3.1. Confirmatory Factor Analysis
Firstly, the factor loadings of the variables were computed.
Table 4 presents the results of this process for the dataset containing all factors (subset #1 in
Table 3). For conciseness purposes, only CFA factor loadings for this subset are presented in this paper; the complete data for all subsets are available in the
Supplementary Materials of this paper. By analyzing the results of the CFAs, we can observe that the factor loadings were strong (above 0.6), indicating a strong relationship between the variable and the factor in most variables, suggesting that the tool is a suitable representation of the underlying structure. Additionally, the
p-values indicate that the factor loadings are statistically significant. In this case, all factor loadings are highly significant (
p < 0.001) [
20]. Similar results were obtained for the loadings in the other datasets.
On the other hand, the results indicated a less-than-adequate fit for all datasets based on several fit indices. The χ
2 test was significant (
p-values < 0.001) for all datasets, indicating a statistically significant divergence between the hypothesized model (as indicated by the questionnaire) and the observed data. Recognizing the disadvantages of the χ
2 test, such as the sensitivity to sample size, with larger samples leading to smaller
p-values, we also used additional fit measures such as Tucker’s TLI [
21], SRMR [
22], and RMSEA [
23] (
Table 5). The values for the comparative fit index (CFI) [
24] ranged from 0.859 to 0.894, falling below the recommended threshold of ≥0.95 for good fit [
25]. The Tucker–Lewis index (TLI) also failed to reach adequacy across datasets, ranging from 0.845–0.884, with values not meeting the ≥0.95 threshold. The standardized root mean square residual (SRMR) fell within the recommended range of ≤0.08 for most of the models (0.0518–0.0757), indicating adequate absolute fit on this index only. However, the root mean square error of approximation (RMSEA) exceeded the recommended cutoff of ≤0.06 for a good fit [
26,
27], with values ranging from 0.0809 to 0.0896. The 90% confidence intervals for RMSEA also confirmed poor fitting across all datasets.
Taken together, these results show inadequate model fit, suggesting that the theoretical model did not fit the empirical data well. Modifications to the hypothesized model are needed to improve fit across datasets before the interpretation of the findings. This was evident in all subsets of data and in almost all goodness-of-fit measures studied. Although the cutoff criteria for CFA are not absolute [
27], the fact that there is almost total agreement between the indexes in all data subsets confirms this claim.
3.2. Exploratory Factor Analysis
The next stage was to perform a series of exploratory factor analyses (EFAs), comparing the factors present in the questionnaire structure with those extracted from the data extension. Two distinct approaches were employed to this end. The first method was to extract factors from the data extension without any constraint on the number of factors to be identified. The second method was to extract factors from the data extension, requesting that the variables within each analyzed subset be grouped to a number of factors equal to that of the subset being analyzed. These two analyses are presented in the following paragraphs.
As noted above, the first approach employed in this stage was to extract the dimensions of the questionnaire as derived from the data, performing a series of exploratory factor analyses (EFAs) without imposing any prerequisites concerning the grouping of the variables. All subsets of data were analyzed in the same way. Assuming that the resulting factors are correlated with each other, the promax rotation method in conjunction with the maximum likelihood extraction method was used. The expected factor structure, according to the questionnaire for the dataset with all dimensions, is shown in
Table 6 below.
The results of all analyses showed that, based on the eigenvalue criterion bigger than 1, the extracted factors were only two instead of three to six, as suggested in the questionnaire (Course, Supporting teaching, Assignments, Teaching staff, Lab, Self-assessment), with no particular conceptual similarity. An example from the subset of data that does not include support teaching, assignments, and labs is shown in
Table 7, where the expected structure based on the questionnaire is not confirmed. The same pattern is repeated in all datasets.
According to the literature, the Keiser criterion [
28] of eigenvalues greater than one is not absolute [
29]; eigenvalue limits less than one and between 0.5 and 0.8 were tested. In these cases, too, the expected number of dimensions was not obtained. Failure to identify a number of dimensions equal to what is expected in each dataset indicates that a mismatch exists between the intended conceptual model and the one that actually emerges in the data.
The second approach followed in this EFA was to perform a factor analysis with a specific number of factors, corresponding to the number of dimensions of the questionnaire for each subset of the data. It was found that the variables that, according to the questionnaire, corresponded to (i) the courses (var1 to var10) and (ii) the teaching staff (var22 to var28) were actually associated with one factor, in a quite distorted fashion compared to the original conceptual grouping of the questionnaire (an example is shown in
Table 8). In contrast, the questions related to students’ self-assessment (var33–var37) appeared to relate to the same factor, distinct from the one to which courses and teaching staff relate. Clustering other variables into dimensions was also found to be biased compared to the theoretical model.
