1. Introduction
Attributed to the development of convolutional neural networks (CNNs) with its strong representation ability and the access of large-scale datasets, semantic segmentation and object detection have developed tremendously. However, it is worth to point out that annotating a large number of object masks is time-consuming, expensive, and sometimes infeasible in some scenarios, such as computer-aided diagnosis systems. Moreover, without massive annotated data, the performance of deep learning models drops dramatically on classes that do not appear in the training dataset. Few-shot segmentation (FSS) is a promising field to tackle this issue. Unlike conventional semantic segmentation, which merely segments the classes appearing in the training set, few-shot segmentation utilizes one or a few annotated samples to segment new classes.
They firstly extract features from both query and support images, and then the support features and their masks are encoded into a single prototype [
1] to represent foreground semantics or a pair of prototypes [
2,
3] to represent the foreground and background. Finally, they conduct dense comparison between prototype(s) and query feature. Feature comparison methods are usually performed in one of two ways: explicit metric function, (e.g., cosine-similarity [
3]) and implicit metric function (e.g., relationNet [
4]).
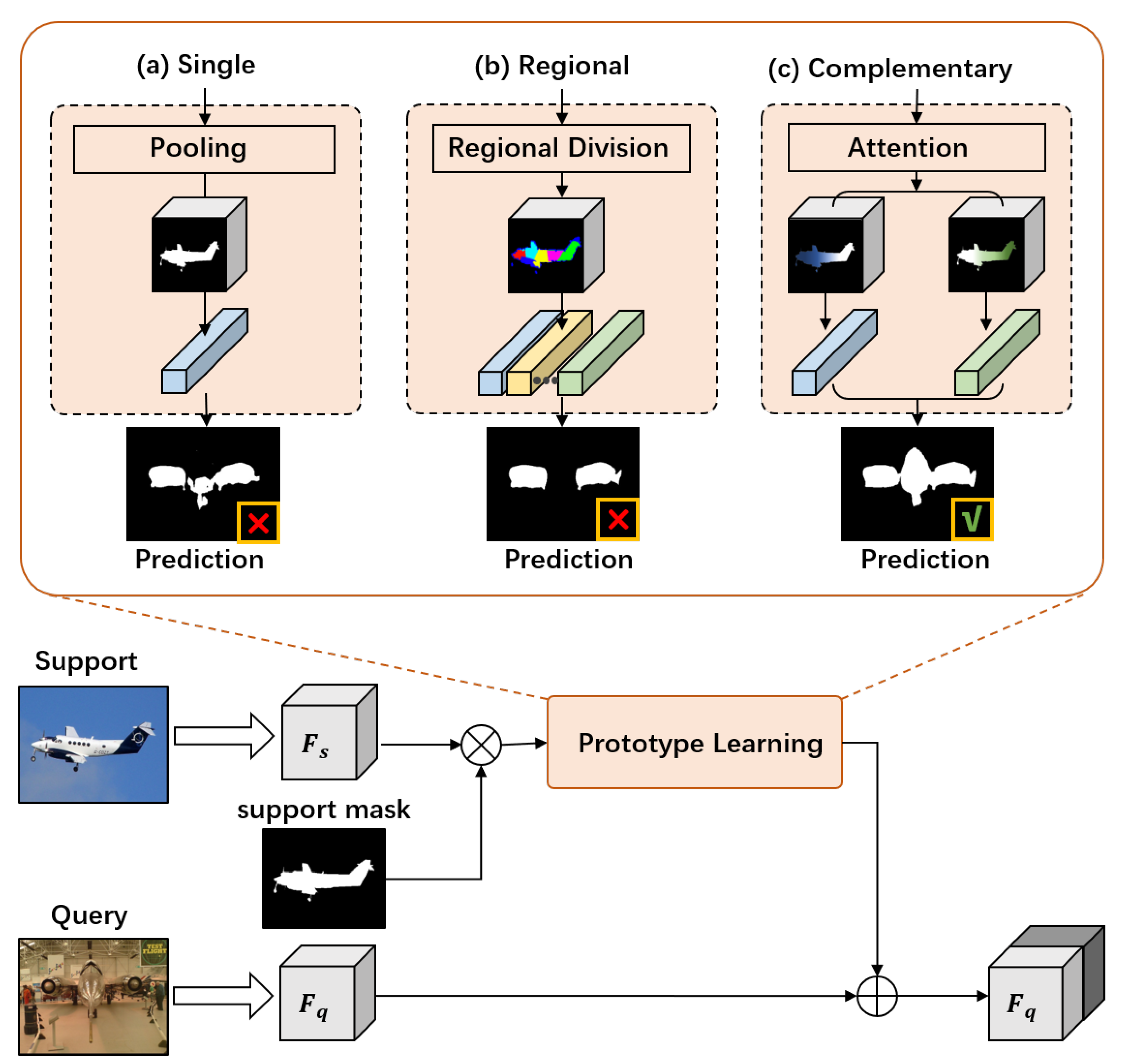
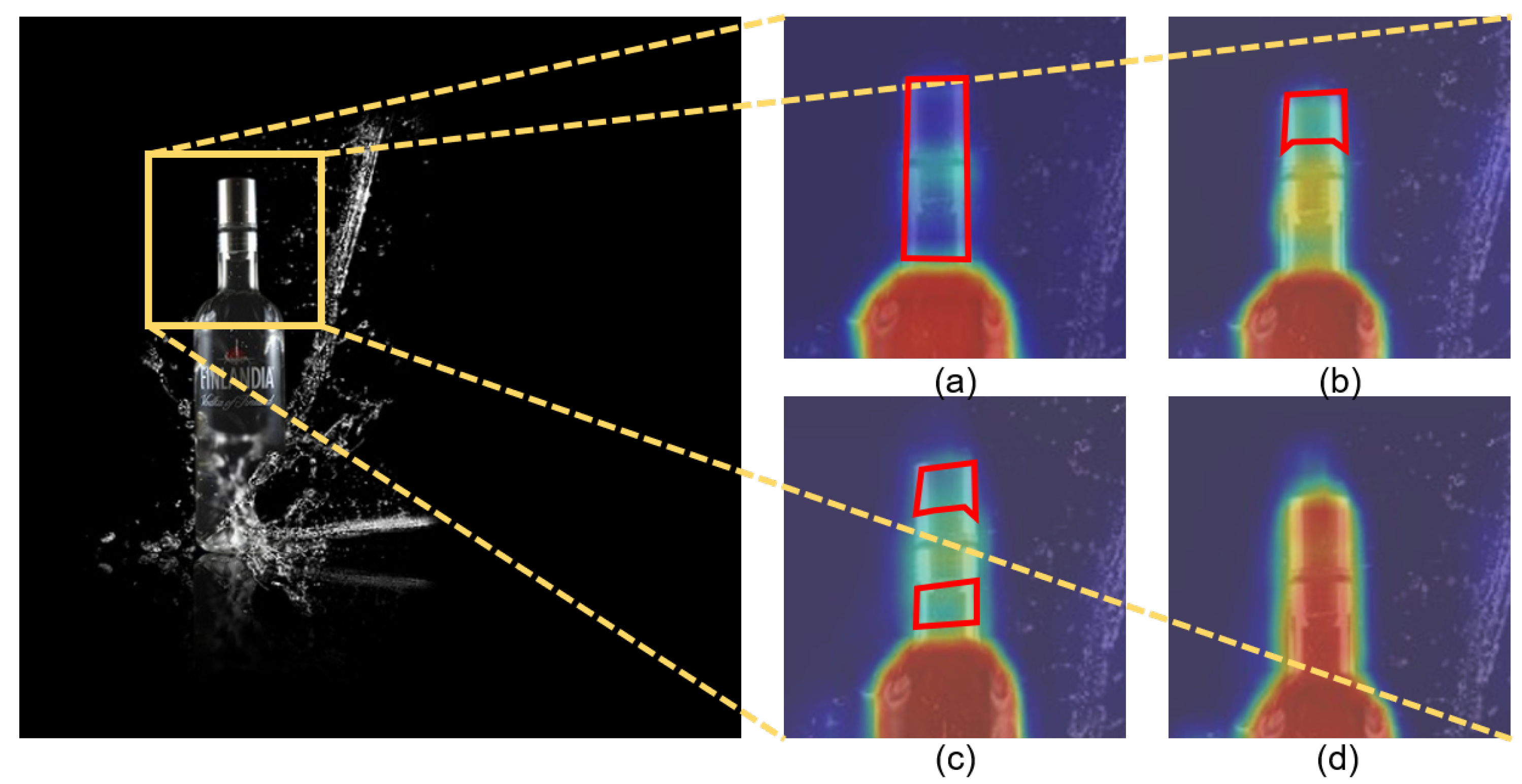
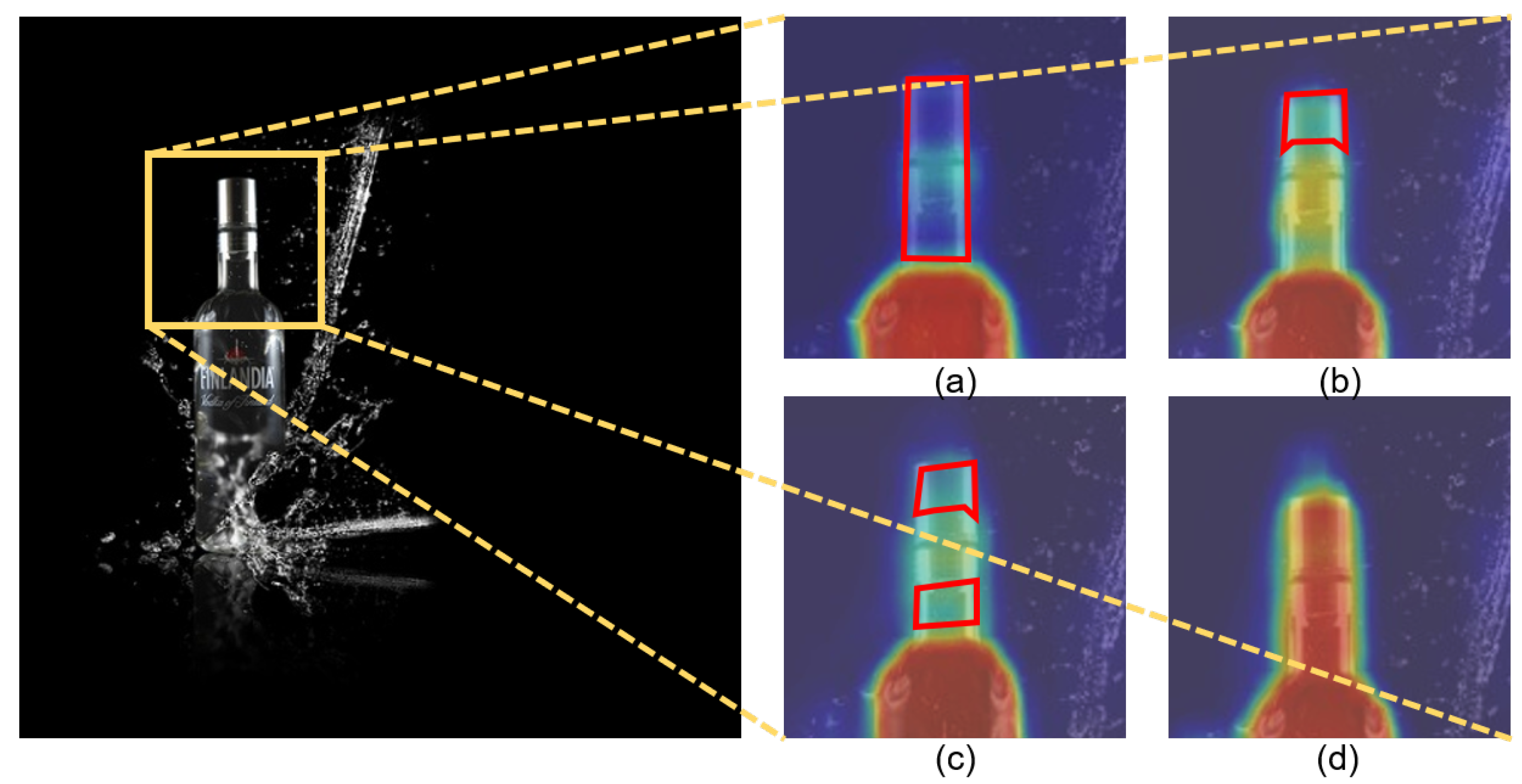
As shown in
Figure 1a, it is common-sense [
2,
5,
6] that using a single prototype generated by masked average pooling is unable to carry sufficient information. Specifically, due to variant appearance and poses, using masked average pooling only retains the information of discriminative pixels and ignores the information of plain pixels. To overcome this problem, multi-prototype strategy [
2,
5,
6] is proposed by dividing foreground regions into several pieces.
However, as shown in
Figure 1b, these multi-prototype methods still suffer from two drawbacks. Firstly, the whole representation of foreground region is weakened, since existing methods split regions into several pieces and damage the correlation among the generated prototypes. Moreover, current methods often ignore inter-class similarity between foreground and background, and their training strategy in the context of segmenting the main foreground objects leads to underestimating the discrimination between the foreground and background. As a result, existing multi-prototype methods tend to misclassify background pixels into foreground.
