1. Introduction
Magnetic resonance imaging (MRI) is a crucial medical imaging technology that is non-invasive and non-ionizing, providing highly detailed and accurate images of tissues in their natural, living state, which is vital for disease diagnosis and medical research. As an indispensable instrument in both diagnostic medicine and clinical studies, MRI plays an essential role [
1,
2].
Although MRI offers superior diagnostic capabilities, its lengthy imaging times, compared to other modalities, restrict patient throughput. This challenge has spurred innovations aimed at speeding up the MRI process, with the shared objective of significantly reducing scan duration while maintaining image quality [
3,
4]. Accelerating data acquisition during MRI scans is a major focus within the MRI and clinical application community. Typically, scanning one sequence of MR images can take at least 30 min, depending on the body part being scanned, which is considerably longer than most other imaging techniques. However, certain groups such as infants, elderly individuals, and patients with serious diseases who cannot control their body movements, may find it difficult to remain still for the duration of the scan. Prolonged scanning can lead to patient discomfort and may introduce motion artifacts that compromise the quality of the MR images, reducing diagnostic accuracy. Consequently, reducing MRI scan times is crucial for enhancing image quality and patient experience.
MRI scan time is largely dependent on the number of phase encoding steps in the frequency domain (k-space), with common methods to accelerate the process involving the reduction of these steps by skipping phase encoding lines and sampling only partial k-space data. However, this approach can lead to aliasing artifacts due to undersampling, violating the Nyquist criterion [
5]. MRI reconstruction involves generating high-quality, artifact-free MR images from undersampled k-space data, which are then used for diagnostic and clinical purposes. In MRI reconstruction, the challenge lies in solving an inverse problem, where the goal is to recover an image from partially sampled and noisy k-space data. Compressed sensing (CS) [
6] MRI reconstruction and parallel imaging [
3,
7,
8] are effective techniques that address this inverse problem, speeding up MRI scans and reducing artifacts. By allowing for undersampling and heaving the ability to reconstruct high-quality MRI images from undersampled data, CS significantly reduces scan time while offering images that are often comparable to those obtained from fully sampled data.
Traditional MRI reconstruction techniques suffer from several limitations and challenges. While faster MRI scans are desirable to reduce patient discomfort and improve throughput, this could lead to reduced sampling which in turn could compromise the integrity of the reconstructed images. In addition to undersampling, certain techniques may be susceptible to noise and other artifacts which could contaminate the images [
9,
10]. Challenges pertaining to reconstructing multi-contrast images have also been discussed by these papers [
11,
12]. These multi-contrast images are often considered to provide rich and more useful information as they involve combining different types of image modalities and MRI sequences. However, reconstructing these images may be computationally expensive with traditional methods and may also involve managing large and complex datasets. Recent studies have proposed numerous deep-learning models to address these challenges.
Deep learning has seen extensive applications in image processing tasks [
13,
14,
15,
16,
17] because of its ability to efficiently manage multi-scale data and learn hierarchical structures effectively, both of which are essential for precise image reconstruction and enhancement. Convolution neural networks (CNNs) are also extensively utilized in MRI reconstruction due to their proficiency in handling complex patterns and noise inherent in MRI data [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27]. By learning from large datasets, deep learning algorithms can improve the accuracy and speed of reconstructing high-quality images, thus significantly enhancing the diagnostic capabilities of MRI technology. Additionally, the deep learning models may be particularly suited for reconstructing the MRI data. This is because these optimization-based models are designed to iteratively refine their outputs, thereby allowing them to efficiently handle the complex inverse problems associated with the MRI reconstruction. Furthermore, deep learning models can effectively incorporate prior knowledge such as sparsity or smoothness constraints, which are essential for reconstructing high-quality images from undersampled data. Owing to the flexibility available during the model design, it is possible to design models that can enforce the physics of MRI acquisition, such as Fourier encoding of spatial information. This would ensure that the reconstructed images are consistent with the underlying data.
In recent years, optimization-based algorithm unrolling networks have gained significant attention in the field of MRI reconstruction [
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37]. These algorithms are inspired by classical optimization techniques and are designed to address the unique challenges posed by MRI data. One notable development in this area is the introduction of learnable optimization algorithms (LOAs). LOAs enhance the interpretability of deep learning models by incorporating MR physics, thereby improving both model performance and training efficiency. The convergence properties of these LOAs can support the fast convergence of the reconstruction process and speed up the model training [
38,
39]. This paper explores several key approaches within this framework, including gradient descent and proximal gradient descent algorithm-inspired networks, variational networks, iterative shrinkage-thresholding algorithm (ISTA) networks, and alternating direction method of multipliers (ADMM)-inspired networks. These methods leverage iterative optimization techniques to refine MRI reconstructions, effectively reducing artifacts and enhancing image clarity. Additionally, the integration of diffusion models, such as the score-based diffusion model and Domain-conditioned diffusion modeling, represents a novel approach that combines deep learning with diffusion processes to more robustly tackle undersampling issues. LOAs, as a subset of physics-driven machine learning methods [
40], explicitly incorporate known physics-based forward imaging models into deep learning architectures. This integration ensures consistency with k-space measurements during the reconstruction process, offering a comprehensive framework for improving the speed and accuracy of MRI scans and advancing the application of machine learning in medical imaging. These methods collectively represent a robust framework for improving the speed and accuracy of MRI scans, advancing both the theory and application of machine learning in medical imaging. The integration of these sophisticated deep learning techniques with traditional optimization algorithms provides a dual advantage of enhancing diagnostic capabilities while significantly reducing scan times. By reviewing how these optimization methods are used in conjunction with novel deep learning techniques, we aim to shed light on the capabilities of state-of-the-art MRI reconstruction techniques and the scope for future work in this direction.
This paper is organized in the following structure:
Section 1 introduces the importance of MRI reconstruction and LOA methods.
Section 2 presents the compressed sensing (CS)-based MRI reconstruction model.
Section 3 provides a detailed overview of various optimization algorithms utilizing deep learning techniques.
Section 4 discusses the current issues and limitations of learnable optimization models.
Section 5 concludes the paper by summarizing the key findings and implications of the study.
2. MRI Reconstruction Model
Parallel imaging methods, such as the generalized auto-calibrating partially parallel acquisition (GRAPPA) [
4] and ESPIRiT [
41], are k-space techniques that focus on manipulating or reconstructing the k-space data before converting it into the image domains using an inverse Fourier transform [
42]. These methods utilize coil-by-coil auto-calibration to achieve accurate reconstruction.
On the other hand, compressed sensing (CS) exploits the sparsity of MR images in a specific transform domain (e.g., wavelet or total variation) to reconstruct images. For CS to be effective, it requires incoherent sampling, which helps to spread the aliasing artifacts in the image domain in a way that makes them easier to remove. CS is primarily applied in the image domain, removing aliasing artifacts by solving a system of equations that relate the image to be reconstructed and the partial k-space data through coil sensitivities. An example of this approach is sensitivity encoding (SENSE) [
3].
This paper focuses on CS-based methods and different algorithms for solving the system equations derived from them. The formulation for the MRI reconstruction problem in CS-based methods is described by a regularized variational model as follows:
where
is the MR image to be reconstructed, consisting of
n pixels, and
denotes the corresponding undersampled measurement data in k-space. The data fidelity term
enforces physical consistency between the reconstructed image
and the partial data
measured in the k-space. The choice of regularization operator plays a critical role in enforcing sparsity or low-rank constraints to stabilize the reconstruction from undersampled k-space data. A common regularization used is
Norm which promotes sparse solutions by penalizing the sum of absolute values of coefficients in transformed domains. Alternatively, a low-rank or non-convex regularization may also be used depending on the application. While a low-rank regularization leverages the fact that MR images exhibit low-rank structures in certain matrix forms, the non-convex penalties provide stronger sparsity-promoting properties similar to
norm. However, the downside is that the non-convex regularization problems are harder to solve due to non-convexity. A practical example illustrating the effectiveness or advantage of enforcing sparsity in a clinical setting is that by enforcing sparsity in the wavelet domain, CS-based methods have been found to accelerate MRI acquisitions by 4 to 6 times while maintaining the image quality [
3].
