1. Introduction
Depression is a common illness; more than 300 million people worldwide suffer from it. Depression can start at any time and affect anyone. It may occur once or on a recurring basis. The presence of persistent sadness and a loss of interest in normally enjoyable activities, along with an inability to perform daily tasks for at least two weeks, characterize depression. It is different from normal mood swings or short-term sadness caused by the problems of everyday life [
1]. Furthermore, Thailand is experiencing an increase in the incidence of adolescent depression. Depression is 14.9% prevalent among Thai teenagers [
2]. Depression has a direct detrimental impact on the quality of life of teenagers, including unpleasant emotions such as sadness, remorse, and low self-esteem. Data revealed that in 2017, the suicide rate among 20- to 24-year-olds was 4.94 per 100,000 people. In 2018, it increased to 5.33 per thousand people. According to yearly data, youth groups increasingly called the Mental Health Hotline 1323 to discuss mental health concerns. During 2018, 70,534 telephone consultations were provided, including 10,298 consultations with children aged 11 to 19 (14.6%) and 14,173 consultations with youth aged 20 to 25 (20.1%). Stress and anxiety are among the top five most prevalent issues among children and adolescents. Regarding psychiatric problems during the first six months of the fiscal year 2019, the service received 40,635 calls, including 13,635 calls from adolescents and young adults aged 11 to 25, according to Mahasarakham University students who visit mental health centers for treatment. During the academic years 2013 to 2017, students with major depressive disorders were diagnosed with 233 psychiatric disorders, or 36.5% [
3].
The Depression Screening Question is a basic and time-consuming questionnaire that can be used for depression assessment and screening. If a patient has a depressed entrance score, an 8-question suicide assessment (8Q) is necessary to assess and continue managing the patient appropriately. Depression screening is, therefore, crucial and straightforward. It employs brief questions and 8Q and 9Q [
4,
5,
6] tests to identify patients with depressive disorders and appropriately introduce them to the program. Although depression screening tools vary in their psychometric properties, the PHQ-9 is the most extensively psychometrically-tested tool [
7]. There is a substantial number of standard questionnaires available in the Thai language, for example the Patient Health Questionnaire (2Q, 8Q, 9Q, and PHQ-A) [
8,
9,
10] and the Beck Depression Inventory-Thai [
11].
Knowledge of data mining is currently utilized in various fields of research, including medical research, as it examines techniques used to classify data in other domains to conduct research and utilize them to develop models for screening students at risk of depression [
12,
13,
14]. Data mining in medicine is an emerging discipline of tremendous relevance for providing a prediction and a deeper understanding of illness classification, particularly in mental health domains concerning the most prevalent diseases of Alzheimer’s, schizophrenia, and depression. In terms of percentages, the main techniques applied to depression are support vector machines [
15,
16,
17], followed by Naïve Bayes, Random Forest [
18], logistic regression [
12,
19,
20], and the Decision Tree [
21]. It has been shown that data mining techniques are increasingly being used to predict depression in students [
22,
23,
24,
25]. Using data mining techniques and specific clinical and demographic factors that predict, we can identify depression risk in a timely and cost-effective manner. Some of these studies combine socio-demographic factors with physiological factors obtained from medical tests, which are also compatible with biomarker diagnosis [
26,
27,
28].
In conclusion, data-mining techniques are accessible and effective diagnostic aids that we can include in the diagnostic workflow. Implementing them in public health care systems or by reaching out to the public, for example, by disseminating triggering advertisements offering to scan people’s social media and alert them if they need to seek help, can be excellent ways to alert people about a possible risk for depression [
29].
The goal of this study was to determine whether a person is at risk of developing depression, to identify the key factors that cause depression, and to determine the best machine learning approach to identify at-risk people. This study also intended to minimize the required time for screening depression.
The major contributions to these goals are as follows:
Identifying the most important socio-demographic, internet addiction, alcohol use disorder, and stress factors of students that contribute to depression formation;
Creation of a dataset containing the students’ socio-demographics, internet addiction, alcohol use disorder, and stress to predict depression;
Exploring different data mining and feature selection algorithms to efficiently screen for the existence of depression;
Due to the simplicity of the required socio-demographic, internet addiction, alcohol usage disorder, and stress information of students used in this study, a student suspected to be at-risk for depression would feel less hassle giving the required information of this study to detect depression rather than answering the questions of different authentic depression screening scales.
