1. Introduction
The landscape of modern experimental physics is best conceived through the set of experimental tools that physicists use to interrogate space and matter. Historically, advances in instrumentation have been as significant as theoretical breakthroughs because the ability to perform new experiments allows scientists to pave over speculation with experimental proof. These advances are not always in hardware. Across techniques as diverse as ptychography [
1], astrophysical imaging, cryo-electron microscopy [
2,
3], and various super-resolution and nonlinear microscopy techniques [
4,
5,
6], instrumentation improvements require the integration of statistically sophisticated approaches to data analysis and acquisition. Over the last decade, analysis software tailored for individual experimental techniques has been a driving factor in bringing new analysis approaches into physical spectroscopies. In the domain of angle-resolved photoemission spectroscopy (ARPES) [
7,
8], the development of analysis and modeling toolkits such as PyARPES [
9] and chinook [
10], the integration of machine-learning-based denoising for ARPES spectra [
11,
12], and the continued development of new paradigms for the analysis of spectral data [
13] all signal continued advances in the interpretation of high-dimensional spectroscopy. While these software packages ease the interpretation of data after data collection, they do not currently permit an effective use of acquisition hardware.
Because rapid innovation in ARPES experiments is still ongoing—most recently in the development of submicron resolution beams for photoemission [
14,
15,
16] and the development of two-angle resolving time-of-flight electron analyzers [
17,
18,
19]—this separation may remain because there is a belief that integrating more complex analysis is unnecessary for the time being. After all, nanoARPES is revolutionizing our understanding of two-dimensional materials [
20], heterostructures [
21,
22,
23,
24,
25], and electronic devices [
26,
27,
28]. However, resolving the additional degrees of freedom in an experiment, as nanoARPES does by adding spatial resolution, usually makes contention for limited time on hardware worse and increases the demands on hardware apparatus for the efficient use of acquisition time. A minor reason for this is the greater demand for more capable experiments, but the real problem is fundamental: the curse of dimensionality means that experiments must record in sparser subsets of configuration space putting pressure on efficient use. The limited penetration of tightly integrated analysis and acquisition software in domains such as ARPES that might address this curse of dimensionality indicates friction and difficulty in tightly joining hardware and software. There are numerous benefits to be gained in more effectively using frequently limited acquisition time [
29,
30,
31], removing sources of systematic bias from physical experiments, serving as checksums against common experimental and sample problems [
32], and in allowing scientists to opt into collecting data driven by the statistical requirements of their analysis [
33,
34].
Scientists also actively interact with their data during an acquisition session by iteratively refining what they are measuring based on the data the experiment has yielded. Consequently, data acquisition is tightly integrated to a user interface (UI) controlling the acquisition session, to domain-specific data analysis tools, and to a large set of “application programming” concerns ranging from logging to data provenance. These are inviolable constraints for scientific data acquisition, but the burden they place explains the absence of universal approaches that more tightly integrate analysis, hardware, and software. It is vital to build software systems that allow scientists to restrict their attention to the issue of succinctly describing how hardware apparatus maps onto experimental degrees of freedom and sequencing data collection. Universal concerns—the thorny issues of user interfaces, data persistence, logging, error recovery, and data provenance—should be recycled because they are used across all scientific acquisition tasks. As things stand, most scientific DAQ software is purpose built to suit a given experiment with a vast amount of effort being spent on re-engineering solutions to the common concerns of the UI, persistence, and provenance. Because the exigency is for data, these concerns may not be addressed at all, especially in smaller university labs where DAQ software has usually evolved from existing LabVIEW VIs. When these issues are addressed, creating DAQ software may represent a substantial fraction of instrumentation effort and costs. Depending on the relative balance of hardware and personnel cost, DAQ engineering overheads may permit or inhibit novel experiments requiring synergistic combinations of hardware.
