1. Introduction
Lattices are discrete sets in
formed by all integer linear combinations of a set of independent vectors, and have found different applications, such as in information theory and communications [
1,
2,
3]. Given a probability distribution in
, two operations can be induced by considering the quotient of the space by a lattice: wrapping and quantization.
The wrapped distribution over the quotient is obtained by summing the probability density over each coset. It is used to define parameters for lattice coset coding, particularly for AWGN and wiretap channels, such as the flatness factor, which is, up to a constant, the
distance from a wrapped probability distribution to a uniform one [
4,
5]. This factor is equivalent to the smoothing parameter, used in post-quantum lattice-based cryptography [
6]. In the context of directional statistics, wrapping has been used as a standard way to construct distributions on a circle and on a torus [
7].
The quantized distribution over the lattice can be defined by integrating over each fundamental domain translation, thus corresponding to the distribution of the fundamental domains after lattice-based quantization is applied. Lattice quantization has different uses in signal processing and coding: for instance, it can achieve the optimal rate-distortion trade-off and can be used for shaping in channel coding [
2]. A special case of interest is when the distribution on the fundamental region is uniform, which amounts to high-resolution quantization or dithered quantization [
8,
9].
In this work, we relate these two operations by remarking that the random variables induced by wrapping and quantization sum up to the original one. We study information properties of this decomposition, both from classical information theory [
10] and from information geometry [
11], and provide some examples for the exponential and Gaussian distributions. We also propose a generalization of these ideas to locally compact groups. Probability distributions on these groups have been studied in [
12], and some information-theoretic properties have been investigated in [
13,
14,
15]. In addition to probability measures, one can also define the notions of lattice and fundamental domains on them, thereby generalizing the Euclidean case. We show that wrapping and quantization are also well defined, and provide some illustrative examples.
2. Lattices, Wrapping and Quantization
2.1. Lattices and Fundamental Domains
A lattice in is a discrete additive subgroup of , or, equivalently, the set formed by all integer linear combinations of a set of linearly independent vector , called a basis of . A matrix B whose column vectors form a basis is called a generator matrix of , and we have . The lattice dimension is k, and, if , the lattice is said to be full-rank; we henceforth consider full-rank lattices. A lattice defines an equivalence relation in : . The associated equivalence classes are denoted by or . The set of all equivalence classes is the lattice quotient , and we denote the standard projection .
Let be a Lebesgue-measurable set of and a lattice. We say that is a fundamental domain or a fundamental region of , or that tiles by , if (1) , and (2) , for all in (it is often only asked that this intersection has Lebesgue measure zero, but we require it to be empty). Given a fundamental domain , each coset has a unique representative in , i.e., the measurable map is a bijection. This fact suggests using a fundamental domain to represent the quotient. Each fundamental domain contains exactly one lattice point, which may be chosen as the origin. An example of a fundamental domain is the fundamental parallelotope with respect to a basis , namely . Another one is the Voronoi region of the origin, given by the points that are closer to the origin than to any other lattice point, with an appropriate choice for ties. It is a well-known fact that every fundamental domain has the same volume, denoted by , for any generator matrix B of .
2.2. Wrapping and Quantization
Consider
with the Lebesgue measure
, and
P a probability measure such that
. Then the probability density function (pdf) of
P is
, the Radon–Nikodym derivative. For fixed full-rank lattice
and fundamental domain
, the
wrapping of
P by
is the distribution
on
, given by
. For simplicity, we identify
with
to regard
as a distribution over
, and then we have
given by
, for all
. Using this identification, the wrapping has density
given by
A construction that is, in some sense, dual to wrapping is quantization. Note that each fundamental domain
partitions the space as
. The quantization function is the measurable map
, given by
, for
and
. The
quantized probability distribution of
P on the discrete set
is
, given by
. The probability mass function of the quantized distribution is then
Letting
X be a vector random variable in
with distribution
p, we define
and
the wrapped and quantized random variables, respectively. By definition, they are distributed according to
and
. Interestingly, they sum up to the original one:
since
. Note also that
has the same distribution as
, by the bimeasurable bijection
. These factors, however, are not independent, since, in general,
. The difference between
and
shall be illustrated in the following examples. Note that the expression for the quantized distribution depends on the choice of fundamental domain, while the wrapped distribution does not, up to a lattice translation.
We say a random variable X over is memoryless if for all , where is the tail distribution function. In particular, a memoryless distribution satisfies for all , , which implies . The converse, however, is not true; for example, independence holds whenever p is constant on each region , for .
