
An Energy-Optimized Artificial Intelligence of Things (AIoT)-Based Biosensor Networking for Predicting COVID-19 Outbreaks in Healthcare Systems

Abstract
1. Introduction
2. Research Significance
3. Literature Review
4. Methodology
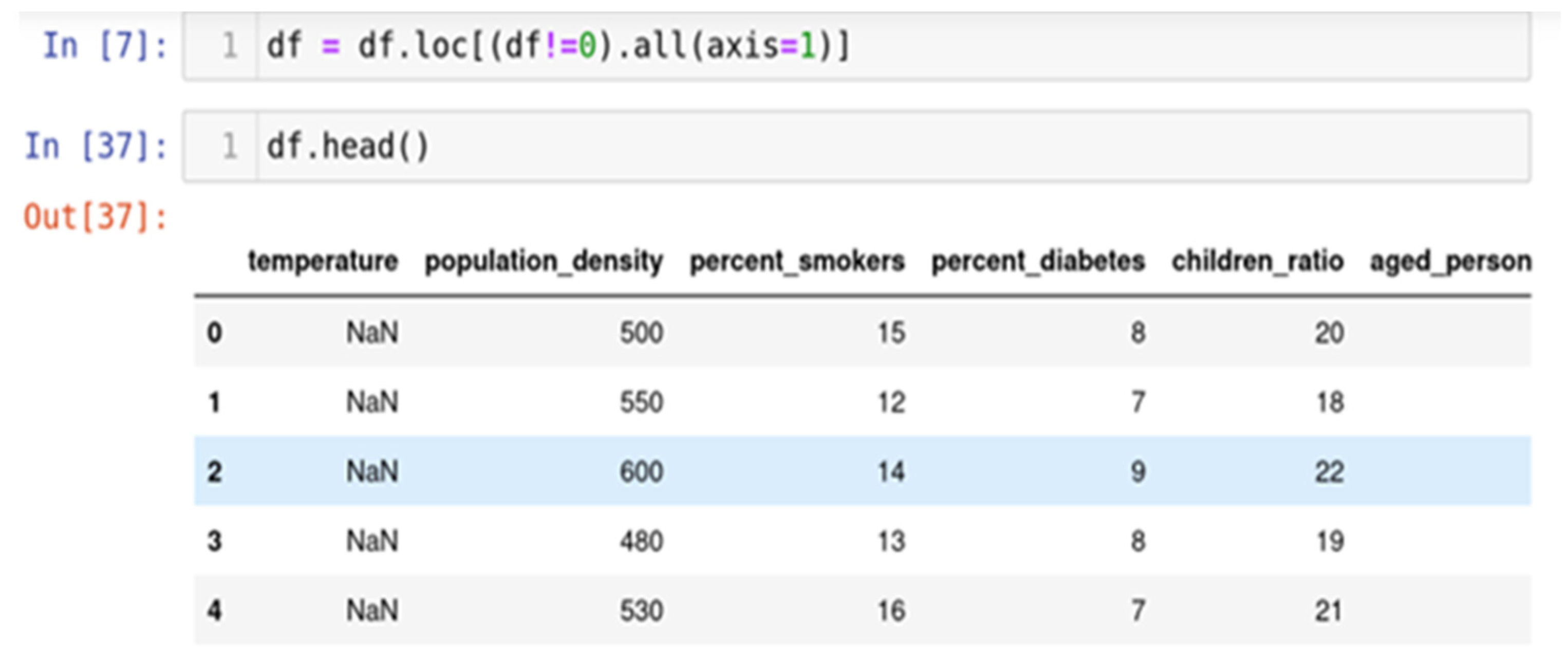
