
#Nomask on Instagram: Exploring Visual Representations of the Antisocial Norm on Social Media

Abstract
1. Introduction
1.1. Social Representation Theory, Hashtags, and Visual Representations
- (a)
- What is the content of the photos?
- (b)
- What are the characteristics of the faces in the photos?
- (c)
- What words are presented in the photos?
1.2. Clustering as an Analytical Strategy for the Examination of Visual Representations
2. Methods
- gather data
- investigate visual representations in the whole dataset: content, facial characteristics, and texts in photos
- cluster photos into subgroups
- compare subgroups in terms of visual representations: content, facial characteristics, texts in photos, pixel-level characteristics, and the public’s response
2.1. Research Sample
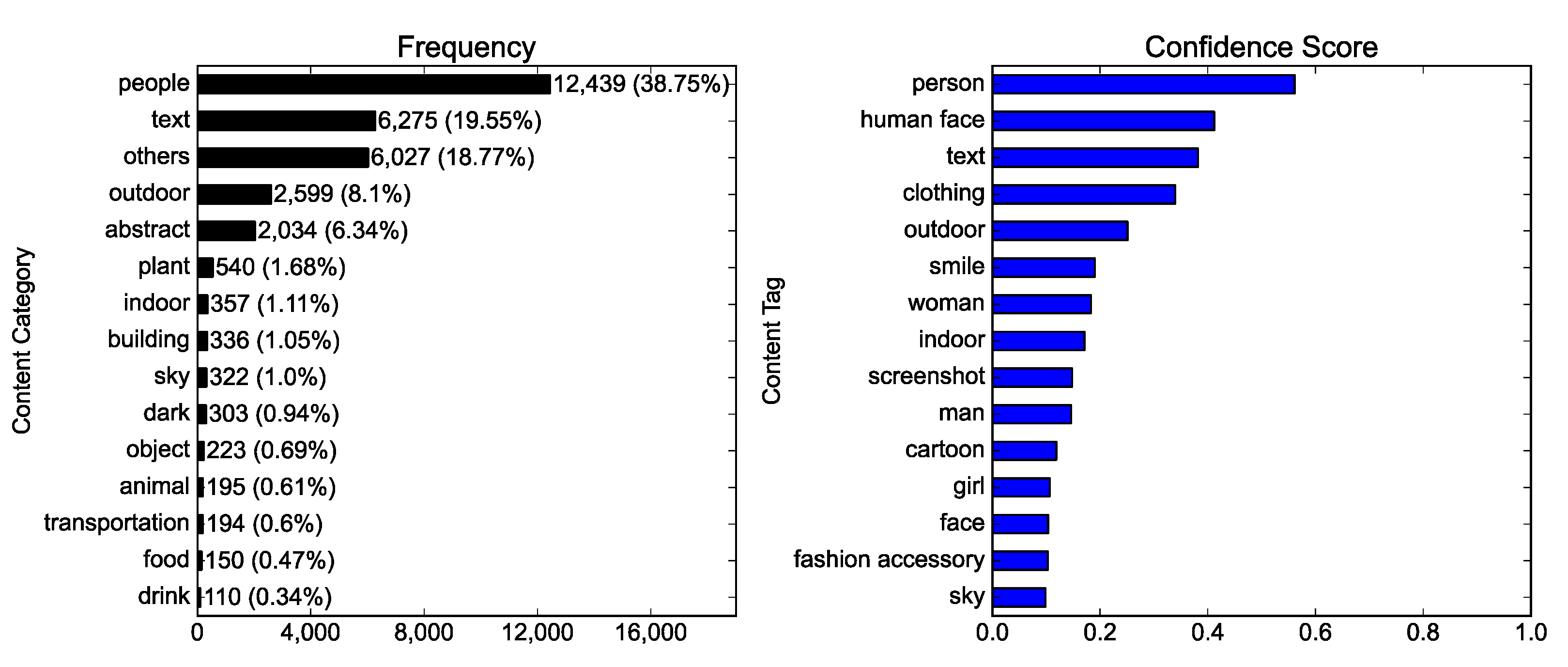
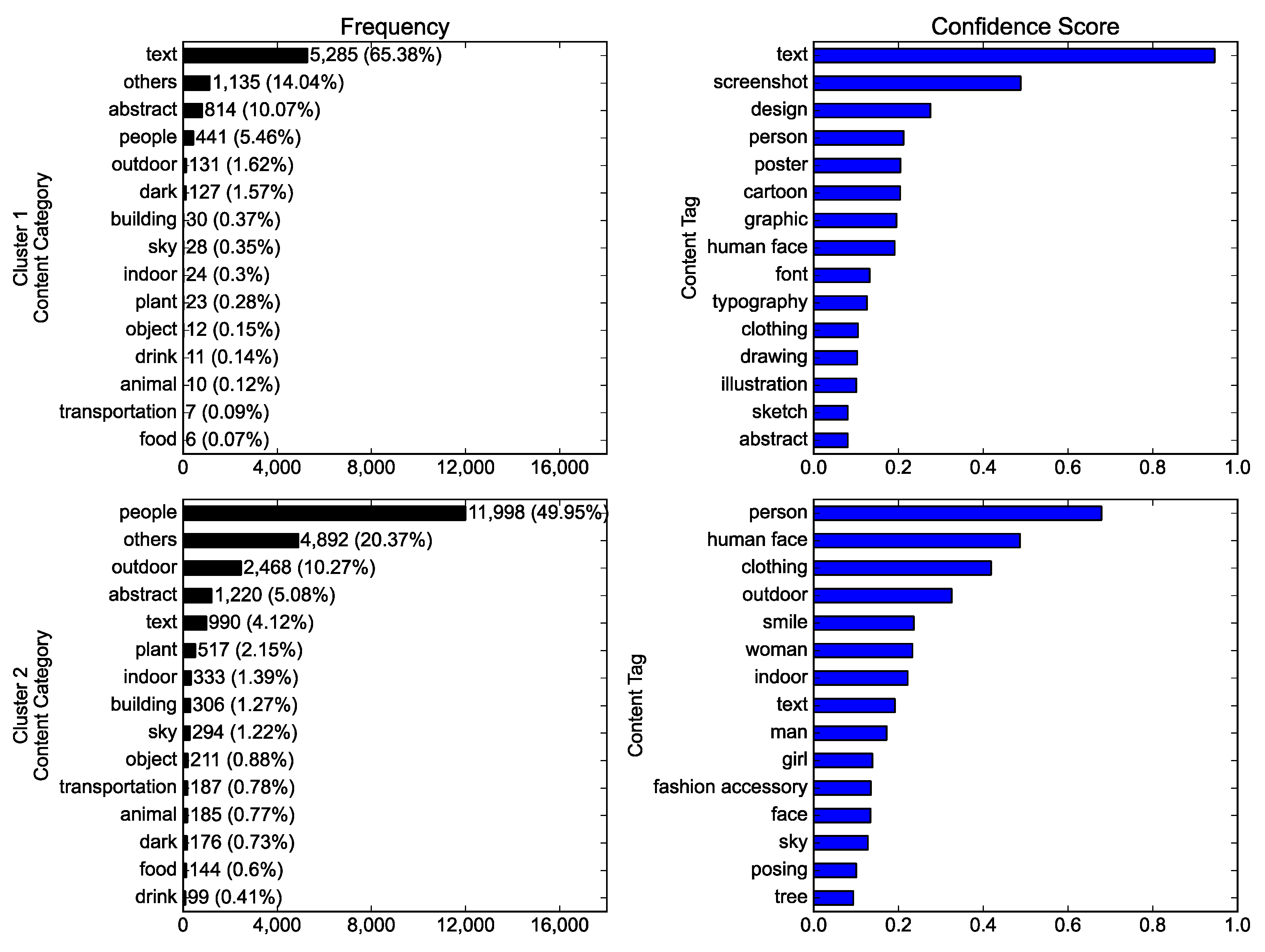
2.2. The Content of Photos
2.3. The Characteristics of Faces in Photos
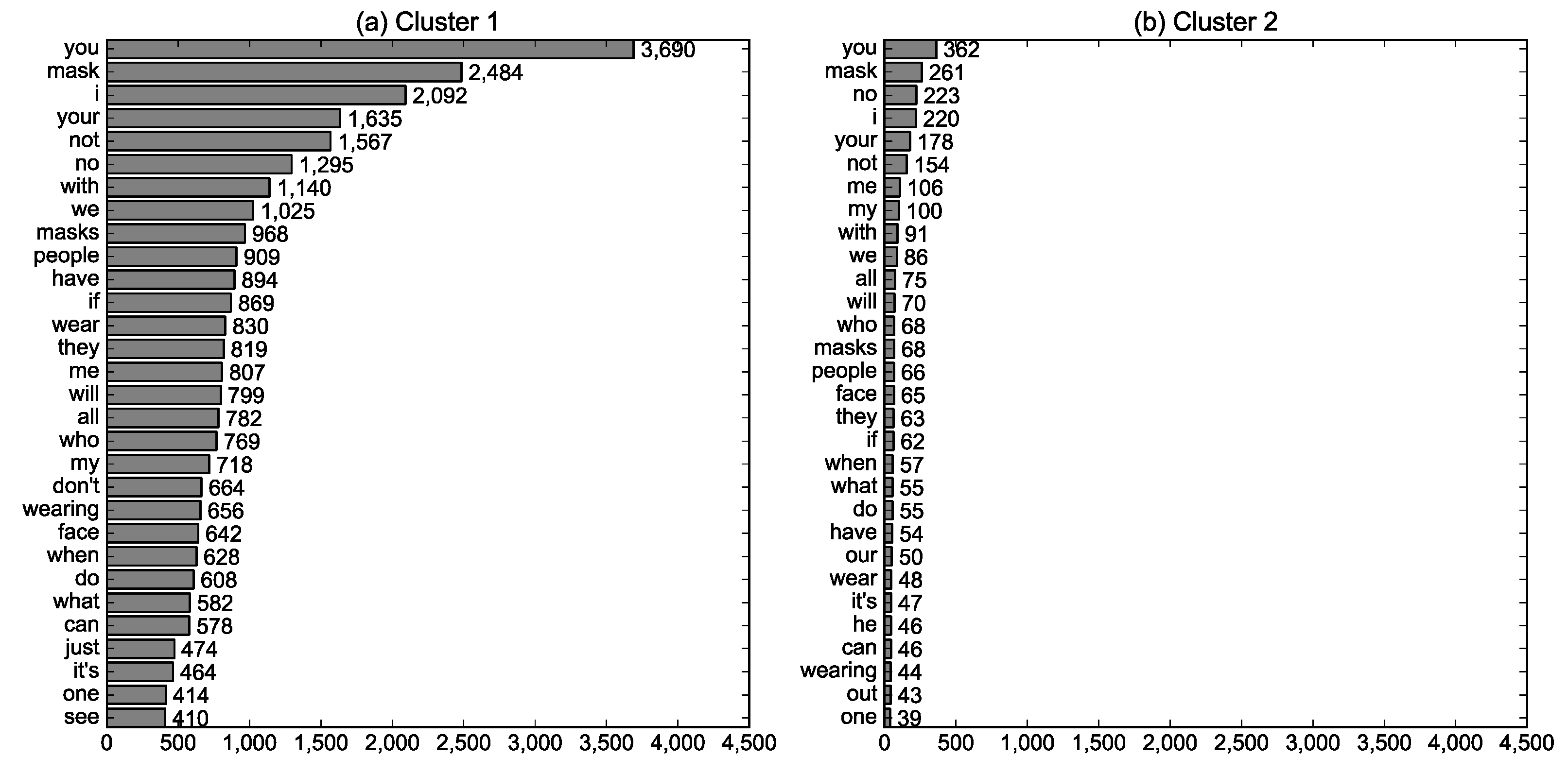
2.4. Texts Presented in Photos
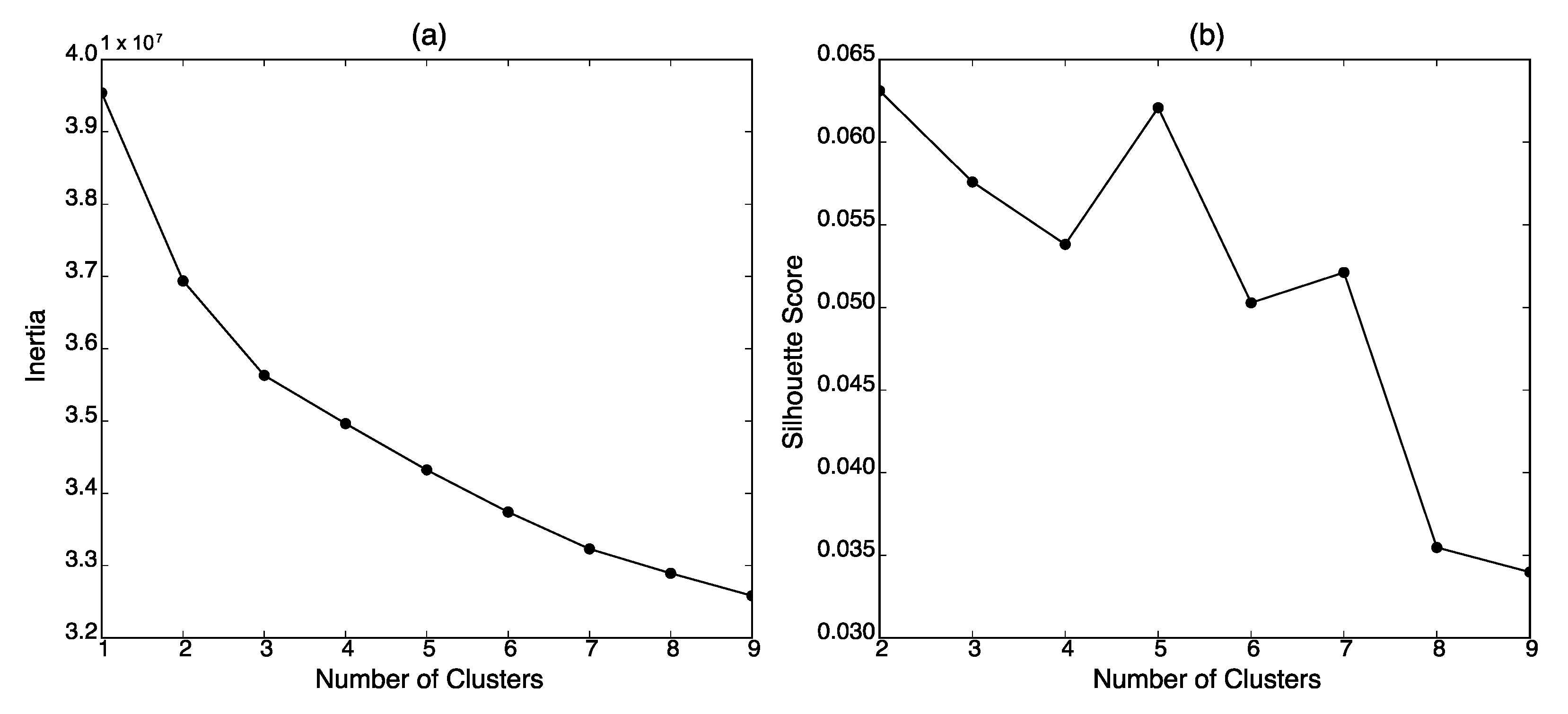
2.5. Clustering
2.6. Pixel-Level Features
2.7. The Public’s Responses
3. Results
3.1. Visual Representations in the #NoMask Instagram Photos (RQ1)
3.2. Differences in Visual Representations between Clusters (RQ2)
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boyd, D. Social media: A phenomenon to be analyzed. Soc. Media Soc. 2015, 1, 1–2. [Google Scholar] [CrossRef]
- Hogan, M.; Strasburger, V.C. Social media and new technology: A primer. Clin Pediatr. 2018, 57, 1204–1215. [Google Scholar] [CrossRef] [PubMed]
- Markham, M.J.; Gentile, D.; Graham, D.L. Social media for networking, professional development, and patient engagement. ASCO Educ. Book 2017, 37, 782–787. [Google Scholar] [CrossRef] [PubMed]
- Jurgenson, N. The Social Photo: On Photography and Social Media; Verso: Brooklyn, NY, USA, 2019. [Google Scholar]
- Chalfen, R. Snapshot Versions of Life; Bowling Green State University Popular Press: Bowling Green, OH, USA, 1987. [Google Scholar]
