
3Cs: Unleashing Capsule Networks for Robust COVID-19 Detection Using CT Images


Abstract
1. Introduction
- Re-purposing CapsNet to deal with lung CT images to speed up the process of medical image annotation.
- Fine-tuning our implementation of CapsNet to work as a multi-class classifier with three classes: NCP, CP and normal control.
- Providing a new state-of-the-art high-accuracy diagnostic technique (3Cs) that can be used with RT–PCR results to verify COVID-19 detection.
2. Related Work
2.1. COVID-19 Detection by Combining CNNs with CapsNets
2.2. COVID-19 Detection by CapsNets
3. Materials and Methods
3.1. Datasets Extraction
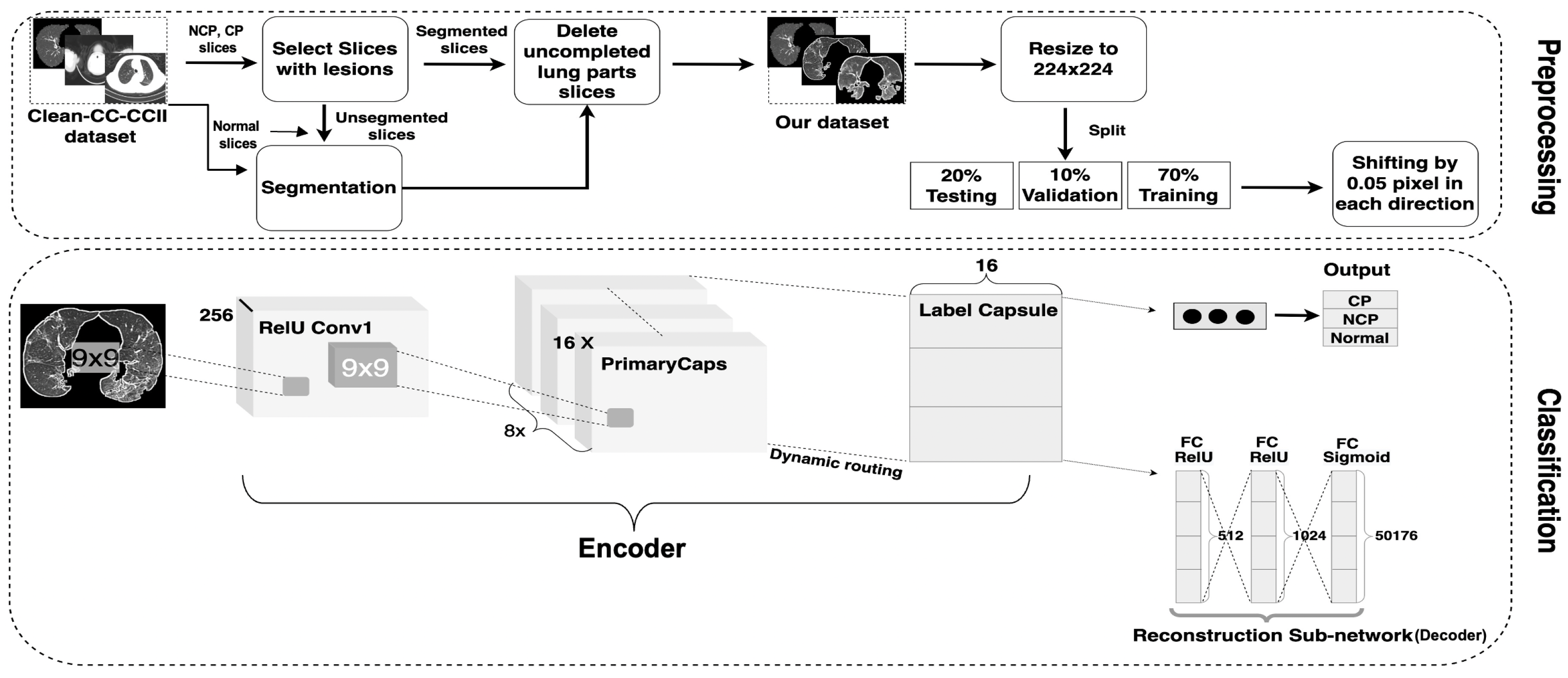
3.2. Dataset Preprocessing
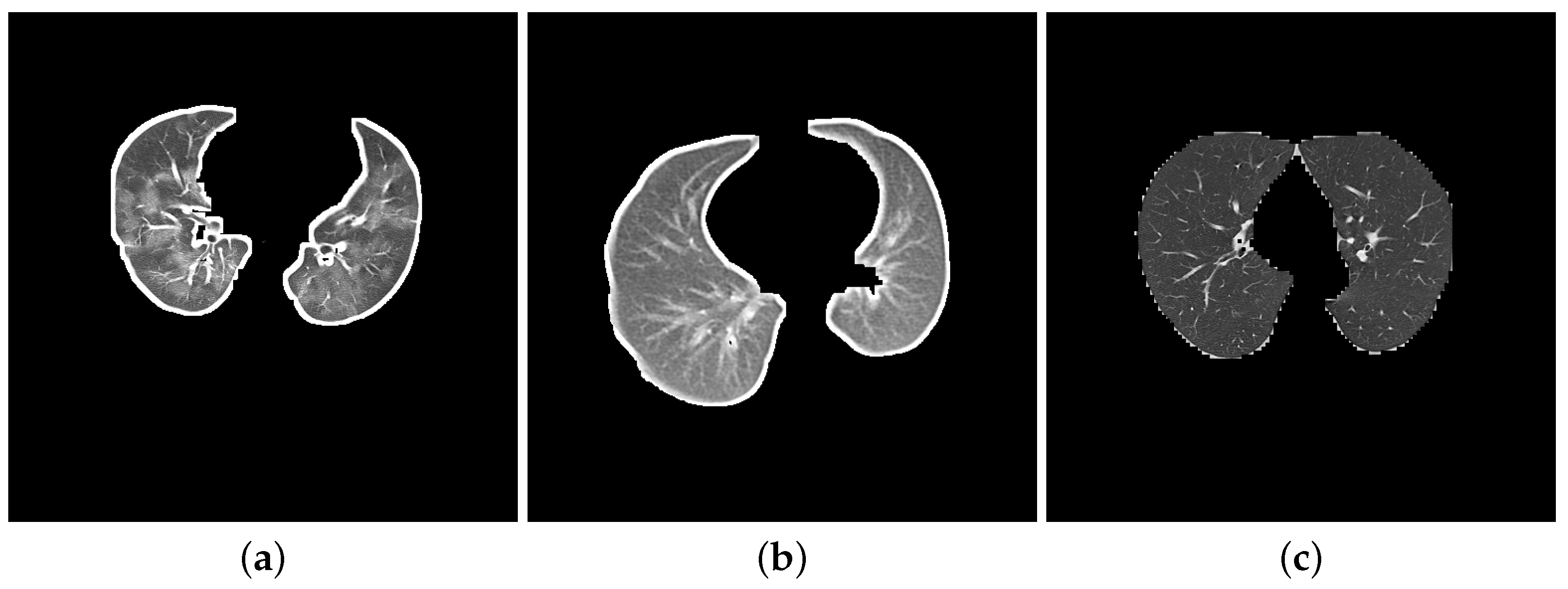
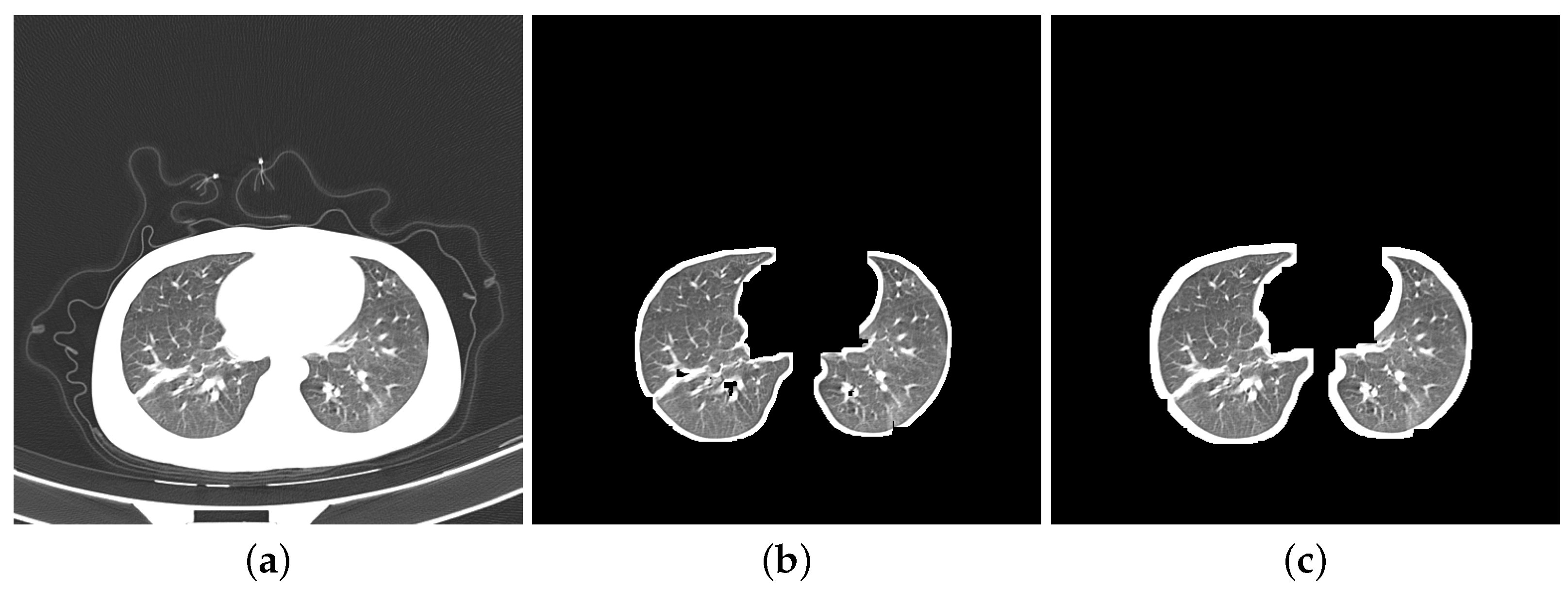
- Segmentation: Segmentation in lung images separates the lung regions from those of the other body parts. More specifically, we segmented DatasetA by using K-Means method to separate lung images from CT slices and eliminate the white background. While the reference paper [20] employed ten dilation kernels, we opted for seven. This choice aimed to achieve a balance between removing the background and preserving the integrity of the lung boundaries. Seven iterations were found to be sufficient for filling small holes within the lungs while minimizing the thickening of the boundaries compared to ten iterations. We did not apply any segmentation to DatasetB as it contains a combination of segmented images from the Clean-CC-CCII dataset and our segmented slices from DatasetA. Figure 2 shows three slices: Figure 2a is from the unsegmented Clean-CC-CCII dataset, Figure 2b is from DatasetA after applying the segmentation using K-Means with seven dilation kernels, and Figure 2c is from DatasetB which is already segmented using K-Means with ten dilation kernels.