Here we present a new software system, AutodiDAQt, to address this problem space by providing a composable platform for describing DAQ systems. This new software system provides the necessary metaphors for tightly integrating scientific analysis and data acquisition and enabling analysis-in-the-loop and machine-learning-in-the-loop acquisition paradigms. This new system synthesizes the user interface and controls directly from the definitions of instrument drivers thereby reducing the problem of constructing scientific data acquisition software to the irreducible one of describing each instrument’s software interface and degrees of freedom. Because mature libraries and drivers for direct instrument control already exist [
35,
36,
37,
38], this reduces data acquisition software prototyping to a task that can be accomplished in a short period of time. Because it handles generating a user interface for instruments and for acquisition without end-user programming, AutodiDAQt is exceptionally well suited for writing DAQ software where scientists expect to be able to walk up to hardware and immediately start collecting data using the user interface, rather than by writing per experiment scan code.
Attempts to incorporate these needs in a flexible structure or to provide a general data acquisition framework for science [
36,
38,
39,
40,
41,
42], and to provide data acquisition systems serving a particular scientific discipline [
33,
34], have been adopted previously. For example, PyMeasure [
35], a data acquisition framework for physics, provides user interface generation primitives for data acquisition but does not confront the problem of data provenance or make it straightforward to compose and refine acquisition sequences. Bluesky [
43] and Auspex [
38] capture the essentials of composing acquisition routines and offer robust support for metadata, but Bluesky requires a significant amount of configuration code and neither framework provides user interface generation to achieve the application fluency appropriate for setting up experiments quickly in small labs. The approach we advocate in AutodiDAQt is a simple, low-code approach incorporating the strengths of PyMeasure (strong user interface support) and Bluesky (strong composability). AutodiDAQt is designed to be appropriate for rapidly creating and modifying scientific experiments and reflects the need for small-scale, flexible experiments that can be adapted to rapid advances in both hardware and data analysis software. This is in strict contrast to systems such as Bluesky which, based on different philosophy, emphasize the ability to adopt pieces of the acquisition system “à la carte” and thereby require software engineering work to integrate into a full-fledged DAQ application. This can be seen as a focus for AutodiDAQt and a distinguishing characteristic in a robust landscape of data acquisition software: AutodiDAQt excels at providing full data acquisition applications by restricting its focus to user interface generation, experiment planning, and downstream application programming consequences such as data provenance. In the following sections, we outline the ways in which AutodiDAQt adopts and extends the strengths of acquisition user interfaces and program composability. In the final section, we discuss how AutodiDAQt permits the control of the acquisition software directly by live analysis and also the prospects for this paradigm in ARPES.
