
Interdisciplinary Analysis of Science Communication on Social Media during the COVID-19 Crisis



Abstract
:1. Introduction
2. State of the Art
2.1. Information Needs during the COVID-19 Crisis
2.2. Science Communication and Knowledge Dissemination
2.3. Analysis of Social Media Communication
3. Method
3.1. Qualitative Analysis of Video Formats
3.2. Science Communication Channels
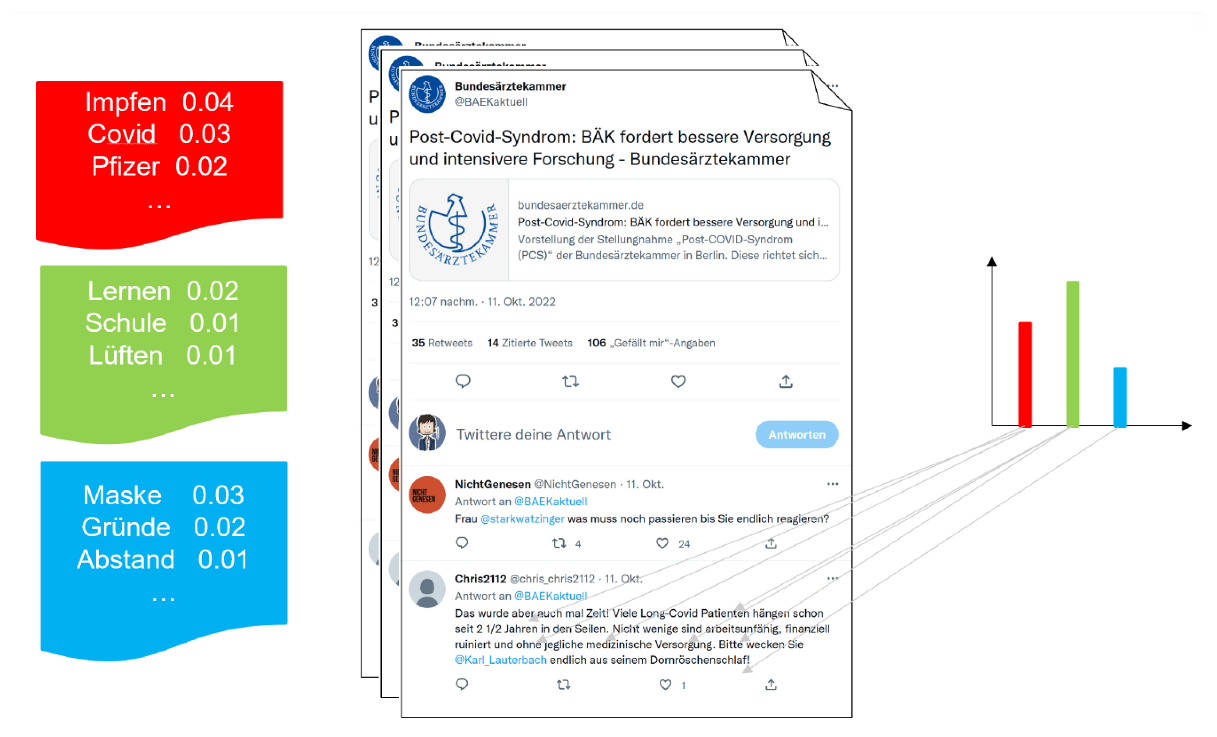
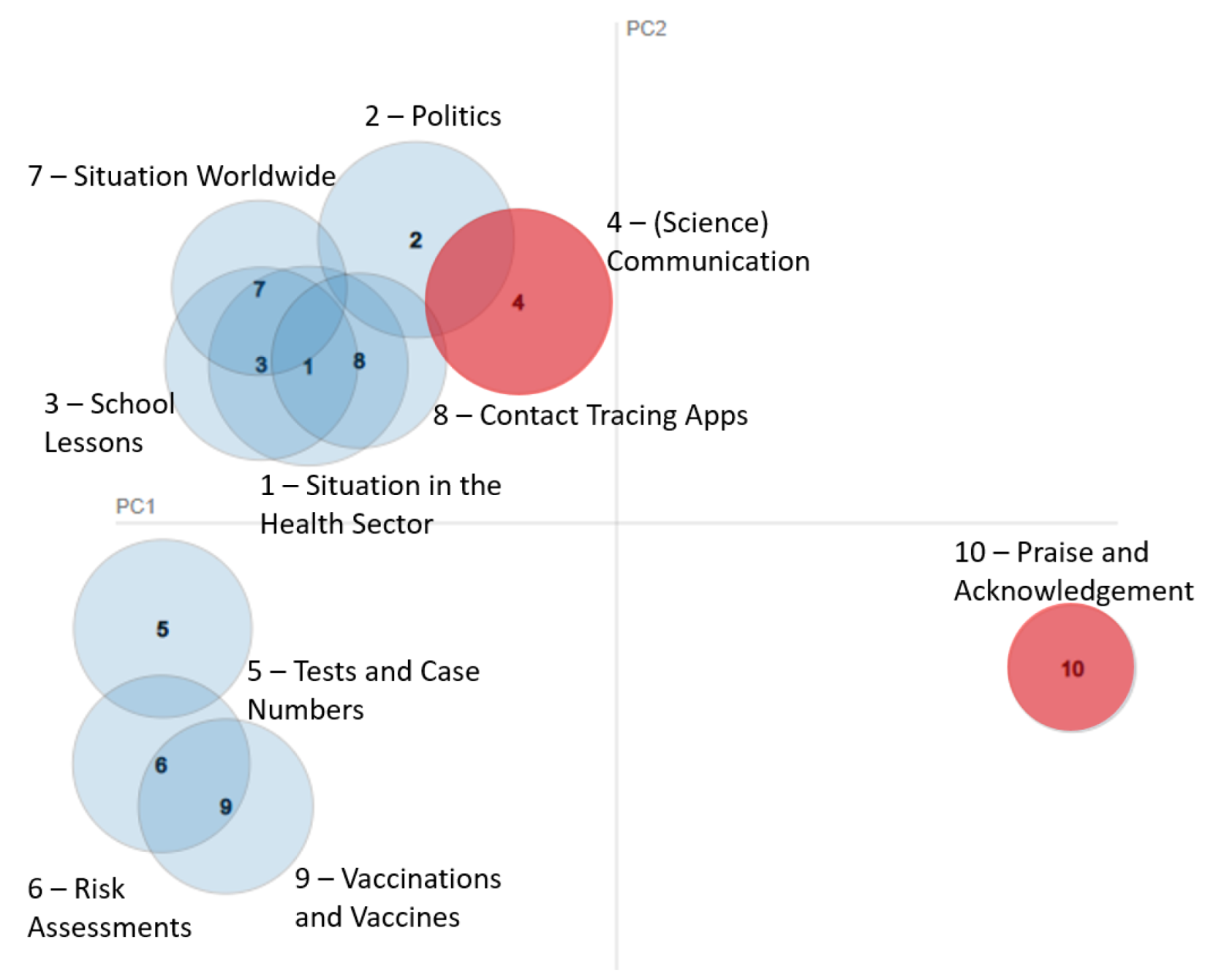
3.3. Topic Modeling and Interpretation
3.4. Tweet Labeling and Analysis
3.5. Sentiment Analysis
4. Results
4.1. Qualitative Analysis of Videos
4.2. Topics within Comments on Science Communication
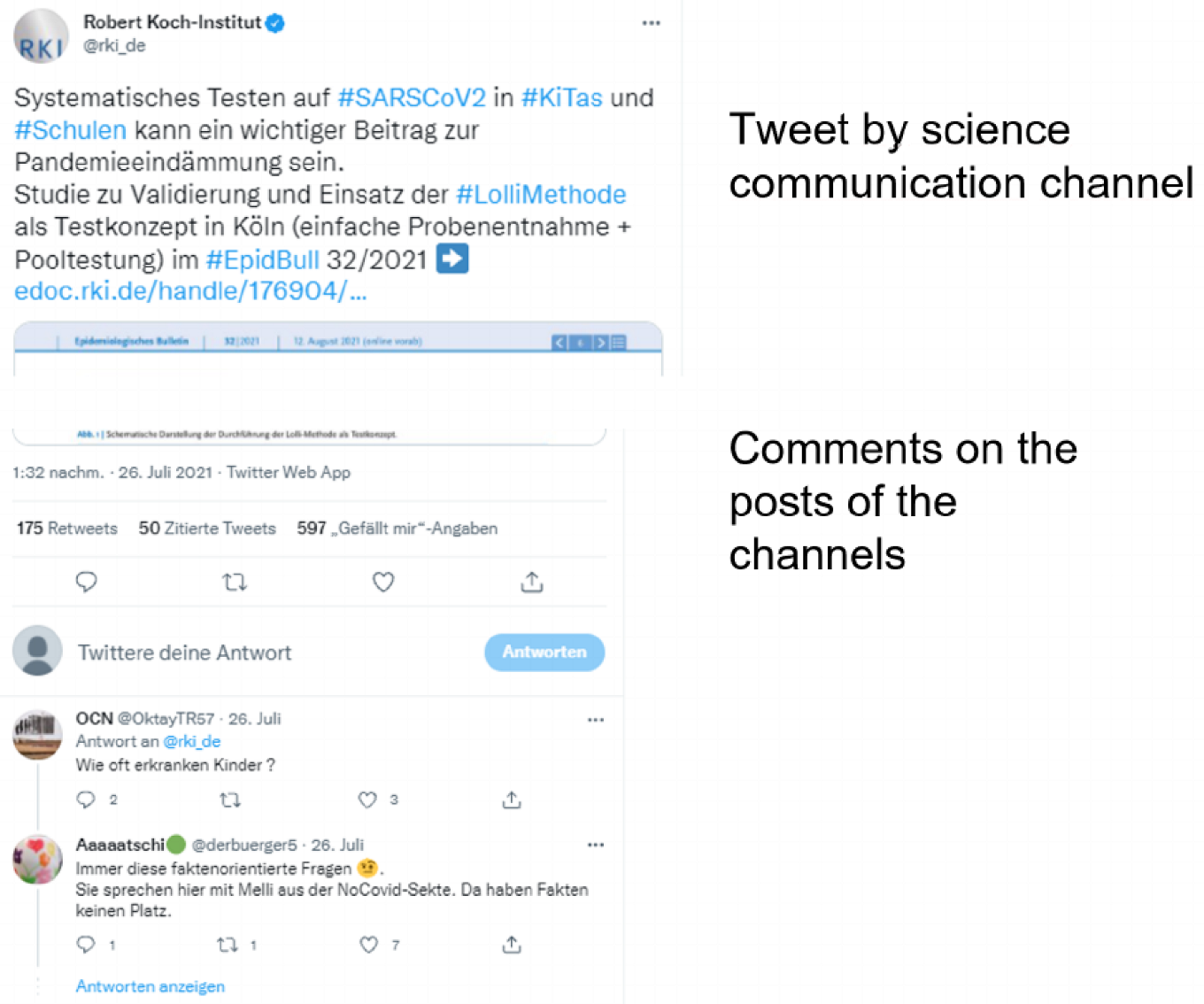
4.3. Tweets on Science Communication
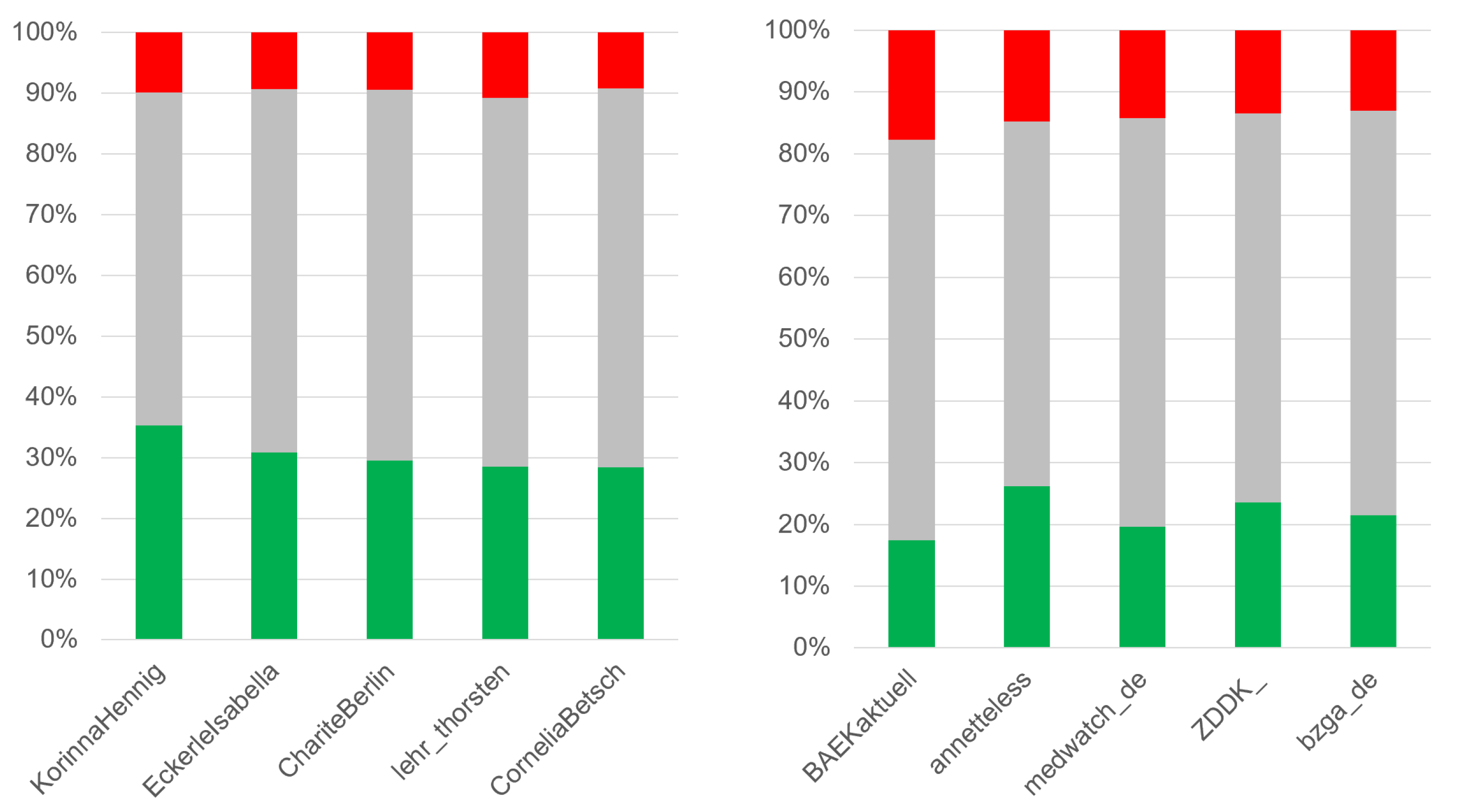
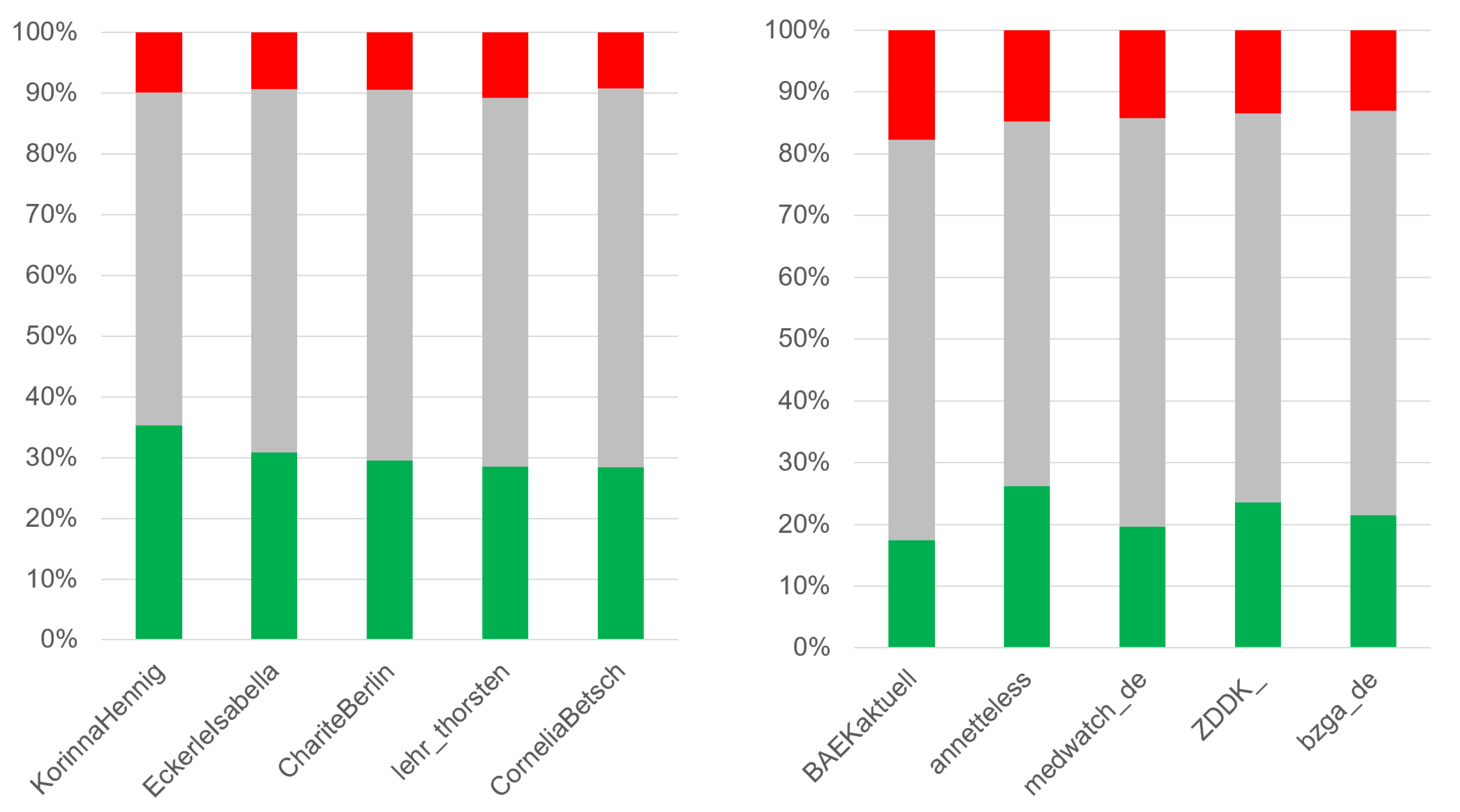
4.4. Sentiment Analysis for Channels
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LDA | Latent Dirichlet Allocation |
References
- Montesi, M. Human information behavior during the COVID-19 health crisis. A literature review. Libr. Inf. Sci. Res. 2021, 43, 101122. [Google Scholar] [CrossRef]
- Jaki, S.; Sabban, A. (Eds.) Wissensformate in den Medien: Analysen aus Medienlinguistik und Medienwissenschaft; Frank & Timme GmbH: Berlin, Germany, 2016; Volume 25. [Google Scholar]
- Shapiro, M.A.; Park, H.W. More than entertainment: YouTube and public responses to the science of global warming and climate change. Soc. Sci. Inf. 2015, 54, 115–145. [Google Scholar] [CrossRef]
- Jaki, S. This is simplified to the point of banality.: Social-Media-Kommentare zu Gestaltungsweisen von TV-Dokus. J. FüR Medien. 2021, 4, 54–87. [Google Scholar] [CrossRef]
- Latif, S.; Usman, M.; Manzoor, S.; Iqbal, W.; Qadir, J.; Tyson, G.; Castro, I.; Razi, A.; Boulos, M.N.K.; Weller, A.; et al. Leveraging data science to combat COVID-19: A comprehensive review. IEEE Trans. Artif. Intell. 2020, 1, 85–103. [Google Scholar] [CrossRef]
