
DAP-SDD: Distribution-Aware Pseudo Labeling for Small Defect Detection †


Abstract
:1. Introduction
- We propose a distribution-aware pseudo labeling method for small defect detection (DAP-SDD) that maximizes the use of the limited number of labels available. Bootstrapping is applied on the limited available labels to obtain an approximate distribution of the complete labels, effectively guiding the pseudo labeling propagation.
- We utilize the approximate distribution in conjunction with t-distribution confidence interval and adaptive training strategies in our proposed threshold setting method, thereby dynamically generating more pseudo labels with high confidence while reducing confirmation bias.
- We conduct extensive experiments on various datasets to validate the proposed method. The evaluation results demonstrate the effectiveness of our proposed approach that outperforms the state-of-the-art techniques.
2. Related Work
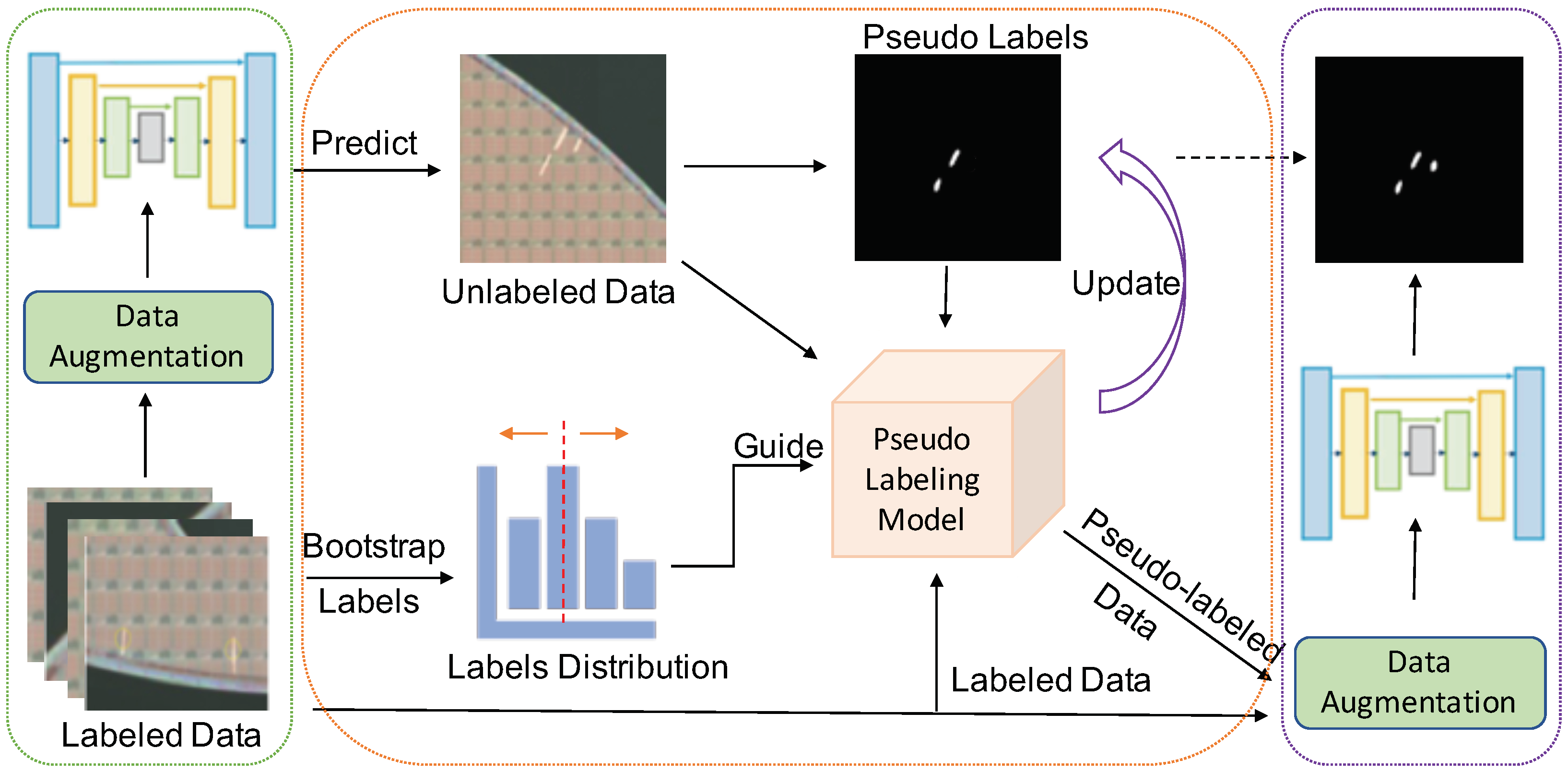
3. Methodology
3.1. Leverage Labeled Data
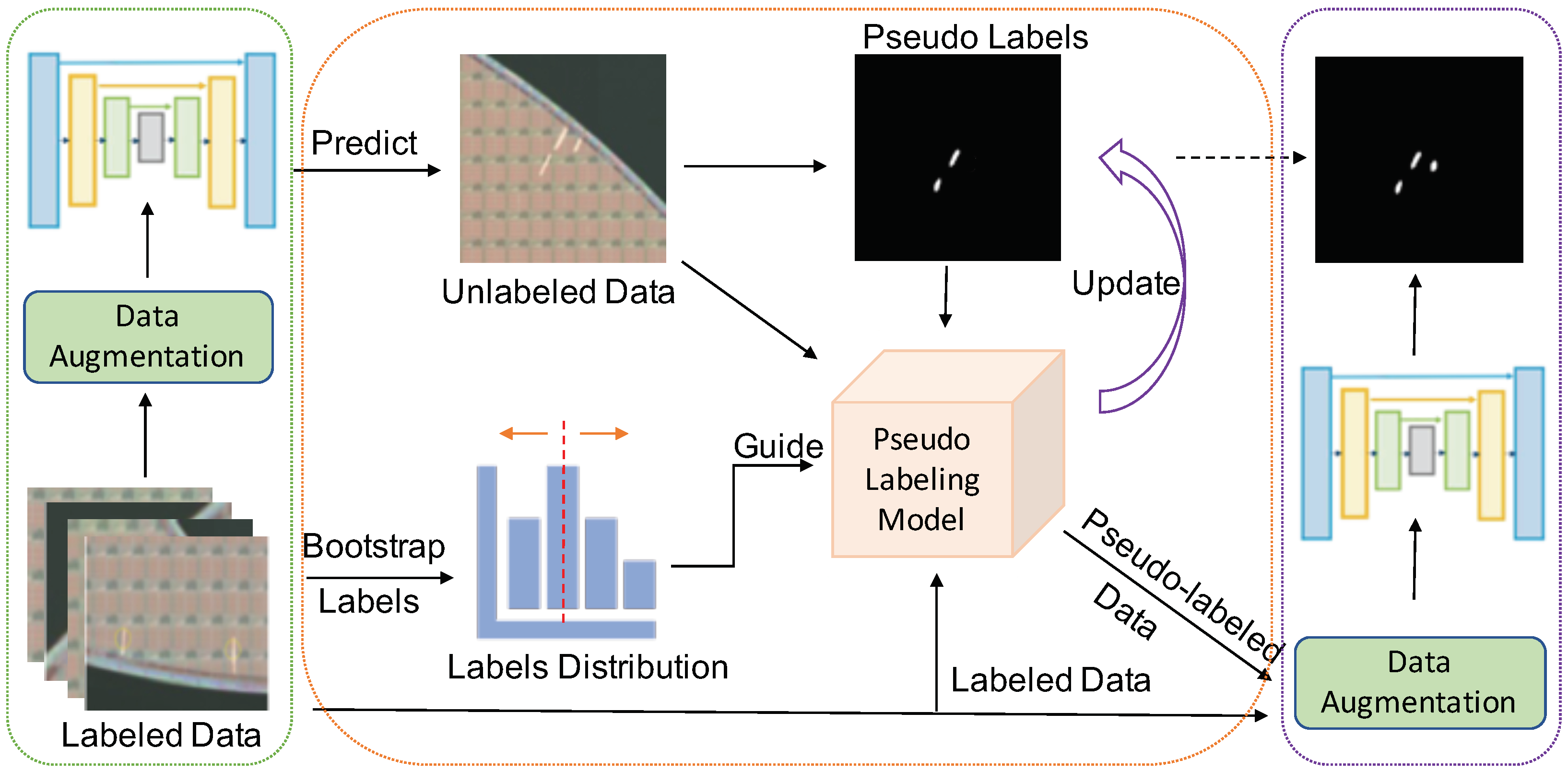
3.2. Distribution-Aware Pseudo Labeling
3.2.1. Bootstrap Labels
3.2.2. Distribution-Aware Pseudo Label Threshold Setting
3.2.3. Training Strategies
| Algorithm 1 Distribution-Aware Pseudo Labeling. |
| 1: Train a model using labeled data . |
| 2: for do |
| 3: Obtain threshold |
| 4: |
| 5: |
| 6: Pseudo label using |
| 7: |
| 8: Train using . |
| 9: |
| 10: end for |
| 11: return |
3.2.4. Loss Function
4. Results and Discussion
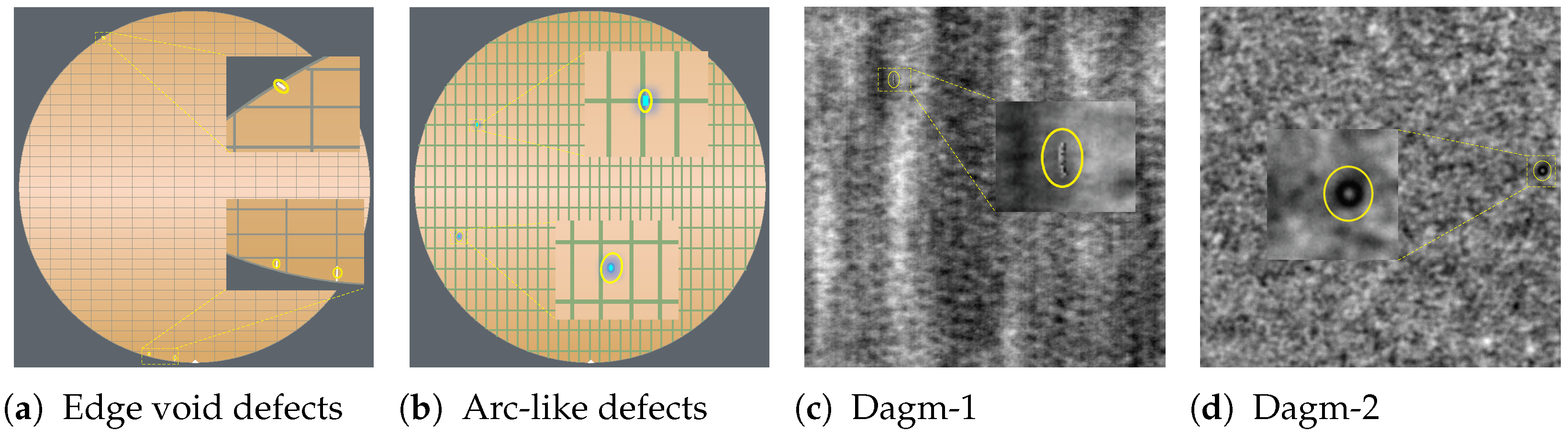
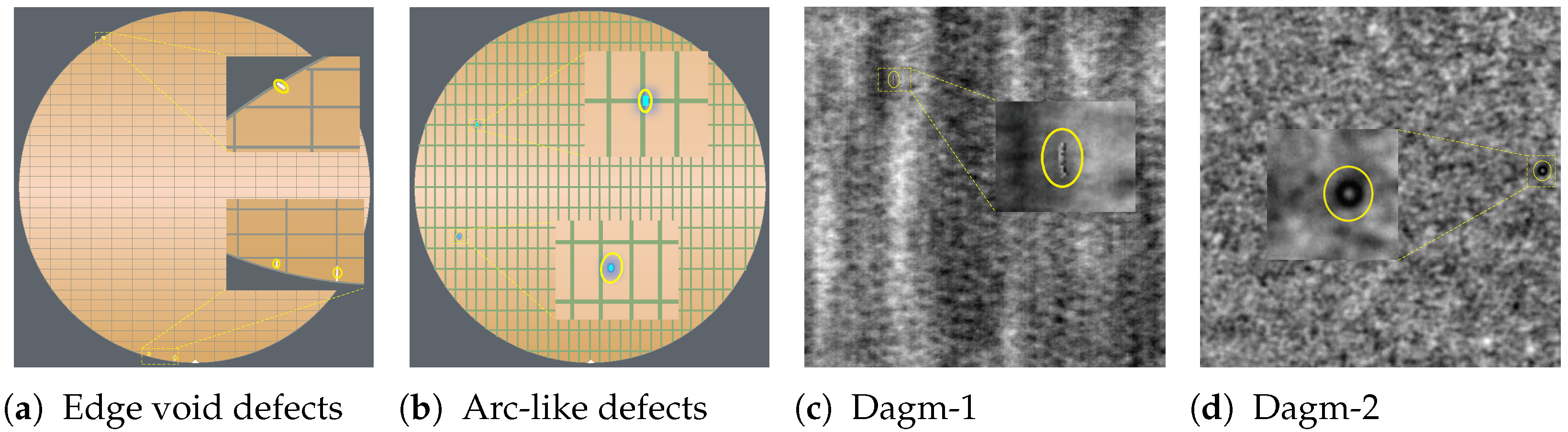
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Settings and Parameters
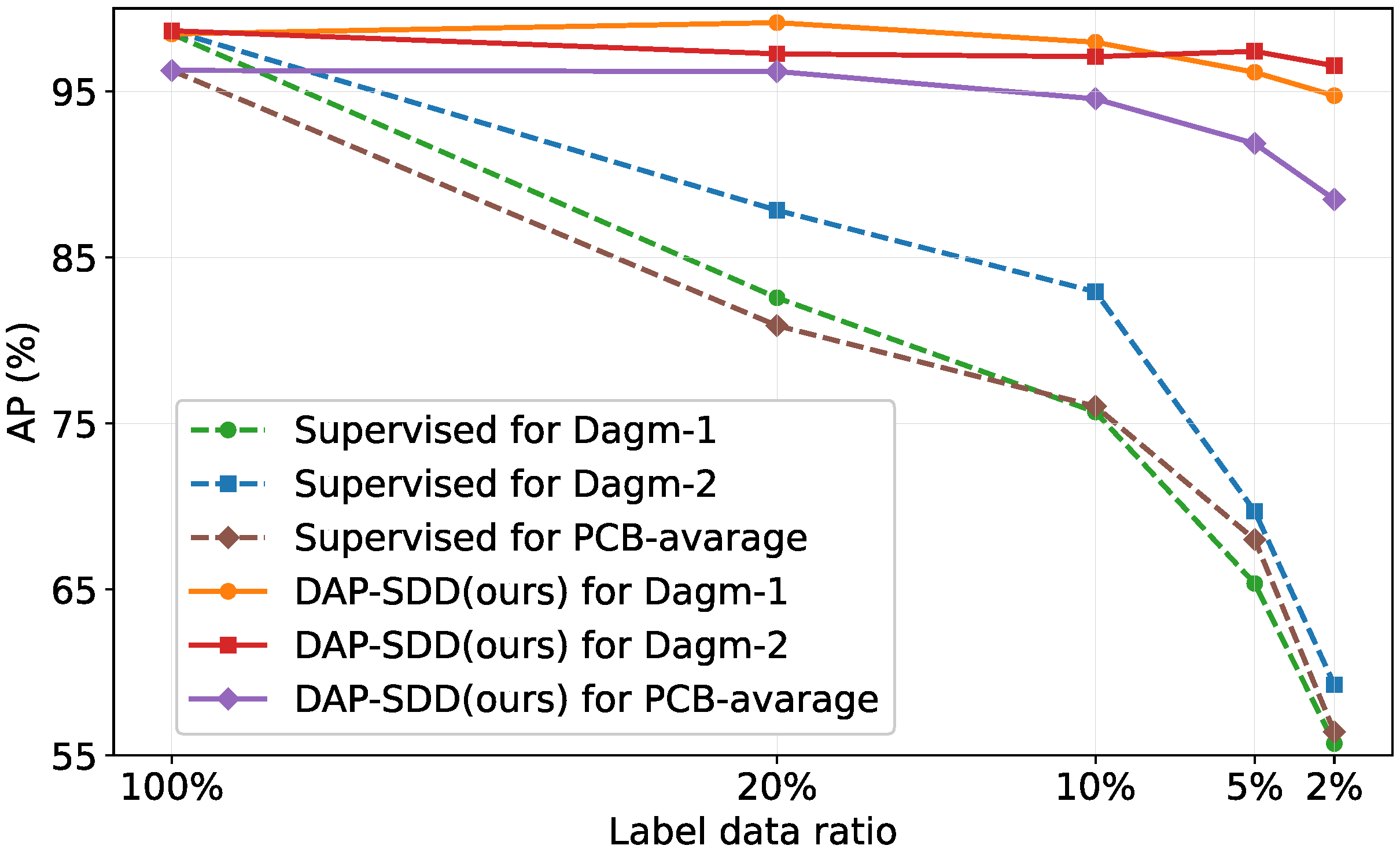
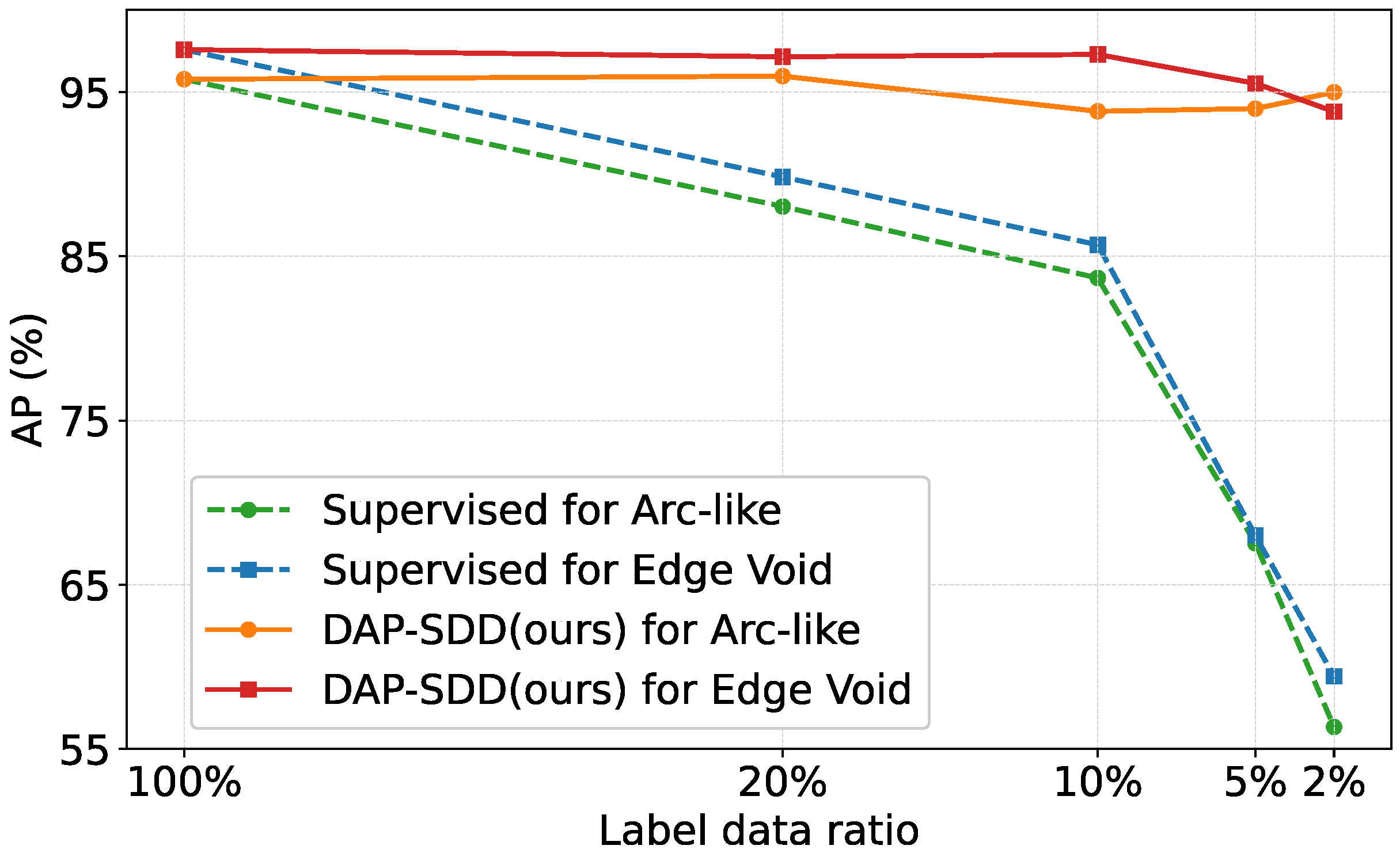
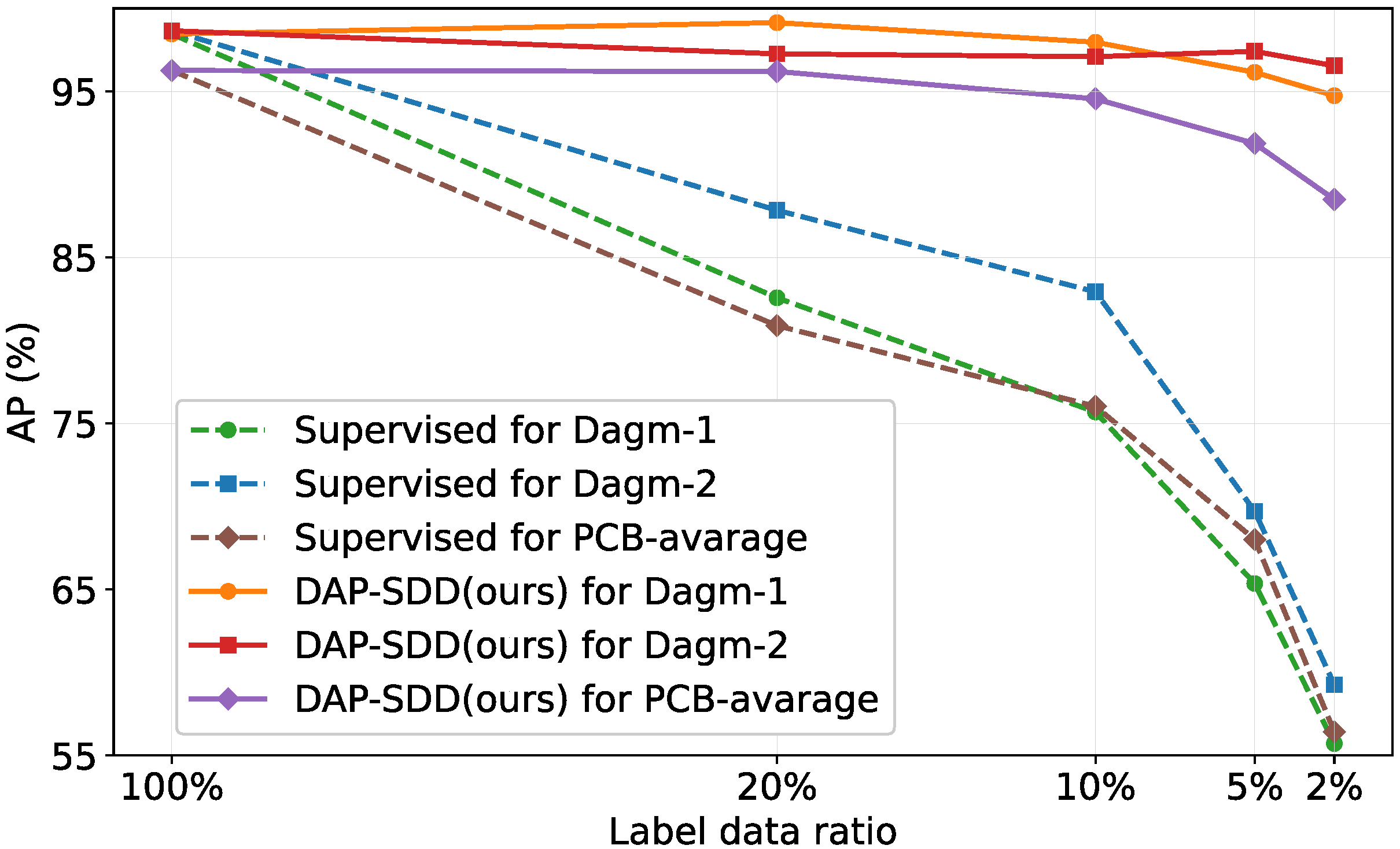
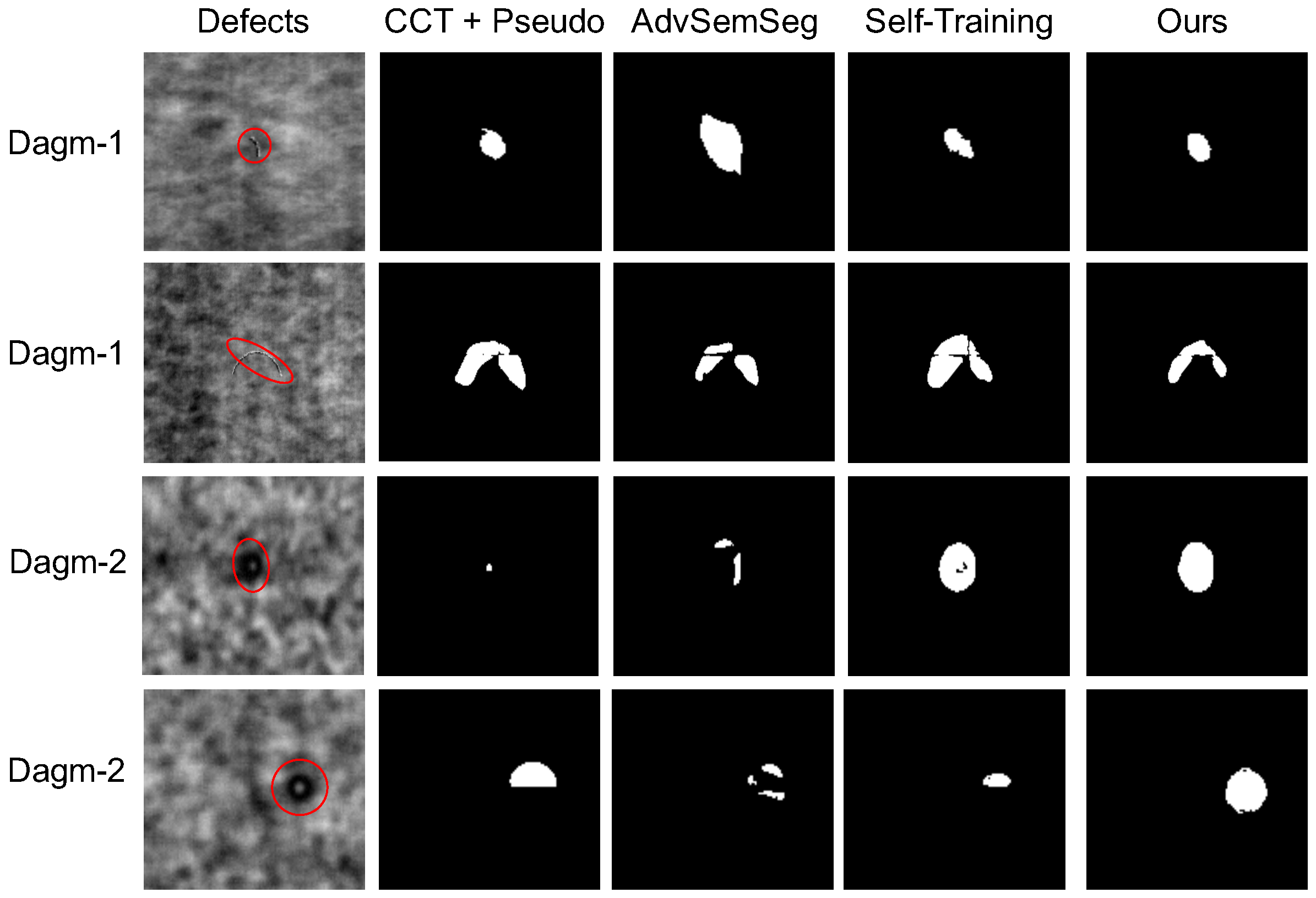
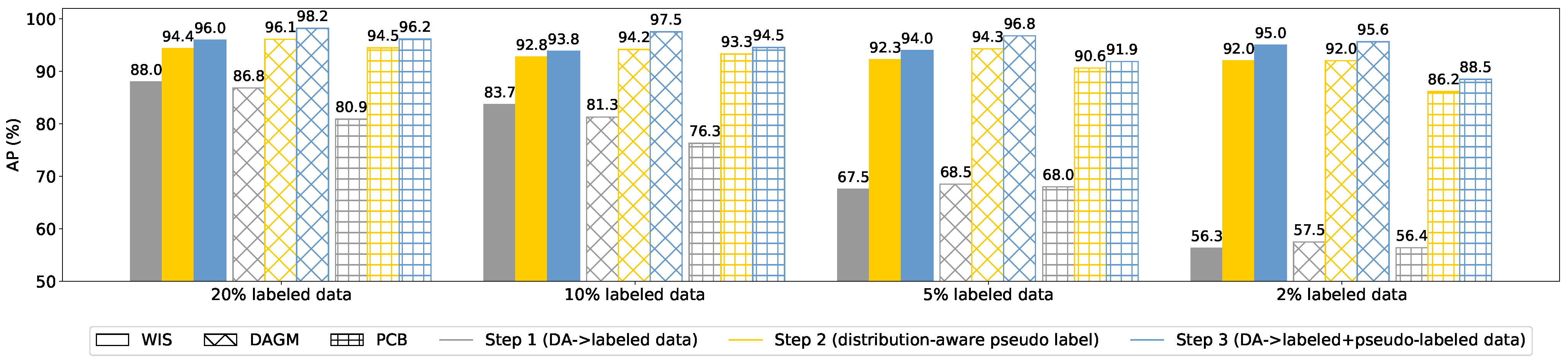
4.4. Experiment Results
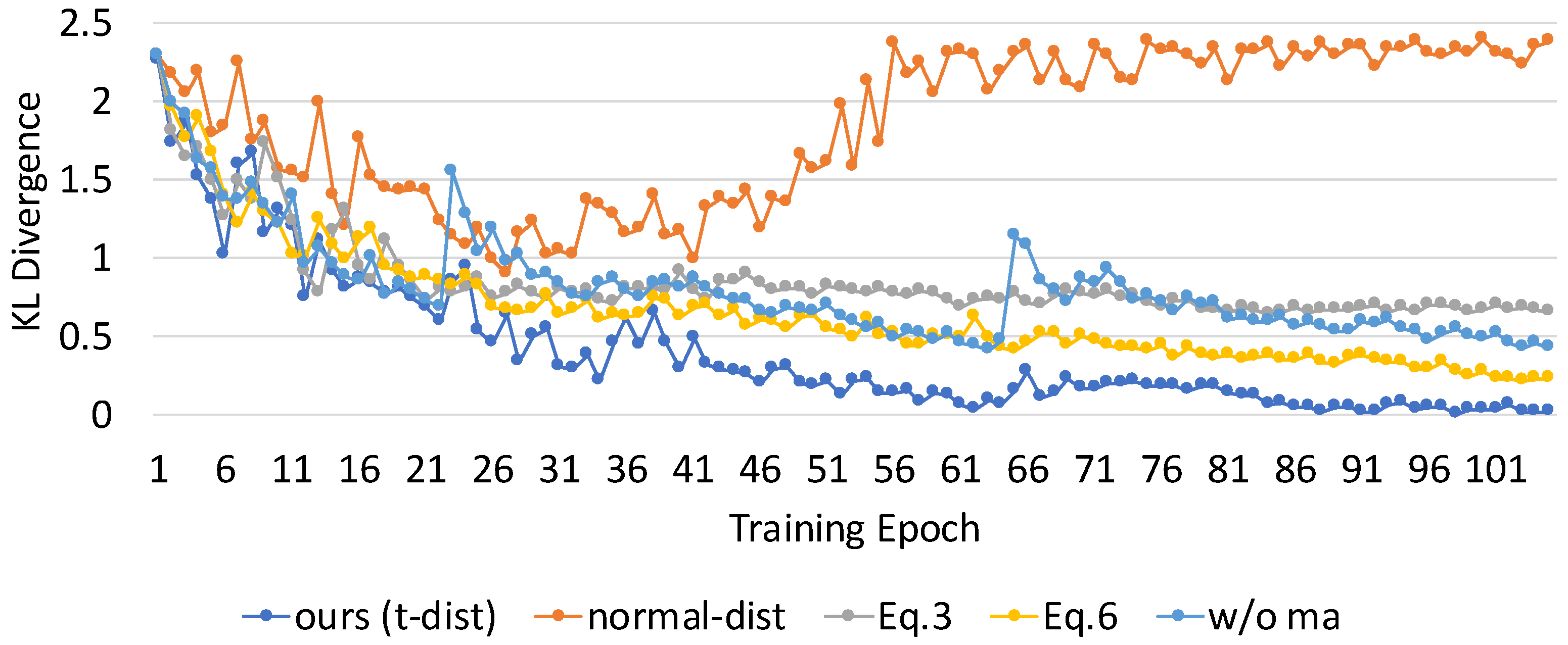
