Owing to the recent success of pretrained models in information extraction tasks, we adopted these models for salient fact extraction. We first describe how we modelled salient fact extraction as a sentence classification task over pretrained models. We describe technical challenges unique to this task. We then describe two methods, representation enrichment and label propagation, to address these challenges.
3.1. Pretrained Model and Fine Tuning
The goal of a supervised-learning model for salient fact extraction tasks is to predict the correct label for an unseen review sentence: 1 if the sentence is salient, and 0 otherwise. The model is trained using a set of labeled text instances , where t is a sentence and l is a binary label. By seeing a number of training instances, the model learns to discriminate between positive and negative instances. However, supervised learning is sensitive to the coverage of salient sentences in the review corpus. It can yield suboptimal models when faced with imbalanced datasets.
Pretrained models, on the other hand, tend to be more robust to such imbalances and generalize better. These models project a text instance t into a high-dimensional vector (e.g., 768 in BERT), such that text instances sharing similar words or synonyms have similar vectors. Since predictions are based on dense-vector representations, they can predict the same label for semantically equivalent instances (e.g., cafe and coffee) without having seen them explicitly during training. As a result, pretrained models require far fewer salient sentences than supervised models trained from scratch do.
Despite their better generalizability, pretrained models struggle to make correct predictions for sentences with unseen attributes or quantities if their synonyms didn’t appear in the training set. As a result, a training set should contain as many infrequent attributes and quantitative descriptions as possible for optimal performance of pretrained models. However, due to the inherent scarcity of infrequent attributes and quantitative descriptions, the models can only see a limited amount of salient facts (and thus infrequent attributes and quantities) during training. We propose representation enrichment and label propagation methods to address these challenges. We next describe these methods in more detail.
3.2. Representation Enrichment
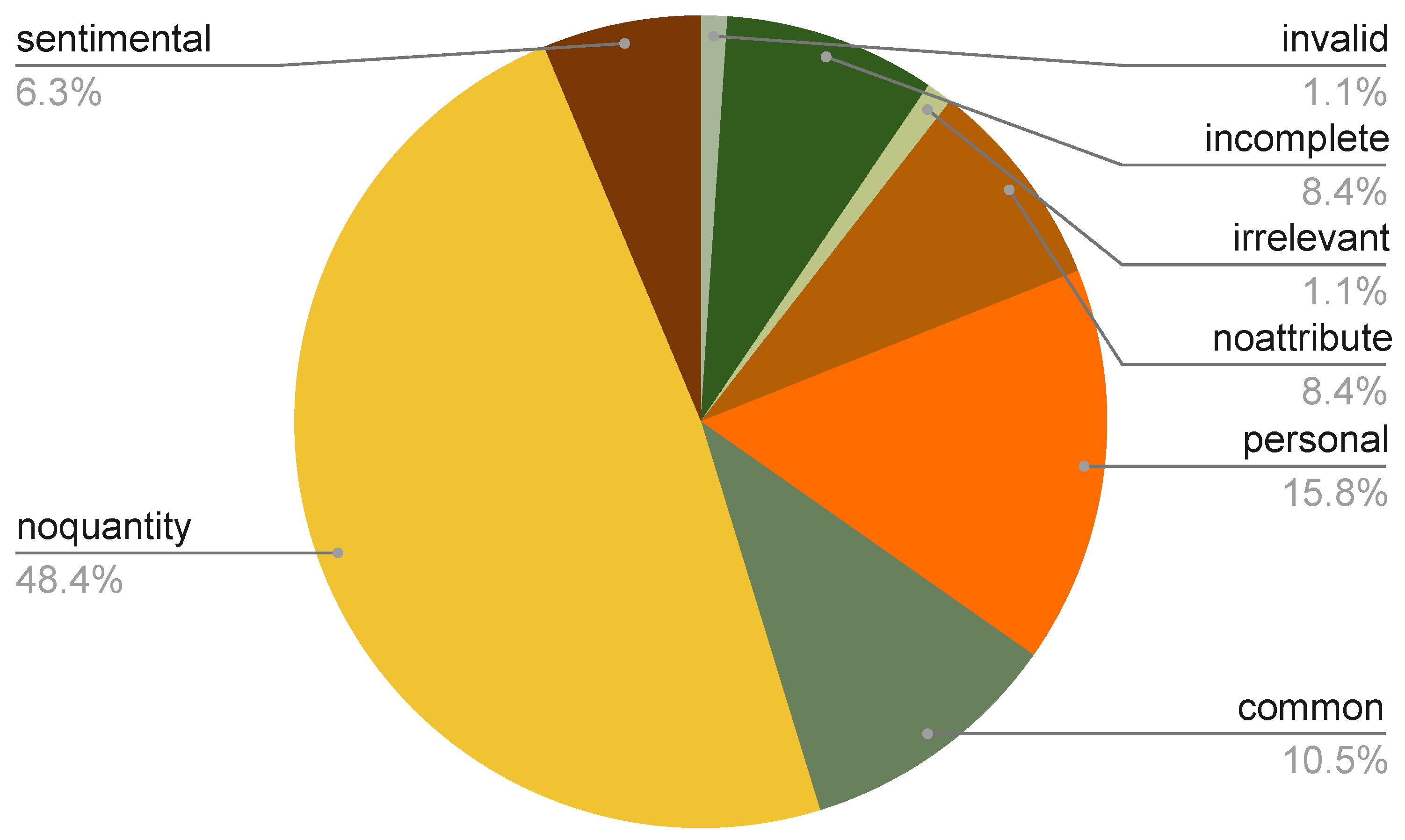
In our empirical experiment, we observed that only 0.55% of labeled sentences were considered to be positive (i.e., salient facts.). Given such an extremely small number of positive examples, there is a chance that the learning algorithm cannot generalize the model using the training set as it may not cover sufficient patterns of salient facts. As a result, a trained model may not be able to recognize salient facts with different linguistic patterns than those of the training instances. In this paper, we considered that we could alleviate the issue by incorporating prior knowledge about the task. Salient facts contain relatively uncommon attributes and/or quantitative descriptions, so we aimed to implement those functions into the model.