3. Materials and Methods
3.1. Instruments
The researchers followed the following procedures and methodologies:
Created a questionnaire based on the quantity of samples used for research and made sure the document was correct, complete, and had all the information it needed;
Asked for a formal letter from the university;
Collected information from each faculty; a process called “informed consent” was used to get the subjects’ consent and make sure they understand what is going on;
Held the processing period from June 2020 through March 2021;
Examined the responses to the questionnaire for completeness;
Collected information from the received questionnaires for further data analysis and interpretation.
The questionnaire consisted of five types, categorized as Type A–E, containing a total of 69 questions, and all questionnaires were non-identifiable to the participants. All questionnaires were filled out by the samplers and required between 20 and 45 min to complete. Type A–D consisted of 59 questions to be used as a predictive variable for depression risk, and Type E consisted of 9 questions to be used as a target variable. Each section’s questionnaire was as follows:
3.1.1. A Demographic Information Questionnaire (Type A)
In addition to relevant reviews, a personal information questionnaire that included questions about gender, college major, grade year, GPA, homeland, income adequacy, family status, health condition, and history of depression in the family.
3.1.2. Assessment of Internet Addiction (Type B)
The social network usage questionnaire adapted from the Young Internet Addiction Test was separated into three categories: frequency of use, length of use, and social network addiction. The test consisted of 12 questions using a Likert scale, which is used to determine the degree of agreement. The total IAT score was the sum of the examinee’s assessments for the 20-item responses. Each item was evaluated from 0 to 5 on a 5-point scale (from 1—not at all, to 5—always). The maximum possible score was 100. The severity of the problem increases as the score increases. Scores between 0 and 30 indicate Internet addiction, 50 to 79 show a moderate level, and 80 to 100 indicate a severe reliance on the Internet.
3.1.3. Alcohol Use Identification Test (AUDIT) (Type C)
The World Health Organization created this evaluation as a time- and space-constrained screening tool for excessive binge drinking. It can also assist in identifying problems with binge drinking that result in illnesses that send people to the doctor. The evaluation is a self-evaluation. It takes some time, but the evaluation is simple.
The AUDIT consists of 10 questions, each with a score of 0, 1, 2, 3, or 4, except for questions 9 and 10, which carry scores of 0, 2, and 4. The range of scores is from 0 to 40, with 0 indicating/showing an abstainer who has never experienced alcohol-related difficulties. The World Health Organization (WHO, Geneva, Switzerland) recommends a score of 1, and 7 indicates low-risk usage. Eight to fourteen points indicate potentially hazardous alcohol usage, while a score of fifteen or higher suggests the likelihood of alcohol dependence (moderate-severe alcohol use disorder).
3.1.4. Stress Test (Type D)
Thailand’s Department of Mental Health (2018) developed a stress test to evaluate what had happened over the previous six months. The SPST explores feelings over the previous 6 months, asking about occurrences and feelings towards such occurrences. The assessment criteria were as follows: 1 point of the stress score represents no stress, 2 points of the stress score represents low stress, 3 points of the stress score represents moderate stress, 4 points of the stress score represents high stress, and 5 points of the stress score represents the highest level of stress. Total scores were summed up and compared with the criteria for assessment of stress level as follows: 0–24 points indicate low stress, 25–42 points indicate moderate stress, 43–62 points indicate high stress, and more than 63 points indicates severe stress.
3.1.5. Patient Health Questionnaire for Adolescents (PHA-A)
A screening model called the Patient Health Questionnaire for Adolescents (PHQ-A) was created to evaluate depression in young people for the use of Thai teenagers. It is a brief examination, but adolescent depression assessments are accurate and congruent with research using earlier, original English-language instruments, including PHQ-9 and PHQ-A. A self-answer questionnaire with 9 items to gauge the severity of depressive symptoms, it is simple to use, reliable, and accurate when measuring depression in young people [
53].
3.2. Data Set
The collection of data is a crucial component of model development. There are a limited number of data collection methods that are entirely dependent on the type of research being conducted. Observation, interview, document scanning, measurement, questionnaire, or a combination of these methods may be used to collect data [
15]. In our work, data was collected from a questionnaire prepared by the authors.