4.5. Ablation Studies
5. Conclusions
Author Contributions
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shankar, N.; Zhong, Z. Defect detection on semiconductor wafer surfaces. Microelectron. Eng. 2005, 77, 337–346. [Google Scholar] [CrossRef]
- Huang, S.H.; Pan, Y.C. Automated visual inspection in the semiconductor industry: A survey. Comput. Ind. 2015, 66, 1–10. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Fu, K.; Li, J.; Ma, L.; Mu, K.; Tian, Y. Intrinsic Relationship Reasoning for Small Object Detection. arXiv 2020, arXiv:2009.00833. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Nguyen, N.D.; Do, T.; Ngo, T.D.; Le, D.D. An Evaluation of Deep Learning Methods for Small Object Detection. J. Electr. Comput. Eng. 2020, 2020, 3189691. [Google Scholar] [CrossRef]
- Heidelberg Collaboratory for Image Processing (HCI). DAGM 2007 Competition Dataset: Industrial Optical Inspection Dataset. Heidelberg Collaboratory for Image Processing, Heidelberg University: Heidelberg, Germany. Available online: https://hci.iwr.uni-heidelberg.de/content/weakly-supervised-learning-industrial-optical-inspection (accessed on 7 April 2022).
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. In Proceedings of the Ninth International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 14–16 October 2017; Volume 10615, p. 106151E. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection-SNIP. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 9333–9343. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Finding Tiny Faces in the Wild with Generative Adversarial Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 21–30. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 210–226. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. MixMatch: A Holistic Approach to Semi-Supervised Learning. Adv. Neural Inf. Process. Syst. 2019, 32, 5049–5059. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Matching and Augmentation Anchoring. arXiv 2020, arXiv:1911.09785. [Google Scholar]
