
Context-Unsupervised Adversarial Network for Video Sensors †


Abstract
:1. Introduction
- An algorithm that can be integrated in video sensors and used in a wide variety of scenarios without requiring context adjustment is proposed.
- The two-step scheme proposed for foreground segmentation provides results superior to the ones obtained by conventional, non-learning based methods, using a convolutional neural network which does not require specific scene training.
- An image-to-image translation network is adapted to be used as a refinement network, by conditioning the output not only on the input image, but also on the rough mask obtained by the statistical based background subtraction.
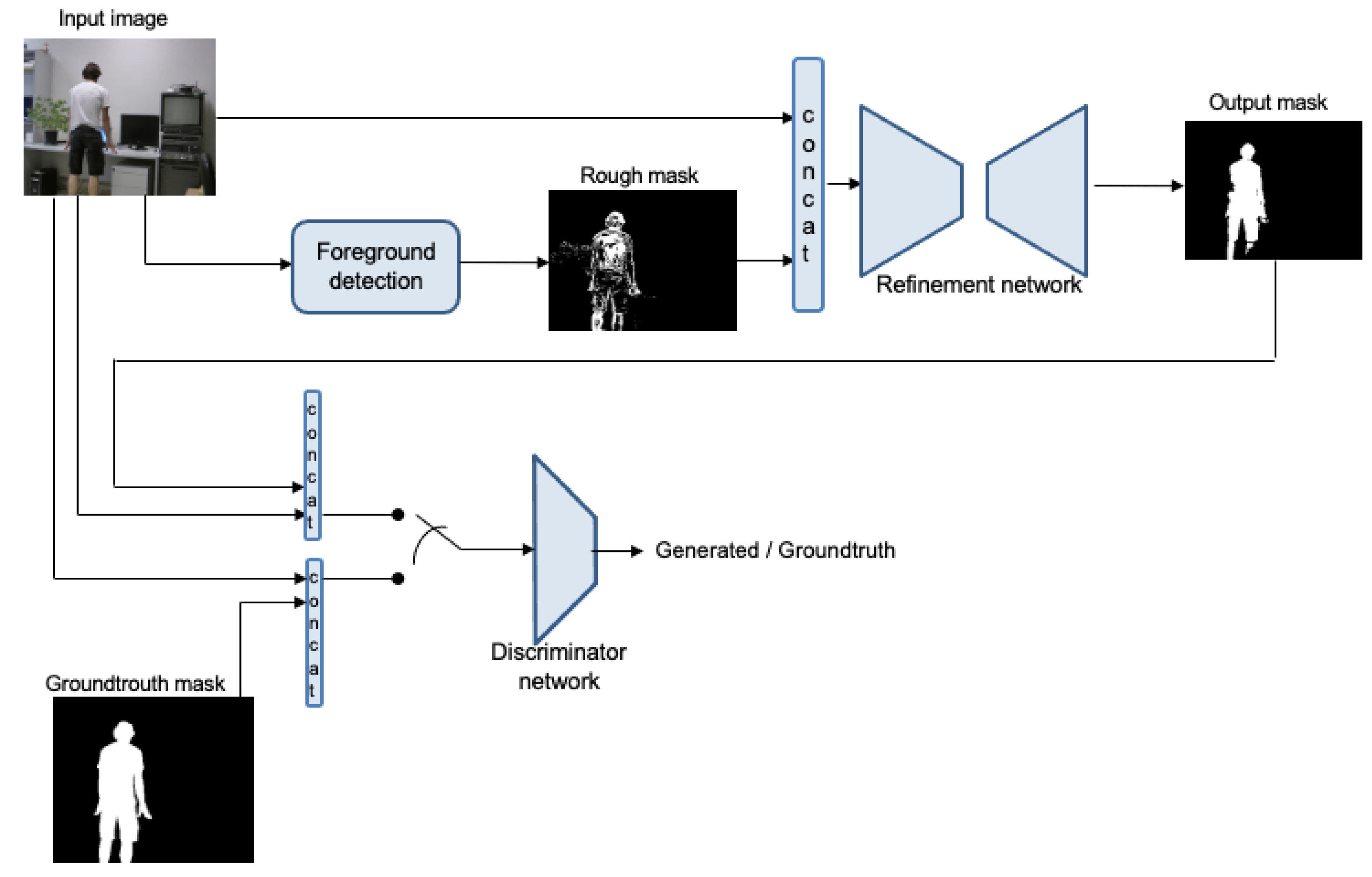
- It is shown that, in a vision task, it is also advantageous to model the loss function with an adversarial network in order to provide better generalization and accuracy.