The allocation of the courses and teaching staff to the same factor, combined with the specific number of factors to be extracted, has been also reported in other studies [
15,
16,
17,
18]. Overall, extracting the expected number of dimensions resulted in an unexpected structure for all data subsets, which was not expected.
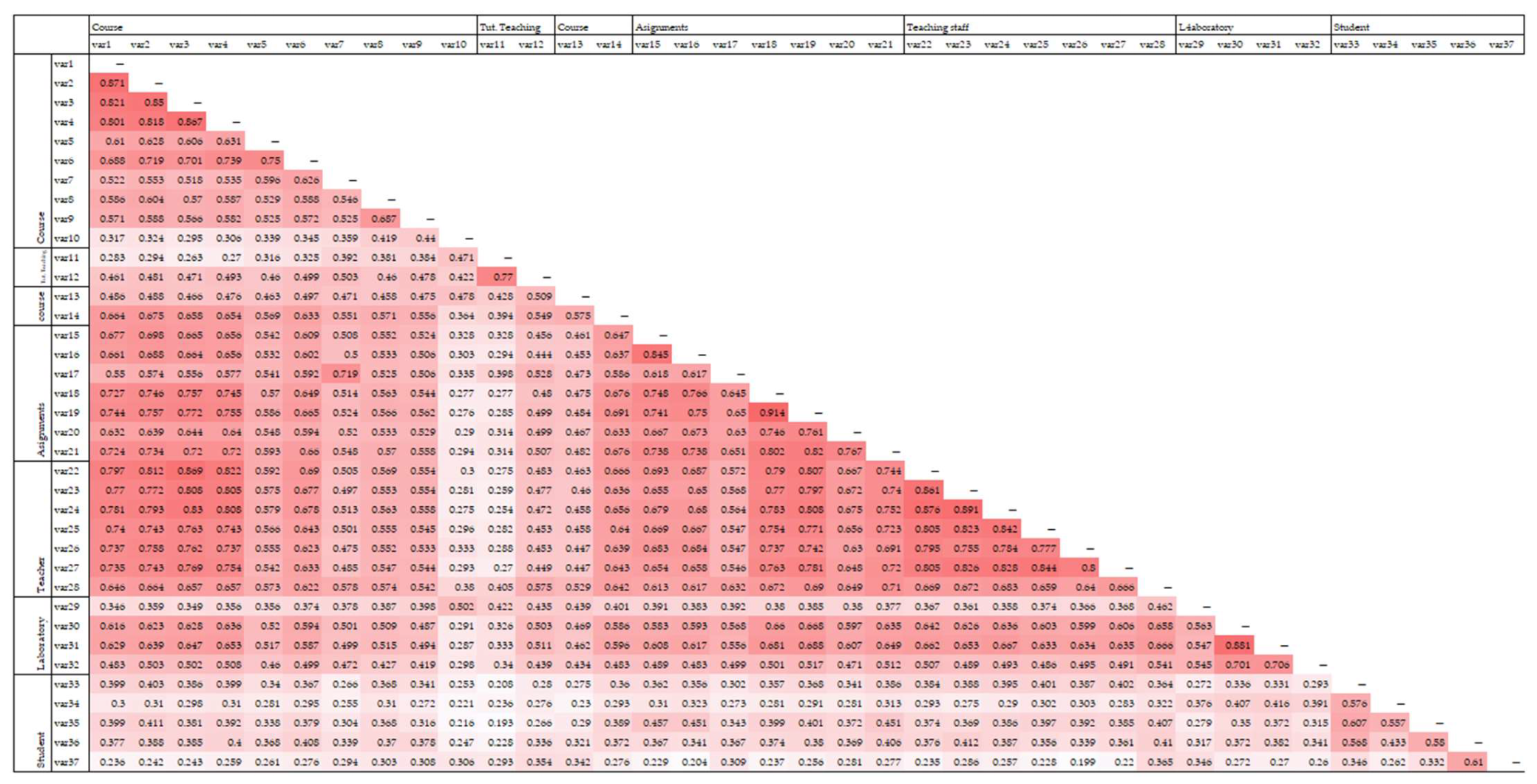
From a statistical perspective, the previous finding is associated with the high correlation coefficients between the variables related to the course (var1 to 5) and the teachers (var22 to 28), as shown in
Figure 1 with italics. In particular, data show moderate to strong average correlation coefficients within the factors’ statements in most cases. The coefficient of correlation between each factor’s questions is high, indicating that the questions meet the requirement of creating a factor. On the other hand, a strong correlation between factors’ statements was found, even if the requirement for a proper structure is a smaller correlation coefficient. The strongest average correlations were seen:
Between course factors and teaching staff factors (avg 0.76), leading to matching to a factor.