In this paper, we propose a simple yet effective method, called Dual Complementary prototype Network (DCNet), to overcome the above mentioned drawbacks. Specifically, it is composed of two branches to segment the foreground and background in a complementary manner, and both segmentation branches rely on our proposed Complementary Prototype Generation (CPG) module. The CPG module is proposed to extract comprehensive support information from the support set. Through global average pooling with support mask, we extract the average prototype at first, and we obtain its attention weight on the support image by calculating the cosine distance between the foreground feature and the average prototype iteratively. In this way, we can easily figure out which part of the information is focused and which part of the information is ignored without segmentation on support image. Then we use this attention weight to generate a pair of prototypes to represent the focused and the ignored region. By using a weight map to generate prototypes for comparison, we can preserve the correlation among the generated prototypes and avoid the information loss to a certain extent.
Furthermore, we introduce background guided learning to pay additional attention on the inter-class similarity between the foreground and background. Considering that the background in support images is not always the same as that in a query image, we adopt a different training manner from foreground segmentation, where the query background mask is used as guidance for query image background segmentation. In this way, our model could learn a more discriminative representation for distinguishing foreground and background. The proposed method effectively and efficiently improves the performance on FSS benchmarks without extra inference cost.
The main contributions of this work are summarized as follows.
We propose Complementary Prototype Generation (CPG) to learn powerful prototype representation without extra parameters costs;
We propose Background Guided Learning (BGL) to increase the feature discrimination between foreground and background. Besides, BGL is merely applied in the training phase so that it would not increase the inference time;
Our approach achieves the state-of-the-art results on both PASCAL- and COCO- datasets and improves the performance of the baseline model by 9.1% and 12.6% for 1-shot and 5-shot setting on COCO-.
3. Proposed Methods
3.1. Problem Setting
The aim of few-shot segmentation is to obtain a model that can learn to perform segmentation from only a few annotated support images in novel classes. The few-shot segmentation model should be trained on a dataset and evaluated on a dataset . Given the classes set in is and classes set in is , there is no overlap between training classes and test classes, e.g., .
