MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images



Abstract

1. Introduction
- (1)
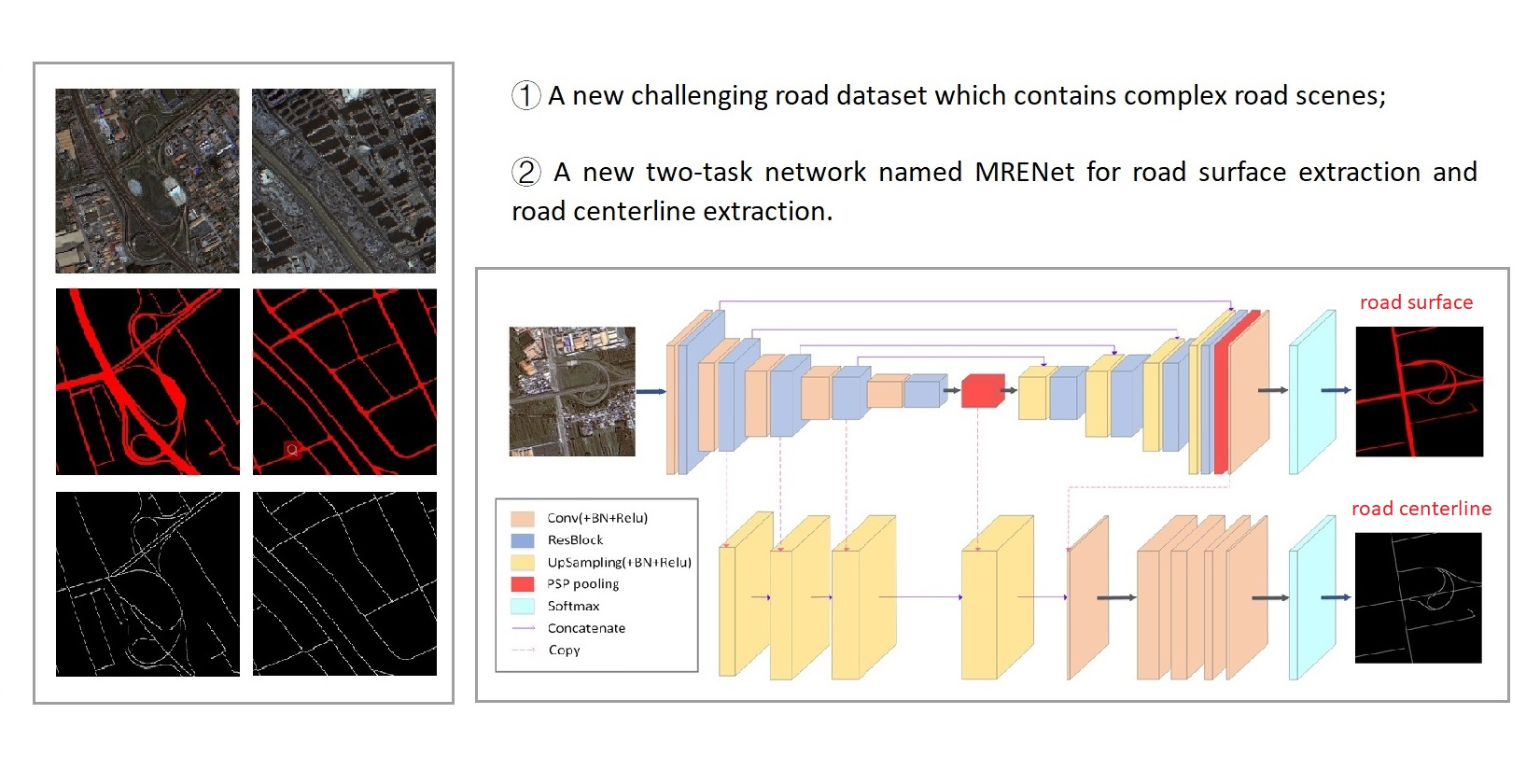
- We introduce a new challenging dataset derived from GF-2 VHR images. The introduced dataset contains complicated urban scenes, which can be better considered as a reflection of the real world, providing more possibilities for road-related information extraction, especially under less ideal situations.
- (2)
- We propose a new network named MRENet that consists of atrous convolutions and a PSP pooling module. The experiments suggest that our approach outperforms existing approaches in both road surface extraction and road centerline extraction tasks.
- (3)
- We conduct a group of band contrast experiments to investigate the effect of incorporating NIR band on experimental results.
