x Good as Others | ||||||
| x Everything an Effort | 0.477 | 0.141 | 3.388 | |||
| x Poor Appetite | 0.311 | 0.081 | 3.826 | |||
| x Difficulty Concentrating | 1.620 | 0.715 | 2.265 | 0.325 | 0.148 | 2.199 |
| x Talked Less than Usual | 0.320 | 0.160 | 2.008 | |||
| x Restless Sleep | 0.342 | 0.116 | 2.959 | |||
| x Not Get Going | 0.343 | 0.095 | 3.602 | |||
| x Fearful | 0.310 | 0.111 | 2.804 | |||
| x Lonely | 0.388 | 0.119 | 3.250 | |||
| x People Unfriendly | 0.370 | 0.106 | 3.500 | |||
| x People Disliked Me | ||||||
| 8. Diabetes x Smoking (Females, n = 39) | ||||||
| x Bothered by Things | 0.684 | 0.183 | 3.742 | |||
| x Life a Failure | 0.437 | 0.124 | 3.510 | |||
| x Crying Spells | 0.497 | 0.128 | 3.892 | |||
| x Depressed | 0.663 | 0.178 | 3.728 | |||
| x Blues | 0.589 | 0.156 | 3.778 | |||
| x Sad | 2.186 | 0.602 | 3.631 | 0.563 | 0.149 | 3.771 |
| x Happy | 0.400 | 0.134 | 2.980 | |||
| x Hopeful | 0.466 | 0.119 | 3.905 | |||
| x Enjoyed Life | 0.442 | 0.128 | 3.442 | |||
| x Good as Others | 0.433 | 0.136 | 3.180 | |||
| x Everything an Effort | 0.479 | 0.113 | 4.228 | |||
| x Poor Appetite | 0.565 | 0.116 | 4.870 | |||
| x Difficulty Concentrating | 1.706 | 0.648 | 2.632 | 0.617 | 0.221 | 2.789 |
| x Talked Less than Usual | 0.403 | 0.134 | 3.003 | |||
| x Restless Sleep | 0.510 | 0.153 | 3.335 | |||
| x Not Get Going | 1.562 | 0.708 | 2.208 | 0.408 | 0.109 | 3.753 |
| x Fearful | 1.746 | 0.808 | 2.161 | 0.327 | 0.107 | 3.064 |
| x Lonely | 1.631 | 0.664 | 2.455 | 0.449 | 0.120 | 3.734 |
| x People Unfriendly | 0.362 | 0.135 | 2.677 | |||
| x People Disliked Me | 4.112 | 1.483 | 2.773 | 0.302 | 0.124 | 2.435 |
| Chronic Conditions & Subgroups | (A) Formative Indicators (Synergies) | (B) Reflective Indicators (Clustering Only) | ||||
|---|---|---|---|---|---|---|
| CES-D Depression Items | b | S.E. | z 2 | λ | S.E. | z 2 |
| I. Synergies and Clustering in Hypertension | ||||||
| 1. Diabetes x Hypertension (Ages 65–74, n = 56) | ||||||
| x Bothered by Things | 2.071 | 0.550 | 3.764 | 0.642 | 0.109 | 5.907 |
| x Life a Failure | 0.500 | 0.126 | 3.958 | |||
| x Crying Spells | 0.558 | 0.133 | 4.196 | |||
| x Depressed | 0.737 | 0.133 | 5.544 | |||
| x Blues | 0.656 | 0.118 | 5.558 | |||
| x Sad | 0.676 | 0.130 | 5.185 | |||
| x Happy | 0.540 | 0.150 | 3.599 | |||
| x Hopeful | 0.523 | 0.092 | 5.707 | |||
| x Enjoyed Life | 0.565 | 0.113 | 4.987 | |||
| x Good as Others | 0.375 | 0.123 | 3.039 | |||
| x Everything an Effort | 0.695 | 0.119 | 5.835 | |||
| x Poor Appetite | 0.630 | 0.114 | 5.530 | |||
| x Difficulty Concentrating | 0.570 | 0.078 | 7.281 | |||
| x Talked Less than Usual | 1.337 | 0.423 | 3.163 | 0.463 | 0.081 | 5.710 |
| x Restless Sleep | 0.498 | 0.126 | 3.967 | |||
| x Not Get Going | 0.491 | 0.125 | 3.933 | |||
| x Fearful | 0.493 | 0.124 | 3.982 | |||
| x Lonely | 0.649 | 0.131 | 4.936 | |||
