1. Introduction
The expansion of Internet of Things is increasing the importance of outlier detection in streaming data. A wide range of tasks ranging from factory control charts to network traffic monitoring depend on the identification of anomalous events associated with intrusion attacks, system faults, and sensor errors [
1,
2]. Some outlier detection methods are designed to find global outliers, while some methods try to find local outliers [
1,
2].
The local outlier factor, LOF, proposed in [
3], is a well-known density-based algorithm for the detection of local outliers in static data. LOF measures the local deviation of data points with respect to their
K nearest neighbors, where
K is a user-defined parameter. This kind of method can be useful in several applications, such as detecting fraudulent transactions, intrusion detection, direct marketing, and medical diagnostics. Later, the concept of LOF was extended for incremental databases [
4], and for streaming environments [
5,
6]. However, recent advances in LOF-based outlier detection algorithms for data streams, MILOF [
5] and DILOF [
6], do not consider variations in data that may change over time. For example, there may appear a new cluster of data points over time in the data streams. In addition, algorithms for data streams need to avoid using outdated data. To handle the data streams, the algorithms utilize a fixed window size to limit the number of data points held in memory by summarizing previous data points. These recent studies base their summaries only on the distribution of previous data; i.e., they do not take the sequence of data into account. The fact that these methods lack a mechanism for the removal of outdated data can greatly hinder their performances. Imagine a situation where sensors installed near a factory are used to detect the emission of PM2.5 pollutants. If pollutants were emitted on more than one occasion (with an intermittent period of normal concentrations), then the fact that the initial pollution event is held in memory might prevent the detection of subsequent violations. In other words, if the previous pollution event is held in memory for longer time, the next pollution event will be treated as an inlier and the method could not detect next pollution event.
Moreover, limited memory and computing power impose limitations on window size and thus on model performance because limitations on memory capacity and computational power necessitate the elimination of some previous data points. However, setting an excessively small window size can degrade performance because we can only hold a few data points in memory and hence there may be lack of neighboring data points with similar features, which affects the outlier scores.
A data stream potentially contains an infinite number of data points: . Each data point is collected at time t. We need to consider the following constrains for applications in data stream environments.
Continuous data points (usually infinite).
Limited memory and limited computing power.
Real time responses for processed data.
Our goal is to detect outliers by calculating the LOF score for each data point. In addition, we are focusing on detecting outliers in data stream. Therefore, the following constraints must be considered in the detection of outliers in a data stream.
Memory limitations constrain the amount of data that can be held in memory. We need to consider this for handling unbounded data stream environment.
The state of the current data point as an outlier/inlier must be established before dealing with subsequent data points. Note that we do not have any information related to subsequent data points appearing in the data stream.
Adding new data may induce new clusters.
Limited computing power needs to be utilized before new data arrives in the data stream. Therefore, the algorithms need to be efficient in terms of execution time.
In this study, we sought to resolve these issues by developing a (1) time-aware and density-summarizing incremental LOF (TADILOF) and (2) a method to approximate the value of LOF. For time-aware summarization, we include a time component, also termed time indicator, with each data point. The inclusion of a time component in the summary phase makes it possible to consider the sequential order of the data, and thereby deal with concept drift and enable the removal of outdated data points. Basically, every data point is assigned a time indicator referring to the point at which it was added to the streaming data. When a new data point arrives, the time indicators of K-nearest neighbor data points are updated if the newly added data point is not judged as an outlier. Using this strategy, the data points near to new data points are updated with the current time indicator and therefore these data points are less likely to be removed in the summarization phase. Thus, our proposed method is more likely to follow the variations in data that may change over time.
Furthermore, we propose a method to calculate approximate LOF score based on the summary information of previous data points. Note that this involves estimating the distances between newly-added data points and potential deleted neighbors (i.e., data points deleted in a previous summary phase). In the proposed method, LOF score is used to decide whether a newly added data point is an outlier or not in accordance with a LOF threshold. LOF score represents the outlierness of the data points based on the local densities defined using K-nearest neighbor data points. In addition, LOF score is able to adjust for the variations in the different local densities [
2]. If the newly added data point is detected as an outlier as per LOF threshold, we use a second check based on proposed approximate LOF score to finally decide whether it is an outlier or not.
To maintain the data in the window, we use the concept of a landmark window strategy as used in the recent studies, MILOF [
5] and DILOF [
6], for local outlier detection in data streams. When the window is filled with the data points, we summarize the window to make space available for new data points by removing the old and less important data identified by the proposed summarization method. In our proposed summarization method, we summarize the data points of complete window using three quarters of the window. Then, one quarter size of window becomes available for new data points. We discuss the details of our summarization method in
Section 3.2.