4.1. Data Cleaning
4.1.1. Remove Duplicate or Irrelevant Observations
4.1.2. Fix Structural Errors
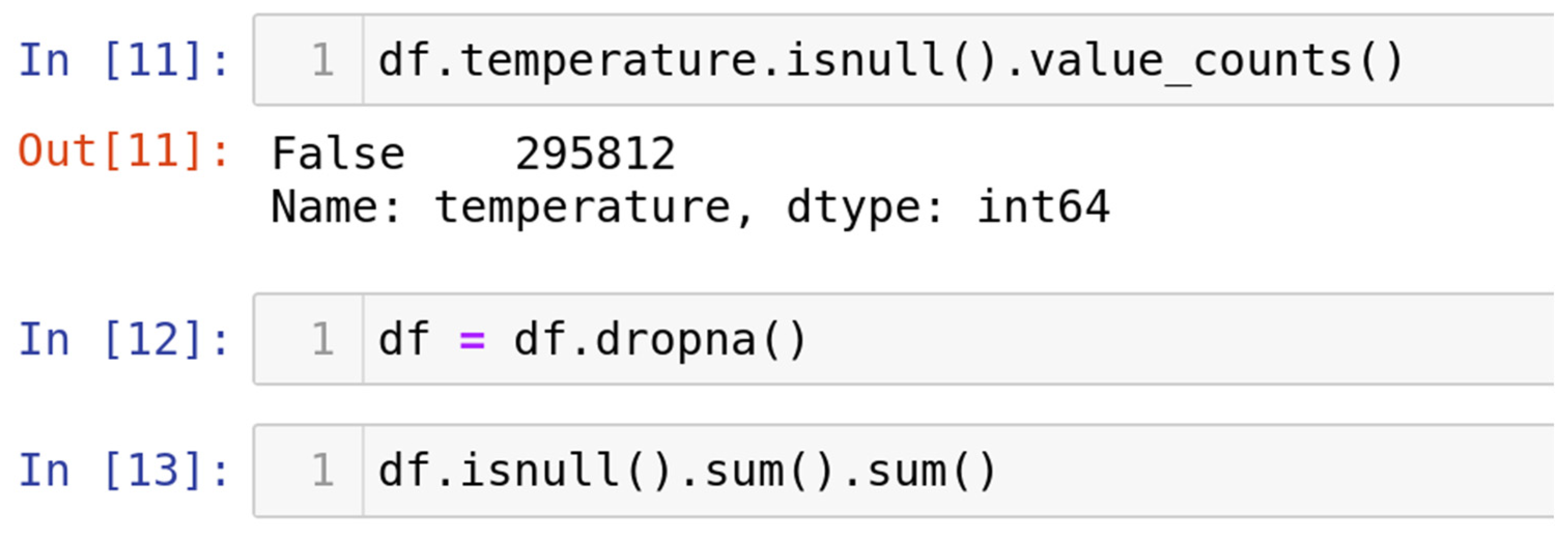
4.1.3. Handle Missing Data
4.1.4. Replacing with Mean/Median/Mode
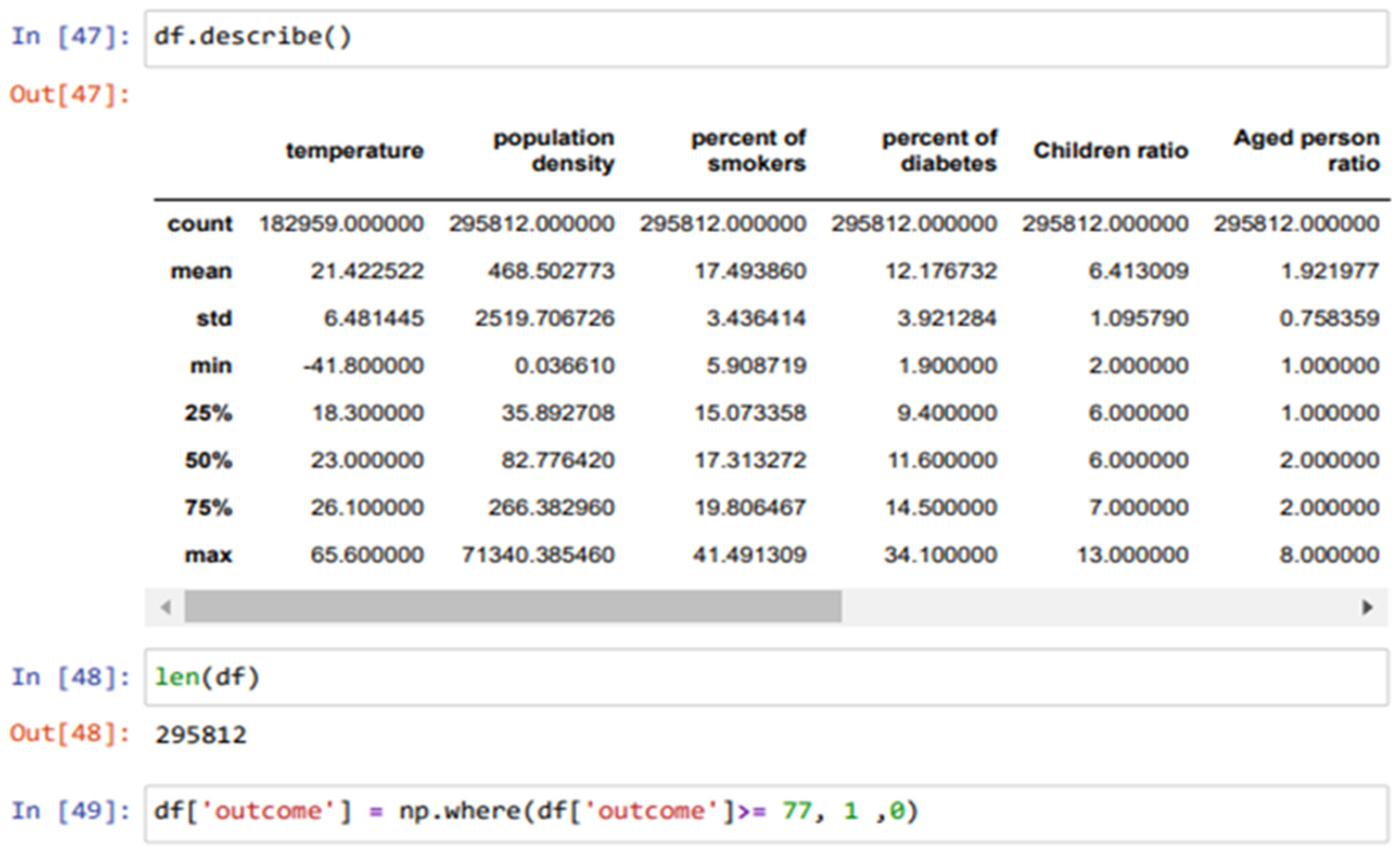