- An example of how learning based techniques can be used in conjunction with non-learning methods is provided. This allows one to introduce high level features according to the application and scenario, which currently cannot be used in most deep learning systems.
2. Related Works
2.1. Classical Approaches to Foreground Detection by Background Modeling and Subtraction
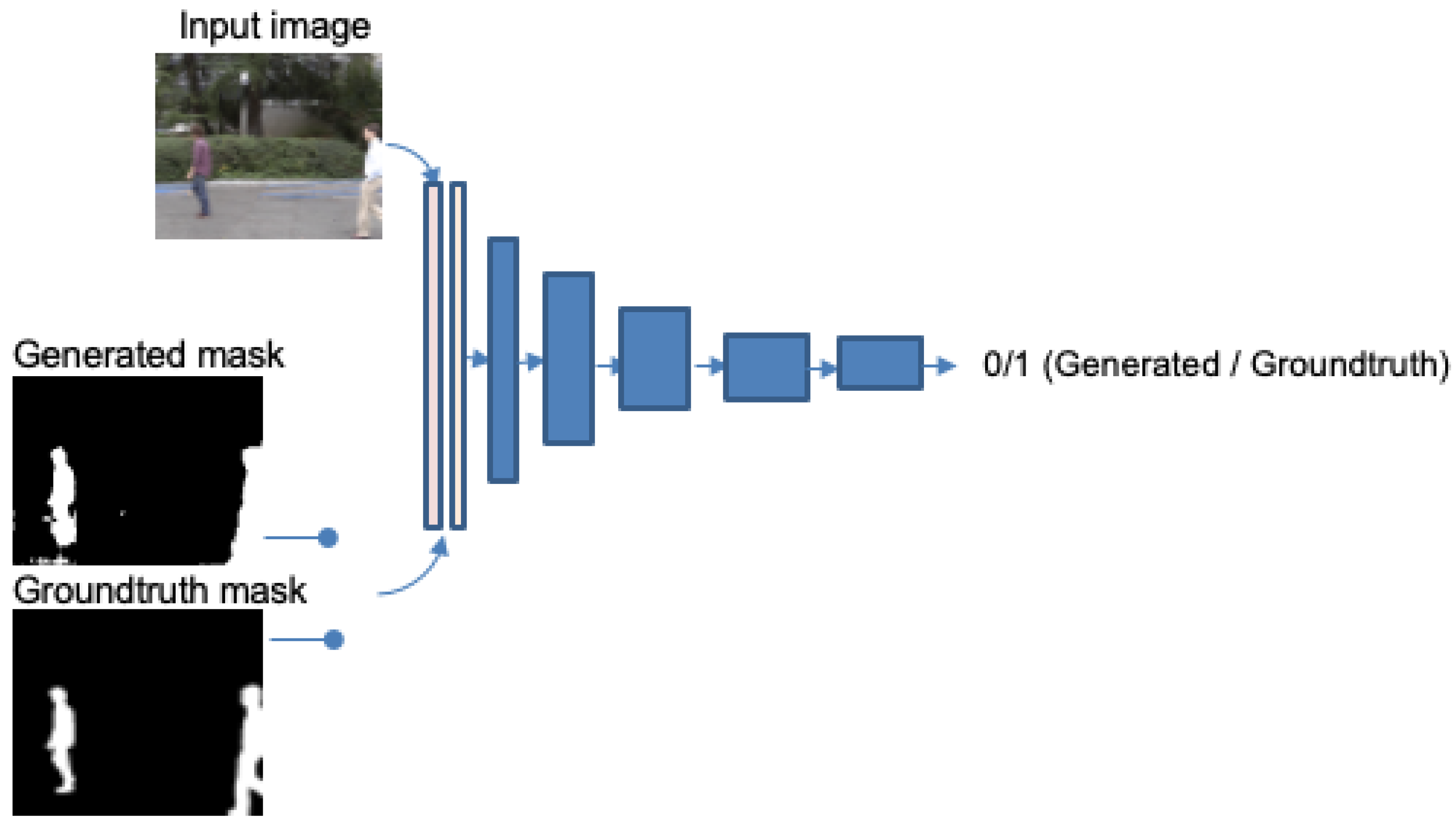
2.2. Adversarial Networks
2.3. Deep Learning Approaches to Foreground Detection
2.3.1. Background Modeling
2.3.2. Background Subtraction
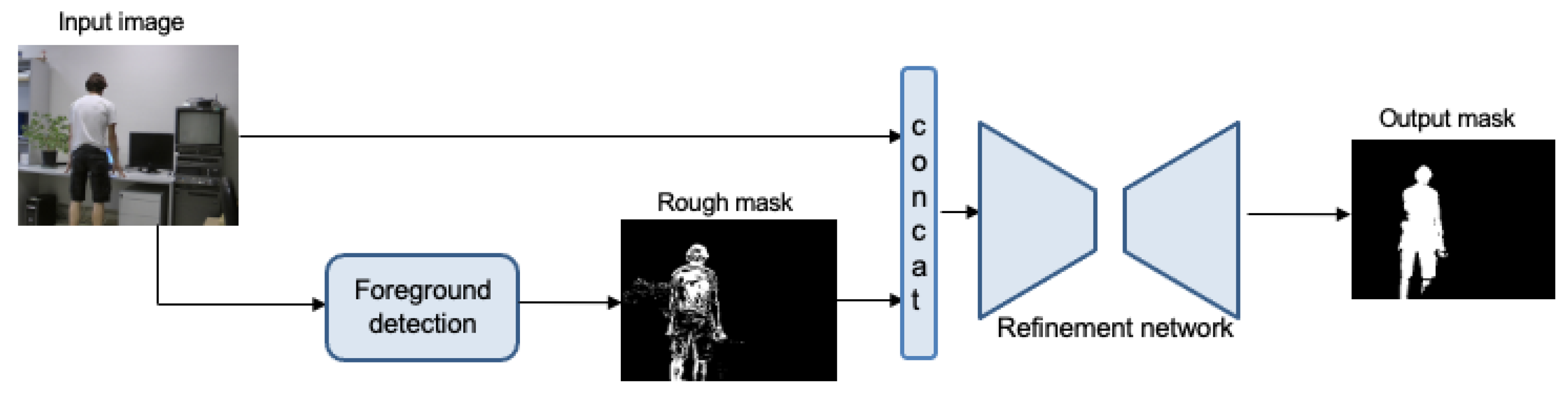
3. Foreground Segmentation Network
3.1. Foreground Detection
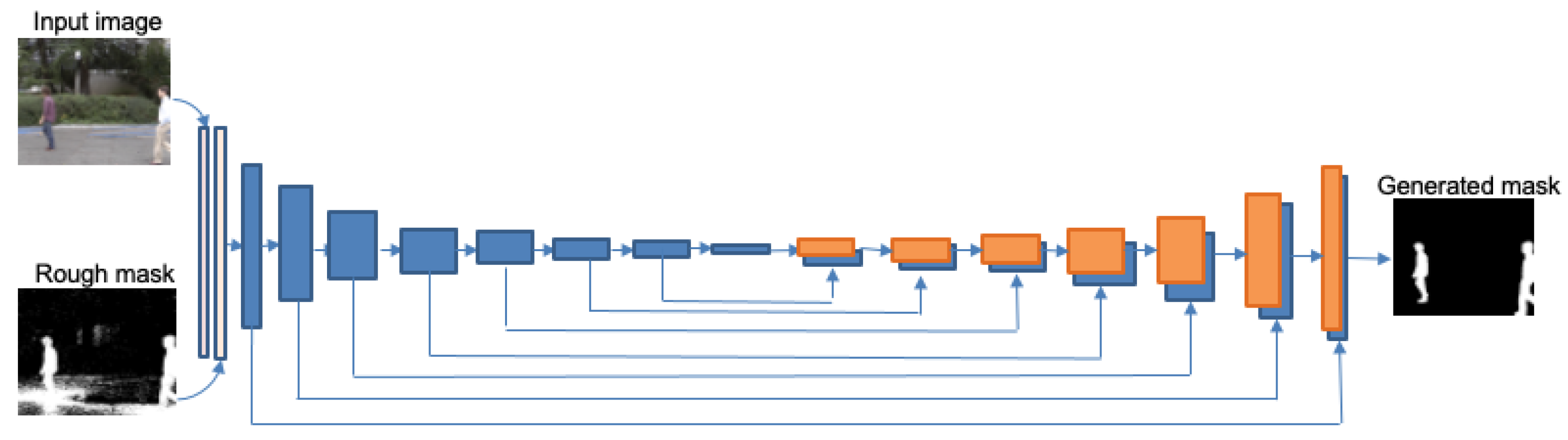
3.2. Refinement Network
3.3. Data Augmentation
4. Results
4.1. Datasets
4.2. Experiments
4.2.1. Hyper-Parameter Search
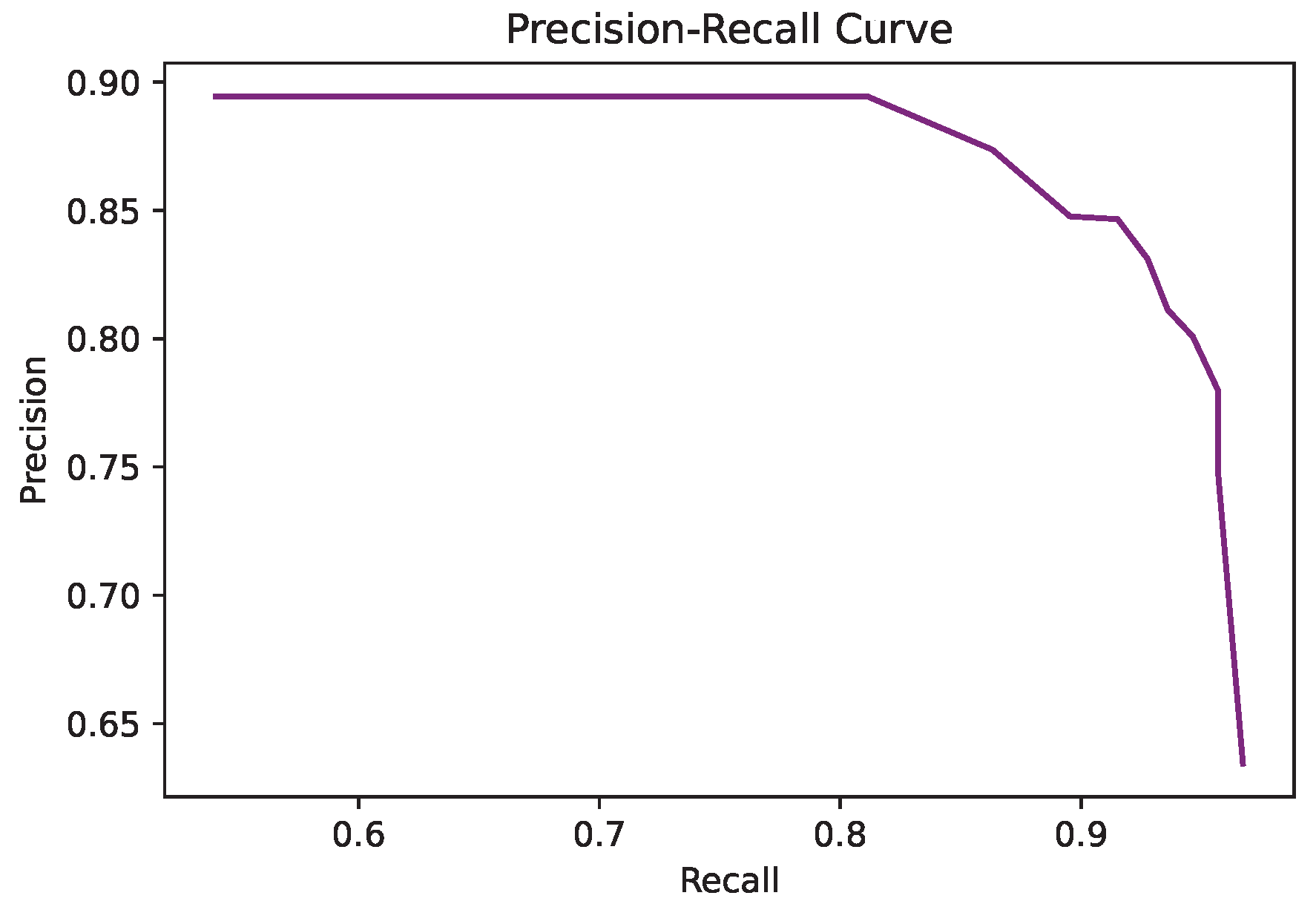
4.2.2. Effect of Adversarial Network
- Higher F-scores were achieved faster with the discriminant network, implying a better generalization of the network.
- The discriminator BCE loss introduces a comparison to the annotation that is not just pixel-wise, but takes into account the whole image for improving the result. This results in a network that has more compact foreground detections (with less or smaller holes). Examples with especially challenging situations are shown in Figure 5. More examples can be seen in the results of next section.
4.2.3. Comparison to State-of-the-Art Methods
5. Discussion and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Video Surveillance: How Technology and the Cloud Is Disrupting the Market. IHS Markit. Available online: https://cdn.ihs.com/www/pdf/IHS-Markit-Technology-Video-surveillance.pdf (accessed on 14 April 2022).