- Bruns, A.; Stieglitz, S. Towards more systematic Twitter analysis: Metrics for tweeting activities. Int. J. Soc. Res. Methodol. 2013, 16, 91–108. [Google Scholar] [CrossRef]
- Davis, M. The online anti-public sphere. Eur. J. Cult. Stud. 2021, 24, 143–159. [Google Scholar] [CrossRef]
- Kitts, J.A. Collective action, rival incentives, and the emergence of antisocial norms. Am. Sociol. Rev. 2006, 71, 235–259. [Google Scholar] [CrossRef]
- O’Connell, K.; Berluti, K.; Rhoads, S.A.; Marsh, A.A. Reduced social distancing early in the COVID-19 pandemic is associated with antisocial behaviors in an online United States sample. PLoS ONE 2021, 16, e0244974. [Google Scholar] [CrossRef]
- Fulcher, J.A.; Dunbar, S.; Orlando, E.; Woodruff, S.J.; Santarossa, S. #selfharn on Instagram: Understanding online communities surrounding non-suicidal self-injury through conversations and common properties among authors. Digit. Health 2020, 6, 1–13. [Google Scholar]
- Kim, Y.; Song, D.; Lee, Y.J. #Antivaccination on Instagram: A computational analysis of hashtag activism through photos and public responses. Int. J. Environ. Res. Public Health 2020, 17, 7550. [Google Scholar]
- Hendriks, H.; Wilmsen, D.; van Dalen, W.; Gebhardt, W.A. Picture me drinking: Alcohol-related posts by Instagram influencers popular among adolescents and young adults. Front. Psychol. 2020, 10, 2991. [Google Scholar] [CrossRef]
- Ketonen, V.; Malik, A. Characterizing vaping posts on Instagram by using unsupervised machine learning. Int. J. Med. Inform. 2020, 141, 104223. [Google Scholar] [CrossRef]
- Li, Y.; Liang, M.; Gao, L.; Ayaz Ahmed, M.; Uy, J.P.; Cheng, C.; Zhou, Q.; Sun, C. Face masks to prevent transmission of COVID-19: A systematic review and meta-analysis. Am. J. Infect. Control 2021, 49, 900–906. [Google Scholar] [CrossRef]
- Al-Ramahi, M.; Elnoshokaty, A.; El-Gayar, O.; Nasralah, T.; Wahbeh, A. Public discourse against masks in the COVID-19 era: Infodemiology study of Twitter data. JMIR Public Health Surveill. 2021, 7, e26780. [Google Scholar] [CrossRef]
