
A Weakly Informative Prior for Resonance Frequencies †


Abstract
:1. Introduction
2. Notation
3. Conflict
A Simple Way Out?
4. Solution
4.1. Derivation of
4.2. Sampling from
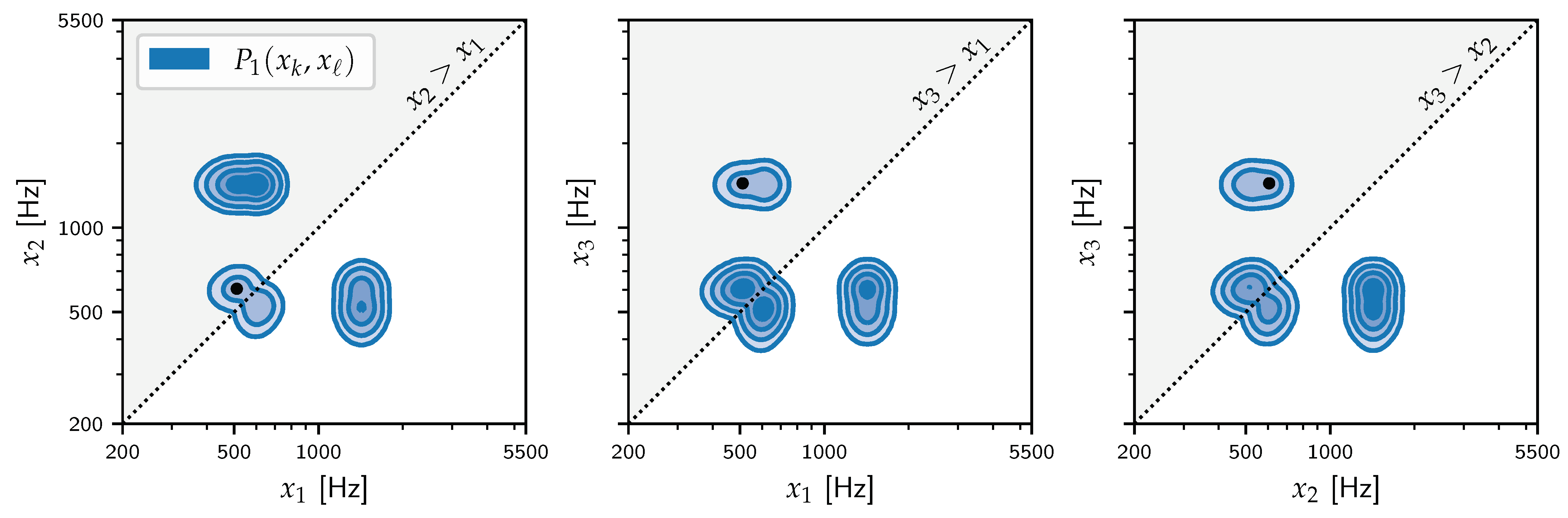
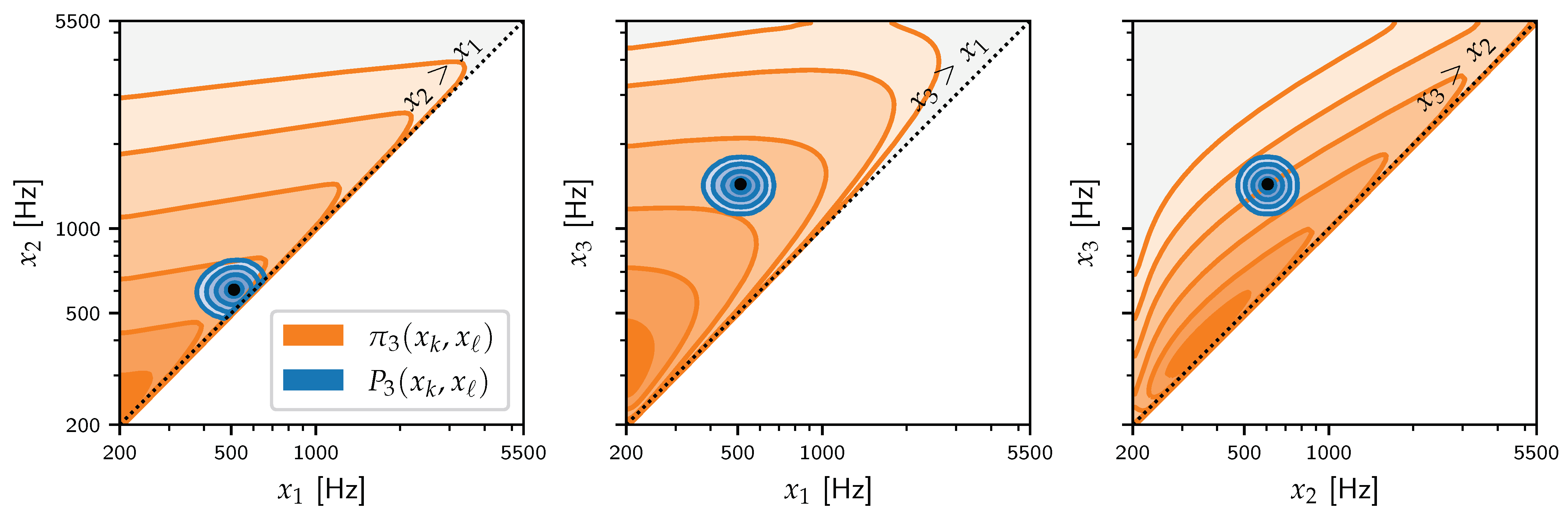
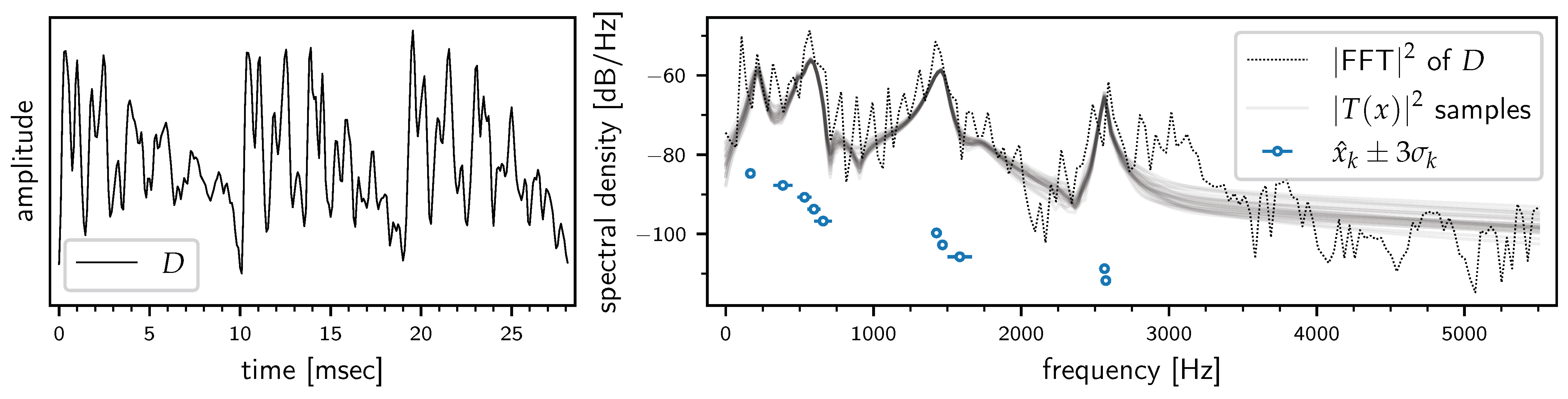
5. Application: The VTR Problem
5.1. Experiment I: Comparing and
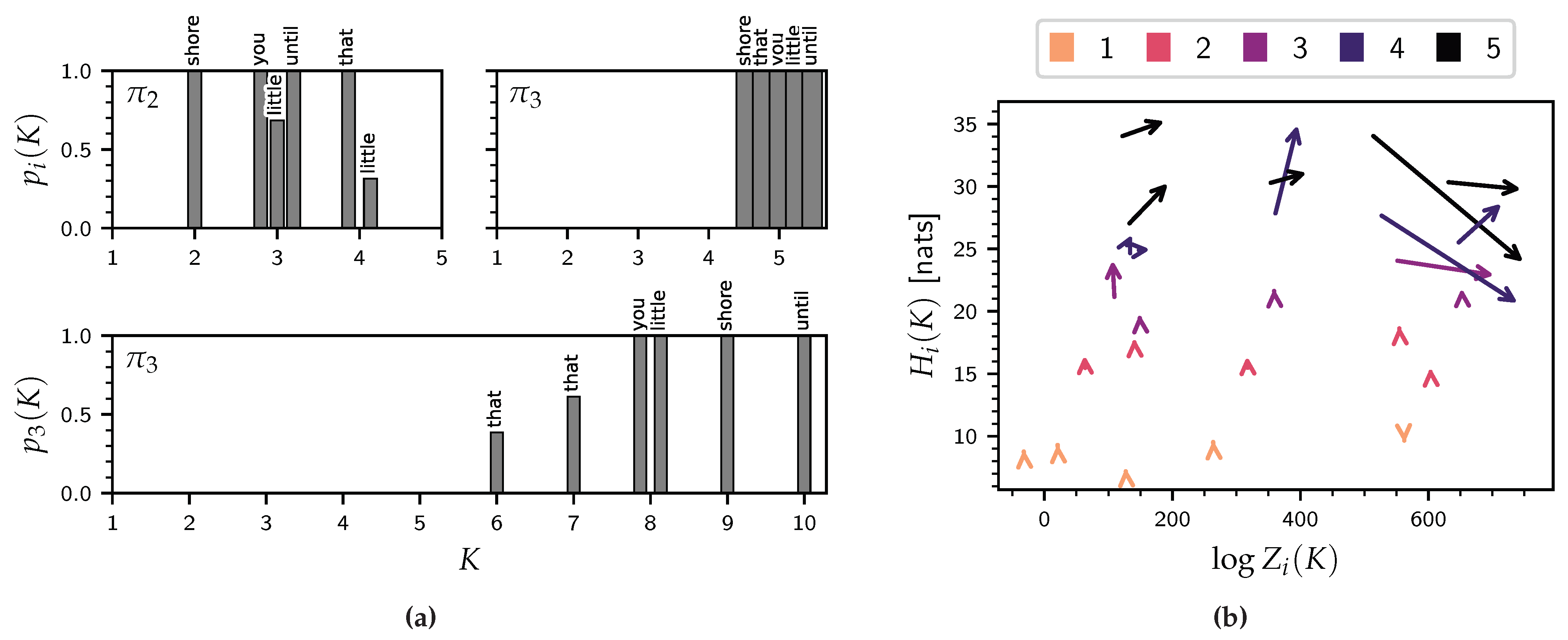
5.2. Experiment II: ‘Free’ Analysis
6. Discussion
It is only when the information in the prior is comparable to the information in the data that the prior probability can make any real difference in parameter estimation problems or in model selection problems.([32], p. 9)
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Skilling, J. Nested Sampling for General Bayesian Computation. Bayesian Anal. 2006, 1, 833–859. [Google Scholar] [CrossRef]
- Green, P.J. Reversible Jump Markov Chain Monte Carlo Computation and Bayesian Model Determination. Biometrika 1995, 82, 711–732. [Google Scholar] [CrossRef]
- Mark, Y.Z.; Hasegawa-johnson, M. Particle Filtering Approach to Bayesian Formant Tracking. In Proceedings of the IEEE Workshop on Statistical Signal Processing, St. Louis, MO, USA, 28 September–1 October 2003. [Google Scholar]
- Zheng, Y.; Hasegawa-Johnson, M. Formant Tracking by Mixture State Particle Filter. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, pp. 1–565. [Google Scholar] [CrossRef]
- Yan, Q.; Vaseghi, S.; Zavarehei, E.; Milner, B.; Darch, J.; White, P.; Andrianakis, I. Formant Tracking Linear Prediction Model Using HMMs and Kalman Filters for Noisy Speech Processing. Comput. Speech Lang. 2007, 21, 543–561. [Google Scholar] [CrossRef]