- Laugraud, B.; Piérard, S.; Braham, M.; Droogenbroeck, M. Simple Median-Based Method for Stationary Background Generation Using Background Subtraction Algorithms. In Proceedings of the International Conference on Image Analysis and Processing, Genoa, Italy, 7–11 September 2015. [Google Scholar] [CrossRef] [Green Version]
- Prati, A.; Mikic, I.; Trivedi, M.; Cucchiara, R. Detecting Moving Shadows: Algorithms and Evaluation. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 918–923. [Google Scholar] [CrossRef] [Green Version]
- Friedman, N.; Russell, S.J. Image Segmentation in Video Sequences: A Probabilistic Approach. arXiv 2013, arXiv:1302.1539. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 2. [Google Scholar]
- Elgammal, A.M.; Harwood, D.; Davis, L.S. Non-parametric Model for Background Subtraction. In Proceedings of the 6th European Conference on Computer Vision-Part II, Dublin, Ireland, 26 June–1 July 2000. [Google Scholar]
- Laugraud, B.; Piérard, S.; Droogenbroeck, M. LaBGen-P: A Pixel-Level Stationary Background Generation Method Based on LaBGen. In Proceedings of the 2016 23rd International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016. [Google Scholar] [CrossRef] [Green Version]
- Javed, S.; Mahmood, A.; Bouwmans, T.; Jung, S. Background-Foreground Modeling Based on Spatiotemporal Sparse Subspace Clustering. IEEE Trans. Image Process. 2017, 26, 5840–5854. [Google Scholar] [CrossRef] [PubMed]
- Kaewtrakulpong, P.; Bowden, R. An Improved Adaptive Background Mixture Model for Realtime Tracking with Shadow Detection. In Proceedings of the 2nd European Workshop on Advanced Video-Based Surveillance Systems, London, UK, 4 September 2001. [Google Scholar] [CrossRef] [Green Version]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 26–26 August 2004; Volume 2, pp. 28–31. [Google Scholar] [CrossRef]