4.2. Data Scaling and Normalization
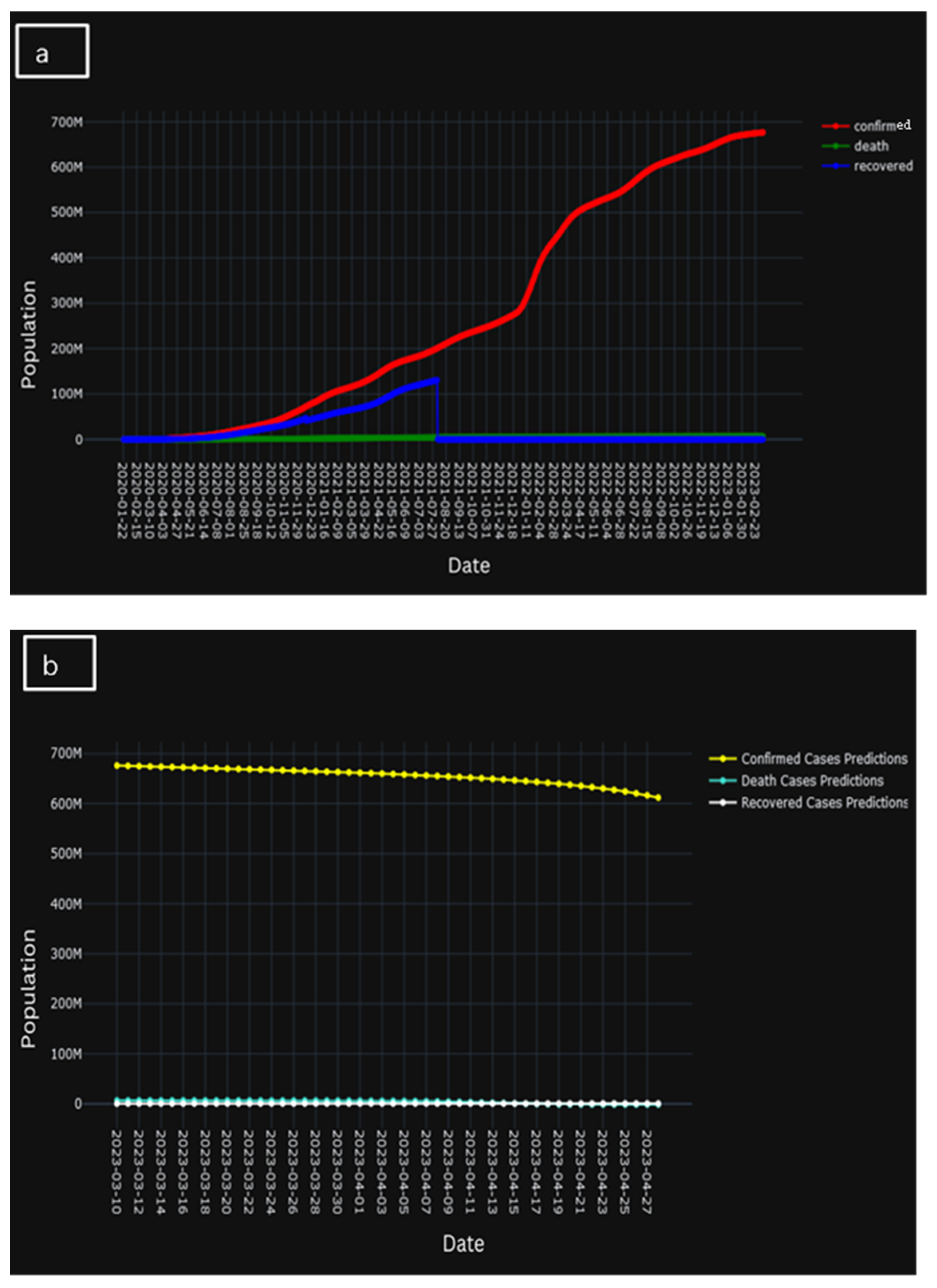
5. Result and Discussion
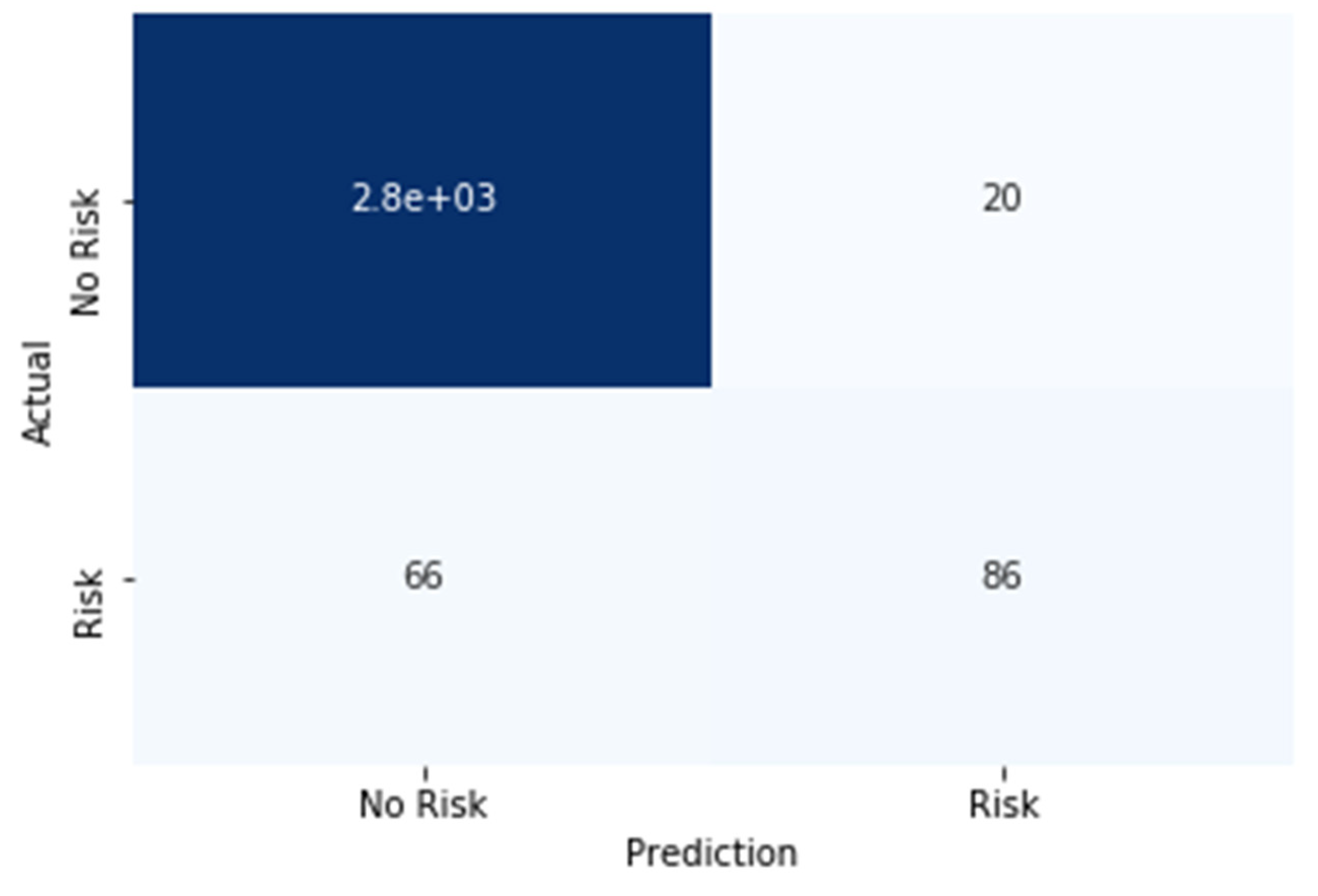
Performance Evaluation
- True Positive (TP): The model correctly identifies 86 instances of positive cases of COVID-19.