- Dreisiebner, S.; März, S.; Mandl, T. Information behavior during the COVID-19 crisis in German-speaking countries. J. Doc. 2022, 78, 160–175. [Google Scholar] [CrossRef]
- Viehmann, C.; Ziegele, M.; Quiring, O. Gut informiert durch die Pandemie? Nutzung unterschiedlicher Informationsquellen in der Corona-Krise. Media Perspekt. 2020, 11, 556–577. [Google Scholar]
- Brill, J.; Rossmann, C. Die Bedeutung von Gesundheitskompetenz für das Informationsverhalten deutscher Bundesbürger*innen zu Beginn der Corona-Pandemie. In Wissen um Corona: Wissenschaftskommunikation, Informationsverhalten, Diskurs; Schmidt, F., Jaki, S., Mandl, T., Eds.; Universitätsverlag Hildesheim: Hildesheim, Germany, 2022; pp. 45–82. [Google Scholar] [CrossRef]
- Schäfer, M.; Stark, B.; Werner, A.; Schäfer, M.; Stark, B.; Werner, A.; Mülder, L.; Reichel, J.; Heller, S.; Pavel Dietz, L. Gut informiert im Pandemie-Modus? Das Gesundheitsinformationsverhalten Studierender während der COVID-19-Pandemie: Zentrale Tendenzen und fachspezifische Unterschiede. Wissen Corona Wiss. Inform. Diskurs 2022, 83–111. [Google Scholar] [CrossRef]
- Viehmann, C.; Ziegele, M.; Quiring, O. Communication, Cohesion, and Corona: The Impact of People’s Use of Different Information Sources on their Sense of Societal Cohesion in Times of Crises. J. Stud. 2022, 23, 629–649. [Google Scholar] [CrossRef]
- Reinhardt, A.; Brill, J.; Rossmann, C. Eine Typologie des Informationsverhaltens der Deutschen in der Corona-Pandemie unter Berücksichtigung von Themenverdrossenheit. In Proceedings of the Jahrestagung der Fachgruppe Gesundheitskommunikation der Deutschen Gesellschaft für Publizistik-und Kommunikationswissenschaft; DEU: Leipzig, Germany, 2021; pp. 31–42. [Google Scholar] [CrossRef]
- Schmidt, F.; Jaki, S.; Mandl, T. (Eds.) Wissen um Corona: Wissenschaftskommunikation, Informationsverhalten, Diskurs; Universitätsverlag Hildesheim: Hildesheim, Germany, 2022. [Google Scholar] [CrossRef]