According to the division of registration at Mahasarakham University, there were 37,579 undergraduate students registered for the second semester of the 2019 academic year. The sample size was calculated using Krejcie and Morgan’s pre-made table, which established the population’s proportion of desirable qualities, 0.5% acceptable tolerance levels, and 95% confidence intervals for 380 individuals.
The survey was conducted in the period between June 2020 and March 2021. The data set consisted of the responses of 460 participants. The inclusion criteria for this study were: either male or female, outpatients, aged more than 18 years, diagnosed without mood disorders, and volunteers who did not know they had depression. Participants were excluded if they were under the age of 18 years, illiterate, enrolled in other trials, or were in situations that did not allow obtaining written informed consent. Participants were not paid. The contents of the monitoring interviews were reviewed to identify patients who had attended at least 2 appointments. These criteria yielded the 380 participants
Among the 380 participants in the accumulated dataset, 296 participants were found to be at risk for depression. The prevalence of depression among the participants of the survey was 77.9%.
Table 1 shows the distribution of depressed and non-depressed participants in the dataset.
Data in
Table 1 are represented with imbalanced data, which is common when predicting with big data. Raw data are directly analyzed without using supplementary techniques such as a sample algorithm for data sets with imbalanced class ratios. This can decrease the performance of machine learning by causing prediction errors. Imbalanced data are data in which certain groups are overrepresented. One of the groups has a large amount of data, separated into majority and minority classes. Imbalanced information will result in the incorrect or less accurate categorization of the data of the minority group. However, it is possible to categorize the data of the majority group more precisely. General information can contain unbalanced information.
In order to improve the data before analyzing them, the Synthetic Minority Over-sampling Technique (SMOTE) [
54,
55,
56,
57] and resampling with replacement (bootstrapping) [
58,
59,
60] were used in this study. With SMOTE, numerous variations exist for an oversampling technique that generates synthetic data by approximating minority instances. It is a type of oversampling method that has been demonstrated to be effective and is frequently utilized in machine learning with imbalanced high-dimensional data, and is increasingly utilized in the medical field. As an alternate way of assessing mediation, bootstrapping is a nonparametric resampling procedure that does not assume the normality of the sampling distribution. Bootstrapping is a computationally demanding method that estimates the indirect effect of each resampled data set by repeatedly sampling from the data set. In addition, as part of the preprocessing, the interviewer’s pauses and background noise were deleted.
This study prepared the data for sampling using the following methods:
Table 2 shows the original data (D-ORI), the minority oversampling data (D-SM), and the resample with replacement data (D-RE).
From
Table 2, it was determined that D-ORI had 380 instances, where majority or those at-risk were recorded for 296 cases and minority or those not at-risk were recorded for 84 cases, demonstrating that the imbalance between majority and minority equals 3.52. D-SM had 464 instances, with a majority of 296 and a minority of 168, for a ratio of 1.76, while D-RE had 380 instances, with a majority of 296 and a minority of 84, for a ratio of 3.52.
3.3. Target Variable
Informing the status of depression as screened by the PHQ-A questionnaire for measuring the target variable: if any of these variables’ value is true, the target variable is defined as “risk of depression” = 1, otherwise “non-risk of depression” = 0.
3.4. Feature Selection Techniques
During the construction of a model, only essential components should be chosen. The model’s performance may degrade if irrelevant features are selected. Selecting inappropriate characteristics may result in a deterioration of the model’s performance. Feature selection makes it easier to get rid of features that are not needed or are redundant and do not change how well the model works.
The following three strategies of characteristics evaluation were employed in the current study: CorrelationAttributeEval, GainRatioAttributeEval and ReliefFAttributeEval. The feature search strategy made use of the ranker method, and the following search techniques were implemented using the Weka software as described below:
CorrelationAttributeEval: This option can evaluate the worth of an attribute by measuring the correlation (Pearson’s) between it and the class;
GainRatioAttributeEval: This option can evaluate the worth of an attribute by measuring the gain ratio with respect to the class;
ReliefFAttributeEval: This option can evaluate the worth of an attribute by repeatedly sampling an instance and considering the value of the given attribute for the nearest instance of the same or different class that can operate on both discrete and continuous class data.
