
Some Comments about the p-Generalized Negative Binomial (NBp) Model


Abstract
1. Introduction
2. Materials and Methods: Clarifying Greene’s Presentation
3. Results: Articulating NBp Variates
3.1. The NBp Moment-Generating Function and Asymptotic Normality
3.1.1. The NBp Moment-Generating Function (mgf)
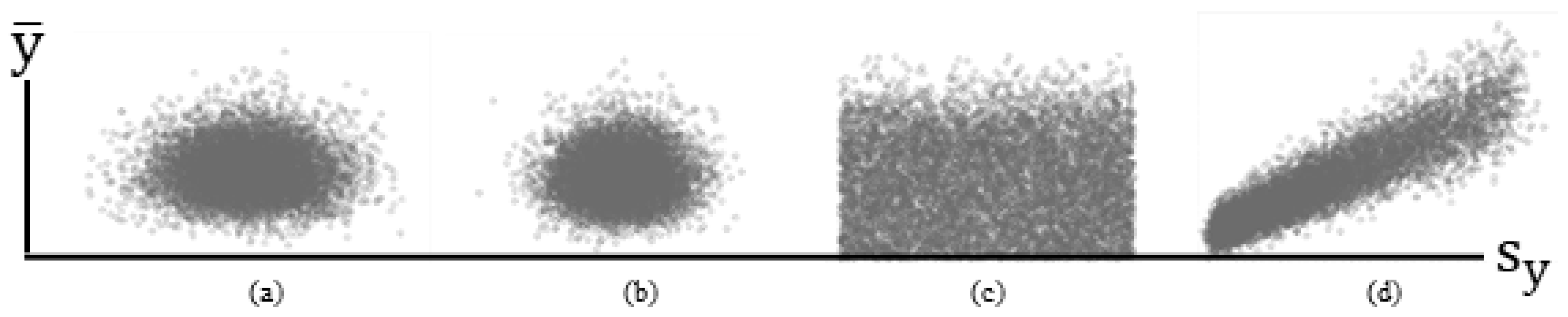
3.1.2. Asymptotic Normality and an NBp RV
- This new theorem indicates that if p = 1 (i.e., a Poisson RV), then ρ = 1, and for the standard NB2 case of p = 2, ρ ≈ 0.968. The parameter p needs to be 20 before this linear correlation is approximately 0.5. The dispersion parameter α does not affect this linear correlation. This new theorem indicates that for the aforementioned NBp, the sample mean and variance, and s2, are correlated (Figure 1d). In other words, the linear correlation between and s2 for a mixture of normal distributions is zero, whereas for a mixture of NBp distributions, it is asymptotically zero as p → ∞. Although this linear correlation remains zero when normal distributions are pooled, it can be as large as 1 for pooled NBp distributions.
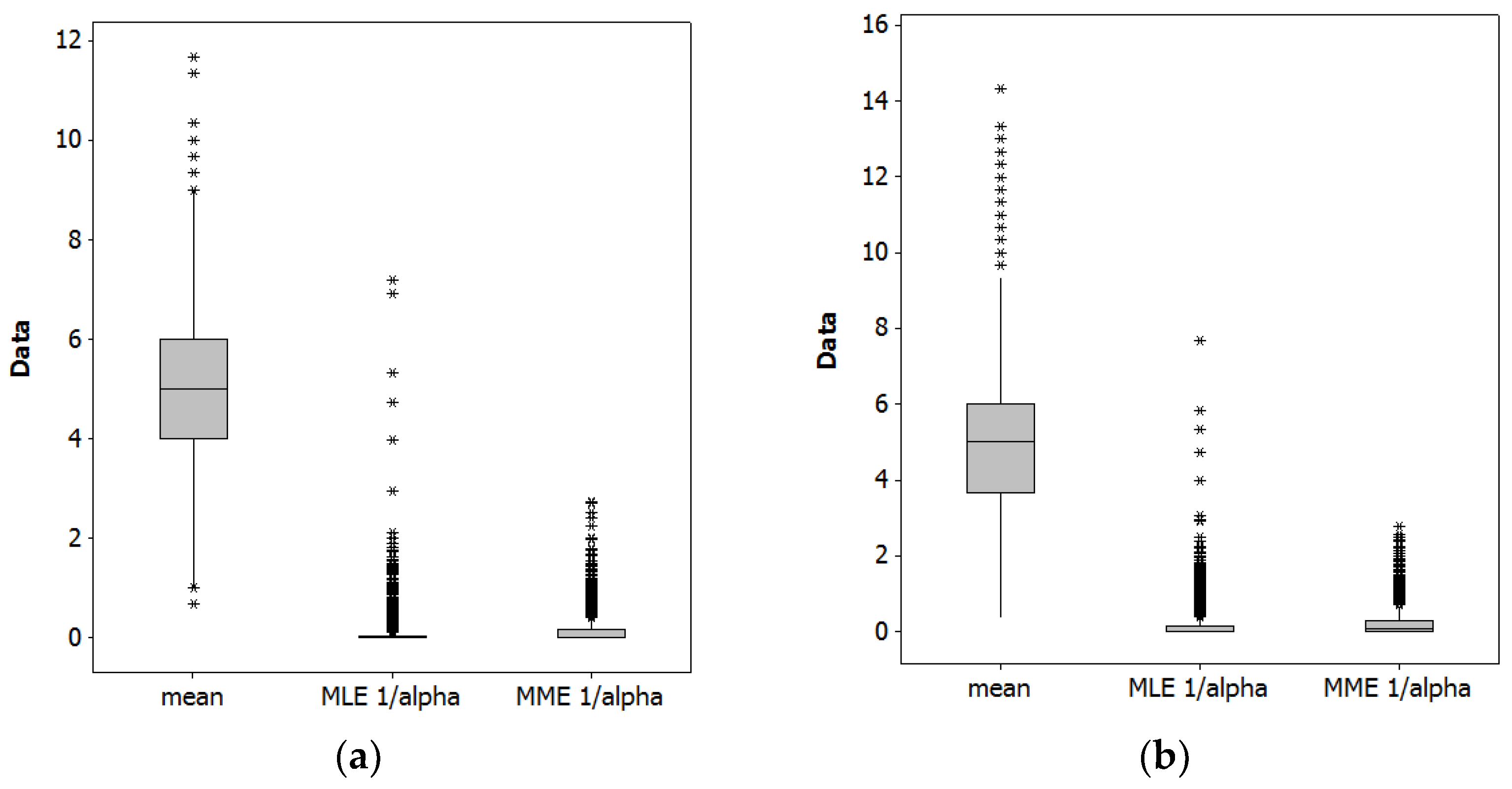
