1. Introduction
We denote with the set of linear bounded operators between the normed spaces V and G with the inner products and , respectively, and . Note that we often omit the space-subscripts in the inner products for brevity when there is no risk of confusion.
Compact linear operators
are the extension of matrices in Hilbert spaces, in which one is able to generalize the spectral theorems. A special compact linear operator which models our problem in Atmospheric Physics, the spheroidal particle ensemble, and many other applications, arises from the Fredholm operator of the first kind. The Fredholm integral equation has the following general form:
where
is the kernel function. In
Section 4, we show an example of such a function representing backscatter and extinction cross sections of aerosol particles. The Riemann–Lebesgue Lemma indicates the underlying reason for the ill-posedness of these integral equations. Consider the function sequence
. Then, for a Riemann-integrable function
, it holds
This result summarizes the smoothing phenomenon imposed by the Fredholm operator to any solution candidate.
The properties of the Singular Value Decomposition (SVD) of the operator are given by: Let and let be the adjoint of T. There exist sequences , , and with and such that the following statements hold:
- 1.
.
- 2.
The sequences and form a complete orthonormal system of the spaces and , respectively:
- 3.
and for all .
- 4.
, and for all .
The triple is called the singular system of the compact operator T. In particular, the sequences and are called the left and right singular functions, respectively, and the sequences are called the singular values of T.
Furthermore, the Picard condition states the following: Let
be a compact operator and
its singular system. An element
is an element of
exactly, when
This condition exposes the decisive role of the convergence rate of the singular values; there only exists a solution if the terms decay faster in competition to the singular values.
Regularization methods are very good candidates in order to gain some control over noisy and highly sensitive solutions and to solve inverse ill-posed problems efficiently. One family of methods, that can be used for regularization, is the one of Runge-Kutta integrators, commonly used for ordinary differential equations.
For linear operators, Rieder [
1] proved that Runge–Kutta integrators applied to the asymptotic regularization and stopped by the discrepancy principle are regularization schemes where the Hölder-type source set
is used. Recently, in Pornsawad et al. [
2], a modified discrepancy principle was investigated for the implicit Euler method of the Runge–Kutta family. In Böckmann et al. [
3] and Pornsawad et al. [
4,
5], the nonlinear operator case was investigated under Hölder-type and logarithmic source conditions. It was shown that convergence and optimal convergence rates can be achieved under certain assumptions. Similarly, in Zhao et al. [
6], a wide class of spectral regularization methods under variational source conditions was shown to yield convergence rates under certain general assumptions, which are also satisfied by asymptotic regularization and Runge–Kutta integrators.
This paper is structured in the following manner: first, in
Section 2, a brief review of regularization methods is given to build up a necessary background, also useful for the investigation of the spheroidal particle model later on. In
Section 3, we propose a new generalized filter of the Runge–Kutta type and prove regularizing properties of such a filter. Readers, only interested in the application in Atmospheric Physics, may skip
Section 2 and
Section 3. Furthermore,
Section 4 and
Section 5 are dedicated to the modeling of a spheroidal particle ensemble and our numerical experiments with different atmospheric scenarios, respectively. The latter is done by means of gradual complexity moving from spherical- to non-spherical particle ensembles and retrieving particle distributions of one and two dimensions, respectively. This serves us in order to introduce a new method and demonstrate its efficiency for the problem of aerosol microphysics in the 1D case (Mie model), which most of the literature is occupied with, and then extend to the quasi-2D case we mostly focus on.
Section 5 is also concerned with the reconstruction of shape-size distributions with modality up to 2.
Section 6 summarizes the upsides and limitations.
2. Preliminaries: Brief Review of Regularization Theory
A well-posed problem has a unique solution which depends on the input data in a stable manner. A problem that violates any of the three properties of well-posedness (existence, uniqueness or stability) is called an ill-posed problem. The degree of ill-posedness is given by: Let be a positive real number. Then, the problem (T, V, G)
- 1.
is mildly ill-posed if has a polynomial behaviour, i.e., .
- 2.
is severely ill-posed if has an exponential behaviour, i.e., .
The ambiguity in the solution space is apparently undesired. It is possible to search for a unique solution by replacing the problem with
which turns out to be equivalent to a least-squares problem.
For , the set of the solutions of the normal equation is non-empty, closed and convex. Moreover, there is a unique solution of minimal norm.
This property of the normal equation along with continuity of the norm allows the existence of a unique solution of minimal norm and strikes out uniqueness from Hadamard’s requirements [
7]. We shall define this as a solution of
in generalized terms.
The operator , with the domain , which assigns uniquely an element of minimal norm to any is called a Moore–Penrose inverse or generalized inverse of . The element is called the minimum-norm solution of .
We are now able to answer by what means and under which circumstances we can invert the equation .
Theorem 1. Let ; then, its generalized inverse has the following properties:
- 1.
is the unique solution of the normal equation in , for every .
- 2.
is linear.
- 3.
.
- 4.
is continuous if and only if is closed. Then, is defined in the whole G.
- 5.
If T is compact, then it is continuous if is finite.
The key to assure the well-posedness of our problem is
. In fact, this allows for characterization of ill-posedness through the closedness of the range
. The ill-posedness by Nashed is defined as follows: The problem
is called ill-posed if
is not closed [
8]. Otherwise, it is called well-posed.
2.1. Regularization with Spectral Filters
First, let us define regularization through a family of operators approximating the desired (generalized) inverse, see e.g., [
9,
10].
Definition 1 (Regularization Scheme).
The family of linear bounded operators from G into V is called a regularization scheme or a regularizer for T if we have the following pointwise convergence:Let there be given noisy data with,, withand letbe a regularization scheme, where. If, for alland allwithwe havethen the pairis called a regularization method for. Furthermore,is called a priori parameter choice rule (PCR) if it only depends on; otherwise, it is called a posteriori parameter choice rule. Note that a PCR depending solely on is called a data-driven one and is often based on heuristics.
In case we have a unique solution
, we can see that the troubling part, regarding stability, is the operator
. Moreover, recalling the singular system of
T,
, we have
and therefore our filters need to target the singular values. This motivates the filter function
for the regularization scheme
An immediate question is what the properties of such a function are in order to constitute a regularization method.
Theorem 2 (Regularizing filters). Let T be an injective compact operator with singular system . If the function satisfies the following conditions:
- 1.
is bounded for all and for all ,
- 2.
for all , there exists a positive constant such that all hold either of the following relations:
- 2.1.
- 2.2.
then is a regularization scheme defined as in (7), and . Moreover, we have and the reconstruction error estimatewhere in case of (i) or in case of (ii) with C denoting a bound on q. The function is then called a regularizing filter. A proof can be found, e.g., in [
10]. Examples of filter functions will now be introduced amid the exposé of the methods we are going to use later in our simulations.
2.1.1. Truncated SVD
Here, we only show a discrete analog of SVD of practical interest: For any matrix
, there exist orthogonal matrices
and
and a matrix
where
and
, so that
M is decomposed to
where
are the orthonormal columns of
U and
V, and they are called left and right singular vectors of
M, respectively. The
-s are called singular values of
M, and the triple
is called singular system of
M. Tiny singular values (close to zero) are the ones responsible for a disproportionate increase in error induced high frequencies; the steeper the decay rate, the higher the degree of ill-posedness. Intuitively, this suggests keeping only the most significant singular values and discard the rest. A threshold
will be the cut-off (regularization) parameter below which no singular value makes it to the sum. We summarize this discussion to the introduction of the reqularizing filter
b of what we call the Truncated SVD (TSVD):
2.1.2. Tikhonov Regularization
TSVD is a straightforward regularization tool which aims to identify and cut out the most vulnerable part of the solution. However, doing so it wastes all the solution information associated with the disposed part. Furthermore, in cases where there is a lot of noise, the “ripping” nature of TSVD may result in an oversmoothed solution. Therefore, instead of cutting some part, we can alternatively give it a shift by a parameter
to counteract its spectral weakness. This correcting procedure, enabling the search of an optimal balance (
) of the good against the troubling solution content, is attributed to A.N. Tikhonov [
11]. The concept of Tikhonov Regularization (TR) is described by the filter function
b:
We introduced Tikhonov’s method from the point of view of the singular values following a possible flaw of the behavior of SVD. There are, nevertheless, a few ways to define this method basically through a minimization procedure, see e.g., [
12].
2.1.3. Iterative Regularization Methods: Runge–Kutta Integrators
Let the following be an initial value problem:
Choosing a step size
,
. We seek an approximation
, given by the formula:
where
is the
i-th stage of the (generally implicit) Runge–Kutta method. Considering
,
,
as the matrix elements of
,
, and
, respectively, the formalism is lightened by the mnemonic device
called the Butcher’s tableau, developed in 1960 by J.C. Butcher [
13]. In our case, we have
. This iterative filter method was first introduced in [
1,
14,
15] and will be studied in more detail in the next Section.