- Resizing: The Clean-CC-CCII dataset has an image resolution of 512 × 512 pixels, which are resized to 224 × 224 pixels to be more suitable for our study. This size (224 × 224 pixels) was found in our experiments to be more efficient for running the CapsNet classification model on the Clean-CC-CCII dataset and produced better results compared to other tested image resolutions.
- Augmentation: Data augmentation artificially generates new data from existing sets to train ML models, consequently improving the model’s performance and generalization ability [44]. Hinton—the CapsNet developer—augmented the MNIST dataset that was used to build the original CapsNet by shifting the data up to two pixels in each direction [18]. In this study, we shifted the CT images by only 0.05 pixels in each direction since lung images have more critical and sensitive features than digit images in the MNIST dataset.
3.3. Model Architecture and Hyperparameters Tuning
- Input Image Size: The digit image size in the original CapsNet was 28 × 28, which has to be enlarged for CT images as they contain more critical information than digit images. The image size has been increased to 224 × 224 to extract more relevant features.
- Conv1 Layer: The number of Conv1 layer strides has been increased from one to two; this makes the filter move two pixels right for each horizontal movement of the filter and two pixels down for each vertical movement when creating the feature map. Also, the padding of the Conv1 layer has been changed to “SAME” rather than “VALID”; “SAME” makes the output size equivalent to the input size.
- PrimaryCapsules layer: The number of capsule channels in the PrimaryCapsules layer has been reduced from 32 to 16.
- Label Capsule: The original CapsNet worked on ten-digit images from the MNIST dataset, which must be adjusted for the problem at hand. Thus, the number of capsules in this layer has been changed to three: NCP, CP diseases and normal control.