2. Materials
2.1. Characteristics of the Road Surface
- In terms of geometric characteristics, urban roads are generally described as a narrow and nearly parallel area with a certain length, stable width, and obvious edge. Both the edge and the centerline have obvious linear geometric features, often with a large length–width ratio;
- In terms of radiation characteristics, roads have distinct spectral characteristics compared with vegetation, soil, and water, but they can be easily confused with artificial structures such as parking lots. The grayscale of the road tends to change uniformly, which generally shows the color of black, white, and gray. However, due to the existence of a large number of vehicles and pedestrians on the surface, such noise interference is inevitable;
- In terms of topological characteristics, urban roads are generally connected with each other, forming a road network with high connectivity;
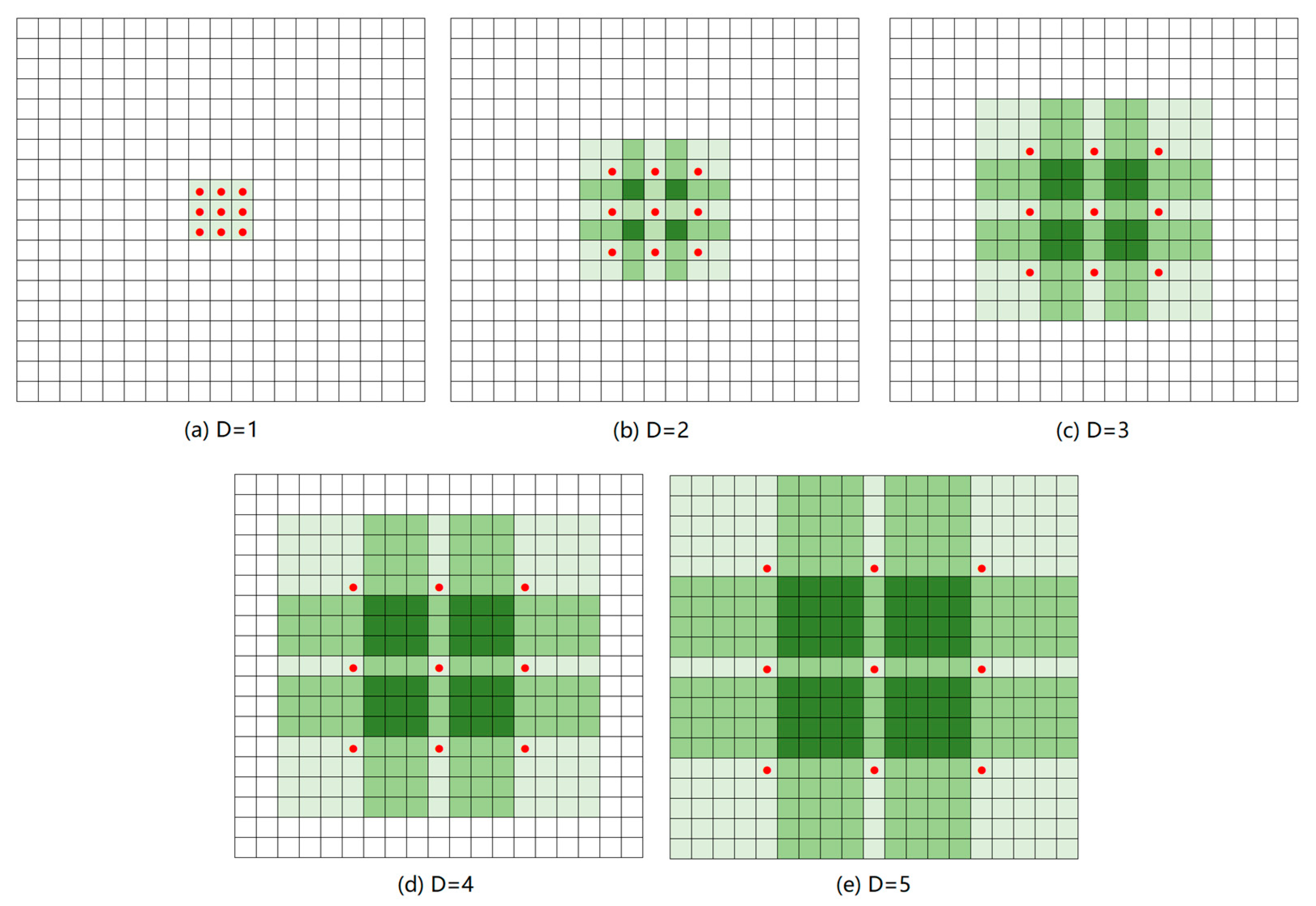
2.2. Characteristics of the Road Centerline
2.3. Description of Datasets
3. Methodology
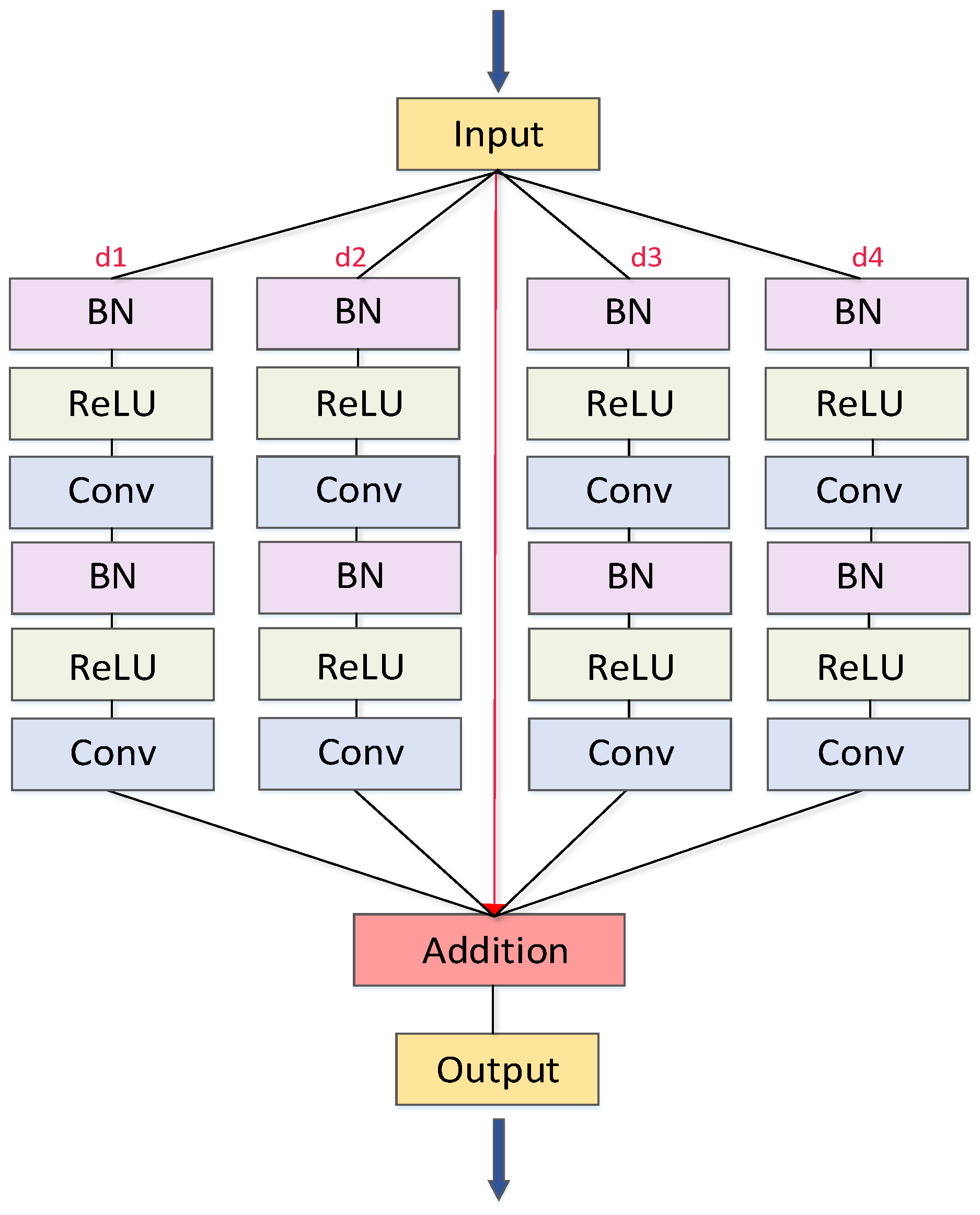
3.1. ResBlock
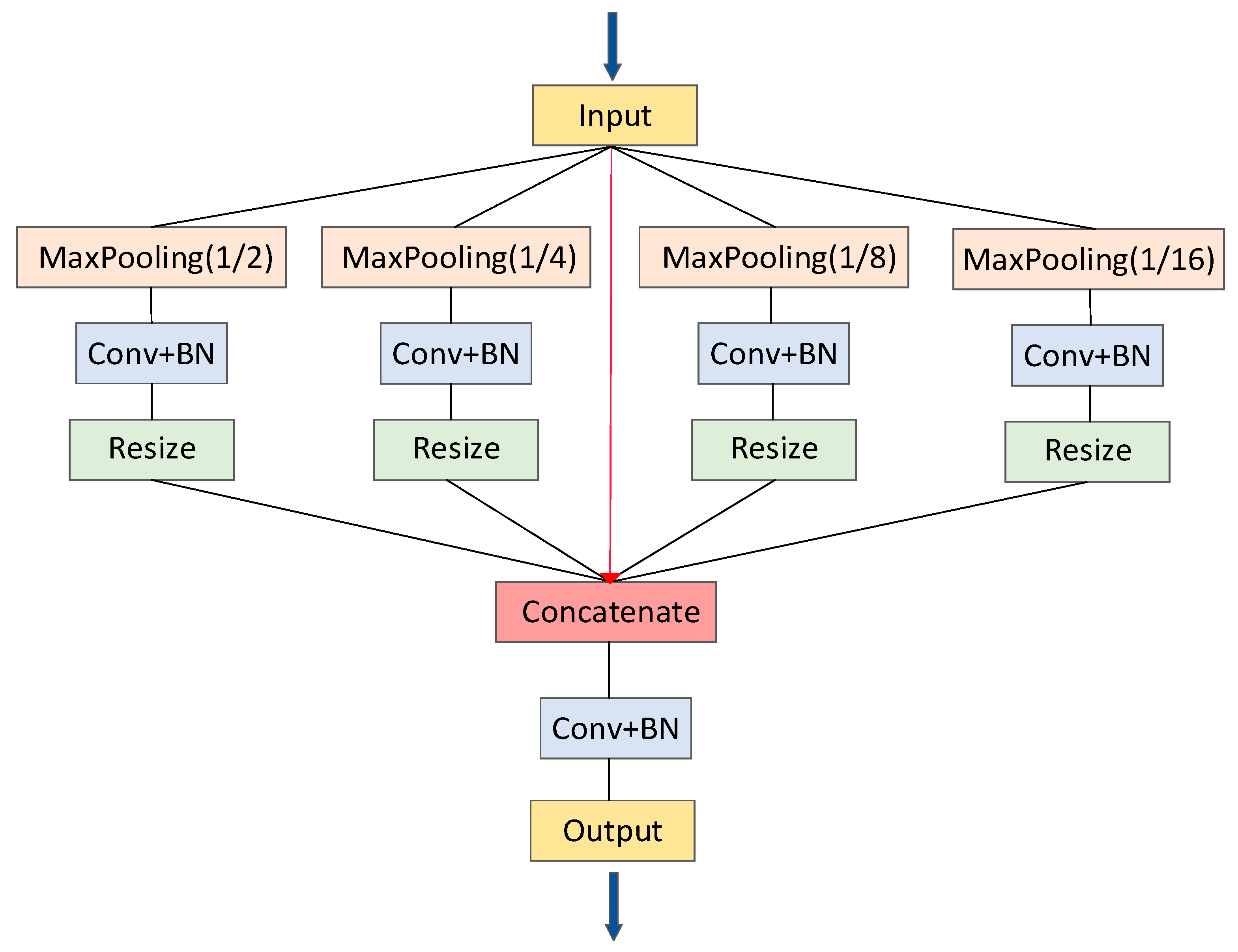
3.2. PSP Pooling
3.3. Multitask Learning
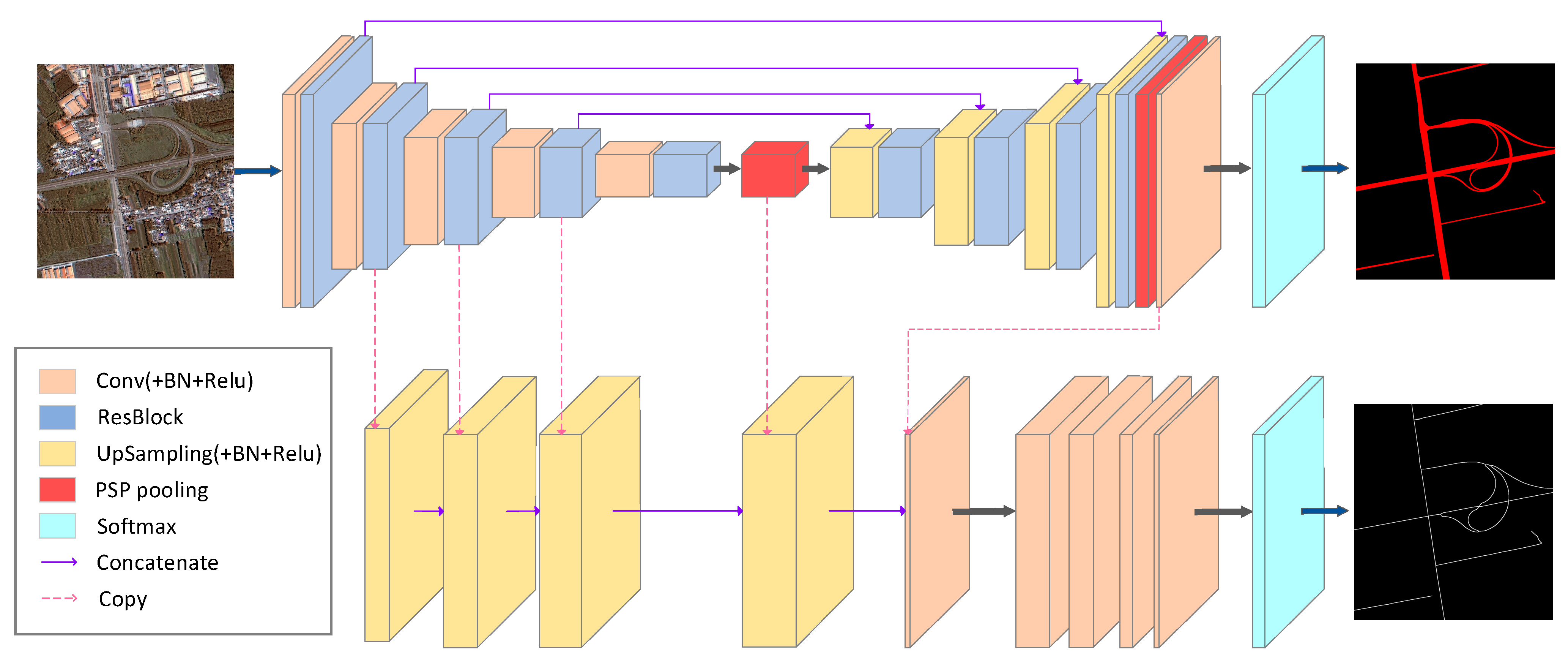
3.4. MRENet Architecture
4. Experiments and Results
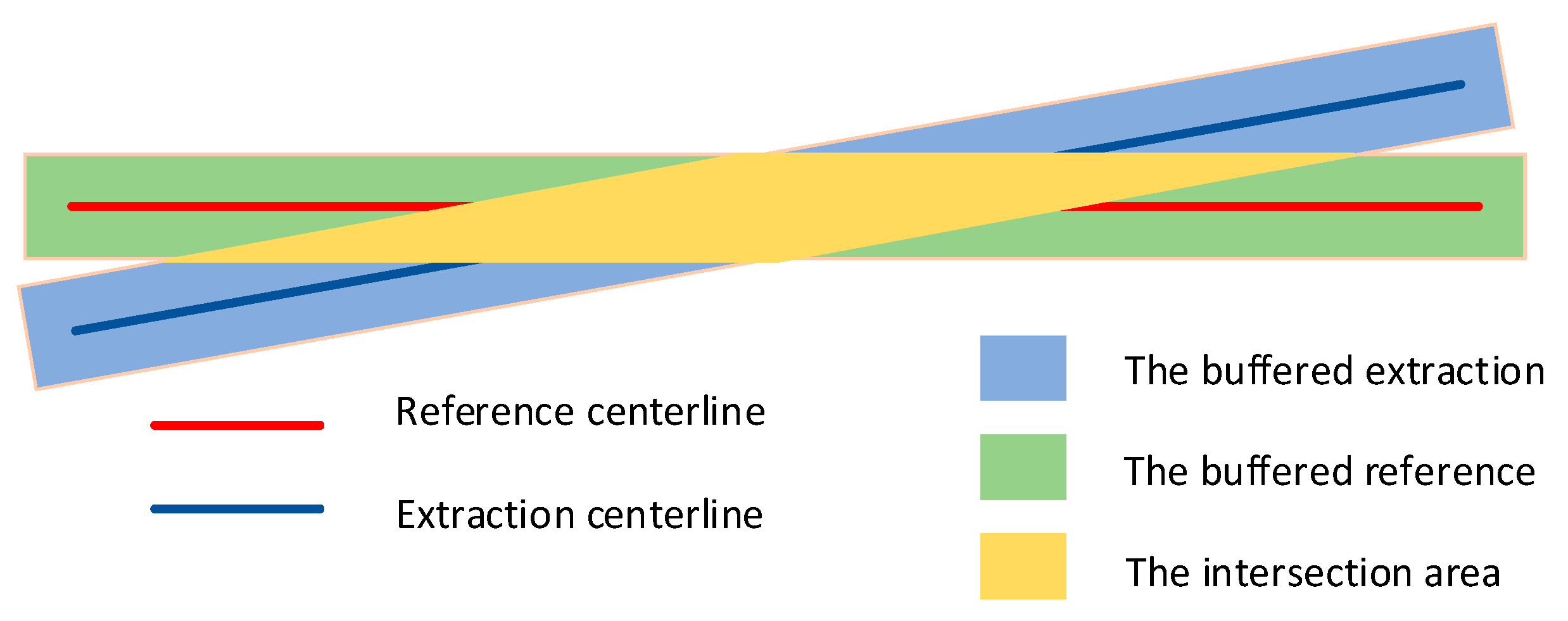
4.1. Evaluation Metrics
4.2. Implementation
4.3. Comparison of Road Surface Extraction
4.4. Comparison of Road Centerline Extraction
5. Discussion
5.1. Comparison of Different Band Selection
5.2. Comparison of Different Upsampling Connection Locations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Bajcsy, R.; Tavakoli, M. Computer Recognition of Roads from Satellite Pictures. IEEE Trans. Syst. Man Cybern. 1976, 6, 623–637. [Google Scholar] [CrossRef]