3.2. MLE and Method of Moments Estimation (MME) of the Dispersion Parameter α
3.2.1. Estimation of Parameter Exponent p
3.2.2. A Simple n = 3 Numerical Example
3.2.3. Moran Eigenvector Spatial Filtering: A Brief Overview
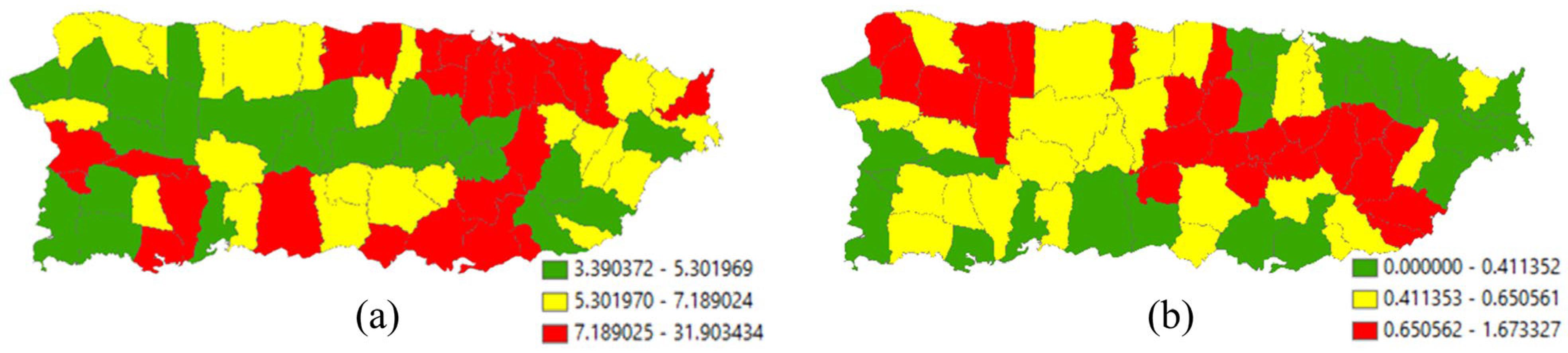
3.2.4. An Empirical 2010 Puerto Rico Population Density Toy Illustration
4. Discussion: Two MESF Empirical Examples
4.1. An Empirical 2010 Puerto Rico Urban Population Density Case Study
4.2. An Empirical 2010 Puerto Rico Rural Population Density Illustration
4.3. An Empirical 2010 Puerto Rico Rural Population Den
5. Concluding Comments and Implications
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Estimation of iid NBp Parameters
Appendix B. SAS PROC NLMIXED Code
- XB differentiates between a constant mean, a bivariate regression with the rural area percentage covariate, and an MESF regression that includes this preceding covariate. P = 3 allows the estimation of NB3; setting P to 2 estimates NB2, and setting it to 1 estimates NB1 (i.e., a Poisson). Finally, the temporary SAS file WORK.MU stores predicted counts for post-processing. The NB1 and NB2 options support comparative output checks with other software modules.
