

Approach to Formalizing Software Projects for Solving Design Automation and Project Management Tasks

Abstract
1. Introduction
- Understanding the context of some problem area (domain).
- Designing a domain model and design space.
- The formation of some understanding of the context as design artifacts.
- The designers did not fully form the CS at the initial stages of the project;
- The designers did not discuss the functional requirements with the customer;
- There is not enough time to conduct usability testing.
- It is necessary to develop a model and methods for building a knowledge base to collect the experience of previous projects to support the processes of software design and construction;
- It is necessary to develop a method of diagnostic analytics for the evaluation of the project development processes to improve the quality and efficiency of management decisions.
- A high level of uncertainty when a project is developed for a new domain or when using new architectural approaches or technologies.
- The influence of the external environment on the development process, including an unexpected reduction in resources.
- A lack of necessary competencies among team members.
- The need for the rapid assessment of numerous factors affecting the success of the project and the quality of project management decisions.
2. State of The Art
- A metamodel for the scope model kind;
- A metamodel for the user model kind;
- A metamodel for the environment model kind.
- Ralph P. The sensemaking-coevolution-implementation theory of software design [2].
- Sosnin P. Substantially evolutionary theorizing in designing software-intensive systems [3].
- Bedjeti A.; Lago P.; Lewis G.A.; De Boer R.D.; Hilliard R. Modeling context with an architecture viewpoint [9].
- Di Noia T.; Mongiello M.; Nocera F.; Straccia U. A fuzzy ontology-based approach for tool-supported decision making in architectural design [14].
- Schermann G.; Zumberi S.; Cito J. Structured information on state and evolution of dockerfiles on GitHub [18].
- Xia T.; Fu W.; Shu R.; Agrawal R.; Menzies T. Predicting health indicators for open source projects (using hyperparameter optimization) [19].
- Design artifacts;
- The project’s compliance with the requirements and constraints of some domain;
- The influence of various indicators and management decisions to the project development process;
- Their cumulative influence on each other.
3. Materials and Methods
- The ability to quickly respond to changing customer requirements;
- An operative demonstration of the new software functionality to customers for evaluation, clarifications, and adjustments;
- An increase in the efficiency of managerial decisions.
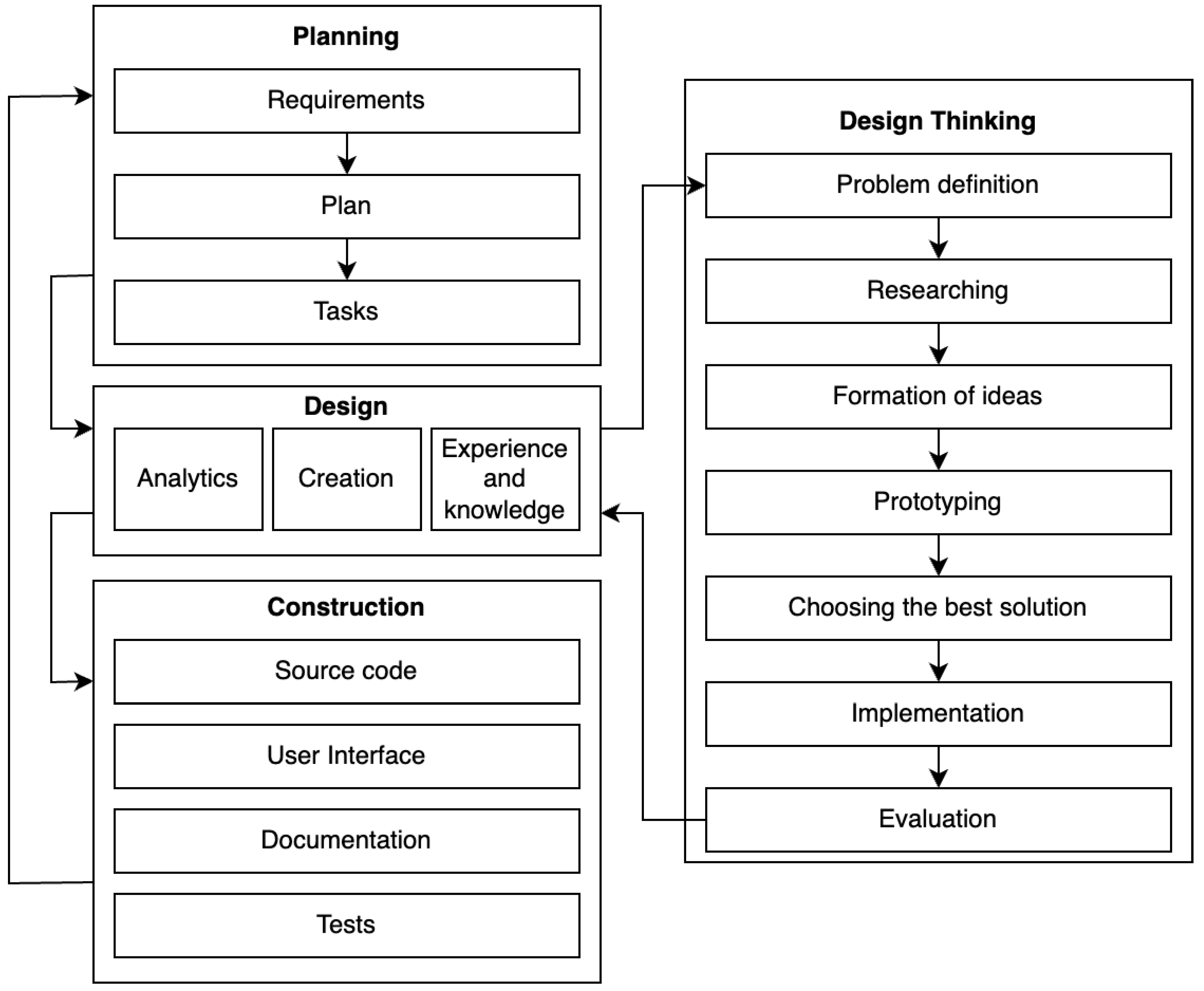
- Problem definition.