3.5. Data Mining Techniques for Depression Prediction
To predict depression, this study used 5 different data mining classifiers, namely: the Support Vector Machine (SVM), Naïve Bayes (NB), Logistic Regression (LR), Random Forest (RF), and Decision Tree (J48).
3.5.1. Support Vector Machine
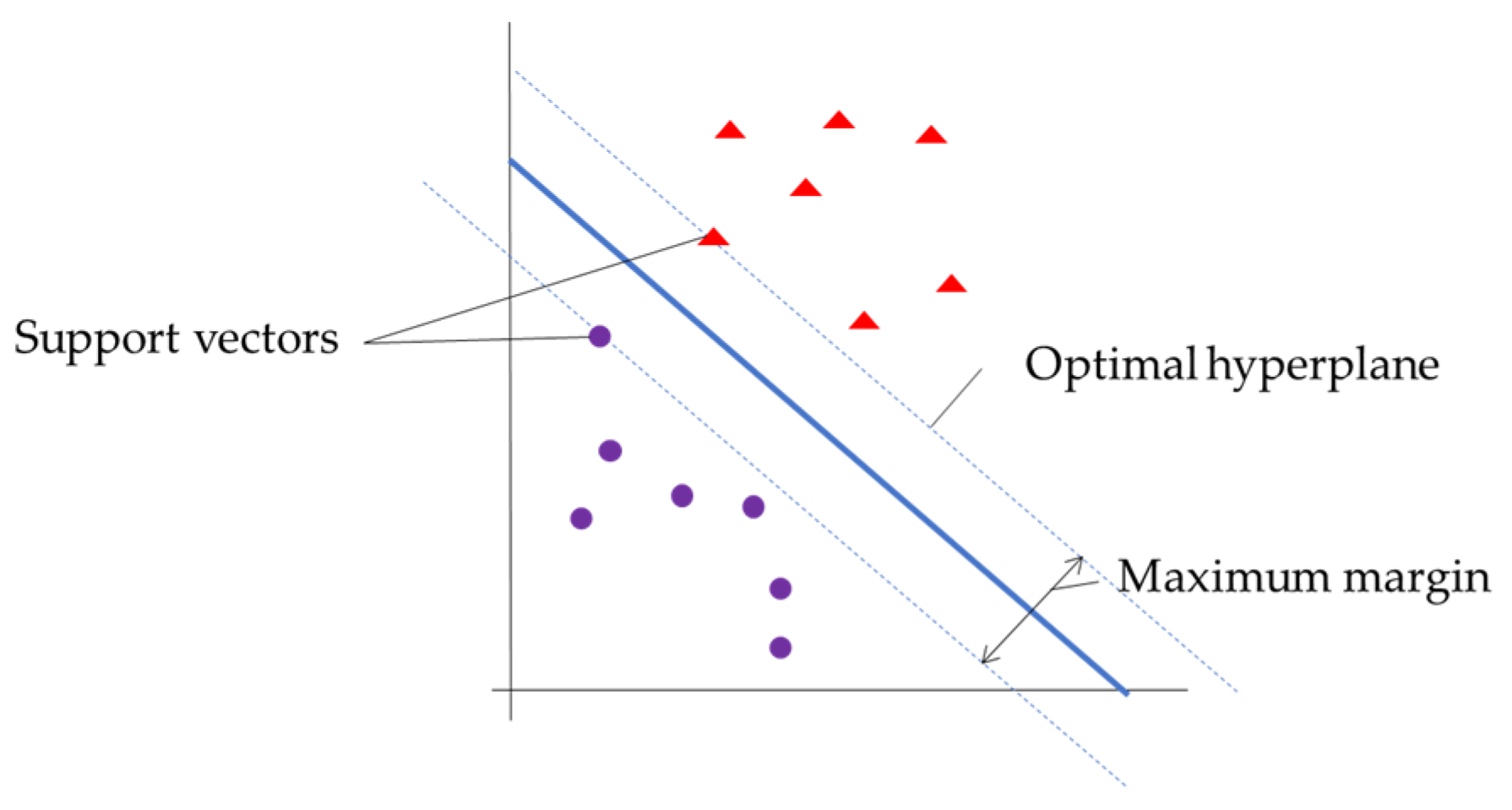
SVM is one of the methods in the problem of pattern classification. SVM finds the optimal hyperplane that categorizes training data input into two classes (good and bad).
