
Bayesian Measurement of Diagnostic Accuracy of the RT-PCR Test for COVID-19


Abstract
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Statistical Analysis
2.2.1. Diagnostic Accuracy Model
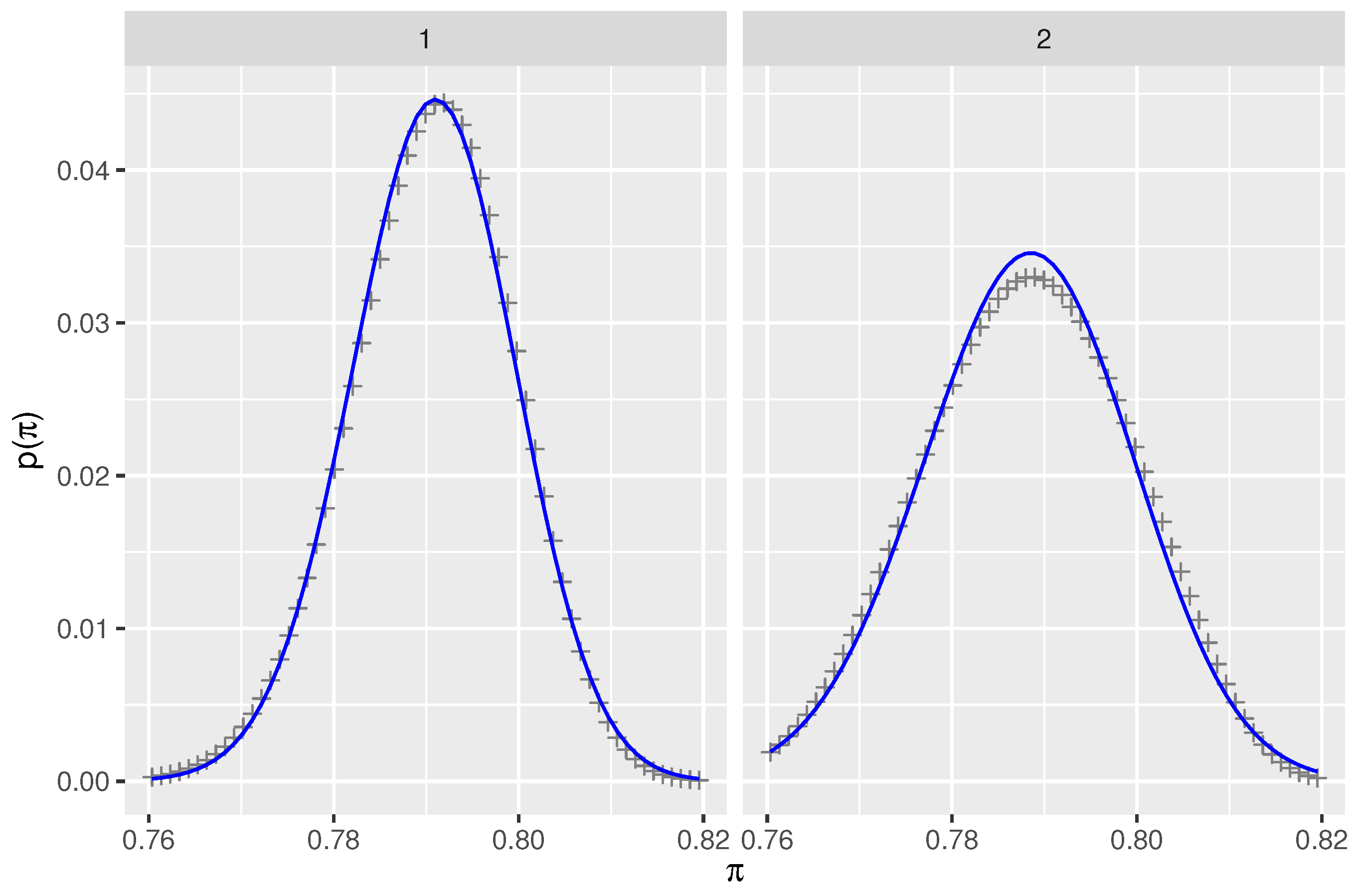
2.2.2. Prior for Prevalence
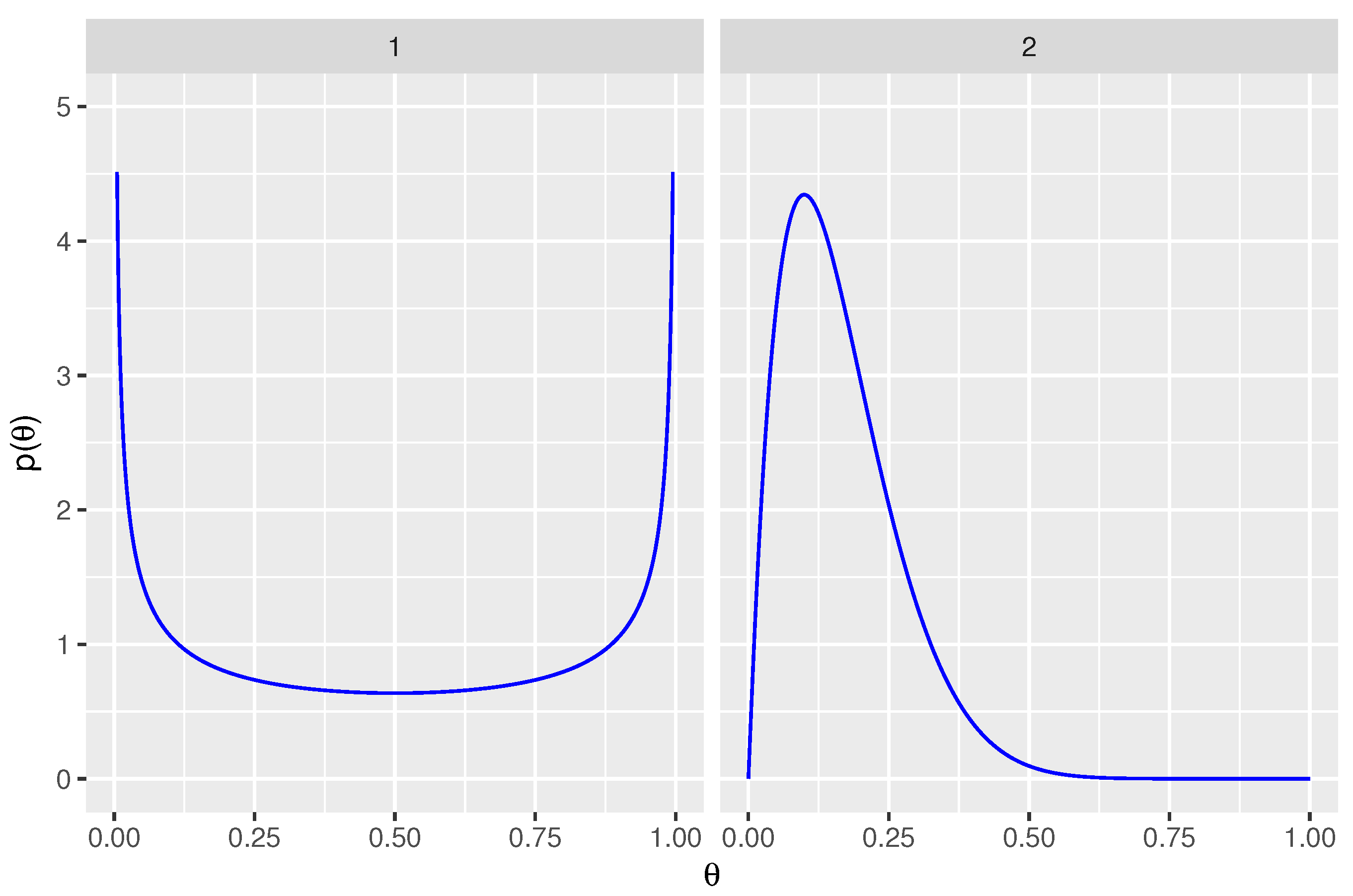
2.2.3. Priors for Sensitivity and False Positive Rate
2.2.4. Implementation in Stan
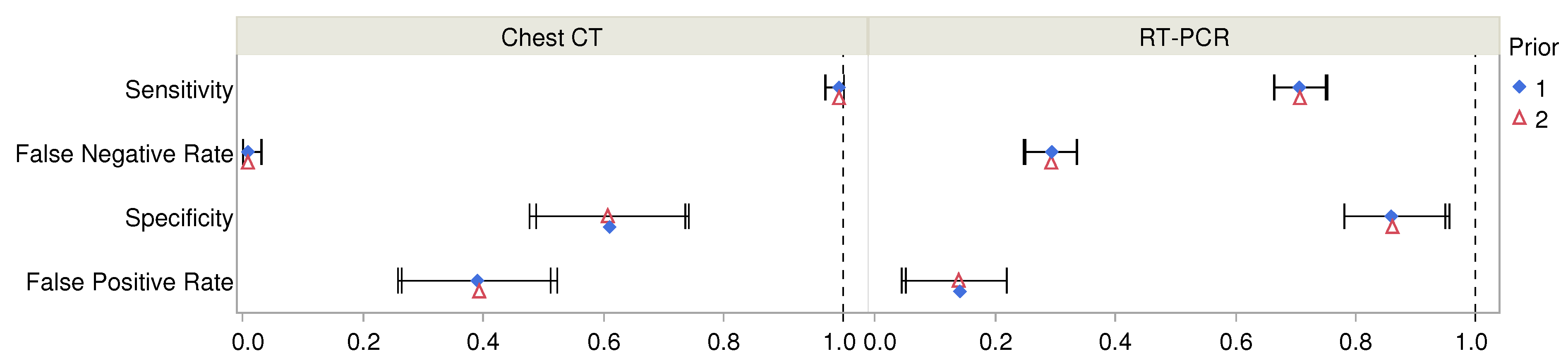
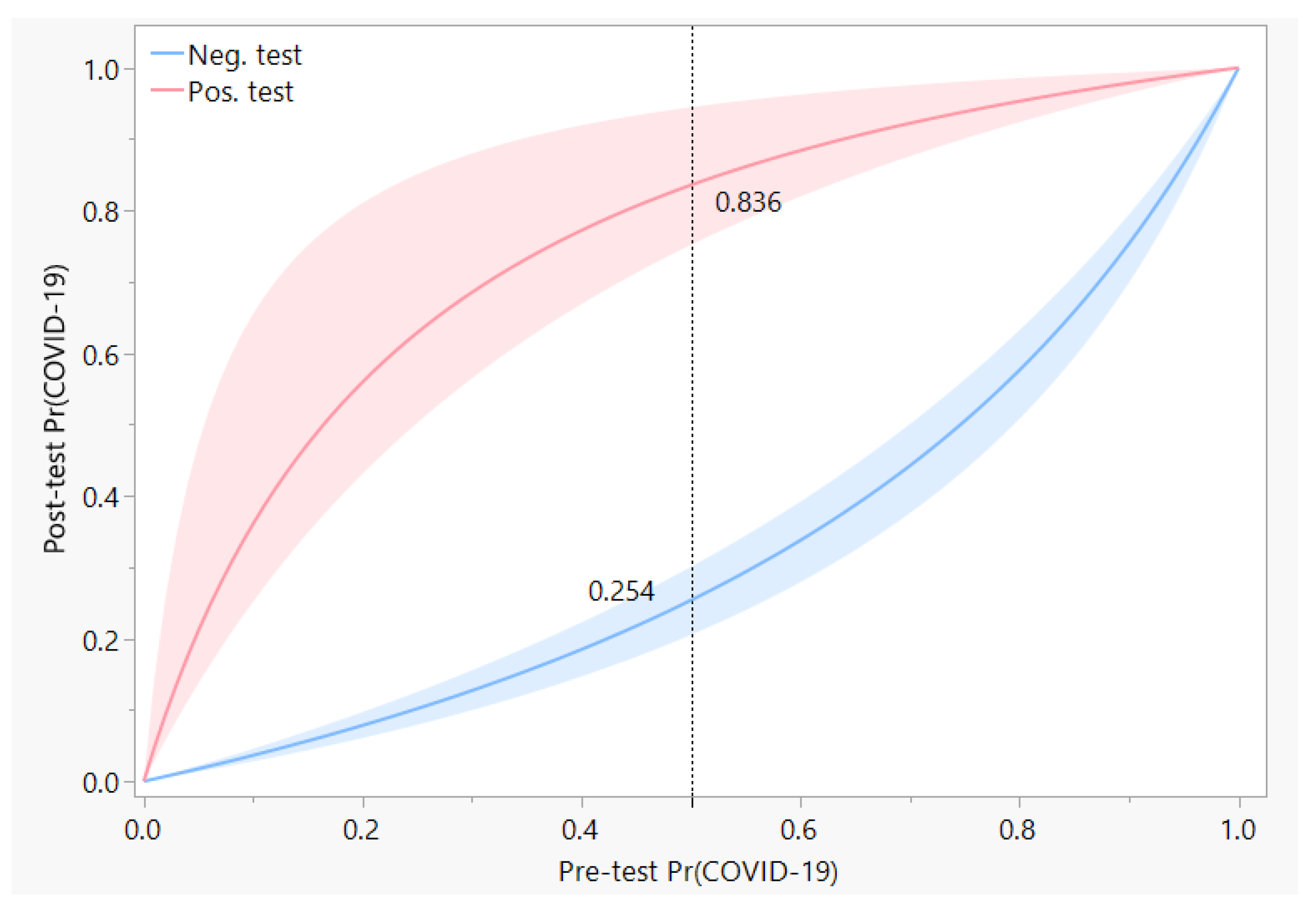
3. Results
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RT-PCR | Reverse transcription polymerase chain reaction |
| COVID-19 | Coronavirus disease 2019 |
| CT | Computerized tomography |
| ICD | Intelligence Community Directive |
| NUTS | No U-turn sampling |
Appendix A
References
- WHO Coronavirus. Library Catalog. Available online: www.who.int (accessed on 16 April 2020).
- Wu, F.; Zhao, S.; Yu, B.; Chen, Y.M.; Wang, W.; Song, Z.G.; Hu, Y.; Tao, Z.W.; Tian, J.H.; Pei, Y.Y.; et al. A new coronavirus associated with human respiratory disease in China. Nature 2020, 579, 265–269. [Google Scholar] [CrossRef] [PubMed]
- Corman, V.M.; Landt, O.; Kaiser, M.; Molenkamp, R.; Meijer, A.; Chu, D.K.; Bleicker, T.; Brünink, S.; Schneider, J.; Schmidt, M.L.; et al. Detection of 2019 novel coronavirus (2019-nCoV) by real-time RT-PCR. Eurosurveillance 2020, 25, 2000045. [Google Scholar] [CrossRef] [PubMed]