2.2. Parameter Choice Rules
Regularization describes the way to reverse the noise effect and restore partly the “natural” regularity of the solution but does not prescribe the depth of its act inherently. The use of parameter choice rules is not an optional addition but necessary in order to make a regularization method successful, or in other words, to minimize regularization errors in some sense. Here, we present the most widely used PCRs in bibliography and those which we are using later in our application, highlighting their assets and drawbacks.
Among all the parameter choice rules, the discrepancy principle is the most facile both conceptually and computationally. It is based on the “reasonable” demand that the data should be approximated with a same-order accuracy as the actual (measurement) data error. The obvious dependence on distorted-data information (
) classifies this technique as an a posteriori PCR. This technique, Morozov’s discrepancy principle, is formalized as follows. Let
be the regularized solution of
produced by the regularization method
and let
be a constant. The regularization parameter
is determined such that
The constant c is often called the safety factor and allows a somewhat safer approach preventing possible oversmoothing.
Despite the unique ease of the discrepancy principle, insufficient knowledge on the error level often strikes it out as an option. This is the basic motivation behind the development of PCRs solely based on the available data. The idea behind the L-curve method lies within the plot of the regularity term against the residual error, first suggested by [
16]. The L-curve criterion is summarized as follows: Let
be the points constituting the L-curve. The regularization parameter is determined by maximizing its curvature function
[
17,
18]
For our purposes, we will use the L-curve criterion combined either with the Tikhonov method or with our iterative regularization. The L-curve method solves heuristically the bargain between the competing error terms (approximation and data error), but there are some obstacles to oversee. The resulting plots for a noisy right-hand side () are neither always “L-shaped” (missing the vertical or horizontal part, or having “local” corners, or being arbitrary shaped) nor a curve, in cases where the regularization parameter is discrete (e.g., the cut-off level of TSVD), in which case the inversion is assisted by interpolation. All the latter scenarios might result in an occasional failure of the method. We note that in this work, for the combination of an iterative regularization (Runge-Kutta) with the L-curve, where the number of iterations is the regularization parameter, we “fill in” the gaps of the discrete L-curve with cubic spline interpolation.
Finally, cross validation [
19] is a well-known learning algorithm from statistics, offering another purely-data-driven regularization method. All previous PCRs do not take into account how good a prediction would be with data that the procedure has not been “trained” to deal with. The first step of this approach includes splitting the data in sets of “training” and “test”. Then, the model equation “learns” by being inverted for the data in the training set and subsequently uses this knowledge
(“-” expresses the missing data) to reproduce the data from the test set with forward calculations (
). Finally, the mean error from the predictions is used to evaluate the prediction.
In this work, we will use the “leave-one-out” partition, which removes only a single point, trains with the rest and goes back to predict the missing one. This is repeated for every data point, and the regularization parameter is chosen so that the mean prediction error is minimized. In our application, we use TR with GCV. The regularization parameter is determined by minimizing the so-called
GCV function 2.3. Collocation Discretization
As every other equation in real-life applications, does the underlying integral equation of our problem needs to be discretized in order to have a practical use. Although discretizing a problem can be seen as a regularization method, see [
12], here we regard it as a separate step before the regularized inversion. Projecting the problem to a finite space which we can subsequently handle computationally is the first decisive step towards its solution. Such a space must reflect properties of the actual solution space, which we, at best, know little about. For this, it is useful to introduce a special type of base functions (B-spline functions) which will carry out this task throughout this work; see
Appendix A.
As we will see in our application, the measurement data are known in certain points, rather than continuously. Projection methods by collocation exploit this very feature most appropriately. Collocation methods can be defined the following way:
Let
, where
compact subset and let
be an injective bounded linear operator, with
V and
G Hilbert spaces and
, with
and a given
. Let the subspace sequences
, and
satisfy
and
. Choose
m points
such that
is unisolvent with respect to
, i.e., any function from
that vanishes in
vanishes identically. Then, the collocation method applied to the equation
gives an approximation of the solution (
v),
, satisfying
Consider
, where
are B-spline functions. Every solution approximation can be expressed with respect to the basis
,
where
are the expansion coefficients. Using the abbreviated notation
, and
, the model Equation (
1) casts to the linear system
Choosing a quadrature rule for the calculation of the integrals in Equation (
19) concludes the transformation of the model equation to a discrete (matrix–vector) problem. Obviously, the last step enables quadrature errors which will be considered negligible for our further analysis. After solving the system (
19) for the coefficients
(regularization), one has to go back to the expansion (
18) to finally obtain
.
3. New Generalized Runge–Kutta Regularizers
Since we have
, we will now appeal to the class of time invariant (autonomous) linear ODEs, in which case there are well-known results about stability. Consider the autonomous ODE system,
and combine it with Equations (
13) and (
14) to derive
where
, known as the stability function,
and
. Then, it can be verified by induction that
Setting
and
, i.e.,
, to Equation (
22), it can be shown, that, for an injective compact linear operator
T with singular system
and
where
is the minimum-norm solution (Moore–Penrose). In [
1],
S is linked to the aforementioned Butcher tableau and the Equation (
14), but here, following our previous analysis, it helps us define naturally a filter function, namely, (
,
). The requirements of Theorem 2 can be met as follows.
Theorem 3 (Generalized filter of Runge–Kutta-type). Let with . If there is a function fulfilling the following properties:
- 1.
for ,
- 2.
there is a constant such that , for all ,
then the function with defining the schemeis a regularizing filter. If , where p and q be real coprime polynomials with , the iterative scheme defined through is called generalized filter of Runge–Kutta-type, and ω is called the relaxation parameter. Proof. For all
and
, it holds
, hence
, so that
We have and . We examine the sign of S.
holds for
for all
and
is bounded with
. In this case, applying Bernoulli’s inequality,
for
and
, we obtain
Assume now there exists
such that
for all
. We have
therefore,
is bounded. If
, then
, which leads to the trivial
. If
, then
and
.
Therefore, for all and all , we have , with . The requirements 1 and 2 of Theorem 2 are satisfied; hence, is a regularizing filter. □
Stiff ODEs cannot be handled by explicit RK methods, which is the main reason for the rise of the implicit RK methods, for which is a rational function. This motivates the study of polynomial quotients of variable degrees, known as Padé approximants, to approximate the exponential function, which is what the stability function does by definition. In this sense, the rational function may disassociate from the Runge–Kutta method and instead follow the requirements of Theorem 3, which will ensure the regularizing effect of the filter.
Definition 2 (Padé approximants).
Consider the power series and the polynomials and with and . The rational function is called the Padé approximant of of order if The normalization
is a usual additional constraint to overcome the undetermined system of equations for the coefficients of
p and
q yielding from (
26). It was shown [
20,
21] that a Padé approximant of the exponential function can define a generalized filter of the Runge–Kutta type. This generalized Runge–Kutta iteration is of optimal convergence rate under the Hölder source condition and the discrepancy principle with infinite qualification. With respect to the degrees of the polynomials and the relaxation parameter
, we obtain the following connection.
Theorem 4 (Padé iterations [
20]).
Let . The iteration scheme defined by the stability function as a Padé approximant of is a generalized Runge–Kutta regularization. It is called the -Padé iteration
. Moreover, if ω is the relaxation parameter, then we have the following convergence behavior:- 1.
If , the -Padé iteration converges for all .
- 2.
If , there exists a constant such that the -Padé iteration converges for all and diverges otherwise.
- 3.
If , there exists a unique optimal relaxation parameter.
- 4.
If , there exists no optimal relaxation parameter, i.e., in increasing the relaxation parameter ω, one can “over-accelerate” the iteration.
Therefore, it is favorable to choose an iteration from case 4 which motivates the use of (2,1)–Padé iteration in
Section 4.
4. Modeling a Spheroidal Particle Ensemble
Having presented briefly the mathematical apparatus behind regularization, PCRs, and a family of iterative regularizers we turn now to our application from Atmospheric Physics. The naive inversion (without regularization) of a non-spherical aerosol ensemble could make an arbitrarily small noise in the data have an arbitrarily large noise effect in the solution (size distribution v).
Our incomplete knowledge of the spatiotemporal distribution of aerosol is a significant source of uncertainty for the radiative balance in climate models [
22]. Lidar (optical radar) is a mature technology used to measure vertically distributed aerosol properties [
23]. Lidar data have been successfully used to derive microphysical properties of aerosols more than 20 years now, first by [
24,
25]. However, mostly Mie theory is employed, which is only valid for spherical particles, which itself remains under active research, see e.g., [
26,
27]. On the other hand, only few novel approaches have been proposed using a spheroidal particle approximation, e.g., by [
28,
29,
30,
31,
32].