To limit the data to fit into available memory, the sliding window technique used in several applications for data streams is also an option. In the sliding window technique, all the old data points are deleted that cannot fit into memory. However, this may degrade the performance of local outlier detection because new events cannot be differentiated from some past events, and the accuracy of the estimated local outlier factor of data points will be affected if the histories of earlier data points are deleted [
5]. Therefore, we use the landmark window strategy. In addition, the proposed strategies of using a time indicator and approximate LOF are suitable in combination with a landmark window for local outlier detection accuracy.
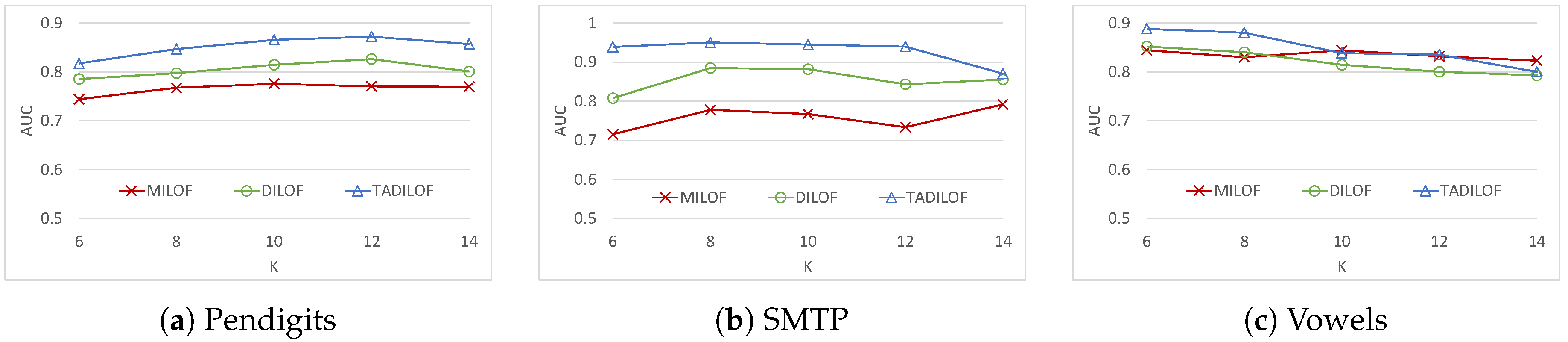
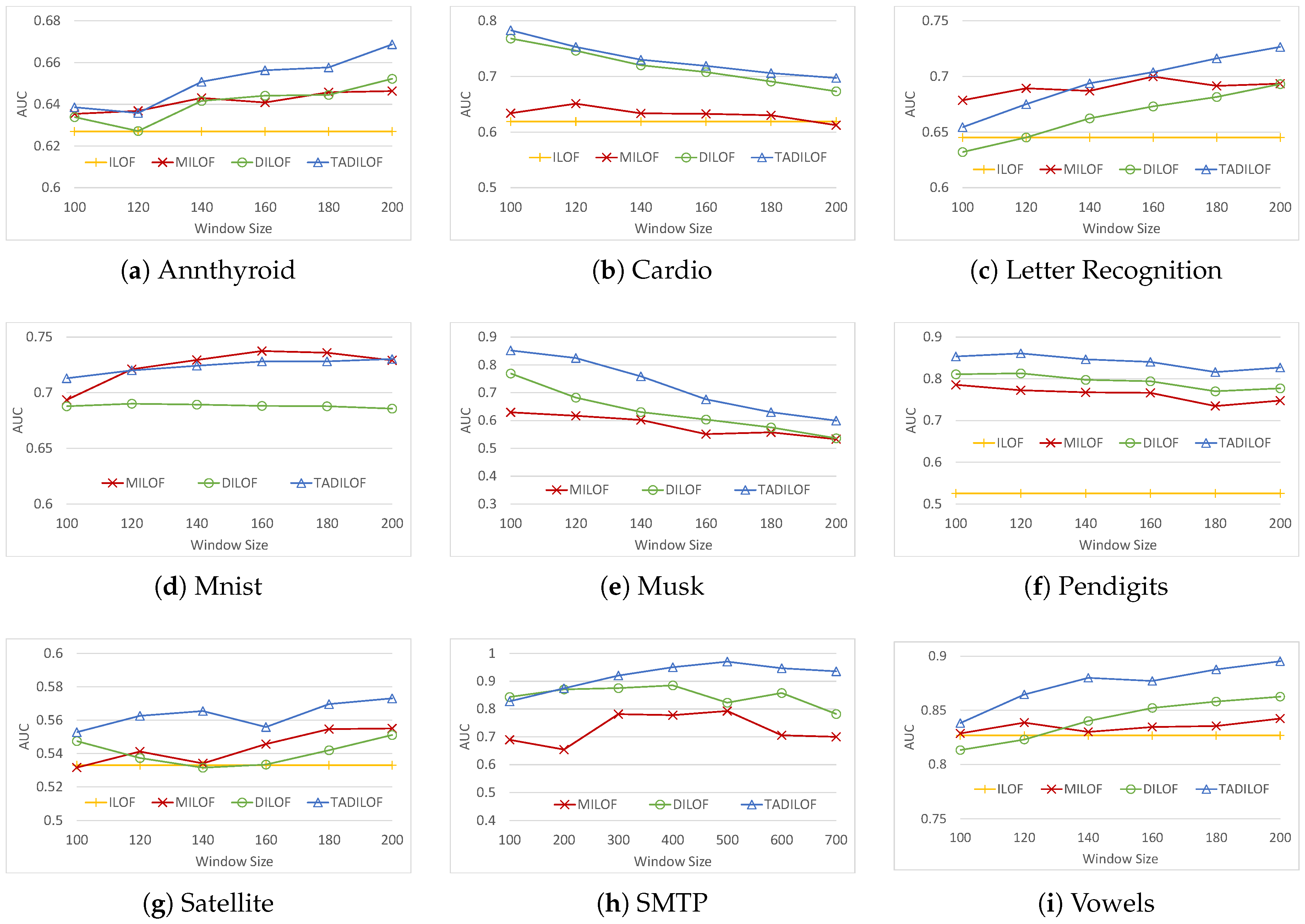
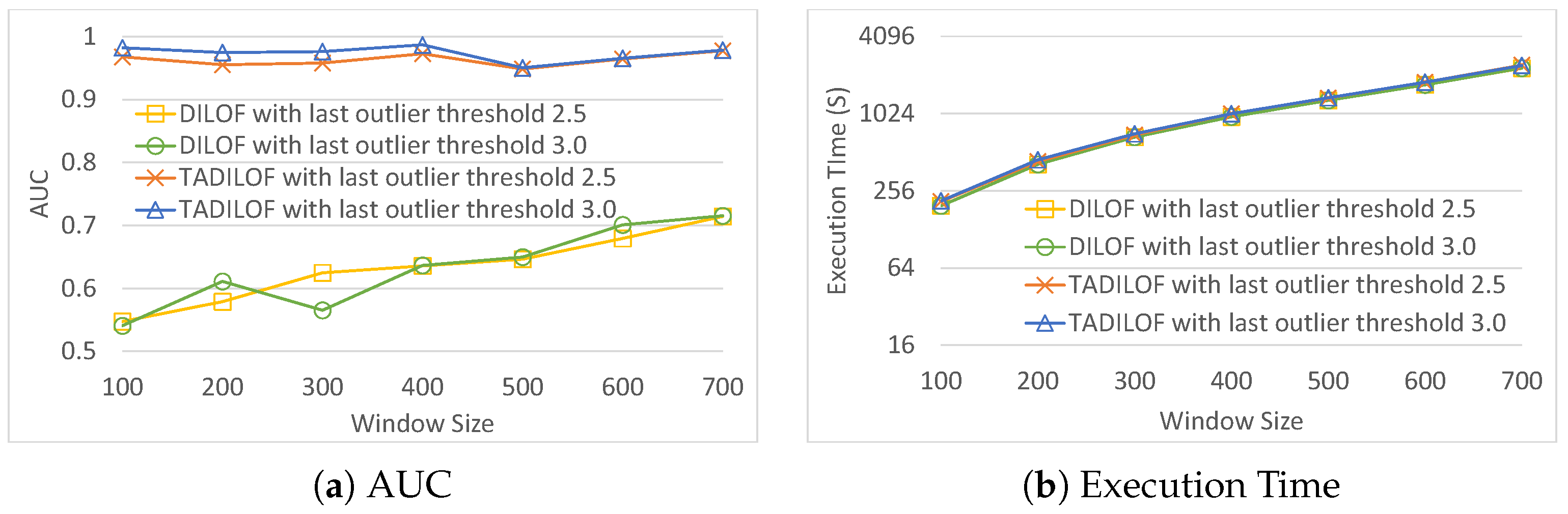
In addition, to evaluate the performance of our proposed method, we executed extensive experiments against the state-of-the-art algorithms on various real datasets. The results of experiments illustrate that the proposed algorithm outperforms state-of-the-art competitors in terms of AUC while achieving similar performance in terms of execution time. The results of experiments validate the effectiveness of the proposed method to use the time component and approximate LOF, which help to achieve better AUC.
Moreover, we applied the proposed method to a real-world data streaming environment for the monitoring of the air quality. The Taiwanese monitoring system referred to as the location-aware sensing system (LASS) employs 2000 sensors, each of which can be viewed as an individual data stream. We used the proposed system to detect outliers in each of these data streams. We call this type of outlier a temporal outlier because such outliers are compared with historical data points from the same device. We then combine the position of every device to facilitate the detection of spatial outliers and pollution events based on outliers from the neighboring devices.
The main contributions of this work are as follows.
We developed a novel algorithm to detect outliers in data streams. The proposed approach is capable of adapting the changes in variations of data over time.
We developed an algorithm to calculate approximate LOF score in order to improve model performance.
Extensive experiments using real-world datasets were performed to compare the performance of the proposed scheme with those of various state-of-the-art methods.
The efficacy of the proposed scheme was demonstrated in a real-world pollution detection system using PM2.5 sensors.
The rest of this paper is organized as follows. In
Section 2, we discuss related works. Then, we introduce the proposed method in
Section 3. In
Section 4, we describe our experiments and a performance evaluation of the proposed method.
Section 5 demonstrates a case study based on our proposed method for monitoring air quality and detection of pollution events. Finally, conclusions are presented in
Section 6.
2. Background and Related Work
Outlier and anomaly detection on large datasets and data streams is a very important research area that has been useful for several applications [
1,
2,
7]. Some studies focus on detecting global outliers, whereas other studies focus on detecting local outliers [
1,
2]. Different approaches have been studied for outlier detection, such as distance-based methods, density-based methods, and neural network-based methods [
8].
In addition, clustering techniques can also be used for outlier detection. Therefore, we discuss some works on clustering and outlier detection based on clustering. In [
9], the authors discussed a method for incremental K-means clustering. In the incremental database, this approach is better than traditional K-means. Similarly, the study in [
10] proposes IKSC, incremental kernel spectral clustering, for online clustering in dynamic data. Another study in [
11] discusses various machine learning approaches for real-world SHM (structural health monitoring) applications. The authors discuss the temporal variations of operational and environmental factors and their influences on the damage detection process. In [
12], the authors propose enhancement of density-based clustering and outlier detection based on clustering. In addition, the authors discuss the approach for parameter reduction for density-based clustering. In [
13], the authors propose a density-based outlier detection method using DBSCAN. First, the authors compute the minimum radius of an accepted cluster; then a revised version process of DBSCAN is used to further fit for data clustering and the decision of whether each point is normal or abnormal can be made. In [
14], the authors provide survey of unsupervised machine learning algorithms that are proposed for outlier detection. In [
15], the authors propose a cervical cancer prediction model (CCPM) for early prediction of cervical cancer using risk factors as inputs. The authors utilize several machine learning approaches and outlier detection for different preprocessing tasks.
The local outlier factor (LOF) [
3] is a well-known density-based algorithm for the detection of local outliers in static data. This method can be useful in several applications, such as detecting fraudulent transactions, intrusion detection, direct marketing, and medical diagnostics [
16,
17,
18]. Based on LOF, the study in [
19] proposed a method to mine top-n local outliers. Later, the concept of LOF was extended for dynamic data—for instance, incremental LOF (iLOF) [
4] was made for incremental databases, and MiLOF [
5] and DILOF [
6] were made for streaming environments. The application of LOF to incremental databases requires updating every previous data point and the recalculation of the LOF score, both of which are computationally intensive. iLOF reduces the time complexity to
by updating the LOF score of data points affected by newly-added data points. Unfortunately, this approach is inapplicable to data streams with limited memory resources. MiLOF leverages the concept of K-means [
20] to facilitate outlier detection in data streams by overcoming the space complexity of iLOF (i.e.,
). MiLOF uses a fixed window size to limit the number of data points held in memory by summarizing previous data points through the formation of K-cluster centers. Note, however, that MiLOF is prone to the loss of density information and a large number of points are required to represent sparse clusters. DILOF was developed to improve the summarization process using the nonparametric Rényi divergence estimator [
21] to select minimum divergence subset from previous data points. However, neither MiLOF nor DILOF consider the concept-drift [
22,
23] of data in data streams to avoid using outdated data [
24]. Furthermore, MiLOF and DILOF base their summaries only on the distribution of previous data; i.e., they do not take the sequence of data into account.
