
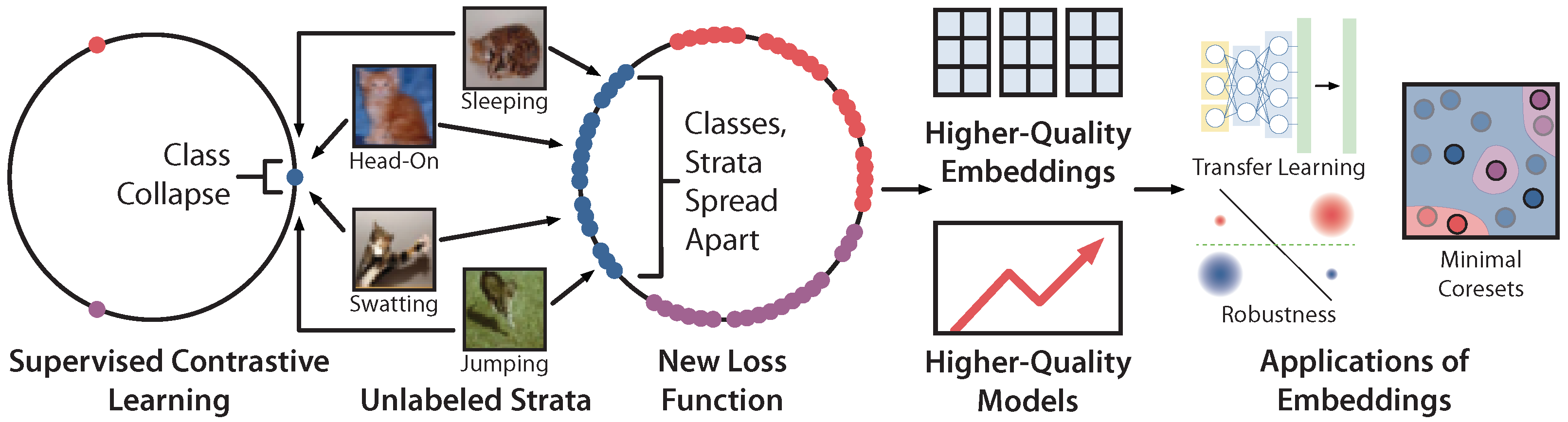
The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning †

Abstract
:1. Introduction
- We evaluate how well ’s embeddings encode fine-grained subclasses with coarse-to-fine transfer learning. achieves up to 4.4 points of lift across four datasets.
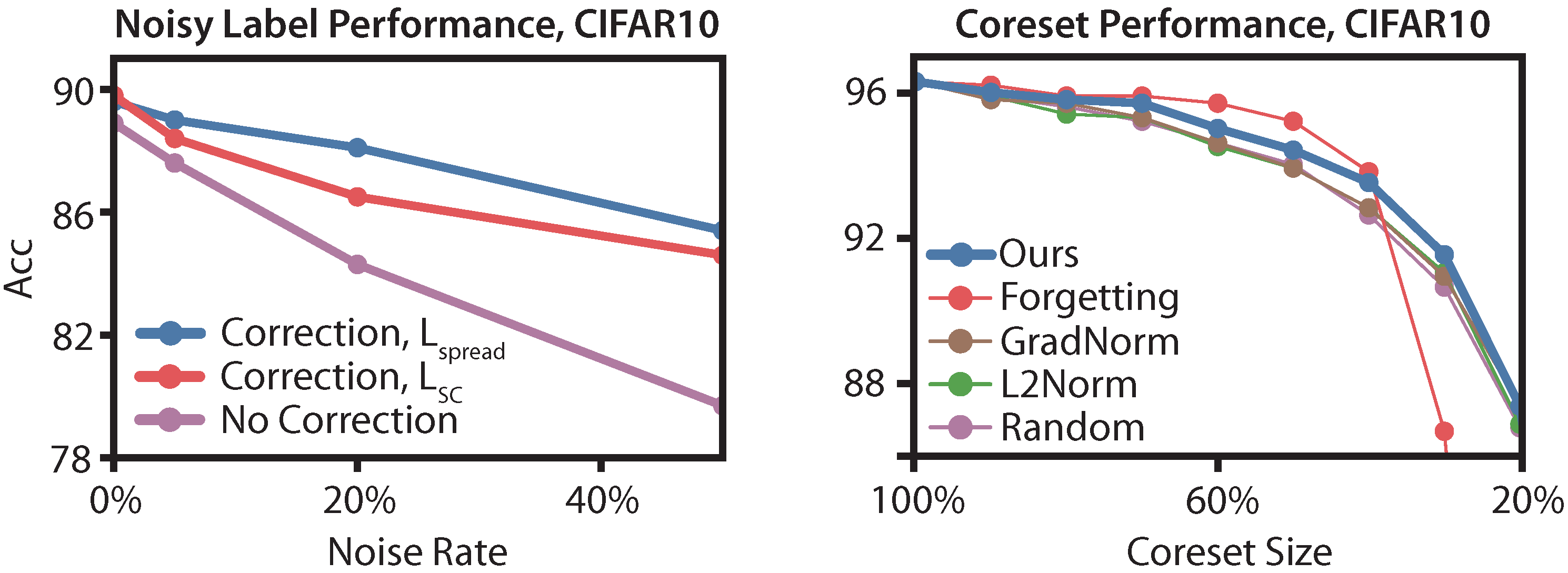
- We evaluate how well embeddings produced by can recover strata in an unsupervised setting by evaluating robustness against worst-group accuracy and noisy labels. We use our insights about how embeds strata of different sizes to improve worst-group robustness by up to 2.5 points and to recover 75% performance when 20% of the labels are noisy.
- We evaluate how well we can differentiate rare strata from common strata by constructing limited subsets of the training data that can achieve the highest performance under a fixed training strategy (the coreset problem). We construct coresets by subsampling points from common strata. Our coresets outperform prior work by 1.0 points when coreset size is 30% of the training set.
