
Survey Optimization via the Haphazard Intentional Sampling Method †



Abstract
:1. Introduction
2. Haphazard Intentional Sampling Method
2.1. Pure Intentional Sampling Formulation
2.2. Haphazard Formulation
3. Case Study
3.1. Auxiliary Regression Model for SARS-CoV-2 Prevalence
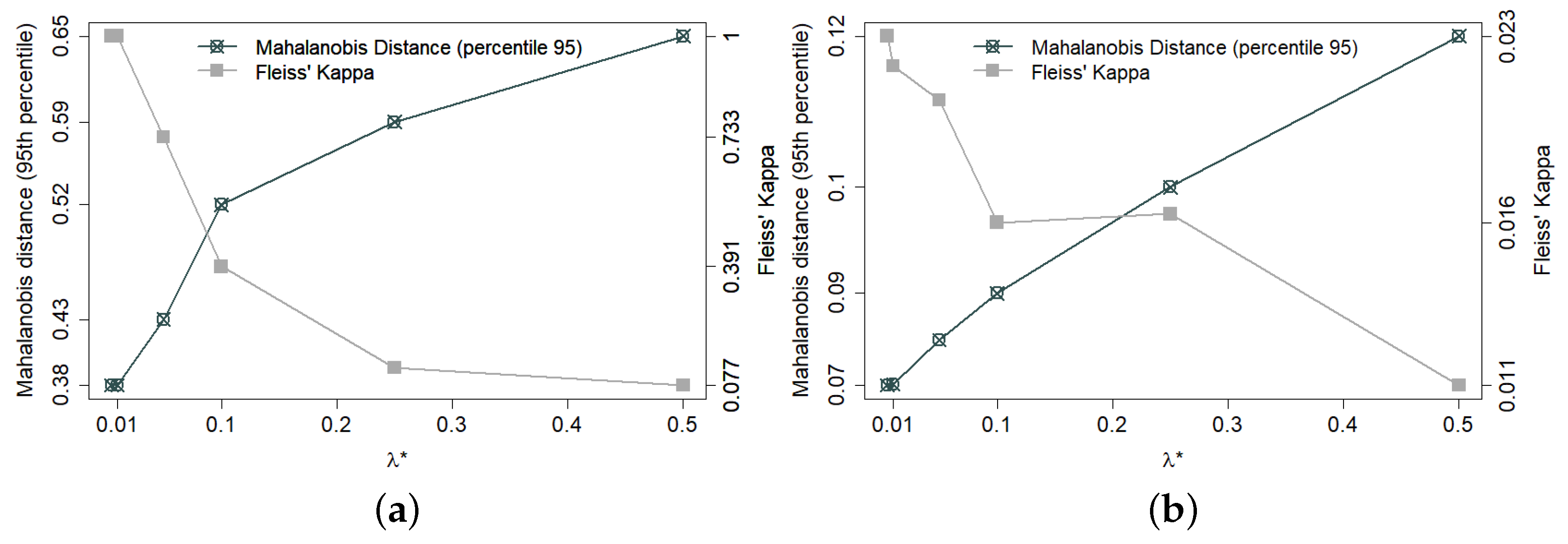
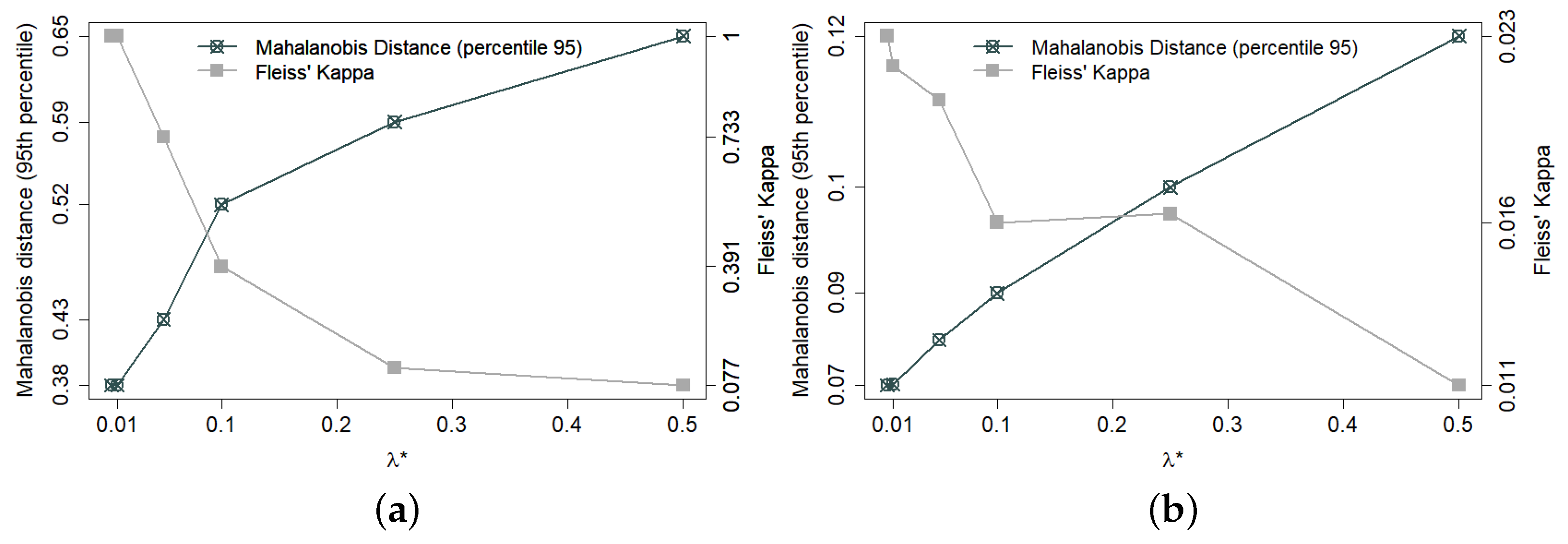
3.2. Balance and Decoupling Trade-Off in the Haphazard Method
3.3. Benchmark Experiments and Computational Setups
4. Experimental Results
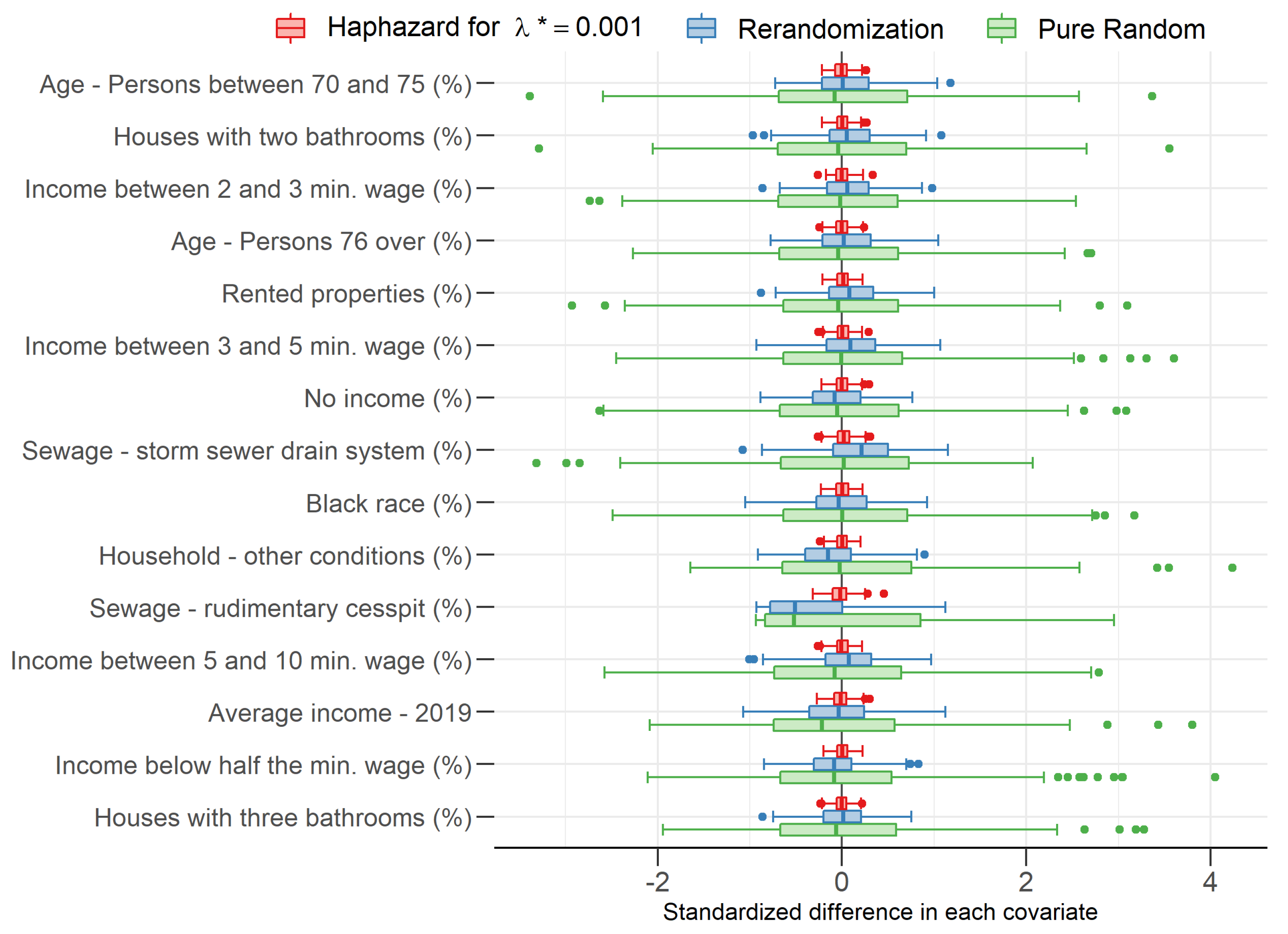
4.1. Group Unbalance among Covariates
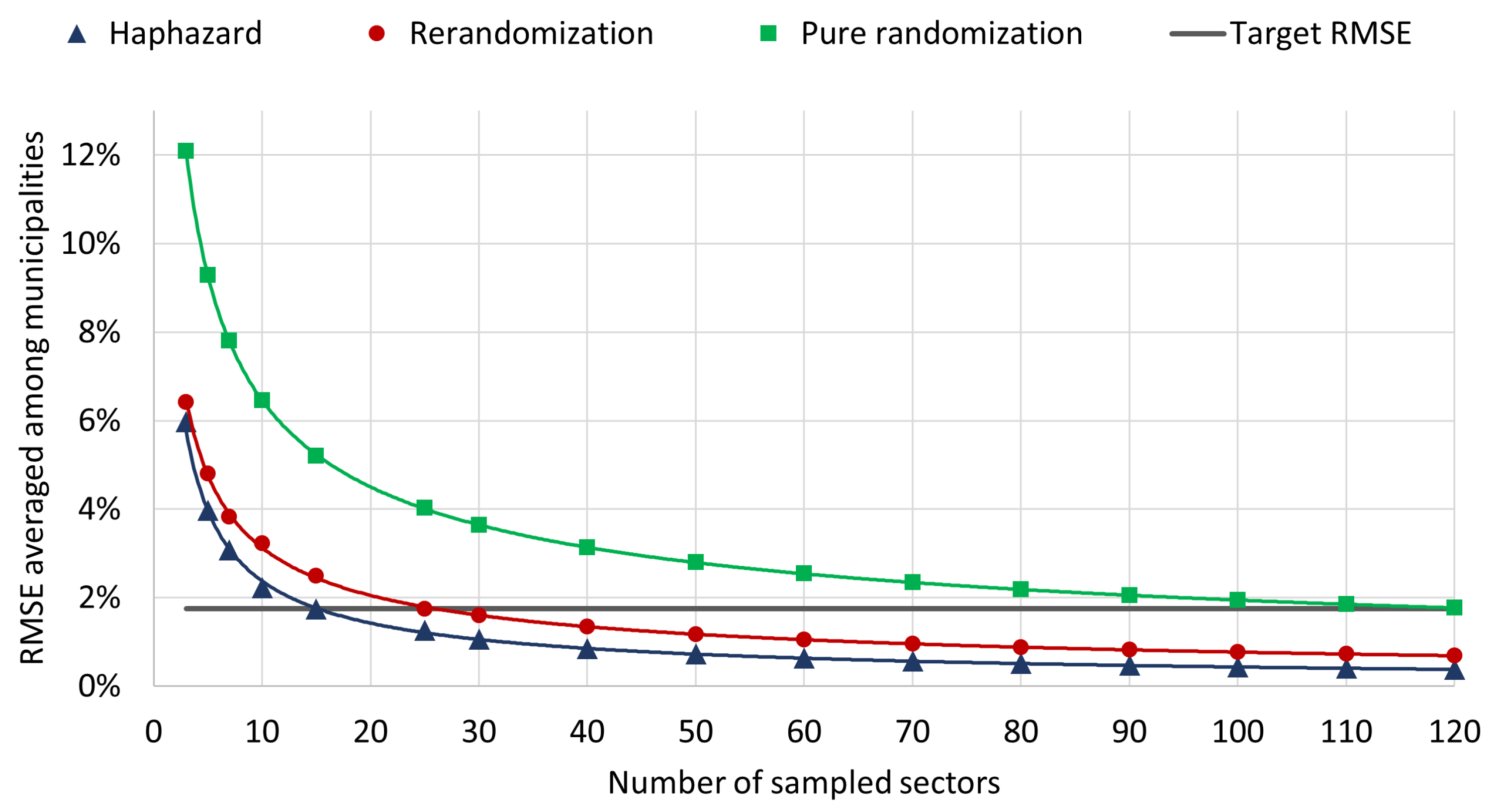
