Abstract
The number of software failures, software reliability, and failure rates can be measured and predicted by the software reliability growth model (SRGM). SRGM is developed and tested in a controlled environment where the operating environment is different. Many SRGMs have developed, assuming that the working and developing environments are the same. In this paper, we have developed a new SRGM incorporating the imperfect debugging and testing coverage function. The proposed model’s parameters are estimated from two real datasets and compared with some existing SRGMs based on five goodness-of-fit criteria. The results show that the proposed model gives better descriptive and predictive performance than the existing selected models.
1. Introduction
During the past four decades, various software reliability growth models (SRGM) [1,2,3,4,5,6,7] have been proposed to estimate reliability, predict the number of faults, determine the release time of the software, etc. Various proposed models have been developed based on different suppositions. For example, some models have discussed perfect debugging [1,7], and others have discussed imperfect debugging [3,4]. Some researchers have studied SRGM by considering a constant fault detection rate [1] or by the learning phenomenon [7]. During the testing and debugging process, various research papers have discussed resource allocation [8,9,10,11,12], testing effort [13,14], etc.
Most models have considered that the operating and testing environments are the same. In general, the software is implemented in the real working environment after the in-house testing process. In early 2000, researchers proposed different SRGMs incorporating uncertainty of the operating environment with new approaches. Teng and Pham [15] proposed a generalized SRGM considering the effects of the uncertainty of the working environment on software failure rate. Pham [6,16] presented an SRGM incorporating Vtub-shaped and Loglog fault detection rates subject to random environments, respectively. Li and Pham [17] discussed an SRGM where fault removal efficiency and error generation are incorporated together with the uncertainty of the operating environment. Li et al. [18] proposed a generalized SRGM incorporating the uncertainty of the operating environment.
This paper presents an SRGM incorporating imperfect debugging and testing coverage functions under the effects of a random field environment. The above discussed model [6,15,16,17,18] have assumed that the random variable follows Gamma distribution. In our model, we have assumed exponential distribution instead of the gamma distribution to keep less number of parameters in the model. We have validated the goodness-of-fit and predictability of the proposed model on two datasets. The remaining part of the paper is as follows. In Section 2, the explicit solution of the mean value function is derived. Numerical and data analysis is performed in Section 3. In Section 4, we summarize the paper’s conclusions.
2. Software Reliability Growth Model
The cumulative number of detected software faults follows non-homogeneous Poisson process (NHPP) and express as follows
The mean value function for the fault counting process is represented in terms of intensity function as
The following assumptions are taken for the proposed model:
- The software fault detection follows the non-homogeneous Poisson process.
- Fault detection rate is proportional to the remaining faults in the software.
- After fault detection, the debugging process takes place immediately.
- During the testing process, new faults are introduced into the software.
- The testing coverage rate function is incorporated as the fault detection rate function.
- Random testing environment affects the fault detection rate.
Considering the above assumptions, the SRGM, with the uncertainty of the operating environment, is
where is random variable, is the testing coverage function, is the total fault present in the software at time t and is cumulative number of software failure at time t.
Initially the software has N number of faults. During debugging phase new faults are introduced at a rate d. Therefore, the fault content function is
The general solution for the MVF is given by
In order to find the mean value function , we have assume that, the random variable follows Exponential distribution, i.e., and the probability density function of is given by
An application of Laplace transformation of Equation (5) using Exponential distribution for random variable , the mean value function is given by:
In this paper, we have considered the following testing coverage rate function as follows:
After substituting in Equation (8), we obtained the following closed form of the solution of the mean value function as:
Table 1 summarizes the MVF of the proposed model and other selected models, which are taken for comparison.

Table 1.
Summary of SRGM.
3. Numerical and Data Analysis
3.1. Software Failure Data
The first dataset (DS-I) discussed in this paper is collected from the online IBM entry software package [2]. During the testing process of 21 weeks, 46 failures are observed. The second dataset (DS-II) is presented and collected from testing system at AT&T [23]. The system takes a total of 14 weeks to perform testing. As a result, 22 number of faults are experienced during the testing weeks.
3.2. Parameter Estimation and Goodness-of-Fit Criteria
Usually, the parameters of the SRGMs are estimated using the least square estimation (LSE) or maximum likelihood estimation (MLE) methods. We have used the least square estimation method to estimate the parameters of the proposed model and the parameter estimation is shown in Table 2.
Table 2.
Parameter estimation for DS-I [2] and DS-II [23].
Several goodness-of-fit criteria are available to predict the best-fit model in the literature. Out of those, the standard criteria used to compare with the existing selected model are mean-squared error (MSE), predictive ratio risk (PRR), bias, variance, and root mean square prediction error (RMSPE). The smaller value of all goodness-of-fit criteria gives a better fit of the model.