- Mehta, D.D.; Rudoy, D.; Wolfe, P.J. Kalman-Based Autoregressive Moving Average Modeling and Inference for Formant and Antiformant Tracking. J. Acoust. Soc. Am. 2012, 132, 1732–1746. [Google Scholar] [CrossRef]
- Shi, Y.; Chang, E. Spectrogram-Based Formant Tracking via Particle Filters. In Proceedings of the (ICASSP ’03), 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; Volume 1, p. 1. [Google Scholar] [CrossRef]
- Deng, L.; Lee, L.J.; Attias, H.; Acero, A. Adaptive Kalman Filtering and Smoothing for Tracking Vocal Tract Resonances Using a Continuous-Valued Hidden Dynamic Model. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 13–23. [Google Scholar] [CrossRef]
- Luberadzka, J.; Kayser, H.; Hohmann, V. Glimpsed Periodicity Features and Recursive Bayesian Estimation for Modeling Attentive Voice Tracking. Int. Congr. Acoust. 2019, 9, 8. [Google Scholar]
- Stephens, M. Dealing with Label Switching in Mixture Models. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2000, 62, 795–809. [Google Scholar] [CrossRef]
- Celeux, G.; Kamary, K.; Malsiner-Walli, G.; Marin, J.M.; Robert, C.P. Computational Solutions for Bayesian Inference in Mixture Models. arXiv 2018, arXiv:1812.07240. [Google Scholar]
- Celeux, G.; Fruewirth-Schnatter, S.; Robert, C.P. Model Selection for Mixture Models - Perspectives and Strategies. arXiv 2018, arXiv:1812.09885. [Google Scholar]
- Bretthorst, G.L. Bayesian Spectrum Analysis and Parameter Estimation; Springer: Berlin/Heidelberg, Germany, 1988. [Google Scholar]
- Knuth, K.H.; Skilling, J. Foundations of Inference. Axioms 2012, 1, 38–73. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Prior Probabilities. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 227–241. [Google Scholar] [CrossRef]