- Zivkovic, Z.; van der Heijden, F. Efficient Adaptive Density Estimation Per Image Pixel for the Task of Background Subtraction. Pattern Recogn. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- Godbehere, A.B.; Matsukawa, A.; Goldberg, K. Visual tracking of human visitors under variable-lighting conditions for a responsive audio art installation. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 4305–4312. [Google Scholar] [CrossRef] [Green Version]
- Cuevas, C.; García, N. Improved background modeling for real-time spatio-temporal non-parametric moving object detection strategies. Image Vis. Comput. 2013, 31, 616–630. [Google Scholar] [CrossRef]
- Berjón, D.; Cuevas, C.; Morán, F.; García, N. Real-time nonparametric background subtraction with tracking-based foreground update. Pattern Recognit. 2017, 74, 156–170. [Google Scholar] [CrossRef]
- Bouwmans, T.; Javed, S.; Sultana, M.; Jung, S.K. Deep Neural Network Concepts for Background Subtraction: A Systematic Review and Comparative Evaluation. arXiv 2018, arXiv:1811.05255. [Google Scholar]
- Xu, P.; Ye, M.; Li, X.; Liu, Q.; Yang, Y.; Ding, J. Dynamic background learning through deep auto-encoder networks. In Proceedings of the 22nd ACM International Conference on Multimedia, New York, NY, USA, 3–7 November 2014; pp. 107–116. [Google Scholar]
- Sultana, M.; Mahmood, A.; Javed, S.; Jung, S.K. Unsupervised Deep Context Prediction for Background Foreground Separation. arXiv 2018, arXiv:1805.07903. [Google Scholar]
- Wang, Y.; Luo, Z.; Jodoin, P.M. Interactive Deep Learning Method for Segmenting Moving Objects. Pattern Recogn. Lett. 2017, 96, 66–75. [Google Scholar] [CrossRef]
- Babaee, M.; Dinh, D.T.; Rigoll, G. A deep convolutional neural network for video sequence background subtraction. Pattern Recognit. 2018, 76, 635–649. [Google Scholar] [CrossRef]