The regularization operator : enforces sparsity or low-rank constraints on the MRI data, incorporating prior knowledge to guide the reconstruction and prevent overfitting of the data fidelity term. It is important to note that MR images are generally not sparse in their original spatial domain. Therefore, to effectively apply CS-based methods, the image must be transformed into a domain where it exhibits sparsity, such as the wavelet or Fourier domain. The regularization term typically enforces sparsity in this transformed domain, allowing for accurate image reconstruction from undersampled data.
The weight parameter
balances the data fidelity term and regularization term. The measurement data is typically expressed as
with
representing the noise encountered during acquisition. The forward measurement encoding matrix
utilized in parallel imaging is defined by:
where
refers to the sensitivity maps of
c different coils,
represents the 2D discrete Fourier transform, and
is the binary undersampling mask that captures
m sampled data points according to the undersampling pattern
.
Figure 1 shows the image reconstruction diagram.
Optimization-based reconstruction methods encompass a variety of techniques for solving complex problems such as (
1). These include gradient descent methods like steepest descent [
43], proximal methods such as ADMM for non-smooth optimization, interior point methods for constrained problems, and Newton-type methods for faster convergence. Other approaches include iterative shrinkage-thresholding algorithms for sparse reconstruction, coordinate descent for large-scale problems, stochastic methods like SGD for machine learning applications, and primal-dual methods that optimize in both spaces simultaneously. Each method offers unique advantages, making them suitable for different types of reconstruction problems based on factors such as problem structure, size, and computational requirements.
3. Optimization-Based Network Unrolling Algorithms for MRI Reconstruction
The deep learning-based model has the capability to leverage large datasets and further improve reconstruction performance compared to traditional methods and therefore has had successful applications in clinical fields [
18,
19,
20,
21,
22,
23,
24,
44,
45]. Most existing deep learning-based methods employ end-to-end neural networks that either map partial k-space data directly to reconstructed images [
46,
47,
48,
49,
50], or map partial k-space data to an estimated fully sampled k-space such as RAKI [
51] and Grappa-Net [
52]. By incorporating optimization algorithms in the end-to-end training, both the acquisition scanning times and image reconstruction time can be drastically reduced to reconstruct high-quality images from undersampled k-space data. This could allow for faster imaging without compromising the MRI’s diagnostic accuracy [
51,
52,
53]. To improve the interpretability of the relation between the topology of the deep model and reconstruction results, a new emerging class of deep learning-based methods known as
learnable optimization algorithms (LOA) have attracted much attention, e.g., [
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
54,
55]. LOA was proposed to map existing optimization algorithms to structured networks where each phase of the networks corresponds to one iteration of an optimization algorithm.
The architectures of these networks are modeled after iterative optimization algorithms. They retain the data fidelity term, which describes image formation based on well-established physical principles that are already known and do not need to be relearned. Instead of using manually designed and overly simplified regularization as in classical reconstruction methods, these networks employ deep neural networks for regularization. Typically, these reconstruction networks consist of a few phases, each mimicking one iteration of a traditional optimization-based reconstruction algorithm. The manually designed regularization terms in classical methods are replaced by layers of CNNs, whose parameters are learned during offline training.
For instance, ADMM-Net [
54], ISTA-Net
+ [
56], and cascade network [
19] are applied on single-coil MRI reconstruction, where the encoding matrix is reduced to
as the sensitivity map
is its identity.Variational networks (VNs) [
18] introduced the gradient descent method with given (pre-calculated) sensitivities
. MoDL [
57] proposed a recursive network by unrolling the conjugate gradient algorithm using a weight-sharing strategy. Blind-PMRI-Net [
58] designed three network blocks to alternatively update multi-channel images, sensitivity maps, and the reconstructed MR image using an iterative algorithm based on half-quadratic splitting. VS-Net [
59] derived a variable splitting optimization method. However, existing methods still face the lack of accurate coil sensitivity maps and proper regularization in the parallel imaging problem. Alder et al. [
60] proposed a reconstruction network that unrolled a primal-dual algorithm where the proximal operator is learnable.
3.1. Gradient Descent Algorithm-Inspired Network
3.1.1. Variational Network
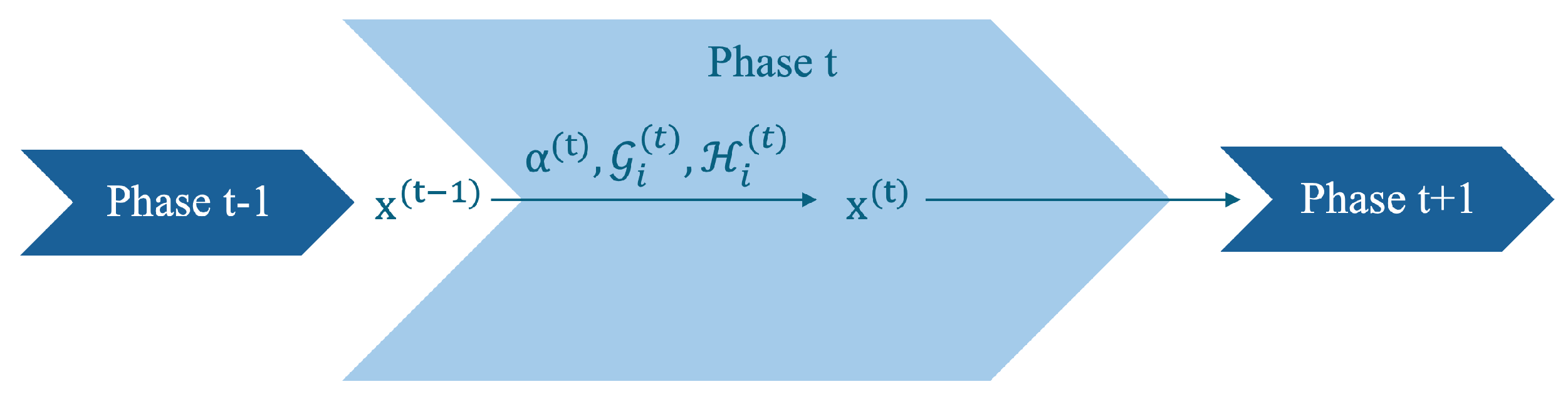
The use of a variational network (VN) [
18] solves model (
1) by using gradient descent:
This model was applied to multi-coil MRI reconstruction. The regularization term was defined by the field-of-experts model:
1>. A convolution neural network
is applied to the MRI data. The function
is defined as non-linear potential functions which are composed of scalar activation functions. Then take the summation of the inner product of the non-linear term
and the vector of ones
. The sensitivity maps are pre-calculated and being used in
. The algorithm of VN unrolls the step (
3) where the regularizer
is parameterized by the learnable network
together with non-linear activation function
:
Figure 2 shows the iterative process of the reconstruction algorithm of VN.