- Böcker, R.M.; Mitera, H.l.T.; Schmidt, F. Wissenschaftskommunikation und Informationsverhalten während der COVID-19-Pandemie: Eine Analyse von Umfragedaten und Interviews. Inf. Wiss. Prax. 2022. [Google Scholar] [CrossRef]
- Bucchi, M.; Trench, B. Science Communication and Science in Society: A Conceptual Review in Ten Keywords. Tecnoscienza 2016, 7, 151–168. [Google Scholar]
- Pasternack, P.; Beer, A. Die externe Kommunikation der Wissenschaft in der bisherigen Corona- Krise (2020/2021). Eine kommentierte Rekonstruktion (HoF-Arbeitsbericht 118); Institut für Hochschulforschung (HoF) an der Martin-Luther-Universität: Halle-Wittenberg, Germany, 2022. [Google Scholar]
- Geipel, A. Wissenschaft@YouTube. In Knowledge in Action: Neue Formen der Kommunikation in der Wissensgesellschaft; Lettkemann, E., Wilke, R., Knoblauch, H., Eds.; Springer Fachmedien: Wiesbaden, Germany, 2018; pp. 137–163. [Google Scholar] [CrossRef]
- Varwig, C. Kommunizieren oder verschweigen—Wie geht man mit wissenschaftlicher Unsicherheit um? In Wissenschaft und Gesellschaft: Ein Vertrauensvoller Dialog: Positionen und Perspektiven der Wissenschaftskommunikation Heute; Schnurr, J., Mäder, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 205–214. [Google Scholar] [CrossRef]
- Jaki, S. Terms in Popular Science Communication: The Case of TV Documentaries. Hermes-J. Lang. Commun. Bus. 2018, 58, 257–272. [Google Scholar] [CrossRef]
- Jaki, S. Emotionalisierung in TV-Wissensdokus. Eine multimodale Analyse englischer und deutscher archäologischer Sendungen. In Mediale Emotionskulturen; Hauser, S., Luginbühl, M., Tienken, S., Eds.; Peter Lang: Frankfurt, Germany, 2019; pp. 83–107. [Google Scholar] [CrossRef]
- Luginbühl, M. Vom Dozieren am Schreibtisch zum Informieren und Einschätzen unterwegs: Die mediale Inszenierung von Geistes-und SozialwissenschaftlerInnen im Wissenschaftsfernsehen. In Geisteswissenschaften und Öffentlichkeit. Linguistisch betrachtet; Luginbühl, M., Schröter, J., Eds.; Peter Lang: Frankfurt, Germany, 2018; pp. 139–168. [Google Scholar]