The MSE measures the average of the deviation between the predicted values with the actual data [24] and is represented as
where n is the number of observations in the model.
The predictive ratio risk (PRR) gives the distance between the model estimates and actual data against the actual data and is defined as [25]
The bias is defined as the sum of the deviation of the model estimates testing curve from the actual data as [26]:
The variance is defined as [27]:
The root mean square prediction error (RMSPE) is defined as [27]
where is the predict fault at time and is the observed fault at time .
3.3. Model Comparison for DS-I
Table 3 shows that the proposed model performs better regarding MSE, PRR, Bias, Variance, and RMSE criteria. The value of MSE, PRR, Bias, Variance, and RMSE of the proposed model are −0.04598, 1.105182 and 1.106138, respectively, which is significantly smaller than the value of the other selected software reliability models. Figure 1a compared the proposed and existing models chosen with observed failure data. Figure 1b shows the relative errors of the proposed model in terms of the test week, which approach to zero compared to the other models. Overall, the proposed model is better than other selected existing models.
Table 3.
Comparison criteria for DS-I.
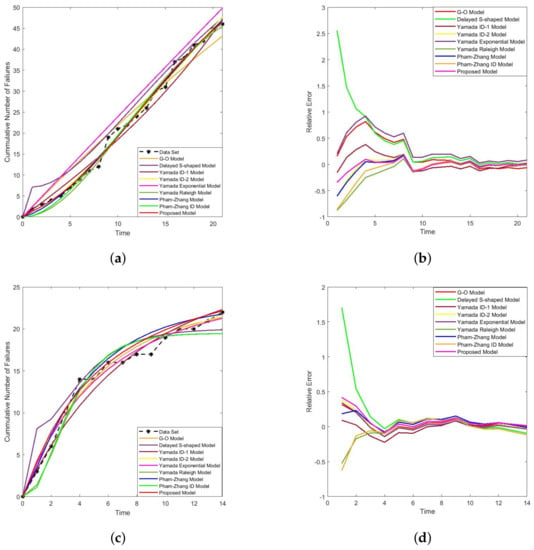
Figure 1.
(a) Estimated MVFs for different selected and proposed model (DS-I). (b) Relative errors curve for different selected and proposed model (DS-I). (c) Estimated MVFs for different selected and proposed model (DS-II). (d) Relative errors curve for different selected and proposed model (DS-II).
3.4. Model Comparison for DS-II
The proposed model’s performance using LSE is evaluated in terms of MSE, PRR, Bias, Variance, and RMSE and shown in Table 4. From Table 4, we observe that the proposed models have the least value of MSE (), PRR (), Bias (), Variance (), and RMSE () than the other models. The comparison between the proposed and selected model’s MVF is depicted in Figure 1c. Figure 1d shows the relative errors for different models and approaches rapidly to zero compared to other selected models. Overall, the proposed model also fits the DS-II better.
Table 4.
Comparison criteria for DS-II.
4. Conclusions
Many SRGMs have been proposed on different realistic issues. This paper has incorporated imperfect debugging and the testing coverage rate function in the model. All the models discussed in Section 1 assumed that the uncertainty of the operating environment follows the gamma distribution. The main contribution of the model is implementing a random variable, which follows an exponential distribution. However, it is a special case of the gamma distribution and keeps fewer parameters in the model. The proposed model’s parameter is estimated using two datasets and validated over five goodness-of-fit criteria. The results show that the proposed model fits better than other selected models. In the future, we will incorporate multi-release and change-point concepts.
Author Contributions
Conceptualization, S.K.P., A.K. and V.K.; methodology, S.K.P., A.K. and V.K.; formal analysis, S.K.P.; validation, S.K.P.; writing original draft, S.K.P.; writing-review and editing, S.K.P., A.K. and V.K. All authors have read and agreed to the published version of the manuscript.
Funding
The authors did not receive any funding from any organizations.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
We confirm that the data supporting the findings of this study are cited and available within the article.
Conflicts of Interest
The authors declare that they have no conflict of interest.