Figure 1 shows the basic support vector machine.
The SVM algorithm is based on the kernel method, and the selection of the kernel type has a strong effect on the classification results. The type of kernel used was the Radial Basis Function (RBF) kernel, as in Equation (1):
3.5.2. Naïve Bayes
NB is a simple, supervised learning method for classification by calculating the probability to infer the solution. A conditional probability model is used as the data training model. It is appropriate for classifying a large sample, as calculated in Equation (2):
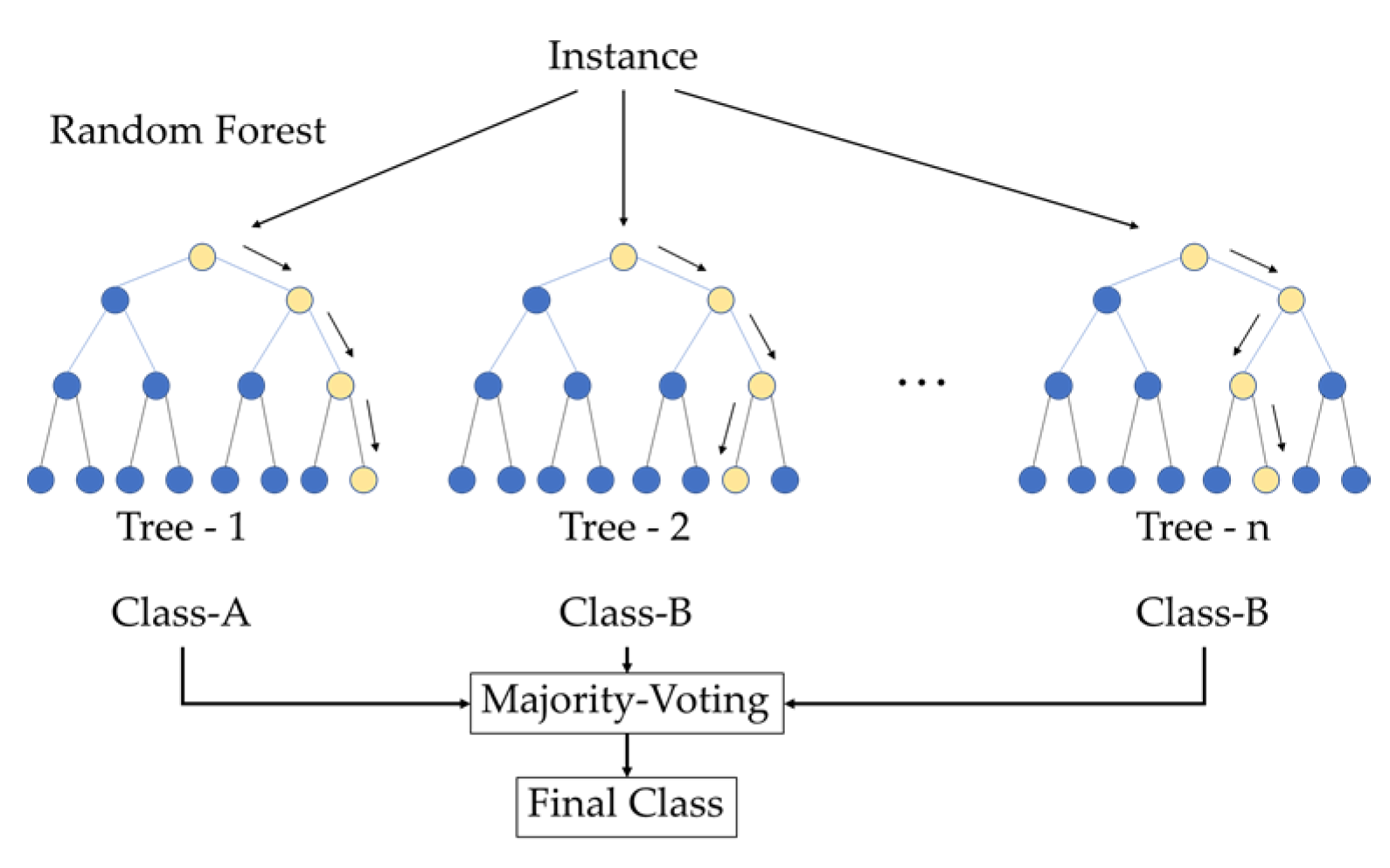
3.5.3. Random Forest
RF is an ensemble learning technique. Multiple sets of training data and unique features are selected at random. The models are then constructed using a series of decision trees, where the out-of-bag data are collected for the prediction data test. Finally, the model outcomes are put to a vote, and the one that receives the most votes is the solution, as represented in
Figure 2.