- Kurakin, A.; Li, C.L.; Raffel, C.; Berthelot, D.; Cubuk, E.D.; Zhang, H.; Sohn, K.; Carlini, N.; Zhang, Z. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning. arXiv 2021, arXiv:2101.06329. [Google Scholar]
- French, G.; Laine, S.; Aila, T.; Mackiewicz, M.; Finlayson, G.D. Semi-supervised semantic segmentation needs strong, varied perturbations. In Proceedings of the 31st British Machine Vision Conference 2020, BMVC 2020, Virtual Event, UK, 7–10 September 2020. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-Supervised Semantic Segmentation With Cross-Consistency Training. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12671–12681. [Google Scholar]
- Verma, V.; Lamb, A.; Kannala, J.; Bengio, Y.; Lopez-Paz, D. Interpolation Consistency Training for Semi-supervised Learning. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI 2019), Macao, China, 10–16 August 2019; pp. 3635–3641. [Google Scholar] [CrossRef] [Green Version]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. PseudoSeg: Designing Pseudo Labels for Semantic Segmentation. arXiv 2021, arXiv:2010.09713. [Google Scholar]
- Lee, D. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the 30th International Conference on Machine Learning (ICML) Workshop, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Oliver, A.; Odena, A.; Raffel, C.A.; Cubuk, E.D.; Goodfellow, I. Realistic Evaluation of Deep Semi-Supervised Learning Algorithms. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 3239–3250. [Google Scholar]
- Chen, Z.; Zhang, R.; Zhang, G.; Ma, Z.; Lei, T. Digging Into Pseudo Label: A Low-Budget Approach for Semi-Supervised Semantic Segmentation. IEEE Access 2020, 8, 41830–41837. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar] [CrossRef] [Green Version]
- Ke, Z.; Qiu, D.; Li, K.; Yan, Q.; Lau, R.W. Guided Collaborative Training for Pixel-wise Semi-Supervised Learning. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Grandvalet, Y.; Bengio, Y. Semi-supervised Learning by Entropy Minimization. Adv. Neural Inf. Process. Syst. 2005, 17, 529–536. [Google Scholar]
- Souly, N.; Spampinato, C.; Shah, M. Semi Supervised Semantic Segmentation Using Generative Adversarial Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5689–5697. [Google Scholar] [CrossRef]
- Hung, W.C.; Tsai, Y.H.; Liou, Y.T.; Lin, Y.Y.; Yang, M.H. Adversarial Learning for Semi-supervised Semantic Segmentation. arXiv 2018, arXiv:1802.07934. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.E.; McGuinness, K. Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Printed Circuit Board (PCB) Tiny Defects Dataset, Open Lab on Human Robot Interaction of Peking University, Beijing, China. Available online: http://robotics.pkusz.edu.cn/resources/dataset/ (accessed on 7 April 2022).