Some other methods based on LOF have been proposed for top-n outlier detection. In [
25], the authors proposed the TLOF algorithm for scalable top-n local outlier detection. The authors proposed a multi-granularity pruning strategy to quickly prune search space by eliminating candidates without computing their exact LOF scores. In addition, the authors designed a density-aware indexing mechanism that helps the proposed pruning strategy and the KNN search. In [
26], the authors proposed local outlier semantics to detect local outliers by leveraging kernel density estimation (KDE). The authors proposed a KDE-based algorithm, KELOS, for top-n local outliers over data streams. In [
27], the authors proposed the UKOF algorithm for top-n local outlier detection based on KDE over large-scale high-volume data streams. The authors defined a KDE-based outlier factor (KOF) to measure the local outlierness score, and also proposed the upper bounds of the KOF and an upper-bound-based pruning strategy to reduce the search space. In addition, the authors proposed LUKOF by applying the lazy update method for bulk updates in high-speed large-scale data streams.
Since this study proposes a method to find local outliers in data streams, we discuss LOF, iLOF, MiLOF, and DILOF in the following subsections.
2.1. LOF and iLOF
LOF scores are computed for all data points according to parameter K (i.e., the number of nearest neighbors). The LOF score is calculated as follows:
Definition 1. is the Euclidean distance between two data points p and o.
Definition 2. K-distance(p), , is defined as the distance between data point p and its nearest neighbor.
Definition 3. Given two data points p and o, reachability distance is defined as: Definition 4. Local reachability density of data point p, , is derived as follows:where is the set of K nearest neighboring data points of point p, and K is a user-defined parameter. Definition 5. Local outlier factor of data point p, , is obtained as follows: If the LOF score of a data point is greater than or equal to the threshold, then that data point is considered an outlier.
LOF is used to calculate the LOF scores only once. iLOF was developed to deal with the problem of data insertion, wherein we update only the previous data points that are affected by the new data point. Note that iLOF is not applicable to the detection of outliers in streaming data, due to the fact that there is no mechanism for the removal of outdated points. In addition, real-world applications lack the memory resources required to deal with the enormous (potentially infinite) number of data points generated by streaming applications.
Since LOF and iLOF are not suitable for data streams, MiLOF [
5] was proposed for the detection of outliers in streaming data. We discuss MiLOF in the next subsection.
2.2. MiLOF
MiLOF [
5] was developed for the detection of outliers in streaming data using limited memory resources. Essentially, MiLOF overcomes the memory issue by summarizing previous data points. MiLOF is implemented in three phases: insertion, summarization, and merging. Note that the insertion step of MiLOF is similar to that of iLOF. When the number of points held in memory reaches the limit imposed by window size
b, the summarization step is invoked, wherein the K-means algorithm is used to find
c cluster centers to represent the first
data points, after which the insertion step is repeated iteratively. In the merging phase, weights are assigned to each cluster center based on the number of associated data points. The weighted K-means algorithm is then used to merge the new cluster center with the old cluster center. When using MiLOF, the total amount of data held in memory does not exceed
. MiLOF can be used to reduce memory and computation requirements; however, it does not preserve the density of the original dataset within the summary, which is crucial to detection accuracy.
2.3. DILOF
Being similar to MILOF, DILOF is a density-based local outlier detection algorithm for data streams that utilizes LOF score to detect outliers. DILOF is implemented in two phases: detection and summarization. The detection phase, which is called last outlier-aware detection (LOD), uses the iLOF technique to calculate LOF values when new data points are added to the dataset. DILOF then classifies the data points within the normal class or as an outlier. The summarization phase, which is called nonparametric density summarization (NDS), is activated when the number of data points reaches the limit defined by window size
W. DILOF uses the nonparametric Rényi divergence estimator [
21] to characterize the divergence between the original data and summary candidate. The gradient descent method is then used to determine the best summary combination. Summarization compiles half of the data
within a space one quarter the size of the window size
by minimizing the loss function. There are four terms in the loss function. In the following, we introduce them one by one.
The first term is the Rényi diversity between the summary candidate and the original data. Renyi diversity is calculated using Equation (
4), as follows:
In Equation (
4),
is the binary decision variable of each data point
. Data point
is selected when
equals 1 and discarded when
equals 0. However, assessing every subset combination to determine the minimum loss values is impractical. NDS resolves this issue by relaxing the decision variable to produce an unconstrained optimization problem, where
becomes a continuous variable. Using the gradient descent method, NDS selects the best combination of
—i.e., the half of parameter set
with the highest values.
is the Euclidean distance between data point
and its
Kth-nearest neighbor in X.
is the Euclidean distance between data point
and its
Kth-nearest neighbor in Z. This term is given by the Rényi divergence estimator.
The second term is the shape term, which preserves the shape of the data distribution by selecting data points at the boundary of clusters, such that the data point within the boundary always has a higher LOF value. This term is shown as Equation (
5).
The third and fourth terms are regularization terms. The third term is used to control
close to 0–1. It is important to avoid excessively high
values, which would render other data points ineffective. The fourth term is used to select half of all data points. These terms are shown in Equation (
6).
Combining all of the components, we obtain the loss function of DILOF as follows:
The gradient descent method is then used to obtain the optimal result as shown in Equation (
8).
In Equation (
8),
is the learning rate, i is the number of iteration, and
is a set of data points that have
as their
Kth-nearest neighbor in Z. Interested readers are referred to the DILOF paper [
6] for details on the calculation of
. After the decision variable has been updated, the larger half is selected as the summary point. Following this summarization phase, half of all data points are summarized into a quarter of all data points. This leaves a space equal to one quarter of the window size into which new data points can be inserted.
The DILOF method lacks a mechanism by which to remove outdated data or compensate for concept drift. NDS calculates only the difference in density in selection of a summary point. We therefore added the concept of time to differentiate outdated data points.
3. Proposed Method: TADILOF
In this section, we outline the proposed TADILOF algorithm and approximate LOF score. Algorithm 1 presents the pseudocode of the TADILOF algorithm. Our scheme also uses density to select the summary; therefore, we have two phases: detection and summarization. In the detection phase, we include a step in which previous information is used to obtain the approximate LOF, which is then used to determine whether the newly-added point is an outlier. This detection phase is referred to as ODA, outlier detection using approximate LOF. We add a time component to the summarization phase, and therefore refer to it as time-aware density summarization (TADS). We provide the details of procedures TADS and ODA in the following subsections. The approximate LOF score is calculated only when there is information from previous data points. Therefore, we introduce the time component before obtaining the approximate LOF score.
| Algorithm 1 TADILOF algorithm |
Input:
: A data stream ,
Window size: W,
Number of neighbor: K,
Threshold: ,
Step size: ,
Regularization constant: ,
Maximum number of iteration: I
Output: The set of outliers in streams
1: ;
2: ;
3: while a new data point is in stream do
4: .add()
5: = ODA(,,)
6: if then
7: .add()
8: if .length then
9: =TADS(,,,I)
10: end while |
3.1. Time Component
Addition of a time component to this type of task allows the model to distinguish old data from new, thereby making it possible to recognize concept drift over time. For example, daytime readings might not be explicitly differentiated from nighttime readings in the PM2.5 data, despite the fact that time of day plays an important role in PM2.5 concentrations. Another example is the degree to which purchasing behavior varies over time as a function of the strength of the economy. The addition of a time component also provides a mechanism by which to remove outdated data, which might otherwise compromise model performance.
In this study, we include a time component in the summarization phase. Basically, every data point is assigned a time indicator
referring to the point at which it was added to the streaming data. In other words, the time indicators describe the age of every data point. The difference between
and the current time point corresponds to the length of time that data point
has existed in the dataset. The objective is to discard outdated data and preserve newer data points, which are presumed to more closely approximate the current situation. TADILOF refreshes data points close to the current data point and updates the time indicator of points neighboring the new data point, as shown in the following equation. Fortunately, this does not incur additional calculations due to the fact that we have already identified the neighbors of the new data in the LOF process.
Refreshing the time indicator of each data point enables our loss function to select data points that fit the current concept. Thus, a new model can be used to select data points in accordance with the density as well as the concept(s) represented by the current data streams. When TADS is triggered to summarize previous data points, it calculates the time difference
between summarized time stamp
and the time stamp of data point
as follows:
In Equation (
10),
is a hyperparameter indicating the amount of time that must elapse before TADILOF designates data as outdated and removes them. For example,
means that any data point with a time difference of less than one quarter of the window size is less likely to be selected for removal by the objective function. We present TADS in the next subsection.
