
Classification and Uncertainty Quantification of Corrupted Data Using Supervised Autoencoders †

 , , , and
, , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction and Motivation
2. Classification and Uncertainty Quantification of Corrupted Data
2.1. Methodology Overview and Related Work
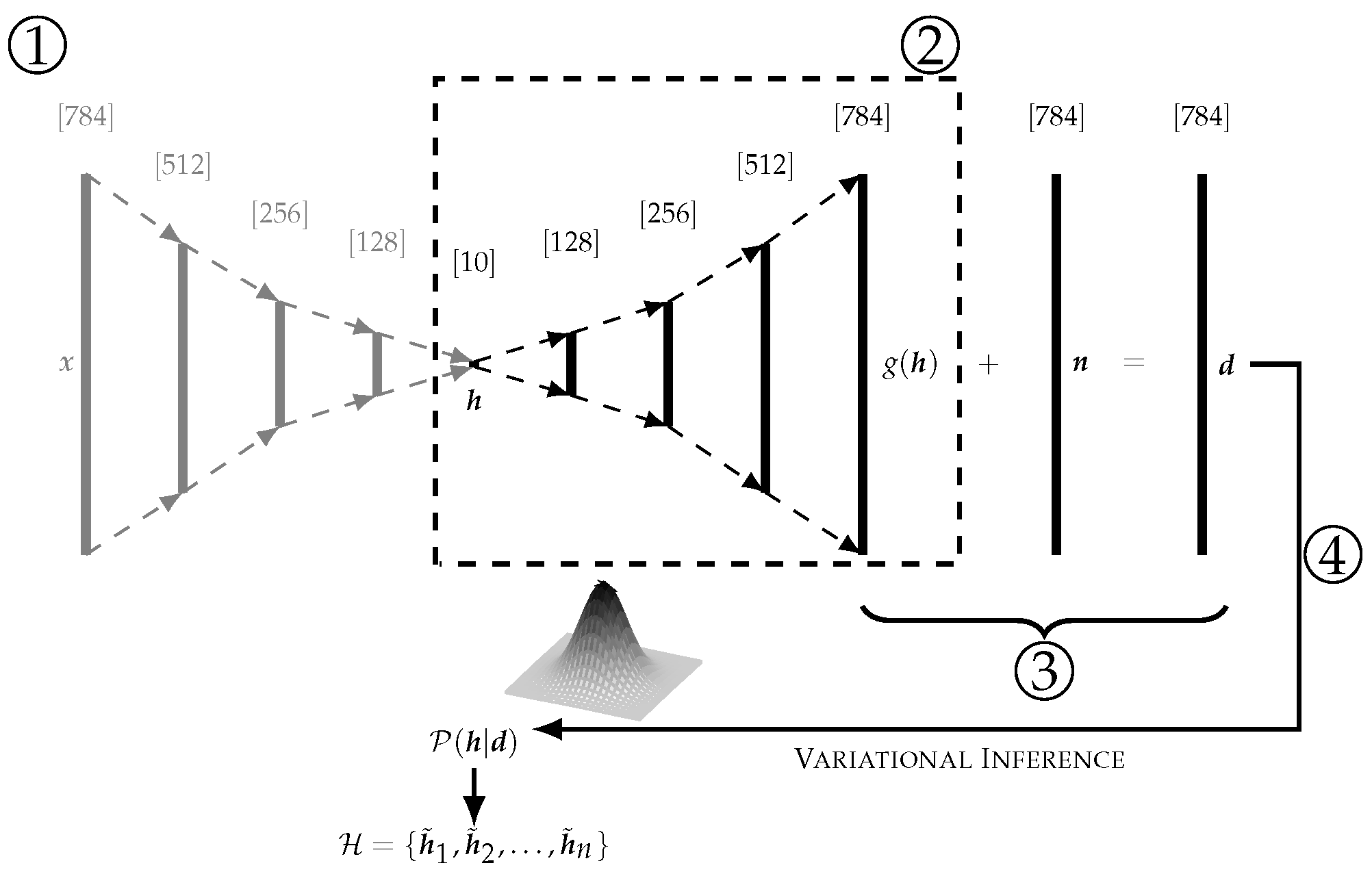
2.2. Generative Model and Bayesian Inference with Neural Networks
2.3. Classification and Uncertainty Quantification
3. Experiments
3.1. Classification
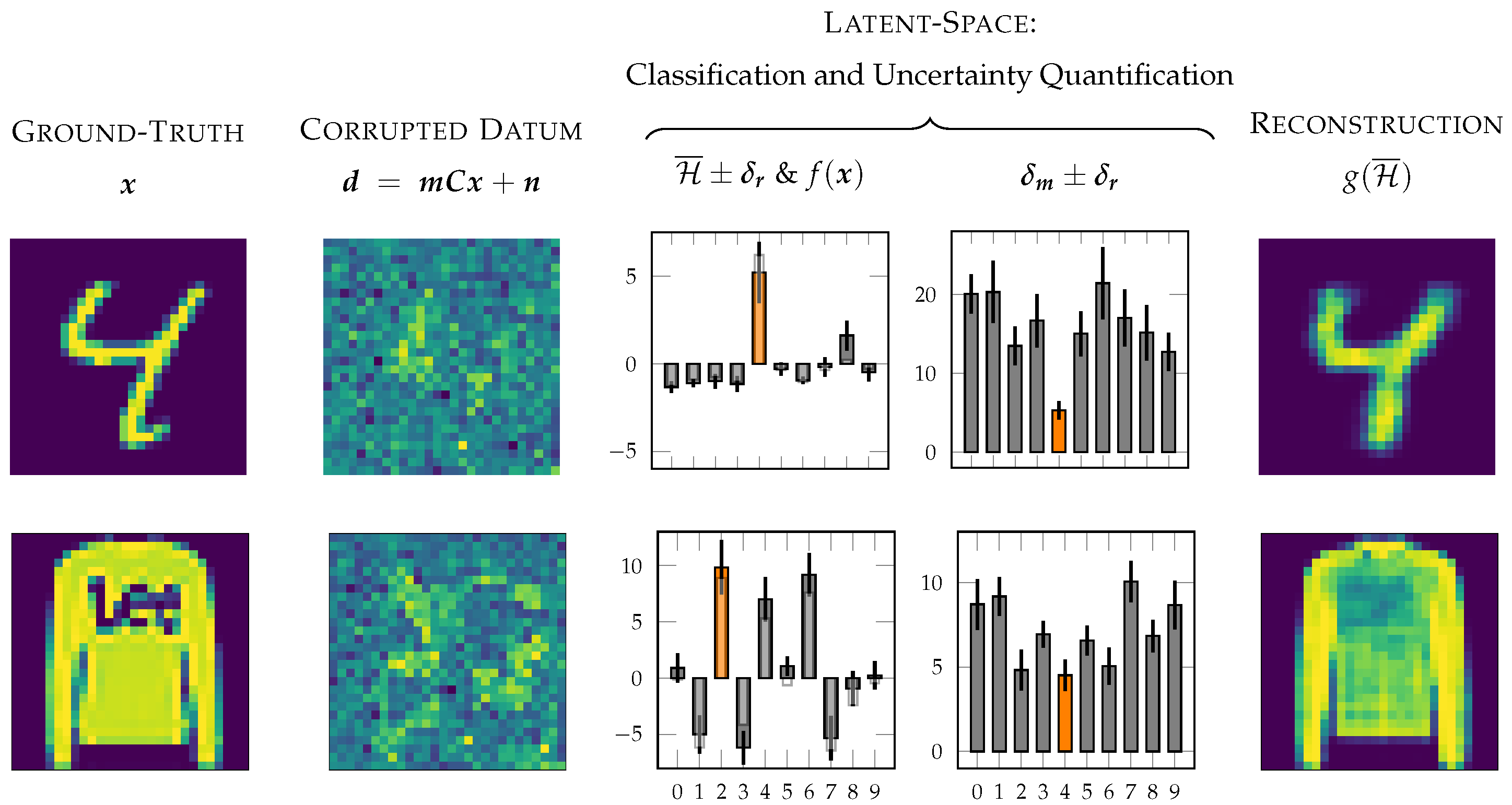
- The reconstruction uncertainty of correct classifications is approximately equivalent to the of wrong classifications. This behavior indicates that the correctness of the classification does not influence the reconstruction uncertainty , showing evidence that is independent of the model uncertainty .
- As opposed to , the model uncertainty strongly depends on the correct/wrong classification of the corrupted datum: is significantly and consistently higher for false classifications than for true classifications. This characteristic sets the basis for a statistical “lie detector” (see Section 3.2) of classification. Fields of application could be the validation of neural networks in, e.g., medical imaging and other safety-critical applications.
