
Graphical Gaussian Models Associated to a Homogeneous Graph with Permutation Symmetries †

Abstract
:1. Introduction
2. Main Results
3. Matrix Realization of Homogeneous Cones
- (V1) ,
- (V2) ,
- (V3) .
4. Toy Example
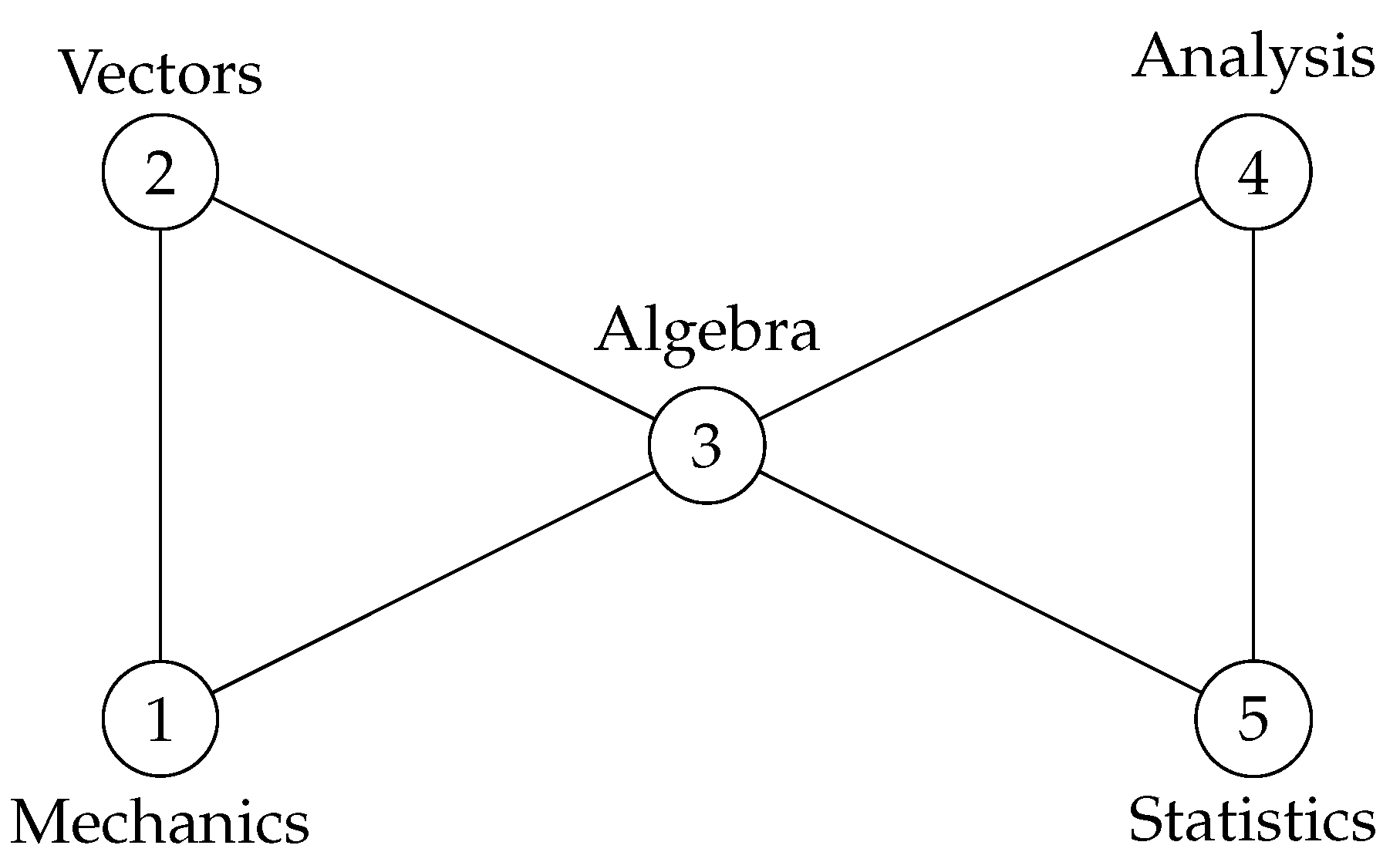
5. Numerical Example
- , which corresponds to full symmetry as ,
- , which corresponds to invariance of the model to interchange (Mechanics, Vectors) ↔ (Statistics, Analysis),
- , which corresponds to no additional symmetry.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Højsgaard, S.; Lauritzen, S.L. Graphical Gaussian models with edge and vertex symmetries. J. R. Stat. Soc. Ser. B Stat. Methodol. 2008, 70, 1005–1027. [Google Scholar] [CrossRef]
- Letac, G.; Massam, H. Wishart distributions for decomposable graphs. Ann. Statist. 2007, 35, 1278–1323. [Google Scholar] [CrossRef]
- Graczyk, P.; Ishi, H.; Kołodziejek, B. Wishart laws and variance function on homogeneous cones. Probab. Math. Statist. 2019, 39, 337–360. [Google Scholar] [CrossRef]
- Mardia, K.V.; Kent, J.T.; Bibby, J.M. Multivariate Analysis; Probability and Mathematical Statistics: A Series of Monographs and Textbooks; Academic Press: New York, NY, USA; Harcourt Brace Jovanovich: Boston, MA, USA, 1979; p. xv+521. [Google Scholar]
- Whittaker, J. Graphical Models in Applied Multivariate Statistics; Wiley Series in Probability and Mathematical Statistics: Probability and Mathematical Statistics; John Wiley & Sons, Ltd.: Chichester, UK, 1990; p. xiv+448. [Google Scholar]
- Edwards, D. Introduction to Graphical Modelling, 2nd ed.; Springer Texts in Statistics; Springer: New York, NY, USA, 2000; p. xvi+333. [Google Scholar]
- Graczyk, P.; Ishi, H.; Kołodziejek, B.; Massam, H. Model selection in the space of Gaussian models invariant by symmetry. Ann. Statist. 2022, 50, 1747–1774. [Google Scholar] [CrossRef]