3.2. Time-Aware Density Summarization (TADS)
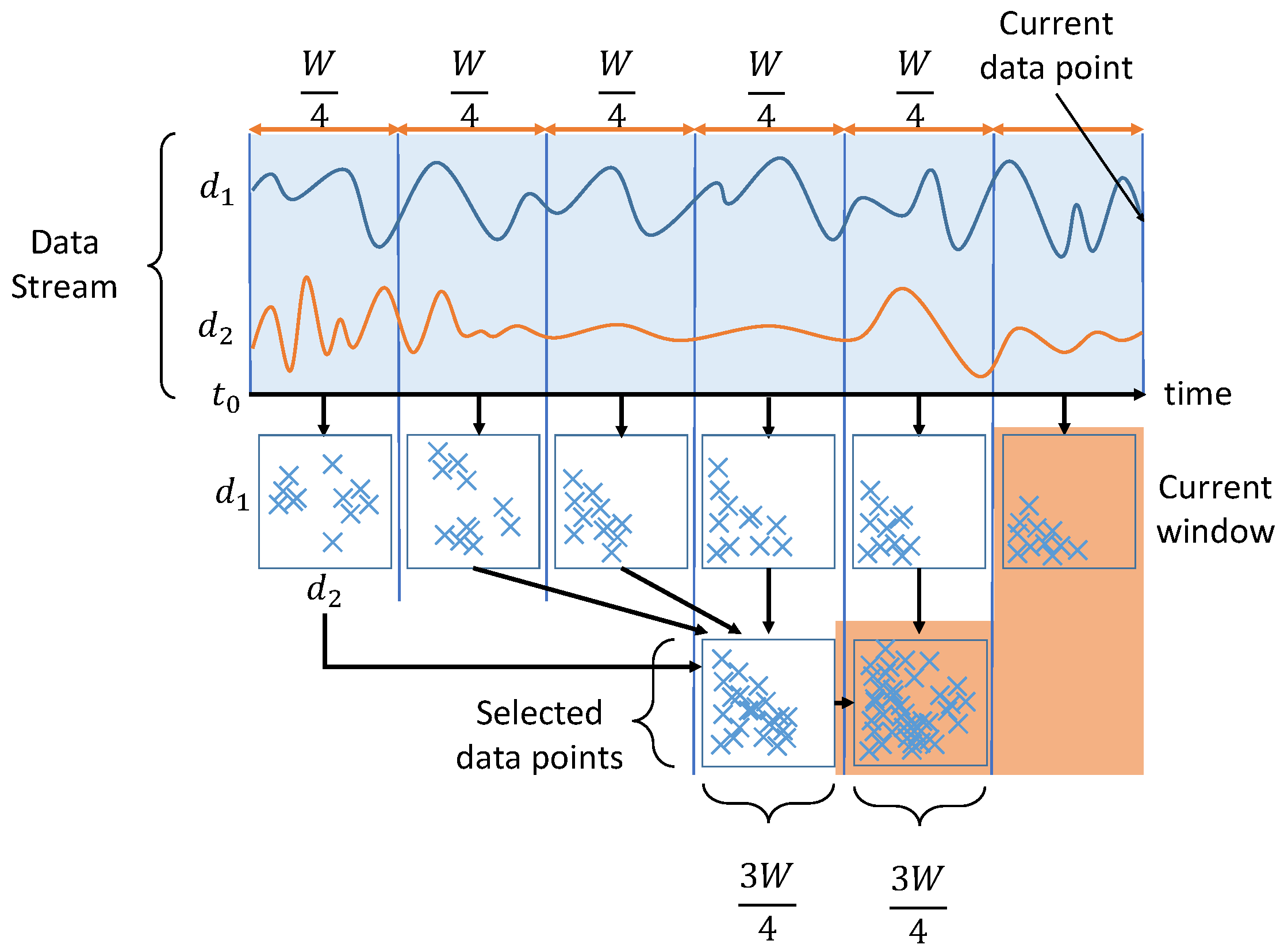
Figure 1 presents the proposed TADS (in the TADILOF algorithm), which differs from NDS (in the DILOF algorithm). Note that NDS always retains the most recent half window of data points and summarizes the older half within a quarter size window. By contrast, TADS summarizes data points from three quarters of the window, and does not necessarily retain only the latest data. Rather, the TADS mechanism considers the density and the age of the data points. The time term is added to the TADS loss function as follows:
The details of the TADS procedure are shown in Algorithm 2.
| Algorithm 2 Procedure TADS |
Input: set of data point in memory ,
Window size: W,
Step size: ,
Regularization constant: ,
Maximum number of iteration: I
Output: summary set
1: for each do
2: if then
3: update LOF,LRD and meanDistance
4: end for
5:
6: for each
do
7: y = 0.75
8: end for
9: for i = 1:I do
10:
11: for n = 1:W do
▹ Using objective function, calculate the score of each data point for selection in the summary set.
12:
13: end for
14: end for
15: Project Y into binary domain
16: for n=1: do
17:
18: end for
19: Return Z
|
3.3. LOF Score and ODA (Outlier Detection Using Approximate LOF)
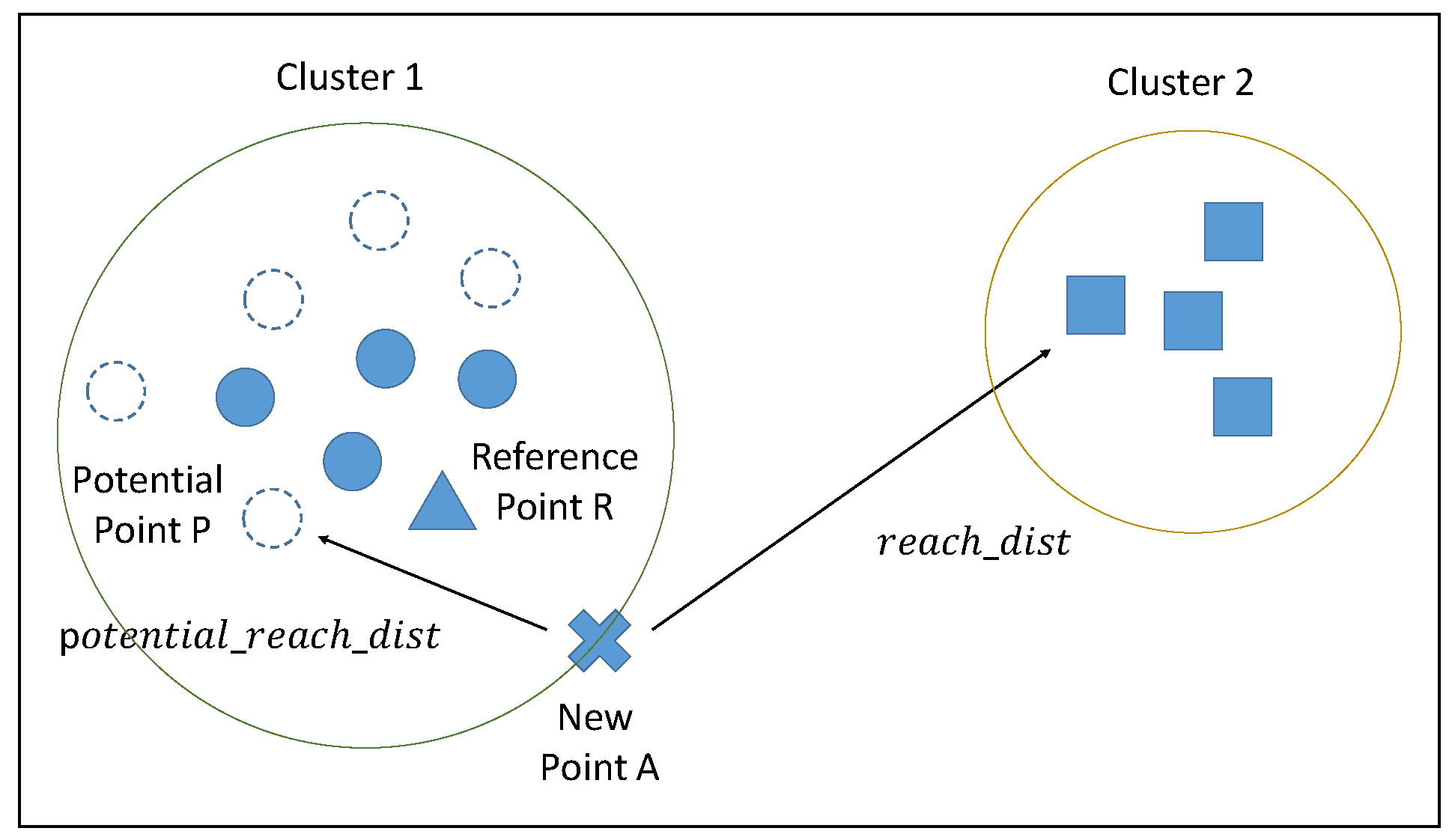
Limitations on memory capacity and computational power necessitate the elimination of some previous data points; however, setting an excessively small window size can degrade performance. Let us take an example shown in
Figure 2 with two local clusters from the data stream. The symbols in different shape do not represent different kind of data points in a data stream. We have just make different symbols to represent two different local clusters of data points from data stream in
Figure 2. In the example in
Figure 2, new point A sits very close to cluster 1, but some of the points in that cluster were deleted in the previous summarization phase, with the result that the new point is unable to find a sufficient number of neighbors in cluster 1. This means that LOF must be calculated using points from cluster 2, which could present the new point as an outlier. We sought to overcome this issue by calculating approximate LOF scores, which are then saved with the LRD and the mean distance between each point to neighbors in every summarization phase. This saved information can then be used to calculate the reachability of potential neighbors.