2. Background
2.1. Data Setup
2.2. Supervised Contrastive Loss
2.2.1. SupCon and Collapsed Embeddings
2.2.2. End Model
3. Method
3.1. Theoretical Motivation
3.2. Modified Contrastive Loss
Qualitative Evaluation
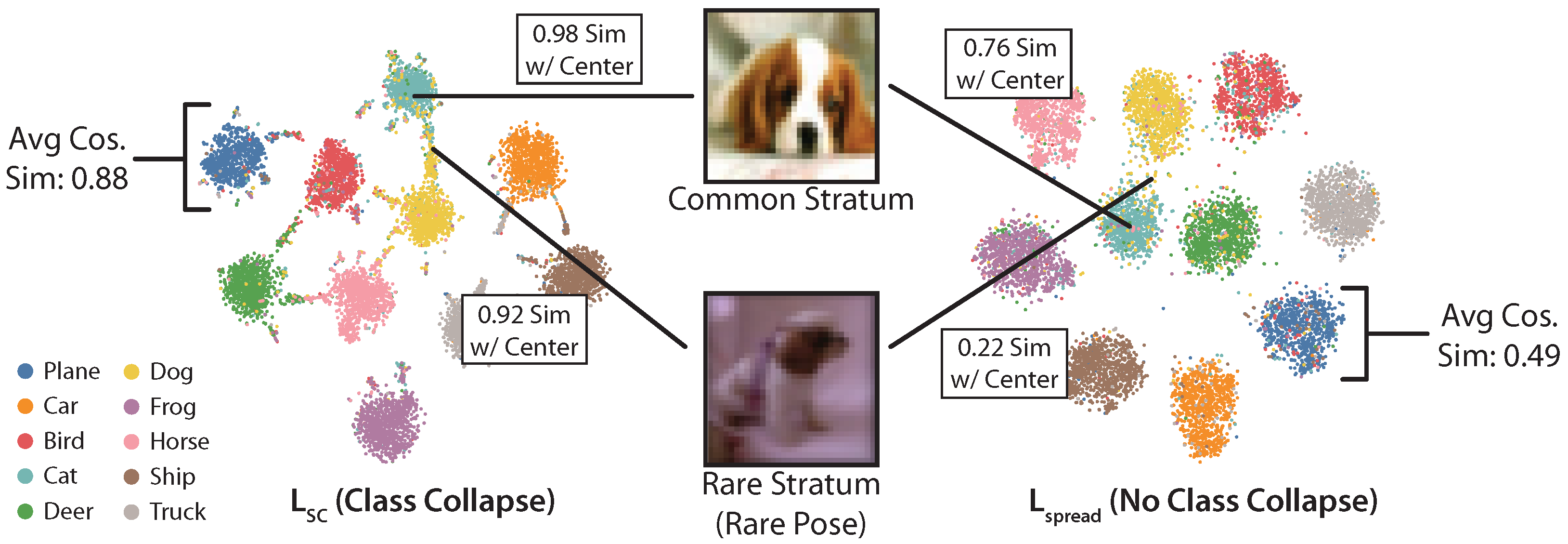
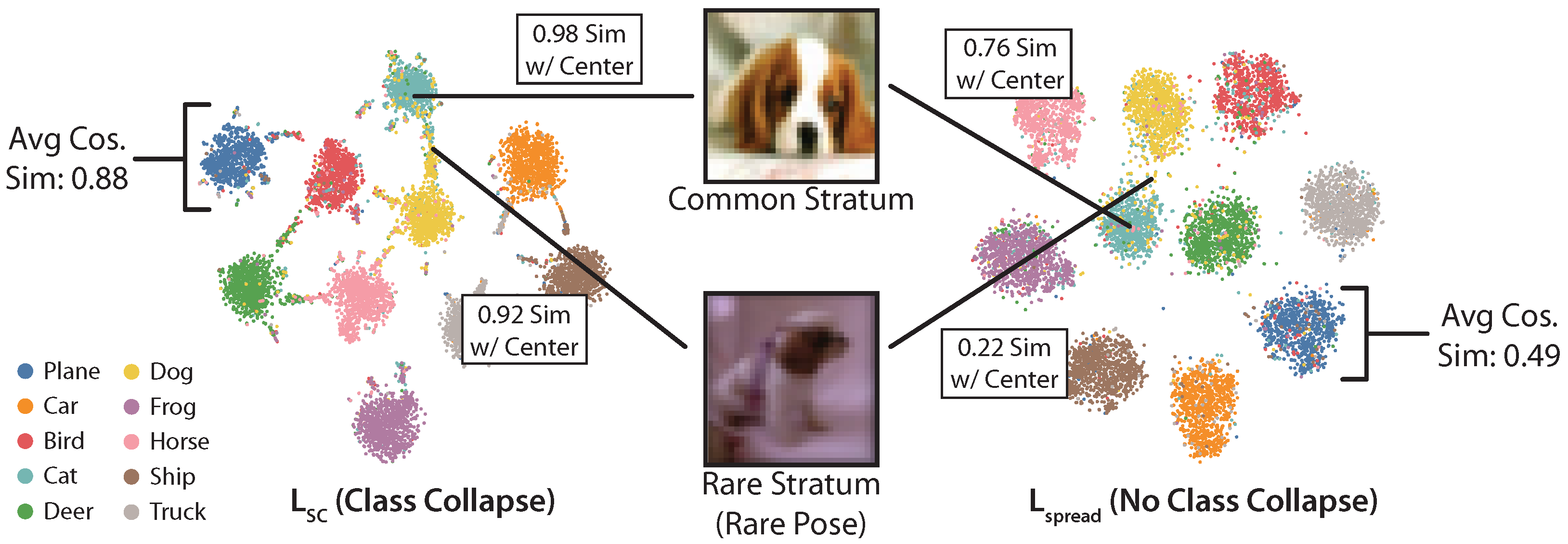
4. Geometry of Strata
4.1. Existing Analysis
4.2. Subsampling Strata
- Both strata appear in The encoder is trained on both z and . For large N, we can approximate this setting by considering trained on infinite data from these strata. Points belonging to these strata will be defined in the optimal embedding distribution on the hypersphere, which can be characterized by prior theoretical approaches [2,8,9]. With , depends on , which controls the extent of spread in the embedding geometry. With , points from the two strata would asymptotically map to one location on the hypersphere, and would converge to 0. This case occurs with probability increasing in and t.
- One stratum but not the other appears in Without loss of generality, suppose that points from z appear in but no points from do. To understand , we can consider how the end model learned using the “source” distribution containing z performs on the “target” distribution of stratum since this downstream classifier is a function of distances in embedding space. Borrowing from the literature in domain adaptation, the difficulty of this out-of-distribution problem depends on both the divergence between source z and target distributions and the capacity of the overall model. The -divergence from Ben-David et al. [10,11], which is studied in lower bounds in Ben-David and Urner [12], and the discrepancy difference from Mansour et al. [13] capture both concepts. Moreover, the optimal geometries of and induce different end model capacities and prediction distributions, with data being more separable under , which can help explain why better preserves strata distances. This case occurs with probability increasing in and decreasing in and t.
- Neither strata appears in The distance in this case is at most (total variation distance) regardless of how the encoder is trained, although differences in transfer from models learned on to z versus can be further analyzed. This case occurs with probability decreasing in and t.
Common strata are more tightly clustered together, while rarer and more semantically distinct strata are far away from them.
4.3. Implications
4.3.1. Theoretical Implications
4.3.2. Practical Implications
5. Experiments
- First, in Section 5.2, we use coarse-to-fine transfer learning to evaluate how well the embeddings maintain strata information. We find that achieves lift across four datasets.