- Tunde, A.; Adeniyi, E. Impact of Road Transport on Agricultural Development: A Nigerian Example. Ethiop. J. Environ. Stud. Manag. 2012, 5, 232–238. [Google Scholar] [CrossRef]
- Frizzelle, B.G.; Evenson, K.R.; Rodriguez, D.A.; Laraia, B.A. The importance of accurate road data for spatial applications in public health: Customizing a road network. Int. J. Health Geogr. 2009, 8, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Li, M.; Stein, A.; Bijker, W.; Zhan, Q. Region-based urban road extraction from VHR satellite images using Binary Partition Tree. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 217–225. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of salient features for the design of a multistage framework to extract roads from high-resolution multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A new method for region-based majority voting CNNs for very high resolution image classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef]
- Li, D.; Ma, J.; Cheng, T.; van Genderen, J.L.; Shao, Z. Challenges and opportunities for the development of MEGACITIES. Int. J. Digit. Earth 2019, 12, 1382–1395. [Google Scholar] [CrossRef]
- McKeown, D.M.; Denlinger, J.L. Cooperative methods for road tracking in aerial imagery. In Proceedings of the CVPR’88: The Computer Society Conference on Computer Vision and Pattern Recognition, Ann Arbor, MI, USA, 5–9 June 1988; pp. 662–672. [Google Scholar]
- Zhang, J.; Lin, X.; Liu, Z.; Shen, J. Semi-automatic road tracking by template matching and distance transformation in Urban areas. Int. J. Remote Sens. 2011, 32, 8331–8347. [Google Scholar] [CrossRef]
- Fu, G.; Zhao, H.; Li, C.; Shi, L. Road Detection from Optical Remote Sensing Imagery Using Circular Projection Matching and Tracking Strategy. J. Indian Soc. Remote Sens. 2013, 41, 819–831. [Google Scholar] [CrossRef]