- Chan, J.F.W.; Yip, C.C.Y.; To, K.K.W.; Tang, T.H.C.; Wong, S.C.Y.; Leung, K.H.; Fung, A.Y.F.; Ng, A.C.K.; Zou, Z.; Tsoi, H.W.; et al. Improved molecular diagnosis of COVID-19 by the novel, highly sensitive and specific COVID-19-RdRp/Hel real-time reverse transcription-polymerase chain reaction assay validated in vitro and with clinical specimens. J. Clin. Microbiol. 2020, 58, e00310-20. [Google Scholar] [CrossRef] [PubMed]
- Pang, J.; Wang, M.X.; Ang, I.Y.H.; Tan, S.H.X.; Lewis, R.F.; Chen, J.I.P.; Gutierrez, R.A.; Gwee, S.X.W.; Chua, P.E.Y.; Yang, Q.; et al. Potential Rapid Diagnostics, Vaccine and Therapeutics for 2019 Novel Coronavirus (2019-nCoV): A Systematic Review. J. Clin. Med. 2020, 9, 623. [Google Scholar] [CrossRef] [PubMed]
- Reusken, C.B.E.M.; Broberg, E.K.; Haagmans, B.; Meijer, A.; Corman, V.M.; Papa, A.; Charrel, R.; Drosten, C.; Koopmans, M.; Leitmeyer, K.; et al. Laboratory readiness and response for novel coronavirus (2019-nCoV) in expert laboratories in 30 EU/EEA countries, January 2020. Eurosurveillance 2020, 25, 2000082. [Google Scholar] [CrossRef] [PubMed]
- Krumholz, H.M. If You Have Coronavirus Symptoms, Assume You Have the Illness, Even if You Test Negative. The New York Times, 1 April 2020. [Google Scholar]
- Lazar, K.; Ryan, A. How accurate are coronavirus tests? Doctors raise concern about ‘false-negative’ results. The Boston Globe, 2 April 2020. [Google Scholar]