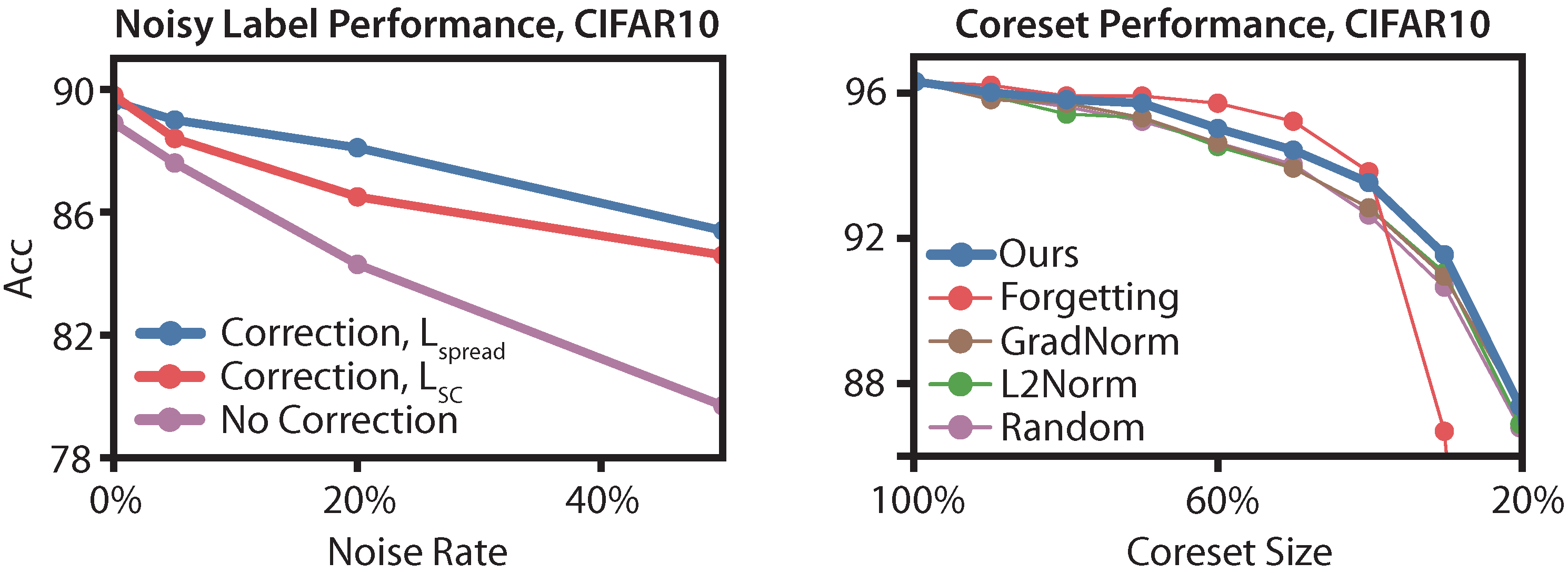
- In Section 5.3, we evaluate how well can detect rare strata in an unsupervised setting. We first use to detect rare strata to improve worst-group robustness by up to 2.5 points. We then use rare strata detection to correct noisy labels, recovering 75% performance under 20% noise.
- In Section 5.4, we evaluate how well can distinguish points from large strata versus points from small strata. We downsample points from large strata to construct minimal coresets on CIFAR10, outperforming prior work by 1.0 points at 30% labeled data.
- Finally, in Section 5.5, we show that training with improves model quality, validating our theoretical claims that preventing class collapse can improve generalization error. We find that improves performance in 7 out of 9 cases.
5.1. Datasets and Models
5.2. Coarse-to-Fine Transfer Learning
5.3. Robustness against Worst-Group Accuracy and Noise
5.4. Minimal Coreset Construction
5.5. Model Quality
6. Related Work and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Glossary

{kind=link}
{kind=link}
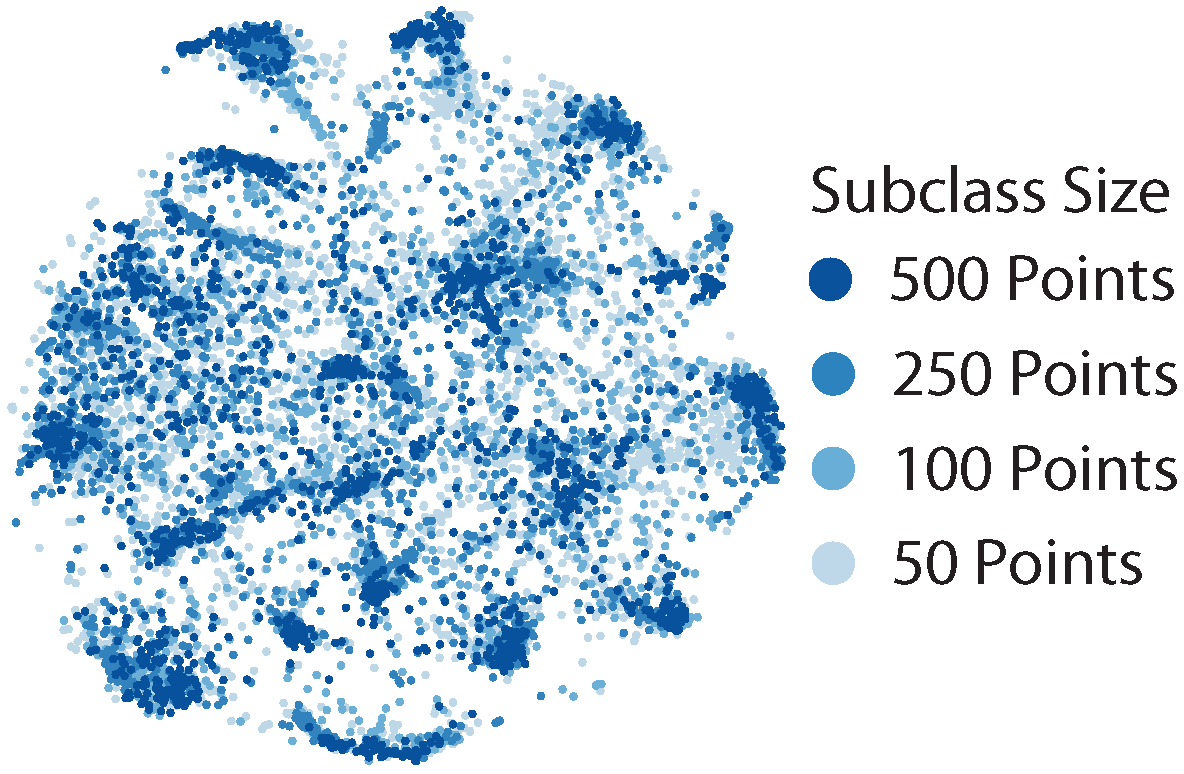{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Used for |
|---|---|
| SupCon (see Section 2.2), a supervised contrastive loss introduced by [1]. | |
| Our modified loss function defined in Section 3.2. | |
| x | Input data . |
| y | Class label . |
| Dataset of N points drawn i.i.d. from . | |
| The class that x belongs to, i.e., is a label drawm from . This label | |
| information is used as input in the supervised contrastive loss. | |
| The end model’s predicted distribution over y given x. | |
| z | A stratum is a latent variable that further categorizes data |
| beyond labels. | |
| The set of all strata corresponding to label k (deterministic). | |
| The label corresponding to strata c (deterministic). | |
| The distribution of input data belonging to stratum z, i.e., . | |
| m | The number of strata per class. |
| d | Dimension of the embedding space. |
| f | The encoder maps input data to an embedding space and is learned by |
| minimizing the contrastive loss function. | |
| The unit hypersphere, formally . | |
| Temperature hyperparameter in contrastive loss function. | |
| Notation for . | |
| Set of batches of labeled data on . | |
| Points in B with the same label as , formally . | |
| A regular simplex inscribed in the hypersphere (see Definition A1). | |
| W | The weight matrix that parametrizes the downstream linear classifier |
| (end model) learned on . | |