- Letac, G. Decomposable Graphs. In Modern Methods of Multivariate Statistics; Hermann: Paris, France, 2014; Volume 82, pp. 155–196. [Google Scholar]
- Roverato, A. Cholesky decomposition of a hyper inverse Wishart matrix. Biometrika 2000, 87, 99–112. [Google Scholar] [CrossRef]
- Ishi, H. Homogeneous cones and their applications to statistics. In Modern Methods of Multivariate Statistics; Hermann: Paris, France, 2014; Volume 82, pp. 135–154. [Google Scholar]
- Ishi, H. Matrix realization of a homogeneous cone. In Geometric Science of Information; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9389, pp. 248–256. [Google Scholar]

{kind=link}
| Mechanics | Vectors | Algebra | Analysis | Statistics | |
|---|---|---|---|---|---|
| Mechanics | 5.85 | −2.23 | −3.72 | 0 | 0 |
| Vectors | −2.23 | 10.15 | −5.88 | 0 | 0 |
| Algebra | −3.72 | −5.88 | 26.95 | −5.88 | −3.72 |
| Analysis | 0 | 0 | −5.88 | 10.15 | −2.23 |
| Statistics | 0 | 0 | −3.72 | −2.23 | 5.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Graczyk, P.; Ishi, H.; Kołodziejek, B. Graphical Gaussian Models Associated to a Homogeneous Graph with Permutation Symmetries. Phys. Sci. Forum 2022, 5, 20. https://doi.org/10.3390/psf2022005020
Graczyk P, Ishi H, Kołodziejek B. Graphical Gaussian Models Associated to a Homogeneous Graph with Permutation Symmetries. Physical Sciences Forum. 2022; 5(1):20. https://doi.org/10.3390/psf2022005020
Chicago/Turabian StyleGraczyk, Piotr, Hideyuki Ishi, and Bartosz Kołodziejek. 2022. "Graphical Gaussian Models Associated to a Homogeneous Graph with Permutation Symmetries" Physical Sciences Forum 5, no. 1: 20. https://doi.org/10.3390/psf2022005020
APA StyleGraczyk, P., Ishi, H., & Kołodziejek, B. (2022). Graphical Gaussian Models Associated to a Homogeneous Graph with Permutation Symmetries. Physical Sciences Forum, 5(1), 20. https://doi.org/10.3390/psf2022005020