Owing to the numerous advantages of CNNs, they can function as implicit regularizers, replacing traditional techniques such as
regularization or dropout layers. CNNs excel at feature extraction and enable weight sharing, which reduces the number of parameters compared to fully connected layers, making the model less susceptible to overfitting. Additionally, the hierarchical learning process of CNNs imposes a structured learning approach, naturally limiting the network’s complexity and providing an implicit regularization effect. Learning regularization terms from training data is becoming a popular trend for solving inverse problems. Some methods were developed via a hybrid domain-specific learning model. For instance, E2EVarNet [
61] performs iterative optimization steps in the k-space domain and uses CNNs to learn the gradient of the regularization term in the image domain within each cascade iteratively.
where
is a CNN applied on the complex image,
and
are expand and reduce operators that take care of coil sensitivity maps, respectively. Recurrent VarNet [
62] utilizes recurrent neural networks (RNN) for learning the image-refinement model
. The coil sensitivity maps are estimated and refined during the training phase. It has strong performance in refining image quality and sensitivity maps, particularly in multi-coil MRI. It is also effective in long-term sequence data, but is computationally intensive. Additionally, other variations of VN [
61,
63] have also been developed. E2E-VarNet [
61] employs hybrid domain learning, combining both k-space and image domain approaches through iterative optimization steps using gradient descent. While this method delivers excellent performance in reconstructing undersampled MRI data in both domains, it comes with a complex training process that demands substantial computational resources. Despite its effectiveness, the high computational requirements for training and deployment present a significant challenge. These works demonstrate the potential of combining variational methods with deep learning for solving complex inverse problems in medical imaging.
3.1.2. Denoising Model-Based Regularizations
A group of optimization models employed denoising model-based regularizations [
57,
64,
65]. They help in the reconstruction of high-quality images by iteratively refining the image while reducing noise and preserving important image details. These types of models balance the reconstruction between fitting the observed data and adhering to the learned priors about noise and artifact patterns. The model-based deep learning (MoDL) [
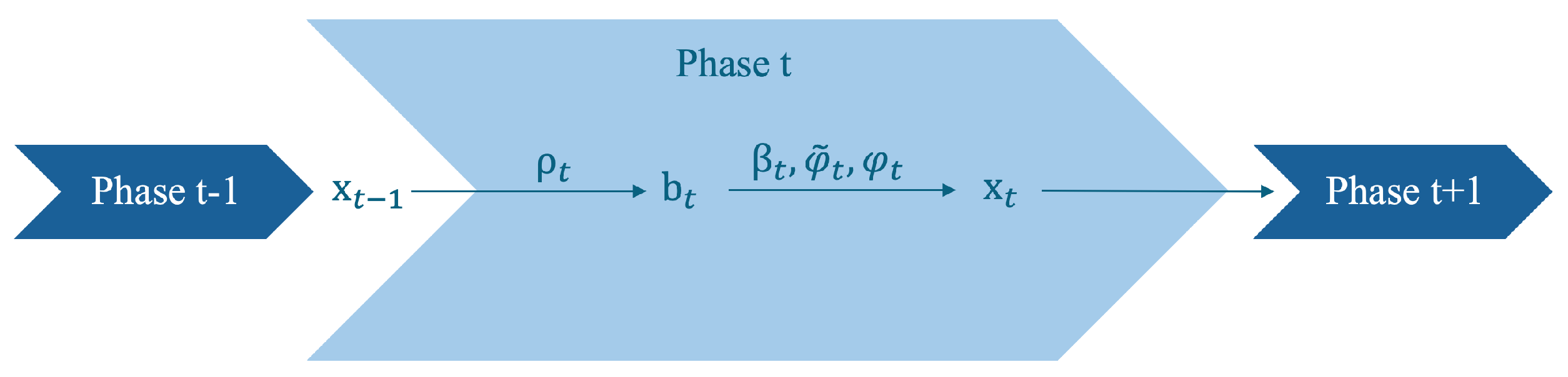
57] framework incorporates a CNN-based regularization prior within a model-based reconstruction scheme. This framework unrolls an alternating recursive algorithm to solve a variational model, where the regularization term is learnable and designed to estimate the noise and alias artifacts:
In Equation (6), the non-linear denoising operator
parameterized by learnable variables
is trained to eliminate noise and artifacts from the image. The regularization term ensures that the reconstructed image
closely approximates the denoised version provided by
. This regularized optimization model is solved by using the normal equations and iterates the following steps:
When dealing with single-channel MRI data, the step (7a) has an analytical solution which can be expressed as a data consistency (DC) layer, where
, and
For the multi-coil MRI data, (7a) is solved using a conjugate gradient optimization algorithm.
Figure 3 shows the iterative process of the reconstruction algorithm of VN.
3.2. Proximal Gradient Descent Algorithm-Inspired Networks
Solving inverse problems using proximal gradient descent has been largely explored and successfully applied in medical imaging reconstruction [
27,
39,
66,
67,
68,
69,
70,
71,
72,
73,
74,
75,
76].
Applying a proximal gradient descent algorithm to approximate a (local) minimizer of (
1) is an iterative process. The first step is gradient descent to force data consistency, and the second step applies a proximal operator to obtain the updated image. The following steps iterates the proximal gradient descent algorithm:
where
is the step size and
is the proximal operator of
defined by
The gradient update step (9a) is straightforward to compute and fully utilizes the relationship between the partial k-space data
and the image
to be reconstructed as derived from MRI physics. This step involves implementing the proximal operation for regularization
, which is equivalent to finding the maximum a posteriori solution for the Gaussian denoising problem at a noise level
[
77,
78]. Thus, the proximal operator can be interpreted as a Gaussian denoiser. However, because the proximal operator
in the objective function (
1) does not admit a closed-form solution, a CNN can be used to substitute
. Constructing the network with residual learning [
66,
71,
76] is suitable to avoid the gradient vanishing problem. This approach allows the CNN to effectively approximate the proximal operator and facilitate the optimization process.
Mardani et al. [
66] introduced a recurrent neural network (RNN) architecture enhanced by residual learning to learn the proximal operator more effectively. This learnable proximal mapping effectively functions as a denoiser, progressively eliminating aliasing artifacts from the input image.
The step size plays a crucial role in determining the convergence and performance of the proximal gradient descent algorithm. LOAs usually apply a learnable step size which adds a layer of adaptability to the optimization process, allowing the algorithm to adjust dynamically to the specific characteristics of the data and the model at each iteration. Traditional fixed step sizes may be either too small, leading to slow convergence, or too large, potentially causing the algorithm to overshoot and oscillate. In contrast, a learnable step size can adjust itself based on the gradient’s magnitude and direction, promoting a more stable and faster convergence. By fine-tuning the step size during the training process, the algorithm can navigate the loss landscape more efficiently, avoiding regions where a fixed step size might struggle. The performance of the proximal gradient descent algorithm in MRI reconstruction is closely tied to how well it can minimize the objective function. A learnable step size has the flexibility that helps in striking a balance between convergence speed and reconstruction accuracy, leading to better overall performance. Additionally, it allows the model to adapt to different noise levels and data inconsistencies, which are common in MRI tasks, further improving the robustness of the reconstruction.
3.2.1. Iterative Shrinkage-Thresholding Algorithm (ISTA) Network
ISTA-Net
+ [
56] formulate the regularizer as a
norm of non-linear transform
. The proximal gradient descent updates (9) become:
The proximal step (11b) can be parameterized as an implicit residual update step due to the lack of a closed-form solution:
where
is a deep neural network with residual learning that approximates the proximal point.