- Kress, G. Multimodality: A Social Semiotic Approach to Contemporary Communication; Routledge: Oxfordshire, UK, 2009. [Google Scholar]
- Stöckl, H. 1. Multimodalität—Semiotische und textlinguistische Grundlagen. Handb. Sprache Multimodalen Kontext 2016, 3–35. [Google Scholar] [CrossRef]
- Bucher, H.J.; Boy, B.; Christ, K. Audiovisuelle Wissenschaftskommunikation auf YouTube: Eine Rezeptionsstudie zur Vermittlungsleistung von Wissenschaftsvideos; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Madhu, H.; Satapara, S.; Modha, S.; Mandl, T.; Majumder, P. Detecting offensive speech in conversational code-mixed dialogue on social media: A contextual dataset and benchmark experiments. Expert Syst. Appl. 2022, 215, 119342. [Google Scholar] [CrossRef]
- Nakov, P.; Barrón-Cedeño, A.; Martino, G.D.S.; Alam, F.; Struß, J.M.; Mandl, T.; Míguez, R.; Caselli, T.; Kutlu, M.; Zaghouani, W.; et al. The CLEF-2022 CheckThat! Lab on Fighting the COVID-19 Infodemic and Fake News Detection. In Proceedings of the 44th European Conference on IR Research ECIR, Stavanger, Norway, 10–14 April 2022; Volume 13186, pp. 416–428. [Google Scholar] [CrossRef]
- Vijayaraghavan, P.; Vosoughi, S. TWEETSPIN: Fine-grained Propaganda Detection in Social Media Using Multi-View Representations. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies NAACL, Seattle, WA, USA, 10–15 July 2022; Carpuat, M., de Marneffe, M., Ruíz, I.V.M., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 3433–3448. [Google Scholar] [CrossRef]
- Basu, M.; Ghosh, S.; Ghosh, K. Overview of the FIRE 2018 Track: Information Retrieval from Microblogs during Disasters (IRMiDis). In Proceedings of the Working Notes of FIRE-Forum for Information Retrieval Evaluation, Gandhinagar, India, 6–9 December 2018; Available online: https://ceur-ws.org/Vol-2266/T1-1.pdf (accessed on 5 February 2023).