Following a previous definition [
22], we divide the images into two non-overlapping sets of classes
and
. The training set
is built on
and the test set is built on
. We adopt the episode training strategy, which has been demonstrated as an effective approach for few-shot recognition. Each episode is composed of a shot support set
and a query set
to form a
K-shot episode
, where
and
are the image and its corresponding mask label, respectively. Then, the training set and test set are denoted by
and
, where
and
is the number of episodes for the training and test set. Note that both the mask
of the support set and the mask
of the query set are provided in the training phase, but only the support image mask
is included in the test phase.
3.2. Overview
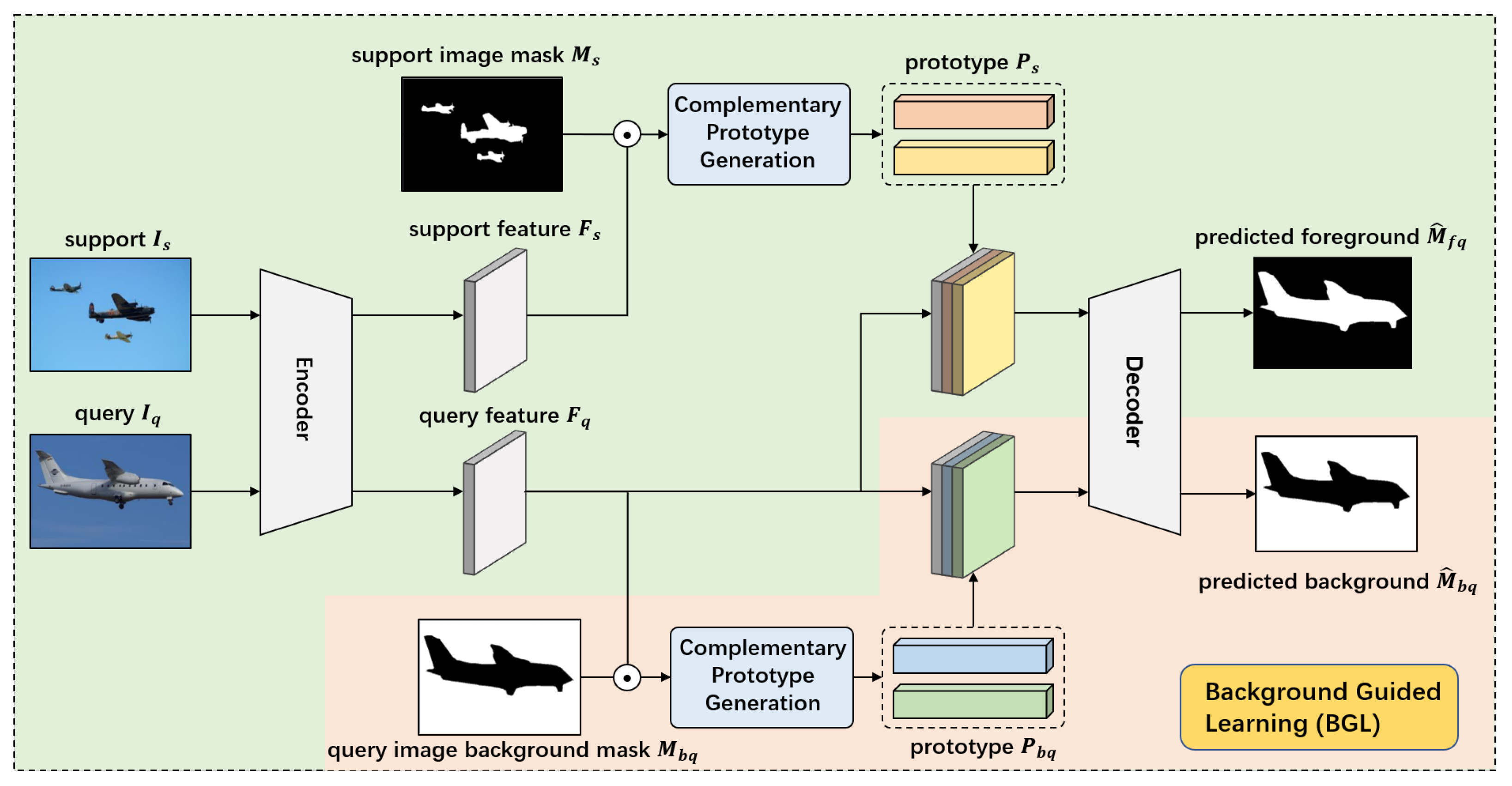
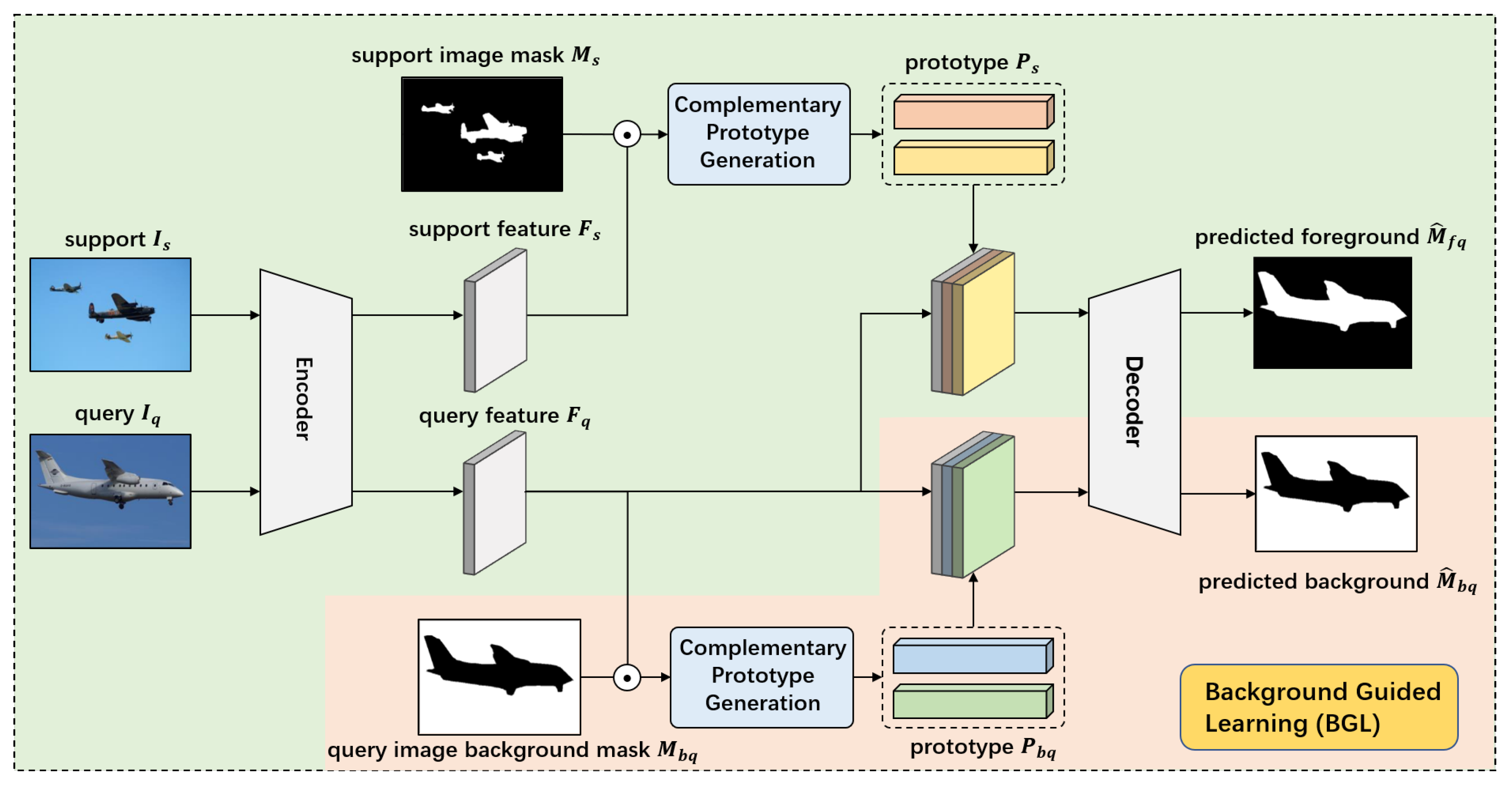
As shown in
Figure 2, our Dual Complementary prototype Network (DCNet) is trained via the episodic scheme on the support-query pairs. In episodic training, supports images and a query image are input to the share-weight encoder for feature extraction. Then, the query feature is compared with prototypes of the current support class to generate a foreground segmentation mask via a FPN-like decoder. Besides, we propose an auxiliary supervision, named Background Guided Learning (BGL), where our network learns robust prototype representation for a class-agnostic background in an embedding space. In this supervision, the query feature is compared with prototypes of the query background to make a prediction on its own background. With this joint training strategy, our model can learn discriminative representation for foreground and background.