- Wang, Y.J.; Shi, M.; Zhang, J.M. What public health campaigns can learn from people’s Twitter reactions on mask-wearing and COVID-19 vaccines: A topic modeling approach. Cogent Soc. Sci. 2021, 7, 1959728. [Google Scholar] [CrossRef]
- Pascual-Ferrá, P.; Alperstein, N.; Barnett, D.J.; Rimal, R.N. Toxicity and verbal aggression on social media: Polarized discourse on wearing face masks during the COVID-19 pandemic. Big Data Soc. 2021, 8, 205395172110235. [Google Scholar] [CrossRef]
- Ahmed, W.; Vidal-Alaball, J.; Lopez Segui, F.; Moreno-Sánchez, P.A. A social network analysis of tweets related to masks during the COVID-19 pandemic. Int. J. Environ. Res. Public Health 2020, 17, 8235. [Google Scholar] [CrossRef]
- Lang, J.; Erickson, W.W.; Jing-Schmidt, Z. #MaskOn! #MaskOff! Digital polarization of mask-wearing in the United States during COVID-19. PLoS ONE 2021, 16, e0250817. [Google Scholar]
- Moscovici, S. The phenomena of social representation. In Social Representation; Farr, R.M., Moscovici, S., Eds.; Cambridge University Press: Cambridge, UK, 1984; pp. 3–69. [Google Scholar]
- De Rosa, A.S.; Gherman, M.-A. State of the art of social representations theory in Asia: An empirical meta-theoretical analysis. J. Pac. Rim Psychol. 2019, 13, e9. [Google Scholar] [CrossRef]
- Wagner, W.; Duveen, G.; Farr, R.; Jovchelovitch, S.; Lorenzi-Cioldi, F.; Marková, I.; Rose, D. Theory and method of social representations. Asian J. Soc. Psychol. 1999, 2, 95–125. [Google Scholar] [CrossRef]
- Lai, P.-H.; Hsu, Y.-C.; Wearing, S. A social representation approach to facilitating adaptive co-management in mountain destinations managed for conservation and recreation. J. Sustain. Tour. 2016, 24, 227–244. [Google Scholar] [CrossRef]
- Höijer, B. Social representations theory: A new theory for media research. Nord. Rev. 2011, 32, 3–16. [Google Scholar] [CrossRef]