- Reconstruction Network: This is an important part of the original CapsNet architecture and is also called the decoder. It regenerates the images from the features of the Label Capsule layer. It learns—with a learning rate (LR) equal to 0.0003—to reconstruct the input image with the minimal SSE (sum squared error) in the case of the original CapsNet, while MSE (mean squared error) was used in the 3Cs model architecture. The reconstruction loss is calculated as indicated in Equation (1). The total loss of the training process is then calculated as a weighted combination of margin and reconstruction losses, as seen in Equation (2).
4. Experiments and Results
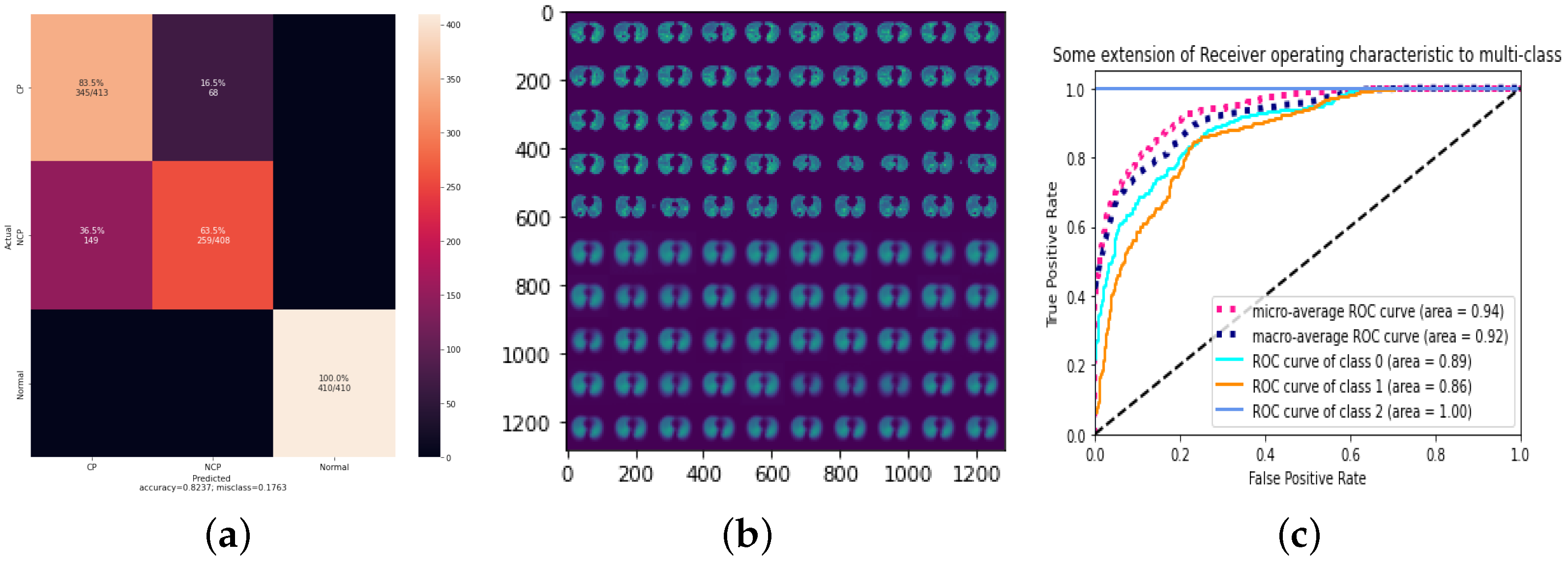
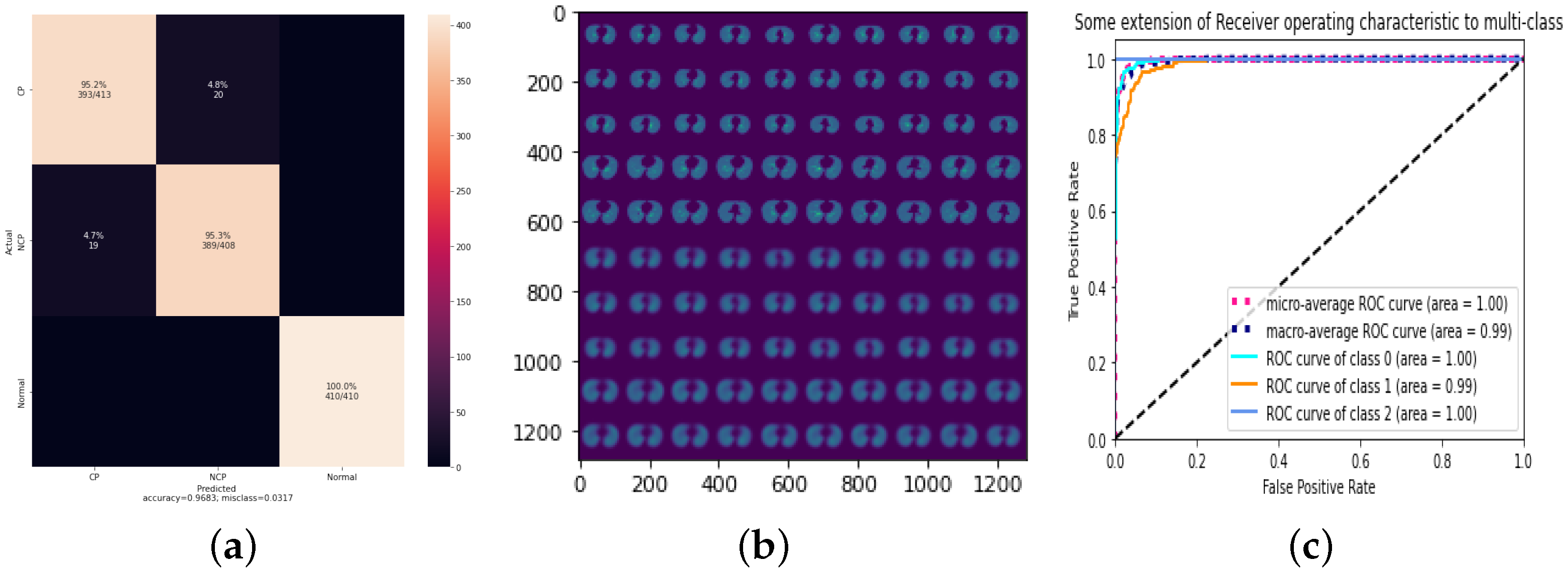
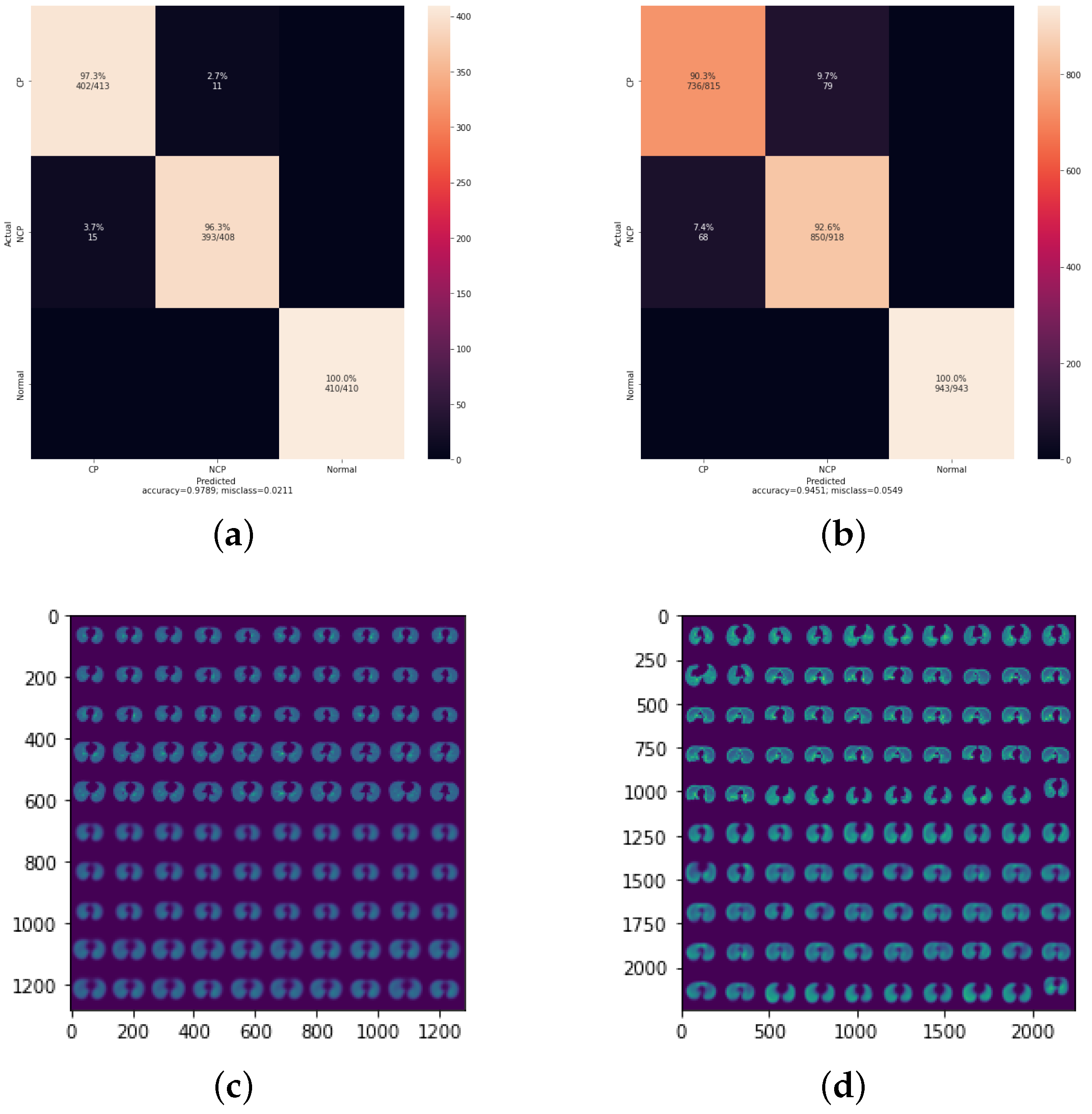
4.1. Result of 3Cs through the Standard CapsNet
4.2. Result of 3Cs with Augmentation Optimization
4.3. Result of 3Cs with Hyperparameter Optimization
5. Discussion and Conclusions
- Exploration of Additional Data Augmentation Techniques: Future studies could explore other data augmentation methods, such as rotation, scaling and flipping, to assess their impact on model performance and robustness.
- Incorporation of Advanced Capsule Network Architectures: Investigating advanced capsule network architectures, such as dynamic routing by agreement and attention-based capsule networks, could potentially improve the model’s ability to capture spatial hierarchies and complex patterns in CT images.
- Expansion to Multi-modal Data: Integrating multi-modal data, such as combining CT images with clinical data and other imaging modalities (e.g., X-rays), could enhance the model’s diagnostic accuracy and provide a more comprehensive assessment of the patient’s condition.
- Real-world Clinical Validation: Conducting real-world clinical trials and validation studies to evaluate the model’s performance in diverse and larger patient populations would be essential to establish its efficacy and reliability in clinical settings.