- De, D.; Thakur, G.S.; Herrmannova, D.; Christopher, C. Methodology to Compare Twitter Reaction Trends between Disinformation Communities, to COVID related Campaign Events at Different Geospatial Granularities. In Proceedings of the Companion of The Web Conference 2022, Virtual Event/Lyon, France, 25–29 April 2022; pp. 458–463. [Google Scholar] [CrossRef]
- Kausar, M.A.; Soosaimanickam, A.; Nasar, M. Public sentiment analysis on Twitter data during COVID-19 outbreak. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 2. [Google Scholar] [CrossRef]
- Koh, J.X.; Liew, T.M. How loneliness is talked about in social media during COVID-19 pandemic: Text mining of 4492 Twitter feeds. J. Psychiatr. Res. 2020, 145, 317–324. [Google Scholar] [CrossRef]
- DeVerna, M.R.; Pierri, F.; Truong, B.T.; Bollenbacher, J.; Axelrod, D.; Loynes, N.; Torres-Lugo, C.; Yang, K.; Menczer, F.; Bryden, J. CoVaxxy: A Collection of English-Language Twitter Posts About COVID-19 Vaccines. In Proceedings of the Fifteenth International AAAI Conference on Web and Social Media, ICWSM Held Virtually, 7–10 June 2021; AAAI Press: Washington, DC, USA, 2021; pp. 992–999. [Google Scholar]
- Shuja, J.; Alanazi, E.; Alasmary, W.; Alashaikh, A. COVID-19 open source data sets: A comprehensive survey. Appl. Intell. 2021, 51, 1296–1325. [Google Scholar] [CrossRef]
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Artemova, E.; Tutubalina, E.; Chowell, G. A large-scale COVID-19 Twitter chatter dataset for open scientific research—an international collaboration. Epidemiologia 2021, 2, 315–324. [Google Scholar] [CrossRef]
- Qazi, U.; Imran, M.; Ofli, F. GeoCoV19: A dataset of hundreds of millions of multilingual COVID-19 tweets with location information. Sigspatial Spec. 2020, 12, 6–15. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Ferrara, E. What Types of COVID-19 Conspiracies are Populated by Twitter Bots? CoRR 2020, abs/2004.09531. Available online: https://arxiv.org/abs/2004.09531 (accessed on 5 February 2023).