Thus, the overall optimization target can be briefly formulated as:
where
and
denote the foreground segmentation loss and background segmentation loss, respectively, and
is the balance weight, which is simply set as 1.
In the following subsections, we first elaborate our prototype generation algorithm. Then, background-guided learning on 1-shot setting is introduced, followed by inference.
3.3. Complementary Prototypes Generation
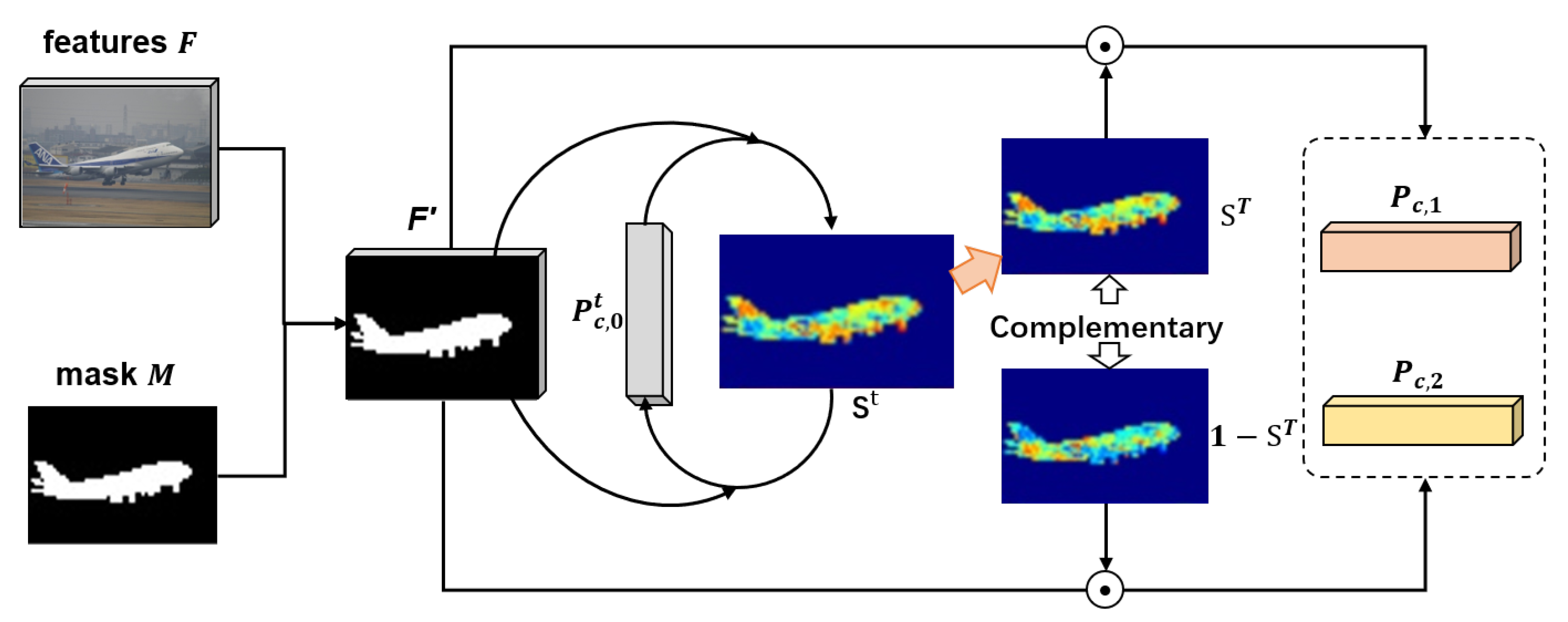
Inspired by SCL [
6], we propose a simple and effective algorithm, named Complementary Prototypes Generation (CPG), as shown in
Figure 3. This CPG algorithm generates a pair of complementary prototypes and aggregates information hidden in features based on cosine similarity. Specifically, given the support feature
with the mask region as
, we extract a pair of prototypes to fully represent the information in the mask region.