- Treash, K.; Amaratunga, K. Automatic Road Detection in Grayscale Aerial Images. J. Comput. Civ. Eng. 2000, 14, 60–69. [Google Scholar] [CrossRef]
- Schubert, H.; van de Gronde, J.J.; Roerdink, J.B.T.M. Efficient Computation of Greyscale Path Openings. Math. Morphol. Theory Appl. 2016, 1, 189–202. [Google Scholar] [CrossRef][Green Version]
- Maboudi, M.; Amini, J.; Hahn, M.; Saati, M. Road network extraction from VHR satellite images using context aware object feature integration and tensor voting. Remote Sens. 2016, 8, 637. [Google Scholar] [CrossRef]
- Maggiori, E.; Manterola, H.L.; del Fresno, M. Perceptual grouping by tensor voting: A comparative survey of recent approaches. IET Comput. Vis. 2015, 9, 259–277. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2017, 126, 245–260. [Google Scholar] [CrossRef]
- Mayer, H.; Laptev, I.; Baumgartner, A.; Steger, C. Automatic Road Extraction Based On Multi-Scale Modeling, Context, And Snakes. Int. Arch. Photogramm. Remote Sens. 1997, 32, 106–113. [Google Scholar]
- Trinder, J.C.; Wang, Y. Automatic road extraction from aerial images. Digit. Signal Process. Rev. J. 1998, 8, 215–224. [Google Scholar] [CrossRef]
- Dal Poz, A.P.; Zanin, R.B.; Do Vale, G.M. Automated extraction of road network from medium-and high-resolution images. Pattern Recognit. Image Anal. 2006, 16, 239–248. [Google Scholar] [CrossRef]
- Cao, C.; Sun, Y. Automatic road centerline extraction from imagery using road GPS data. Remote Sens. 2014, 6, 9014–9033. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, Z.; Li, S.; Tao, D. Road detection by using a generalized hough transform. Remote Sens. 2017, 9, 590. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xia, M.; Wang, X.; Liu, Y. RoadNet: Learning to Comprehensively Analyze Road Networks in Complex Urban Scenes from High-Resolution Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2043–2056. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-Scale and Multi-Task Deep Learning Framework for Automatic Road Extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.V.; Paluri, M. Improved road connectivity by joint learning of orientation and segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10377–10385. [Google Scholar]
- Qi, J.; Tao, C.; Wang, H.; Tang, Y.; Cui, Z. Spatial Information Inference Net: Road Extraction Using Road-Specific Contextual Information. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 9478–9481. [Google Scholar]
- Zhang, X.; Han, X.; Li, C.; Tang, X.; Zhou, H.; Jiao, L. Aerial image road extraction based on an improved generative adversarial network. Remote Sens. 2019, 11, 930. [Google Scholar] [CrossRef]
- Liu, B.; Wu, H.; Wang, Y.; Liu, W. Main road extraction from ZY-3 grayscale imagery based on directional mathematical morphology and VGI prior knowledge in Urban areas. PLoS ONE 2015, 10, e0138071. [Google Scholar] [CrossRef]
- Amini, J.; Saradjian, M.R.; Blais, J.A.R.; Lucas, C.; Azizi, A. Automatic road-side extraction from large scale imagemaps. Int. J. Appl. Earth Obs. Geoinf. 2002, 4, 95–107. [Google Scholar] [CrossRef]
- Zheng, S.; Liu, J.; Shi, W.Z.; Zhu, G.X. Road central contour extraction from high resolution satellite image using tensor voting framework. In Proceedings of the 5th International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 3248–3253. [Google Scholar]
- Miao, Z.; Shi, W.; Zhang, H.; Wang, X. Road Centerline Extraction From High-Resolution Imagery Based on Shape Features and Multivariate Adaptive Regression Splines. IEEE Geosci. Remote Sens. Lett. 2013, 10, 583–587. [Google Scholar] [CrossRef]