- Transfer Learning and Domain Adaptation: Employing transfer learning techniques to adapt the model to different imaging devices, protocols and other respiratory diseases could make the model more versatile and widely applicable.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DL | Deep Learning |
| CT | Computed Tomography |
| RT–PCR | Reverse Transcription Polymerase Chain Reaction |
| CapsNet | Capsules Neural Network |
| CNN | Convolutional Neural Network |
| NCP | Novel Coronavirus Pneumonia |
| CP | Common Pneumonia |
| GGO | Ground-Glass Opacity |
| DECAPS | DEtail-oriented Capsule Networks |
| ResNet | Residual Neural Network |
| SVM | Support Vector Machine |
| ReLU | Rectified Linear Units |
| SSE | Sum Squared error |
| MSE | Mean Squared error |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| FNR | False-Negative Rate |
| FPR | False Positive Rate |
| LR | Learning Rate |
| ROC | Receiver Operator Characteristic |
| AUC | Area Under the Curve |
References
- World Health Organization. Coronavirus. 2024. Available online: https://www.who.int/health-topics/coronavirus#tab=tab_1 (accessed on 12 June 2024).
- Gorbalenya, A.E.; Baker, S.C.; Baric, R.S.; de Groot, R.J.; Drosten, C.; Gulyaeva, A.A.; Haagmans, B.L.; Lauber, C.; Leontovich, A.M.; Neuman, B.W.; et al. Severe acute respiratory syndrome-related coronavirus: The species and its viruses—A statement of the Coronavirus Study Group. bioRxiv 2020. [Google Scholar] [CrossRef]
- World Health Organization. Laboratory Testing for Coronavirus Disease 2019 (COVID-19) in Suspected Human Cases: Interim Guidance, 2 March 2020. Technical Documents. 2020. Available online: https://iris.who.int/handle/10665/331329 (accessed on 12 June 2024).
- World Health Organization. WHO Director-General’s Opening Remarks at the Media Briefing on COVID-19—11 March 2020. 2020. Available online: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19---11-march-2020 (accessed on 12 June 2024).