- Researching.
- The formation of ideas.
- Prototyping.
- Choosing the best solution.
- Implementation.
- Evaluation.
- Planning.
- Design.
- Construction.
- The result of the planning stage depends on the quality of the analysis of functional and non-functional requirements [4], as well as on the quality of management decisions. We can represent management decisions as a set of tasks for developers and as a set of team management decisions. The project manager at the planning stage must consider the limitations of the resources, the limitations of the real world (domain), and the quality requirements.
- The result of the design stage depends on the planning stage and the qualifications of designers. Moreover, the design stage is a creative process in terms of the DT methodology, which requires the development of automated CS generation tools [2,3]. As you can see from the review of publications about the study, the use of methods of intellectual analysis and knowledge engineering makes it possible to automate the design stage based on the formalization of the experience of previous projects.
3.1. Knowledge Base Model for Formalizing of the Experience of Previous Projects
- A requirement to meet stakeholder needs;
- Project constraints;
- Quality attributes;
- Architectural decisions;
- Aims and goals;
- Stakeholder expectations, etc.
- As a basis for the design and construction processes of a software system;
- As a basis for the analysis and evaluation of alternative implementations of an AD;
- As documentation in the development and maintenance processes of a software system;
- To document significant aspects of a software system;
- As input to automated tools for modeling, system simulation and analysis;
- To define a group of software systems that have common properties (for example, architectural styles, reference architectures, and product line architectures);
- For communication between the teams involved in software system development;
- To provide communication between customers and developers;
- To document the characteristics, properties, and features of a software system;
- As a basis for planning the transition from a legacy architecture to a new one;
- As a guide to operational and infrastructure support and the configuration management of a software system;
- To support system planning and activities related to timelines and budgets;
- As a basis for audits, analysis, and evaluation of a software system;
- As a basis for the analysis and evaluation of alternative architectures;
- For reusing the architectural knowledge through points of view, patterns, and styles;
- To educate stakeholders on best practices for architecting and development.
- The concepts of a domain;
- The features of design artifacts formalized as knowledge base fragments;
- The features of the development process as the main stages of a software system life cycle;
- Sets of semantic relations between knowledge base entities;
- Interpretation functions.
- ⊤ is a special class with every individual as an instance (top);
- ⊥ is an empty class (bottom);
- is the class inclusion axiom (A is a subclass of B);
- is the disjoint classes axiom;
- is the intersection or conjunction of axioms (classes or roles);
- is the universal restriction axiom;
- is the existential restriction axiom;
- is the functional roles axiom;
- is the inverse roles axiom;
- is the transitive roles axiom;
- is the irreflexive roles axiom.
- A set of classes for describing the following:
- −
- Milestone—;
- −
- Issue—;
- −
- Merge/pull request—;
- −
- Branch—;
- −
- Commit—;
- −
- Contributor—;
- −
- File— (this is a part of the representation of the software project structure ).