- Cheng, G.; Zhu, F.; Xiang, S.; Wang, Y.; Pan, C. Accurate urban road centerline extraction from VHR imagery via multiscale segmentation and tensor voting. Neurocomputing 2016, 205, 407–420. [Google Scholar] [CrossRef]
- Cheng, G.; Zhu, F.; Xiang, S.; Pan, C. Road Centerline Extraction via Semisupervised Segmentation and Multidirection Nonmaximum Suppression. IEEE Geosci. Remote Sens. Lett. 2016, 13, 545–549. [Google Scholar] [CrossRef]
- Gao, L.; Shi, W.; Miao, Z.; Lv, Z. Method based on edge constraint and fast marching for road centerline extraction from very high-resolution remote sensing images. Remote Sens. 2018, 10, 900. [Google Scholar] [CrossRef]
- Zhou, T.; Sun, C.; Fu, H. Road information extraction from high-resolution remote sensing images based on road reconstruction. Remote Sens. 2019, 11, 79. [Google Scholar] [CrossRef]
- Yujun, W.; Xiangyun, H.; Jinqi, G. End-to-end road centerline extraction via learning a confidence map. In Proceedings of the 2018 10th IAPR Workshop on Pattern Recognition in Remote Sensing, PRRS 2018, Beijing, China, 19–20 August 2018; pp. 1–5. [Google Scholar]
- Zhang, Y.; Xiong, Z.; Zang, Y.; Wang, C.; Li, J.; Li, X. Topology-aware road network extraction via Multi-supervised Generative Adversarial Networks. Remote Sens. 2019, 11, 1017. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Object detection in UAV images via global density fused convolutional network. Remote Sens. 2020, 12, 3140. [Google Scholar] [CrossRef]