| x People Unfriendly | 0.325 | 0.106 | 3.076 | |||
| x People Disliked Me | 0.281 | 0.081 | 3.474 | |||
| 2. Diabetes x Hypertension (Over Age 74, n = 55) | ||||||
| x Bothered by Things | 1.626 | 0.536 | 3.032 | 0.568 | 0.133 | 4.278 |
| x Life a Failure | 0.403 | 0.078 | 5.147 | |||
| x Crying Spells | 0.536 | 0.173 | 3.095 | |||
| x Depressed | 0.770 | 0.224 | 3.445 | |||
| x Blues | 0.668 | 0.160 | 4.185 | |||
| x Sad | 0.849 | 0.384 | 2.210 | 0.724 | 0.208 | 3.472 |
| x Happy | 0.688 | 0.199 | 3.457 | |||
| x Hopeful | 0.619 | 0.152 | 4.082 | |||
| x Enjoyed Life | 0.617 | 0.173 | 3.570 | |||
| x Good as Others | 0.367 | 0.161 | 2.285 | |||
| x Everything an Effort | 1.280 | 0.492 | 2.602 | 0.637 | 0.138 | 4.629 |
| x Poor Appetite | 0.298 | 0.092 | 3.245 | |||
| x Difficulty Concentrating | 0.534 | 0.115 | 4.651 | |||
| x Talked Less than Usual | 0.715 | 0.224 | 3.201 | |||
| x Restless Sleep | 0.665 | 0.294 | 2.261 | |||
| x Not Get Going | 0.414 | 0.137 | 3.035 | |||
| x Fearful | 2.220 | 0.753 | 2.946 | 0.544 | 0.200 | 2.714 |
| x Lonely | 0.627 | 0.146 | 4.280 | |||
| x People Unfriendly | 0.567 | 0.174 | 3.259 | |||
| x People Disliked Me | 0.388 | 0.089 | 4.343 | |||
| 3. Diabetes x Hypertension with No Medication(Ages 65–74, n = 56) | ||||||
| x Bothered by Things | 2.068 | 0.551 | 3.752 | 0.647 | 0.112 | 5.804 |
| x Life a Failure | 0.503 | 0.127 | 3.967 | |||
| x Crying Spells | 0.567 | 0.134 | 4.234 | |||
| x Depressed | 0.747 | 0.138 | 5.422 | |||
| x Blues | 0.664 | 0.122 | 5.425 | |||
| x Sad | 0.684 | 0.134 | 5.092 | |||
| x Happy | 0.543 | 0.152 | 3.569 | |||
| x Hopeful | 0.524 | 0.093 | 5.624 | |||
| x Enjoyed Life | 0.568 | 0.116 | 4.901 | |||
| x Good as Others | 0.377 | 0.180 | 2.101 | |||
| x Everything an Effort | 0.704 | 0.122 | 5.755 | |||
| x Poor Appetite | 0.638 | 0.116 | 5.480 | |||
| x Difficulty Concentrating | 0.570 | 0.079 | 7.184 | |||
| x Talked Less than Usual | 1.336 | 0.423 | 3.162 | 0.464 | 0.082 | 5.682 |
| x Restless Sleep | 0.499 | 0.127 | 3.929 | |||
| x Not Get Going | 0.492 | 0.126 | 3.906 | |||
| x Fearful | 0.495 | 0.125 | 3.944 | |||
| x Lonely | 0.654 | 0.136 | 4.822 | |||
| x People Unfriendly | 0.325 | 0.116 | 2.796 | |||
| x People Disliked Me | 0.283 | 0.079 | 3.581 | |||
| 4. Diabetes x Hypertension with No Medication(Over Age 74, n = 54) | ||||||
| x Bothered by Things | 1.609 | 0.554 | 2.905 | 0.571 | 0.129 | 4.44 |
| x Life a Failure | 0.405 | 0.077 | 5.252 | |||
| x Crying Spells | 0.537 | 0.166 | 3.238 | |||
| x Depressed | 0.768 | 0.205 | 3.743 | |||
| x Blues | 0.668 | 0.150 | 4.448 | |||
| x Sad | 0.726 | 0.192 | 3.773 | |||
| x Happy | 0.690 | 0.186 | 3.715 | |||
| x Hopeful | 0.622 | 0.141 | 4.411 | |||
| x Enjoyed Life | 0.618 | 0.166 | 3.729 | |||
| x Good as Others | 0.369 | 0.152 | 2.435 | |||