Between course and assignment factors (avg 0.67).
The high correlation between course and teaching staff factors is the root cause that led to a different factor structure than expected based on the under-study tool.
Correlations between supporting teaching and other factors are low or moderate, ranging from 0.19 to 0.57. Correlations between assignment and teaching staff factors are also strong, around 0.69, while the correlations between the assignment factor and the student factor are weak (avg 0.34). Teaching staff and laboratory factors show a moderate correlation of 0.53. Finally, student factors and other groups show low average correlations, ranging from 0.27 to 0.34. In summary, the strongest inter-factor correlations on average are seen between the factors of (i) course, (ii) teaching staff, and (iii) assignment. The weakest average correlations are between the student factor and the other factors.
The goodness-of-fit test indexes of EFAs with a specific number of factors indicate an acceptable or less than the good fit across all sub-datasets. The p-values for the χ2 test are all less than 0.0001, suggesting poor fit, but the χ2 test is affected by sample size. The corrected χ2 statistic based on the degrees of freedom shows an acceptable fit for “Lab-No AS/NT-TS” and a marginally acceptable fit for the “Lab-No AS/NT-Νο TS” subset.
Related to mean square error (RMSEA) values, we can observe that data subsets “Lab-AS/NT-TS” and “No Lab-AS/NT-TS” have the lowest values (0.711 and 0.741, respectively), while the “No Lab-AS/NT-No TS” data subset exhibits the highest value (0.0840). Considering that the RMSEA values of 0.05 and 0.08 correspond to “good fit” and “mediocre fit” [
20], we can conclude that the determined RMSEA indicates a model fit that is marginally acceptable to mediocre. The 90% confidence intervals of RMSEA are narrow, demonstrating precision around the point estimates, below the 0.1 threshold. The Tucker–Lewis index (TLI) values exceed 0.90 for the “Lab-No AS/NT-TS” and “No Lab-AS/NT-TS“ datasets, signifying a good fit relative to the conventional cutoffs. The values of TLI for the rest of the subsets are between 0.857 and 0.895, indicating an adequate fit.
Regarding comparisons between datasets, the “Lab-AS/NT-TS” model exhibits the best fit based on the combination of a low RMSEA value (0.0711) and a high TLI (0.917). The “No Lab-No AS/NT-No TS” dataset also shows a good fit (TLI 0.892, RMSEA 0.0772, RMSEA 90% CI (0.0734, 0.0812)). In contrast, the “Lab-No AS/NT-TS” dataset has a lower TLI (0.848) compared to alternatives. Overall, the results provide some support for an acceptable fit across the sub-datasets, with some variability across them. However, the resulting factor structure is different from the expected one.
Finally, variables were clustered based on the factor loadings determined by EFA, and this clustering was compared to the clustering expressed by the questionnaire structure using the adjusted rand score index [
30]. The computed adjusted rand score ranges from 0.2316 to 0.5128, indicating that the groupings observed in practice differ significantly from the theoretical ones.
The goodness-of-fit measures of exploratory factor analysis (EFA) without prerequisites of factors across the different datasets reveal varying degrees of model fit. The Root Mean Square Error of Approximation (RMSEA) generally suggests an acceptable-to-mediocre fit, with values ranging from approximately 0.0930 to 0.112; the Tucker–Lewis Index (TLI) values range from about 0.776 to 0.841, indicating an adequate fit for datasets. Despite significant chi-square (χ
2) values, likely influenced by large sample sizes, the χ
2/df ratios generally suggest a reasonable fit in some datasets, ranging from 3.83 to 152.23. Additionally, all datasets exhibit
p-values below 0.0001, indicating rejection of the null hypothesis of perfect fit. Overall, the EFA models show significant differences between observed and hypothesized structures. Also, the study of multiple fit indexes shows a moderate fit. Again, variables were clustered based on the factor loadings determined by EFA, and this clustering was compared to the clustering expressed by the questionnaire structure using the adjusted rand score index [
30]. The computed adjusted rand score ranges from 0.0549 to 0.3670 (
Table 9), indicating that the groupings observed in practice differ significantly from the theoretical ones. This range is lower than that observed when a specific number of outputs is requested to be extracted (
Table 10).







{kind=link}