- Wang, C.; Bai, X.; Wang, S.; Zhou, J.; Ren, P. Multiscale Visual Attention Networks for Object Detection in VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 310–314. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Yang, W.; Zhang, L. Recent advances and opportunities in scene classification of aerial images with deep models. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 4371–4374. [Google Scholar]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud detection in remote sensing images based on multiscale features-convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Qi, K.; Liu, W.; Yang, C.; Guan, Q.; Wu, H. Multi-task joint sparse and low-rank representation for the scene classification of high-resolution remote sensing image. Remote Sens. 2017, 9, 10. [Google Scholar] [CrossRef]
- Caruana, R.; Mitchell, T.; Pomerleau, D.; Dietterich, T.; State, O. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between precision-recall and ROC curves. In Proceedings of the ICML 2006: 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar] [CrossRef]
- Khryashchev, V.; Larionov, R. Wildfire Segmentation on Satellite Images using Deep Learning. In Proceedings of the 2020 Moscow Workshop on Electronic and Networking Technologies, MWENT 2020, Moscow, Russia, 11–13 March 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bands | Resolution (m) | Wavelength (μm) |
|---|---|---|
| Pan | 1 | 0.45–0.90 |
| Blue | 4 | 0.45–0.52 |
| Green | 4 | 0.52–0.59 |
| Red | 4 | 0.63–0.69 |
| NIRed | 4 | 0.77–0.89 |
| Methods | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| FCN | 0.7097 | 0.6455 | 0.6761 | 0.5107 |
| SegNet | 0.7447 | 0.6650 | 0.7025 | 0.5415 |
| Unet | 0.7591 | 0.6688 | 0.7111 | 0.5517 |
| Ours | 0.7554 | 0.6771 | 0.7141 | 0.5553 |
| Buffer Xidth | Methods | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|---|
| ρ = 1 | FCN | 0.6488 | 0.5727 | 0.6084 | 0.4372 |
| SegNet | 0.7004 | 0.5911 | 0.6411 | 0.4718 | |
| Unet | 0.7091 | 0.6164 | 0.6595 | 0.4920 | |