Assume that new point A is added to the dataset. If the calculated LOF exceeds the threshold, then the algorithm classifies it as an outlier. At the same time, historical information related to reference point R (a KNN neighbor of A) is used to find potential neighbor point P as a function of historical distance between R and its neighbors. Following the identification of the reference point R and its potential neighbor point P, the approximate LOF value is calculated to reassess whether the data point in question should be classified as an outlier or an inlier.
Calculation of the approximate LOF score requires preservation of some of the information in the previous window. In the summarization phase, the LOF score of any data point selected for inclusion in the first summary is retained as its historical LOF score. Note that its historical LRD and the mean distance to its neighbors are also preserved. For any data point selected for the initial and subsequent summarization, we compare the current LOF score with its historical LOF score. In cases where the current LOF score is lower, the associated information is updated. Note that a lower LOF score is indicative of the density typical of inliers.
Point A has K-nearest neighbors. Our aim is to identify the neighbor with the lowest product of historical LOF score and Euclidean distance between A and itself. That neighbor is then used as a reference point R by which to calculate the approximate LOF score of A.
We can use the historical LRD of R to obtain the mean reachability distance between R and P using the following equation:
Our objective is to identify potential neighbors of new point A. Even though the current state indicates that A is an outlier, it may in fact be an inlier if some of its neighbors avoided deletion in the previous few windows.
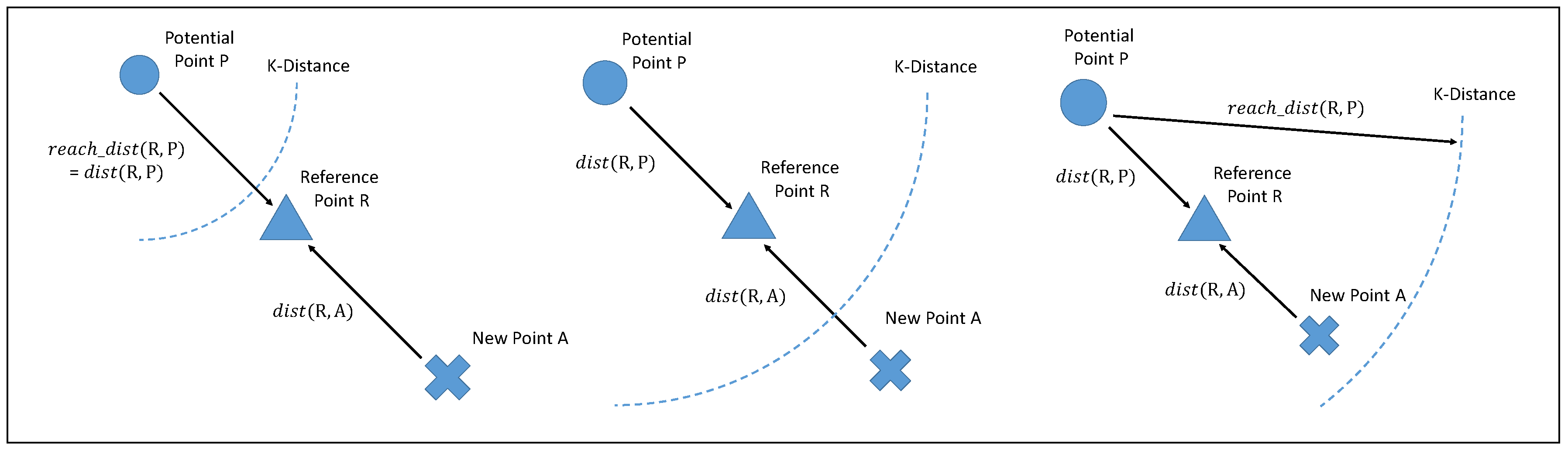
There are three scenarios in which new point A, reference point R, and potential neighbor P, which represents a deleted data point, could be distributed in ODA. In Definition 1 is used to represent the mean Euclidean distance between R and P. Using Definition 3, indicates the mean reachability distance between R and P. Before we discuss these three scenarios, it is necessary to discuss the distribution of potential neighbors. Potential neighbor P can be in any position, including the space between the reference point and the new point. It is infeasible to record all potential neighbor positions; therefore, we use the case where the potential neighbor is located at the greatest distance between the new data point and itself. We then use the mean distance between R and its historical neighbors and the mean reachability distance to calculate the approximate reachability distance between A and P.
In the first scenario (
Figure 3 left), reachability distance
is equal to Euclidean distance
, which is larger than
. In this scenario, ODA can use
to cast the mean approximate reachability distance between
A and
P. In the second scenario (
Figure 3 middle),
is larger than
but less than
. In this case, ODA can also use
to cast the mean approximate reachability distance between
A and
P. In the third scenario (
Figure 3 right),
is larger than
. In this case, ODA can use
to represent the mean approximate reachability distance
.
By assembling these, we can obtain the approximate mean reachability distance between point
P and
A using the following equation:
After obtaining the approximate mean reachability distance of point
A, we can calculate the approximate LRD of
A using Equation (
2) (Definition 4), based on the fact that LRD is the reciprocal of the mean reachability distance.
ODA then calculates the sum of LRD of
P using Definition 5, as follows:
The approximate reachability distance and average LRD of the potential neighbor are then used to compute the approximate LOF using Definition 5, as follows:
ODA can use this approximate LOF to determine whether A is an outlier or an inlier. The pseudocode of the ODA procedure is shown in Algorithm 3.
| Algorithm 3 Procedure of ODA |
Input:data point
set of data point in memory ,
threshold: ,
set of detected outlier:
Output: LOF score of
1: Using incremental LOF technique updates all reverse KNNs of
2: = All KNNs of
3: for each
do
4: updating time stamp of n
5: end for
6: Compute
7: if
then
8: Reference Point R=
9: Find the approximate reachability distance using Equation (12)
10: Find the approximate LRD of using Equation (13)
11: Use historical LRD of R and historical LOF of R to find mean of LRD of potential neighbors by Equation (14)
12: Find the approximate LOF of using Equation (15)
13: if approximate LOF of Threshold then
14: .add()
|
3.4. Time and Space Complexity
In DILOF [
6], the authors analyzed time complexity from the perspectives of summarization and detection separately. Note that time complexity of DILOF in the detection phase is
, whereas time complexity of DILOF in the summarization phase is
. The space complexity of DILOF algorithms is
, where
D is the dimensionality of the data points.
In the following, we discuss the detection phase of the proposed algorithm, TADILOF, in which we calculate the approximate value of the points classified as outliers by the LOF score. Let us assume that z is the number of points that are classified as outliers. In our proposed detection phase, is incurred in calculating the approximate LOF score for each point. Thus, indicates the time complexity in the detection phase. However, the number of neighbors K is far less than window size W. Therefore, the cost incurred in the detection phase is .