- Wagner, W. Social representation theory. In The Encyclopedia of Peace Psychology; Christie, D.J., Ed.; Blackwell Publishing Ltd.: Oxford, UK, 2012; pp. 1–5. [Google Scholar]
- Arruda, A. Image, social imaginary and social representations. In The Cambridge Handbook of Social Representations; Sammut, G., Andreouli, E., Gaskell, G., Valsiner, J., Eds.; Cambridge University Press: Cambridge, UK, 2015; pp. 128–142. [Google Scholar]
- Martikainen, J. Visual representations of teachership: A social representations approach. Ph.D. Thesis, University of Eastern Finland, Kuopip, Finland, 2020. [Google Scholar]
- Stocchetti, M. Digital visuality and social representation. Research notes on the visual construction of meaning. KOME 2017, 5, 38–56. [Google Scholar] [CrossRef]
- Martikainen, J.; Sakki, I. How newspaper images position different groups of people in relation to the COVID-19 pandemic: A social representations approach. J. Community Appl. Soc. Psychol. 2021, 31, 465–494. [Google Scholar] [CrossRef]
- Sarrica, M.; Brondi, S. Photovoice as a visual-verbal strategy for studying contents and processes of social representations: A participatory project on sustainable energy. Qual. Res. Psychol. 2020, 17, 565–586. [Google Scholar] [CrossRef]
- Howarth, C.; Kessi, S. Towards a visual social psychology of identity and representation: Photographing the self, weaving the family in a multicultural British community. In A Handbook of Visual Methods in Psychology: Using and Interpreting Images in Qualitative Research; Reavey, P., Ed.; Routledge: London, UK; New York, NY, USA, 2020; pp. 394–408. [Google Scholar]
- Hakoköngäs, E.; Halmesvaara, O.; Sakki, I. Persuasion through bitter humor: Multimodal discourse analysis of rhetoric in Internet memes of two far-right groups in Finland. Soc. Media Soc. 2020, 6, 205630512092157. [Google Scholar] [CrossRef]
- De Paola, J.; Hakoköngäs, E.J.; Hakanen, J.J. #Happy: Constructing and sharing everyday understandings of happiness on Instagram. Hum. Arenas 2020, 1–19. [Google Scholar] [CrossRef]