| x Everything an Effort | 1.293 | 0.524 | 2.469 | 0.637 | 0.130 | 4.908 |
| x Poor Appetite | 0.304 | 0.090 | 3.385 | |||
| x Difficulty Concentrating | 0.535 | 0.107 | 5.002 | |||
| x Talked Less than Usual | 0.715 | 0.209 | 3.424 | |||
| x Restless Sleep | 0.668 | 0.162 | 4.128 | |||
| x Not Get Going | 0.419 | 0.139 | 3.018 | |||
| x Fearful | 2.207 | 0.736 | 2.999 | 0.546 | 0.202 | 2.701 |
| x Lonely | 0.642 | 0.325 | 1.977 | 0.632 | 0.140 | 4.523 |
| x People Unfriendly | 0.567 | 0.164 | 3.452 | |||
| x People Disliked Me | 0.390 | 0.086 | 4.523 | |||
| 5. Diabetes x Suspected Hypertension (Over Age 74, n = 8) | ||||||
| x Bothered by Things | 0.812 | 0.213 | 3.816 | |||
| x Life a Failure | 0.640 | 0.139 | 4.611 | |||
| x Crying Spells | 0.752 | 0.157 | 4.781 | |||
| x Depressed | 1.052 | 0.340 | 3.098 | |||
| x Blues | 0.967 | 0.286 | 3.382 | |||
| x Sad | 0.941 | 0.288 | 3.269 | |||
| x Happy | 0.948 | 0.273 | 3.479 | |||
| x Hopeful | 0.783 | 0.223 | 3.506 | |||
| x Enjoyed Life | 0.918 | 0.255 | 3.601 | |||
| x Good as Others | 0.579 | 0.186 | 3.111 | |||
| x Everything an Effort | 0.938 | 0.264 | 3.561 | |||
| x Poor Appetite | 0.456 | 0.118 | 3.859 | |||
| x Difficulty Concentrating | 0.678 | 0.148 | 4.569 | |||
| x Talked Less than Usual | 0.906 | 0.330 | 2.742 | |||
| x Restless Sleep | 0.827 | 0.249 | 3.325 | |||
| x Not Get Going | 0.587 | 0.147 | 3.995 | |||
| x Fearful | 2.231 | 0.766 | 2.914 | 0.698 | 0.221 | 3.153 |
| x Lonely | 0.879 | 0.249 | 3.532 | |||
| x People Unfriendly | 0.704 | 0.207 | 3.406 | |||
| x People Disliked Me | 0.585 | 0.115 | 5.070 | |||
| 6. Diabetes x Hypertension with No Medication or Suspected Hypertension (Ages 65–74, n = 56) | ||||||
| x Bothered by Things | 2.078 | 0.552 | 3.765 | 0.645 | 0.110 | 5.844 |
| x Life a Failure | 0.501 | 0.127 | 3.948 | |||
| x Crying Spells | 0.562 | 0.133 | 4.216 | |||
| x Depressed | 0.741 | 0.136 | 5.465 | |||
| x Blues | 0.659 | 0.120 | 5.489 | |||
| x Sad | 0.680 | 0.133 | 5.126 | |||
| x Happy | 0.541 | 0.151 | 3.572 | |||
| x Hopeful | 0.523 | 0.093 | 5.633 | |||
| x Enjoyed Life | 0.566 | 0.115 | 4.929 | |||
| x Good as Others | 0.376 | 0.124 | 3.023 | |||
| x Everything an Effort | 0.699 | 0.121 | 5.771 | |||
| x Poor Appetite | 0.633 | 0.115 | 5.491 | |||
| x Difficulty Concentrating | 0.570 | 0.079 | 7.221 | |||
| x Talked Less than Usual | 1.339 | 0.424 | 3.160 | 0.464 | 0.082 | 5.684 |
| x Restless Sleep | 0.499 | 0.126 | 3.946 | |||
| x Not Get Going | 0.492 | 0.126 | 3.911 | |||
| x Fearful | 0.494 | 0.125 | 3.942 | |||
| x Lonely | 0.651 | 0.134 | 4.871 | |||
| x People Unfriendly | 0.325 | 0.116 | 2.798 | |||
| x People Disliked Me | 0.282 | 0.080 | 3.546 | |||
| II. Synergies and Clustering in Other Conditions | ||||||
| 1. Diabetes x Silent Cerebrovascular Disease(Ages 65–74, n = 39) | ||||||
| x Bothered by Things | 0.521 | 0.094 | 5.537 | |||