Since models may meet unseen salient facts during prediction, we developed a representation enrichment method to help the models in recognizing their attributes and quantities for prediction. The method appends a special tag to text instances if they contain tokens related to uncommon attributes or quantitative descriptions. The model can learn that a text instance containing the special tag tends to be a salient fact. During prediction, even if a model does not recognize unseen tokens in a salient fact instance, the model can recognize the special tag and make accurate prediction.
The expansion process begins by selecting a set of salient tokens. The salient tokens are those common words that appear in the review corpus to describe uncommon attributes or quantities. The expansion process comprises two steps. The first step identifies a list of salient tokens as part of the inputs to Algorithm 1. The second step takes the list and a special tag token (e.g., “salient” for uncommon attribute token list) to run Algorithm 1. The algorithm iterates all text instances. If a text instance contains any token of the list, the algorithm appends a special tag to it. All instances that contain salient tokens share the same tag. After the two steps, both groups of tagged and untagged text instances are fitted to train the extraction model. After the model is trained, it is used to produce predictions for salient facts.
Uncommon attribute token list: we used a two-step method to discover tokens that are used in the corpus to describe uncommon attributes. First, we identified nouns, since attribute tokens are mostly nouns. We used NLTK to extract noun words. Second, we ranked the nouns by their IDF scores. The IDF of a noun w is calculated as , where T is the total number of sentences and is the number of sentences that contain the noun token w. Nouns that appeared the least frequently (i.e., top 1000 words based on the IDF scores) in the review corpus were considered to be uncommon attribute tokens. We next inspect the top list to label tokens that are used to describe uncommon attributes. The purpose was to exclude nonattribute words. By applying this two-step method, we successfully constructed a list of uncommon attribute tokens.
Quantitative description token list: we curated a list of tokens that are used to describe quantities. The list contains three types of tokens: digit, numeric, and unit. Digit tokens include all integer numbers from 0 to 9 and any integers composed of the 10 integers. Numeric (
https://helpingwithmath.com/cha0301-numbers-words01/, accessed on 22 August 2020) are word descriptions of numbers, and representatives are hundreds, thousands, and millions. Unit (
https://usma.org/detailed-list-of-metric-system-units-symbols-and-prefixes, accessed on 22 August 2020) consist of commonly used measurements that often appear in quantitative descriptions, and some examples include hour and percentage. Digit, numeric, and unit form a comprehensive coverage of word tokens that people commonly use in quantitative descriptions. We last inspected the set of tokens and curated a final list of tokens for quantitative descriptions.
| Algorithm 1 Representation enrichment. |
| Input: Text instance t with tokens , list l of salient tokens, and special token s |
| Output: A new text instance |
| 1: |
| 2: for to k do |
| 3: if then |
| 4: |
| 5: return |
| 6: end if |
| 7: end for |
| 8: return |
3.3. Label Propagation
Due to the extremely sparse positive examples for salient facts, the training procedure may fail to generalize the model. To alleviate the issue, we augmented training data by searching similar instances.