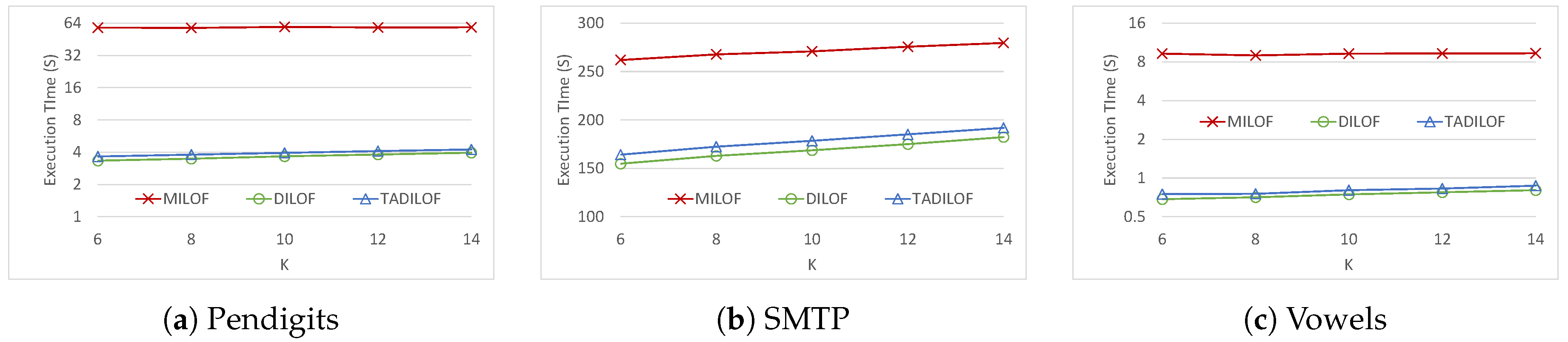
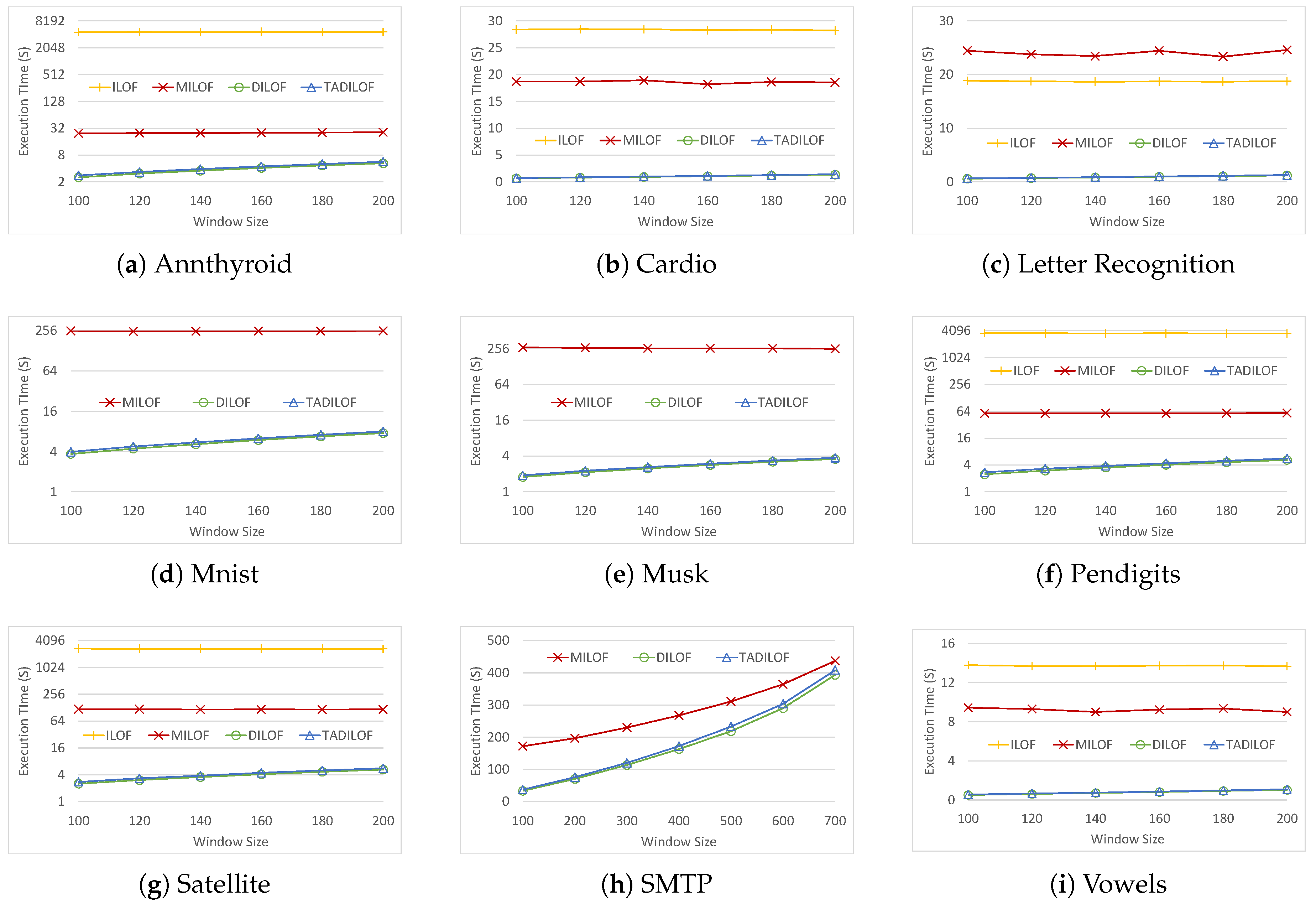
The time complexity of TADILOF in the summarization phase is . TADILOF tends to require more time than DILOF. However, the execution times in the experiments were still very close.
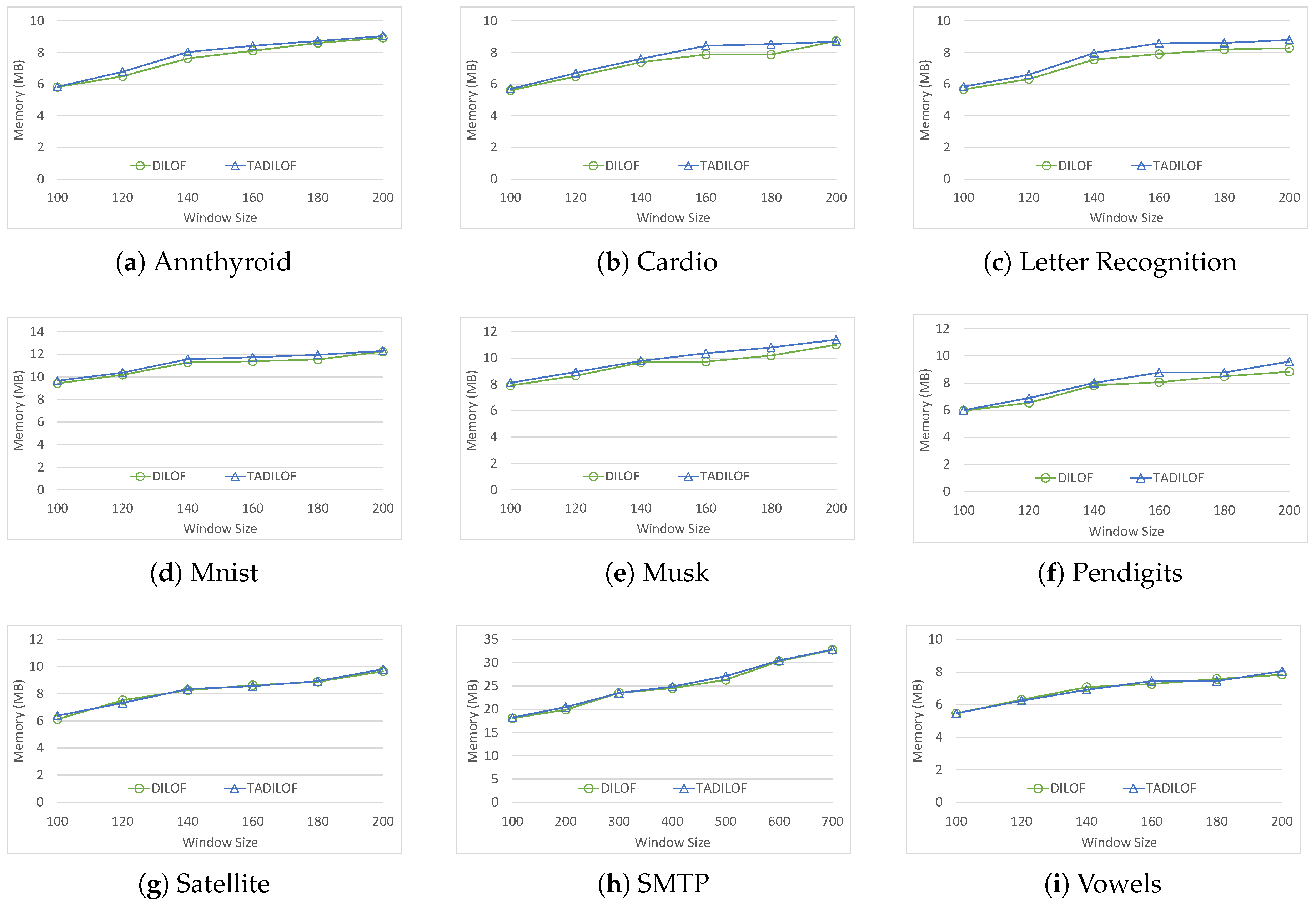
The additional space complexity associated with the proposed method includes the time indicator, historical LOF, historical LRD, and mean neighbor distance. Note that the size of the data in the summary is . Therefore, the total cost is . From this, we can see that the space complexity of TADILOF with approximate LOF is .
5. PM2.5 Sensors Case Study
In this section, we introduce the application of our proposed method that we used for monitoring air quality in Taiwan. There are several recent studies which have focused on air quality and PM2.5 forcasting [
29,
30,
31,
32], and anomaly detection in air quality [
33].
In an effort to control air pollution in Taiwan, low-cost devices have been developed for monitoring air quality. These devices are referred to as LASSs. The Taiwanese government has initiated a project in cooperation with Edimax for the wide-scale deployment of LASS in elementary schools, high schools, and universities. The LASS used in this project are referred to as AirBox devices. Our objective in this study was to enable the real-time monitoring of all 2000 AirBox devices simultaneously.
We deployed a system in Taiwan for the detection of outliers in a large-scale dataset from PM2.5 sensors. This system provided 2000 data streams from 2000 sensors transmitting reading data at intervals of 5 min. The proposed method was used to detect outliers in each of the streams, with a focus on temporal outliers to compensate for inter-device variation in terms of quality and sensitivity. Following the identification of temporal outliers, we combined the positions of the devices with meteorological data to facilitate the detection of pollution events.