| The empirical cross entropy loss used to learn W over dataset (see (A1)). | |
| The generalization error of the end model of predicting output y on x using | |
| encoder f (see (A2) and (A3)). | |
| A variant on SupCon that is used in that pushes points of a class together | |
| (see (2)). | |
| A class-conditional InfoNCE loss that is used in to pull apart points | |
| within a class (see ()). | |
| Hyperparameter controls how to balance and . | |
| An augmentation of data point x. | |
| Points in B with a label different from that of , formally . | |
| t | Fraction of training data that is varied in our thought experiment. |
| Randomly sampled dataset from with size equal to fraction of . | |
| Encoder trained on sampled dataset . | |
| The distance between centers of strata z and under encoder , | |
| namely . |
Appendix B. Definitions
- 1.
- 2.
- for all i
- 3.
- s.t. for
Appendix C. Additional Theoretical
Appendix C.1. Transfer Learning on
Appendix C.2. Probabilities of Strata Appearing in Subsampled Dataset
Appendix C.3. Performance of Collapsed Embeddings on Coarse-to-Fine Transfer and Original Task
Appendix D. Proofs
Appendix D.1. Proofs for Theoretical Motivation
Appendix D.2. Proofs for Theoretical Implications
Appendix E. Additional Experimental Details
Appendix E.1. Datasets
- CIFAR10, CIFAR100, and MNIST are all the standard computer vision datasets.
- CIFAR10-Coarse consists of two superclasses: animals (dog, cat, deer, horse, frog, bird) and vehicles (car, truck, plane, boat).
- CIFAR100-Coarse consists of twenty superclasses. We artificially imbalance subclasses to create CIFAR100-Coarse-U. For each superclass, we select one subclass to keep all 500 points, select one subclass to subsample to 250 points, select one subclass to subsample to 100 points, and select the remaining two to subsample to 50 points. We use the original CIFAR100 class index to select which subclasses to subsample: the subclass with the lowest original class index keeps all 500 points, the next subclass keeps 250 points, etc.
- MNIST-Coarse consists of two superclasses: <5 and ≥5.
- Waterbirds [14] is a robustness dataset designed to evaluate the effects of spurious correlations on model performance. The waterbirds dataset is constructed by cropping out birds from photos in the Caltech-UCSD Birds dataset [43], and pasting them on backgrounds from the Places dataset [44]. It consists of two categories: water birds and land birds. The water birds are heavily correlated with water backgrounds and the land birds with land backgrounds, but 5% of the water birds are on land backgrounds, and 5% of the land birds are on water backgrounds. These form the (imbalanced) hidden strata.