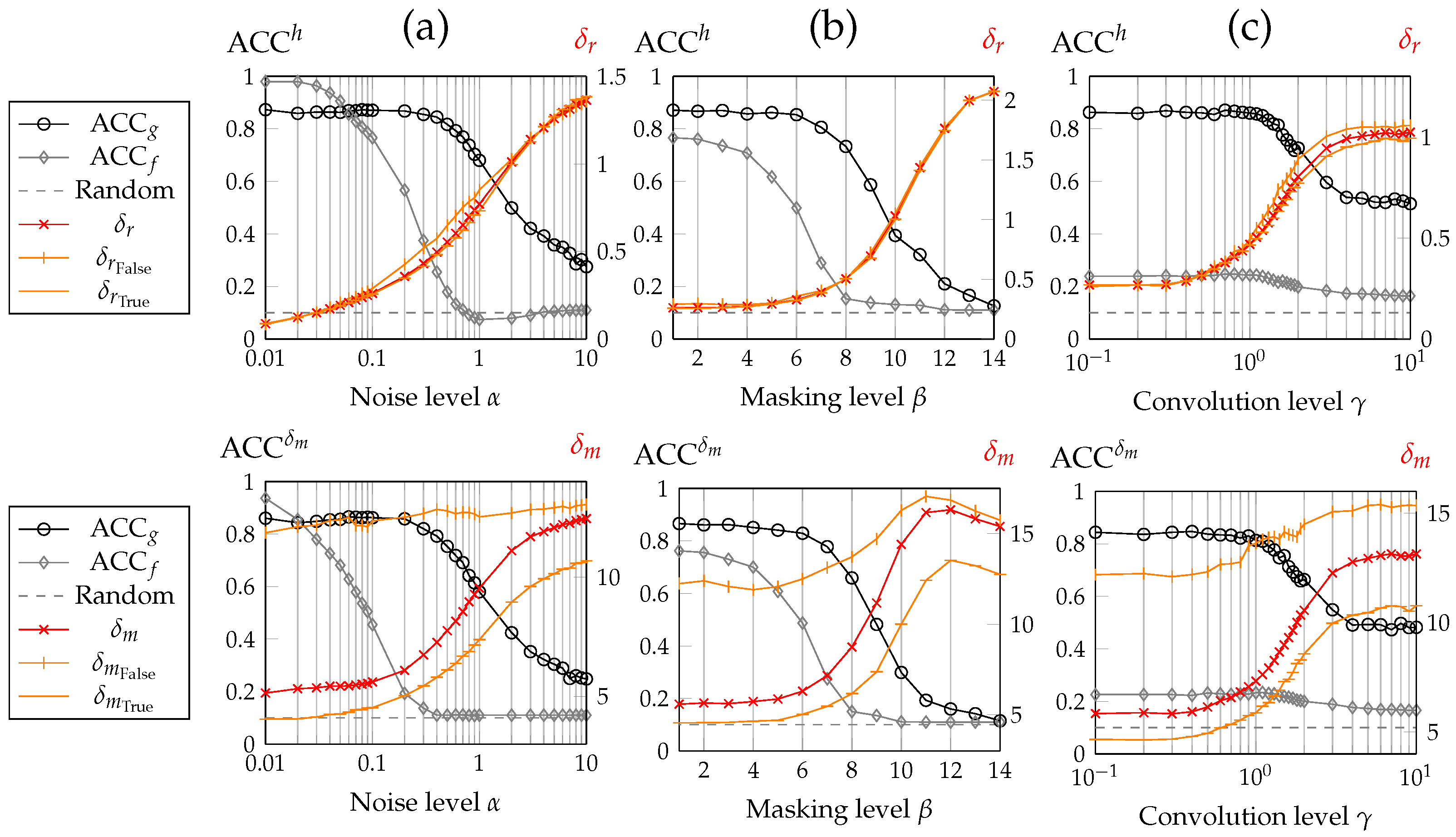
- Classifying corrupted data through the decoder (see in Figure 3) (rather than the encoder (see )), with a suitable channel model considering the corruption, significantly improved the model’s accuracy without the necessity of retraining the autoencoder. Especially for high levels of all corruption types, the accuracy of the model notably improved. Corruption by convolution had catastrophic consequences for classifying data in a straightforward manner through the encoder f, while this type of corruption seemed to only have a minor impact on our method.
- Both uncertainties and rose with increasing levels of corruption.