- False Positive (FP): The model erroneously predicts 20 instances as positive cases of COVID-19, which is harmful.
- True Negative (TN): Demonstrating exceptional accuracy, the model correctly identifies 2.8 and 103 instances of negative cases of COVID-19 observed.
- False Negative (FN): The model mistakenly classifies 66 instances as negative cases of COVID-19, when they are, in fact, positive.
- Accuracy: Defined as the proportion of correct predictions out of the total predictions made by the model. The accuracy of the proposed model is computed as (TP + TN)/(TP + FP + TN + FN), yielding an impressive value of 0.96 or 96%.
- Precision: An indicator of the model’s capability to accurately identify positive samples among all samples predicted as positive. The precision of the proposed model is calculated as TP/(TP + FP), presenting a noteworthy value of 0.97 or 97%.
- Recall: Also referred to as sensitivity or actual positive rate, this metric signifies the proportion of actual positive samples the model correctly identifies. The recall of the proposed model is computed as TP/(TP + FN), amounting to 0.81 or 81%.
- F1 Score: Representing a harmonious amalgamation of precision and recall, the F1 score provides a balanced assessment of the model’s performance. It is calculated as 2 × (Precision × Recall)/(Precision + Recall), resulting in a significant value of 0.88 or 88%.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, S.; Tiwari, P.; Zymbler, M. Internet of Things is a revolutionary approach for future technology enhancement: A review. J. Big Data 2019, 6, 111. [Google Scholar] [CrossRef]
- Saleem, T.J.; Chishti, M.A. Data analytics in the internet of things: A survey. Scalable Comput. Pract. Exp. 2019, 20, 607–629. [Google Scholar] [CrossRef]
- Noura, M.; Atiquzzaman, M.; Gaedke, M. Interoperability in Internet of Things: Taxonomies and Open Challenges. Mob. Netw. Appl. 2019, 24, 796–809. [Google Scholar] [CrossRef]