- Bakkay, M.C.; Rashwan, H.A.; Salmane, H.; Khoudour, L.; Puigtt, D.; Ruichek, Y. BSCGAN: Deep Background Subtraction with Conditional Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Image Processing, ICIP 2018, Athens, Greece, 7–10 October 2018; pp. 4018–4022. [Google Scholar]
- Pardàs, M.; Canet Tarrés, G. Refinement Network for unsupervised on the scene Foreground Segmentation. In Proceedings of the 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic Segmentation using Adversarial Networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arxiv 2016, arXiv:1611.07004. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Braham, M.; Droogenbroeck, M. Deep Background Subtraction with Scene-Specific Convolutional Neural Networks. In Proceedings of the IEEE International conference on systems, signals and image processing (IWSSIP), Bratislava, Slovakia, 23–25 May 2016; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Lim, L.A.; Keles, H.Y. Learning multi-scale features for foreground segmentation. Pattern Anal. Appl. 2020, 23, 1369–1380. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Benny, Y.; Wolf, L. Onegan: Simultaneous unsupervised learning of conditional image generation, foreground segmentation, and fine-grained clustering. In European Conference on Computer Vision; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 514–530. [Google Scholar]
- Zheng, W.; Wang, K.; Wang, F.Y. Background Subtraction Algorithm With Bayesian Generative Adversarial Networks. Acta Autom. Sin. 2018, 44, 878. [Google Scholar] [CrossRef]
- Mandal, M.; Dhar, V.; Mishra, A.; Vipparthi, S.K.; Abdel-Mottaleb, M. 3DCD: Scene Independent End-to-End Spatiotemporal Feature Learning Framework for Change Detection in Unseen Videos. IEEE Trans. Image Process. 2021, 30, 546–558. [Google Scholar] [CrossRef]
- Tezcan, M.O.; Ishwar, P.; Konrad, J. BSUV-Net: A Fully-Convolutional Neural Network for Background Subtraction of Unseen Videos. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 2763–2772. [Google Scholar] [CrossRef]