- The class has the following:
- −
- The , , , and roles to specify ties between a project and a set of its milestones, merge/pull requests, issues, and branches;
- −
- The and transitive roles to define ties between a project and a set of its commits and contributors;
- −
- The functional role to specify a tie between a project and its description:
- The class has the following:
- −
- The , , and roles to specify ties between a milestone and a set of its merge/pull requests, issues, and comments;
- −
- The functional role to specify a tie between a milestone and its description;
- −
- The inverse functional role to define a tie between a milestone and its project:
- The class has the following:
- −
- The and roles to specify ties between an issue and a set of its contributors and comments;
- −
- The functional role to specify a tie between an issue and its description;
- −
- The , , , and inverse functional roles to define ties between an issue and its milestone, merge/pull request, branch, and project:
- The class has the following:
- −
- The and roles to specify ties between a merge/pull request and a set of its issues and comments;
- −
- The functional role to specify a tie between a merge/pull request and its description;
- −
- The , , and inverse functional roles to define ties between a merge/pull request and its milestone, branch, and project;
- −
- The and transitive roles to define ties between a merge/pull request and a set of its commits and contributors:
- The class has the following:
- −
- The , , and roles to specify ties between a branch and a set of its commits, merge/pull requests, and issues;
- −
- The inverse functional role to define a tie between a branch and its project:
- The class has the following:
- −
- The functional role to specify a tie between a commit and its contributor;
- −
- The and roles to specify ties between a commit and a set of its comments and modified files;