- Kominek, J.; Black, A.W. The CMU Arctic Speech Databases. In Proceedings of the Fifth ISCA Workshop on Speech Synthesis, Pittsburgh, PA, USA, 14–16 June 2004. [Google Scholar]
- Van Soom, M.; de Boer, B. A New Approach to the Formant Measuring Problem. Proceedings 2019, 33, 29. [Google Scholar] [CrossRef] [Green Version]
- Van Soom, M.; de Boer, B. Detrending the Waveforms of Steady-State Vowels. Entropy 2020, 22, 331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Speagle, J.S. Dynesty: A Dynamic Nested Sampling Package for Estimating Bayesian Posteriors and Evidences. arXiv 2019, arXiv:1904.02180. [Google Scholar] [CrossRef] [Green Version]
- Feroz, F.; Hobson, M.P.; Bridges, M. MULTINEST: An Efficient and Robust Bayesian Inference Tool for Cosmology and Particle Physics. Mon. Not. R. Astron. Soc. 2009, 398, 1601–1614. [Google Scholar] [CrossRef] [Green Version]
- Neal, R.M. Slice Sampling. Ann. Stat. 2003, 31, 705–767. [Google Scholar] [CrossRef]
- Handley, W.J.; Hobson, M.P.; Lasenby, A.N. POLYCHORD: Nested Sampling for Cosmology. Mon. Not. R. Astron. Soc. 2015, 450, L61–L65. [Google Scholar] [CrossRef]
- Handley, W.J.; Hobson, M.P.; Lasenby, A.N. POLYCHORD: Next-Generation Nested Sampling. Mon. Not. R. Astron. Soc. 2015, 453, 4384–4398. [Google Scholar] [CrossRef] [Green Version]
- Buchner, J. Nested Sampling Methods. arXiv 2021, arXiv:2101.09675. [Google Scholar]
- Peterson, G.E.; Barney, H.L. Control Methods Used in a Study of the Vowels. J. Acoust. Soc. Am. 1952, 24, 175–184. [Google Scholar] [CrossRef]
- Hillenbrand, J.; Getty, L.A.; Clark, M.J.; Wheeler, K. Acoustic Characteristics of American English Vowels. J. Acoust. Soc. Am. 1995, 97, 3099–3111. [Google Scholar] [CrossRef] [Green Version]