Candidate Selection: we show the label propagation process in Algorithm 2. The process takes salient fact instance
t from existing training data as input. Then, it searches the
m-most similar instances from unlabeled text instances (denoted as
.) As the similarity function, we used the Jaccard score as defined in Equation (
1), where
and
denote the distinct vocabulary sets of
t and
u respectively. The score is 1 if two texts share exactly same vocabulary sets, and 0 if they do not share any common tokens.
To obtain vocabulary sets, we used the BERT WordPiece tokenizer to split the text into tokens by matching character sequence with a predefined vocabulary of about 30,000 [
5]. Since an unlabeled corpus contains abundant text instances, Algorithm 2 can help in retrieving the instances that are the most similar to salient facts to expand our training set.
| Algorithm 2 Label propagation: candidate selection. |
| Input: Salient instances set T, unlabeled instances set U, similarity function , candidate size m. |
| Output: Candidate instances set C of size m |
| 1: Candidate set |
| 2: for t in T do |
| 3: for to n do |
| 4: |
| 5: |
| 6: end for |
| 7: end for |
| 8: |
| 9: Sort C by score |
| 10: return |
Reranking: Jaccard score favors frequent word tokens such as stopwords. Therefore, a negative instance can be ranked high and returned as a candidate if it contains a lot of stopwords. To solve this issue, we introduced a reranking operator that sorts all candidates by their relative affinity to positive and negative examples in the training set, as shown in Algorithm 3. For every candidate
c, we calculated two scores, i.e., textual affinity
and semantic affinity
, which were used to measure the overall distances to a group of examples
G.
Textual affinity
was defined as Equation (
3) to measure the relative affinity of a candidate
c to the positive- and negative-example groups of the training set. Affinity is measured by counter average distance (see Equation (
2)). Greater textual affinity is better, which means that
c has smaller distance to the positive group and larger distance to the negative group. Intuitively, textual affinity favors candidate
c that shares many common tokens with positive examples, while such tokens are not common (e.g., stopwords) in negative examples.
Textual affinity cannot recognize semantically connected words (e.g., million and billion). Therefore, we introduced semantic affinity
as defined in Equation (
4). Semantic affinity requires a discriminator that uses word embeddings as input representation. In other words, a discriminator can recognize semantically connected words through similar word vectors. Next, we trained the discriminator using the training set, so that the discriminator learned to predict whether an input sentence is a positive example according to its word vectors. The trained discriminator is used to estimate the probability of candidate