3.5.4. Logistic Regression
LR is applicable to data sets with dichotomous dependent and independent features. Due to the binary nature of the depression prediction data set, it cannot be modeled using linear regression. Logistic regression (LR) is necessary for such data. Two sets of experiments exist. One set produces a positive result, which is the attribute set by which depressive people are identified, while the other produces a negative result, which identifies those who are not depressed. The logistic function used in this model to predict the output of an experiment is illustrated in Equation (3).
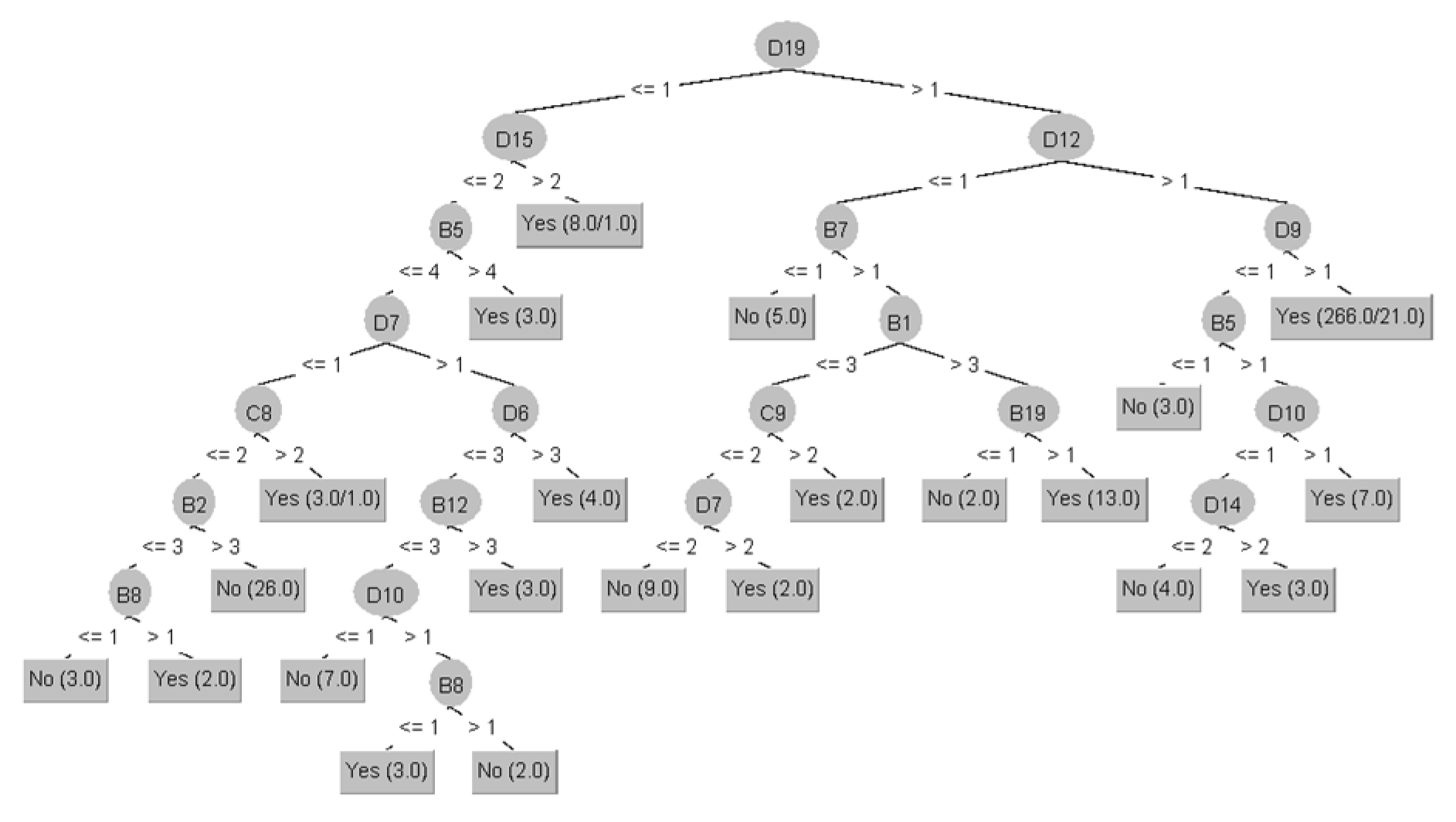
3.5.5. Decision Tree
J48 is a classifier based on trees utilized for predictive modeling. It consists of an algorithm to construct decision tables and a visualization component to depict the model’s graphical user interface. It creates a hierarchical structure of the input data set based on the relationship among the data. The algorithm selects the most important attribute set from the original data set, reducing the likelihood of overestimation. From this small and compact output decision table, a classification decision is made about how to set rules for making decisions among certain qualities, as shown in
Figure 3.
