1. Introduction
Consider a function approximation problem in which we use to approximate a target function g. Assume are bijective functions with the range consisting of elements from , and to obtain different functions, we sample elements of ranges of from the Gaussian distribution. When we only use linear combinations to approximate g, the expectation of minimal residual sum of squares (RSS) is achieved at . However, if we introduce a non-linear function and use to approximate g, we can achieve an averaged RSS lower than . This paper quantitatively investigates the RSS that the non-linear approximator achieves, which is lower than its linear counterpart.
The function approximation problem revealed above can also be formulated in the terminology of neural networks. It is well-known that with only one hidden layer and choosing sigmoid as the activation function, we can use neural networks to approximate any continuous function [
1]. However, this universal approximation theorem requires that the non-linear activation function satisfies certain regularity conditions and does not tell us which kind of activation function performs best in a certain problem. On the contrary, this paper shows that the Hermite polynomial is the optimal candidate to achieve the minimal RSS in the problem mentioned above.
Moreover, note that most of the previous works along this direction focused on providing upper and lower bounds [
2] of the function approximation performance without closed-form characterizations. On the other hand, our formulation not only illustrates the role non-linearity plays in activation function, but more importantly, we provide the closed-form solutions for the non-linear activation function to achieve the minimal RSS. To the best of our knowledge, this is the first work that demonstrates how profitable that non-linear functions can be in a tight formulation.
In particular, our work is not restricted to any specific family of activation functions but only requires the activation function to be a perturbation of linear functions. This assumption allows us to study the non-linear gain when a non-linear term is added to the network. Such a gain can be expressed quantitatively up to the second-order approximation of
. To simplify the technical analysis, we use the one-node neural network which outputs one-dimensional feature [
3]. The network we consider can be regarded as a special ResNet model, which is widely used as a building block in deep neural network architectures. We use RSS to measure the network loss, from which we can obtain the universally optimal activation function for the given network, and it is found that the averaged loss is minimized when the activation function is the Hermite polynomial, which validates the previous empirical results [
4].
The rest of this paper is organized as follows. In
Section 3, we formulate the universally optimal activation function problem mathematically. Under specific assumptions, we derive the optimal solution in the form of the Hermite polynomial and establish the error rate in
Section 4. Furthermore, in
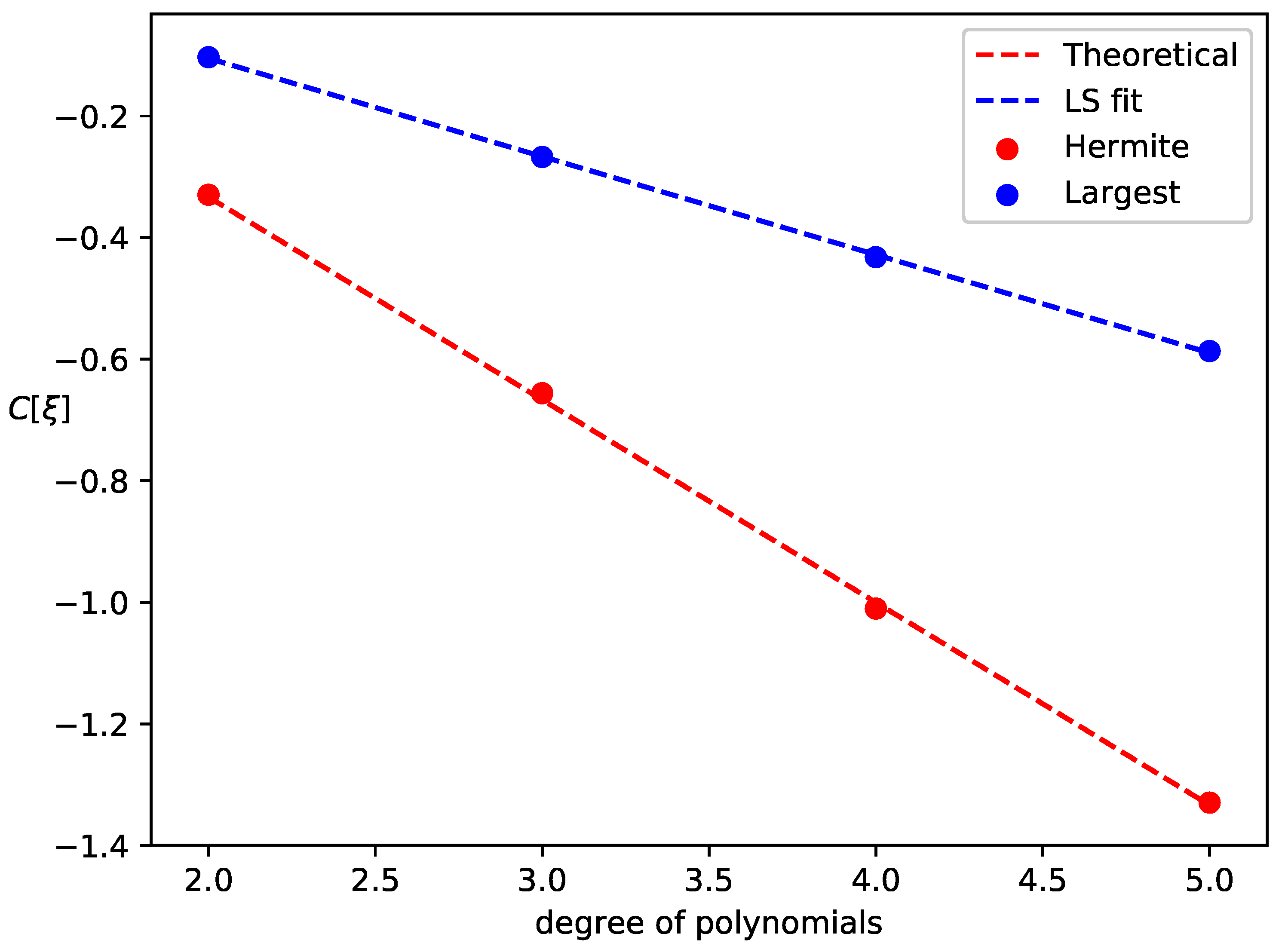
Section 5, numerical experiments are conducted to verify our theoretical results.