- Vallée, N. Systèmes Vocaliques: De La Typologie Aux Prédictions. Ph.D. Thesis, Université Stendhal, Grenoble, France, 1994. [Google Scholar]
- Kent, R.D.; Vorperian, H.K. Static Measurements of Vowel Formant Frequencies and Bandwidths: A Review. J. Commun. Disord. 2018, 74, 74–97. [Google Scholar] [CrossRef]
- Vorperian, H.K.; Kent, R.D.; Lee, Y.; Bolt, D.M. Corner Vowels in Males and Females Ages 4 to 20 Years: Fundamental and F1–F4 Formant Frequencies. J. Acoust. Soc. Am. 2019, 146, 3255–3274. [Google Scholar] [CrossRef] [PubMed]
- Klatt, D.H. Software for a Cascade/Parallel Formant Synthesizer. J. Acoust. Soc. Am. 1980, 67, 971–995. [Google Scholar] [CrossRef] [Green Version]
- de Boer, B. Acoustic Tubes with Maximal and Minimal Resonance Frequencies. J. Acoust. Soc. Am. 2008, 123, 3732. [Google Scholar] [CrossRef] [Green Version]
- Bretthorst, G.L. Bayesian Analysis. II. Signal Detection and Model Selection. J. Magn. Reson. 1990, 88, 552–570. [Google Scholar] [CrossRef]
- Buscicchio, R.; Roebber, E.; Goldstein, J.M.; Moore, C.J. Label Switching Problem in Bayesian Analysis for Gravitational Wave Astronomy. Phys. Rev. D 2019, 100, 084041. [Google Scholar] [CrossRef] [Green Version]
- Wilson, A.G.; Wu, Y.; Holland, D.J.; Nowozin, S.; Mantle, M.D.; Gladden, L.F.; Blake, A. Bayesian Inference for NMR Spectroscopy with Applications to Chemical Quantification. arXiv 2014, arXiv:1402.3580. [Google Scholar]
- Xu, K.; Marrelec, G.; Bernard, S.; Grimal, Q. Lorentzian-Model-Based Bayesian Analysis for Automated Estimation of Attenuated Resonance Spectrum. IEEE Trans. Signal Process. 2019, 67, 4–16. [Google Scholar] [CrossRef]