In this vein, consider now the following generalization of Equation (
1) to model the spheroidal particle ensemble
For our problem, the kernel functions K represent backscatter or extinction cross sections, i.e., the probability of either event to take place as a result of interaction between photons (e.g., a laser beam of a lidar system) and scattering particles, whose size and shape shall be analyzed. Bringing together the contributions from
n single scattering objects (multi-scattering effects are ignored) of a certain type (e.g., size
r or shape
) gives us the so-called backscatter or extinction coefficients at different wavelengths
, which are direct lidar measurement products (
). The unknown function
v acquires an additional dimension (
), but the right-hand side (input data) remains a function of a single variable, which is why we shall call Equation (
27) the quasi-two-dimensional case (quasi-2D case). Assume now an expansion of the form (
A5) with basis functions
and
and set
for brevity. Applying formally the collocation steps to Equation (
27) for each available data point
, we have the scheme
The parenthesized term is now an element of a two-dimensional matrix (3rd order tensor) with
i rows,
j columns and
k layers, which makes the equation ambiguous. How to deal with such a scheme most efficiently is a subject of active research on multilinear analysis, with its solvability being under question as well. In order to overcome this difficulty, we follow a concept from image processing (see [
33]) where the indices
are “compressed” to one index
h with the bijective index reordering
Now, the collocation process forms a matrix again with dimensions
and
is assumed to have a (compatible to the matrix dimension) B-spline expansion
, hence the problem is reduced to the one-dimensional case (
19). In contrast to the one-dimensional case, after inverting the discrete equation, the resulting approximation