- −
- The and inverse functional roles to define ties between a commit and its branch and project;
- −
- The and functional roles to specify a tie between a commit and its description and date:
- The class has the following:
- −
- The , , and roles to specify ties between a contributor and a set of its issues, commits, and requests;
- −
- The inverse functional role to define a tie between a contributor and its project:
- A set of classes for describing the following:
- −
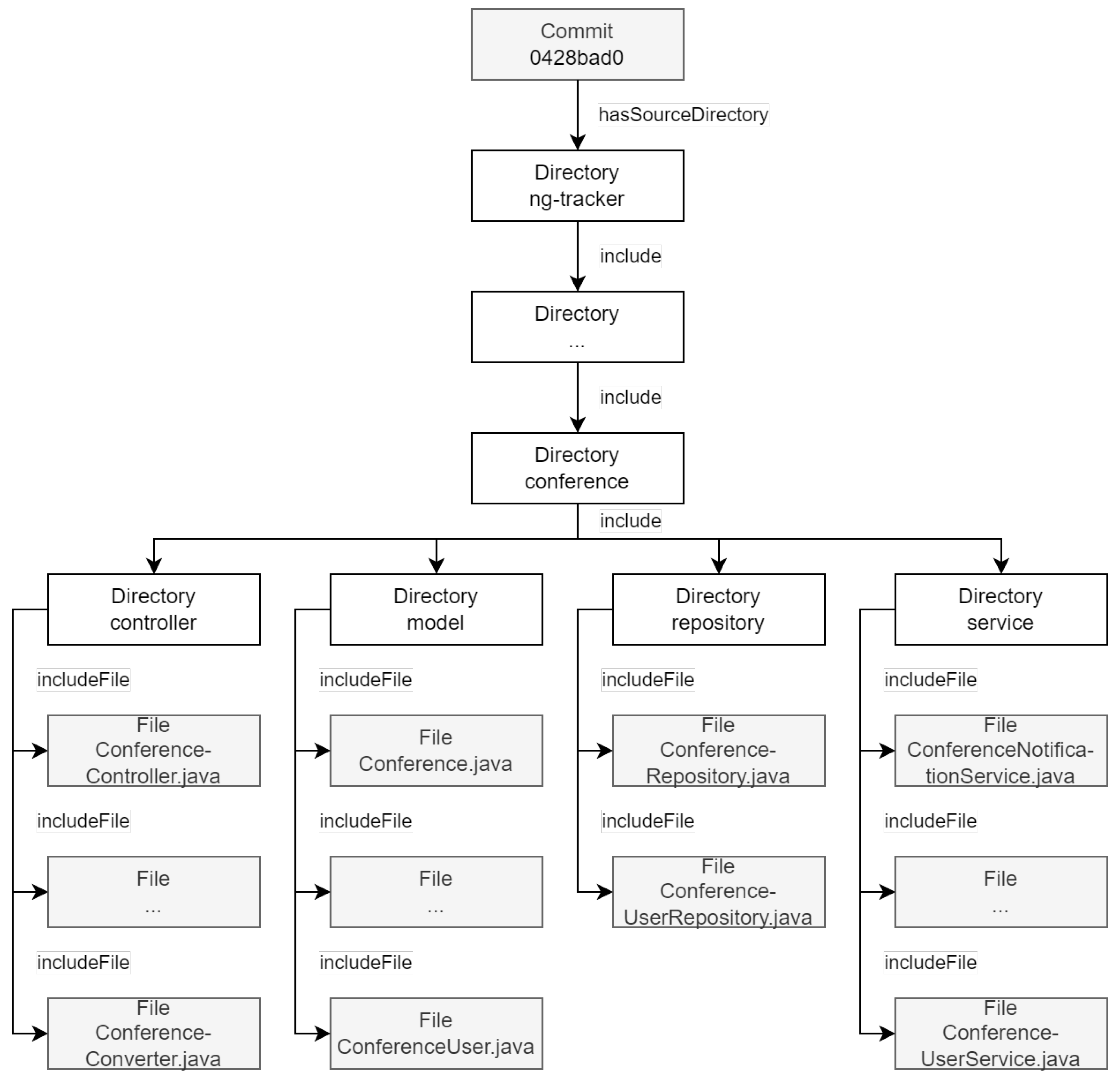
- Directory—;
- −
- File—;
- −
- Commit— (is a part of the representation of the project development process );
- The class has the and functional roles to define ties between a commit and its source directory and build file:
- The class has the following:
- −
- The irreflexive role to specify ties between a directory and a set of its subdirectories;
- −
- The role to define a ties between a directory and a set of its files:
- A set of classes for describing the following:
- −
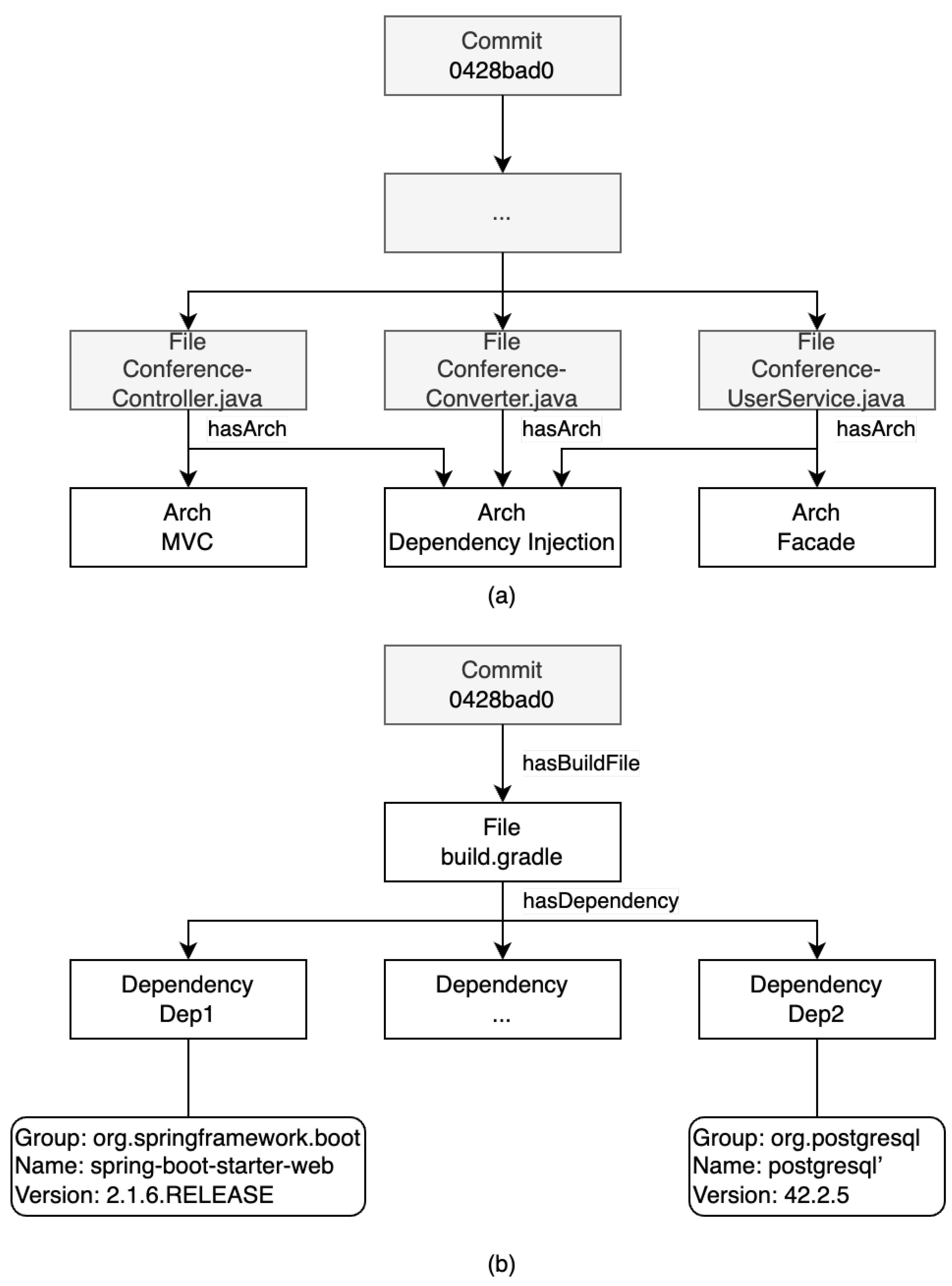
- Architecture styles or design patterns—. The set is defined using an enumerated class. The enumerated class contains a list of architectural styles and design patterns for which we develop the search and analysis method;
- −
- Third-party dependencies of a software project (libraries, frameworks, external services, database management systems, etc.)—;
- −
- File— (this is a part of the representation of the software project structure ):
- The class has the and roles to specify ties between a file and a set of its architecture styles or design patterns and third-party dependencies:
- The class has the , , and functional roles to define the dependency properties (group, name, and version):
- A set of classes for describing the following:
- −
- Domain entities—;
- −
- Domain business processes—;
- −
- File— (this is a part of the representation of the software project structure ).