Using the mean value theorem, ISTA-Net
+ derives an approximation theorem:
with
. Thus, the proximal update step (11b) was written as
Assuming
is orthogonal and invertible, ISTA-Net
+ provides the following closed-form solution:
where
and
is the soft shrinkage operator with vector
. Thus, Equation (12) is reduced to an explicit form as given in (14), which we summarize together with (11a) in the following scheme:
The deep network
is applied with the symmetric structure to
and is trained separately to enhance the capacity of the network. The initial input
was set to be the zero-filled reconstruction
.
The loss function was designed in two parts. The first part is the discrepancy loss:
This loss measures the squared discrepancy between the reference image
and the reconstructed image from the last iteration
. The second part of the loss function is to enforce the consistency of
and
:
This loss aims to ensure that
, an identity mapping. The training process minimizes the following loss function:
where
is a balancing parameter.
Figure 4 shows the iterative process of the reconstruction algorithm of VN.
The derivation of the approximation theorem in ISTA-Net+ relies on several critical assumptions including orthogonality and invertibility of non-linear transform (
). One of the primary assumptions is that
is the orthogonal means that the transform
satisfies:
where I is the identity matrix. Another assumption is that
is invertible and it ensures that there exists a unique inverse transform. This assumption ensures that no information is lost and allows for a complete reconstruction of the original signal after transformation. The final assumption is the mean value theorem application. The approximation theorem assumes that
satisfies the conditions necessary for applying the mean value theorem. Discussing the practical implications of these assumptions, the orthogonality assumption allows for more straightforward updates leading to a closed-form solution. Similarly, the invertibility is an important requirement to ensure that the transformation
does not lose any critical information. Finally, the mean value theorem provides a convenient way to approximate the relationship between the transformed variables.
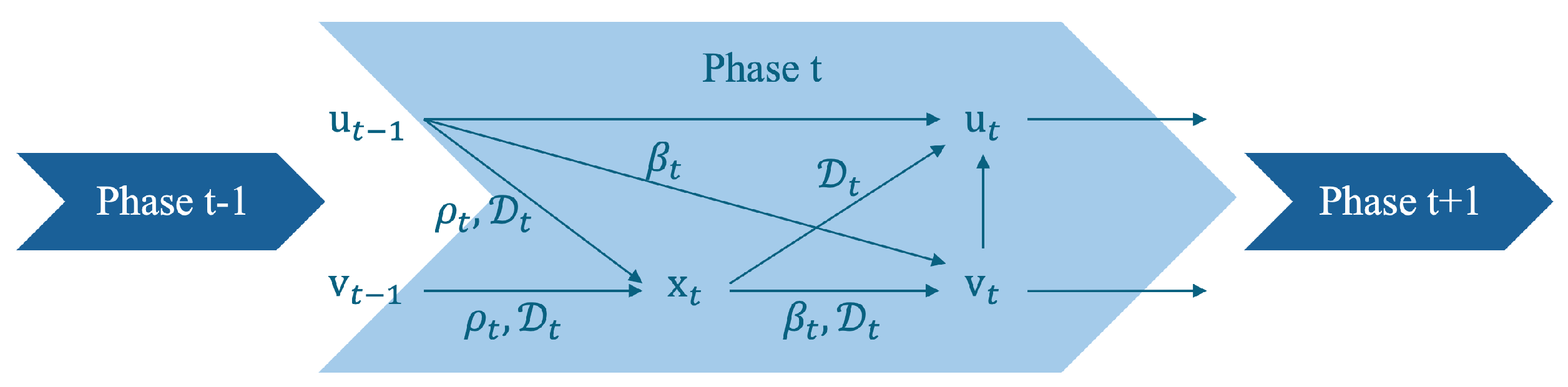
3.2.2. Parallel MRI Network
Parallel MRI networks [
71] leverage residual learning to learn the proximal mapping and tackle model (9), thus bypassing the requirement for pre-calculated coil sensitivity maps in the encoding matrix (
2). Similar to the model for joint reconstruction and synthesis [
70], parallel MRI networks consider the MRI reconstruction as a bi-level optimization problem:
The variable
denotes the multi-coil MRI data scanned from
c coil elements, with each
corresponding to i-th coil for
. The study constructs a model
to incorporate dual regularization terms applied to both image space and k-space, described by:
The channel-combination operator
aims to learn a combination of multi-coil MRI data which integrates the prior information among multiple channels. Then the image domain regularizer
extracts the information from the channel-integration image
. The regularizer
is designed to obtain prior information from k-space data.
The upper-level optimization (20a) is the network training process where the loss function
is defined as the discrepancy between learned
and the ground truth
. The lower level optimization (20b) is solved by the following redefined algorithm:
The proximal operator can be understood as a Gaussian denoiser. Nevertheless, the proximal operator
in the objective function (22b) lacks a closed-form solution, necessitating the use of a CNN as a substitute for
. This network is designed as a residual learning network denoted by
in the image domain and
in the k-space domain, and the algorithm (22a), (22b) and (22c) are implemented in the following scheme:
The CNN
utilizes channel-integration operator
and operates with shared weights across iterations, effectively learning spatial features. However, it may erroneously enhance oscillatory artifacts as real features. In the k-space denoising step (23c), the k-space network
φ focuses on low-frequency data, helping to remove high-frequency artifacts and restore image structure. Alternating between (23b) and (23c) in their respective domains balances their strengths and weaknesses, improving overall performance.
Figure 5 shows the iterative process of reconstruction algorithm of the parallel MRI network.
The construction of iterative algorithm (23) is inspired by cross-domain reconstruction methods [
79,
80,
81,
82], which aimed at improving the quality and speed of MRI image reconstruction by leveraging information from multiple domains—typically the image domain and the k-space (frequency) domain. This approach integrates data and knowledge across different domains to enhance the accuracy and efficiency of reconstructing high-quality images from undersampled MRI data.
Learning sensitivity maps also represent a related group of reconstruction techniques [
61,
83,
84,
85,
86]. Deep J-Sense builds on the joint SENSE model, which solves for both the image and coil sensitivity maps simultaneously during MRI reconstruction. This work incorporates unrolled alternating optimization to refine both the magnetization (image) kernel and the sensitivity maps iteratively. The optimization problem is defined as
are regularization terms for the image and sensitivity maps, respectively.
and
are regularization parameters. This optimization problem is solved iteratively by alternating between updating the image
and the sensitivity maps
.
For the sensitivity maps update:
For the image update:
The end-to-end deep neural networks
and
are applied to refine the sensitivity maps and refine the image, respectively.
Parallel MRI network architecture has also been generalized to quantitative MRI (qMRI) reconstruction problems under a self-supervised learning framework. The next subsection introduces a similar learnable optimization algorithm for the qMRI reconstruction network.