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Tao, Q.; Sun, Z.; Xia, L. Correlation of Chest CT and RT-PCR Testing in Coronavirus Disease 2019 (COVID-19) in China: A Report of 1014 Cases. Radiology 2020, 296, E32–E40. [Google Scholar] [CrossRef] [PubMed]
- Dawid, A.P.; Skene, A.M. Maximum Likelihood Estimation of Observer Error-Rates Using the EM Algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 20–28. [Google Scholar] [CrossRef]
- Intelligence Community Directive 203, Analytic Standards; Technical Report ICD 203; Office of the Director of National Intelligence: Washington, DC, USA, 2015.
- Wintle, B.C.; Fraser, H.; Wills, B.C.; Nicholson, A.E.; Fidler, F. Verbal probabilities: Very likely to be somewhat more confusing than numbers. PLoS ONE 2019, 14, e0213522. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Stan Development Team. RStan: The R Interface to Stan; R Package Version 2.21.5. 2022. Available online: http://mc-stan.org/ (accessed on 4 August 2022).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 4 August 2022).
- RStudio Team. RStudio: Integrated Development Environment for R; RStudio, PBC.: Boston, MA, USA, 2022. [Google Scholar]
- López Roa, P.; Catalán, P.; Giannella, M.; García de Viedma, D.; Sandonis, V.; Bouza, E. Comparison of real-time RT-PCR, shell vial culture, and conventional cell culture for the detection of the pandemic influenza A (H1N1) in hospitalized patients. Diagn. Microbiol. Infect. Dis. 2011, 69, 428–431. [Google Scholar] [CrossRef]