- Tezcan, M.O.; Ishwar, P.; Konrad, J. BSUV-Net 2.0: Spatio-Temporal Data Augmentations for Video-Agnostic Supervised Background Subtraction. IEEE Access 2021, 9, 53849–53860. [Google Scholar] [CrossRef]
- Perazzi, F.; Khoreva, A.; Benenson, R.; Schiele, B.; Sorkine-Hornung, A. Learning video object segmentation from static images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2663–2672. [Google Scholar]
- Khoreva, A.; Benenson, R.; Ilg, E.; Brox, T.; Schiele, B. Lucid Data Dreaming for Object Tracking. In Proceedings of the 2017 DAVIS Challenge on Video Object Segmentation—CVPR Workshops, Honolulu, HI, USA, 21–27 July 2017. [Google Scholar]
- Buslaev, A.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.; Kalinin, A. Albumentations: Fast and flexible image augmentations. arXiv 2018, arXiv:1809.06839. [Google Scholar]
- Kalsotra, R.; Arora, S. A Comprehensive Survey of Video Datasets for Background Subtraction. IEEE Access 2019, 7, 59143–59171. [Google Scholar] [CrossRef]
- Goyette, N.; Jodoin, P.M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection. net: A new change detection benchmark dataset. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–8. [Google Scholar]
- Wang, Y.; Jodoin, P.; Porikli, F.; Konrad, J.; Benezeth, Y.; Ishwar, P. CDnet 2014: An Expanded Change Detection Benchmark Dataset. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 393–400. [Google Scholar] [CrossRef] [Green Version]
- Cuevas, C.; María Yáñez, E.; García, N. Labeled dataset for integral evaluation of moving object detection algorithms: LASIESTA. Comput. Vis. Image Underst. 2016, 152, 103–117. [Google Scholar] [CrossRef]
- Wren, C.R.; Azarbayejani, A.; Darrell, T.; Pentland, A.P. Pfinder: Real-time tracking of the human body. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 780–785. [Google Scholar] [CrossRef] [Green Version]