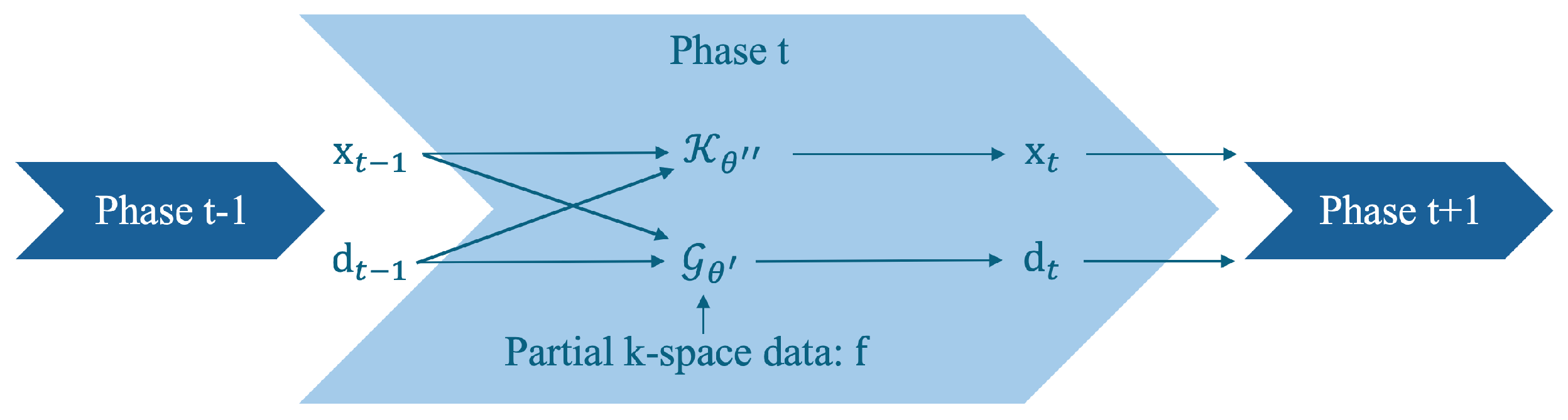
3.2.3. Self-Supervised Approaches for Quantitative MRI Reconstruction
Recent advancements in quantitative MRI (qMRI) reconstruction have seen the incorporation of self-supervised learning techniques, which have proven effective in reconstructing quantitative mapping from the undersampled k-space MRI data. Among these, the RELAX-MORE [
76] algorithm has introduced a self-supervised learning framework that optimizes reconstruction by leveraging the underlying physics of MRI signal acquisition.
RELAX-MORE introduced an optimization algorithm to unroll the proximal gradient for qMRI reconstruction. The loss function minimizes the discrepancy between undersampled reconstructed MRI k-space data and the “true” undersampled k-space data retrospectively. The model, once thoroughly trained, can be adapted to other testing data through the use of transfer learning.
The qMRI reconstruction model aims to reconstruct the quantitative parameters
and this problem can be formulated as a bi-level optimization model:
The model
represents the MR signal function that maps the set of quantitative parameters
to the MRI data. The loss function in (27a) is addressed through a self-supervised learning network, and
is derived from the network parameterized by
. The upper-level problem (27a) focuses on optimizing the learnable parameters for network training, while the lower-level problem (27b) concentrates on optimizing the quantitative MR parameters. RELAX-MORE uses
mapping obtained through the variable flip angle (vFA) method [
87] as an example. The MR signal model
is described by the following equation:
where
represents flip angle for
, where
is the total number of the flip angles acquired.
and
are the spin-lattice relaxation time maps and proton density maps, respectively. Therefore, the parameter set needed for reconstruction is
.
Similar to the parallel MRI network [
71], RELAX-MORE employs a proximal gradient descent algorithm to address the lower level problem (27b), with a residual network structure designed to learn the proximal mapping. Below is the unrolled learnable Algorithm 1 for resolving (27b):
| Algorithm 1 Learnable proximal gradient descent algorithm |
- Input:
. - 1:
for to T do - 2:
for to N do - 3:
- 4:
- 5:
end for - 6:
- 7:
end for - Output:
and .
|
Step 4 implements the residual network structure to learn the proximal operator with regularization . The learnable operators and have a symmetric network structure, and is the soft thresholding operator threshold parameter .
3.3. Alternating Direction Method of Multipliers (ADMM) Algorithm-Inspired Networks
ADMM introduced an auxiliary variable
to solve the following bi-level problem:
we can consider
as a gradient operator to reinforce the sparsity of MRI data such as total variation norm.
The first step is to form the augmented Lagrangian for the given problem. The augmented Lagrangian combines the objective function with a penalty term for the constraint violation and a Lagrange multiplier:
where
is the Lagrange multiplier and
is a penalty parameter.
The ADMM algorithm solves the above problem by alternating the following three subproblems:
We can obtain the closed-form solutions for each subproblem as follows:
If the regularizer is
norm
, then (32b) reduces to
with the soft shrinkage threshold
.
In the ADMM, tuning penalty and regularization parameters play a crucial role in the algorithm’s performance—particularly the penalty parameter and the augmented Lagrangian parameter . These parameters significantly influence the convergence and performance of the algorithm. A well-chosen can accelerate convergence by appropriately weighting the constraints in the problem. However, if is too large, the algorithm may become unstable or oscillate between iterations. Conversely, if is too small, convergence can be excessively slow. The parameter controls the weight of the augmented Lagrangian term in ADMM. It influences the convergence speed and stability of the algorithm. A large can enforce constraints more strictly but may lead to numerical instability, while a small might result in slower convergence. Tuning parameters typically rely on heuristic methods or cross-validation to find a suitable value. One approach to mitigating the challenges of parameter selection is to adaptively update and during the iterations based on the observed residuals. This strategy can help balance the trade-off between convergence speed and stability, but it adds complexity to the algorithm.
Gradient descent is simple and widely used but it suffers from slow convergence, particularly in ill-conditioned problems. ADMM can converge faster for certain problem classes, especially when the objective function can be split into simpler subproblems. Proximal gradient descent extends gradient descent by incorporating proximal operators, making it suitable for optimization problems with non-smooth terms. ADMM can be seen as a more general approach that also leverages proximal operators but in a way that allows for better decomposition of the problem.
ADMM-Net
ADMM-Net [
54] reformulates these three steps through an augmented Lagrangian method. This approach leverages a cell-based architecture to optimize neural network operations for MRI image reconstruction. The network is structured into several layers, each corresponding to a specific operation in the ADMM optimization process. The gradient operator
is parameterized as a deep neural network
. All the scalars
and
are learnable parameters to be trained and updated through ADMM iterations:
The Reconstruction layer (33a) uses a combination of Fourier and penalized transformations to reconstruct images from undersampled k-space data, incorporating learnable penalty parameters and filter matrices. The Convolution layer
applies a convolution operation, transforming the reconstructed image to enhance feature representation, using distinct, learnable filter matrices to increase the network’s capacity. The Non-linear Transform layer (33b) replaces traditional regularization functions with a learnable piecewise linear function, allowing for more flexible and data-driven transformations that go beyond simple thresholding. Finally, the Multiplier Update layer (33c) updates the Lagrangian multipliers, essential for integrating constraints into the learning process, with learnable parameters to adaptively refine the model’s accuracy. Each layer’s output is methodically fed into the next, ensuring a coherent flow that mimics the iterative ADMM process, thus systematically refining the image reconstruction quality with each pass through the network.
Figure 6 shows the iterative process of the reconstruction algorithm of the parallel MRI network.
3.4. Primal-Dual Hybrid Gradient (PDHG) Algorithm-Inspired Networks
There are several networks [
60,
88] are developed inspired by the PDHG algorithm. PDHG can be used to solve the model (
1) by iterating the following steps:
where
H is the data fidelity function defined as
in the model (
1). In the learned primal-dual model [
60], the traditional proximal operators are replaced with learned parametric operators. These operators are not necessarily proximal but are instead learned from training data, aiming to act similarly to denoising operators, such as block matching 3D (BM3D). The proximal operators can be parameterized as deep networks
and
. PD-Net [
88] iterates the following two steps:
The key innovation here is that these operators—both for the primal and dual variables—are parameterized and optimized during training, allowing the model to learn optimal operation strategies directly from the data. The learned primal-dual model operates under a fixed number of iterations, which serves as a stopping criterion. This approach ensures that the computation time remains predictable and manageable, which is beneficial for time-sensitive applications. The algorithm maintains its structure but becomes more adaptive to specific data characteristics through the learning process, potentially enhancing reconstruction quality over traditional methods.
Figure 7 shows the iterative process of the reconstruction algorithm of a parallel MRI network.