- The class has the and roles to specify ties between a file and a set of its entities and business processes:
- The class has the role to define a tie between an entity and a set of its business processes:
- A set of classes for describing the following:
- −
- Domain concepts—. Concepts describe various entities and processes of some domain;
- −
- Terms that describe a domain concept—. Terms allow us to associate the names of various software project objects with the concepts of the linguistic environment;
- −
- Domain entities— (this is a part of the representation of domain features );
- −
- Domain business processes (this is a part of the representation of domain features ).
- The and classes have the functional role to specify a tie between an entity or process and its concept:
- The class has the role to define ties between a concept and its terms:
- is a unified resource locator of a software project repository on the Internet;
- is the representation of a software project as a fragment of the proposed knowledge base.
3.2. Formalizing the Experience of Previous Projects
- The project-hosting API (GitLab, GitHub, etc.);
- The project Git repository.
- GET https://gitlab.com/api/v4/projects/romanov73%2Fng-tracker/milestones (accessed on 29 December 2022)This HTTP-request is used to obtain the list of the ng-tracker project milestones.
- GET https://gitlab.com/api/v4/projects/romanov73%2Fng-tracker/milestones/681923/issues (accessed on 29 December 2022)This HTTP-request is used to obtain the issues of the milestone #681923 (‘Conferences’).
- GET https://gitlab.com/api/v4/projects/romanov73%2Fng-tracker/issues/57/related_merge_requests (accessed on 29 December 2022)This HTTP-request is used to obtain the merge request of the issue #57 (‘Creating classes for the Conference module’).
- The SHA hash;
- The date;
- The message (description);
- The branch;
- The contributor;
- The diff (changes).
- Listing 1. Fragment of the MVC controller of the ng-tracker project.
 |
- Listing 2. Fragment of the build.gradle file of the ng-tracker project.
 |
- Listing 3. Fragment of the entity class of the ng-tracker project.
 |
- Listing 4. Fragment of the business logic class of the ng-tracker project.
 |
3.3. Diagnostic Analytics Method for Decision Support in Project Management
- is a knowledge base fragment for the i repository;
- are settings for extracting a set of time series: period and discreteness;
- is a set of time series of n indicators (one time series for each indicator) with length m extracted from the knowledge base;
- is a time series of the i-th indicator.
- is a function for time series classification;
- is a set of time series with a positive or negative dynamic of the project development.
- The evaluation of the indicator value using a set of expert ’if-then’ rules. Each rule defines a range of values. The indicator is assigned some linguistic value when an indicator value belongs to a certain interval.
- The modification of state values based on the mutual influence of indicators on each other. For example, if the number of contributors increases, the state for the number of commits indicator should be changed to a lesser value.
4. Results
4.1. Information Retrieval of Software Projects
- The number of contributors;
- The number of commits.
- The name of the entity;
- The name of the business process;
- The number of entities;
- The number of business processes.
- is a subset of projects that match query parameters;
- B is a set of indexed projects of the knowledge base.
- is the number of matching parameters in project and query Q;
- is the number of parameters in query Q.
- The ‘Project’ node.
- The ‘Entity’ node. These nodes are formed based on the set of project entities from the representation (Figure 6).
- ‘Process’ node. This type of node is formed based on representation processes associated with a specific entity.
- The ‘Metric’ node: ‘Contributors’, ‘Commits’, ‘Entities’, and ‘Processes’. The values of ‘Contributors’ and ‘Commits’ metric nodes are formed based on the aggregation of data by the number of changes and contributors of the representation (Figure 3). The values for ‘Entities’ and ‘Processes’ metric nodes are formed based on the number of ‘Entity’ and ‘Process’ nodes.
- A ‘hasEntity’ relation for a ‘Project’ and an ‘Entity’ nodes connection;
- A ‘hasProcess’ relation for an ‘Entity’ and ‘Process’ nodes connection;
- A ‘hasMetric’ relation for a ‘Project’ and ‘Metric’ nodes connection.
- Listing 5. Example of the Cypher query of the information retrieval subsystem.
 |
- It needs to transit from the term to concept by the ‘hasTerm’ relation.
- Then, it needs to transit to the the entity or business process by the ‘hasConcept’ relation.
4.2. Generating Use Case Diagrams in UML Notation
- is a set of actors that perform certain roles in a given system;
- is a set of system boundaries that define the limits of the system;
- is a set of use cases that represent a business functionality;
- and is a set of relations:
- is an include relationship, a use case that includes the functionality described in another use case as a part of its business process flow;
- is an extend relationship, where the child use case adds to the existing functionality and characteristics of the parent use case;
- is a generalization relationship, a parent–child relationship between use cases;
- is an association relationship, a relationship between actors and use cases.