- ISIC is a public skin cancer dataset for classifying skin lesions [15] as malignant or benign. 48% of the benign images contain a colored patch, which form the hidden strata.
Appendix E.2. Hyperparameters
Appendix E.3. Applications
Appendix E.3.1. Robustness against Worst-Group Performance
Appendix E.3.2. Robustness against Noise
Appendix E.3.3. Minimal Coreset Construction
Appendix F. Additional Experimental Results
Appendix F.1. Performance of
| End Model Perf. | ||||
|---|---|---|---|---|
| Dataset | ||||
| CIFAR10 | 89.7 | 90.9 | 91.3 | 91.5 |
| CIFAR100 | 68.0 | 67.5 | 68.9 | 69.1 |
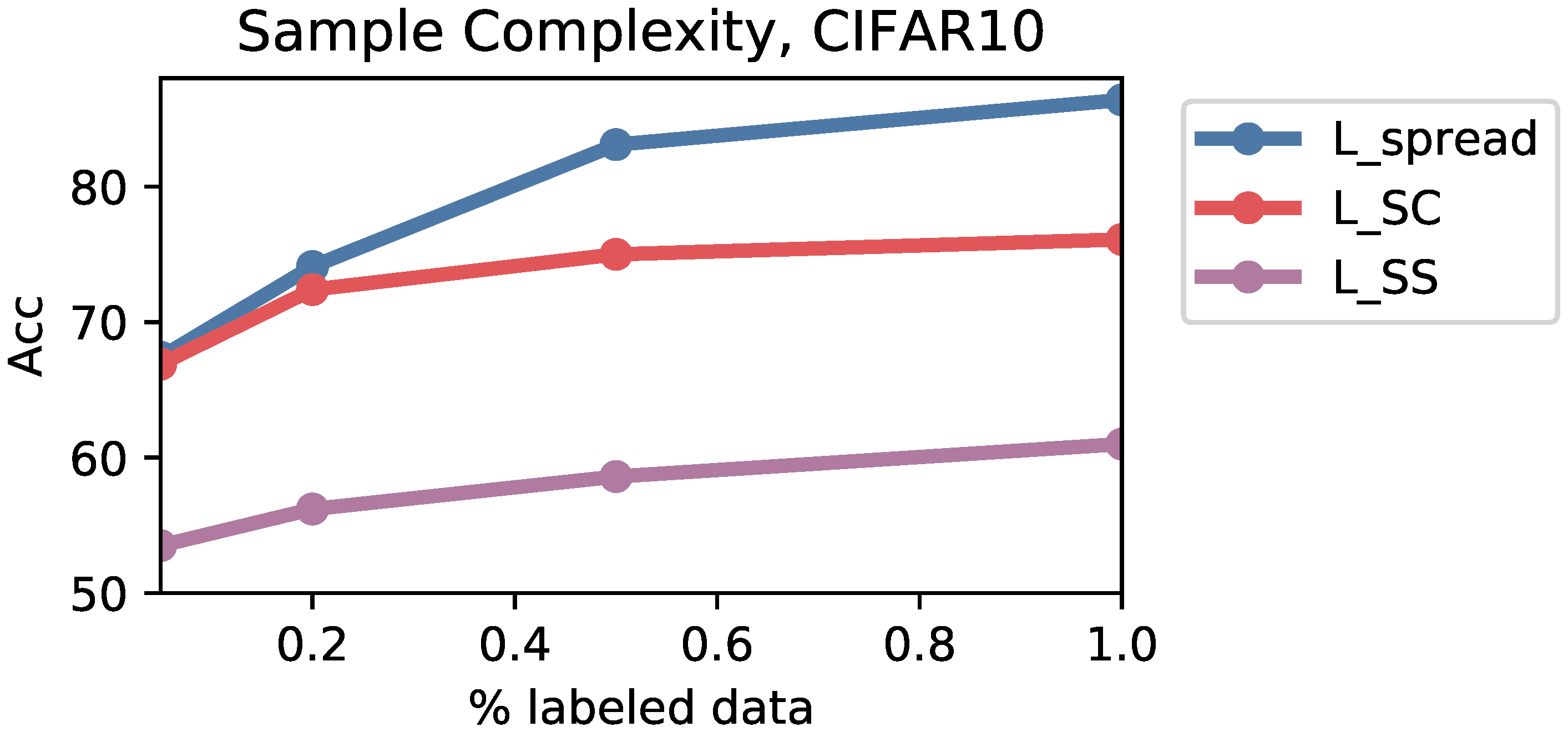
Appendix F.2. Sample Complexity
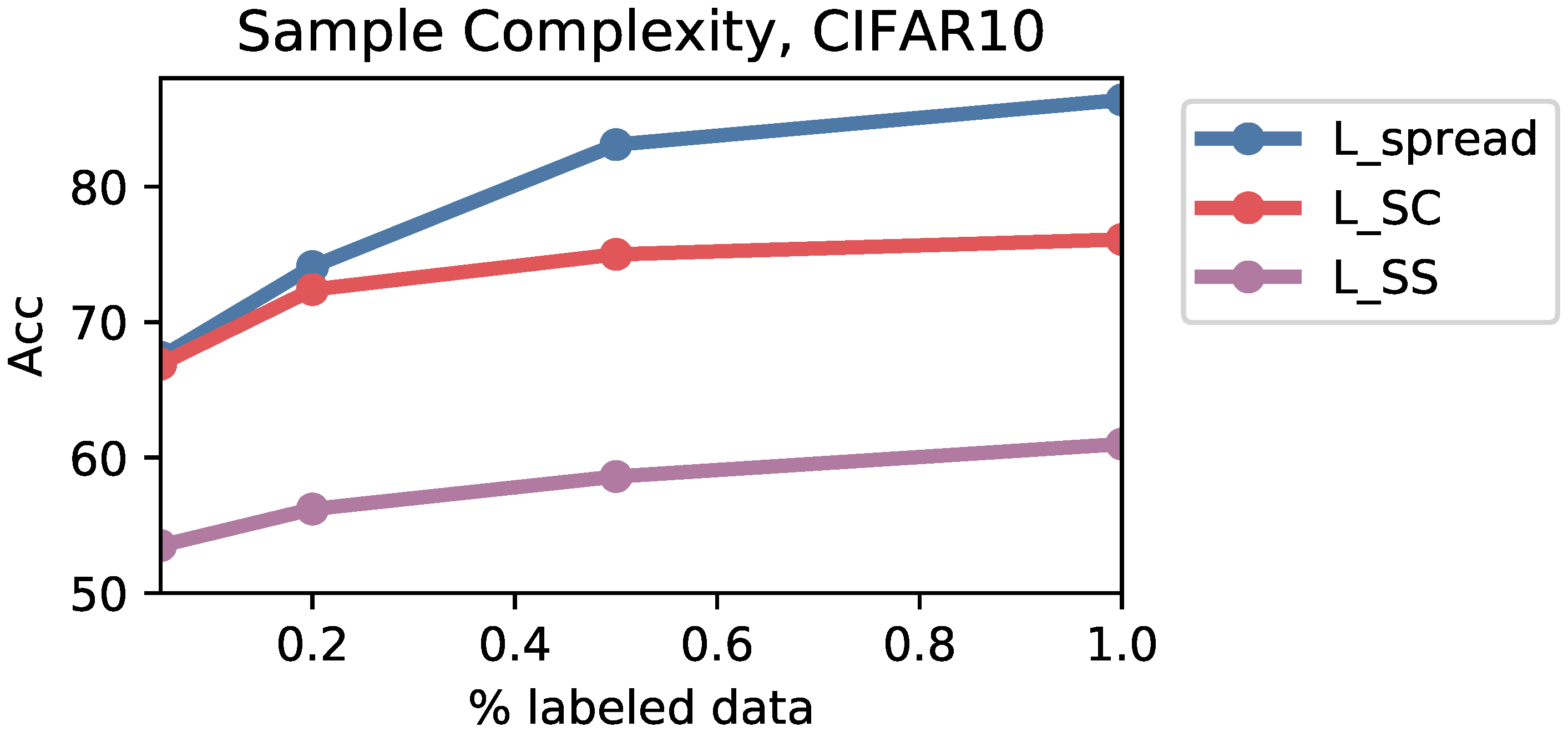
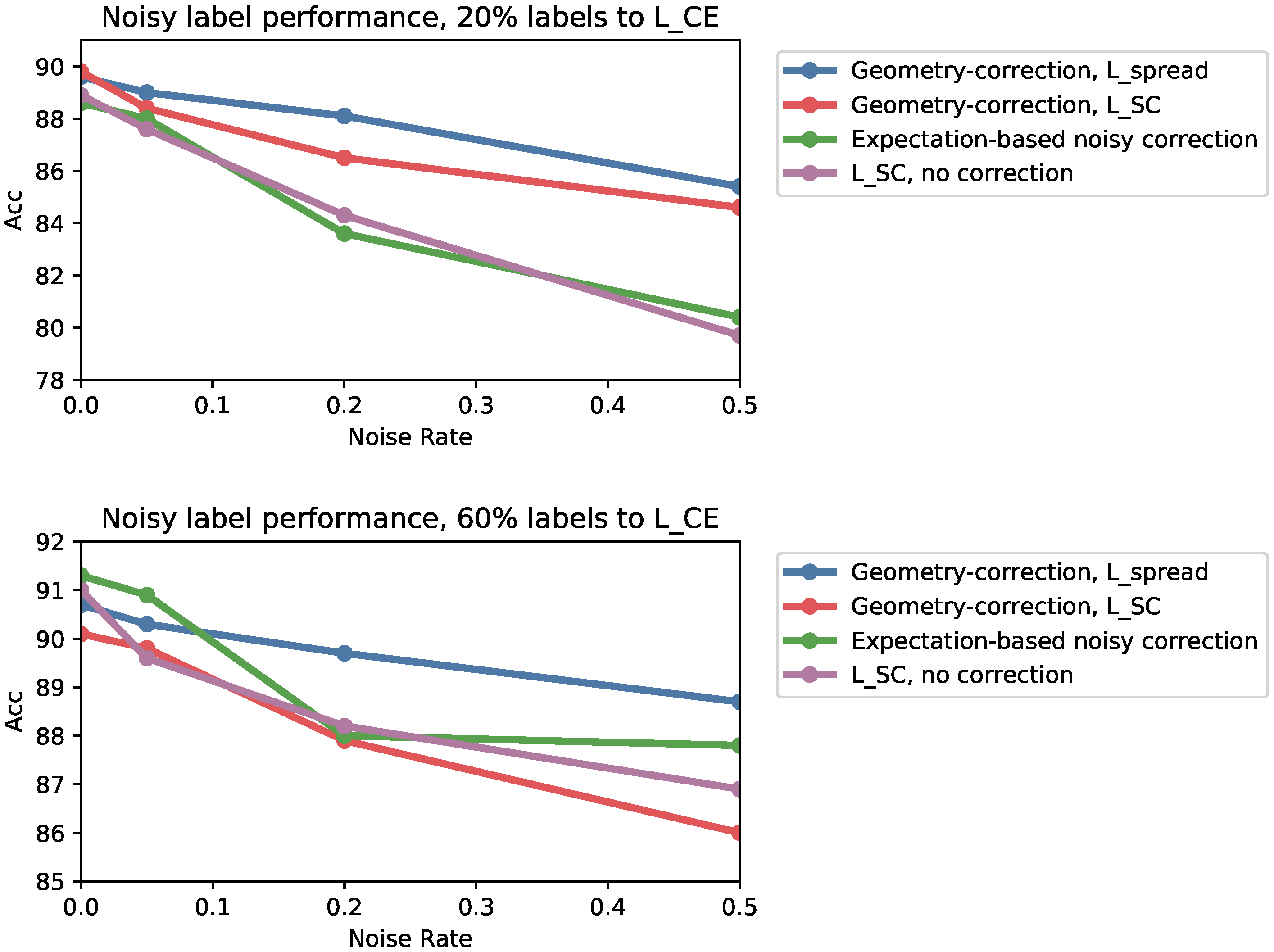
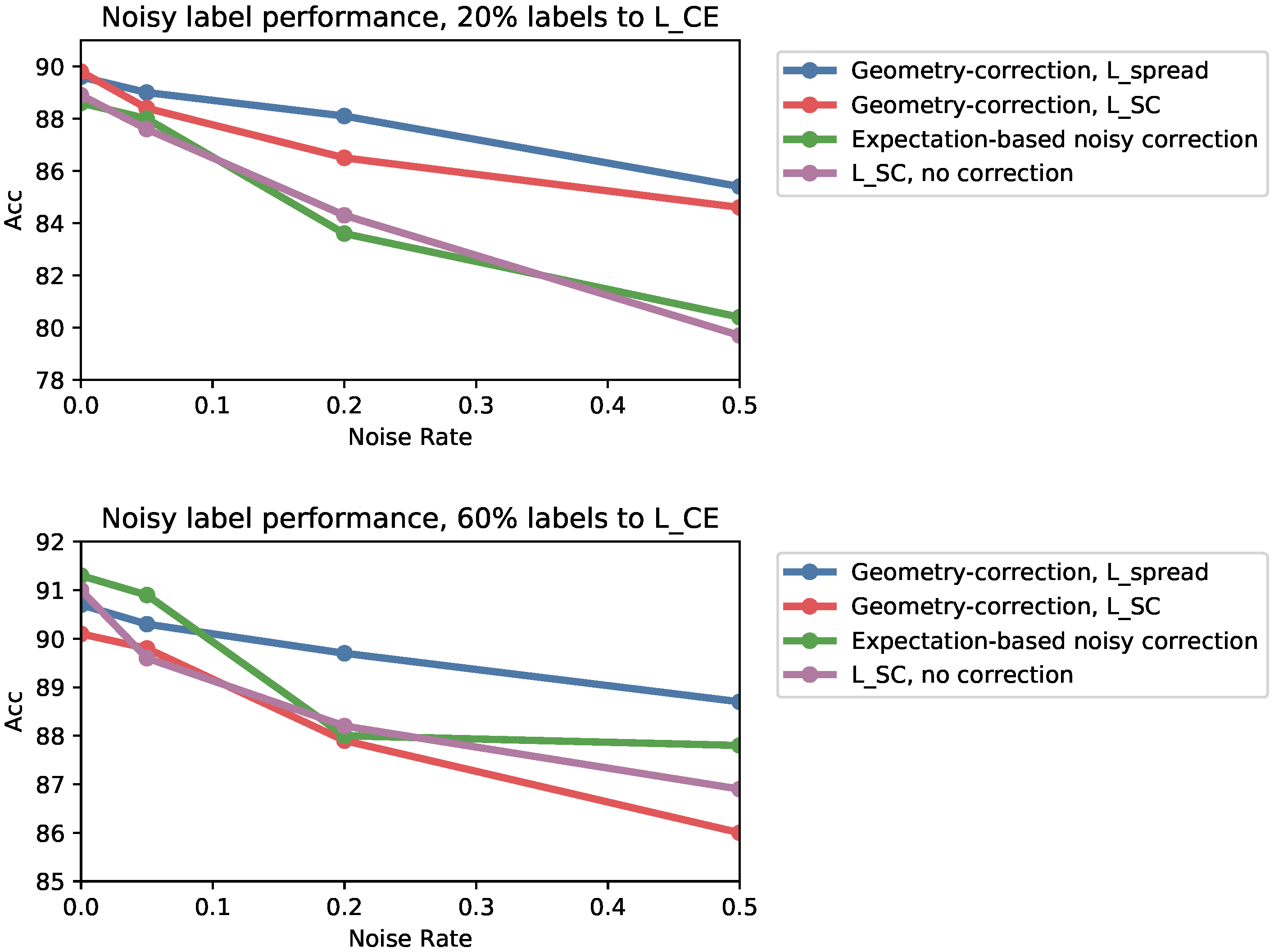
Appendix F.3. Noisy Labels
Appendix F.3.1. Debiasing Noisy Contrastive Loss
Noise-Aware Triplet Loss
Appendix F.3.2. Additional Noisy Label Results
References
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Mschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Graf, F.; Hofer, C.; Niethammer, M.; Kwitt, R. Dissecting Supervised Constrastive Learning. Proc. Int. Conf. Mach. Learn. PMLR. 2021, 139, 3821–3830. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. Commun. ACM 2016, 64, 107–115. [Google Scholar] [CrossRef]
- Hoffmann, A.; Kwok, R.; Compton, P. Using subclasses to improve classification learning. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2001; pp. 203–213. [Google Scholar]
- Sohoni, N.; Dunnmon, J.; Angus, G.; Gu, A.; Ré, C. No Subclass Left Behind: Fine-Grained Robustness in Coarse-Grained Classification Problems. Adv. Neural Inf. Process. Syst. 2020, 33, 19339–19352. [Google Scholar]
- Oakden-Rayner, L.; Dunnmon, J.; Carneiro, G.; Ré, C. Hidden stratification causes clinically meaningful failures in machine learning for medical imaging. In Proceedings of the Proceedings of the ACM conference on Health, Inference, and Learning, Toronto, ON, Canada, 2–4 April 2020; pp. 151–159. [Google Scholar]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. Proc. Int. Conf. Mach. Learn. PMLR 2020, 119, 9929–9939. [Google Scholar]
- Robinson, J.; Chuang, C.Y.; Sra, S.; Jegelka, S. Contrastive learning with hard negative samples. arXiv 2020, arXiv:2010.04592. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. Adv. Neural Inf. Process. Syst. 2007, 19, 137. [Google Scholar]