has to be “decompressed” again to obtain a (quasi-)2D solution
The model relating the optical particle parameters
with the particle volume size distribution (PVSD)
is described by the action of a 2D Fredholm integral operator of the 1st kind
where
A is the particle surface area,
m is the complex refractive index (RI),
is the wavelength,
r is the volume equivalent radius,
, and
are sensible radius and aspect ratio ranges. Here, we used the fact that, in a convex particle ensemble, the average area per particle is equal to
, see [
34].
denotes either the optical extinction
and/or optical backscatter
(cross (⊥) and parallel (‖) coefficients, and
Q stands for either the extinction or the backscatter (dimensionless) efficiencies, respectively. Moreover, the concept of random orientation of non-spherical particles (here spheroids) is the basis for the calculations of these efficiencies. Identifying
as our noisy data and
as the unknown PVSD, the problem reduces to the inversion of Equation (
31). Formula (
31) was also derived by [
30,
35]. The real-life application forces us to solve the problem with limited data. In practice, this means there are at most 3
, 3
and 2
available to us, which will be thereafter our default setup.
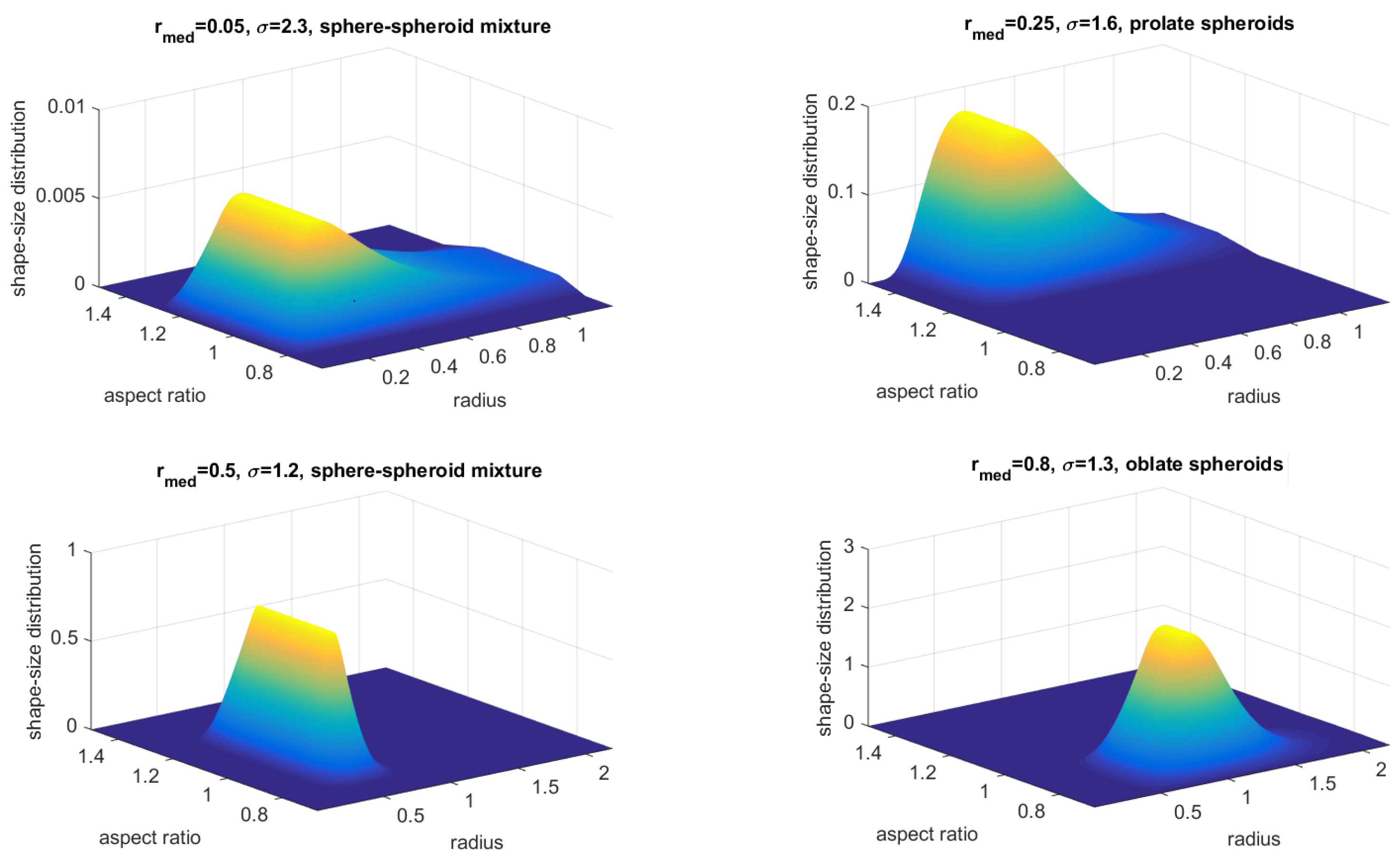
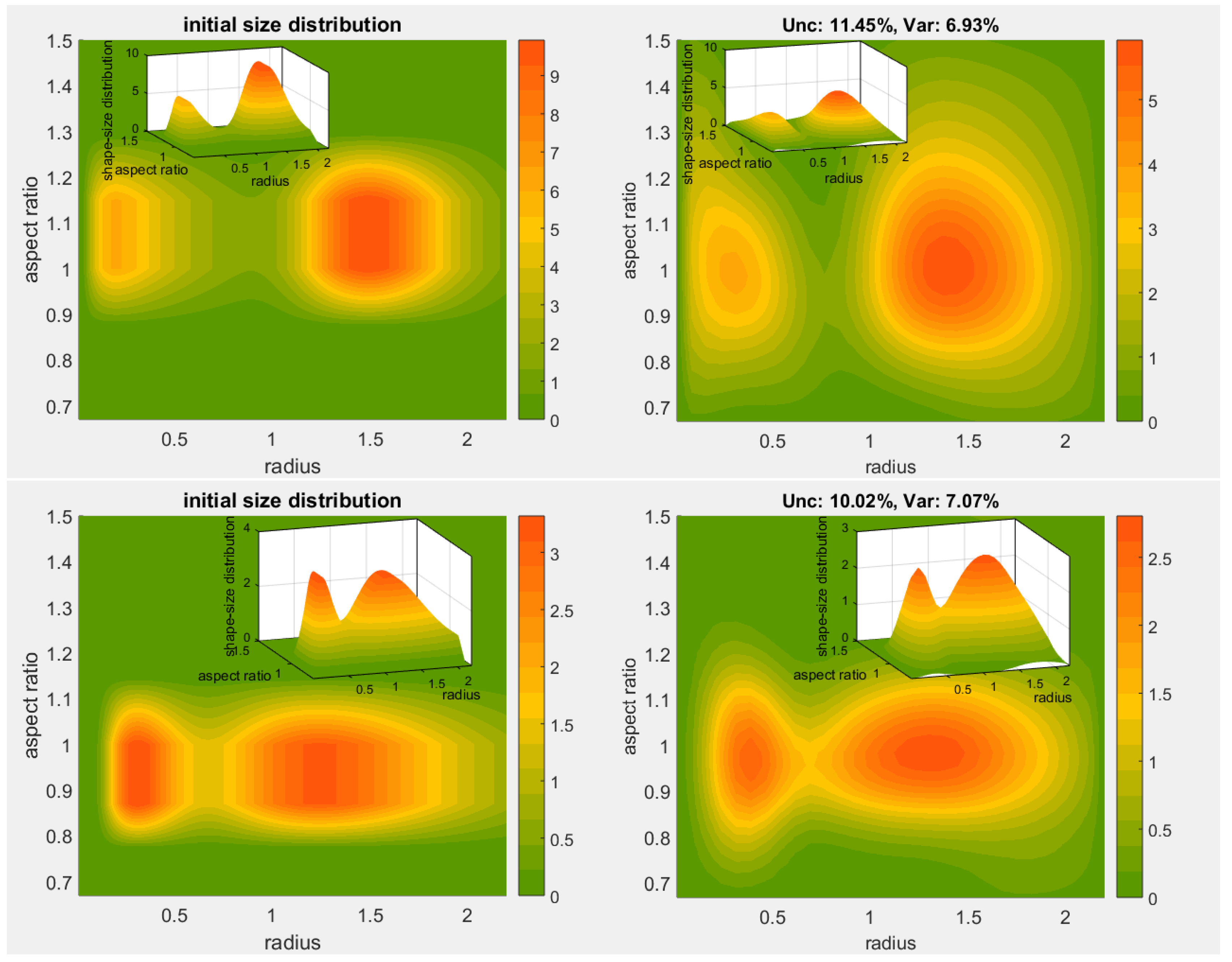
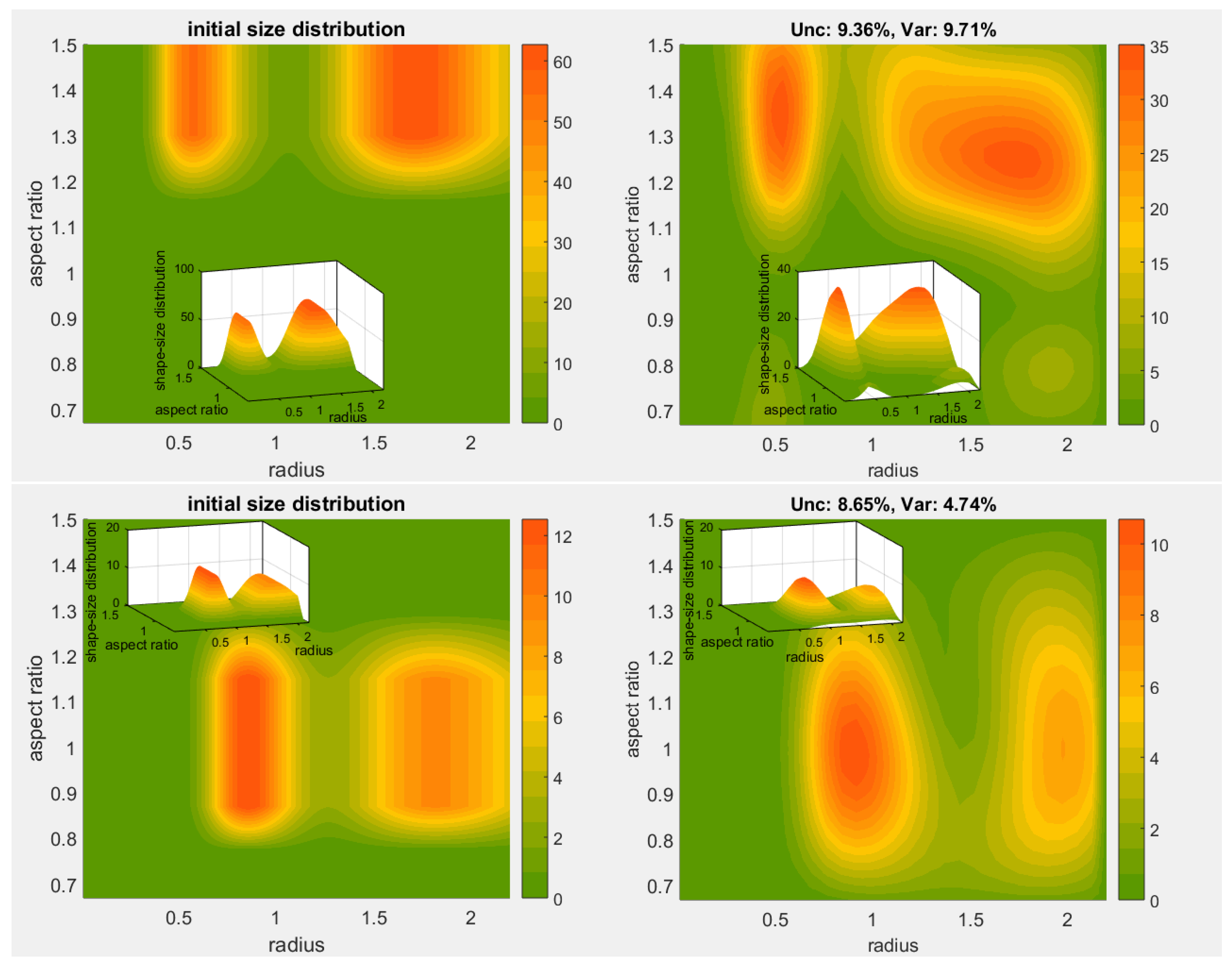
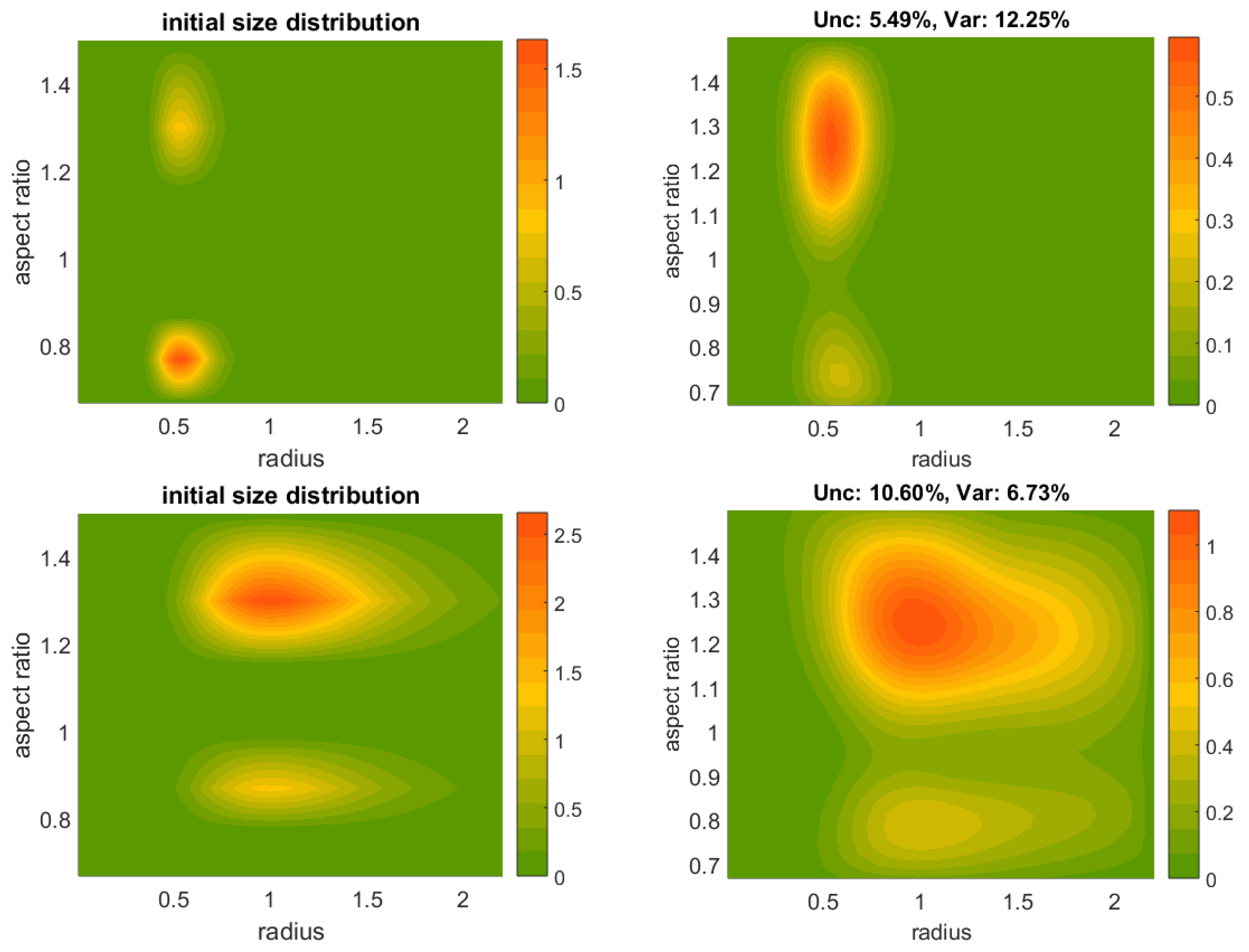
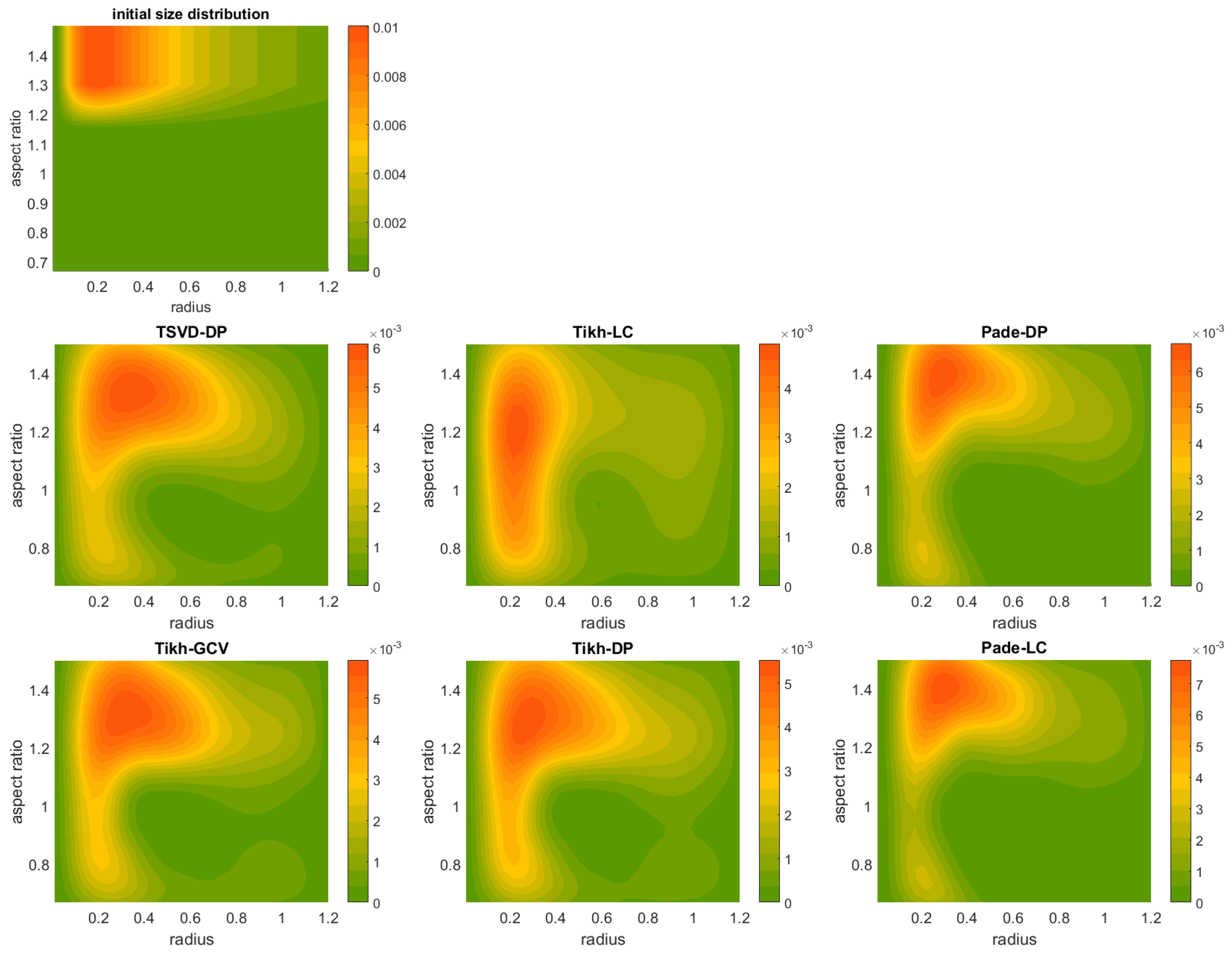
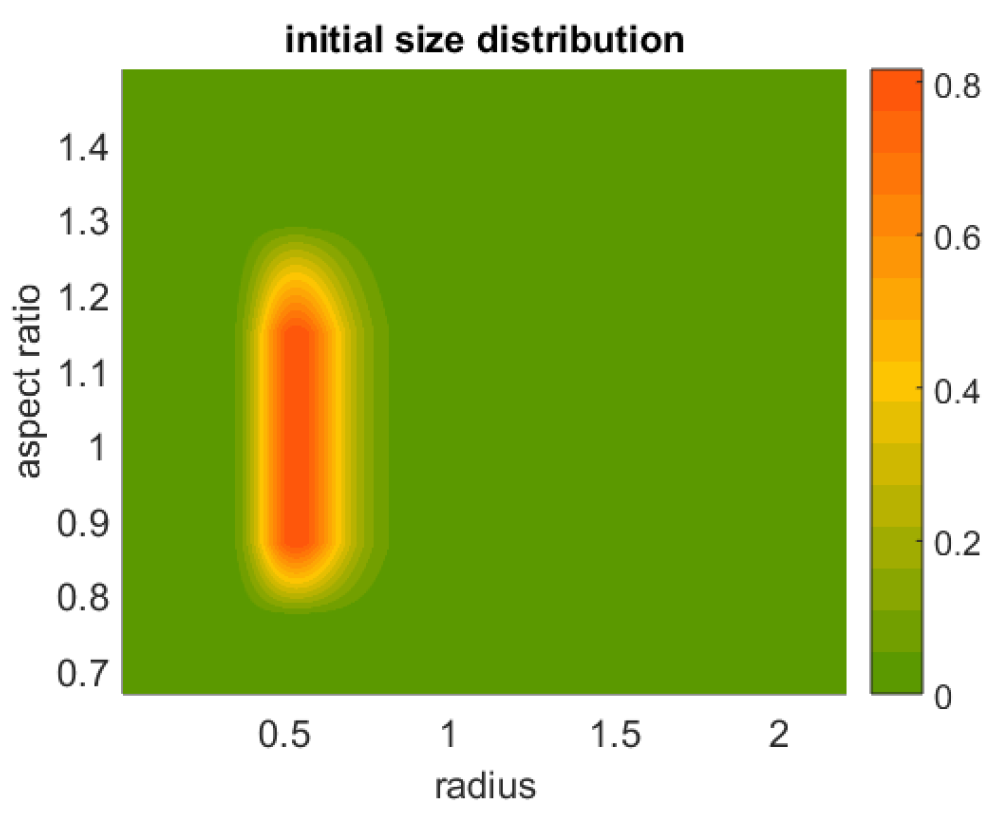
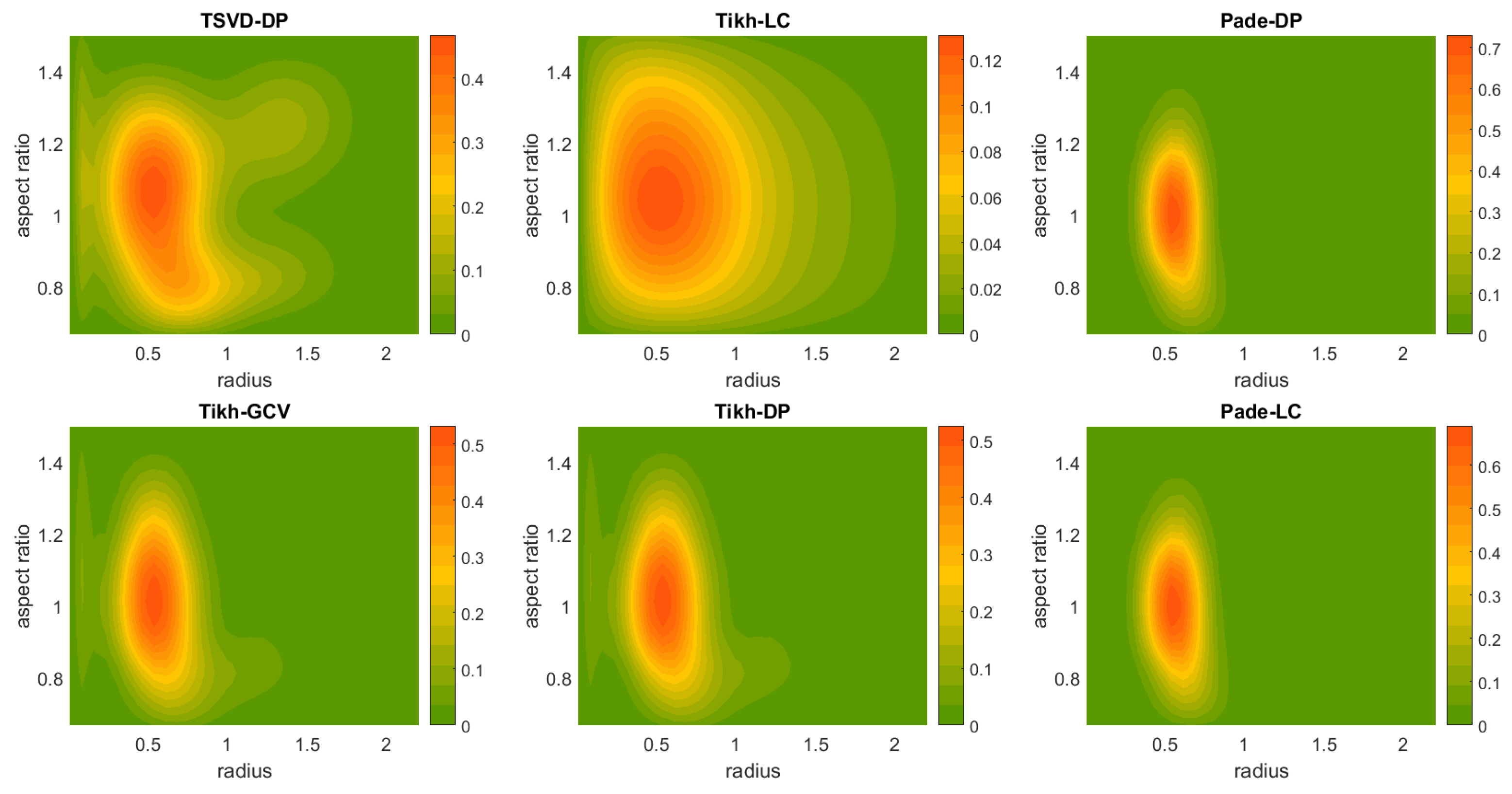
The primary objective of our inversion here is the shape-size distribution
. The first stage in trying to solve Equation (
31) is, of course, a discretization, which is done here with projection by quasi-2D collocation as proposed before. There are two other important practical implications here: (i) the determination of the refractive index (