- Create an actor with the name ‘User’: ::User:
- Create a root use case: . Specify the name of the project as the name for a root use case:(ng-tracker)
- Connect a root use case with an association relation with an actor: ::User: - (ng-tracker)
- Form a use case for each entity and connect it with an inclusion relation with the root use case:Specify the name of an entity as the name of a use case:(ng-tracker)..>(Conference):include(ng-tracker)..>(ConferenceUser):include
- Obtain a list of business processes () for each entity. Create a use case for each business process from and connect it with an inclusion relation with a parent use case (entity ):Specify the name of a business process as the name of a use case:(Conference)..>(findAll):include(Conference)..>(save):include(Conference)..>(findOne):include(Conference)..>(createByTitle):include(Conference)..>(findAllActive):include(Conference)..>(create):include(Conference)..>(delete):include(Conference)..>(getActiveConferenceByUser):include(Conference)..>(findAllActiveByCurrentUser):include(ConferenceUser)..>(getAllParticipation):include(ConferenceUser)..>(getAllDeposit):include(ConferenceUser)..>(saveOrCreate):include
- Use additional information from the knowledge base to improve the quality of the generated diagrams;
- Add extend and generalization relations support;
- Use natural language processing methods and linguistic environment to generate more correct (in terms of UML notation) names for use cases.
4.3. Diagnostic Analytics of Software Projects
5. Discussion
- Development process features;
- Structure features;
- Environment features;
- Domain features;
- Project in dynamic representation.
- A class diagram;
- A composite structure diagram;
- A component diagram;
- A deployment diagram;
- A package diagram.
- The need for expertise to adapt the approach to different programming languages and technologies;
- The need for expertise to consider the features of the development process;
- The need to use the project-hosting API (GitHub, GitLab) to extract information about the development process: stages, tasks, merge requests, etc.
- Support for fuzzy logic;
- Generating new types of design artifacts;
- The automatic generation of project management recommendations;
- Data mining methods.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AD | Architectural Description |
| OS | Operational Space of Design Activity |
| CS | Conceptual Space of Design Activity |
| DT | Design Thinking Methodology |
| DL | Description Logic |
| HTTP | HyperText Transfer Protocol |
| REST | Representational State Transfer |
| API | Application Programming Interface |
| SHA | Secure Hash Algorithms |
| MVC | Model–view–controller |
| UML | Unified Modeling Language |
References
- Chaos Reports 1994–2017. Available online: http://www.standishgroup.com (accessed on 2 February 2023).
- Ralph, P. The sensemaking-coevolution-implementation theory of software design. Sci. Comput. Program. 2015, 101, 21–41. [Google Scholar] [CrossRef]
- Sosnin, P. Substantially evolutionary theorizing in designing software-intensive systems. Information 2018, 9, 91. [Google Scholar] [CrossRef]
- Ferreira Martins, H.; Carvalho; de Oliveira, A., Jr.; Dias Canedo, E.; Dias Kosloski, R.A.; Ávila Paldês, R.; Costa Oliveira, E. Design thinking: Challenges for software requirements elicitation. Information 2019, 10, 371. [Google Scholar] [CrossRef]
- Hoda, R.; Murugesan, L.K. Multi-level agile project management challenges: A self-organizing team perspective. J. Syst. Softw. 2016, 117, 245–257. [Google Scholar] [CrossRef]
- da Silva, F.Q.; Costa, C.; Franca, A.C.C.; Prikladinicki, R. Challenges and solutions in distributed software development project management: A systematic literature review. In Proceedings of the 5th IEEE International Conference on Global Software Engineering, Princeton, NJ, USA, 23–26 August 2010; pp. 87–96. [Google Scholar]
- Niazi, M.; Mahmood, S.; Alshayeb, M.; Riaz, M.R.; Faisal, K.; Cerpa, N.; Khan, S.U.; Richardson, I. Challenges of project management in global software development: A client-vendor analysis. Inf. Softw. Technol. 2016, 80, 1–19. [Google Scholar] [CrossRef]
- Engwall, M.; Jerbrant, A. The resource allocation syndrome: The prime challenge of multi-project management? Int. J. Proj. Manag. 2003, 21, 403–409. [Google Scholar] [CrossRef]
- Bedjeti, A.; Lago, P.; Lewis, G.A.; De Boer, R.D.; Hilliard, R. Modeling context with an architecture viewpoint. In Proceedings of the IEEE International Conference on Software Architecture (ICSA-2017), Gothenburg, Sweden, 3–7 April 2017; pp. 117–120. [Google Scholar]
- Wongthongtham, P.; Pakdeetrakulwong, U.; Marzooq, S.H. Ontology annotation for software engineering project management in multisite distributed software development environments. In Software Project Management for Distributed Computing; Mahmood, Z., Ed.; Springer: Cham, Switzerland, 2017; pp. 315–343. [Google Scholar]
- Namestnikov, A.; Guskov, G. Ontological mapping for conceptual models of software system. In Proceedings of the Open Semantic Technologies for Intelligent Systems Conference, Minsk, Republic of Belarus, 16–18 February 2017; pp. 16–18. [Google Scholar]
- Guskov, G.; Namestnikov, A.; Yarushkina, N. Approach to the search for similar software projects based on the UML ontology. In Proceedings of the International Conference on Intelligent Information Technologies for Industry, Varna, Bulgaria, 14–16 September 2017; pp. 3–10. [Google Scholar]
- Bechberger, L.; Kühnberger, K.U. A thorough formalization of conceptual spaces. In Proceedings of the Joint German/Austrian Conference on Artificial Intelligence, Dortmund, Germany, 25–29 September 2017; pp. 58–71. [Google Scholar]
- Di Noia, T.; Mongiello, M.; Nocera, F.; Straccia, U. A fuzzy ontology-based approach for tool-supported decision making in architectural design. Knowl. Inf. Syst. 2019, 58, 83–112. [Google Scholar] [CrossRef]
- ISO/IEC/IEEE 42010:2022. Software, Systems and Enterprise–Architecture Description. Available online: https://www.iso.org/standard/74393.html (accessed on 27 November 2022).