| x Life a Failure | 0.399 | 0.139 | 2.874 | |||
| x Crying Spells | 0.630 | 0.318 | 1.978 | 0.406 | 0.089 | 4.578 |
| x Depressed | 0.536 | 0.097 | 5.524 | |||
| x Blues | 0.778 | 0.288 | 2.706 | 0.491 | 0.078 | 6.285 |
| x Sad | 0.513 | 0.093 | 5.546 | |||
| x Happy | 1.077 | 0.206 | 5.219 | 0.529 | 0.077 | 6.910 |
| x Hopeful | 0.419 | 0.072 | 5.831 | |||
| x Enjoyed Life | 0.492 | 0.190 | 2.594 | |||
| x Good as Others | 0.356 | 0.112 | 3.179 | |||
| x Everything an Effort | 1.047 | 0.493 | 2.125 | 0.365 | 0.082 | 4.447 |
| x Poor Appetite | 0.475 | 0.093 | 5.113 | |||
| x Difficulty Concentrating | 0.677 | 0.219 | 3.097 | 0.417 | 0.091 | 4.590 |
| x Talked Less than Usual | 0.384 | 0.080 | 4.780 | |||
| x Restless Sleep | 0.412 | 0.067 | 6.120 | |||
| x Not Get Going | 0.466 | 0.086 | 5.439 | |||
| x Fearful | 0.363 | 0.090 | 4.014 | |||
| x Lonely | 0.409 | 0.098 | 4.183 | |||
| x People Unfriendly | 1.928 | 0.766 | 2.518 | 0.244 | 0.090 | 2.702 |
| x People Disliked Me | 0.320 | 0.154 | 2.075 | |||
| 2. Stroke with No Diabetes (Over Age 74, n = 39) | ||||||
| Stroke with No Diabetes | 15.656 | 1.404 | 11.155 | |||
| x Bothered by Things | 0.444 | 0.042 | 10.595 | |||
| x Life a Failure | 0.334 | 0.052 | 6.410 | |||
| x Crying Spells | 0.393 | 0.111 | 3.554 | |||
| x Depressed | 0.499 | 0.072 | 6.953 | |||
| x Blues | 0.476 | 0.086 | 5.513 | |||
| x Sad | 0.439 | 0.078 | 5.610 | |||
| x Happy | 0.495 | 0.090 | 5.473 | |||
| x Hopeful | 0.234 | 0.108 | 2.164 | 0.398 | 0.043 | 9.325 |
| x Enjoyed Life | 0.444 | 0.083 | 5.327 | |||
| x Good as Others | 0.369 | 0.064 | 5.724 | |||
| x Everything an Effort | 0.541 | 0.231 | 2.345 | 0.463 | 0.090 | 5.161 |
| x Poor Appetite | 0.544 | 0.192 | 2.840 | 0.419 | 0.080 | 5.249 |
| x Difficulty Concentrating | 1.610 | 0.487 | 3.305 | 0.445 | 0.040 | 11.162 |
| x Talked Less than Usual | 0.595 | 0.280 | 2.123 | 0.454 | 0.060 | 7.548 |
| x Restless Sleep | 0.404 | 0.054 | 7.413 | |||
| x Not Get Going | 0.421 | 0.046 | 9.227 | |||
| x Fearful | 0.512 | 0.129 | 3.984 | |||
| x Lonely | 0.423 | 0.083 | 5.061 | |||
| x People Unfriendly | 0.633 | 0.207 | 3.055 | 0.386 | 0.083 | 4.671 |
| x People Disliked Me | 0.422 | 0.113 | 3.753 | |||
| 3. Diabetes x Heart Attack (Over Age 74, n = 37) | ||||||
| x Bothered by Things | 0.505 | 0.128 | 3.953 | |||
| x Life a Failure | 0.366 | 0.123 | 2.966 | |||
| x Crying Spells | ||||||
| x Depressed | 0.549 | 0.143 | 3.851 | |||
| x Blues | 1.740 | 0.646 | 2.693 | 0.386 | 0.133 | 2.912 |
| x Sad | 2.536 | 0.820 | 3.094 | 0.461 | 0.138 | 3.348 |
| x Happy | 0.541 | 0.127 | 4.26 | |||
| x Hopeful | 0.421 | 0.095 | 4.421 | |||
| x Enjoyed Life | 0.383 | 0.158 | 2.424 | |||
| x Good as Others | 0.295 | 0.095 | 3.102 | |||
| x Everything an Effort | 0.463 | 0.089 | 5.186 | |||
| x Poor Appetite | 0.471 | 0.114 | 4.126 | |||