In addition, we used precision PM2.5 stations which are provided by the Environmental Protection Administration (EPA), Taiwan, to predict air quality. We integrated the data from precision PM2.5 sensors provided by EPA, Taiwan, because the quality of the data from precision PM2.5 sensors is better. However, there are only 77 PM2.5 stations in Taiwan and they provide an average PM2.5 value every hour. In this situation, we cannot find small pollution events. Therefore, we used low cost but large-scale PM2.5 devices for detecting pollution events. There are some advantages to using those PM2.5 sensors. The first benefit is that we can monitor air quality of Taiwan by a fine resolution on space because the number of active devices is more than 2000 regarding those that are deployed in Taiwan. The second benefit is that their sampling rate is 5 min. Therefore, we can also have a fine resolution on time domain to monitor air quality of Taiwan.
After getting fine resolution data based on both time and space, the challenge is how to use those data to detect pollution events. There are three challenges of using those data to detect pollution events. The first one is those devices are low cost and there is lack of maintenance. In general case, those kind of sensors need device correction every few month, so that the reading number is more accurate. The second challenge is there are numerous devices, and each device has a very high sampling rate which is every 5 min. We can see one of these devices as a data stream, and hence there are 2000 data streams. Therefore, we need to handle this large amount of data streams. Our proposed method has the capability to not only find outliers on different devices but also to deal with large number of data streams which have the high sampling rate. Next, we introduce how our method finds the pollution events in the following subsection.
Monitoring a PM2.5 Pollution Event
In this section, we introduce how to use the proposed method to monitor PM2.5 pollution event. First, we define spatial neighbors of devices using average wind speed of Taiwan. According to Central Weather Bureau (CWB) of Taiwan, the average wind speed of Taiwan is 3.36 km/h. Therefore, we define neighbor distance to be 1.5 km, which means any two devices are neighbors if the distance between these two devices is less than 1.5 km.
Each device produces a data stream because every device samples the concentration of PM2.5 at interval of every five minutes and the number of data values is unbounded. We implemented our proposed method on each data stream. Thus, we can detect outliers on different devices separately. We call this type of outlier a temporal outlier because such outliers are compared with historical data points from the same device. If proposed method detects any temporal outlier on devices, we add the device to a set called outlier-event-pool and set an expire time as 30 min. In next 30 min, if we can find two neighbor devices in the outlier-event-pool for any device in the outlier-event-pool, we call this event a pollution event. Otherwise, it represents a spatial outlier of the device.
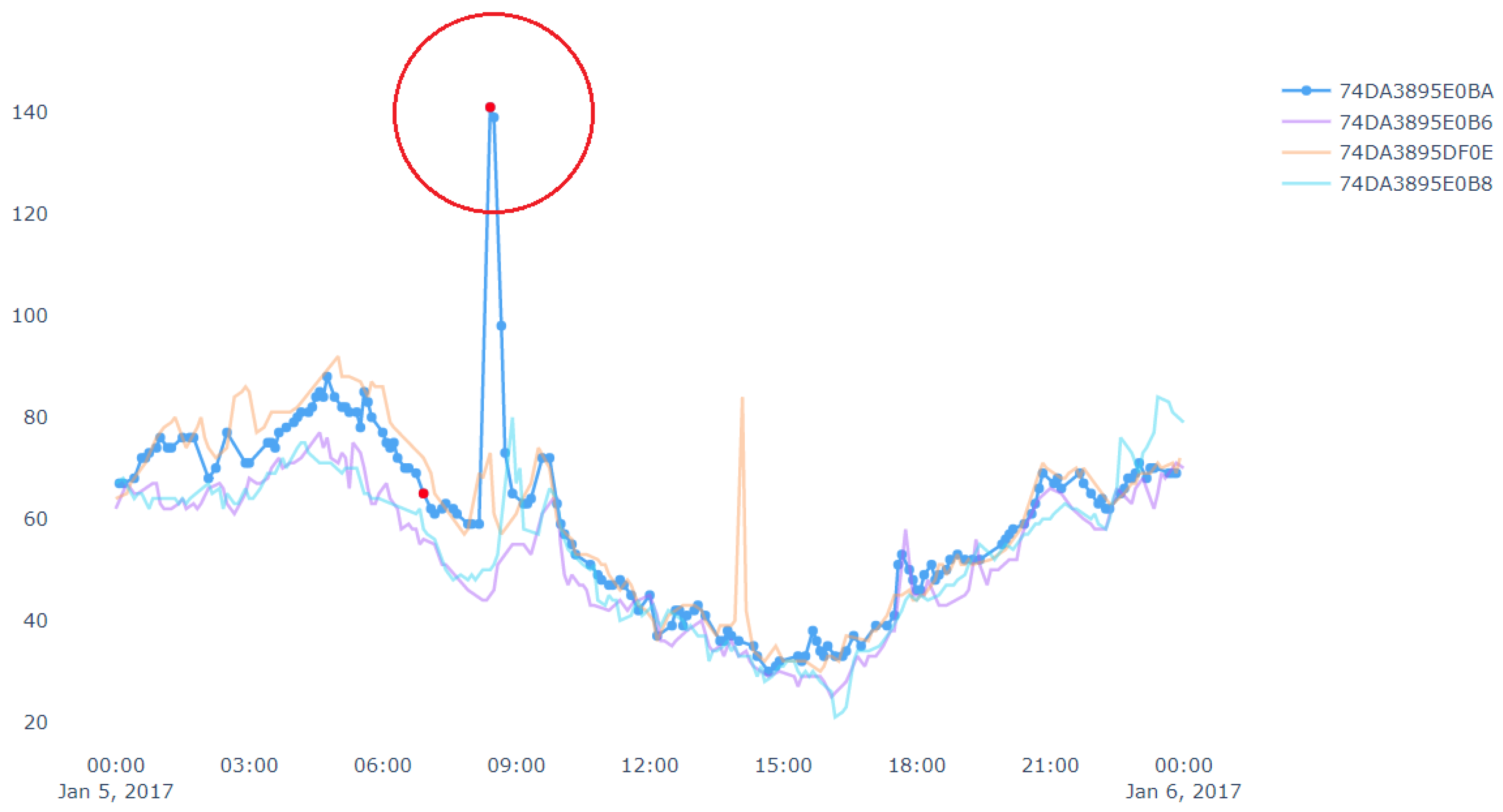
Figure 10 shows an example of spatial outlier. A spatial outlier means that there is only one device which has a sudden rise/fall in the measurement value and other nearby devices do not have any such change in the measurement. In
Figure 10, the data stream in blue represents a target device which shows outlier data points marked in red. Outliers from other data streams are not shown, i.e., not marked in red in this figure. Similarly,
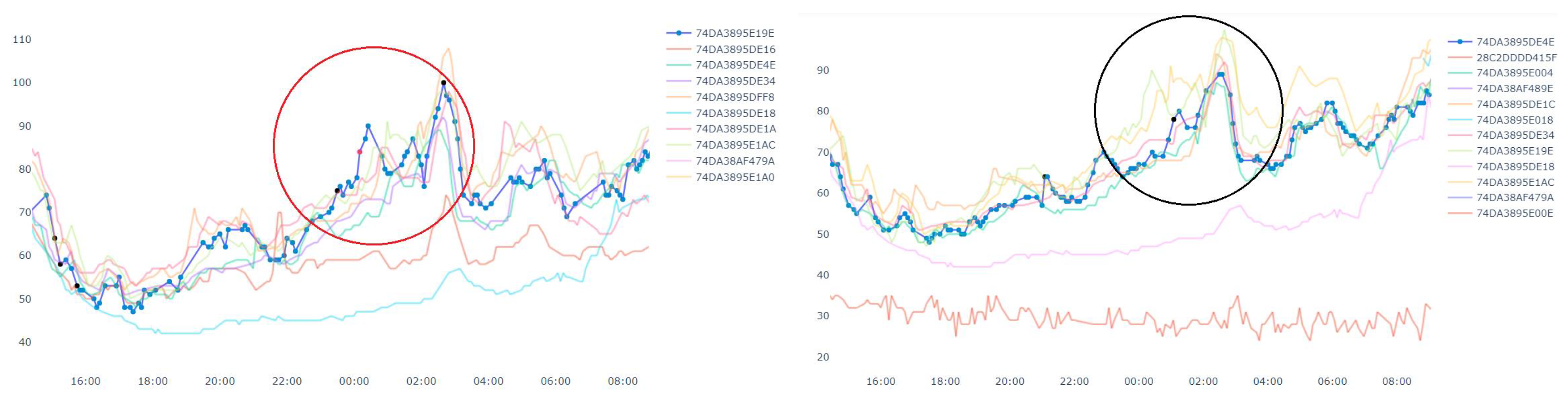
Figure 11 shows an example of pollution event. At the left side of the figure, the measurement value from a device has a sudden rise. Then the neighbor devices in the right side of the figure also has a rise in the measurement value in next few minutes. Since this event may have been started by nearby device shown in the left side of the figure. Thus, we can get the potential pollution event region.
