
Two-Component Unit Weibull Mixture Model to Analyze Vote Proportions †

 , ,
, , 
Abstract
:1. Introduction
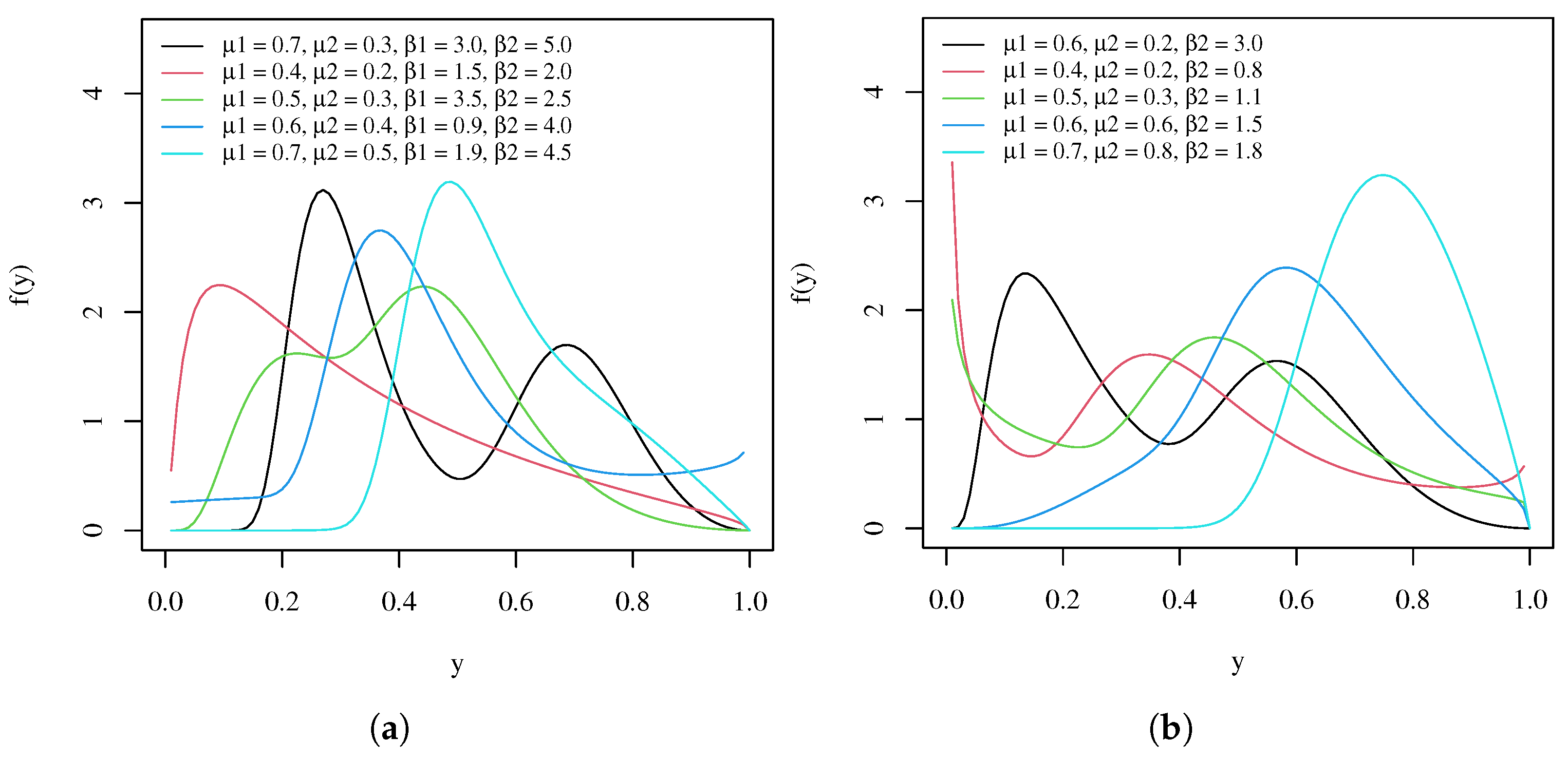
2. The Proposed Model
3. Parameter Estimation
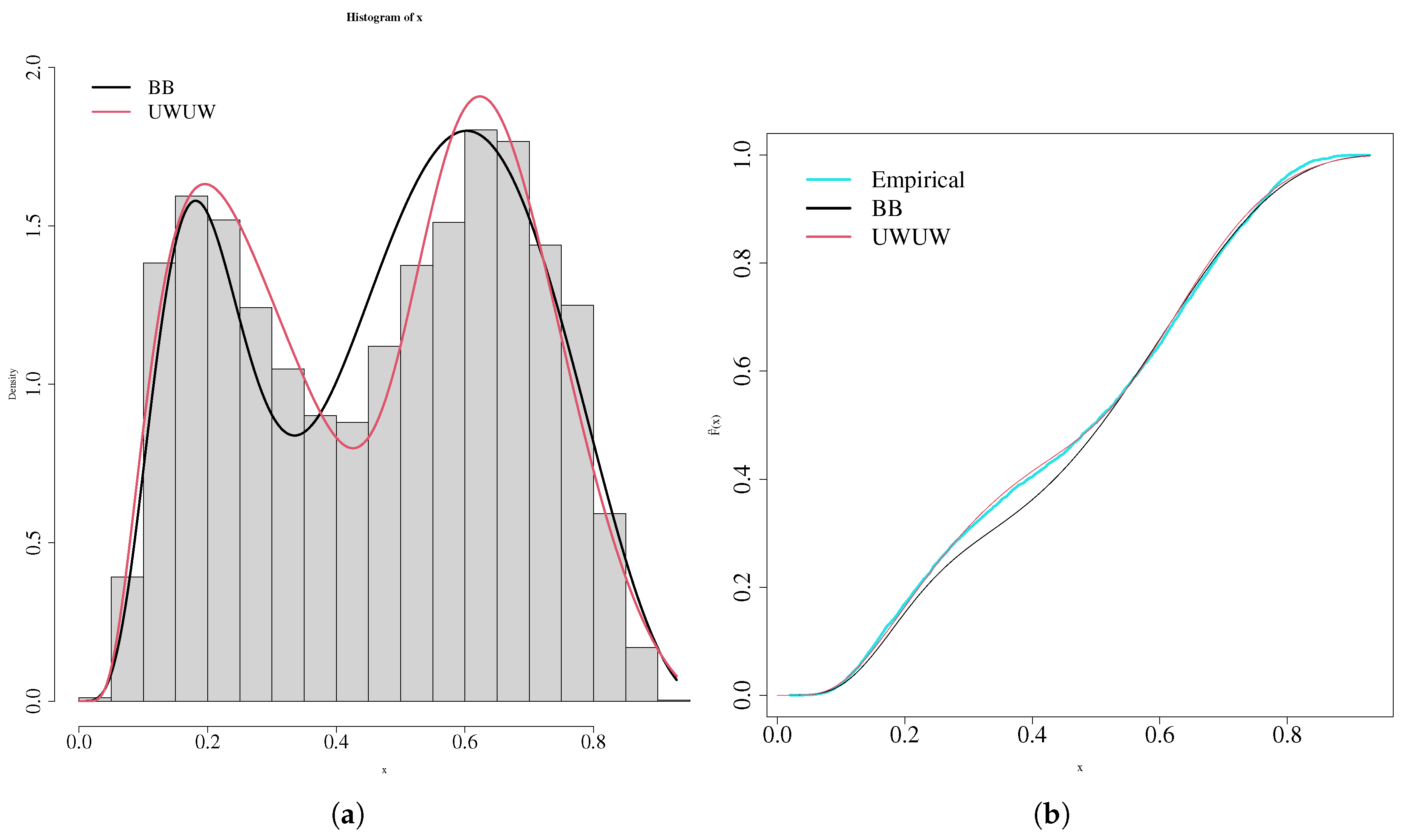
4. Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pearson, K. Contributions to the mathematical theory of evolution. Philos. Trans. R. Soc. Lond. A 1894, 185, 71–110. [Google Scholar]
- Lachos, V.H.; Moreno, E.J.L.; Chen, K.; Cabral, C.R.B. Finite mixture modeling of censored data using the multivariate Student-t distribution. J. Multivar. Anal. 2017, 159, 151–167. [Google Scholar] [CrossRef]
- Jewell, N.P. Mixtures of exponential distributions. Ann. Stat. 1982, 10, 479–484. [Google Scholar] [CrossRef]
- Jiang, R.; Murthy, D. Mixture of Weibull distributions-parametric characterization of failure rate function. Appl. Stoch. Model. Data Anal. 1998, 14, 47–65. [Google Scholar] [CrossRef]
- Bučar, T.; Nagode, M.; Fajdiga, M. Reliability approximation using finite Weibull mixture distributions. Reliab. Eng. Syst. Saf. 2004, 84, 241–251. [Google Scholar] [CrossRef]
- Huang, W.; Dong, S. Probability distribution of wave periods in combined sea states with finite mixture models. Appl. Ocean Res. 2019, 92, 101938. [Google Scholar] [CrossRef]
- Ji, Y.; Wu, C.; Liu, P.; Wang, J.; Coombes, K.R. Applications of beta-mixture models in bioinformatics. Bioinformatics 2005, 21, 2118–2122. [Google Scholar] [CrossRef]
- Bouguila, N.; Ziou, D.; Monga, E. Practical Bayesian estimation of a finite beta mixture through Gibbs sampling and its applications. Stat. Comput. 2006, 16, 215–225. [Google Scholar] [CrossRef]