| x Difficulty Concentrating | 0.449 | 0.119 | 3.780 | |||
| x Talked Less than Usual | 0.396 | 0.125 | 3.173 | |||
| x Restless Sleep | 0.492 | 0.092 | 5.366 | |||
| x Not Get Going | 1.327 | 0.458 | 2.899 | 0.492 | 0.101 | 4.867 |
| x Fearful | 2.530 | 1.210 | 2.091 | 0.465 | 0.112 | 4.159 |
| x Lonely | 1.109 | 0.348 | 3.193 | 0.395 | 0.128 | 3.092 |
| x People Unfriendly | 0.272 | 0.047 | 5.816 | |||
| x People Disliked Me | 5.042 | 1.211 | 4.165 | 0.225 | 0.052 | 4.332 |
| 4. Diabetes x Excess Weight (Ages 65–74, n = 100) | ||||||
| x Bothered by Things | 0.756 | 0.104 | 7.245 | |||
| x Life a Failure | 0.577 | 0.124 | 4.669 | |||
| x Crying Spells | 0.800 | 0.160 | 5.004 | |||
| x Depressed | 0.883 | 0.123 | 7.179 | |||
| x Blues | 1.804 | 0.496 | 3.640 | 0.800 | 0.099 | 8.068 |
| x Sad | 0.987 | 0.139 | 7.113 | |||
| x Happy | 0.743 | 0.300 | 2.475 | 0.694 | 0.145 | 4.793 |
| x Hopeful | 0.586 | 0.077 | 7.626 | |||
| x Enjoyed Life | 0.797 | 0.103 | 7.730 | |||
| x Good as Others | 0.527 | 0.108 | 4.864 | |||
| x Everything an Effort | 0.769 | 0.088 | 8.766 | |||
| x Poor Appetite | 0.618 | 0.118 | 5.238 | |||
| x Difficulty Concentrating | 1.111 | 0.351 | 3.167 | 0.613 | 0.106 | 5.799 |
| x Talked Less than Usual | 0.628 | 0.088 | 7.167 | |||
| x Restless Sleep | 0.540 | 0.073 | 7.353 | |||
| x Not Get Going | 1.107 | 0.553 | 2.001 | 0.563 | 0.077 | 7.359 |
| x Fearful | 0.938 | 0.367 | 2.554 | 0.534 | 0.101 | 5.304 |
| x Lonely | 0.608 | 0.300 | 2.022 | 0.731 | 0.120 | 6.075 |
| x People Unfriendly | 0.859 | 0.281 | 3.059 | 0.535 | 0.112 | 4.758 |
| x People Disliked Me | 0.441 | 0.058 | 7.607 | |||
| 5. Diabetes x Heart Failure (Over Age 74, n = 32) | ||||||
| x Bothered by Things | 1.685 | 0.640 | 2.633 | |||
| x Life a Failure | ||||||
| x Crying Spells | 2.770 | 1.210 | 2.289 | |||
| x Depressed | ||||||
| x Blues | 4.452 | 1.578 | 2.821 | |||
| x Sad | 1.046 | 0.436 | 2.401 | |||
| x Happy | ||||||
| x Hopeful | ||||||
| x Enjoyed Life | ||||||
| x Good as Others | ||||||
| x Everything an Effort | ||||||
| x Poor Appetite | 0.861 | 0.409 | 2.106 | |||
| x Difficulty Concentrating | 0.836 | 0.397 | 2.105 | |||
| x Talked Less than Usual | ||||||
| x Restless Sleep | ||||||
| x Not Get Going | 3.269 | 1.208 | 2.706 | |||
| x Fearful | 4.791 | 2.060 | 2.326 | |||
| x Lonely | 2.057 | 0.822 | 2.503 | |||
| x People Unfriendly | 0.742 | 0.287 | 2.582 | |||
| x People Disliked Me | 5.820 | 2.436 | 2.389 | |||
| 6. Diabetes x Smoking (Ages 65–74, n = 39) | ||||||
| x Bothered by Things | 0.564 | 0.088 | 6.391 | |||
| x Life a Failure | 0.418 | 0.111 | 3.754 | |||
| x Crying Spells | 0.518 | 0.093 | 5.569 | |||
| x Depressed | 0.635 | 0.112 | 5.661 | |||
| x Blues | 0.619 | 0.098 | 6.303 | |||
| x Sad | 1.763 | 0.525 | 3.355 | 0.574 | 0.108 | 5.301 |
| x Happy | 0.448 | 0.113 | 3.966 | |||
| x Hopeful | 0.459 | 0.073 | 6.269 | |||