References
- Cameron, C.; Trivedi, P. Regression Analysis of Count Data; Cambridge University Press: New York, NY, USA, 1998. [Google Scholar]
- Barreto-Souza, W.; Ombao, H. The negative binomial process: A tractable model with composite likelihood-based inference. Scand. J. Stat. 2021, 49, 568–592. [Google Scholar] [CrossRef]
- Greene, W. Functional forms for the negative binomial model for count data. Econ. Lett. 2008, 99, 585–590. [Google Scholar] [CrossRef]
- Di, Y.; Schafer, D.W.; Cumbie, J.S.; Chang, J.H. The NBP Negative Binomial Model for Assessing Differential Gene Expression from RNA-Seq. Stat. Appl. Genet. Mol. Biol. 2011, 10, 1–28. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, Z.; Lord, D. Estimating dispersion parameter of negative binomial distribution for analysis of crash data: Bootstrapped maximum likelihood method. Transp. Res. Rec. J. Transp. Res. Board 2019, 2019, 15–21. [Google Scholar] [CrossRef]
- Pearson, K. Method of Moments and Method of Maximum Likelihood. Biometrika 1936, 28, 34–59. [Google Scholar] [CrossRef]
- Hendry, D.; Nielsen, B. Econometric Modeling: A Likelihood Approach; Princeton University Press: Princeton, NJ, USA, 2007. [Google Scholar]
- Chambers, R.L.; Steel, D.G.; Wang, S.; Welsh, A. Maximum Likelihood Estimation for Sample Surveys; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Rossi, R. Mathematical Statistics: An Introduction to Likelihood Based Inference; Wiley: New York, NY, USA, 2018. [Google Scholar]
- Ward, M.; Ahlquist, J. Maximum Likelihood for Social Science: Strategies for Analysis; Cambridge University Press: New York, NY, USA, 2018. [Google Scholar]
- Hoeffding, W. The Large-Sample Power of Tests Based on Permutations of Observations. Ann. Math. Stat. 1952, 23, 169–192. [Google Scholar] [CrossRef]
- Bagui, S.; Mehra, K. On the convergence of negative binomial distribution. Am. J. Math. Stat. 2019, 9, 44–50. [Google Scholar]
- Bowman, K.; Shenton, L. Estimator: Method of moments, Encyclopedia of Statistical Sciences, vol. 3 (D’Agostino Test of Normality to Eye Estimate), 2nd ed.; Kotz, S., Read, C., Balakrishnan, N., Vidakovic, B., Johnson, N., Eds.; Wiley: New York, NY, USA, 2006; pp. 2092–2098. [Google Scholar]
- van de Geer, S. A New Approach to Least-Squares Estimation, with Applications. Ann. Stat. 1987, 15, 587–602. [Google Scholar] [CrossRef]
- van de Geer, S. Least squares estimation. In Encyclopedia of Statistics in Behavioral Science; Everitt, B., Howell, D., Eds.; Wiley: Chichester, UK, 2005; Volume 2, pp. 1041–1045. Available online: https://people.math.ethz.ch/~geer/bsa199_o.pdf (accessed on 1 March 2024).