- World Health Organization. COVID-19 Dashboard: Deaths. 2024. Available online: https://data.who.int/dashboards/covid19/deaths?n=c (accessed on 12 June 2024).
- World Health Organization. Timeline of WHO’s Response to COVID-19. 2020. Available online: https://www.who.int/news/item/29-06-2020-covidtimeline (accessed on 12 June 2024).
- World Health Organization. Use of Chest Imaging in COVID-19: A Rapid Advice Guide. 2020. Available online: https://iris.who.int/bitstream/handle/10665/332336/WHO-2019-nCoV-Clinical-Radiology_imaging-2020.1-eng.pdf?sequence=1 (accessed on 12 June 2024).
- Shi, H.; Han, X.; Jiang, N.; Cao, Y.; Alwalid, O.; Gu, J.; Fan, Y.; Zheng, C. Radiological findings from 81 patients with COVID-19 pneumonia in Wuhan, China: A descriptive study. Lancet Infect. Dis. 2020, 20, 425–434. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Kang, H.; Liu, X.; Tong, Z. Combination of RT-qPCR testing and clinical features for diagnosis of COVID-19 facilitates management of SARS-CoV-2 outbreak. J. Med. Virol. 2020, 92, 538. [Google Scholar] [CrossRef] [PubMed]
- Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [CrossRef] [PubMed]
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of Chest CT for COVID-19: Comparison to RT-PCR. Radiology 2020, 296, E115–E117. [Google Scholar] [CrossRef] [PubMed]
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Tao, Q.; Sun, Z.; Xia, L. Correlation of Chest CT and RT-PCR Testing for Coronavirus Disease 2019 (COVID-19) in China: A Report of 1014 Cases. Radiology 2020, 296, E32–E40. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Xu, H.; Zhang, N.; Xu, H.; Li, Z.; Chen, H.; Xu, R.; Sun, R.; Wen, L.; Xie, L.; et al. Association between Clinical, Laboratory and CT Characteristics and RT-PCR Results in the Follow-up of COVID-19 patients. medRxiv 2020. [Google Scholar] [CrossRef]
- Alaufi, R.; Kalkatawi, M.; Abukhodair, F. Challenges of deep learning diagnosis for COVID-19 from chest imaging. Multimed. Tools Appl. 2024, 83, 14337–14361. [Google Scholar] [CrossRef]
- Lu, L.; Zheng, Y.; Carneiro, G.; Yang, L. Deep Learning and Convolutional Neural Networks for Medical Image Computing: Precision Medicine, High Performance and Large-Scale Datasets; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Chen Yen-Wei, J.L.C. Deep Learning in Healthcare: Paradigms and Applications; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Cao, J.; Zhao, A.; Zhang, Z. Automatic image annotation method based on a convolutional neural network with threshold optimization. PLoS ONE 2020, 15, e0238956. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing between Capsules. arXiv 2017, arXiv:1710.09829. [Google Scholar]
- Kronenberger, J.; Haselhoff, A. Do Capsule Networks Solve the Problem of Rotation Invariance for Traffic Sign Classification? In Artificial Neural Networks and Machine Learning—ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Proceedings, Part III 27; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Springer: Cham, Switzerland, 2018; pp. 33–40. [Google Scholar]
- He, X.; Wang, S.; Shi, S.; Chu, X.; Tang, J.; Liu, X.; Yan, C.; Zhang, J.; Ding, G. Benchmarking Deep Learning Models and Automated Model Design for COVID-19 Detection with Chest CT Scans. medRxiv 2020. [Google Scholar] [CrossRef]
- Quan, H.; Xu, X.; Zheng, T.; Li, Z.; Zhao, M.; Cui, X. DenseCapsNet: Detection of COVID-19 from X-ray images using a capsule neural network. Comput. Biol. Med. 2021, 133, 104399. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, S.; Jain, A. Convolutional capsule network for COVID-19 detection using radiography images. Int. J. Imaging Syst. Technol. 2021, 31, 525–539. [Google Scholar] [CrossRef]
- Javidi, M.; Abbaasi, S.; Atashi, S.N.; Jampour, M. COVID-19 early detection for imbalanced or low number of data using a regularized cost-sensitive CapsNet. Sci. Rep. 2021, 11, 18478. [Google Scholar] [CrossRef] [PubMed]
- Mobiny, A.; Cicalese, P.A.; Zare, S.; Yuan, P.; Abavisani, M.; Wu, C.C.; Ahuja, J.; de Groot, P.M.; Nguyen, H.V. Radiologist-Level COVID-19 Detection Using CT Scans with Detail-Oriented Capsule Networks. arXiv 2020, arXiv:2004.07407. Available online: https://arxiv.org/abs/2101.07433 (accessed on 12 June 2024).
- Yousra, D.; Abdelhakim, A.B.; Mohamed, B.A. A Novel Model for Detection and Classification Coronavirus (COVID-19) Based on Chest X-ray Images Using CNN-CapsNet. In Sustainable Smart Cities and Territories Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Li, Z.; Xing, Q.; Zhao, J.; Miao, Y.; Zhang, K.; Feng, G.; Qu, F.; Li, Y.; He, W.; Shi, W.; et al. COVID19-ResCapsNet: A Novel Residual Capsule Network for COVID-19 Detection From Chest X-Ray Scans Images. IEEE Access 2023, 11, 52923–52937. [Google Scholar] [CrossRef]
- Praveen. CoronaHack Chest X-ray Dataset. Available online: https://www.kaggle.com/praveengovi/coronahack-chest-xraydataset (accessed on 12 June 2024).