- Wagner, W. The social representation paradigm. Jpn. J. Exp. Soc. Psychology 1996, 35, 247–255. [Google Scholar] [CrossRef][Green Version]
- Hu, Y.; Manikonda, L.; Kambhampati, S. What we Instagram: A first analysis of Instagram photo content and user types. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; pp. 595–598. [Google Scholar]
- Rateau, P.; Moliner, P.; Guimelli, C.; Abric, J.-C. Social representation theory. In Handbook of Theories of Social Psychology: Volume 2; Van Lange, P.A.M., Kruglanski, A.W., Higgins, E.T., Eds.; SAGE Publications Ltd: London, UK, 2012; pp. 477–497. [Google Scholar]
- Martikainen, J. Social representations of teachership based on cover images of Finnish teacher magazine: A visual rhetoric approach. J. Soc. Political Psychol. 2019, 7, 890–912. [Google Scholar] [CrossRef]
- Filho, D.B.F.; Rocha, E.C.D.; Júnior, J.A.D.S.; Paranhos, R.; Silva, M.B.D.; Duarte, B.S.F. Cluster analysis for political scientists. Appl Math 2014, 5, 2408–2415. [Google Scholar] [CrossRef]
- Mostafa, M.M.; Nebot, N.R. The Arab image in Spanish social media: A Twitter sentiment analytics approach. J. Intercult. Commun. Res. 2020, 49, 133–155. [Google Scholar] [CrossRef]
- Kaneko, T.; Yanai, K. Event photo mining from Twitter using keyword bursts and image clustering. Neurocomputing 2016, 172, 143–158. [Google Scholar] [CrossRef]
- Huang, J.; Obracht-Prondzynska, H.; Kamrowska-Zaluska, D.; Sun, Y.; Li, L. The image of the city on social media: A comparative study using “Big Data” and “Small Data” methods in the Tri-City Region in Poland. Landsc. Urban Plan. 2021, 206, 103977. [Google Scholar] [CrossRef]
- Curiskis, S.A.; Drake, B.; Osborn, T.R.; Kennedy, P.J. An evaluation of document clustering and topic modelling in two online social networks: Twitter and Reddit. Inf. Process. Manag. 2020, 57, 102034. [Google Scholar] [CrossRef]