- Maddalena, L.; Petrosino, A. The SOBS algorithm: What are the limits? In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 6–21 June 2012; pp. 21–26. [Google Scholar] [CrossRef]
- Haines, T.S.F.; Xiang, T. Background Subtraction with DirichletProcess Mixture Models. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 670–683. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sobral, A.; Vacavant, A. A comprehensive review of background subtraction algorithms evaluated with synthetic and real videos. Comput. Vis. Image Underst. 2014, 122, 4–21. [Google Scholar] [CrossRef]
- Wu, G.; Guo, Y.; Song, X.; Guo, Z.; Zhang, H.; Shi, X.; Shibasaki, R.; Shao, X. A stacked fully convolutional networks with feature alignment framework for multi-label land-cover segmentation. Remote. Sens. 2019, 11, 1051. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Background Modeling | Background Subtraction | Statistical | CNN | GAN | Context Dependent | |
|---|---|---|---|---|---|---|
| 2,3,4,7,8 | X | X | ||||
| 5,6,9,10,11,12,13,14 | X | X | X | |||
| 16 | X | X | X | |||
| 17 | X | X | X | X | ||
| 18,19,26,27 | X | X | X | X | ||
| 20,28,29,30 | X | X | X | X | ||
| 31 | X | X | X | |||
| 32,33 | X | X | ||||
| Ours | X | X | X | X | X |
| CDNet | LASIESTA | |
|---|---|---|
| Sequences | 53 | 20 |
| Categories | 11 | 10 |
| Indoor sequences | 8 | 14 |
| Outdoor sequences | 45 | 10 |
| Frames/sequence | 600–7999 | 225–1400 |
| Resolution | 320 × 240–720 × 576 | 352 × 288 |
| Labeled images | 1 out of 10 | All |
| SI | CA | OC | IL | MB | BS | CL | RA | SN | SU | AV | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec | 0.77 | 0.86 | 0.74 | 0.76 | 0.94 | 0.85 | 0.84 | 0.85 | 0.89 | 0.93 | 0.83 |
| Rec | 0.94 | 0.93 | 0.94 | 0.9 | 0.92 | 0.87 | 0.85 | 0.95 | 0.89 | 0.82 | 0.92 |