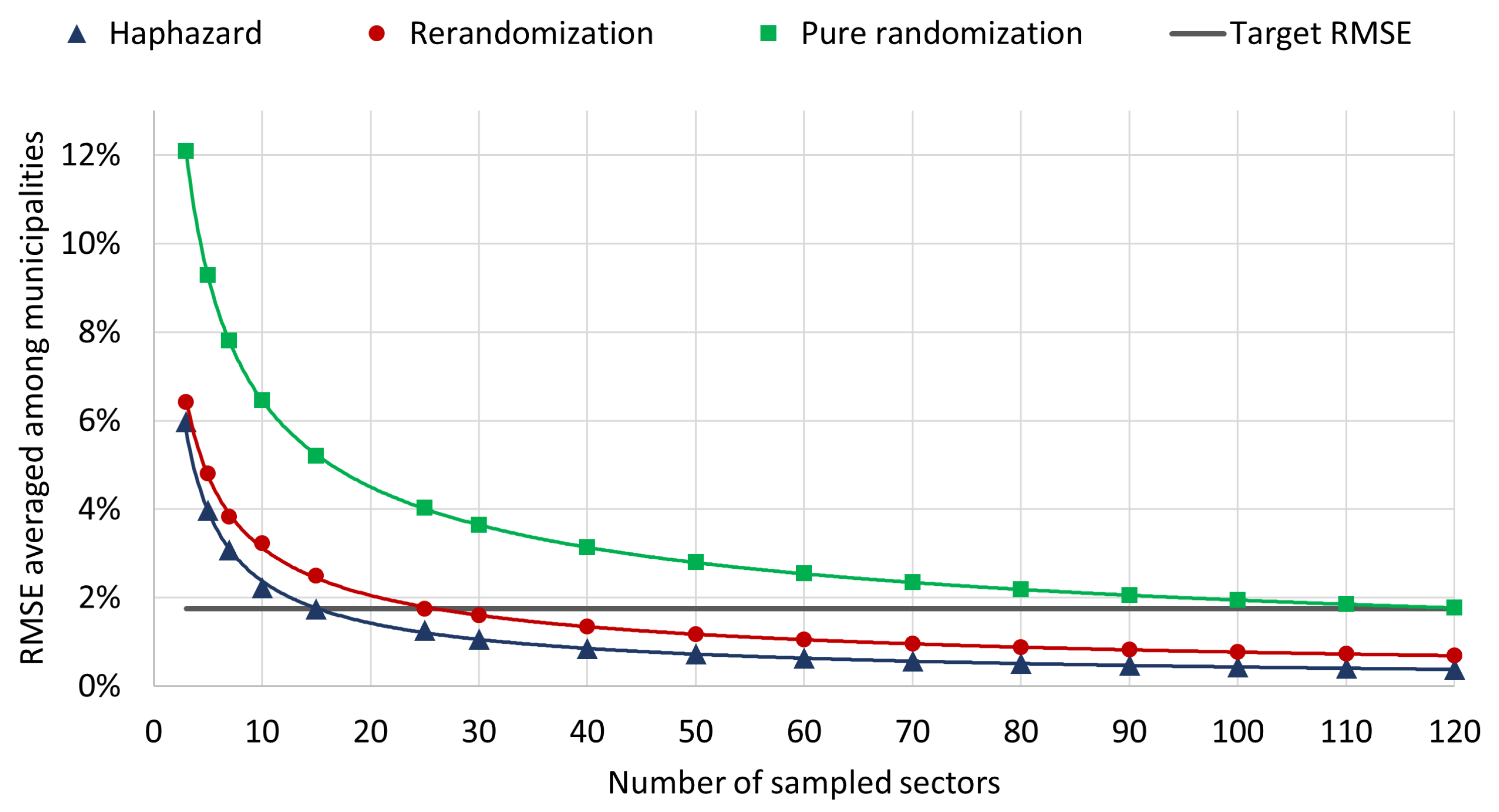
4.2. Root Mean Square Errors of Simulated Estimations
5. Final Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IBGE | Instituto Brasileiro de Geografia e Estatística (Brazilian Institute of Geography and Statistics) |
| IBOPE | Instituto Brasileiro de Opinião Pública e Estatística (Brazilian Institute of Public Opinion and Statistics) |
| MILP | Mixed-Integer Linear Programming |
| MIQP | Mixed-Integer Quadratic Programming |
| RMSE | Root mean square error |
| SD | Standard deviation |
References