3.2. Detection of False Classifications
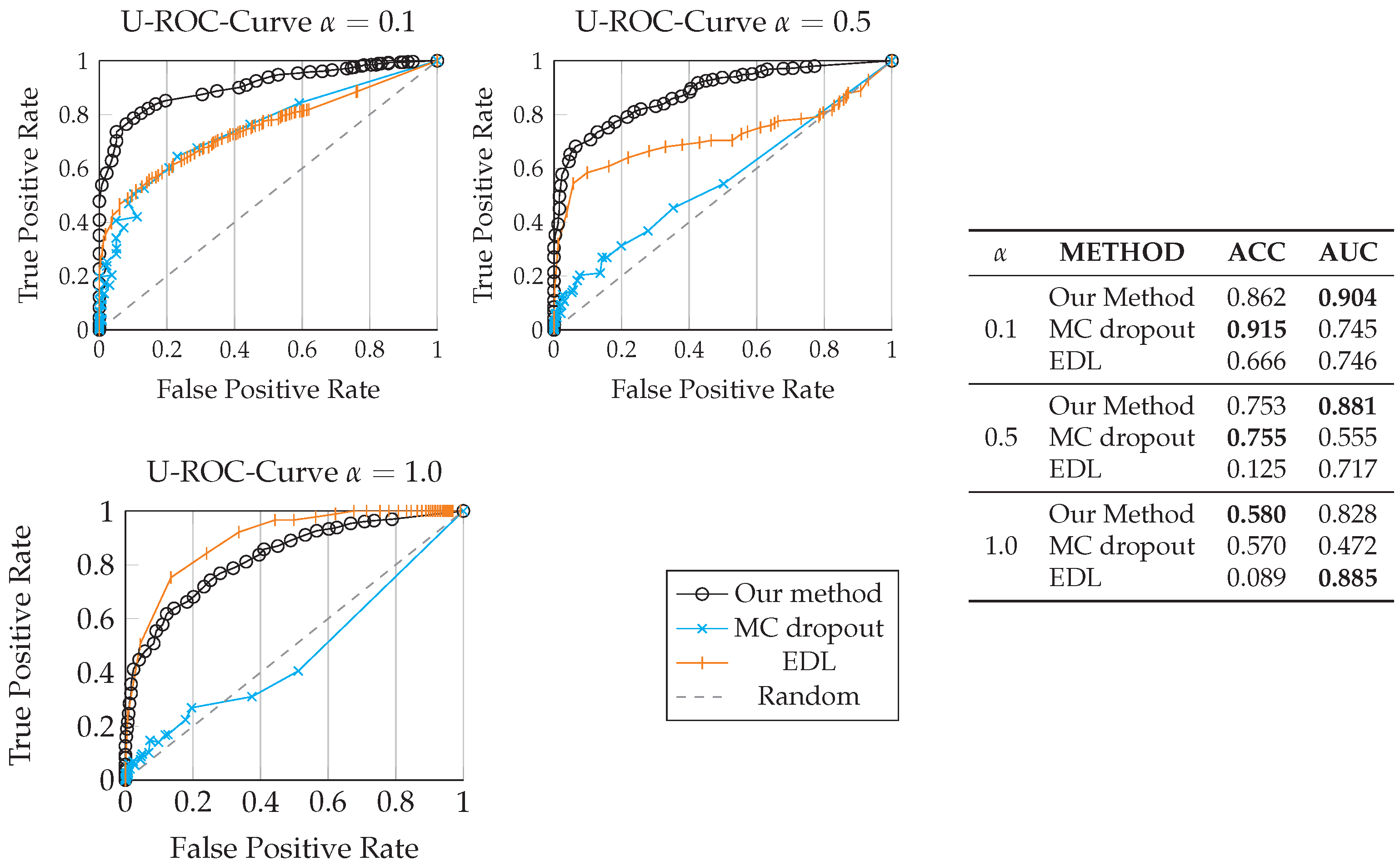
- Our method seemed to outperform MC-dropout and EDL to detect false classifications given the same data samples at the input for and . One reason for this might be that the M-distance serves as a reliable out-of-distribution detector, exploiting the inherent latent space structure of uncorrupted data as a reference, as opposed to MC-dropout and EDL. For , both EDL and our method outperformed MC-dropout, while the Area Under the Curve (AUC) of EDL was largest. Here, it should be noted that EDL cannot classify the corrupted data at this noise level (accuracy: ), resulting in only few samples to test the cases of True Positives and False Positives.
- All three methods provided reliable results for detecting false classifications for low noise levels. The model uncertainty truly reflects the confidence of the classification, i.e., a high value of correlates empirically with a higher probability of false classification.
- The U-ROC curve combined with the accuracy indicates that EDL seemed to overestimate uncertainties, leading to a very robust U-ROC curve for high noise levels, but simultaneously leading to a severe drop in the accuracy in the presence of data corruption. We observed comparable results on F-MNIST data.