| F-meas | 0.84 | 0.89 | 0.83 | 0.82 | 0.93 | 0.86 | 0.84 | 0.90 | 0.89 | 0.87 | 0.87 |
| SI | CA | OC | IL | MB | BS | CL | RA | SN | SU | AV | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Wren [41] | 0.82 | 0.76 | 0.89 | 0.49 | 0.74 | 0.47 | 0.86 | 0.85 | 0.60 | 0.75 | 0.72 |
| Stauffer [5] | 0.83 | 0.83 | 0.89 | 0.29 | 0.76 | 0.36 | 0.87 | 0.78 | 0.60 | 0.72 | 0.69 |
| Zivkovik [11] | 0.90 | 0.83 | 0.95 | 0.24 | 0.87 | 0.53 | 0.88 | 0.88 | 0.38 | 0.71 | 0.72 |
| Madd. [42] | 0.95 | 0.86 | 0.95 | 0.21 | 0.91 | 0.40 | 0.97 | 0.90 | 0.81 | 0.88 | 0.78 |
| Haines [43] | 0.89 | 0.89 | 0.92 | 0.85 | 0.84 | 0.68 | 0.83 | 0.89 | 0.17 | 0.85 | 0.78 |
| Cuevas [14] | 0.88 | 0.84 | 0.79 | 0.65 | 0.94 | 0.66 | 0.93 | 0.87 | 0.78 | 0.72 | 0.80 |
| Mandal [31] | 0.86 | 0.49 | 0.93 | 0.85 | 0.79 | 0.87 | 0.87 | 0.87 | 0.49 | 0.83 | 0.79 |
| Tezcan [33] | 0.92 | 0.68 | 0.96 | 0.88 | 0.81 | 0.77 | 0.93 | 0.94 | 0.84 | 0.79 | 0.85 |
| MOG [10] | 0.70 | 0.68 | 0.72 | 0.41 | 0.65 | 0.55 | 0.57 | 0.67 | 0.38 | 0.71 | 0.60 |
| Ours | 0.84 | 0.89 | 0.83 | 0.82 | 0.93 | 0.86 | 0.84 | 0.90 | 0.89 | 0.87 | 0.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Canet Tarrés, G.; Pardàs, M. Context-Unsupervised Adversarial Network for Video Sensors. Sensors 2022, 22, 3171. https://doi.org/10.3390/s22093171
Canet Tarrés G, Pardàs M. Context-Unsupervised Adversarial Network for Video Sensors. Sensors. 2022; 22(9):3171. https://doi.org/10.3390/s22093171
Chicago/Turabian StyleCanet Tarrés, Gemma, and Montse Pardàs. 2022. "Context-Unsupervised Adversarial Network for Video Sensors" Sensors 22, no. 9: 3171. https://doi.org/10.3390/s22093171
APA StyleCanet Tarrés, G., & Pardàs, M. (2022). Context-Unsupervised Adversarial Network for Video Sensors. Sensors, 22(9), 3171. https://doi.org/10.3390/s22093171