- Lauretto, M.S.; Nakano, F.; Pereira, C.A.B.; Stern, J.M. Intentional Sampling by goal optimization with decoupling by stochastic perturbation. AIP Conf. Proc. 2012, 1490, 189–201. [Google Scholar]
- Lauretto, M.S.; Stern, R.B.; Morgan, K.L.; Clark, M.H.; Stern, J.M. Haphazard intentional allocation an rerandomization to improve covariate balance in experiments. AIP Conf. Proc 2017, 1853, 050003. [Google Scholar]
- Fossaluza, V.; Lauretto, M.S.; Pereira, C.A.B.; Stern, J.M. Combining Optimization and Randomization Approaches for the Design of Clinical Trials. In Interdisciplinary Bayesian Statistics; Springer: New York, NY, USA, 2015; pp. 173–184. [Google Scholar]
- Stern, J.M. Decoupling, Sparsity, Randomization, and Objective Bayesian Inference. Cybern. Hum. Knowing 2008, 15, 49–68. [Google Scholar]
- Lauretto, M.S.; Stern, R.B.; Ribeiro, C.O.; Stern, J.M. Haphazard Intentional Sampling Techniques in Network Design of Monitoring Stations. Proceedings 2019, 33, 12. [Google Scholar] [CrossRef] [Green Version]
- Morgan, K.L.; Rubin, D.B. Rerandomization to improve covariate balance in experiments. Ann. Stat. 2012, 40, 1263–1282. [Google Scholar] [CrossRef]
- Stern, J.M. Symmetry, Invariance and Ontology in Physics and Statistics. Symmetry 2011, 3, 611–635. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2012. [Google Scholar]
- Wolsey, L.A.; Nemhauser, G.L. Integer and Combinatorial Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Ward, J.; Wendell, R. Technical Note-A New Norm for Measuring Distance Which Yields Linear Location Problems. Oper. Res. 1980, 28, 836–844. [Google Scholar] [CrossRef]
- Murtagh, B.A. Advanced Linear Programming: Computation And Practice; McGraw-Hill International Book Co.: New York, NY, USA, 1981. [Google Scholar]
- EPICOVID19. Available online: http://www.epicovid19brasil.org/?page_id=472 (accessed on 21 August 2020).