- Boon-Itt, S.; Skunkan, Y. Public perception of the COVID-19 pandemic on Twitter: Sentiment analysis and topic modeling study. Jmir Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- De Melo, T.; Figueiredo, C.M. Comparing news articles and tweets about COVID-19 in Brazil: Sentiment analysis and topic modeling approach. Jmir Public Health Surveill. 2021, 7, e24585. [Google Scholar] [CrossRef] [PubMed]
- Yin, H.; Song, X.; Yang, S.; Li, J. Sentiment analysis and topic modeling for COVID-19 vaccine discussions. World Wide Web 2022, 25, 1067–1083. [Google Scholar] [CrossRef]
- Mitera, H. Topic-Modeling-Ansätze für Social Media Kommunikation in der Coronapandemie. Inf.-Wiss. Prax. 2022, 73, 197–205. [Google Scholar] [CrossRef]
- Jia, X.; Chen, J.; Chen, C.; Zheng, C.; Li, S.; Zhu, T. Public discourse and sentiment during the COVID 19 pandemic: Using Latent Dirichlet Allocation for topic modeling on Twitter. PLoS ONE 2020, 15, e0239441. [Google Scholar] [CrossRef]
- Chandrasekaran, R.; Mehta, V.; Valkunde, T.; Moustakas, E. Topics, Trends, and Sentiments of Tweets About the COVID-19 Pandemic: Temporal Infoveillance Study. J. Med. Internet Res. 2020, 22, e22624. [Google Scholar] [CrossRef]
- Kydros, D.; Argyropoulou, M.; Vrana, V. A content and sentiment analysis of Greek tweets during the pandemic. Sustainability 2021, 13, 6150. [Google Scholar] [CrossRef]
- Liu, Q.; Zheng, Z.; Zheng, J.; Chen, Q.; Liu, G.; Chen, S.; Chu, B.; Zhu, H.; Akinwunmi, B.; Huang, J.; et al. Health Communication Through News Media During the Early Stage of the COVID-19 Outbreak in China: Digital Topic Modeling Approach. J. Med. Internet Res. 2020, 22, e19118. [Google Scholar] [CrossRef]
- Creswell, J.; Plano, V. Designing and Conducting Mixed Methods Research; SAGE: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Molina-Azorín, J.F. Understanding how mixed methods research is undertaken within a specific research community: The case of business studies. Int. J. Mult. Res. Approaches 2009, 3, 47–57. [Google Scholar] [CrossRef]
- Max Planck Institute for Psycholinguistics. ELAN (Version 6.4). 2022. Available online: https://www.mpi.nl/tools/elan/docs/ELAN_manual.pdf (accessed on 5 February 2023).
- Vayansky, I.; Kumar, S.A. A review of topic modeling methods. Inf. Syst. 2020, 94, 101582. [Google Scholar] [CrossRef]
- Rehurek, R.; Sojka, P. Gensim–Python framework for vector space modelling. NLP Cent. Fac. Inform. Masaryk. Univ. Brno 2011, 3, 2. [Google Scholar]