m) and (ii) the calculations of the kernel functions (efficiencies). The refractive index is actually an unknown too, and solving for it introduces a highly nonlinear quest. However, in this work, we only investigate several instances of an a priori known refractive index.
The most time-consuming part of solving the model equation is the discretization due to the unprecedented computational expense of the kernel-function calculations. For this reason a precalculated database was created by [
36] using the software tool Mieschka. Additionally, it provides an extensive database of scattering quantities for spheroidal geometries, currently also available through an interactive platform of the German Aerospace Center (DLR). Mieschka’s look-up tables include scattering efficiencies for a
(
) refractive index grid (a total of 42 RI values), seven different aspect ratios and a size parameter range
m with a resolution of 0.2. Specifically, the refractive indices and aspect ratios used from the database of Mieschka software [
36], are the following:
The resolution gap in the aspect ratio needed for the integrations is handled with interpolation to the nearest neighbor; other interpolation techniques, e.g., cubic interpolation, show only tenuous differences in the discretization outputs.
Although the calculation of the efficiencies for a specific refractive index, size parameter and aspect ratio is already handled by the look-up tables of Mieschka software, we are still left with the interpolation of these functions and the double integration of the discretization procedure, see Equation (
28). For this reason, another database was created, this time including the discretization matrices with number of spline points from 3 up to 20 combined with spline degree from 2 up to 6. The spline points for the aspect ratio are fixed to 7, the actual number of different aspect ratio values (Equation (