The configurations of the data mining classifier used in each experiment were determined in this study as shown in
Table 3.
3.6. Training the Model
Following the selection of features, the models were built using the classification techniques. The 10-folds cross validation technique was used to validate the models’ performances. In this technique, the entire dataset is divided into 10 subsets and then processed 10 times. Nine subsets are used as testing sets, and the remaining one is used as a training set. Finally, the results are shown by averaging each of the 10 iterations. The subsets are divided using stratified sampling, meaning that each subset will have the same class ratio as the main dataset.
3.7. Performance Evaluation
Different performance metrics such as accuracy, precision, recall, and area under the curve (AUC) having been determined for all the models constructed in the previous subsection, the efficacies of these models were evaluated based on these performance metrics. Finally, the best model for predicting depression was chosen, according to the outcomes of these performance metrics.
The proposed model used WEKA and a confusion matrix to estimate classification algorithms: SVM, NB, RF, LR, and J48. For the model, there were three most common evaluation indexes: accuracy, precision, and recall. The calculation of these evaluation indexes is inseparable from the existence of a confusion matrix, which is often used in classification algorithms. Accuracy reflects the proportion of correct classification in the classification results of each category; that is, the accuracy of each category is judged by the model. The formula for this is provided in Equation (4). The ratio of accurately identified true positives to total positive samples is known as precision. The formula is provided in Equation (5). The recall rate reflects the sensitivity of the classification model to each category dataset. The recall percentages of correctly identified positive samples, total positive samples, and total false-negative samples are illustrated in Equation (6). The Area Under the Curve is a measure of a classifier’s ability to distinguish between classes and is used as a summary of the ROC curve. The higher the AUC, the better the model’s performance at distinguishing between the positive and negative classes, as shown in
Table 4.
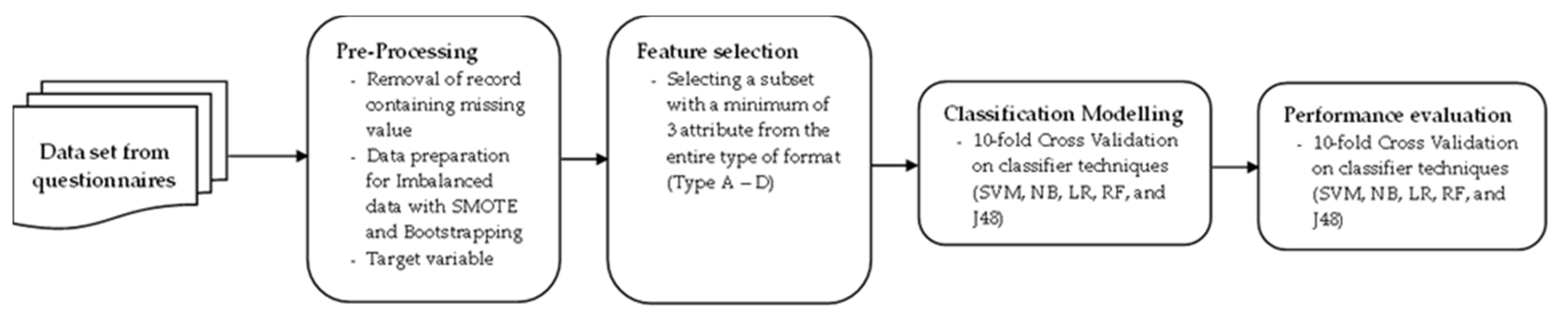
Our model employed classification techniques such as SVM, NB, RF, LR, and J48 for prediction.