- Boiy, E.; Hens, P.; Deschacht, K.; Moens, M.F. Automatic Sentiment Analysis in On-line Text. In Proceedings of the Openness in Digital Publishing: Awareness, Discovery and Access-Proceedings of the 11th International Conference on Electronic Publishing, Vienna, Austria, 13–15 June 2007; pp. 349–360. [Google Scholar]
- Schulz, J.M.; Womser-Hacker, C.; Mandl, T. Multilingual Corpus Development for Opinion Mining. In Proceedings of the Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10); European Language Resources Association (ELRA): Valletta, Malta, 2010; Available online: http://www.lrec-conf.org/proceedings/lrec2010/pdf/689_Paper.pdf (accessed on 5 February 2023).
- Diyasa, I.G.S.M.; Mandenni, N.M.I.M.; Fachrurrozi, M.I.; Pradika, S.I.; Manab, K.R.N.; Sasmita, N.R. Twitter Sentiment Analysis as an Evaluation and Service Base on Python Textblob. In Proceedings of the IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2021; Volume 1125, p. 012034. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Göpfert, W. Beispiele, Vergleiche und Metaphern. In Wissenschafts-Journalismus: Ein Handbuch für Ausbildung und Praxis, 4th ed.; Göpfert, W., Ruß-Mohl, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 107–121. [Google Scholar] [CrossRef]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 63–70. [Google Scholar] [CrossRef]
- Chandrasekaran, G.; Hemanth, J. Deep Learning and TextBlob Based Sentiment Analysis for Coronavirus (COVID-19) Using Twitter Data. Int. J. Artif. Intell. Tools 2022, 31, 2250011. [Google Scholar] [CrossRef]
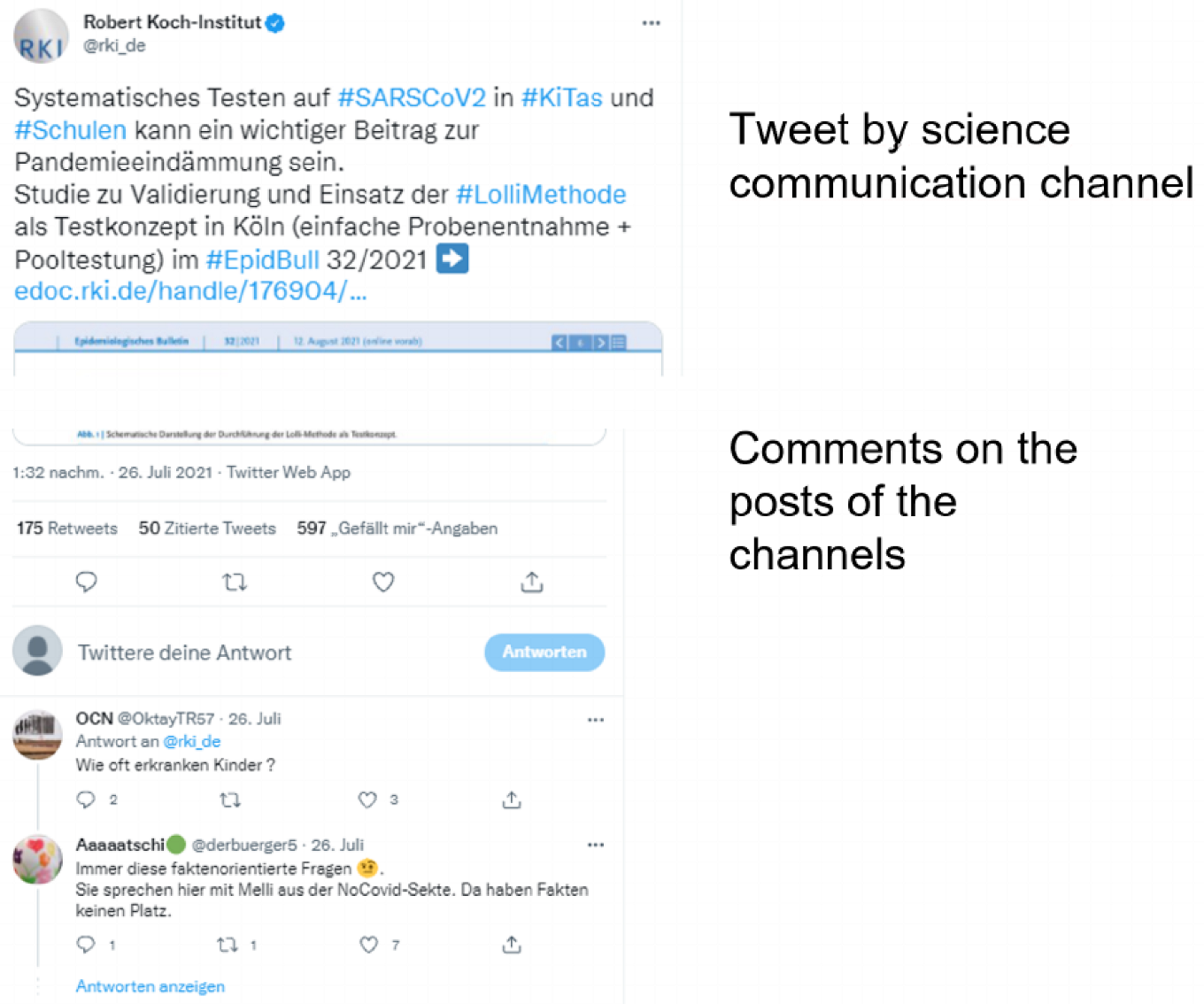

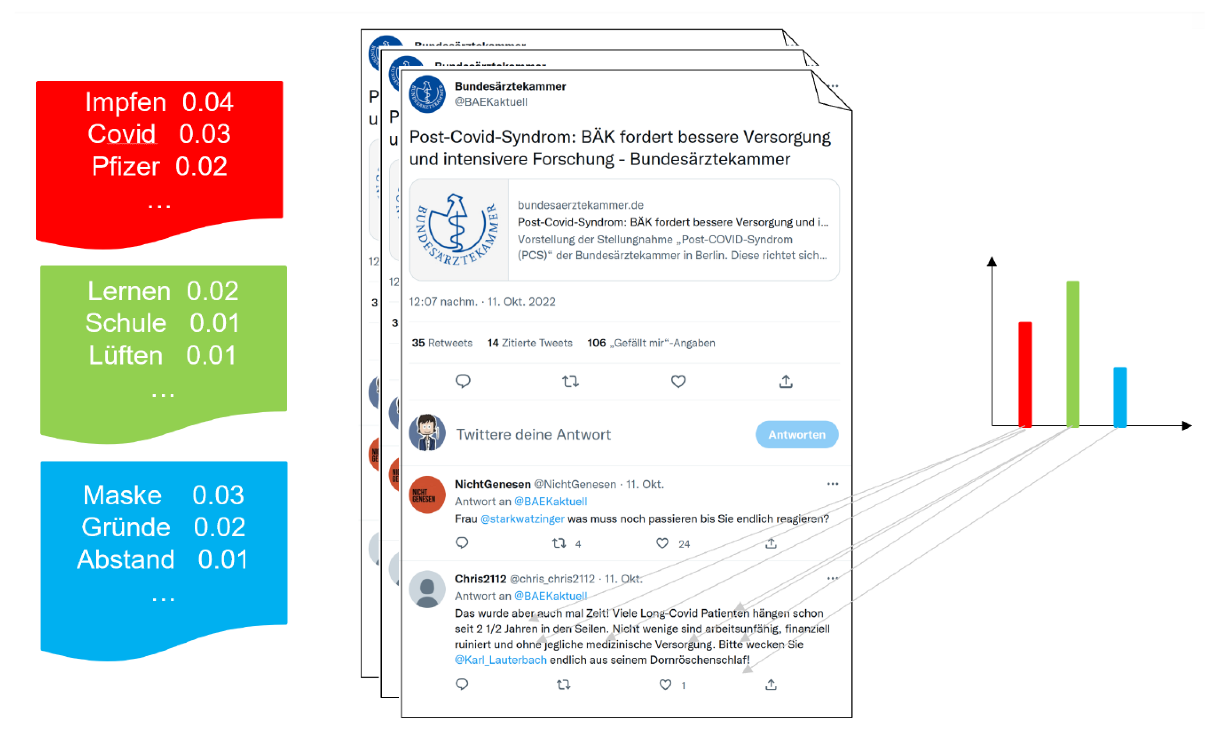
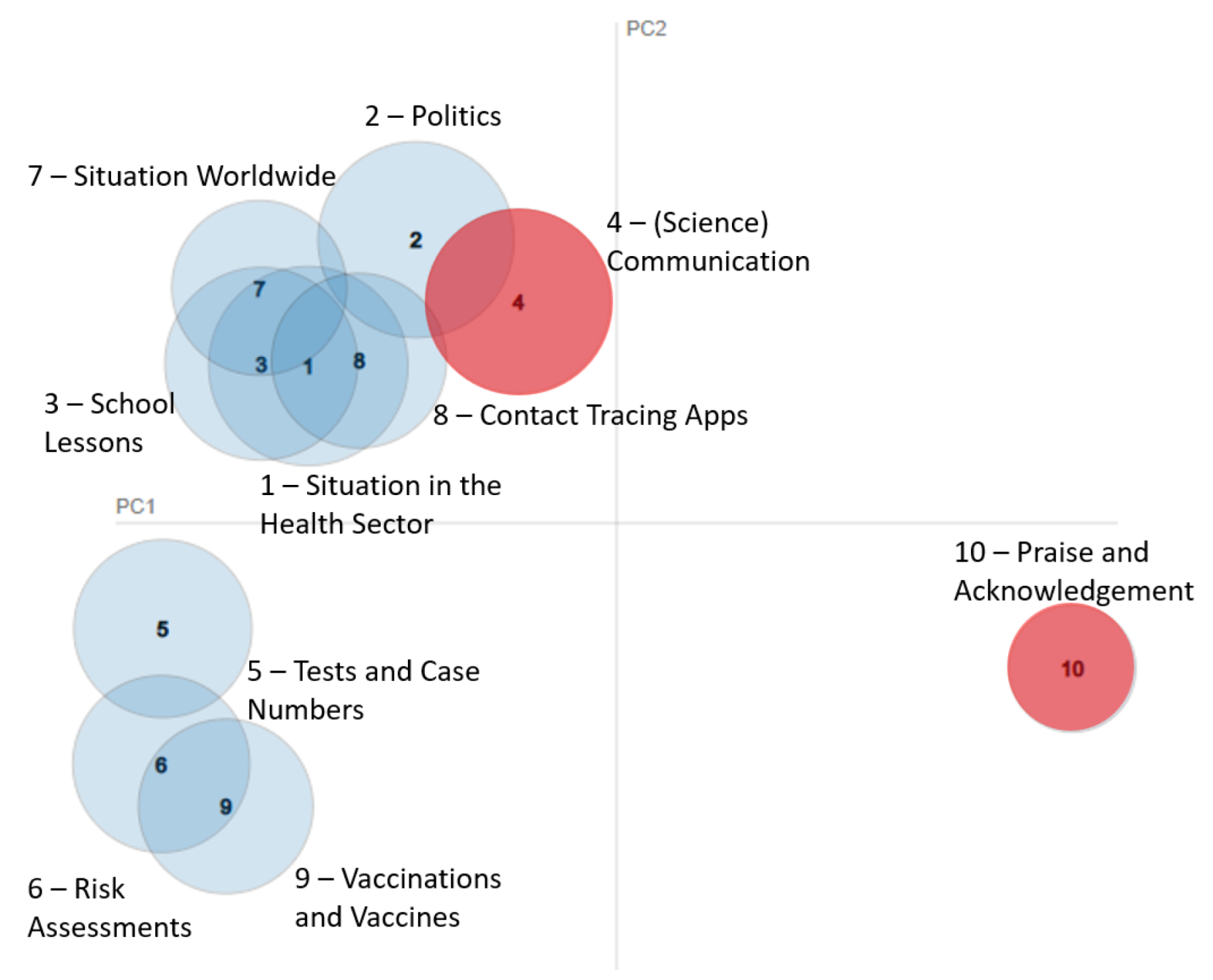

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic Number | Frequent Words |
|---|---|
| 1 | data, government, fear, people, before |
| 2 | vaccination, vaccinated, infect, people, patients |
| 3 | weeks, positive, last, week, tests |
| 4 | exactly, past, situation, interventions, drosten |
| 5 | simple, infection, sick, summer, sad |
| 6 | opinion, flu, variant, mister, truth |
| 7 | clear, hopefully, long, human, person |
| 8 | important, mister, decision, sick, problems |
| 9 | vaccinate, mask, masks, countries, immediately |
| 10 | numbers, current, parents, schools, test |
| 11 | politics, gladly, full, harm, group |
| 12 | questions, virus, serious, out, mutations |
| 13 | studies, German, reason, immunity, federal government |
| 14 | thanks, scientific, work, people, twitter |
| 15 | wrong, panic, free, country, great |
| Topic Number | Frequent Words |
|---|---|
| 17 | risk, low, answer, good, away |
| 20 | beautiful, effectiveness, side, sometimes, wrong |
| 21 | children, children, whatever, contacts, teen |
| 26 | vaccinations, people, healthy, life, course |