2. Materials and Methods
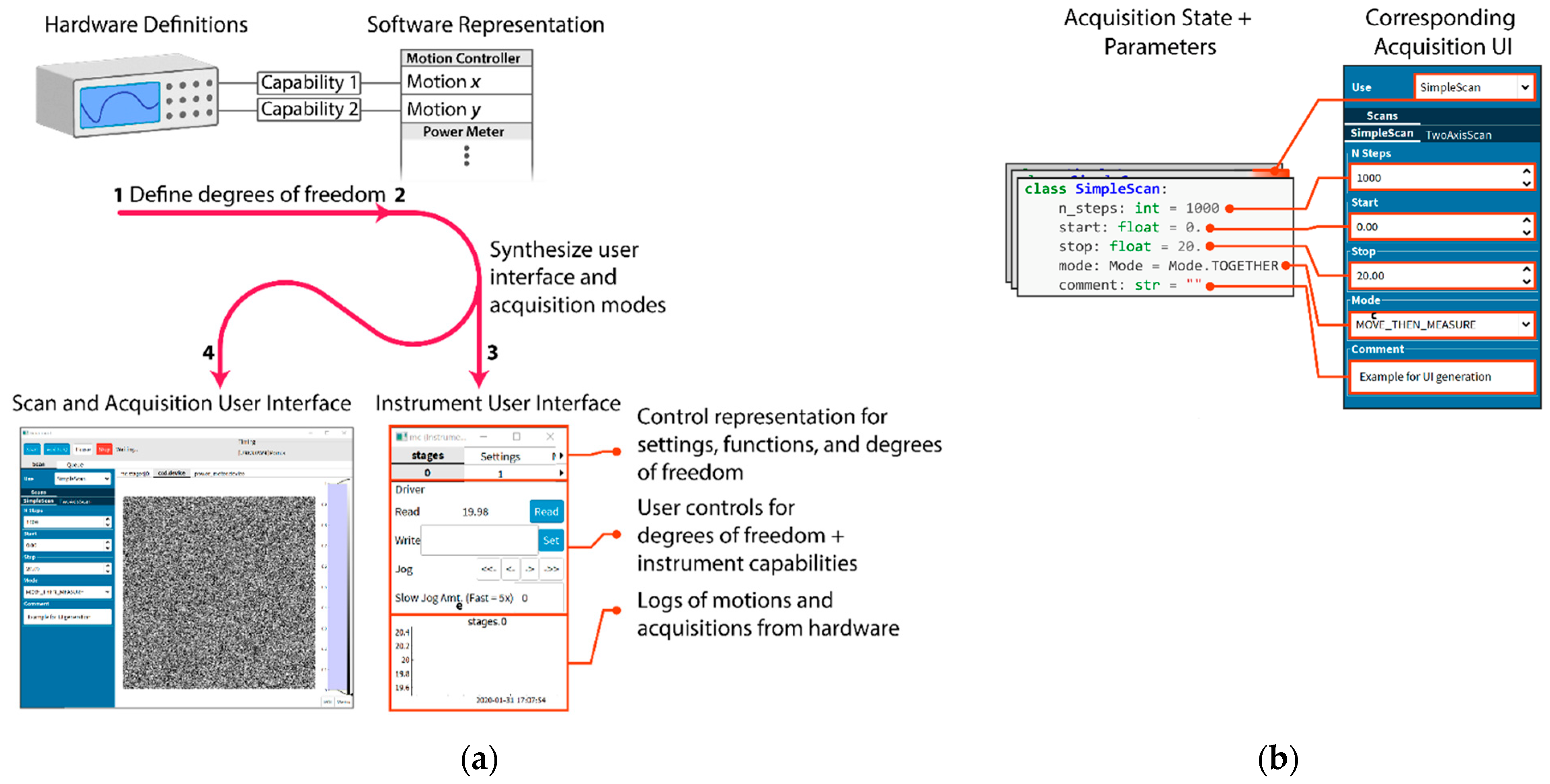
Relieving the burden of application programming from scientists requires automatically generating as much of the common user interface as is possible. AutodiDAQt leverages the highly structured nature of DAQ tasks to generate user interface (UI) elements for experiment parameters, collected values, data streams, and experimental apparatus. For this reason, AutodiDAQt uses schemas extending the Python-type system to provide control over data validation and data representation in the UI. At a coarser level, we recognize that writing DAQ software is an application programming task more than an algorithmic one and so provides high-level primitives for the UI that map onto application features where it is necessary or desirable to extend the default AutodiDAQt—for instance as the application needs to mature with an experiment. Experiment controls and acquisition interfaces are generated automatically (
Figure 1(a3)) together within the acquisition session manager (
Figure 1(a4)) just by defining the degrees of freedom in an experiment in terms of hardware capabilities exposed by instrument drivers (
Figure 1(a1)). Most significantly, AutodiDAQt generates controls, streaming plots, and virtual front panels for hardware (
Figure 1(a3)), obviating the need for UI programming, unless an experiment’s constraints are very unusual, through a combination of schema annotation and instrument driver specification. By defining these degrees of freedom, we will see in the following section that AutodiDAQt makes it straightforward to compose acquisition programs. Internal state and acquisition parameters of these programs are also associated automatically with user interface elements (
Figure 1b).
The following user interface programming tasks are requirements that have been carried out by scientists—creating front panels for instruments that are coherently linked with the acquisition system, creating control interfaces for different acquisition programs and their data streams, and linking the internal application state to user interface elements; however, AutodiDAQt can perform all of these just by defining the software representation of the hardware capabilities (
Figure 1(a1,a2) and
Supplementary Materials).
Composability
In AutodiDAQt, the structure of acquisition programs reduces the burden on scientists to prototype their acquisition software. Principally, AutodiDAQt automates experiment planning by using the definitions of the underlying experimental degrees of freedom in two ways. First, AutodiDAQt permits defining logical hardware atop physical hardware by expressing coordinate transforms and their inverse functions over physical hardware. This is exceptionally useful for sample positioning but carries the benefits of allowing the experimenter to attach physically meaningful coordinates to hardware, such as when a motion controller is used to implement an optical delay line and would prefer to work in temporal units instead of spatial units.