c belonging to the positive group. In our experiments, we used BERT as the discriminator and took the product of textual affinity
and semantic affinity
to yield the best F1 scores.
Lastly, we sorted all candidates in descending order by their overall affinity score (i.e., textual affinity × semantic affinity). We returned the top
as positive examples, and tail
as negative examples, where
and
are user-defined parameters. In our experiments, label propagation performed reasonably well if
equalled to the label ratio, and
equalled to the training size but was smaller than half the size of unlabeled examples.
| Algorithm 3 Label propagation: reranking. |
| Input: Candidate collection C, training set , number of pseudopositive examples , and negative examples |
| Output: positive and negative pseudoexamples |
| 1: Reranking set |
| 2: for c in C do |
| 3: ta = textual_affinity(c, X, Y) |
| 4: estimator = BERT (X, Y) |
| 5: sa = semantic_affinity(c, estimator) |
| 6: |
| 7: end for |
| 8: |
| 9: return head and tail of R as positive and negative pseudoexamples
|
3.4. Additional Training Techniques
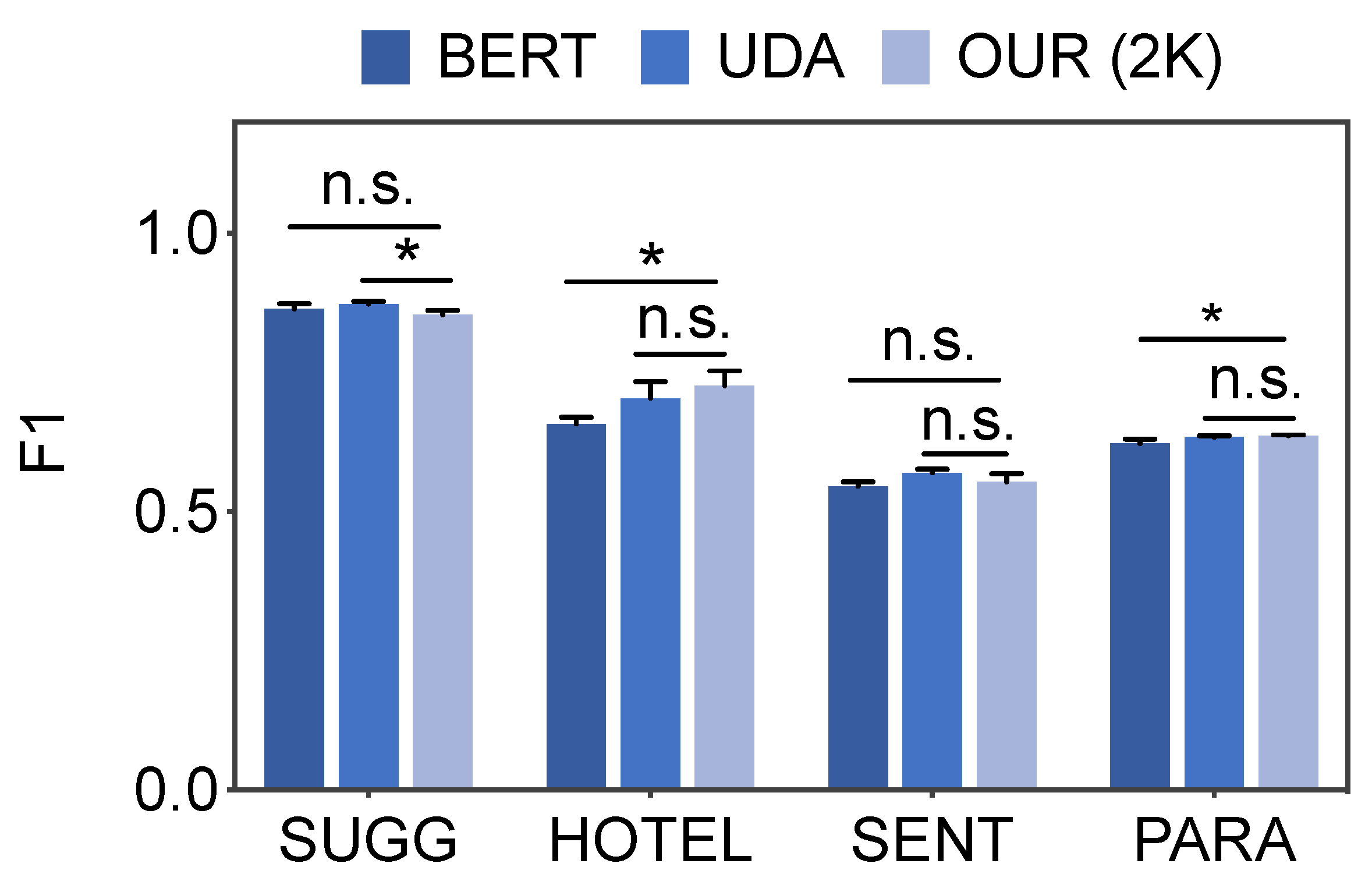
Fine tuning pretrained language models is limited in batch size due to GPU memory capacity. For example, the maximal batch size that BERT base model can process on a 16 GB GPU is around 64. Given the extremely low label ratio (e.g., 5%), it is possible that a batch may not contain any positive examples. Consequently, the trained model may exhibit significant biases against positive examples. To alleviate this problem, we leveraged two fine-tuning techniques, namely, thresholding and choosing the best snapshot (described below), to enable the trained model to weigh more on the positive examples.
Thresholding: pretrained models such as BERT adopt argmax to predict the label of an example. First, the pretrained model outputs two probability scores for the same example, indicating the likelihood of this example belonging to the negative or positive class. Next, argmax selects the class of a larger score as the final prediction. Experiments showed that the average positive probability was much smaller than negative probability; thus, we replaced argmax with thresholding that only concerned the positive prediction score. Thresholding sorts all examples by positive prediction scores and varies a threshold from the highest to the lowest score. We tried 100 different thresholds at equal intervals between highest and lowest, and chose the threshold that led to the largest F1 on the training set.
Choose best snapshot: due to severe label imbalance, a model could achieve the best performance during its training snapshots. A potential reason is that the model met the highest-quality positive and negative examples at the snapshots. Therefore, we set a fixed number of snapshots and inspected the model during each snapshot. We compared the model performance between two consecutive snapshots and checkpointed the model if better performance was observed.


 ,
, 

{kind=link}
{kind=link}