- Ben-David, S.; Urner, R. On the Hardness of Domain Adaptation and the Utility of Unlabeled Target Samples. In Proceedings of the 23rd International Conference, Lyon, France, 29–31 October 2012; Bshouty, N.H., Stoltz, G., Vayatis, N., Zeugmann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 139–153. [Google Scholar]
- Mansour, Y.; Mohri, M.; Rostamizadeh, A. Domain adaptation: Learning bounds and algorithms. arXiv 2009, arXiv:0902.3430. [Google Scholar]
- Sagawa, S.; Koh, P.W.; Hashimoto, T.B.; Liang, P. Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization. arXiv 2019, arXiv:1911.08731. [Google Scholar]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the Proceedings of International Conference on Computer Vision (ICCV), Santiago, Chile, 7 December 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Toneva, M.; Sordoni, A.; des Combes, R.T.; Trischler, A.; Bengio, Y.; Gordon, G.J. An Empirical Study of Example Forgetting during Deep Neural Network Learning. arXiv 2018, arXiv:1812.05159. [Google Scholar]
- Paul, M.; Ganguli, S.; Dziugaite, G.K. Deep Learning on a Data Diet: Finding Important Examples Early in Training. arXiv 2021, arXiv:2107.07075. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. Proc. Int. Conf. Mach. Learn. PMLR 2020, 119, 1597–1607. [Google Scholar]
- Arora, S.; Khandeparkar, H.; Khodak, M.; Plevrakis, O.; Saunshi, N. A theoretical analysis of contrastive unsupervised representation learning. arXiv 2019, arXiv:1902.09229. [Google Scholar]
- Zimmermann, R.S.; Sharma, Y.; Schneider, S.; Bethge, M.; Brendel, W. Contrastive Learning Inverts the Data Generating Process. arXiv 2021, arXiv:2012.08850. [Google Scholar]
- Chuang, C.Y.; Robinson, J.; Torralba, A.; Jegelka, S. Debiased Contrastive Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 8765–8775. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Tian, Y.; Sun, C.; Poole, B.; Krishnan, D.; Schmid, C.; Isola, P. What makes for good views for contrastive learning? arXiv 2020, arXiv:2005.10243. [Google Scholar]
- Tsai, Y.H.H.; Wu, Y.; Salakhutdinov, R.; Morency, L.P. Self-supervised Learning from a Multi-view Perspective. arXiv 2020, arXiv:2006.05576. [Google Scholar]