The second and most beneficial way is by permitting acquisition composition, effectively by running one acquisition program inside another, or by performing direct products over the configuration spaces of two acquisition programs. This facility, sometimes called sweep composition or acquisition strategies, is available in other software such as Auspex [
38] and Bluesky [
43]. However, AutodiDAQt coordinates exceptionally well with user interface generation, as it can also supply all the user interface elements required to populate the composite acquisition program (see
Supplementary Materials for an example). In practice, the composition of arbitrary acquisition programs is possible because AutodiDAQt separates the set of high-level instructions required to perform acquisition—which is what the scientist cares about—from the asynchronous runtime required to orchestrate the hardware and acquisition. This declarative approach—such as that adopted in Bluesky—has distinct advantages that make writing experiments more expressive and improves the durability and correctness of results. Acquisition sequences are automatically logged and recorded alongside the collected data, meaning the scientist can replay and retrospect the acquisition in ways that are very difficult, if not impossible, to accomplish without declarative separation. Acquisition sequences are automatically robust to changes in instrumentation because of inherent loose coupling. Because of this loose coupling, AutodiDAQt can also create mock instruments for prototyping by generating synthetic values according to their declared schema. This approach pushes error handling and recovery fully onto AutodiDAQt, which improves acquisition software robustness and correctness. Finally, the declarative approach makes it straightforward to allow an external analysis routine to specify the acquisition sequence, providing tighter feedback between data analysis and data acquisition while offloading analysis responsibilities that bloat and complicate data acquisition systems.
The core provision for modularity in AutodiDAQt comes from viewing the configuration space of the experiment as inheriting algebraic structure. Direct products of the degrees of freedom of the experiment define high-dimensional configuration spaces where data can be recorded. Analogously, direct products of coordinate intervals (e.g., one-dimensional sweeps) for these degrees of freedom correspond to acquisition programs that follow trajectories through this space.
3. Results
3.1. Analysis-in-the-Loop: Applications to ARPES
So far, we have described how AutodiDAQt provides application primitives that remove the burdens common to implementing correct and reliable data acquisition applications. In a large variety of scientific data acquisition tasks, the experimenter needs to iteratively refine the acquisition task based on the quality of data previously acquired or conditioned on features of the data identified by on-the-spot analysis. The most straightforward approach is to integrate appropriate analysis tools directly into the acquisition suite. However, this approach is fundamentally flawed because the software used to make DAQ systems (LabVIEW, systems languages, and asynchronous runtimes) is ill-suited to analysis. In addition, placing burden on the acquisition runtime can cause errors and even pose safety risks, as analysis code typically has less rigor and minimal quality control when compared to the code managing hardware. As a practical matter, the inclusion of analysis tools further complicates analysis for scientists at user facilities, who cannot plug their favorite analysis tools directly into the acquisition suite and must instead learn to use an additional system to perform their work under time constraints. A safer approach that simultaneously makes better use of the rich scientific data ecosystem built-in languages such as Python is to isolate analysis from acquisition but to make data available for analysis in open formats during the data acquisition session and even before data are written to disk.
AutodiDAQt addresses this issue by providing no programming interface to facilitate real-time analysis in the acquisition framework. In fact, AutodiDAQt performs minimal handling of data and encourages direct retention of the analysis log as the experimental ground truth. This approach provides high runtime performance and better correctness guarantees. Instead, AutodiDAQt provides a client library, AutodiDAQt Receiver, which runs alongside AutodiDAQt across a message broker. The receiver collates data during an acquisition into an analysis process running on the same or a remote computer and can issue control instructions driven by an experimenter’s analysis. The receiver can also dispatch predefined experiments, as through the application UI. In practice, the receiver can issue, write, and read commands using the same API as when manual experiment planning is used in AutodiDAQt directly (see examples in the receiver codebase and the AutodiDAQt codebase). Partial data are available on the receiver as a convenient xarray. Dataset instance containing all prior data received from the runtime.