4. Requirements and Summary
- : Without loss of generality, here, we assumed corruption by masking and convolution represented by and in the AWGN channel model, as depicted in Equation (2). Here, can in real-world applications often be derived from the image processing system in use. Algorithms to detect possibly occluding objects (represented by masking ) were given by, e.g., [20].
- : Noise covariance matrix. AWGN with and applied additively to the data . Among others, the methodology published by [21] enables the derivation of given noisy data .
- : Sampling covariance matrix of all (uncorrupted) latent space activations processed by the encoding function f. We used the assumption that an autoencoder can represent an inherent, lower-dimensional structure of the data in its latent space and assumed this sub-dimensional structure to sufficiently follow a multivariate Gaussian probability distribution.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Le, L.; Patterson, A.; White, M. Supervised autoencoders: Improving generalization performance with unsupervised regularizers. In NIPS’18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 107–117. [Google Scholar]
- Knollmüller, J.; Enßlin, T. Metric Gaussian Variational Inference. arXiv 2020, arXiv:1901.11033. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A Simple Unified Framework for Detecting out-of-Distribution Samples and Adversarial Attacks. In NIPS’18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 7167–7177. [Google Scholar]
- Böhm, V.; Lanusse, F.; Seljak, U. Uncertainty Quantification with Generative Models. arXiv 2019, arXiv:1910.10046. [Google Scholar]
- Böhm, V.; Seljak, U. Probabilistic Auto-Encoder. arXiv 2020, arXiv:2006.05479. [Google Scholar]
- Adler, J.; Öktem, O. Deep Bayesian Inversion. arXiv 2018, arXiv:1811.05910. [Google Scholar]
- Seljak, U.; Yu, B. Posterior Inference Unchained with EL_2O. arXiv 2019, arXiv:1901.04454. [Google Scholar]
- Wu, G.; Domke, J.; Sanner, S. Conditional Inference in Pre-trained Variational Autoencoders via Cross-coding. arXiv 2018, arXiv:1805.07785. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Sensoy, M.; Kaplan, L.; Kandemir, M. Evidential Deep Learning to Quantify Classification Uncertainty. In NIPS’18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 3183–3193. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Kucukelbir, A.; Tran, D.; Ranganath, R.; Gelman, A.; Blei, D.M. Automatic Differentiation Variational Inference. J. Mach. Learn. Res. 2017, 18, 430–474. [Google Scholar]
- LeCun, Y. The MNIST database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 6 June 2020).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. In NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 972–981. [Google Scholar]
- Selig, M.; Bell, M.R.; Junklewitz, H.; Oppermann, N.; Reinecke, M.; Greiner, M.; Pachajoa, C.; Enßlin, T.A. NIFTY–Numerical Information Field Theory-A versatile PYTHON library for signal inference. Astron. Astrophys. 2013, 554, A26. [Google Scholar] [CrossRef]
- Li, B.; Hu, W.; Wu, T.; Zhu, S.C. Modeling occlusion by discriminative and-or structures. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2560–2567. [Google Scholar]
- Liu, X.; Tanaka, M.; Okutomi, M. Noise level estimation using weak textured patches of a single noisy image. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 665–668. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joppich, P.; Dorn, S.; De Candido, O.; Knollmüller, J.; Utschick, W. Classification and Uncertainty Quantification of Corrupted Data Using Supervised Autoencoders. Phys. Sci. Forum 2022, 5, 12. https://doi.org/10.3390/psf2022005012
Joppich P, Dorn S, De Candido O, Knollmüller J, Utschick W. Classification and Uncertainty Quantification of Corrupted Data Using Supervised Autoencoders. Physical Sciences Forum. 2022; 5(1):12. https://doi.org/10.3390/psf2022005012
Chicago/Turabian StyleJoppich, Philipp, Sebastian Dorn, Oliver De Candido, Jakob Knollmüller, and Wolfgang Utschick. 2022. "Classification and Uncertainty Quantification of Corrupted Data Using Supervised Autoencoders" Physical Sciences Forum 5, no. 1: 12. https://doi.org/10.3390/psf2022005012
APA StyleJoppich, P., Dorn, S., De Candido, O., Knollmüller, J., & Utschick, W. (2022). Classification and Uncertainty Quantification of Corrupted Data Using Supervised Autoencoders. Physical Sciences Forum, 5(1), 12. https://doi.org/10.3390/psf2022005012