- Huh, H.J.; Kim, J.Y.; Kwon, H.J.; Yun, S.A.; Lee, M.K.; Ki, C.S.; Lee, N.Y.; Kim, J.W. Performance Evaluation of the PowerChek MERS (upE & ORF1a) Real-Time PCR Kit for the Detection of Middle East Respiratory Syndrome Coronavirus RNA. Ann. Lab. Med. 2017, 37, 494–498. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Kucirka, L.M.; Lauer, S.A.; Laeyendecker, O.; Boon, D.; Lessler, J. Variation in False-Negative Rate of Reverse Transcriptase Polymerase Chain Reaction–Based SARS-CoV-2 Tests by Time Since Exposure. Ann. Intern. Med. 2020, 173, 262–267. [Google Scholar] [CrossRef]
- Peiris, J.; Chu, C.; Cheng, V.; Chan, K.; Hung, I.; Poon, L.; Law, K.; Tang, B.; Hon, T.; Chan, C.; et al. Clinical progression and viral load in a community outbreak of coronavirus-associated SARS pneumonia: A prospective study. Lancet 2003, 361, 1767–1772. [Google Scholar] [CrossRef]
- Poon, L.L.M.; Chan, K.H.; Wong, O.K.; Yam, W.C.; Yuen, K.Y.; Guan, Y.; Lo, Y.M.D.; Peiris, J.S.M. Early diagnosis of SARS Coronavirus infection by real time RT-PCR. J. Clin. Virol. 2003, 28, 233–238. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Xu, Y.; Gao, R.; Lu, R.; Han, K.; Wu, G.; Tan, W. Detection of SARS-CoV-2 in Different Types of Clinical Specimens. JAMA 2020, 323, 1843–1844. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Yang, M.; Shen, C.; Wang, F.; Yuan, J.; Li, J.; Zhang, M.; Wang, Z.; Xing, L.; Wei, J.; et al. Evaluating the accuracy of different respiratory specimens in the laboratory diagnosis and monitoring the viral shedding of 2019-nCoV infections. medRxiv 2020. [Google Scholar] [CrossRef]
- Kovács, A.; Palásti, P.; Veréb, D.; Bozsik, B.; Palkó, A.; Kincses, Z.T. The sensitivity and specificity of chest CT in the diagnosis of COVID-19. Eur. Radiol. 2020, 31, 2819–2824. [Google Scholar] [CrossRef]
- Caruso, D.; Zerunian, M.; Polici, M.; Pucciarelli, F.; Polidori, T.; Rucci, C.; Guido, G.; Bracci, B.; de Dominicis, C.; Laghi, A. Chest CT Features of COVID-19 in Rome, Italy. Radiology 2020, 296, E79–E85. [Google Scholar] [CrossRef]
- Cheng, Z.; Lu, Y.; Cao, Q.; Qin, L.; Pan, Z.; Yan, F.; Yang, W. Clinical Features and Chest CT Manifestations of Coronavirus Disease 2019 (COVID-19) in a Single-Center Study in Shanghai, China. AJR Am. J. Roentgenol. 2020, 215, 121–126. [Google Scholar] [CrossRef]
- Dramé, M.; Tabue Teguo, M.; Proye, E.; Hequet, F.; Hentzien, M.; Kanagaratnam, L.; Godaert, L. Should RT-PCR be considered a gold standard in the diagnosis of COVID-19? J. Med. Virol. 2020, 92, 2312–2313. [Google Scholar] [CrossRef]
- Bisoffi, Z.; Pomari, E.; Deiana, M.; Piubelli, C.; Ronzoni, N.; Beltrame, A.; Bertoli, G.; Riccardi, N.; Perandin, F.; Formenti, F.; et al. Sensitivity, Specificity and Predictive Values of Molecular and Serological Tests for COVID-19: A Longitudinal Study in Emergency Room. Diagnostics 2020, 10, 669. [Google Scholar] [CrossRef] [PubMed]