| x Enjoyed Life | 0.568 | 0.086 | 6.589 | |||
| x Good as Others | 0.392 | 0.146 | 2.689 | |||
| x Everything an Effort | 1.109 | 0.300 | 3.701 | 0.431 | 0.079 | 5.476 |
| x Poor Appetite | 0.485 | 0.071 | 6.791 | |||
| x Difficulty Concentrating | 0.543 | 0.109 | 4.987 | |||
| x Talked Less than Usual | 0.443 | 0.096 | 4.634 | |||
| x Restless Sleep | 0.435 | 0.097 | 4.490 | |||
| x Not Get Going | 0.429 | 0.086 | 4.997 | |||
| x Fearful | 1.785 | 0.718 | 2.486 | 0.345 | 0.073 | 4.691 |
| x Lonely | 0.458 | 0.097 | 4.733 | |||
| x People Unfriendly | 0.342 | 0.078 | 4.398 | |||
| x People Disliked Me | 0.286 | 0.116 | 2.461 | |||
| 7. Diabetes x Lost Ten Pounds (Ages 65–74, n = 39) | ||||||
| x Bothered by Things | 3.227 | 0.920 | 3.509 | 0.533 | 0.164 | 3.243 |
| x Life a Failure | 0.202 | 0.056 | 3.595 | |||
| x Crying Spells | 0.374 | 0.189 | 1.978 | |||
| x Depressed | 2.032 | 0.737 | 2.757 | 0.474 | 0.155 | 3.060 |
| x Blues | 0.457 | 0.146 | 3.122 | |||
| x Sad | 0.512 | 0.140 | 3.663 | |||
| x Happy | 0.450 | 0.118 | 3.820 | |||
| x Hopeful | 0.456 | 0.116 | 3.943 | |||
| x Enjoyed Life | 0.392 | 0.076 | 5.172 | |||
| x Good as Others | 0.916 | 0.327 | 2.804 | 0.358 | 0.133 | 2.699 |
| x Everything an Effort | 0.447 | 0.117 | 3.807 | |||
| x Poor Appetite | 0.396 | 0.152 | 2.610 | |||
| x Difficulty Concentrating | 1.292 | 0.379 | 3.414 | 0.478 | 0.109 | 4.397 |
| x Talked Less than Usual | 0.372 | 0.140 | 2.659 | |||
| x Restless Sleep | 0.424 | 0.100 | 4.243 | |||
| x Not Get Going | 0.465 | 0.110 | 4.244 | |||
| x Fearful | 2.695 | 0.438 | 6.157 | 0.393 | 0.150 | 2.621 |
| x Lonely | 0.470 | 0.161 | 2.927 | |||
| x People Unfriendly | ||||||
| x People Disliked Me | 0.402 | 0.204 | 1.972 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Francoeur, R.B. Synergies vs. Clustering Only of Depressive Symptoms in Diabetes and Co-Occurring Conditions: Symmetric Indicators with Asymmetric, Bidirectional Influences in MIMIC Models. Symmetry 2022, 14, 2275. https://doi.org/10.3390/sym14112275
Francoeur RB. Synergies vs. Clustering Only of Depressive Symptoms in Diabetes and Co-Occurring Conditions: Symmetric Indicators with Asymmetric, Bidirectional Influences in MIMIC Models. Symmetry. 2022; 14(11):2275. https://doi.org/10.3390/sym14112275
Chicago/Turabian StyleFrancoeur, Richard B. 2022. "Synergies vs. Clustering Only of Depressive Symptoms in Diabetes and Co-Occurring Conditions: Symmetric Indicators with Asymmetric, Bidirectional Influences in MIMIC Models" Symmetry 14, no. 11: 2275. https://doi.org/10.3390/sym14112275
APA StyleFrancoeur, R. B. (2022). Synergies vs. Clustering Only of Depressive Symptoms in Diabetes and Co-Occurring Conditions: Symmetric Indicators with Asymmetric, Bidirectional Influences in MIMIC Models. Symmetry, 14(11), 2275. https://doi.org/10.3390/sym14112275