- Aramendia-Muneta, M.E.; Olarte-Pascual, C.; Ollo-López, A. Key image attributes to elicit likes and comments on Instagram. J. Promot. Manag. 2021, 27, 50–76. [Google Scholar] [CrossRef]
- Li, Y.; Xie, Y. Is a picture worth a thousand words? An empirical study of image content and social media engagement. J. Mark. Res. 2020, 57, 1–19. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384–392. [Google Scholar] [CrossRef]
- Küntzler, T.; Höfling, T.T.A.; Alpers, G.W. Automatic facial expression recognition in standardized and non-standardized emotional expressions. Front. Psychol. 2021, 12, 627561. [Google Scholar] [CrossRef]
- Fu, Y.; Timothy, D.J. Social media constraints and destination images: The potential of barrier-free internet access for foreign tourists in an internet-restricted destination. Tour. Manag. Perspect. 2021, 37, 100771. [Google Scholar] [CrossRef]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Miami, FL, USA; 2009; pp. 248–255. [Google Scholar]
- Yuan, C.; Yang, H. Research on k-value selection method of k-means clustering algorithm. J 2019, 2, 226–235. [Google Scholar] [CrossRef]
- Mao, X.; Chen, B.; Muta, I. Affective property of image and fractal dimension. Chaos Solitons Fractals 2003, 15, 905–910. [Google Scholar] [CrossRef]
- San Pedro, J.; Siersdorfer, S. Ranking and classifying attractiveness of photos in folksonomies. In Proceedings of the 18th International Conference on World Wide Web (WWW ‘09), Madrid, Spain, 20–24 April 2009; pp. 771–780. [Google Scholar]
- Hasler, D.; Süsstrunk, S. Measuring colorfulness in natural images. In Human Vision and Electronic Imaging VIII; Rogowitz, B.E., Pappas, T.N., Eds.; International Society for Optics and Photonics: San Jose, CA, USA, 2003; pp. 87–95. [Google Scholar]
- Huang, K.-Q.; Wang, Q.; Wu, Z.-Y. Natural color image enhancement and evaluation algorithm based on human visual system. Comput. Vis. Image. Underst. 2006, 103, 52–63. [Google Scholar] [CrossRef]