Section 6 concludes the paper. The detail of proofs of our results are provided in
Appendix A.
Throughout this paper, we use and to represent random variables, random vectors and random matrices. In addition, we use (or ) to represent a numerical value, numerical vector and numerical matrix. In addition, we use to denote the n-dimensional identity matrix, and is the transpose operation on matrices. Moreover, we use to denote the indicator function and which equals 1 if is even and 0 otherwise. Finally, is the double factorial which equals if n is odd and for even n. and are defined specifically.
3. Models and Methods
We consider one-node neural network, whose structure is shown in
Figure 1. Its input is a
k-dimensional random vector
and it outputs a random variable
Y. The one-node neural network is the output layer in a complex neural network for the regression task, where
is the extracted feature vector by previous layers. Although our study focuses on this specific network structure, we enlarge the choice of activation term
to find insights for the best choice of activation functions. Our goal is to predict
Y using
. For a given sampling result, we have
n data pairs
, and the
loss function is given by
where
is the
i-th column of the feature vector
and
is the label vector.
is applied to a vector in an elementwise way. The optimal weight for a given activation function
is the minimizer of
.
This type of network arises from function approximation problems, where a target function g, defined in a finite set, is estimated by . Suppose the ranges of are with cardinality n; then, the functions themselves can be completely determined by n-dimensional vectors. Furthermore, we assume each element from the ranges of is sampled from a distribution, since we are considering the average performance over different pairs. Then, we can establish a correspondence between and , and between g and .
In our model, we suppose
are drawn from a joint distribution
G. That is,
are samples of random matrix
and random vector
. We are interested to find a function
which minimizes the expectation
. Our requirement of the activation function
is of the special form
where
is a small constant. Such a form of
can be regarded as a special kind of ResNet [
9]. To draw a fair comparison between different non-linear terms
for given
, we apply the normalization constraint
to
, where
is the matrix-vector product with
.
We formulate the universally optimal activation function as follows:
Definition 1. Assume follow distribution G, and is a function space for . Then, we define the averaged residual error as The function which minimizes is called the universally optimal activation function for the one-node neural network, i.e., .
Definition 1 is a general formulation for any distribution space G. To obtain analytical insights, we should choose some specific distribution. Therefore, in the following analysis, we assume:
- (1)
follows Gaussian distribution .
- (2)
is a uniformly distributed random orthogonal matrix.
- (3)
and are independent.
For assumption (2), the definition of uniformly distributed random orthogonal matrix is
where elements of
are i.i.d.
random variables ([
10] Proposition 7.1). Since
,
is indeed an orthogonal matrix. The definition of
can be regarded as the post-processing result of PCA (Principal Component Analysis) on network input
and weight
, because we make the transformation
. We see that
. For assumption (3), notice that when we project a random vector
into a fixed linear subspace,
is independent from the fixed space. When we are evaluating the representability of non-linear activation, we also choose a scenerario in which the input and output are independent to demonstrate that the non-linearity, instead of the correlation, helps to decrease the residual error. Based on the distribution space
G by (1) –(3), for linear function space, we have the following conclusion:
Proposition 1. We have where is the identity function.
Proposition 1 says that the averaged residue error for linear function is equal to , which is consistent with our intuition, since we use k degrees of freedom to estimate an arbitrary vector in n-dimensional space.
We have analyzed the averaged error for linear function. To extend our result to non-linear functions, we need to choose a proper function space . In this paper, we consider a local region which contains a non-linear function perturbed from the linear space. The distance from non-linear function to linear space is quantified by a positive value . Thus, we consider . Then, all smooth functions can be treated as . The norm of function is chosen as the expectation with respect to the distribution space G. That is, where .
We are particularly interested in how the averaged error changes when is contracted to along a certain direction in . That is, given a function , we can construct where . Then, is equivalent to .
To measure the change rate of when , we introduce the concept of the asymptotic error rate as follows:
Definition 2. Let ; then, the asymptotic error rate for ξ is can represent the error change rate of perturbation from a linear function. If
is negative for a given
,
decreases in the rate of
along the perturbation direction
, which can be seen more clearly if we rewrite (
2) as
. In this form, we can also see that
is the coefficient of the second-order term of
.
To justify the definition of
, we need to show the limit in Equation (
2) exists, which is guaranteed by the following proposition:
Proposition 2. Let . Then, we have Our goal is to obtain the fastest decreasing path from to ; this is equivalent to solving an optimization problem constraint by . It is hard to optimize over directly, and we consider instead. consists of polynomials with the degree no greater than m, and we have .
For , we have the following result:
Proposition 3. If , and , then we have The constraint is equivalent with Proposition 3 gives a feasible approach to choose the optimal by solving a quadratic optimization problem. We make the assumption to write in a concise form. This assumption requires that we should choose low degree polynomials as an activation function, and the number of nodes k should be relatively large to represent features. Since the computational cost is proportional to the degree of polynomials and feature dimensions are usually high, our assumption does not lose practicality.


{kind=link}
{kind=link}