Now, we discuss a use case related to a fire event, where we applied the proposed approach discussed above. In this case study, we targeted to track the pollution events where there is sudden increase in PM2.5 values. Our analysis targeted a fire event, which was reported at 17:51 2019/11/12 in Tainan city following reports of burning rubber. The Tainan EPB sent emergency notifications to Tainan citizens at 21:00. However, our system detected (and reports) the event at approximately 17:00.
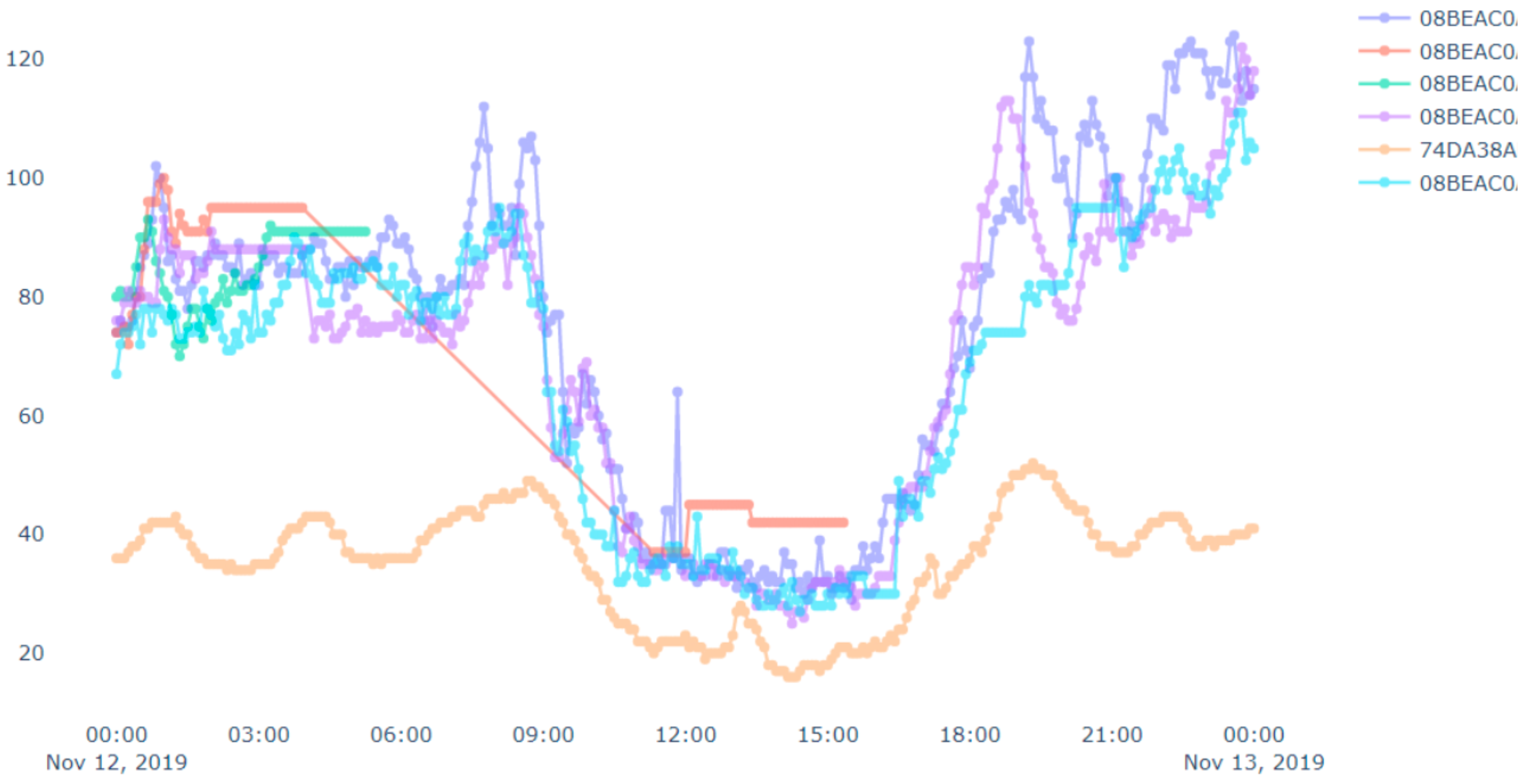
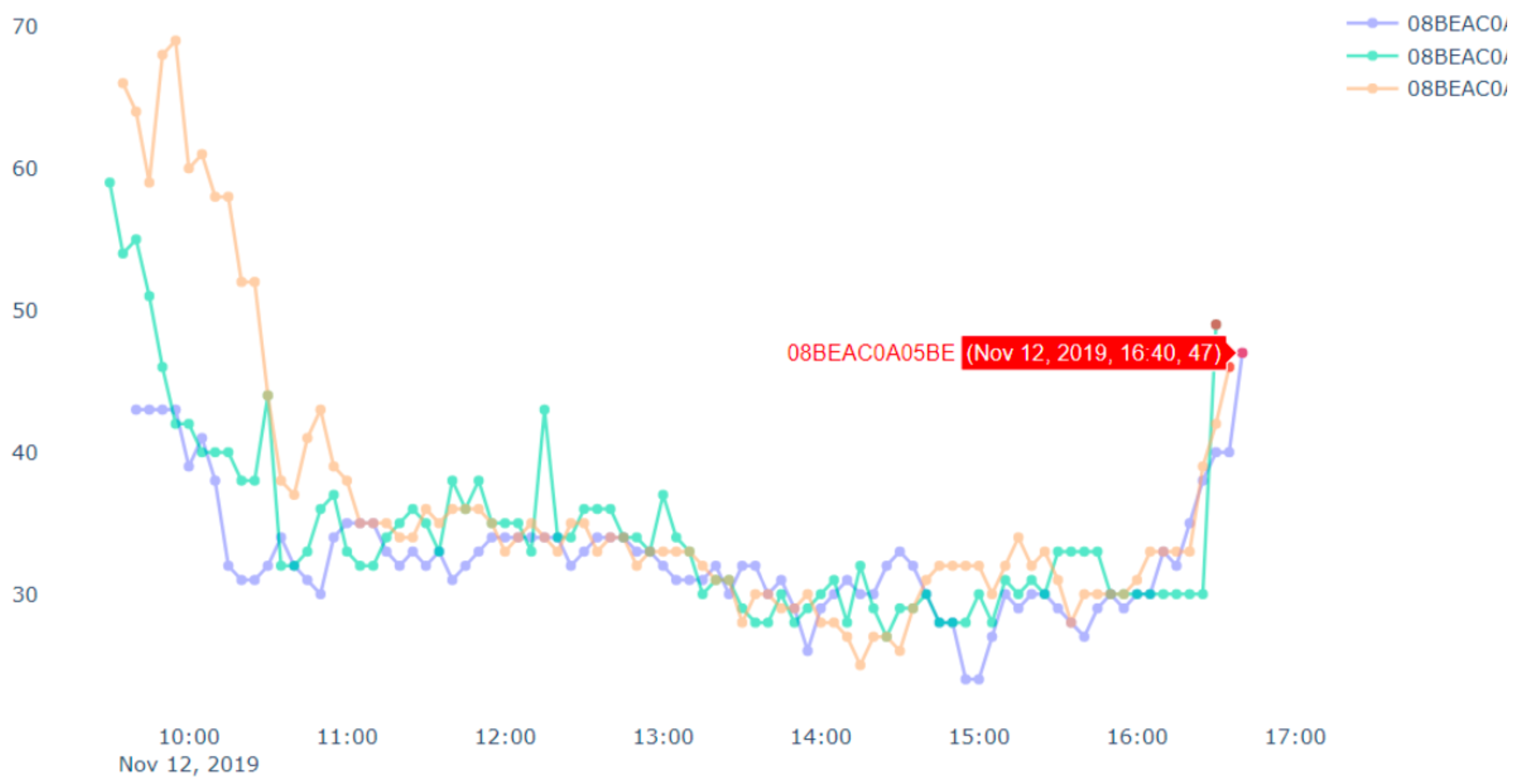
Figure 12 presents PM2.5 data for all devices in the vicinity of the fire throughout the day. We can see some flat lines in the readings. These are due to device malfunctions or reading errors (we have mentioned above about the issues related to the low-cost airbox devices). Similarly, we can see some bottom curves in
Figure 11 and
Figure 12. These are there because of the placements of the airbox devices. Some of the devices were placed indoors whereas other devices were placed outdoors. The indoor devices had a different environment (such as air conditioned room) than the outdoor devices, which affected the readings among different devices. Therefore, bottom curves are different from the others.
Figure 13 shows the result that our implemented system detects the pollution event (fire event). In
Figure 13, we can see that the proposed system sends the alert to subscribers at approximately 5 p.m.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}