- Borle, N.C.; Feghhi, M.; Stroulia, E.; Greiner, R.; Hindle, A. Analyzing the effects of test driven development in GitHub. Empir. Softw. Eng. 2018, 23, 1931–1958. [Google Scholar] [CrossRef]
- Henkel, J.; Bird, C.; Lahiri, S.K.; Reps, T. Learning from, understanding, and supporting devops artifacts for docker. In Proceedings of the 42nd International Conference on Software Engineering (ICSE-2020), Seoul, Republic of Korea, 5–11 October 2020; pp. 38–49. [Google Scholar]
- Schermann, G.; Zumberi, S.; Cito, J. Structured information on state and evolution of dockerfiles on GitHub. In Proceedings of the 15th international conference on mining software repositories, Gothenburg, Sweden, 28–29 May 2018; pp. 26–29. [Google Scholar]
- Xia, T.; Fu, W.; Shu, R.; Agrawal, R.; Menzies, T. Predicting health indicators for open source projects (using hyperparameter optimization). Empir. Softw. Eng. 2022, 27, 1–31. [Google Scholar] [CrossRef]
- De Stefano, M.; Pecorelli, F.; Tamburri, D.A.; Palomba, F.; De Lucia, A. Splicing community patterns and smells: A preliminary study. In Proceedings of the 42nd international conference on software engineering workshops, Seoul, Republic of Korea, 27 June–19 July 2020; pp. 703–710. [Google Scholar]
- Tamburri, D.A.; Palomba, F.; Serebrenik, A.; Zaidman, A. Discovering community patterns in open-source: A systematic approach and its evaluation. Empir. Softw. Eng. 2019, 24, 1369–1417. [Google Scholar] [CrossRef]
- Bhatia, M.P.S.; Kumar, A.; Beniwal, R. Ontologies for software engineering: Past, present and future. Indian J. Sci. Technol. 2016, 9, 1–16. [Google Scholar] [CrossRef]
- Isotani, S.; Bittencourt, I.I.; Barbosa, E.F.; Dermeval, D.; Paiva, R.O.A. Ontology driven software engineering: A review of challenges and opportunities. IEEE Lat. Am. Trans. 2015, 13, 863–869. [Google Scholar] [CrossRef]
- Rudolph, S. Foundations of description logics. In Proceedings of the 7th International Summer School on Reasoning Web. Semantic Technologies for the Web of Data, Galway, Ireland, 23–27 August 2011; pp. 76–136. [Google Scholar]
- OWL 2 Web Ontology Language. Structural Specification and Functional-Style Syntax (Second Edition). Available online: https://www.w3.org/TR/owl2-syntax/ (accessed on 2 February 2023).
- Ng-Tracker Repository on GitLab. Available online: https://gitlab.com/romanov73/ng-tracker (accessed on 2 February 2023).
- Filippov, A.; Romanov, A.; Iastrebov, D. An Approach to Data Mining of Software Repositories in Terms of Quantitative Indicators of the Development Process and Domain Features. In Proceedings of the International Conference on Intelligent Information Technologies for Industry, Istanbul, Turkey, 31 October–6 November 2022; pp. 346–357. [Google Scholar]
- GitLab REST API Documentation. Available online: https://docs.gitlab.com/ee/api/rest/ (accessed on 2 February 2023).
- Eclipse JGit Official Website. Available online: https://www.eclipse.org/jgit/ (accessed on 2 February 2023).