3.5. Diffusion Models Meet Gradient Descent for MRI Reconstruction
A notable development for MRI reconstruction using diffusion models is the emergence of denoising diffusion probabilistic models (DDPMs) [
89,
90,
91,
92]. In denoising diffusion probabilistic models (DDPMs), the forward diffusion process systematically introduces noise into the input data, incrementally increasing the noise level until the data becomes pure Gaussian noise. This alteration progressively distorts the original data distribution. Conversely, the reverse diffusion process, or the denoising process, aims to reconstruct the original data structure from this noise-altered distribution. DDPMs effectively employ a Markov chain mechanism to transition from a noise-modified distribution back to the original data distribution via learned Gaussian transitions. The learnable Gaussian noise can be parametrized in a U-net architecture that consists of transformers/attention layers [
93] in each diffusion step. The transformer model has demonstrated promising performance in generating global information and can be effectively utilized for image denoising tasks.
DDPMs represent an innovative class of generative models renowned for their ability to master complex data distributions and achieve high-quality sample generation without relying on adversarial training methods. Their adoption in MRI reconstruction has been met with growing enthusiasm due to their robustness, particularly in handling distribution shifts. Recent studies exploring DDPM-based MRI reconstructions [
89,
90,
91,
92] demonstrate how these models can generate noisy MR images which are progressively denoised through iterative learning at each diffusion step, either unconditionally or conditionally. This approach has shown promise in enhancing MRI workflows by speeding up the imaging process, improving patient comfort, and boosting clinical throughput. Moreover, the model [
90] has proven exceptionally robust, producing high-quality images even when faced with data that deviates from the training set (distribution shifts) [
94], accommodating various patient anatomies and conditions, and thus enhancing the accuracy and reliability of diagnostic imaging.
3.5.1. Score-Based Diffusion Model
Chung et al. [
89] presented an innovative framework that applies score-based diffusion models to solve inverse imaging problems. The core technique involves training a continuous time-dependent score function using denoising score matching. The score function of the data distribution
is defined as the gradient of log density w.r.t the input data. This is estimated by a time-conditional deep neural network
. The score model is trained by minimizing the following loss function on the magnitude image:
During inference, the model alternates between a numerical stochastic differential equation (SDE) solver and a data consistency step to reconstruct images. The method is agnostic to subsampling patterns, enabling its application across various sampling schemes and body parts not included in the training data. Chung et al. [
89] proposed the following Algorithm (2) with the predictor-corrector (PC) sampling algorithm [
95]. For
, the predictor is defined as
with
. The corrector is defined as
with step size
.
Incorporating a gradient descent step to emphasize the data consistency after the predictor and corrector, we can obtain the following Algorithm 2:
| Algorithm 2 Score-based sampling for MRI reconstruction [89] |
- Input:
, Learned score function , step size , noise schedule and MRI encoding matrix . - 1:
for
do - 2:
- 3:
- 4:
- 5:
- 6:
for do - 7:
- 8:
- 9:
- 10:
- 11:
end for - 12:
end for
|
The above Algorithm 2 can be variate to other two different algorithms. One is the parallel implementation for each coil image for parallel MRI reconstruction. The other one considers the correlation among the multiple coil images and eliminates the calculation of sensitivity maps, and the final magnitude image is obtained by using the sum-of-root-sum-of-squares of each coil. The results outperforms conventional deep learning methods, including UNet [
96], DuDoRNet [
97], and E2E-Varnet [
61], which requires complex k-space data.
3.5.2. Domain-Conditioned Diffusion Modeling
Domain-conditioned diffusion modeling (DiMo) [
73] and quantitative DiMo were developed for application on both accelerated multi-coil MRI and quantitative MRI (qMRI) using diffusion models conditioned on the native data domain rather than the image domain. The method incorporates a gradient descent optimization within the diffusion steps to improve feature learning and denoising effectiveness. The training and sampling algorithm for MRI reconstruction is illustrated in Algorithms 3 and 4.
| Algorithm 3 Training process of static DiMo |
- Input:
fully scanned k-space , undersampling mask , partial scanned k-space , and coil sensitivities . Initialization: - 1:
- 2:
▹ DC - 3:
for to do - 4:
▹ GD - 5:
end for - 6:
Take gradient descent update step Until converge - Output:
, .
|
| Algorithm 4 Sampling process of static DiMo |
- Input:
, undersampling mask , partial scanned k-space , and coil sensitivities . - 1:
for
do - 2:
if , else - 3:
- 4:
▹ DC - 5:
for to do - 6:
▹ GD - 7:
end for - 8:
end for - Output:
|
In the training and sampling algorithm, the data consistency (DC) term was used to emphasize the physical consistency between the partial k-space and reconstructed images. Then, the gradient descent (GD) algorithm is applied iteratively into the diffusion step to refine k-space data further. The matrix
only contains a value of one. GD in here solves the optimization problem (
1) without the regularization term.
Static DiMo performed a qualitative comparison with both the image domain diffusion model presented by Chung et al. [
89] and the k-space domain diffusion model MC-DDPM [
98] and demonstrated robust performance in reconstruction quality and noise reduction. Quantitative DiMo reconstructs the quantitative parameter maps from the partial k-space data. The MR signal model
defined in (28) maps MR parameter maps to the static MRI; therefore, it is one more function inside the reconstruction model:
The MR parameter maps are denoted as
where
indicates each MR parameter and
N is the total number of MR parameters to be estimated.
The training and sampling diffusion model for quantitative MRI (qMRI) DiMo follows the same steps as static DiMo, where the signal model should take the inverse when calculating the quantitative maps
from the updated k-space. Quantitative DiMo showed the least error compared to other methods [
99,
100,
101]. This is likely achieved through integrating the unrolling gradient descent algorithm and diffusion denoising network, prioritizing noise suppression without compromising the fidelity and clarity of the underlying tissue structure.
3.6. Bi-Level Optimization Model for Multi-Task Learning
In recent years, a large amount of work introduced the customized variational model for multi-task learning using bi-level optimization models. For example, joint tasks of reconstruction and multi-contrast synthesis [
70] and meta-learning model for MRI reconstruction [
39].
Consider a clinical situation where a patient with suspected multiple sclerosis (MS) undergoes an MRI scan. The clinician requires both T1-weighted and T2-weighted images to assess different tissue characteristics—T1 for detailed anatomical structures and T2 for detecting lesions with high water content, commonly associated with MS. Typically, reconstructing these sequences separately is time-consuming due to the high-resolution requirements. Concurrently, there is a need to synthesize a FLAIR (Fluid-Attenuated Inversion Recovery) image, which is crucial for suppressing cerebrospinal fluid signals and enhancing the visibility of lesions. Given the urgency of diagnosis and the need for comprehensive imaging, a joint reconstruction and synthesis model can be employed. This model not only reconstructs the T1 and T2 sequences simultaneously, thereby reducing overall scan and processing time, but also synthesizes the FLAIR image directly from the acquired data. By leveraging the complementary information between the T1 and T2 sequences, the model ensures that the synthesized FLAIR image is consistent and reliable, providing the clinician with a complete set of images for accurate diagnosis without the need for additional scans.
A provable learnable optimization algorithm [
70] was introduced for joint MRI reconstruction and synthesis. Consider the partial k-space data
of the source modalities (e.g., T1 and T2) obtained from the measurement domain. The goal is to
reconstruct the corresponding images
and
synthesize the image
of the missing modality (e.g., FLAIR) without having its k-space data. The following optimization model is designed:
The first term
ensures the fidelity of the reconstructed images
to their partial k-space data
. The second term
regularizes the images using modality-specific feature extraction operators
The third term
enforces consistency between the synthesized image
and the learned correlation relationship from the reconstructed images
. To synthesize the image
using
and
, a feature-fusion operator
was employed which learns the mapping from the features
and
to the image
.