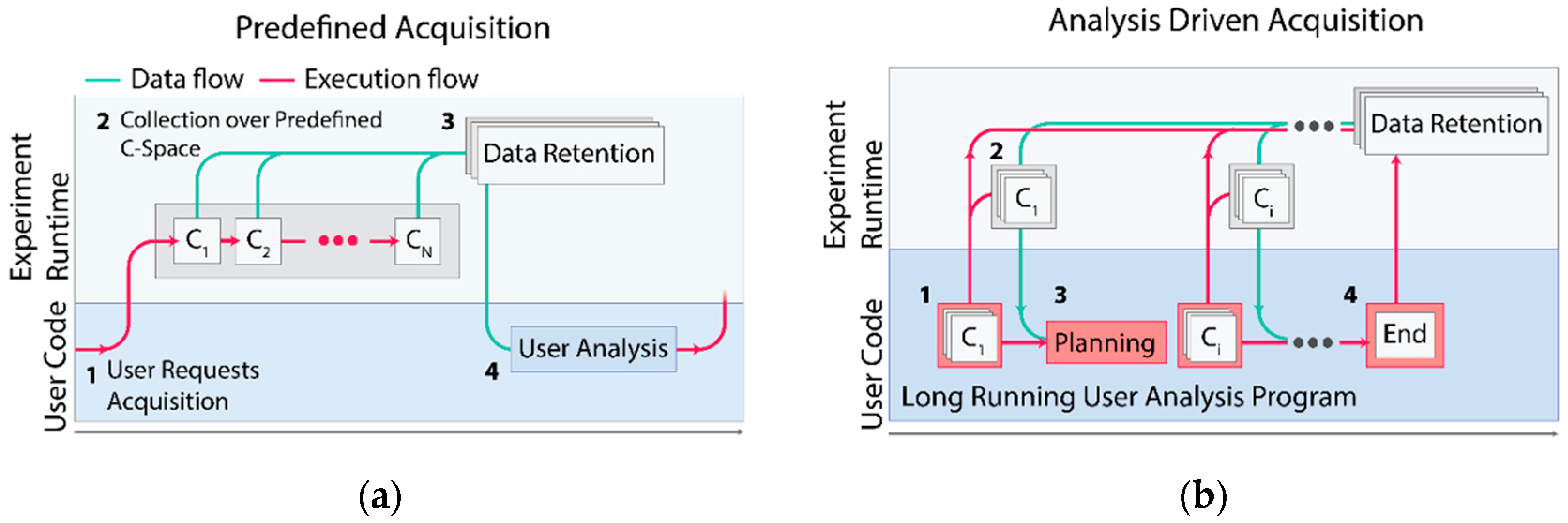
With this change, it becomes apparent to perform complex acquisitions under one of two different paradigms for data acquisition. Under the traditional paradigm, users can select a predefined acquisition program and issue collection over a predefined collection of experimental configurations (
Figure 2a). Next, they can analyze their data before making further decisions about what data to collect. Alternatively, the fine-grained decisions about the next data point to collect can be made by a user analysis program running asynchronously on AutodiDAQt Receiver, as is shown in
Figure 2b. The ability to perform acquisitions driven by analysis, or simply to rapidly adapt the acquisition in response to the experimental data, provides a leap in capability and experimental efficiency. Because data are available during acquisition, the experimenter is free to begin analysis and decision making using whatever tools they are most comfortable with.
It pays to be concrete, so here we will consider two examples that stem from photoemission spectroscopy. By considering nanoARPES and nanoXPS, where regions with distinct electronics and morphology require efficient use of acquisition time, we will explore two approaches that permit the rapid acquisition and interpretation of data. Using time-resolved ARPES (TARPES), we will see how the approach can improve the reliability and fidelity of recorded data and reconfigure the acquisition to defeat hardware limitations.