- Adnan, A.; Razzaque, M.A.; Ahmed, I.; Isnin, I.F. Bio-Mimic Optimization Strategies in Wireless Sensor Networks: A Survey. Sensors 2013, 14, 299–345. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Malik, A.; Kumar, R. Energy efficient heterogeneous DEEC protocol for enhancing lifetime in WSNs. Eng. Sci. Technol. Int. J. 2017, 20, 345–353. [Google Scholar] [CrossRef]
- Singh, S. A sustainable data gathering technique based on nature inspired optimization in WSNs. Sustain. Comput. Inform. Syst. 2019, 24, 100354. [Google Scholar] [CrossRef]
- Ramteke, R.; Singh, S.; Malik, A. Optimized routing technique for IoT enabled software-defined heterogeneous WSNs using genetic mutation based PSO. Comput. Stand. Interfaces 2022, 79, 103548. [Google Scholar] [CrossRef]
- Qing, L.; Zhu, Q.; Wang, M. Design of a distributed energy-efficient clustering algorithm for heterogeneous wireless sensor networks. Comput. Commun. 2006, 29, 2230–2237. [Google Scholar] [CrossRef]
- Singh, S. An energy aware clustering and data gathering technique based on nature inspired optimization in WSNs. Peer Netw. Appl. 2020, 13, 1357–1374. [Google Scholar] [CrossRef]
- Heinzelman, W.; Chandrakasan, A.; Balakrishnan, H. Energy-efficient communication protocol for wireless microsensor networks. In Proceedings of the Hawaii International Conference on System Sciences, Maui, HI, USA, 7 January 2002; p. 8020. [Google Scholar]
- Heinzelman, W.; Chandrakasan, A.; Balakrishnan, H. An application-specific protocol architecture for wireless microsensor networks. IEEE Trans. Wirel. Commun. 2002, 1, 660–670. [Google Scholar] [CrossRef]
- Mhatre, V.; Rosenberg, C. Design guidelines for wireless sensor networks: Communication, clustering and aggregation. Ad Hoc Netw. 2004, 2, 45–63. [Google Scholar] [CrossRef]
- Younis, O.; Fahmy, S. HEED: A hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Trans. Mob. Comput. 2004, 3, 366–379. [Google Scholar] [CrossRef]
- Khan, M.K.; Shiraz, M.; Shaheen, Q.; Butt, S.A.; Akhtar, R.; Khan, M.A.; Changda, W. Hierarchical routing protocols for wireless sensor networks: Functional and performance analysis. J. Sens. 2021, 2021, 7459368. [Google Scholar] [CrossRef]