32)). This large collection far exceeds the needs of the present work, covering lots of different discretization dimensions. The integrations involved a two-dimensional Gaussian quadrature integration scheme with a relative tolerance
.
The latter approach is particularly useful for another important reason too. Prior to the regularization, the problem has to be projected in a space of finite dimension, to be able to be solved in the first place. Finding a suitable dimension is the key as shown in [
37], and it is often problematic to pick one dimension as a global setting to handle datasets which correspond to very different atmospheric scenarios. Therefore, the mathematical constraint we will use in this work are the spline features (number of spline points and spline degree) which are associated with the dimension of the produced linear system. Previous work done with real-life data in [
25,
37,
38,
39] in parallel with several early simulations for this work, showed the benefit of such
hybrid algorithms, the concept of which is the leading approach of the present work as well.
After discretizing the model Equation (
31), we solve the resulting linear system with regularization, which is the first big step to counteract the ill-posedness of this inverse problem. Having usually no further information about the data error makes it difficult to choose an optimal regularization parameter which will guarantee physical adequacy.
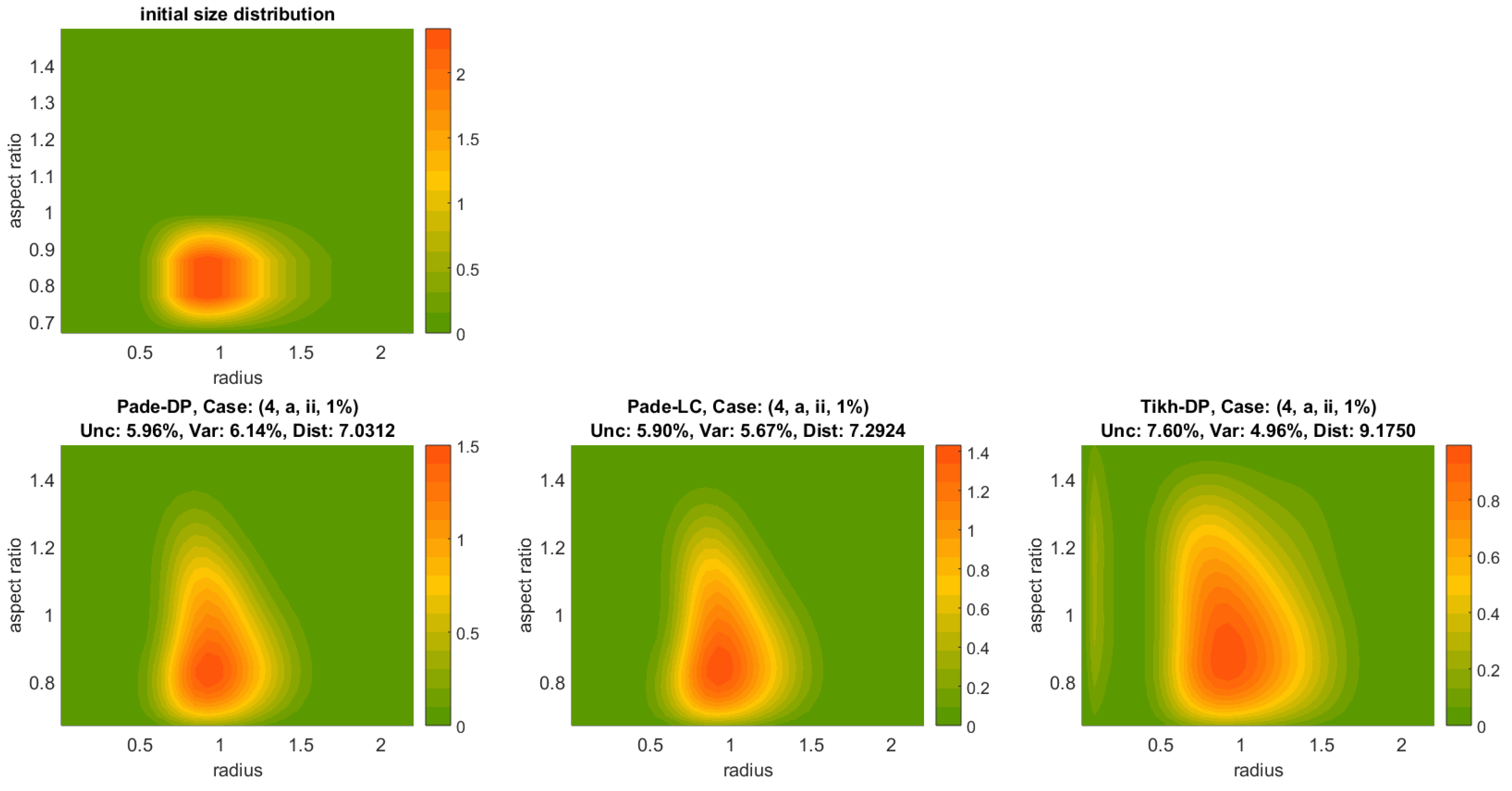
We often encounter a situation where the actual solution coefficients are zero (or nearly zero), but might, nevertheless, turn to negative values due the noise presence (e.g., measurement errors). This is apparently an undesired eventuality from a physical point of view, which we prevent by setting all strictly negative coefficients to zero. This decision is a result of early numerical experiments for this work leading to a superior algorithm performance. Especially for Padé iteration, we apply the non-negativity constraint to the solution in each iteration.