3.2. Application to NanoXPS
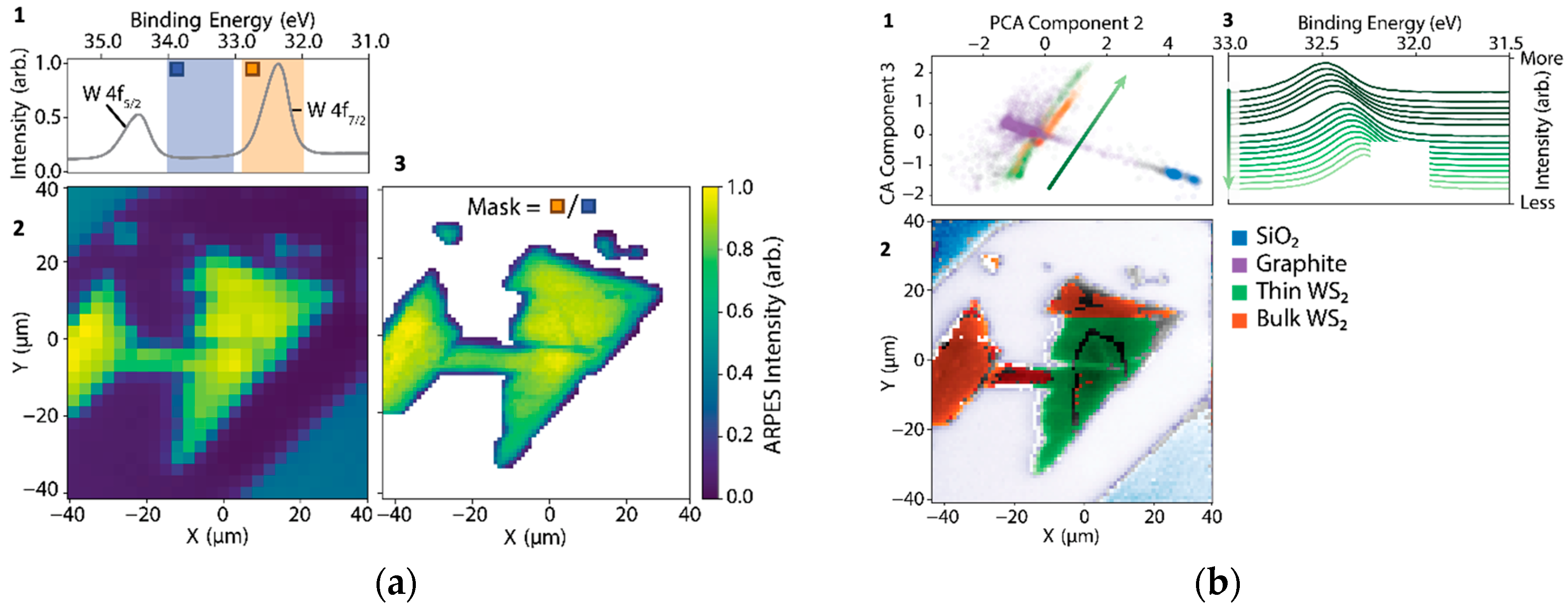
In
Figure 3a(1–3), we show how even rudimentary applications of the analysis-in-the-loop would provide gigantic efficiency gains over data that were collected under standard acquisition controls. In
Figure 3(a1), core-level spectra from a multilayer sample of WS
2 were collected by coarsely rastering over a sample surface (
Figure 3(a2)) using a nanoXPS setup. In the conducted experiment, which was performed with traditional DAQ software roughly following the scheme of
Figure 2a, the resolution was increased by a factor of nine to resolve details in the sample morphology. However, analysis-in-the-loop, which adaptively increases the resolution only on a sample region with intense W 4f core levels (orange divided by blue regions in
Figure 3(a1)), would have permitted acquiring data over only relevant portions of the sample, shown in
Figure 3(a3), and would have used only 37% of the total acquisition time as was used in the measurement.
Other more sophisticated schemes, falling under the broader umbrella of machine-learning-in-the-loop, have been explored. One approach class based on Gaussian process (GP) regression has already demonstrated progress toward autonomous experimentation in photoemission spectroscopy [
29]. Autonomous GP regression assumes, however, that all sources of variance in experimental data are salient, whereas most are not and can be rejected instantly by a domain expert. This contention between automation and domain expertise is likely to prevent the wide application of fully autonomous experimentation for a long time to come, with narrow exceptions for well-defined experimental tasks. Human-in-the-loop methods, which improve the decision-making power of scientists, are a more capable middle ground and promise to improve throughput while targeting the specific needs of scientists. Of course, these approaches can include machine learning, especially that used for exploratory data analysis.