- Ichau, E.; Frissen, T.; d’Haenens, L. From #selfie to #edgy. Hashtag networks and images associated with the hashtag #jews on Instagram. Telemat. Inform. 2019, 44, 101275. [Google Scholar]
- Tiggemann, M.; Zaccardo, M. ‘Strong is the new skinny’: A content analysis of #fitspiration images on Instagram. J. Health Psychol. 2018, 23, 1003–1011. [Google Scholar]
- Kearney, M.D.; Selvan, P.; Hauer, M.K.; Leader, A.E.; Massey, P.M. Characterizing HPV vaccine sentiments and content on Instagram. Health Educ. Behav. 2019, 46, 37S–48S. [Google Scholar] [CrossRef]
- Bakhshi, S.; Shamma, D.A.; Gilbert, E. Faces engage us: Photos with faces attract more likes and comments on Instagram. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada; 2014; pp. 965–974. [Google Scholar]
- Lindell, A.K. Left cheek poses garner more likes: The effect of pose orientation on Instagram engagement. Laterality 2019, 24, 600–613. [Google Scholar] [CrossRef]
- Sensales, G.; Di Cicco, G.; Baldner, C. Representations of Italian populism and immigration on Facebook: A comparison of the posts by Luigi Di Maio and Matteo Salvini (2014–2018). Pap. Soc. Represent. 2021, 30, 2.1–2.34. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Mean (SD) |
|---|---|
| Number of faces | 1.441 (1.614) |
| Closeup | 0.110 (0.132) |
| Face ratio | 0.120 (0.134) |
| Age | 30.997 (10.787) |
| Gender | 0.855 (1.366) |
| Anger | 0.014 (0.081) |
| Contempt | 0.013 (0.061) |
| Disgust | 0.002 (0.024) |
| Fear | 0.002 (0.026) |
| Happiness | 0.433 (0.436) |
| Sadness | 0.019 (0.077) |
| Surprise | 0.017 (0.087) |
| Neutral | 0.499 (0.421) |
| Feature | Cluster 1 | Cluster 2 | t |
|---|---|---|---|
| Number of faces | 0.320 | 0.675 | −22.329 * |
| Closeup | 0.011 | 0.056 | −35.973 * |
| Face ratio | 0.013 | 0.061 | −36.738 * |
| Age | 7.311 | 14.380 | −33.475 * |
| Gender | 0.153 | 0.413 | −21.078 * |
| Anger | 0.006 | 0.006 | −0.229 |
| Contempt | 0.002 | 0.006 | −8.861 * |
| Disgust | 0.001 | 0.001 | −1.013 |
| Fear | 0.001 | 0.001 | 2.079 * |