- Cao, Z.; Yang, Z.; Zhuo, X.; Lin, R.; Wu, S.; Huang, L.; Han, M.; Zhang, Y.; Ma, J. DeepLIMa: Deep Learning Based Lesion Identification in Mammograms. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 362–370. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, L.; Sun, X.; Zhou, Z.; Li, X.; Yu, Y.; Wang, Y. Cascaded Generative and Discriminative Learning for Microcalcification Detection in Breast Mammograms. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12570–12578. [Google Scholar] [CrossRef]
- Zoph, B.; Ghiasi, G.; Lin, T.Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q.V. Rethinking Pre-training and Self-training. arXiv 2020, arXiv:2006.06882. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Edge Void | Arc-Like | ||
|---|---|---|---|---|
| AP (%) | F1 (%) | AP (%) | F1 (%) | |
| CCT (Ouali et al.) | - | - | - | - |
| CCT+Pseudo (Ouali et al.) | 70.75 | 69.80 | 71.09 | 72.13 |
| AdvSemSeg (Hung et al.) | 76.61 | 76.42 | 76.98 | 79.51 |
| Self-training (Zoph et al.) | 89.29 | 88.14 | 85.34 | 86.89 |
| DAP-SDD (Ours) | 97.29 | 96.64 | 94.99 | 91.38 |
| Data Amount | DAGM | PCB | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Dagm-1 | Dagm-2 | Missing Hole | Mouse Bite | Open Circuit | Short | Spur | Spurious Copper | Average | |
| 100% | 98.46 | 98.65 | 98.75 | 96.03 | 95.34 | 98.57 | 96.38 | 92.46 | 96.26 |
| 20% | 99.14 | 97.26 | 98.54 | 94.71 | 96.45 | 94.03 | 97.19 | 96.27 | 96.20 |
| 10% | 97.96 | 97.09 | 97.35 | 93.98 | 91.75 | 92.77 | 95.28 | 96.19 | 94.55 |
| 5% | 96.15 | 97.41 | 97.13 | 89.10 | 86.07 | 89.92 | 91.95 | 96.98 | 91.86 |
| 2% | 94.74 | 96.54 | 95.67 | 87.71 | 83.07 | 85.79 | 88.32 | 90.38 | 88.49 |
| Data Amount | DAGM | PCB | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Dagm-1 | Dagm-2 | Missing Hole | Mouse Bite | Open Circuit | Short | Spur | Spurious Copper | Average | |
| CCT [26] | 69.55 | 66.07 | 63.81 | 57.84 | 55.72 | 56.39 | 63.61 | 63.67 | 62.08 |
| CCT+Pseudo [26] | 83.15 | 82.79 | 79.37 | 73.32 | 70.18 | 72.46 | 79.40 | 76.99 | 75.29 |
| AdvSemSeg [38] | 84.62 | 85.68 | 84.28 | 80.71 | 80.44 | 82.10 | 83.45 | 83.75 | 82.46 |
| Self-training [45] | 92.59 | 91.18 | 88.15 | 85.84 | 86.83 | 85.67 | 87.92 | 87.41 | 86.97 |
| DAP-SDD (Ours) | 97.96 | 97.09 | 97.35 | 93.98 | 91.75 | 92.77 | 95.28 | 96.19 | 94.55 |
| Baseline Method | AP (%) | KL Divergence |
|---|---|---|
| Normal distribution | 66.52 | 2.3772 |
| Fixed threshold Equation (3) | 81.63 | 0.6528 |
| DAP-SDD via Equation (6) | 94.34 | 0.2288 |
| DAP-SDD w/o ma | 86.98 | 0.4181 |
| DAP-SDD (t-dist, Equation (5), ma) | 97.29 | 0.0127 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuo, X.; Rahfeldt, W.; Zhang, X.; Doros, T.; Son, S.W. DAP-SDD: Distribution-Aware Pseudo Labeling for Small Defect Detection. Comput. Sci. Math. Forum 2022, 3, 5. https://doi.org/10.3390/cmsf2022003005
Zhuo X, Rahfeldt W, Zhang X, Doros T, Son SW. DAP-SDD: Distribution-Aware Pseudo Labeling for Small Defect Detection. Computer Sciences & Mathematics Forum. 2022; 3(1):5. https://doi.org/10.3390/cmsf2022003005
Chicago/Turabian StyleZhuo, Xiaoyan, Wolfgang Rahfeldt, Xiaoqian Zhang, Ted Doros, and Seung Woo Son. 2022. "DAP-SDD: Distribution-Aware Pseudo Labeling for Small Defect Detection" Computer Sciences & Mathematics Forum 3, no. 1: 5. https://doi.org/10.3390/cmsf2022003005
APA StyleZhuo, X., Rahfeldt, W., Zhang, X., Doros, T., & Son, S. W. (2022). DAP-SDD: Distribution-Aware Pseudo Labeling for Small Defect Detection. Computer Sciences & Mathematics Forum, 3(1), 5. https://doi.org/10.3390/cmsf2022003005