Denote
, the forward learnable optimization algorithm is presented in Algorithm 5. In step 3, the algorithm performs a gradient descent update with a step size found via line search, while keeping the smoothing parameter
fixed. In step 4, the reduction of
ensures the subsequence which met the
reduction criterion must have an accumulation point that is a Clarke stationary point of the problem.
| Algorithm 5 Learnable descent algorithm for joint MRI reconstruction and synthesis |
- 1:
Input: Initial estimate , step size range , initial smoothing parameter , , . Maximum iterations T. Set tolerance . - 2:
for
do - 3:
, where the step size is determined by a line search such that holds. - 4:
if , set ; otherwise, set . - 5:
if , terminate and go to step 6, - 6:
end for and output .
|
Algorithm 5 is a forward MRI reconstruction algorithm. Let
denote the collection of all the learnable parameters and
denote a parameter to balance the reconstruction part and image synthesis part. The backward network training algorithm is designed to solve a bilevel optimization problem:
The following Algorithm 6 was proposed for training the model for joint reconstruction and synthesis.
| Algorithm 6 Mini-batch alternating direction penalty algorithm |
- 1:
Input Training data , validation data , tolerance . Initialize, , , and , . - 2:
while
do - 3:
Sample training batch and validation batch . - 4:
while do - 5:
for (inner loop) do - 6:
Update - 7:
end for - 8:
Update - 9:
end while and update , . - 10:
end while and output: .
|
The training Algorithm 6 considers updating the network parameters
and the balancing parameter
by minimizing the loss function (40) on both validation and training data sets for each task
.
Figure 8 shows the overall network architecture of iterating forward optimization Algorithm 5 with backward training Algorithm 6.
4. Discussion
4.1. Evaluation Metrics and Loss Functions
To quantitatively compare the performance of several MRI reconstruction algorithms, evaluation metrics are essential. These metrics need to be standardized in order to provide a consistent comparison between algorithms proposed in different studies and provide insights into effectiveness of the algorithms. In this paper, we introduce a few evaluation metrics used in previous studies. A common evaluation metric used across multiple studies is the root mean squared error (RMSE), which provides the square root of the average squared difference between predicted and actual images. The RMSE between the reconstruction
and the ground truth
is defined as
Studies have also discussed the peak signal-to-noise ratio (PSNR), which expresses the ratio between the maximum possible pixel value and the power of the noise. A higher PSNR values indicate better predictive quality. Typically, a PSNR of above 30 dB is considered acceptable for reconstructions. The PSNR is defined as follows.
where
N is the total number of pixels in the magnitude of ground truth.
Finally, the structural similarity index (SSIM) evaluates the quality of the model predictions by comparing luminance, contrast, and structure between the reconstructed and original images. A higher SSIM indicates closer structural similarity. The SSIM ranges between −1 and 1, with 1 being considered as being perfect structural similarity. The following equation calculates SSIM between reconstruction
and reference
:
where
are local means of pixel intensity,
denote the standard deviation and
is covariance between
and
.
are constants to avoid the denominator being zero, where
.
L is the largest pixel value of the magnitude of images.
Loss functions play crucial roles in training the network and optimizing model performance. Studies proposing various networks have also discussed novel loss functions that may enhance image reconstruction. We listed the loss functions that are being used in several key representative methods. Most of the LOAs are supervised learning which requires ground truth in the loss function. RELAX-MORE [
76] is subject-dependent self-supervised learning method that does not require fully sampled k-space data. The
Table 1 shows the comparisons of different loss functions.
It is worth noting that the goal for diffusion models is to learn the Gaussian noise added in each diffusion step, the network learns to remove the noise that is added in the forward process and matches the target distribution. Therefore, the loss function measures the discrepancy between the estimated learned noise in each step and the actual added noise in the training process.
4.2. Comparing Learnable Optimization Algorithms (LOA) with Traditional Optimization
Methods
LOA has emerged as an effective alternative to traditional optimization methods. Despite its advantages, the LOA is computationally expensive, especially during the training phase. LOAs need a substantial amount of training data to generalize well across optimization tasks. Furthermore, owing to the requirement of large-scale training, the training process for the LOA could also be quite slow, especially when suffering the curse of dimensionality. Discussing the predictive performance and accuracy of the LOA and comparing it with the traditional optimization methods, LOA often tends to outperform traditional methods on more complex non-convex problems with irregular landscapes. Focusing on MRI reconstruction, LOAs have shown impressive results in recovering high-quality MRI images from undersampled k-space data. Additionally, studies have demonstrated that LOAs can handle noise and artifacts better, which are common in clinical MRI scans. Another advantage is that once the LOA is trained, they can reconstruct MRI images much quicker than traditional methods. This efficiency makes LOAs more attractive for real-time applications. However, as indicated earlier, this efficiency comes at the cost of increasing training time.
4.3. Strengths, Weakness, and Performance of the Reviewed Algorithms in Different Scenarios
In this paper, several algorithms focusing on MRI reconstruction have been discussed. To fully understand the limitations of existing algorithms and the need for future research, it is vital to perform a comparative analysis between the algorithms in this paper. The
Table 2 summarized a detailed comparisons among several well-known LOA inspired methods.
4.4. Selection of Acquisition Parameters
The selection of acquisition parameters is a critical aspect of MRI reconstruction, influencing the efficiency and accuracy of deep learning models. The architecture of deep reconstruction networks and efficient numerical methods play a pivotal role in this selection. In LOAs, one must determine the appropriate number of iterations
T and the initial step size for gradient descent to ensure the reconstruction network converges to the local optimum of the problem (
1). The convergence to the local optimum is essential for producing high-quality reconstructed images. The required number of iterations and the step size depend on the specific application tasks and whether the step size is learnable or fixed in the gradient descent-based algorithm used for reconstruction. Proper tuning of these parameters is crucial for optimizing the performance of the reconstruction network.
4.5. Theoretical Convergence and Practical Considerations
While unrolling-based deep-learning methods are derived from numerical algorithms with convergence guarantees, these guarantees do not always extend to the unrolled methods due to their dynamic nature and the direct replacement of functions by neural networks. Theoretical convergence is compromised, and only a few works have analyzed the convergence behavior of unrolling-based methods in theory. Notable studies include [
38,
39,
70], which provide insights into the theoretical convergence of these methods. For example, reference [
70] proved that if
satisfies the stopping criterion, then there exists a subsequence
at least one accumulation point, and every accumulation point of
is a Clarke stationary point of the (
1). Understanding the convergence properties of unrolled networks is crucial for ensuring the reliability and robustness of MRI reconstruction algorithms. Future research should focus on establishing stronger theoretical foundations and convergence guarantees for unrolling-based deep learning methods. This includes developing new theoretical frameworks that can account for the dynamic and adaptive nature of these models, as well as creating more rigorous validation protocols.
A significant application of deep learning in clinical MRI is its use in accelerating image acquisition, making it possible to acquire images up to 10 times faster than conventional methods without compromising diagnostic quality [
24,
94,
103]. Artifact reduction is a critical challenge in MRI, where motion artifacts or metal implants can significantly degrade image quality. Deep learning models have shown scalability across different MRI modalities and anatomical regions, which is crucial for their widespread adoption in clinical practice. The ability to handle large datasets and perform real-time processing is also vital for integrating these models into routine workflows. For deep learning models to be truly effective in clinical settings, they must generalize well across diverse patient populations, imaging protocols, and MRI scanners. This requires robust training on large, heterogeneous datasets and careful validation across multiple sites and clinical conditions.