- Grün, B.; Kosmidis, I.; Zeileis, A. Extended Beta Regression in R: Shaken, Stirred, Mixed, and Partitioned; Technical Report, Working Papers in Economics and Statistics; University of Innsbruck, Research Platform Empirical and Experimental Economics (EEECON): Innsbruck, Austria, 2011. [Google Scholar]
- Khalid, M.; Aslam, M.; Sindhu, T.N. Bayesian analysis of 3-components Kumaraswamy mixture model: Quadrature method vs. Importance sampling. Alex. Eng. J. 2020, 59, 2753–2763. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.; Ghitany, M. The unit-Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar]
- Redner, R.A.; Walker, H.F. Mixture densities, maximum likelihood and the EM algorithm. SIAM Rev. 1984, 26, 195–239. [Google Scholar] [CrossRef]
- Alemán, E.; Kellam, M. The nationalization of presidential elections in the Americas. Elect. Stud. 2017, 47, 125–135. [Google Scholar] [CrossRef]
- Powell, E.N.; Tucker, J.A. Revisiting electoral volatility in post-communist countries: New data, new results and new approaches. Br. J. Political Sci. 2013, 44, 123–147. [Google Scholar] [CrossRef]
- Bayes, C.L.; Bazán, J.L.; De Castro, M. A quantile parametric mixed regression model for bounded response variables. Stat. Its Interface 2017, 10, 483–493. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes 3rd Edition: The Art of Scientific Computing; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Ferrari, S.L.P.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 7, 799–815. [Google Scholar] [CrossRef]
- Chen, G.; Balakrishnan, N. A general purpose approximate goodness-of-fit test. J. Qual. Technol. 1995, 27, 154–161. [Google Scholar] [CrossRef]
- Durbin, J.; Knott, M. Components of Cramér-Von Mises statistics. J. R. Stat. Soc. Ser. B (Methodol.) 1972, 34, 290–307. [Google Scholar] [CrossRef]