- Wolberg, J. Data Analysis Using the Method of Least Squares: Extracting the Most Information from Experiments; Springer: Berlin, Germany, 2005. [Google Scholar]
- Delicado, P.; Goria, M.N. A small sample comparison of maximum likelihood, moments and L-moments methods for the asymmetric exponential power distribution. Comput. Stat. Data Anal. 2008, 52, 1661–1673. [Google Scholar] [CrossRef]
- Griffith, D.A. A Family of Correlated Observations: From Independent to Strongly Interrelated Ones. Stats 2020, 3, 166–184. [Google Scholar] [CrossRef]
- Griffith, D. Spatial filtering. In Encyclopedia of Geographic Information Science; Kemp, K., Ed.; SAGE: Thousand Oaks, CA, USA, 2008; pp. 413–415. [Google Scholar]
- Griffith, D.; Getis, A. Spatial filtering. In Encyclopedia of GIS, 2nd ed.; Shekhar, S., Xiong, H., Zhou, X., Eds.; Springer: Cham, Switzerland, 2016; pp. 1–14. [Google Scholar] [CrossRef]
- Griffith, D.; Chun, Y. Spatial Autocorrelation and Spatial Filtering. In Handbook of Regional Science, 2nd ed.; Fischer, M., Nijkamp, P., Eds.; Springer-Verlag: Berlin, Germany, 2022; pp. 1863–1892, (revised, update to 2014 version). [Google Scholar]
- Moran, P. The interpretation of statistical maps. J. R. Stat. Soc. B 1948, 10, 243–251. [Google Scholar] [CrossRef]
- Geary, R.C. The Contiguity Ratio and Statistical Mapping. Incorp. Stat. 1954, 5, 115–127+129–146. [Google Scholar] [CrossRef]
- Tiefelsdorf, M.; Boots, B. The exact distribution of Moran’s I. Environ. Plan. A 1995, 27, 985–999. [Google Scholar] [CrossRef]
- Griffith, D.A. Spatial autocorrelation and eigenfunctions of the geographic weights matrix accompanying geo-referenced data. Can. Geogr. Can. 1996, 40, 351–367. [Google Scholar] [CrossRef]
- de Jong, P.; Sprenger, C.; van Veen, F. On extreme values of Moran’s I and Geary’s c. Geogr. Anal. 1984, 16, 17–24. [Google Scholar] [CrossRef]
- Borcard, D.; Legendre, P. All-scale spatial analysis of ecological data by means of principal coordinates of neighbour matrices. Ecol. Model. 2002, 153, 51–68. [Google Scholar] [CrossRef]
- Borcard, D.; Legendre, P.; Avois-Jacquet, C.; Tuomisto, H. Dissecting the spatial structure of ecological data at multiple scales. Ecology 2004, 85, 1826–1832. [Google Scholar] [CrossRef]
- Cameron, A.C.; Windmeijer, F.A.G. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econ. 1997, 77, 329–342. [Google Scholar] [CrossRef]
- Christensen, R. General Prediction Theory and the Role of R2, Unpublished Manuscript; Department of Mathematics and Statistics, University of New Mexico: Albuquerque, NM, USA, 2007; Available online: https://www.math.unm.edu/~fletcher/JPG/rsq.pdf (accessed on 1 March 2024).
- Hoetker, G. The use of logit and probit models in strategic management research: Critical issues. Strat. Manag. J. 2007, 28, 331–343. [Google Scholar] [CrossRef]
- Cakmakyapan, S.; Demirhan, H. A Monte Carlo-based pseudo-coefficient of determination for generalized linear models with binary outcome. J. Appl. Stat. 2016, 44, 2458–2482. [Google Scholar] [CrossRef]
- Kawamura, K. The structure of bivariate Poisson distribution. Kodai Math. J. 1973, 25, 246–256. [Google Scholar] [CrossRef]
- Mortici, C. Very accurate estimates of the polygamma functions. Asymptot. Anal. 2010, 68, 125–134. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Estimate | Standard Deviation | Range | % 0 s | % < 0 |
|---|---|---|---|---|---|
| using MLEs as the population parameters | |||||
| μ | 4.984 | 1.410 | 0.7–11.7 | ||
| 1/αMLE | 0.073 | 0.231 | 0.0–7.2 | 71.1 | |
| 1/αMME | 0.113 | 0.213 | 0.0–2.7 | 5.4 | 52.2 |
| using MMEs as the population parameters | |||||
| μ | 5.003 | 1.714 | 0.3–14.3 | ||
| 1/αMLE | 0.137 | 0.315 | 0.0–7.7 | 58.4 | |
| 1/αMME | 0.190 | 0.295 | 0.0–2.8 | 1.3 | 40.6 |
| Model Specification | NB2 Urban Population Density | Rural Population Density | ||||
|---|---|---|---|---|---|---|
| NB2 | NB3 | |||||
| Pseudo–R2 | Pseudo–R2 | Pseudo–R2 | ||||
| Intercept only | 0.6707 | 0 | 1.8760 | 0 | 1.8285 | 0 |
| Single covariate | 0.4848 | 0.18 | 1.3964 | 0.48 | 1.1847 | 0.48 |
| Covariate + ESF | 0.2021 | 0.79 | 1.0399 | 0.52 | 1.0065 | 0.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Griffith, D.A. Some Comments about the p-Generalized Negative Binomial (NBp) Model. AppliedMath 2024, 4, 731-742. https://doi.org/10.3390/appliedmath4020039
Griffith DA. Some Comments about the p-Generalized Negative Binomial (NBp) Model. AppliedMath. 2024; 4(2):731-742. https://doi.org/10.3390/appliedmath4020039
Chicago/Turabian StyleGriffith, Daniel A. 2024. "Some Comments about the p-Generalized Negative Binomial (NBp) Model" AppliedMath 4, no. 2: 731-742. https://doi.org/10.3390/appliedmath4020039
APA StyleGriffith, D. A. (2024). Some Comments about the p-Generalized Negative Binomial (NBp) Model. AppliedMath, 4(2), 731-742. https://doi.org/10.3390/appliedmath4020039