- Jin, R.; Fan, X.; Sun, T. Centralized Multi-Hop Routing Based on Multi-Start Minimum Spanning Forest Algorithm in the Wireless Sensor Networks. Sensors 2021, 21, 1775. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Wang, Q.; Lin, D.; Deng, Y. An Energy-Efficient Clustering Routing Protocol Based on Evolutionary Game Theory in Wireless Sensor Networks. Int. J. Distrib. Sens. Netw. 2015, 11, 409503. [Google Scholar] [CrossRef]
- Nguyen, N.-T.; Le, T.T.; Nguyen, H.-H.; Voznak, M. Energy-Efficient Clustering Multi-Hop Routing Protocol in a UWSN. Sensors 2021, 21, 627. [Google Scholar] [CrossRef] [PubMed]
- Lalwani, P.; Das, S. Bacterial Foraging Optimization Algorithm for CH selection and routing in wireless sensor networks. In Proceedings of the 2016 3rd International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 3–5 March 2016; pp. 95–100. [Google Scholar]
- Rajabi, M.; Hossani, S.; Dehghani, F. A literature review on current approaches and applications of fuzzy expert systems. arXiv 2019, arXiv:1909.08794. [Google Scholar]
- Gupta, I.; Riordan, D.; Sampalli, S. Cluster-Head Election Using Fuzzy Logic for Wireless Sensor Networks. In Proceedings of the 3rd Annual Communication Networks and Services Research Conference (CNSR’05), Halifax, NS, Canada, 16–18 May 2005; pp. 255–260. [Google Scholar]
- Kim, J.-M.; Park, S.-H.; Han, Y.-J.; Chung, T.-M. CHEF: Cluster Head Election mechanism using Fuzzy logic in Wireless Sensor Networks. In Proceedings of the 2008 10th International Conference on Advanced Communication Technology, Phoenix Park, Republic of Korea, 17–20 February 2008; Volume 1, pp. 654–659. [Google Scholar] [CrossRef]
- Mao, S.; Zhao, C.-L. Unequal clustering algorithm for WSN based on fuzzy logic and improved ACO. J. China Univ. Posts Telecommun. 2011, 18, 89–97. [Google Scholar] [CrossRef]