Figure 3b(1–3) illustrate an approach covering the same problem space as discussed in
Figure 3a(1–3).
Figure 3b1 shows a principal component analysis (PCA) decomposition of the XPS curves from the same sample region. Colored scatter cohorts are identified by visual clustering and correspond to sample morphology and content in
Figure 3(b3). Although not principled in the sense of accurately modeling the experimental data’s distribution, rudimentary decompositions such as PCA rapidly provide insight that drives the efficient use of acquisition time. Decomposition features are also frequently highly correlated with relevant sample physics even if they provide no causal or generative information: in
Figure 3(a3), it is apparent that PCA has identified a proxy for the inhomogeneous doping variations on the WS
2 sample. In this scheme, machine learning is used for the rapid surveying and summarization of datasets, optimizing the use of available scientific expertise for decision making.
3.3. Application to Pump-Probe ARPES
Alternatively, the analysis-in-the-loop approach provides scientists with the ability to rapidly adapt to changes in experimental conditions and to remove dataset bias, by treating software as a malleable tool rather than a fixed constraint. To give an example where this is valuable, we now turn to issues of systematic bias arising in pump-probe ARPES experiments. Because fourth harmonic or high harmonic generation is common in attaining DUV and XUV pulses from Ti:Sapph lasers, pump-probe ARPES experiments are especially susceptible to laser intensity fluctuations. These fluctuations can create confounding effects where infrared and UV doses can be highly correlated with measured delay time. These issues compound with other nonlinearities in the photoelectron detection process [
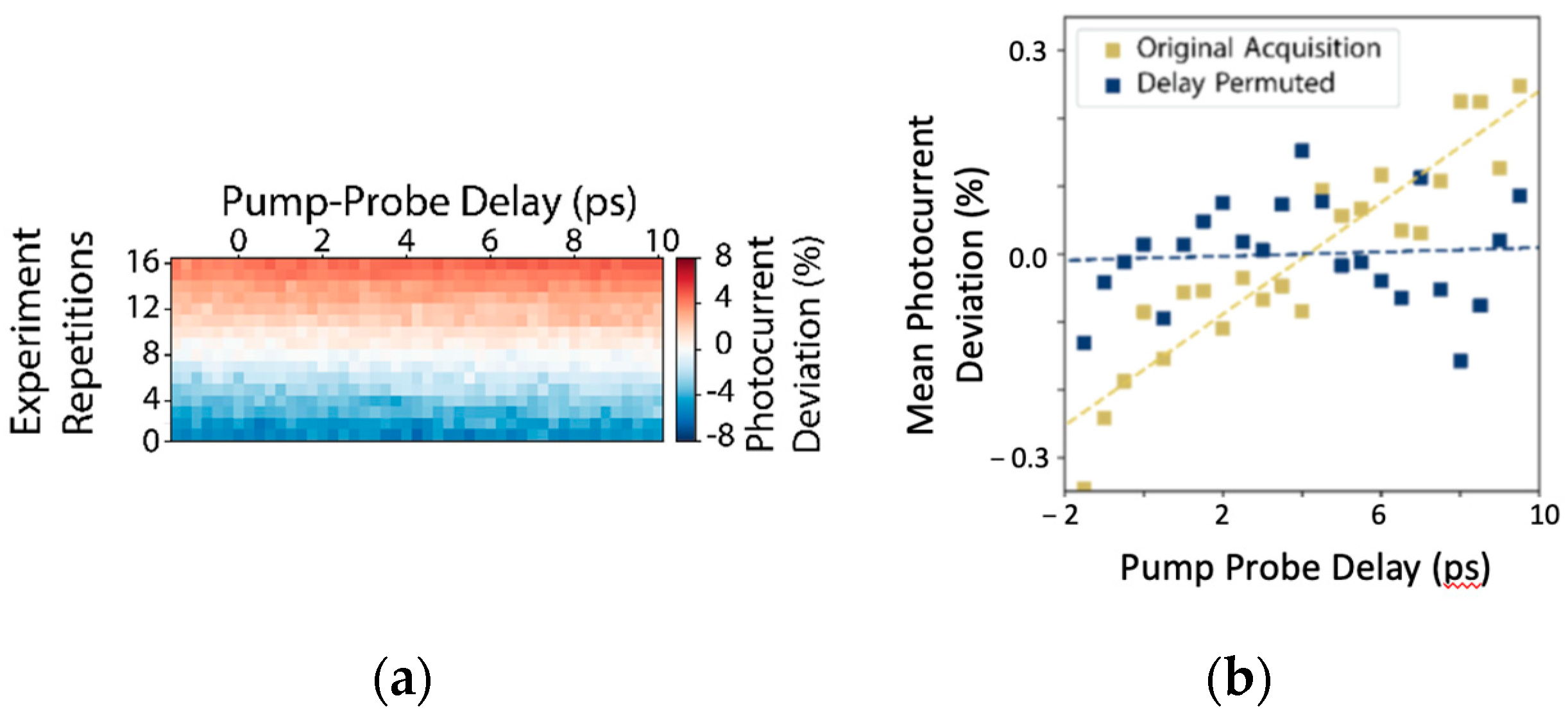
44]. One very common way of minimizing this effect, if stabilizing the source power is not feasible, is to repeat the experiment in many short repetitions so that transients are better spread across different delays. Although not guaranteed to remove the correlation between delay and laser power, this approach is very common on photoemission apparatus because it is simple to shoehorn it into complicated data acquisition software merely by running additional sweeps. The resulting total dose delivered can be visualized in this scheme for an actual experiment in
Figure 4a. Despite the appearance that this minimizes the effects of transients, when we average data across repetitions, we see that there is still a pernicious dependence of mean dose, measured by total photoelectron yield, as a function of the experimental delay, as in