The reader is reminded that the primary unknowns of the resulting linear systems are the spline coefficients of the shape-size distribution (and not the function itself) with respect to the specified projection space.
Algorithm using a fixed refractive index:
Specify the range of the number of spline points and the range of spline degrees.
Discretize for every number of spline points, every spline degree and the fixed refractive index. (Use of database of precalculated discretization matrices (T))
Choose a regularization method and a parameter choice rule to solve the linear systems for a given (error-) dataset (g) applying the non-negativity constraint.
For all sets of solution coefficients v, make the forward calculation and estimate the residual error .
Calculate the solutions (shape-size distributions) with respect to the corresponding projection spaces.
Calculate the mean solution out of a few least-residual solutions.
The regularization methods and the parameter choice rules are chosen among the following ones:
Truncated singular value decomposition with the discrepancy principle (TSVD-DP);
Tikhonov regularization with the L-curve method (Tikh-LC);
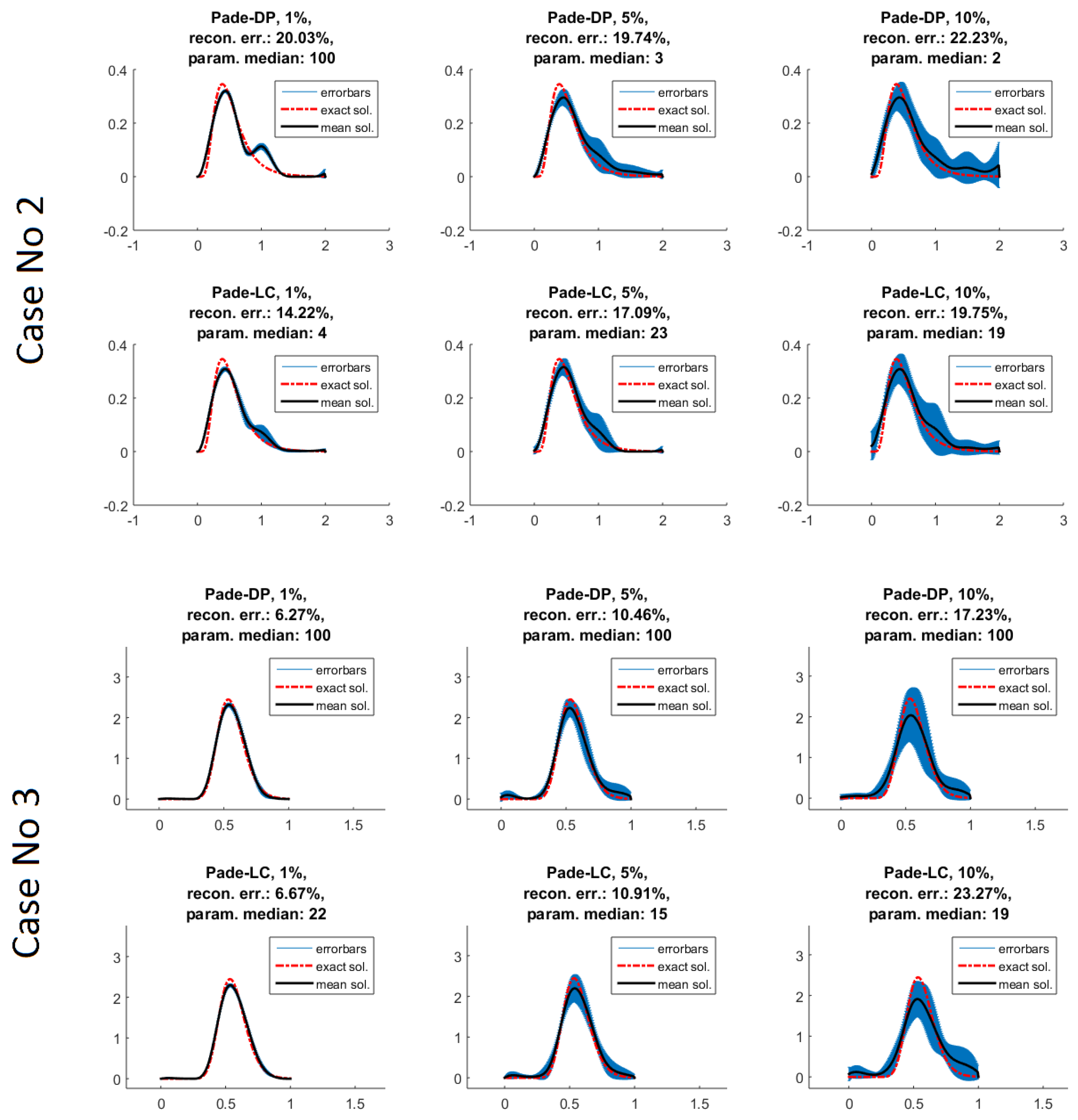
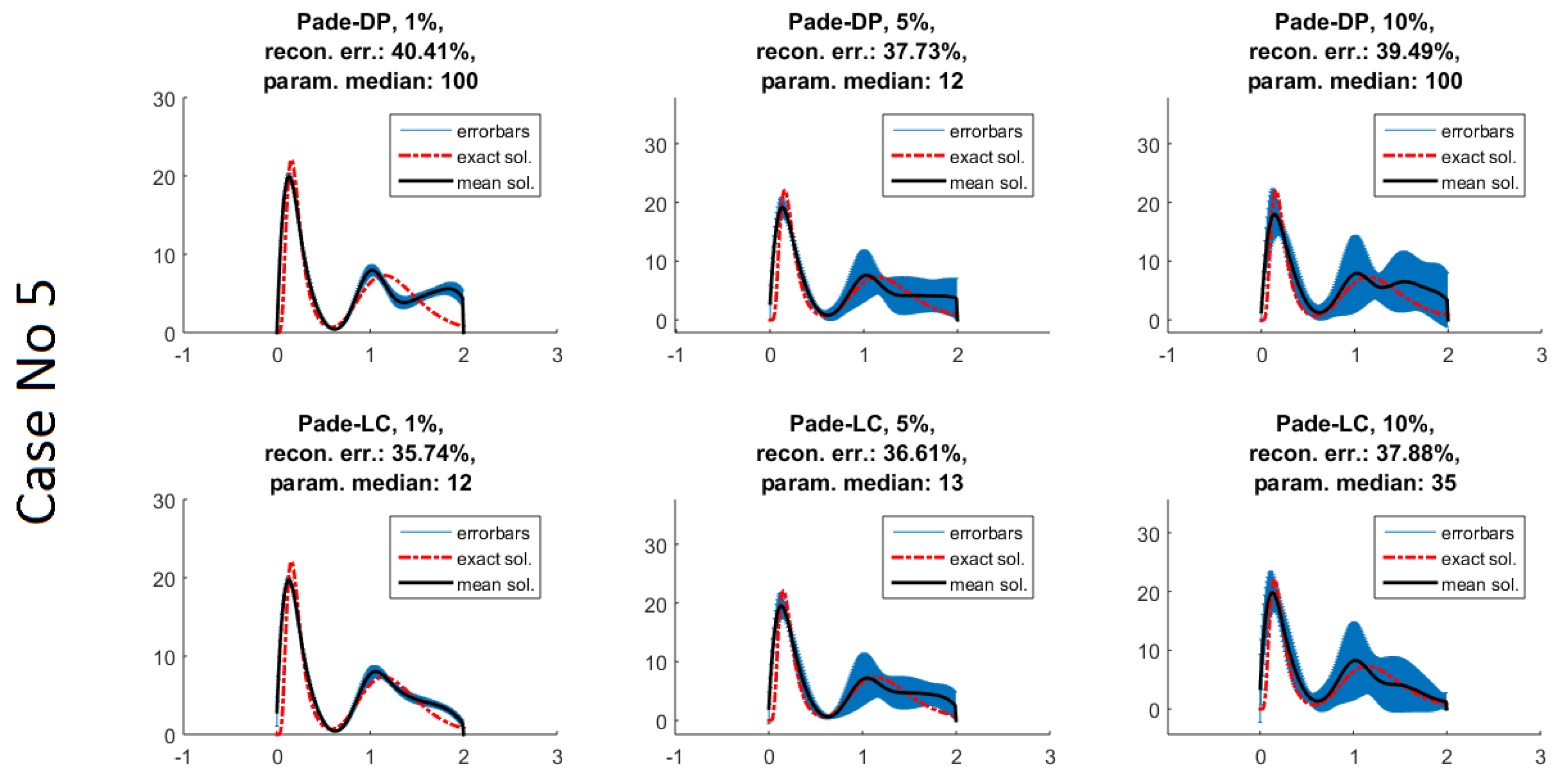
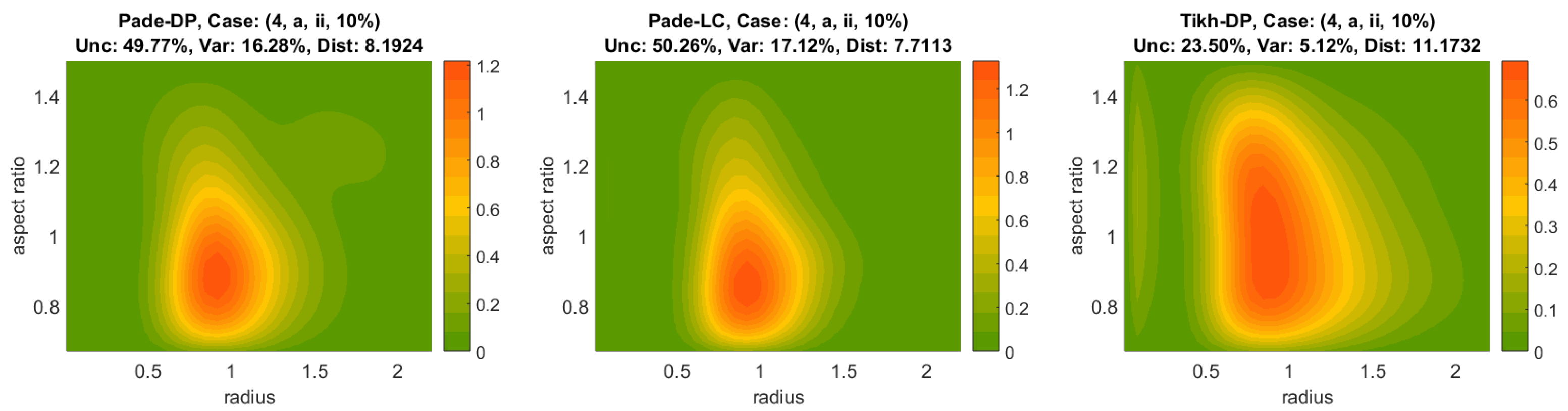
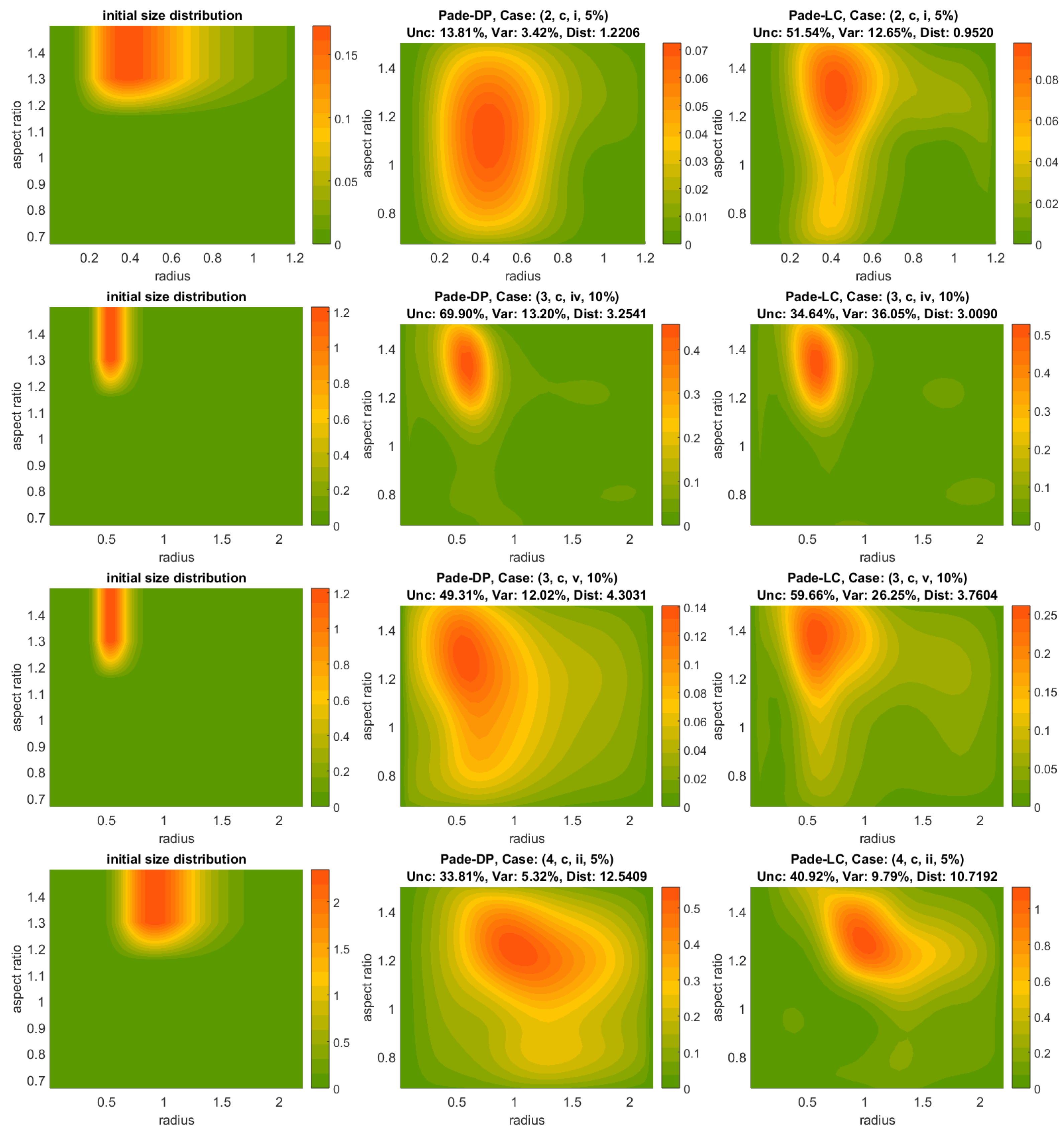
Padé iteration with the discrepancy principle (Padé-DP);
Tikhonov regularization with the generalized cross validation method (Tikh-GCV);
Tikhonov regularization with the discrepancy principle (Tikh-DP); and
Padé iteration with the L-curve (Padé-LC).
The methods in 1, 2, 4 and 5 are well studied regularization methods and parameter choice rules which have been widely used for the spherical particle model, e.g., [
24,
25], and it is interesting to see their efficiency for the new spheroidal model as well. Similarly, we investigate the lesser known Padé iteration as a regularization method, first used in the lidar-data inversion by [