As the first step, we extract the targeted feature
filtered through mask
M from
F, in Equation (2),
where ⊙ represents element-wise multiplication. Then, we initiate prototype
by masked average pooling, in Equation (3),
where
represents the coordination of each pixel,
denotes the width and height of feature
, respectively. Since
, the sum of
M represents the area of the foreground region.
In the next step, we aggregate the foreground features into two complementary clusters. For each iteration
t, we first compute the cosine distance matrix
between the prototype
and the targeted features
as follows,
As we keep the relu layer in the encoder layer, the cosine distance is limited in
. To calculate the weight of target features contributed to
, we normalize the
S matrix as:
Then, after the end of the iteration, based on matrix
, we aggregate the features into two complementary prototypes as:
It is worth noting that these prototypes are not separated like priors and CPG algorithm utilizes a weighted map to generate a pair of complementary prototypes. In this way, we retain the correlation between the prototypes. The whole CPG is delineated in Algorithm 1.
| Algorithm 1: Complementary Prototypes Generation (CPG). |
| Input: targeted feature , corresponding mask M, the number of iteration T. |
| init prototype by masked average pooling with . |
| for iteration t in {1, …, T} do |
| Compute association matrix S between targeted feature and prototype , |
| Standardize association , |
| |
| Update prototype , |
| |
| end for |
| generate complementary prototypes from , |
| |
| |
| return final prototypes |
3.4. Background Guided Learning
In previous works [
1,
5,
6], the background information has not been adequately exploited for few-shot learning. Especially, these methods only use foreground prototypes to make a final prediction on the query image in the training. As a result, the representation on class-agnostic background is the lack of discriminability. To solve this problem, Background Guided Learning (BGL) is proposed via joint training strategy.
As shown in
Figure 2, BGL is proposed to segment the background on the query image based on query background mask
. As the first step, query feature
and its background mask
are fed into the CPG module to generate a pair of complementary prototypes
, following Algorithm 1. Next, we concatenate the complementary prototype
with all spatial location in query feature map
, as Equation (8):
where
denotes the expansion operation and ⊕ denotes the concatenation operation,
and
are the complementary prototypes
as well as
, denoting the concatenated feature. Then, concatenate feature
is fed into the decoder, generating the final prediction, as shown in Equation (9):
where
is the prediction of the model, D is a decoder. The loss
is computed by:
where
denotes the background prediction on a query image and CE denotes the cross-entropy loss.
Intuitively, if the model can predict a good segmentation mask for the foreground using a prototype extracted from the foreground mask region, the prototype learned from the background mask region should be able to segment itself well. Thus, our BGL encourages the model to distinguish the background from the foreground better.
3.5. Inference
In the inference phase, we only keep the foreground segmentation branch for the final prediction. For K-shot setting, we following previous works and use the average to generate a pair of complementary prototypes.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}