- Woloshin, S.; Patel, N.; Kesselheim, A.S. False Negative Tests for SARS-CoV-2 Infection—Challenges and Implications. New Engl. J. Med. 2020, 383, e38. [Google Scholar] [CrossRef]
- Lee, K.K.; Doudesis, D.; Ross, D.A.; Bularga, A.; MacKintosh, C.L.; Koch, O.; Johannessen, I.; Templeton, K.; Jenks, S.; Chapman, A.R.; et al. Diagnostic performance of the combined nasal and throat swab in patients admitted to hospital with suspected COVID-19. BMC Infect. Dis. 2021, 21, 318. [Google Scholar] [CrossRef]
- Tsang, N.N.Y.; So, H.C.; Ip, D.K.M. Is oropharyngeal sampling a reliable test to detect SARS-CoV-2? – Authors’ reply. Lancet Infect. Dis. 2021, 21, 1348–1349. [Google Scholar] [CrossRef]
- Arevalo-Rodriguez, I.; Buitrago-Garcia, D.; Simancas-Racines, D.; Zambrano-Achig, P.; Campo, R.D.; Ciapponi, A.; Sued, O.; Martinez-García, L.; Rutjes, A.W.; Low, N.; et al. False-negative results of initial RT-PCR assays for COVID-19: A systematic review. PLoS ONE 2020, 15, e0242958. [Google Scholar] [CrossRef] [PubMed]
- Bélisle, P.; Joseph, L. beta.parms.from.quantiles, an R Program for Computing Beta Distribution Parameters. Available online: www.medicine.mcgill.ca/epidemiology/joseph/pbelisle/BetaParmsFromQuantiles.html (accessed on 6 November 2020).