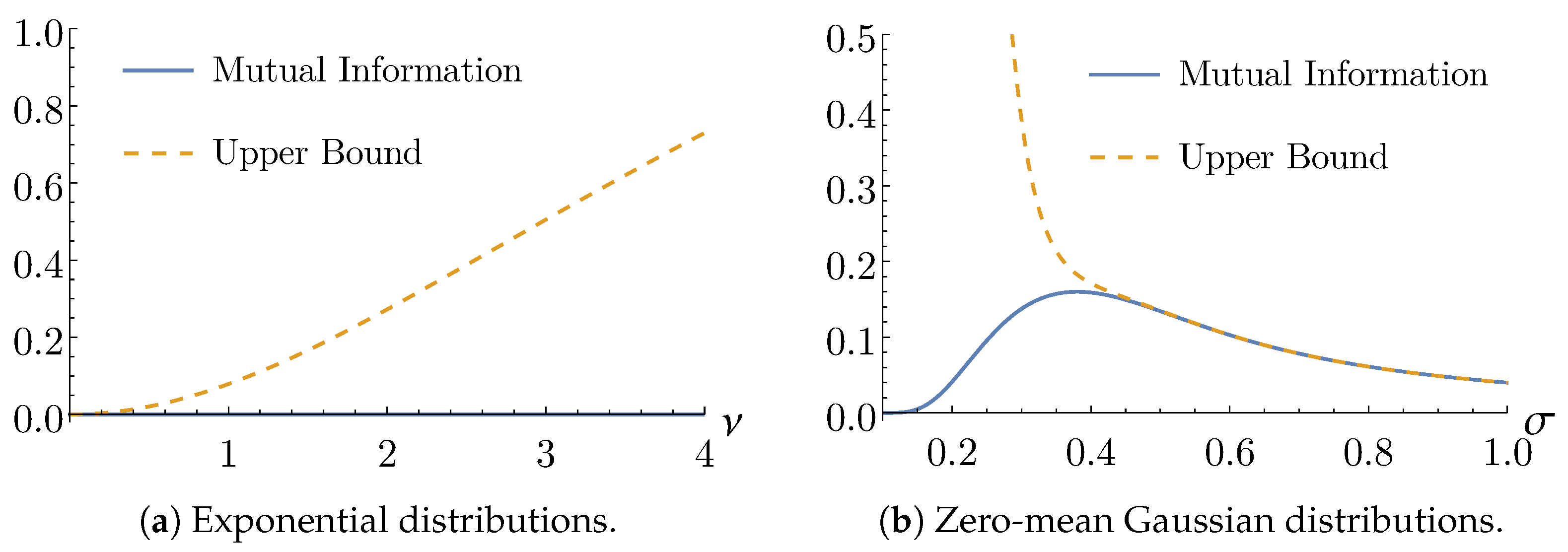
Example 1. The exponential distribution, parametrized by , is defined aswhere takes value 1 if , and 0 otherwise. Choosing the lattice , , and the fundamental domain , one can write closed-form expressions for the wrapped and quantized distributions: Note that, in this special case, , as a consequence of memorylessness. The wrapped distribution with , which amounts to a distribution on the unitary circle, is well studied in [16]. Example 2. Consider the univariate Gaussian distributionand the lattice , with fundamental domain , . The wrapped and quantized distributions are given respectively by The value for the wrapped distribution on a unitary circle is usually considered in directional statistics [7]. Figure 1 illustrates the original, wrapped, quantized and product distributions for different zero-mean Gaussian distributions. As can be seen in the figure, in this case, . A straightforward consequence of the decomposition (
3) is
;
,
where , and denote, respectively, the expectation, the variance and the cross-covariance operators.
We note that different types of discretization have also been studied, other then integrating over a fundamental domain [
17]. For instance, in [
4,
18,
19], the discretized distribution is defined by restricting the original pdf
to the lattice
, and then normalizing:
for a fixed
. This discretization is nothing other than the conditional distribution of
given that
, expressed as
. Moreover, when
, such as in the exponential distribution, cf. example 1, then
.
4. A Generalization to Topological Groups
A topological group is a topological space
that is also a group with respect to some operation · called
product, and such that the inverse
and product
are continuous. As additional requisites, we ask
G to be locally compact, Hausdorff and second-countable (i.e., has a countable basis) [
22]. Let
be the the Borel
-algebra of
G. Haar’s theorem says there is a unique (up to a constant) Radon measure on
G that is invariant by left translations—we will suppose a fixed normalization, and denote both the measure and integration with respect to it by d
g. The group
G is said to be
unimodular if d
g is also invariant by right translations. Since
G is
-compact, the Haar measure is
-finite [
12].