- Goodman, L.A. Kolmogorov-Smirnov tests for psychological research. Psychol. Bull. 1954, 51, 160–168. [Google Scholar] [CrossRef]
- Marinho, P.R.D.; Silva, R.B.; Bourguignon, M.; Cordeiro, G.M.; Nadarajah, S. AdequacyModel: An R package for probability distributions and general purpose optimization. PLoS ONE 2019, 14, e0221487. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| 0.5816 | 0.1985 | 9.7510 | 29.3260 | 0.7268 | 1.2937 | 7.4584 | 0.0477 | |
| (0.0035) | (0.0026) | (0.3201) | (1.3521) | - | ||||
| 0.2677 | 0.6491 | 2.7011 | 2.9611 | 0.5368 | 0.4119 | 3.6768 | 0.0153 | |
| (0.0039) | (0.0027) | (0.0545) | (0.0567) | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guerra, R.R.; Peña-Ramírez, F.A.; Mafalda, C.P.; Cordeiro, G.M. Two-Component Unit Weibull Mixture Model to Analyze Vote Proportions. Comput. Sci. Math. Forum 2023, 7, 45. https://doi.org/10.3390/IOCMA2023-14550
Guerra RR, Peña-Ramírez FA, Mafalda CP, Cordeiro GM. Two-Component Unit Weibull Mixture Model to Analyze Vote Proportions. Computer Sciences & Mathematics Forum. 2023; 7(1):45. https://doi.org/10.3390/IOCMA2023-14550
Chicago/Turabian StyleGuerra, Renata Rojas, Fernando A. Peña-Ramírez, Charles P. Mafalda, and Gauss Moutinho Cordeiro. 2023. "Two-Component Unit Weibull Mixture Model to Analyze Vote Proportions" Computer Sciences & Mathematics Forum 7, no. 1: 45. https://doi.org/10.3390/IOCMA2023-14550
APA StyleGuerra, R. R., Peña-Ramírez, F. A., Mafalda, C. P., & Cordeiro, G. M. (2023). Two-Component Unit Weibull Mixture Model to Analyze Vote Proportions. Computer Sciences & Mathematics Forum, 7(1), 45. https://doi.org/10.3390/IOCMA2023-14550