4.6. Limitations of the Existing Deep Learning Approaches
Despite the advancements in reconstructing MRI images through deep learning methods, there are several practical challenges that need to be addressed. Most deep learning approaches focus on designing end-to-end networks that are independent of intrinsic MRI physical characteristics, leading to sub-optimal performance. Deep learning methods are also often criticized for their lack of mathematical interpretation, being seen as “black boxes”. Acquiring and processing large high-quality datasets that are needed for training deep-learning models may be difficult, especially when dealing with diverse patient populations and varying imaging conditions. Training deep neural networks may require a large quantity of data and may be prone to over-fitting when data is scarce. Additionally, both the training and inference process of deep learning models may require substantial computational resources, which may act as a barrier for certain medical institutions. Hence, it may be a trade-off between cost and time. Ensuring that the model generalizes well across different MRI scans and clinical settings is also essential for the widespread adoption of deep-learning techniques. Finally, the technologies utilized in clinical settings might need to be validated, transparent, and fully interpretable in order to ensure that clinicians trust the decision-making capabilities of the algorithms. Future studies may focus on addressing the above-mentioned challenges, which would accelerate the adoption of deep learning methods and advance the field of medical imaging.
4.7. Computational Burden, Memory Consumption, and Inference Time
Deep learning-based MRI reconstruction methods, particularly those involving unrolled optimization algorithms, demand significant computational resources. The training process involves substantial GPU memory consumption to store intermediate results and their corresponding gradients. This high memory requirement, coupled with potentially long training times, arises from the need to repeatedly apply the forward and adjoint operators during training.
However, diffusion models, for example, require long inference times due to the pre-scheduled denoising steps involved in the sampling process. Additionally, training diffusion models is time-consuming and memory-intensive, particularly because of the self-attention modules incorporated in the denoising network at each diffusion step.
The LOAs such as ISTA-Net, and PD-Net unroll iterative optimization procedures, with each phase of the network being trained independently without parameter sharing. As the number of iterations increases, so does the computational and memory burden, making these methods more resource-intensive. It is crucial to acknowledge these limitations in the design of the network architecture, such as long inference times, model complexity, memory consumption, and computational burden, alongside the advantages of these methods. Addressing these challenges will be key to improving the feasibility and efficiency of deep learning approaches in MRI reconstruction.
To address these challenges, techniques such as pruning, quantization, and knowledge distillation can reduce the model size and memory footprint without significantly sacrificing performance. In addition, implement gradient checkpointing, where only a subset of activations is stored during the forward pass, and others are recomputed during the backward pass. This can significantly reduce memory usage during training. Splitting the training process across multiple GPUs or even across different nodes in a cluster can help manage memory constraints by distributing the workload. Advancements in hardware acceleration, such as the use of specialized AI chips and tensor processing units (TPUs), could further enhance the performance of deep learning-based MRI reconstruction.
4.8. Other Related Reconstruction Methods
Federated learning (FL) for MRI reconstruction [
104,
105,
106] is an innovative approach that enables multiple institutions to collaboratively train a deep learning model without sharing patient data, thus preserving privacy. This method is particularly valuable in the medical imaging field, where data privacy and security are paramount, and where institutions may have diverse datasets collected under different conditions, such as varying sensors, disease types, and acquisition protocols. For example, the FL-MR framework [
105] trains local models at multiple institutions. Each local model computes reconstruction losses and update parameters through gradient descent. Then the updated model parameters are sent to the central server, where they are averaged to update the global model. The updated global model is then redistributed to local institutions for further training, iterating until the model converges.
Plug-and-play (PnP) methods [
78,
107,
108,
109] integrate state-of-the-art denoising algorithms as priors into the image reconstruction process. The PnP approach allows for the decoupling of image modeling (denoising) from forward modeling (data acquisition), which is particularly advantageous in MRI, where the forward model can vary significantly between different scans. For example, proximal-based PnP methods [
78] leverage the ADMM framework to decouple the regularization term (which encodes prior knowledge of the image) from the data fidelity term. In these methods, a denoising algorithm replaces the proximal operator that would typically be used in the optimization process. Gradient-based PnP methods [
108] involve using gradient descent-based algorithms like the fast iterative shrinkage-thresholding algorithm (FISTA) in combination with denoisers. Instead of solving the proximal update exactly, a gradient descent step is performed to handle the data fidelity term, followed by a denoising step that uses the denoiser as a regularizer. This category emphasizes computational efficiency, as gradient steps are generally less expensive than solving proximal updates. The consensus equilibrium (CE) framework [
110,
111,
112,
113] provides a theoretical understanding of PnP methods. It interprets the denoiser used in the PnP algorithm as a solution to an equilibrium equation rather than an exact minimization of a cost function. This framework helps to address questions related to the convergence of PnP methods, particularly when the denoiser does not correspond to any known regularizer.
Blind-PMRI-Net [
58] is a method that alternates between updating images and sensitivity maps to solve multi-channel MRI problems. It employs a half-quadratic splitting approach, resulting in a complex network design that requires careful balancing of updates to maintain stability. This method is particularly effective in multi-coil MRI scenarios where sensitivity maps are not known a priori, making it well-suited for handling complex imaging tasks. However, optimizing this approach can be challenging due to its intricate structure.
VS-Net [
59] utilizes variable splitting optimization to manage complex multi-coil data. While it performs well in parallel imaging tasks, its robustness is limited by its handling of sensitivity maps, making it less adaptable to certain coil configurations. VS-Net delivers good performance, but its sensitivity to inaccuracies in the sensitivity maps can impact its effectiveness in some scenarios.
4.9. Future Directions and Research Opportunities
Future research should aim to address the limitations of current models and explore new avenues for enhancement. Emerging AI techniques, such as reinforcement learning, offer promising directions for improving MRI reconstruction. To further enhance MRI reconstruction, future work may focus on leveraging reinforcement learning (RL). RL can optimize acquisition parameters dynamically during the scan. This could lead to more efficient data collection and potentially reduce scan times further, thereby making MRI procedures more responsive to specific patient needs and scanning conditions. In addition to RL, self-supervised learning also holds immense promise in improving the efficacy, quality, and accuracy of MRI reconstruction. Self-supervised learning can exploit the structure in MRI data, such as the physical constraints of the imaging process, to generate useful training signals without the need for a large quantity of ground truth data. This can serve as a catalyst for the development of novel models and reduce any dependency the researchers may have on expensive and time-consuming data labeling. Future work may see the development of more sophisticated self-supervised to leverage domain-specific knowledge and enhance model performance.
In addition to leveraging various techniques, personalized medicine approaches, where models are tailored to individual patient characteristics, could provide significant benefits. These approaches can leverage patient-specific data to enhance the accuracy and reliability of MRI reconstructions, leading to more precise diagnoses and personalized treatment plans. Additionally, the integration of self-supervised learning techniques, which can operate with limited ground truth data, represents a promising avenue. Self-supervised learning can leverage the inherent structure in MRI data to improve model training, reducing the dependency on extensive labeled datasets.
Moreover, exploring hybrid models that combine multiple algorithms may offer a more comprehensive solution to the challenges of MRI reconstruction. These hybrid models can integrate the strengths of different techniques, such as combining the robustness of classical optimization with the adaptability of deep learning. Collaborative efforts between researchers, clinicians, and industry partners will be essential for advancing the field and translating research innovations into clinical practice. Ensuring that these models are user-friendly and seamlessly integrated into existing clinical workflows will be critical for their successful implementation.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}