| 27 | school, happiness, state, solution, word |
| Annotator | Number of Tweets Marked as Relevant |
|---|---|
| 1 | 189 |
| 2 | 77 |
| 3 | 68 |
| Two annotators | 57 |
| All three annotators | 44 |
| Two or three annotators | 101 |
| Original Tweet in German | Tweet in English (Translated by Authors) |
|---|---|
| Wenn ein Artikel zu der Coronastrategie in einem Land mit 340,000 Pendlern täglich bebildert wird mit einem Foto von einer recht abgelegenen Insel, würde ich das allerdings nicht "Information" nennen. "Irreführung" scheint mir da der bessere Begriff zu sein. | If an article on the COVID strategy in a country with 340,000 daily commuters is illustrated with a photo of a rather remote island, I would not call that "information," however. "Misleading" seems to be the better word. |
| Ich finde es sehr schön, dass Sie auch Studien zitieren, die nicht Ihren Thesen entsprechen! Damit will ich nicht sagen, dass man auch unseriösen Stimmen Gehör einräumen müsste, wie es leider in der Presse viel zu oft getan wird. | I find it very good that you also quote studies that do not correspond to your theses! Nevertheless, that does not mean that you need to hear all sorts of questionable opinions, as it is done in the press way too often, unfortunately. |
| Danke für dieses sehr sprechende Beispiel. Wir können es ja einfach mal kurz plakativ zusammenfassen: Wir gefährden gerade Akut unsere Leistungsträger der Gesellschaft und unsere Zukunft. Das darf nicht passieren! | Thank you for this very telling example. We can simply summarize it briefly as follows: We are currently acutely endangering our top performers in society as well as our future. This must be prevented! |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mandl, T.; Jaki, S.; Mitera, H.; Schmidt, F. Interdisciplinary Analysis of Science Communication on Social Media during the COVID-19 Crisis. Knowledge 2023, 3, 97-112. https://doi.org/10.3390/knowledge3010008
Mandl T, Jaki S, Mitera H, Schmidt F. Interdisciplinary Analysis of Science Communication on Social Media during the COVID-19 Crisis. Knowledge. 2023; 3(1):97-112. https://doi.org/10.3390/knowledge3010008
Chicago/Turabian StyleMandl, Thomas, Sylvia Jaki, Hannah Mitera, and Franziska Schmidt. 2023. "Interdisciplinary Analysis of Science Communication on Social Media during the COVID-19 Crisis" Knowledge 3, no. 1: 97-112. https://doi.org/10.3390/knowledge3010008
APA StyleMandl, T., Jaki, S., Mitera, H., & Schmidt, F. (2023). Interdisciplinary Analysis of Science Communication on Social Media during the COVID-19 Crisis. Knowledge, 3(1), 97-112. https://doi.org/10.3390/knowledge3010008