| Happiness | 0.072 | 0.211 | −31.517 * |
| Sadness | 0.006 | 0.008 | −3.888 * |
| Surprise | 0.005 | 0.008 | −3.236 * |
| Neutral | 0.111 | 0.234 | −26.594 * |
| Feature | Cluster 1 | Cluster 2 | t |
|---|---|---|---|
| Red mean | 150.756 | 125.352 | 41.639 * |
| Red variance | 4953.540 | 4631.434 | 10.894 * |
| Green mean | 145.916 | 116.136 | 50.536 * |
| Green variance | 4939.018 | 4288.623 | 22.782 * |
| Blue mean | 145.276 | 111.059 | 56.675 * |
| Blue variance | 4771.863 | 4066.758 | 23.713 * |
| Saturation mean | 60.708 | 81.059 | −34.837 * |
| Saturation variance | 3016.080 | 2936.486 | 2.759 * |
| Value mean | 163.111 | 137.228 | 44.193 * |
| Value variance | 4561.874 | 4435.141 | 4.540 * |
| Hue peaks | 2.144 | 2.166 | −1.577 |
| Brightness | 147.289 | 118.316 | 50.381 * |
| Colorfulness | 35.170 | 40.213 | −16.172 * |
| Naturalness | 0.356 | 0.440 | −15.394 * |
| Contrast | 63.567 | 61.118 | 11.600 * |
| RGB contrast | 115.070 | 111.426 | 10.112 * |
| Sharpness | 7,4597.393 | 8,2896.601 | −8.018 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y. #Nomask on Instagram: Exploring Visual Representations of the Antisocial Norm on Social Media. Int. J. Environ. Res. Public Health 2022, 19, 6857. https://doi.org/10.3390/ijerph19116857
Kim Y. #Nomask on Instagram: Exploring Visual Representations of the Antisocial Norm on Social Media. International Journal of Environmental Research and Public Health. 2022; 19(11):6857. https://doi.org/10.3390/ijerph19116857
Chicago/Turabian StyleKim, Yunhwan. 2022. "#Nomask on Instagram: Exploring Visual Representations of the Antisocial Norm on Social Media" International Journal of Environmental Research and Public Health 19, no. 11: 6857. https://doi.org/10.3390/ijerph19116857
APA StyleKim, Y. (2022). #Nomask on Instagram: Exploring Visual Representations of the Antisocial Norm on Social Media. International Journal of Environmental Research and Public Health, 19(11), 6857. https://doi.org/10.3390/ijerph19116857