- Tschannen, M.; Djolonga, J.; Rubenstein, P.K.; Gelly, S.; Lucic, M. On Mutual Information Maximization for Representation Learning. arXiv 2019, arXiv:1907.13625. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. arXiv 2019, arXiv:1911.05722. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Goyal, P.; Caron, M.; Lefaudeux, B.; Xu, M.; Wang, P.; Pai, V.; Singh, M.; Liptchinsky, V.; Misra, I.; Joulin, A.; et al. Self-supervised Pretraining of Visual Features in the Wild. arXiv 2021, arXiv:2103.01988. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Islam, A.; Chen, C.F.; Panda, R.; Karlinsky, L.; Radke, R.; Feris, R. A Broad Study on the Transferability of Visual Representations with Contrastive Learning. arXiv 2021, arXiv:2103.13517. [Google Scholar]
- Bukchin, G.; Schwartz, E.; Saenko, K.; Shahar, O.; Feris, R.; Giryes, R.; Karlinsky, L. Fine-grained Angular Contrastive Learning with Coarse Labels. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19 June 2021; 2021. [Google Scholar] [CrossRef]
- d’Eon, G.; d’Eon, J.; Wright, J.R.; Leyton-Brown, K. The Spotlight: A General Method for Discovering Systematic Errors in Deep Learning Models. arXiv 2021, arXiv:2107.00758. [Google Scholar]
- Duchi, J.; Hashimoto, T.; Namkoong, H. Distributionally robust losses for latent covariate mixtures. arXiv 2020, arXiv:2007.13982. [Google Scholar]
- Goel, K.; Gu, A.; Li, Y.; Re, C. Model Patching: Closing the Subgroup Performance Gap with Data Augmentation. arXiv 2020, arXiv:2008.06775. [Google Scholar]
- Liu, S.; Niles-Weed, J.; Razavian, N.; Fernandez-Granda, C. Early-Learning Regularization Prevents Memorization of Noisy Labels. Adv. Neural Inf. Process. Syst. 2020, 33, 20331–20342. [Google Scholar]
- Li, J.; Xiong, C.; Hoi, S.C. Semi-supervised Learning with Contrastive Graph Regularization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11 October 2021. [Google Scholar]
- Ciortan, M.; Dupuis, R.; Peel, T. A Framework using Contrastive Learning for Classification with Noisy Labels. arXiv 2021, arXiv:2104.09563. [Google Scholar] [CrossRef]
- Li, J.; Socher, R.; Hoi, S.C. DivideMix: Learning with Noisy Labels as Semi-supervised Learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- Ju, J.; Jung, H.; Oh, Y.; Kim, J. Extending Contrastive Learning to Unsupervised Coreset Selection. arXiv 2021, arXiv:2103.03574. [Google Scholar] [CrossRef]
- Sener, O.; Savarese, S. Active Learning for Convolutional Neural Networks: A Core-Set Approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200. In Technical Report CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition using Places Database. Adv. Neural Inf. Process. Syst. 2014, 27, 487–495. [Google Scholar]
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3. [Google Scholar] [CrossRef]