- Grün, B.; Leisch, F. FlexMix Version 2: Finite Mixtures with Concomitant Variables and Varying and Constant Parameters. J. Stat. Softw. 2008, 28, 1–35. [Google Scholar] [CrossRef]
- Nash, J.C. Compact Numerical Methods for Computers: Linear Algebra and Function Minimisation; Hilger: Bristol, England, 1990. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive Chest CT | Negative Chest CT | Row Sums | |
|---|---|---|---|
| Positive RT-PCR | 580 | 21 | 601 |
| Negative RT-PCR | 308 a | 105 | 413 |
| Column Sums | 888 | 126 | 1014 |
| Test | Parameter | Prior a | Mean | SD | 95% Posterior Int. | ESS b | |
|---|---|---|---|---|---|---|---|
| Lower | Upper | ||||||
| RT-PCR | Sensitivity | Prior 1 | 0.706 | 0.022 | 0.665 | 0.750 | 8807 |
| Prior 2 | 0.707 | 0.023 | 0.664 | 0.753 | 6828 | ||
| False Negative Rate | Prior 1 | 0.294 | 0.022 | 0.250 | 0.335 | 8807 | |
| Prior 2 | 0.293 | 0.023 | 0.247 | 0.336 | 6828 | ||
| Specificity | Prior 1 | 0.859 | 0.042 | 0.781 | 0.949 | 7475 | |
| Prior 2 | 0.861 | 0.043 | 0.781 | 0.956 | 5591 | ||
| False Positive Rate | Prior 1 | 0.141 | 0.042 | 0.051 | 0.219 | 7475 | |
| Prior 2 | 0.139 | 0.043 | 0.044 | 0.219 | 5591 | ||
| Chest CT | Sensitivity | Prior 1 | 0.992 | 0.009 | 0.970 | 1.000 | 6518 |
| Prior 2 | 0.992 | 0.009 | 0.969 | 1.000 | 5355 | ||
| False Negative Rate | Prior 1 | 0.008 | 0.009 | 0.000 | 0.030 | 6518 | |
| Prior 2 | 0.008 | 0.009 | 0.000 | 0.031 | 5355 | ||
| Specificity | Prior 1 | 0.610 | 0.063 | 0.488 | 0.736 | 8473 | |
| Prior 2 | 0.607 | 0.067 | 0.477 | 0.742 | 6403 | ||
| False Positive Rate | Prior 1 | 0.390 | 0.063 | 0.264 | 0.512 | 8473 | |
| Prior 2 | 0.393 | 0.067 | 0.258 | 0.523 | 6403 | ||
| RT-PCR | Chest CT | Mean | SD | 95% Posterior Int. | ESS a | |
|---|---|---|---|---|---|---|
| Lower | Upper | |||||
| Negative | Negative | 0.017 | 0.018 | 0.000 | 0.063 | 5985 |
| Positive | 0.766 | 0.052 | 0.655 | 0.860 | 4863 | |
| Positive | Negative | 0.208 | 0.219 | 0.000 | 0.768 | 4169 |
| Positive | 0.980 | 0.007 | 0.966 | 0.993 | 8052 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Padhye, N. Bayesian Measurement of Diagnostic Accuracy of the RT-PCR Test for COVID-19. Metrology 2022, 2, 414-426. https://doi.org/10.3390/metrology2040025
Padhye N. Bayesian Measurement of Diagnostic Accuracy of the RT-PCR Test for COVID-19. Metrology. 2022; 2(4):414-426. https://doi.org/10.3390/metrology2040025
Chicago/Turabian StylePadhye, Nikhil. 2022. "Bayesian Measurement of Diagnostic Accuracy of the RT-PCR Test for COVID-19" Metrology 2, no. 4: 414-426. https://doi.org/10.3390/metrology2040025
APA StylePadhye, N. (2022). Bayesian Measurement of Diagnostic Accuracy of the RT-PCR Test for COVID-19. Metrology, 2(4), 414-426. https://doi.org/10.3390/metrology2040025