| Ours | 0.7180 | 0.6160 | 0.6631 | 0.4960 | |
| ρ = 3 | FCN | 0.6820 | 0.6184 | 0.6486 | 0.4800 |
| SegNet | 0.7250 | 0.6258 | 0.6718 | 0.5057 | |
| Unet | 0.7321 | 0.6354 | 0.6803 | 0.5155 | |
| Ours | 0.7406 | 0.6377 | 0.6853 | 0.5213 | |
| ρ = 5 | FCN | 0.7118 | 0.6379 | 0.6728 | 0.5070 |
| SegNet | 0.7365 | 0.6465 | 0.6886 | 0.5251 | |
| Unet | 0.7427 | 0.6571 | 0.6973 | 0.5353 | |
| Ours | 0.7516 | 0.6566 | 0.7009 | 0.5395 |
| Bands | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| RGB | 0.7526 | 0.6480 | 0.6964 | 0.5342 |
| RGB + NIR | 0.7554 | 0.6771 | 0.7141 | 0.5553 |
| Buffer Width | Methods | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|---|
| ρ = 1 | RGB | 0.7070 | 0.5933 | 0.6452 | 0.4762 |
| RGB + NIR | 0.7180 | 0.6160 | 0.6631 | 0.4960 | |
| ρ = 3 | RGB | 0.7290 | 0.6251 | 0.6731 | 0.5072 |
| RGB + NIR | 0.7406 | 0.6377 | 0.6853 | 0.5213 | |
| ρ = 5 | RGB | 0.7398 | 0.6448 | 0.6890 | 0.5256 |
| RGB + NIR | 0.7516 | 0.6566 | 0.7009 | 0.5395 |
| Bands | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| MRENet_Conv | 0.7144 | 0.6123 | 0.6594 | 0.4919 |
| MRENet_Resblock | 0.7180 | 0.6160 | 0.6631 | 0.4960 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sens. 2021, 13, 239. https://doi.org/10.3390/rs13020239
Shao Z, Zhou Z, Huang X, Zhang Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sensing. 2021; 13(2):239. https://doi.org/10.3390/rs13020239
Chicago/Turabian StyleShao, Zhenfeng, Zifan Zhou, Xiao Huang, and Ya Zhang. 2021. "MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images" Remote Sensing 13, no. 2: 239. https://doi.org/10.3390/rs13020239
APA StyleShao, Z., Zhou, Z., Huang, X., & Zhang, Y. (2021). MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sensing, 13(2), 239. https://doi.org/10.3390/rs13020239