References
- Goel, A.L.; Okumoto, K. Time-dependent error-detection rate model for software reliability and other performance measures. IEEE Trans. Reliab. 1979, 28, 206–211. [Google Scholar] [CrossRef]
- Ohba, M. Software reliability analysis models. IBM J. Res. Dev. 1984, 28, 428–443. [Google Scholar] [CrossRef]
- Yamada, S.; Tokuno, K.; Osaki, S. Imperfect debugging models with fault introduction rate for software reliability assessment. Int. J. Syst. Sci. 1992, 23, 2241–2252. [Google Scholar] [CrossRef]
- Pham, H. An imperfect-debugging fault-detection dependent-parameter software. Int. J. Autom. Comput. 2007, 4, 325. [Google Scholar] [CrossRef]
- Pham, H. A software cost model with imperfect debugging, random life cycle and penalty cost. Int. J. Syst. Sci. 1996, 27, 455–463. [Google Scholar] [CrossRef]
- Pham, H. Loglog fault-detection rate and testing coverage software reliability models subject to random environments. Vietnam. J. Comput. Sci. 2014, 1, 39–45. [Google Scholar] [CrossRef]
- Yamada, S.; Ohba, M.; Osaki, S. S-shaped reliability growth modeling for software error detection. IEEE Trans. Reliab. 1983, 32, 475–484. [Google Scholar] [CrossRef]
- Pradhan, S.K.; Kumar, A.; Kumar, V. An Optimal Resource Allocation Model Considering Two-Phase Software Reliability Growth Model with Testing Effort and Imperfect Debugging. Reliab. Theory Appl. 2021, 16, 241–255. [Google Scholar]
- Pradhan, S.K.; Kumar, A.; Kumar, V. An Effort Allocation Model for a Three Stage Software Reliability Growth Model. In Predictive Analytics in System Reliability; Springer: Cham, Switzerland, 2023; pp. 263–282. [Google Scholar]
- Pradhan, S.K.; Kumar, A.; Kumar, V. An optimal software enhancement and customer growth model: A control-theoretic approach. Int. J. Qual. Reliab. Manag. 2023. [Google Scholar] [CrossRef]
- Kumar, V.; Sahni, R. Dynamic testing resource allocation modeling for multi-release software using optimal control theory and genetic algorithm. Int. J. Qual. Reliab. Manag. 2020, 37, 1049–1069. [Google Scholar] [CrossRef]
- Kumar, V.; Kapur, P.K.; Taneja, N.; Sahni, R. On allocation of resources during testing phase incorporating flexible software reliability growth model with testing effort under dynamic environment. Int. J. Oper. Res. 2017, 30, 523–539. [Google Scholar] [CrossRef]
- Kapur, P.; Goswami, D.; Bardhan, A. A general software reliability growth model with testing effort dependent learning process. Int. J. Model. Simul. 2007, 27, 340–346. [Google Scholar] [CrossRef]
- Samal, U.; Kushwaha, S.; Kumar, A. A Testing-Effort Based Srgm Incorporating Imperfect Debugging and Change Point. Reliab. Theory Appl. 2023, 18, 86–93. [Google Scholar]
- Teng, X.; Pham, H. A new methodology for predicting software reliability in the random field environments. IEEE Trans. Reliab. 2006, 55, 458–468. [Google Scholar] [CrossRef]
- Pham, H. A new software reliability model with Vtub-shaped fault-detection rate and the uncertainty of operating environments. Optimization 2014, 63, 1481–1490. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. NHPP software reliability model considering the uncertainty of operating environments with imperfect debugging and testing coverage. Appl. Math. Model. 2017, 51, 68–85. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. A generalized software reliability growth model with consideration of the uncertainty of operating environments. IEEE Access 2019, 7, 84253–84267. [Google Scholar] [CrossRef]
- Yamada, Shigeru; Ohba, Mitsuru and Osaki, Shunji S-shaped software reliability growth models and their applications. IEEE Trans. Reliab. 1984, 33, 289–292.
- Yamada, S.; Ohtera, H.; Narihisa, H. Software reliability growth models with testing-effort. IEEE Trans. Reliab. 1986, 35, 19–23. [Google Scholar] [CrossRef]
- Pham, H.; Zhang, X. An NHPP software reliability model and its comparison. Int. J. Reliab. Qual. Saf. Eng. 1997, 4, 269–282. [Google Scholar] [CrossRef]
- Pham, H. System Software Reliability; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Ehrlich, W.; Prasanna, B.; Stampfel, J.; Wu, J. Determining the cost of a stop-test decision (software reliability). IEEE Softw. 1993, 10, 33–42. [Google Scholar] [CrossRef]
- Kapur, P.; Goswami, D.; Bardhan, A.; Singh, O. Flexible software reliability growth model with testing effort dependent learning process. Appl. Math. Model. 2008, 32, 1298–1307. [Google Scholar] [CrossRef]
- Pham, H.; Deng, C. Predictive-ratio risk criterion for selecting software reliability models. In Proceedings of the 9th International Conference on Reliability and Quality in Design, Waikiki, HI, USA, 6–8 August 2003; pp. 17–21. [Google Scholar]
- Pillai, K.; Nair, V.S. A model for software development effort and cost estimation. IEEE Trans. Softw. Eng. 1997, 23, 485–497. [Google Scholar] [CrossRef]
- Kapur, P.; Pham, H.; Anand, S.; Yadav, K. A unified approach for developing software reliability growth models in the presence of imperfect debugging and error generation. IEEE Trans. Reliab. 2011, 60, 331–340. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).