Figure 4 presents the proposed model structure.
5. Discussion
Most of the publications included in our review presented high accuracy in classifying individuals with depression based on SMOTE techniques [
55,
64]. Balancing data by using the SMOTE technique is not the most accurate method for predicting risk of depression. Data balanced using the bootstrapping technique is more accurate than SMOTE.
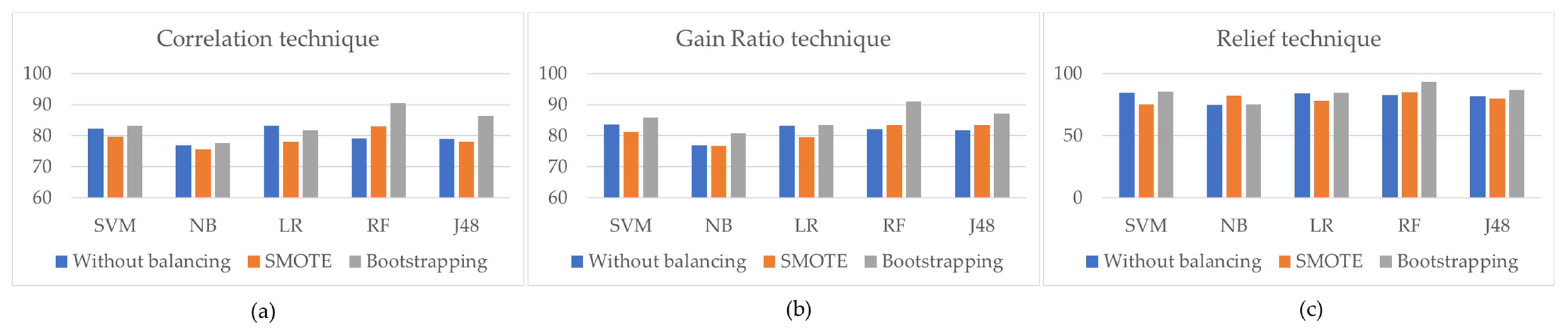
In this study, we compared SMOTE and bootstrapping techniques. As a result, the accuracy of all the data mining classifiers dramatically increased by combining different feature selection techniques with a balancing technique, as shown in
Figure 5. It was discovered that when using the SMOTE technique, the data mining technique’s accuracy value was reduced compared to when using the bootstrapping technique.
Figure 5c demonstrates the highest degree of accuracy when using Relief selection techniques.
The purpose of this study was to identify and create the most significant predictor of depression in students, taking into account socio-demographics, internet addiction, alcohol use disorder, and stress factors, as shown in
Table 8.
6. Conclusions
Different variables can contribute to the development of depression in a person. This study aimed at identifying the most prevalent risk factors for depression. To assess the risk of depression, a dataset of four types, as well as 380 participants, was compiled. Different feature selection techniques extracted the students’ most important socio-demographic, internet addiction, alcohol usage disorder, and stress factors responsible for forming the risk of depression. These feature selection techniques not only increased the training speed of the classifiers, but also improved their ability to accurately screen for depression. This study utilized five different data mining classifiers to determine the presence of depression. By observing the outcomes of the various models presented in this study, it was confirmed that the Random Forest classifier with the Relief feature selection technique was almost the perfect model to predict depression among the participants. It obtained an accuracy of 93.16%.
This work has only predicted the presence of depression in individual students. In the future, this study could be extended to identifying the severity of depression in students. As different socio-demographic and other factors have a big effect on how likely it is that a student will be depressed, this second study could look at the different characteristics of the participants. Several studies show that the performance of a model gets better when different data mining classifiers with balancing techniques and feature selection techniques are used during the data preprocessing steps. In the future, these methods could be used, their results could be compared to those of the current study, and this research could be developed into a more comprehensive depression assessment questionnaire for students than those currently in use.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}