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 Image Data Collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]
- Chowdhury, M.E.H.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al-Emadi, N.; et al. COVID-19 Radiography Database. 2020. Available online: https://kaggle.com/tawsifurrahman/covid19-radiography-database (accessed on 12 June 2024).
- Ning, W.; Lei, S.; Yang, J.; Cao, Y.; Jiang, P.; Yang, Q.; Zhang, J.; Wang, X.; Chen, F.; Geng, Z.e.a. Open resource of clinical data from patients with pneumonia for the prediction of COVID-19 outcomes via deep learning. Nat. Biomed. Eng. 2020, 4, 1197–1207. [Google Scholar] [CrossRef] [PubMed]
- Larxel. COVID-19 X-rays. Available online: https://www.kaggle.com/datasets/andrewmvd/convid19-x-rays (accessed on 12 June 2024).
- Sait, U.; Lal, K.; Prajapati, S.; Bhaumik, R.; Kumar, T.; S, S.; Bhalla, K. Curated Dataset for COVID-19 Posterior-Anterior Chest Radiography Images (X-rays). 2022. Available online: https://data.mendeley.com/datasets/9xkhgts2s6/1 (accessed on 12 June 2024).
- He, X.; Yang, X.; Zhang, S.; Zhao, J.; Zhang, Y.; Xing, E.; Xie, P. Sample-Efficient Deep Learning for COVID-19 Diagnosis Based on CT Scans. medRxiv 2020. [Google Scholar] [CrossRef]
- Afshar, P.; Heidarian, S.; Naderkhani, F.; Oikonomou, A.; Plataniotis, K.N.; Mohammadi, A. COVID-CAPS: A capsule network-based framework for identification of COVID-19 cases from X-ray images. Pattern Recognit. Lett. 2020, 138, 638–643. [Google Scholar] [CrossRef]
- Toraman, S.; Alakus, T.B.; Turkoglu, I. Convolutional capsnet: A novel artificial neural network approach to detect COVID-19 disease from X-ray images using capsule networks. Chaos Solitons Fractals 2020, 140, 110122. [Google Scholar] [CrossRef] [PubMed]
- Aksoy, B.; Salman, O.K.M. Detection of COVID-19 Disease in Chest X-ray Images with capsul networks: Application with cloud computing. J. Exp. Theor. Artif. Intell. 2021, 33, 527–541. [Google Scholar] [CrossRef]
- Akinyelu, A.A.; Bah, B. COVID-19 Diagnosis in Computerized Tomography (CT) and X-ray Scans Using Capsule Neural Network. Diagnostics 2023, 13, 1484. [Google Scholar] [CrossRef] [PubMed]
- Sridhar, S.; Sanagavarapu, S. Multi-Lane Capsule Network Architecture for Detection of COVID-19. In Proceedings of the 2021 2nd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 28–30 April 2021. [Google Scholar] [CrossRef]
- Du, W.; Sun, Y.; Li, G.; Cao, H.; Pang, R.; Li, Y. CapsNet-SSP: Multilane capsule network for predicting human saliva-secretory proteins. Bmc Bioinform. 2020, 21, 237. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wong, A.; Lin, Z.Q.; McInnis, P.; Chung, A.; Gunraj, H.; Lee, J.; Ross, M.; VanBerlo, B.; Ebadi, A.; et al. Figure 1 COVID-19 Chest X-ray Dataset. 2020. Available online: https://github.com/agchung/Figure1-COVID-chestxray-dataset (accessed on 12 June 2024).
- Chowdhury, M.E.H.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Emadi, N.A.E.A. Can AI Help in Screening Viral and COVID-19 Pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- The Wiki-Based Collaborative Radiology Resource. 2019. Available online: https://radiopaedia.org/ (accessed on 12 June 2024).