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Am. Psychol. Assoc. (APA) 1971, 76, 378–382. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Gurobi Optimization Inc. Gurobi: Gurobi Optimizer 9.01 Interface; R Package Version 9.01; Gurobi Optimization Inc.: Beaverton, OR, USA, 2021. [Google Scholar]
- Morgan, K.L.; Rubin, D.B. Rerandomization to Balance Tiers of Covariates. J. Am. Stat. Assoc. 2015, 110, 1412–1421. [Google Scholar] [CrossRef] [PubMed] [Green Version]

{kind=link}
{kind=link}
{kind=link}
| Sectors | Time (s) | |
|---|---|---|
| <50 | 0.1 | 5 |
| 50–4000 | 0.01 | 30 |
| >4000 | 0.001 | 120 |
| City | Haphazard | Rerandomizaton | Pure Randomizaton | |||
|---|---|---|---|---|---|---|
| RMSE | SD | RMSE | SD | RMSE | SD | |
| São Paulo | 1.6558% | 1.6516% | 2.4683% | 2.3900% | 4.9930% | 4.9899% |
| Rorainópolis | 0.8582% | 0.7487% | 1.5116% | 1.4310% | 3.0028% | 3.0008% |
| Rio de Janeiro | 1.3864% | 1.3310% | 1.9441% | 1.9394% | 4.6324% | 4.6216% |
| Oiapoque | 1.3887% | 1.3835% | 1.7651% | 1.7509% | 3.2107% | 3.2107% |
| Marília | 1.1624% | 1.1603% | 1.4787% | 1.4737% | 3.4950% | 3.4919% |
| Iguatu | 0.8329% | 0.8196% | 1.3029% | 1.3025% | 3.9094% | 3.9003% |
| Cruzeiro do Sul | 1.3873% | 1.3489% | 2.0482% | 2.0457% | 5.0029% | 5.0003% |
| Corrente | 0.7496% | 0.7000% | 1.0708% | 1.0665% | 2.8250% | 2.8230% |
| Campos dos Goytacazes | 0.9419% | 0.9350% | 1.8786% | 1.8522% | 4.4839% | 4.4829% |
| Brasília | 1.7978% | 1.3434% | 1.5739% | 1.5299% | 3.9608% | 3.9539% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miguel, M.; Waissman, R.; Lauretto, M.; Stern, J. Survey Optimization via the Haphazard Intentional Sampling Method. Phys. Sci. Forum 2021, 3, 4. https://doi.org/10.3390/psf2021003004
Miguel M, Waissman R, Lauretto M, Stern J. Survey Optimization via the Haphazard Intentional Sampling Method. Physical Sciences Forum. 2021; 3(1):4. https://doi.org/10.3390/psf2021003004
Chicago/Turabian StyleMiguel, Miguel, Rafael Waissman, Marcelo Lauretto, and Julio Stern. 2021. "Survey Optimization via the Haphazard Intentional Sampling Method" Physical Sciences Forum 3, no. 1: 4. https://doi.org/10.3390/psf2021003004
APA StyleMiguel, M., Waissman, R., Lauretto, M., & Stern, J. (2021). Survey Optimization via the Haphazard Intentional Sampling Method. Physical Sciences Forum, 3(1), 4. https://doi.org/10.3390/psf2021003004