- Trassinelli, M. Bayesian Data Analysis Tools for Atomic Physics. Nucl. Instruments Methods Phys. Res. Sect. Beam Interact. Mater. Atoms 2017, 408, 301–312. [Google Scholar] [CrossRef] [Green Version]
- Fancher, C.M.; Han, Z.; Levin, I.; Page, K.; Reich, B.J.; Smith, R.C.; Wilson, A.G.; Jones, J.L. Use of Bayesian Inference in Crystallographic Structure Refinement via Full Diffraction Profile Analysis. Sci. Rep. 2016, 6, 31625. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Littenberg, T.B.; Cornish, N.J. Bayesian Inference for Spectral Estimation of Gravitational Wave Detector Noise. Phys. Rev. D 2015, 91, 084034. [Google Scholar] [CrossRef] [Green Version]
- Xiang, N. Model-Based Bayesian Analysis in Acoustics—A Tutorial. J. Acoust. Soc. Am. 2020, 148, 1101–1120. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 200 | 600 | 1400 | 2900 | 3500 | |||||||
| 1100 | 3500 | 4000 | 4500 | 5500 | |||||||
| 200 | 500 | 1000 | 1500 | 2000 | 2500 | 3000 | 3500 | 4000 | 4500 | 5000 | |
| other | 200 | 5500 | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van Soom, M.; de Boer, B. A Weakly Informative Prior for Resonance Frequencies. Phys. Sci. Forum 2021, 3, 2. https://doi.org/10.3390/psf2021003002
Van Soom M, de Boer B. A Weakly Informative Prior for Resonance Frequencies. Physical Sciences Forum. 2021; 3(1):2. https://doi.org/10.3390/psf2021003002
Chicago/Turabian StyleVan Soom, Marnix, and Bart de Boer. 2021. "A Weakly Informative Prior for Resonance Frequencies" Physical Sciences Forum 3, no. 1: 2. https://doi.org/10.3390/psf2021003002
APA StyleVan Soom, M., & de Boer, B. (2021). A Weakly Informative Prior for Resonance Frequencies. Physical Sciences Forum, 3(1), 2. https://doi.org/10.3390/psf2021003002