- Zhang, K.; Liu, X.; Shen, J.; He, J.; Lin, T.; Li, W.; Wang, G. Consortium of Chest CT Image Investigation (CC-CCII) Dataset. Cell 2020, 181, 1423–1433. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Type of Classification | Image Type | Pre-Trained CNN | COVID-19 Dataset | Segmentation | Augmentation | F1-Score | Accuracy | Recall | Precision | Specificity |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [21] | Binary | X-ray | DenseNet | [27,28,29] | Yes | Yes | - | 98.5% | 97% | - | 100% |
| [21] | Multi | X-ray | DenseNet | [27,28,29] | Yes | Yes | 90.90% | 90.7% | 90.7% | 91.1% | 95.3% |
| [23] | Binary | CT | DenseNet | [30] | Yes | No | 91.86% | 92.49% | 92.3% | 91.67% | 92.66% |
| [22] | Binary | X-ray | VGG16 | [31] | No | No | 97% | 97% | 97% | 97% | - |
| [22] | Multi | X-ray | VGG16 | [31] | No | No | 91.7% | 92% | 92% | 91.7% | - |
| [25] | Multi | X-ray | VGG16 | [29,32] | No | Yes | 94% | 94% | 93% | 95% | - |
| [24] | Binary | CT | ResNet | [33] | No | Yes | 87.1% | 87.6% | 91.5% | 84.3% | 85.2% |
| [26] | Binary | X-ray | ResNet | [28] | No | No | 99.8% | 99.88% | 99.61% | 100% | 100% |
| [26] | Binary | X-ray | ResNet | - | No | No | 99.33% | 99.33% | 98.67% | 100% | 100% |
| Ref. | Type of Classification | Image Type | COVID-19 Dataset | Segmentation | Augmentation | F1-Score | Accuracy | Recall | Precision | Specificity |
|---|---|---|---|---|---|---|---|---|---|---|
| [34] | Binary | X-ray | [28] | No | - | 98.30% | 80% | - | 98.60% | |
| [35] | Binary | X-ray | [28] | Yes | 97.20% | 97.24 | 97.40% | 97.10% | 97.00% | |
| [35] | Multi | X-ray | [28] | No | Yes | 84.20% | 89.20% | 84% | 84.60% | 92% |
| [36] | Binary | X-ray | [28,40,41] | No | - | 98.02% | 96% | - | 100% | |
| [38] | Binary | X-ray | [42] | Yes | 97.19% | 96.8% | - | - | - | |
| [37] | Binary | CT | Sample of 7 datasets | No | 99.93% | 99.32% | 100% | 99.89% | - | |
| [37] | Multi | X-ray | [29] | No | 93.39% | 94.72% | 92.95% | 93.86% | - |
| Class | Count | Percentage |
|---|---|---|
| NCP | 2032 | 33.3% |
| CP | 2033 | 33.2% |
| Normal | 2039 | 33.5% |
| % of Dataset | NCP | CP | Normal | |
|---|---|---|---|---|
| Train | 64% | 33.3% | 33.2% | 33.5% |
| Val | 16% | 33.3% | 33.3% | 33.3% |
| Test | 20% | 33.1% | 33.6% | 33.3% |
| Class | Count | Percentage |
|---|---|---|
| NCP | 4581 | 33% |
| CP | 4310 | 31% |
| Normal | 4983 | 36% |
| % of Dataset | NCP | CP | Normal | |
|---|---|---|---|---|
| Train | 65% | 33% | 31.4% | 35.5% |
| Val | 16% | 31.3% | 30.3% | 38.4% |
| Test | 19% | 34.3% | 30.5% | 35.2% |
| LR | Accuracy | Precision | Recall | F1-Score | AUC | FNR |
|---|---|---|---|---|---|---|
| 0.0001 | 78% | 78.67% | 78% | 77.67% | 0.91 | 21.89% |
| 0.0003 | 74% | 75% | 74.33% | 87.33% | 0.91 | 25.68% |
| 0.00005 | 82% | 83% | 82.33% | 82% | 0.92 | 18% |
| LR | Accuracy | Precision | Recall | F1-Score | AUC | FNR |
|---|---|---|---|---|---|---|
| 0.0001 | 96.75% | 96.67% | 96.67% | 96.67% | 0.99 | 3.26% |
| 0.0003 | 96.34% | 96.33% | 96.33% | 96.33% | 0.99 | 3.66% |
| 0.00005 | 96.59% | 96.67% | 96.67% | 96.67% | 0.99 | 3.42% |
| LR | Accuracy | Precision | Recall | F1-Score | AUC | FNR |
|---|---|---|---|---|---|---|
| 0.0001 | 96.83% | 97% | 97% | 96.67% | 99.57% | 3.17% |
| 0.0003 | 96.83% | 96.67% | 96.67% | 96.67% | 99.46% | 2.81% |
| 0.00005 | 92.61% | 93.33% | 92.67% | 96% | 99.33% | 7.42% |
| LR | Accuracy | Precision | Recall | F1-Score | AUC | FNR |
|---|---|---|---|---|---|---|
| 0.0001 | 94.07% | 96.67% | 96.67% | 96.67% | 0.99 | 2.8% |
| 0.0003 DatasetA | 97.89% | 97.67% | 97.8% | 98.62% | 0.99 | 2.11% |
| 0.0003 DatasetB | 94.51% | 94.35% | 94.33% | 94.33% | 0.99 | 5.7% |
| 0.00005 | 90.41% | 97% | 97% | 96.67% | 0.99 | 3.17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alaufi, R.; Abukhodair, F.; Kalkatawi, M. 3Cs: Unleashing Capsule Networks for Robust COVID-19 Detection Using CT Images. COVID 2024, 4, 1113-1127. https://doi.org/10.3390/covid4080077
Alaufi R, Abukhodair F, Kalkatawi M. 3Cs: Unleashing Capsule Networks for Robust COVID-19 Detection Using CT Images. COVID. 2024; 4(8):1113-1127. https://doi.org/10.3390/covid4080077
Chicago/Turabian StyleAlaufi, Rawan, Felwa Abukhodair, and Manal Kalkatawi. 2024. "3Cs: Unleashing Capsule Networks for Robust COVID-19 Detection Using CT Images" COVID 4, no. 8: 1113-1127. https://doi.org/10.3390/covid4080077
APA StyleAlaufi, R., Abukhodair, F., & Kalkatawi, M. (2024). 3Cs: Unleashing Capsule Networks for Robust COVID-19 Detection Using CT Images. COVID, 4(8), 1113-1127. https://doi.org/10.3390/covid4080077