- Xie, W.-X.; Zhang, Q.-Y.; Sun, Z.-M.; Zhang, F. A Clustering Routing Protocol for WSN Based on Type-2 Fuzzy Logic and Ant Colony Optimization. Wirel. Pers. Commun. 2015, 84, 1165–1196. [Google Scholar] [CrossRef]
- Baranidharan, B.; Santhi, B. DUCF: Distributed load balancing Unequal Clustering in wireless sensor networks using Fuzzy approach. Appl. Soft Comput. 2016, 40, 495–506. [Google Scholar] [CrossRef]
- Singh, D.; Kumar, B.; Singh, S.; Chand, S. A secure IoT-based mutual authentication for healthcare applications in wireless sensor networks using ECC. Int. J. Healthc. Inf. Syst. Inform. 2021, 16, 21–48. [Google Scholar] [CrossRef]
- Gupta, P.; Tripathi, S.; Singh, S. Energy efficient rendezvous points based routing technique using multiple mobile sink in heterogeneous wireless sensor networks. Wirel. Netw. 2021, 27, 3733–3746. [Google Scholar] [CrossRef]
- Singh, S.; Nandan, A.S.; Malik, A.; Kumar, N.; Barnawi, A. An Energy-Efficient Modified Metaheuristic Inspired Algorithm for Disaster Management System Using WSNs. IEEE Sens. J. 2021, 21, 15398–15408. [Google Scholar] [CrossRef]
- Nandan, A.S.; Singh, S.; Awasthi, L.K. An efficient cluster head election based on optimized genetic algorithm for movable sinks in IoT enabled HWSNs. Appl. Soft Comput. 2021, 107, 107318. [Google Scholar] [CrossRef]
- Chand, S.; Singh, S.; Kumar, B. Heterogeneous HEED Protocol for Wireless Sensor Networks. Wirel. Pers. Commun. 2014, 77, 2117–2139. [Google Scholar] [CrossRef]
- Dwivedi, A.K.; Sharma, A.K. EE-LEACH: Energy Enhancement in LEACH using Fuzzy Logic for Homogeneous WSN. Wirel. Pers. Commun. 2021, 120, 3035–3055. [Google Scholar] [CrossRef]
- Vijayashree, R.; Dhas, C.S.G. Energy efficient data collection with multiple mobile sink using artificial bee colony algorithm in large-scale WSN. Automatika 2019, 60, 555–563. [Google Scholar] [CrossRef]
- Manju; Singh, S.; Kumar, S.; Nayyar, A.; Al-Turjman, F.; Mostarda, L. Proficient QoS-Based Target Coverage Problem in Wireless Sensor Networks. IEEE Access 2020, 8, 74315–74325. [Google Scholar] [CrossRef]