Figure 4b. Properly removing the bias requires stratifying individual experimental runs by dose cohort and randomly shuffling the acquisition order so that there can be no correlation. Adaptively accommodating these kinds of responses to issues arising during acquisition requires a dynamic and cooperative approach between acquisition and analysis. In this narrow case, AutodiDAQt provides support for acquisition shuffling in either of the supported acquisition paradigms.
In the broader context, deeper cooperation between DAQ-aware user analysis programs, such as PyARPES [
9] in the context of angle-resolved photoemission spectroscopy, permit scientists to rapidly define acquisitions over trajectories that are challenging to define without expert knowledge. In this approach, it is straightforward to collect data along a particular path in a given material’s 2D surface Brillouin zone, or in the 3D bulk Brillouin zone.
4. Discussion
AutodiDAQt makes some assumptions about the data acquisition task to simplify the acquisition runtime. Significantly, because AutodiDAQt implements the acquisition runtime as a set of asynchronous tasks running on a single process, AutodiDAQt assumes that reads from instrumentation are IO bound rather than CPU bound. Although this is not a strict assumption, communication with another process that is set up during the application startup is still possible, circumventing this assumption requires that the end user take care of any multitasking concerns arising out of the partial adoption of multiprocessing.
Despite this constraint, the AutodiDAQt runtime is a very low overhead, as can be verified by running the profiling benchmarks included in the source repository. Benchmarks are always machine dependent, but on plain consumer hardware available at the time of publication, the overhead per experimental configuration (“point”) is in the order of when running an acquisition generating synthetic data from a 250 px by 250 px virtual CCD. As AutodiDAQt is not intended for applications that need to operate instruments in closed loop control or collect data in real-time, overheads of less than one millisecond per point makes the use of multiprocessing unnecessary for most experiments. AutodiDAQt achieves this level of performance by running UI repainting infrequently, using the Qt event loop in place of the standard library event loop, and by performing essentially no data bookkeeping other than memory allocation during an experimental run. All data collation and transformation is deferred to a separate process once an experiment is complete.


{kind=link}
{kind=link}
{kind=link}
{kind=link}