Let
be a discrete subgroup of
G, which is necessarily closed, since
G is Hausdorff, and countable, since
G is second-countable. Let us also consider the quotient space of left cosets
which has a natural projection
, given by
. We call
a
lattice if the induced Haar measure on
is finite and bi-invariant. A particular case is when the quotient
is compact; then
is said to be a
uniform lattice. A
cross-section is defined as a set
of representatives of
such that all cosets are uniquely represented. A
fundamental domain is a measurable cross-section. It can be shown that
is a lattice if, and only if, it admits a fundamental domain. Furthermore, every fundamental domain has the same measure [
23,
24].
Let
P be a probability measure on the space
that is absolutely continuous with respect to the Haar measure d
g. By the Radon–Nikodym theorem, we can define a density function
, such that
and
, for all
. The original measure can be represented as
, and we consider the family of all such densities
Probability distributions on locally compact groups have been studied in [
12], and some information-theoretic properties have been investigated in [
13,
14,
15]. The result that allows us to consider wrapped distributions in this context is the
Weil formula, taken as a particular case of [
24] (Theorem 3.4.6):
Theorem 1. For any , the wrapping , is well defined -almost everywhere, belongs to , and As a consequence, for every probability density
, we can consider its wrapping
, which is
, non-negative and is also a probability density:
. The associated probability measure over
is
. This notation, suggesting
as the push-forward measure by
, is not a coincidence, since, from Theorem 1,
Analogously, given a fundamental domain , it is possible to define a quantization map by , for every , which is unique since . The quantized probability distribution is the discrete probability measure over , defined by the mass function , or as the push-forward measure .
If
X is distributed according to
p, and
,
, then
, again, as a consequence of
being a measurable bijection whose inverse is the product
. Despite being an abstract definition, this framework expands the scope of the previous approach, cf. examples below. In the following, let
be a full-rank lattice, and
be a full-rank sublattice, as defined in
Section 2.
Example 6. Let and . This recovers the approach from Section 2 as a particular case. Example 7. Let and . A fundamental domain is a choice of points, where each point corresponds to a coset . Of particular interest are Voronoi constellations [25,26] where the coset leaders are selected, with some choice made for ties. Since Λ is discrete, the Haar measure is the counting measure , and . The wrapped and quantized distributions are , and . Example 8. Let (a torus) and (the projection of Λ
to G). Then consists of a finite family of cosets , for , and a choice of fundamental domain is the projection of a fundamental domain of Λ
. There are some standard choices for the distribution on G, such as a wrapping from the Euclidean space and the bivariate von Mises distribution [7] (Section 11.4). Then, and , and, in the particular case where is a -wrapped distribution, they become and . Example 9. Let (a finite field) or , and (any linear block code). A fundamental domain can be a finite set of points that tiles the space by . The distributions then become finite sums, such as in Example 7.
Example 10. Let , the Lie group of square matrices with determinant 1, and (the subgroup of integer matrices). This is, in fact, a lattice, since for , where ζ is the Riemann zeta function, and for the finite covolume is calculated in [27], where descriptions of fundamental domains are also given. 


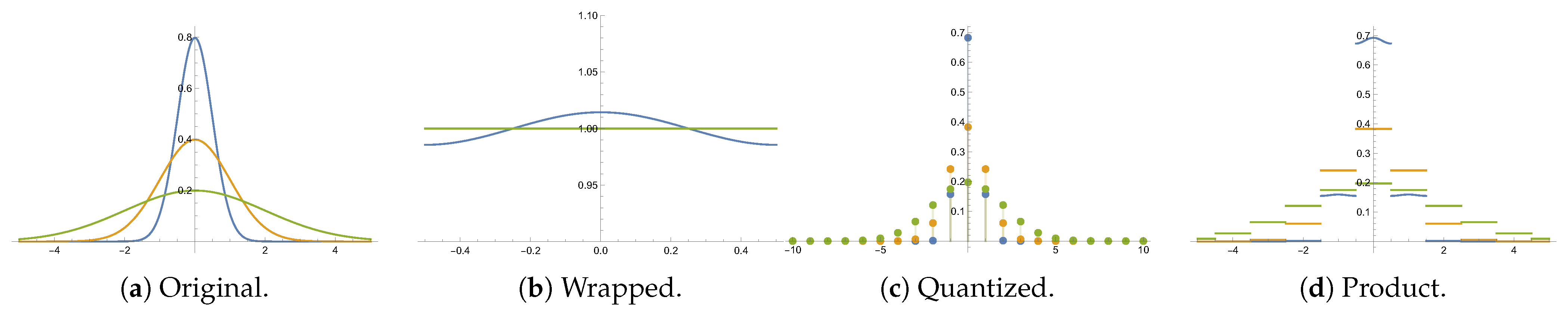{kind=link}
{kind=link}