- Xu, K. Silicon electro-optic micro-modulator fabricated in standard CMOS technology as components for all silicon monolithic integrated optoelectronic systems. J. Micromechanics Microengineering 2021, 31, 054001. [Google Scholar] [CrossRef]
- Bos, G. ISO 13485:2003/2016—Medical Devices—Quality Management Systems—Requirements for Regulatory Purposes. In Handbook of Medical Device Regulatory Affairs in Asia; CRC Press: Boca Raton, FL, USA, 2018; pp. 153–174. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Training accuracy | 96% |
| F1 score | 88% |
| Precision | 97% |
| Recall | 81% |
| Parameter | Best Value | Highest Accuracy |
|---|---|---|
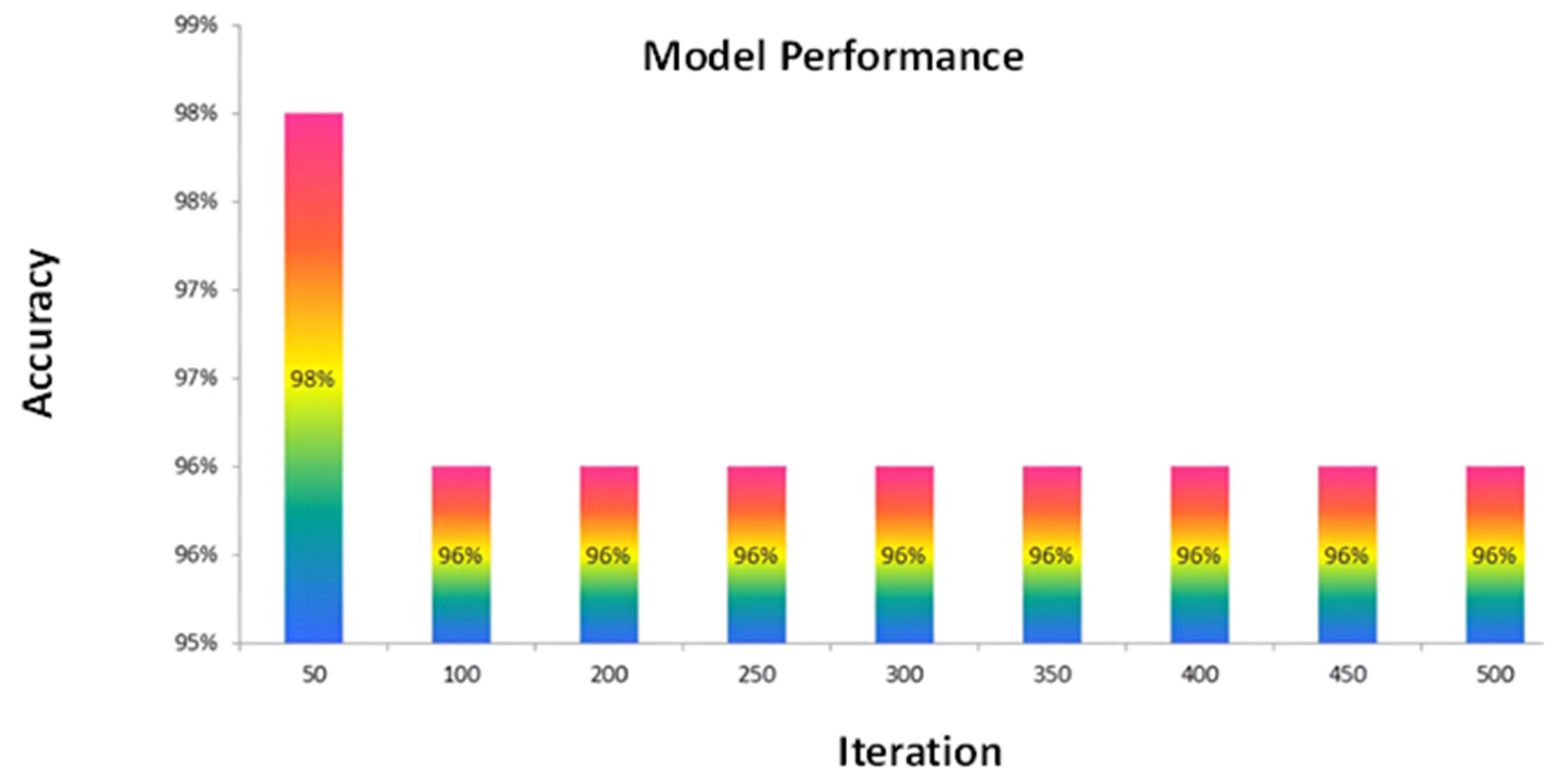
| Learning rate | 50 | 97% |
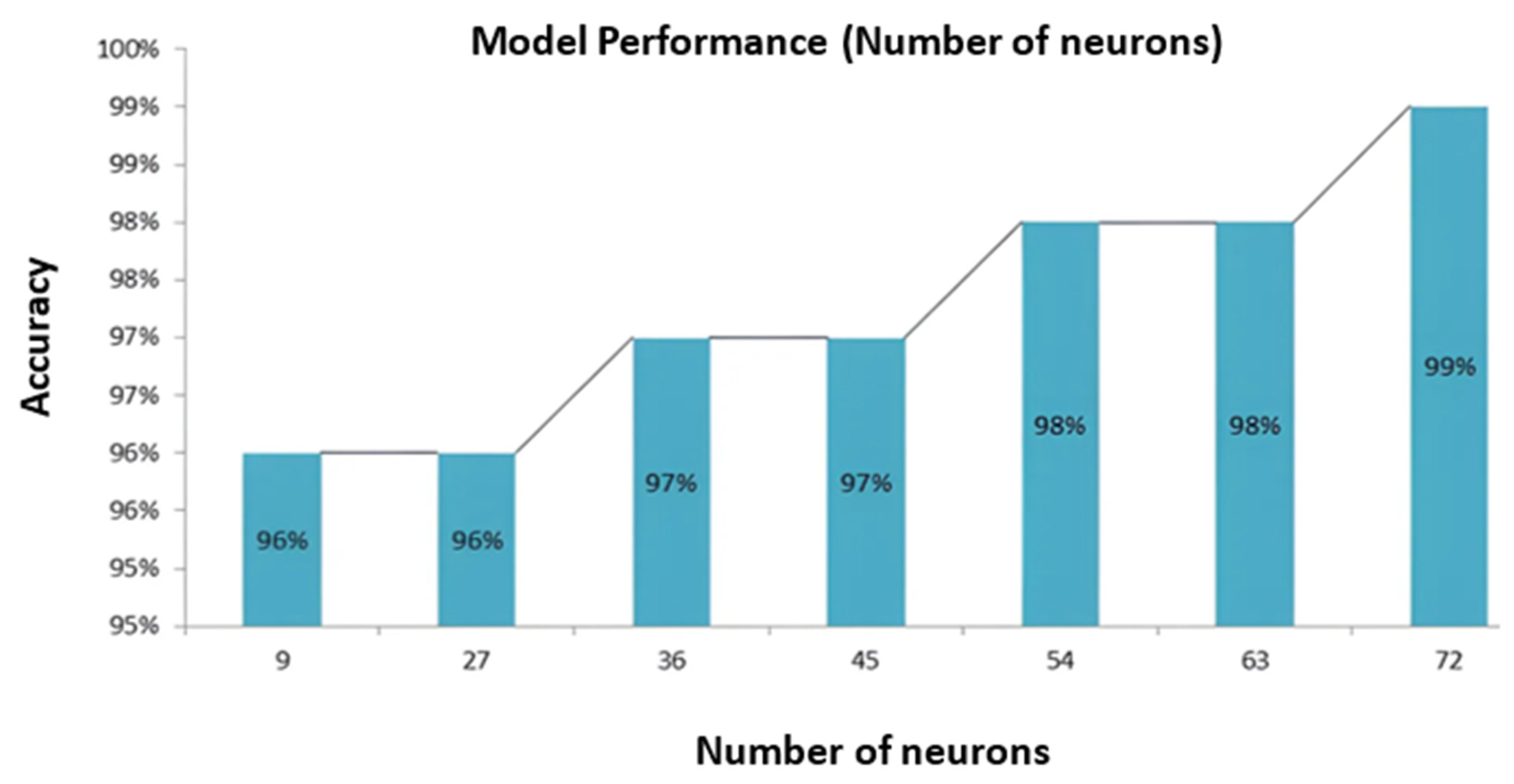
| Total number of neurons | 72 | 99% |
| Total number of features | 7 | 97% |
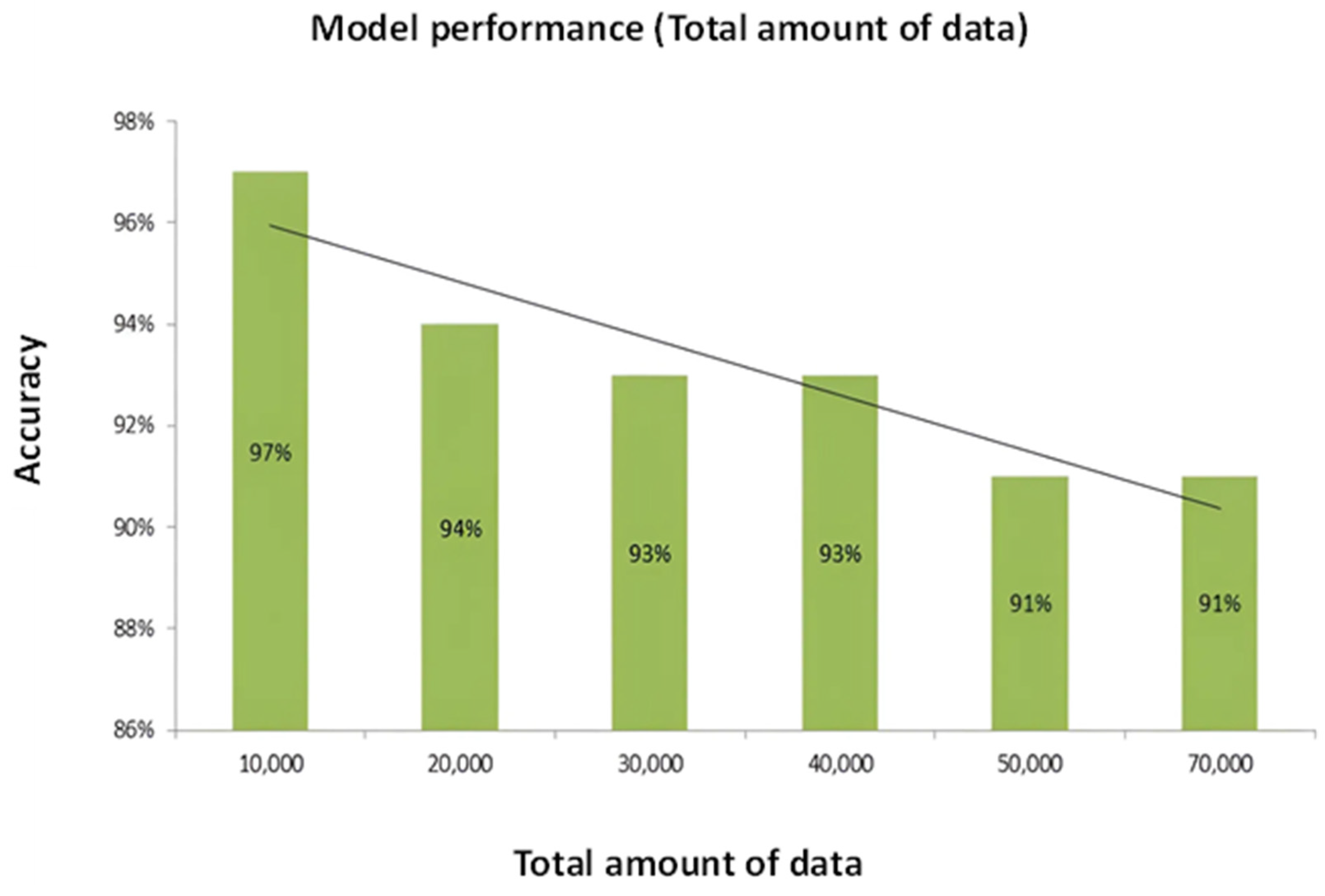
| Total amount of data | 10,000 | 97% |
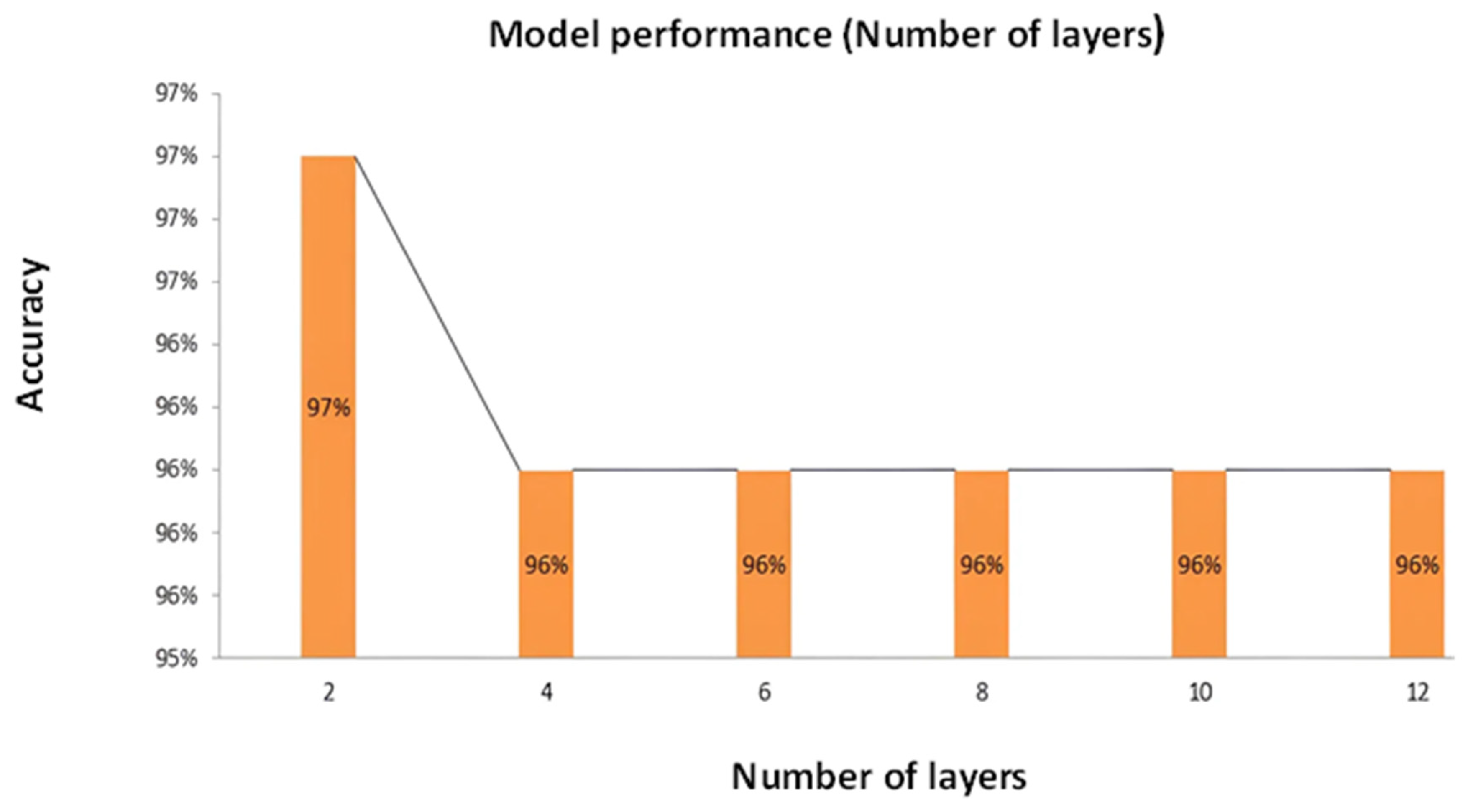
| Total number of layers | 2 | 97% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pahuja, M.; Kumar, D. An Energy-Optimized Artificial Intelligence of Things (AIoT)-Based Biosensor Networking for Predicting COVID-19 Outbreaks in Healthcare Systems. COVID 2024, 4, 696-714. https://doi.org/10.3390/covid4060047
Pahuja M, Kumar D. An Energy-Optimized Artificial Intelligence of Things (AIoT)-Based Biosensor Networking for Predicting COVID-19 Outbreaks in Healthcare Systems. COVID. 2024; 4(6):696-714. https://doi.org/10.3390/covid4060047
Chicago/Turabian StylePahuja, Monika, and Dinesh Kumar. 2024. "An Energy-Optimized Artificial Intelligence of Things (AIoT)-Based Biosensor Networking for Predicting COVID-19 Outbreaks in Healthcare Systems" COVID 4, no. 6: 696-714. https://doi.org/10.3390/covid4060047
APA StylePahuja, M., & Kumar, D. (2024). An Energy-Optimized Artificial Intelligence of Things (AIoT)-Based Biosensor Networking for Predicting COVID-19 Outbreaks in Healthcare Systems. COVID, 4(6), 696-714. https://doi.org/10.3390/covid4060047