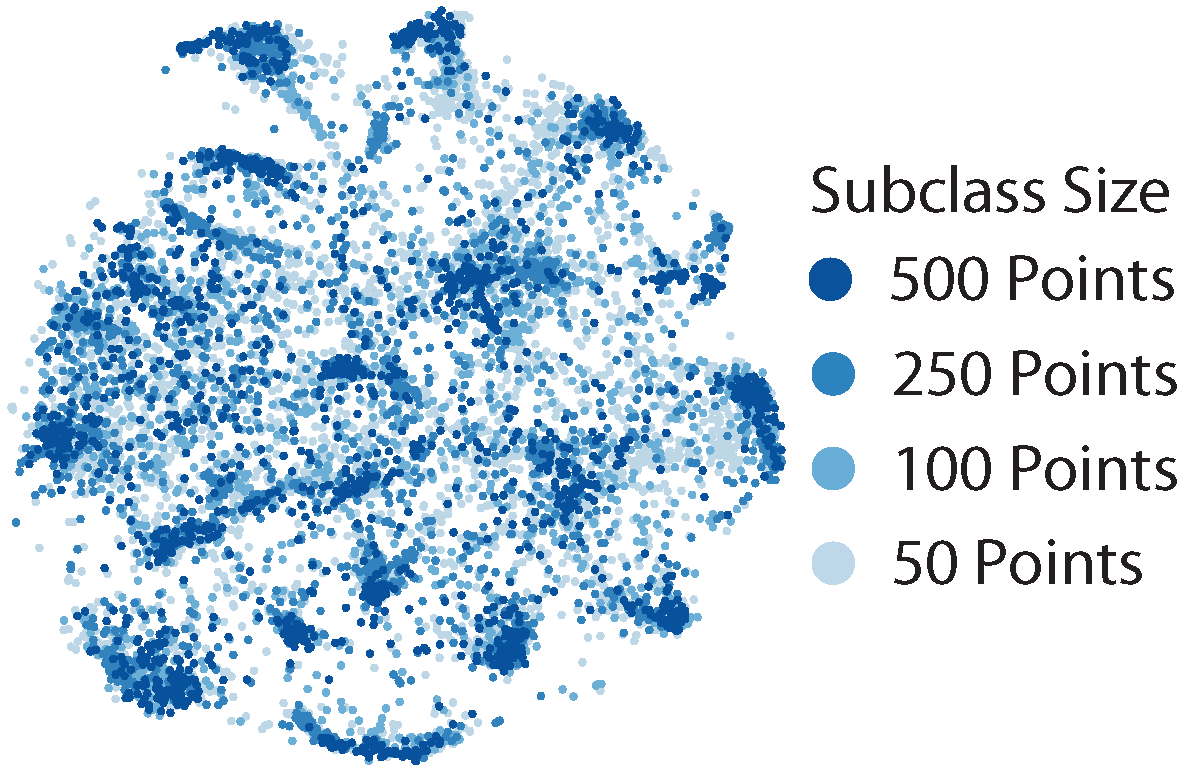
| Dataset | Notes |
|---|---|
| CIFAR10 | Standard computer vision dataset |
| CIFAR10-Coarse | CIFAR10 with animal/vehicle coarse labels |
| CIFAR100 | Standard computer vision dataset |
| CIFAR100-Coarse | CIFAR100 with standard coarse labels |
| CIFAR100-Coarse-U | CIFAR100 with standard coarse labels, but with some fine classes |
| sub-sampled | |
| MNIST | Standard computer vision dataset |
| MNIST-Coarse | MNIST with <5 and ≥5 coarse labels |
| Waterbirds | Robustness dataset mixing up images of birds and their |
| backgrounds [14] | |
| ISIC | Images of skin lesions [15] |
| CelebA | Images of celebrity faces [16] |
| Coarse-to-Fine Transfer | |||
|---|---|---|---|
| Dataset | |||
| CIFAR10-Coarse | 71.7 | 52.5 | 76.1 |
| CIFAR100-Coarse | 62.0 | 62.4 | 63.9 |
| CIFAR100-Coarse-U | 61.9 | 59.5 | 62.4 |
| MNIST-Coarse | 97.1 | 98.8 | 99.0 |
| Sub-Group Recovery | |||
|---|---|---|---|
| Dataset | Sohoni et al. [5] | ||
| Waterbirds | 56.3 | 47.2 | 59.0 |
| ISIC | 74.0 | 92.5 | 93.8 |
| CelebA | 24.2 | 19.4 | 24.8 |
| Worst-Group Robustness | |||
| Waterbirds | 88.4 | 86.5 | 89.0 |
| ISIC | 92.0 | 93.3 | 92.6 |
| CelebA | 55.0 | 66.1 | 67.8 |
| End Model Perf. | |||
|---|---|---|---|
| Dataset | |||
| CIFAR10 | 89.7 | 90.9 | 91.5 |
| CIFAR10-Coarse | 97.7 | 96.5 | 98.1 |
| CIFAR100 | 68.0 | 67.5 | 69.1 |
| CIFAR100-Coarse | 76.9 | 77.2 | 78.3 |
| CIFAR100-Coarse-U | 72.1 | 71.6 | 72.4 |
| MNIST | 99.1 | 99.3 | 99.2 |
| MNIST-Coarse | 99.1 | 99.4 | 99.4 |
| Waterbirds | 77.8 | 73.9 | 77.9 |
| ISIC | 87.8 | 88.7 | 90.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, D.Y.; Chen, M.F.; Zhang, M.; Fatahalian, K.; Ré, C. The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning. Comput. Sci. Math. Forum 2022, 3, 4. https://doi.org/10.3390/cmsf2022003004
Fu DY, Chen MF, Zhang M, Fatahalian K, Ré C. The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning. Computer Sciences & Mathematics Forum. 2022; 3(1):4. https://doi.org/10.3390/cmsf2022003004
Chicago/Turabian StyleFu, Daniel Y., Mayee F. Chen, Michael Zhang, Kayvon Fatahalian, and Christopher Ré. 2022. "The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning" Computer Sciences & Mathematics Forum 3, no. 1: 4. https://doi.org/10.3390/cmsf2022003004
APA StyleFu, D. Y., Chen, M. F., Zhang, M., Fatahalian, K., & Ré, C. (2022). The Details Matter: Preventing Class Collapse in Supervised Contrastive Learning. Computer Sciences & Mathematics Forum, 3(1), 4. https://doi.org/10.3390/cmsf2022003004