40], here combined with the discrepancy principle (3), and for the first time with the L-curve method (6). The parameter choice rules are also common in bibliography, and, while they operate very differently, the primary reason for their use here is the presence (DP) or lack of a priori error knowledge (LC, GCV); see the brief review in
Section 2.
TSVD-DP (1) is implemented using the theory directly from
Section 2.1.1. We start by including all the terms in the SVD-description of the solution and remove them one by one till the discrepancy principle is fulfilled or we arrive at a single term. Apparently, the assumed discrepancy (perhaps multiplied by a safety factor) cannot be smaller than the residual error with all the SVD-terms included. In other words, we cannot demand a better approximation than the best we have.
The Padé approximants (see Equation (
26)) for Padé iteration (3, 6) were calculated using a routine implemented by [
15], which was integrated in the code. Padé-DP is implemented simply by fixing a maximum number of iterations (MNI) and checking if the assumed discrepancy is interposed between the corresponding residual terms of two successive iterations. The iteration is stopped either by the satisfaction of the DP or by reaching the MNI. For Padé-LC (6), we use a discrete implementation of L-curve with respect to the number of iterations the following way:
Fix a maximum number of iterations (MNI) m and run Padé iteration for each number . (m independent times in total);
Store the residual error and the regularity term for each number of iterations;
Build the L-curve with cubic spline interpolation from the points ;
Locate the point of maximum curvature of the L-curve ;
Take as the solution the output of Padé iteration with iterations.
For Tikh-LC (2), Tikh-GCV (4) and Tikh-DP (5), we used modified versions of routines used in the software package
Regularization Tools by P.C. Hansen [
41].



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}