- Pecherskikh, A.A.; Romanov, A.A.; Beresnev, I.I. An approach for searching software system projects with similar structure. Autom. Control. Process. 2022, 3, 20–26. [Google Scholar] [CrossRef]
- Namestnikov, A.M.; Filippov, A.A.; Avvakumova, V.S. An ontology based model of technical documentation fuzzy structuring. In Proceedings of the 2nd International Workshop on Soft Computing Applications and Knowledge Discovery (SCAKD 2016), Moscow, Russia, 18 July 2016; pp. 63–74. [Google Scholar]
- Yarushkina, N.; Filippov, A.; Grigoricheva, M.; Moshkin, V. The Method for Improving the Quality of Information Retrieval Based on Linguistic Analysis of Search Query. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing (ICAISC-2019), Zakopane, Poland, 16–20 June 2019; pp. 474–485. [Google Scholar]
- Romanov, A.A.; Filippov, A.A.; Voronina, V.V.; Guskov, G.Y.; Yarushkina, N.G. Modeling the Context of the Problem Domain of Time Series with Type-2 Fuzzy Sets. Mathematics 2021, 9, 2947. [Google Scholar] [CrossRef]
- Rahman, M.M.; Chakraborty, S.; Kaiser, G.; Ray, B. A case study on the impact of similarity measure on information retrieval based software engineering tasks. arXiv 2018, arXiv:1808.02911. Available online: https://arxiv.org/pdf/1808.02911.pdf (accessed on 27 November 2022).
- Holzschuher, F.; Peinl, R. Performance of graph query languages: Comparison of Cypher, Gremlin and native access in Neo4j. In Proceedings of the Joint EDBT/ICDT 2013 Workshops, Genoa, Italy, 18–22 March 2013; pp. 95–204. [Google Scholar]
- PlantUML. UML Diagram Generator. Available online: https://plantuml.com (accessed on 27 November 2022).
- Tabbychat. Plugin for Minecraft. Available online: https://github.com/killjoy1221/tabbychat (accessed on 2 February 2023).
- The 2020 Scrum Guide: Scrum Team. Available online: https://www.scrumguides.org/scrum-guide.html#scrum-team (accessed on 27 November 2022).
- Grönlund, M.; Jefford-Baker, J. Measuring Correlation between Commit Frequency and Popularity on GitHub; School of Computer Science and Communication (CSC): Stockholm, Sweden, 2017. [Google Scholar]
- Romanov, A.; Yarushkina, N.; Filippov, A. Application of time series analysis and forecasting methods for enterprise decision-management. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 12–14 October 2020; pp. 326–337. [Google Scholar]
- Zhu, J.; Zhou, M.; Mockus, A. Patterns of folder use and project popularity: A case study of GitHub repositories. In Proceedings of the 8th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Torino, Italy, 18–19 September 2014; pp. 1–4. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Indicator (Number) | Month | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| tabbychat | Commits | 57 | 64 | 76 | 117 | 130 |
| Contributors | 3 | 4 | 6 | 6 | 6 | |
| Entities | 7 | 7 | 7 | 7 | 7 | |
| Processes | 158 | 164 | 164 | 164 | 164 | |
| ng-tracker | Commits | 251 | ||||
| Contributors | 1 | 1 | 8 | 8 | 8 | |
| Entities | 5 | 5 | 18 | 18 | 19 | |
| Processes | 115 | 129 | 206 | 271 | 273 | |
| Project | Indicator (State) | Month | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| tabbychat | Commits | middle | middle | few | few | few |
| Contributors | middle | middle | few | few | few | |
| Entities | few | few | few | few | few | |
| Processes | middle | middle | middle | middle | middle | |
| ng-tracker | Commits | few | few | few | few | few |
| Contributors | few | few | middle | middle | middle | |
| Entities | few | few | middle | middle | middle | |
| Processes | middle | middle | few | few | few | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Filippov, A.; Romanov, A.; Skalkin, A.; Stroeva, J.; Yarushkina, N. Approach to Formalizing Software Projects for Solving Design Automation and Project Management Tasks. Software 2023, 2, 133-162. https://doi.org/10.3390/software2010006
Filippov A, Romanov A, Skalkin A, Stroeva J, Yarushkina N. Approach to Formalizing Software Projects for Solving Design Automation and Project Management Tasks. Software. 2023; 2(1):133-162. https://doi.org/10.3390/software2010006
Chicago/Turabian StyleFilippov, Aleksey, Anton Romanov, Anton Skalkin, Julia Stroeva, and Nadezhda Yarushkina. 2023. "Approach to Formalizing Software Projects for Solving Design Automation and Project Management Tasks" Software 2, no. 1: 133-162. https://doi.org/10.3390/software2010006
APA StyleFilippov, A., Romanov, A., Skalkin, A., Stroeva, J., & Yarushkina, N. (2023). Approach to Formalizing Software Projects for Solving Design Automation and Project Management Tasks. Software, 2(1), 133-162. https://doi.org/10.3390/software2010006