1. Introduction
In modern vehicle and powertrain design, climate protection and emission reduction are high priorities [
1]. The trend and direction of vehicle development are influenced by a reduction in energy and fuel consumption, as well as the optimization of the overall system with the aim of producing zero-impact emission vehicles [
2,
3]. Furthermore, legislation continues to drive this change by adjusting emission regulations [
4,
5].
With the central component of the EU6d legislation [
6], automobile testing under real driving conditions is mandated for the first time. The EU6d standards limit the test scenarios with regard to acceleration intensities, route characteristics, and environmental factors such as temperature and altitude. However, the potential scenarios for real driving emissions (RDE) generate an almost infinite range of testable space that must be taken into account, tested, and validated. The current planning for EU7 legislation [
7] suggests that there will be further expansion [
8]. With a heightened emphasis on real-world testing and the potential elimination of limitations on the dynamics criteria, the testing area may expand even further, thus presenting greater challenges to available testing resources.
With the increasing complexity resulting from the electrification and hybridization of vehicles, the importance of testing and analyzing measurement data using suitable methods is increasing. The rise in the number of components, such as electric machines and high-voltage batteries, introduces additional interdependencies into test matrices. When assessing the robustness and quality of the complete powertrain, it is essential to consider all possible worst-case scenario combinations. Novel techniques are necessary to reduce the number of required tests and ensure the quality and statistical robustness of the calibrations. Thus, this paper proposes a method to improve the data analysis and statistical evaluation of vehicle calibration. To facilitate its application in emission calibration, this approach clusters critical events based on signal traces. A single signal is utilized solely for clustering in this demonstration, while, in general, the approach could be extended to consider a multitude of signals to describe the present data on a more detailed level.
The presentation begins with a discussion of the current state-of-the-art methods in the calibration process to justify the necessity for a novel approach to data analysis. This is followed by a brief overview of the overall methodology. Subsequently, the utilized data source and fundamental steps of the clustering procedure are presented. The impact of dynamic time warping on the present data is first discussed in the results section. Next, the HDBSCAN (Hierarchical Density-based Spatial Clustering of Applications with Noise) algorithm results regarding emission event traces are presented in two parts. Initially, a section of the data is manually transferred into reference clusters, and the HDBSCAN outcomes are compared in terms of the Adjusted Rand Index () for various signals. Following, the HDBSCAN is applied to the complete set of events using only the engine speed signal. Finally, this paper examines the utility of clustering for vehicle calibration purposes using the presented results as an example.
State-of-the-Art—Novel Methods for Vehicle Calibration
Addressing the challenges posed by system complexity and test condition boundaries can be achieved with modifications to the testing facility or test scenario generation methods. Enhanced test facilities can increase the speed of required tests and improve test-to-test reproducibility, while innovative methods for test scenario generation can reduce the overall number of necessary tests by focusing on vehicle-specific relevant aspects. Therefore, this excerpt of the state-of-the-art focuses on advanced testing facilities and the methods used for data evaluation and test scenario generation. While current research emphasizes improving test bed facilities, limited research has been published regarding dedicated data analysis in the context of vehicle calibration.
Virtual environments and intelligent test scenario design methods are central to investigations on vehicle calibration, as shown in [
9]. In vehicle development, calibration tasks commonly use Model-in-the-Loop (MiL), Hardware-in-the-Loop (HiL) [
10,
11], and Engine-in-the-Loop (EiL) [
12,
13,
14]. These X-in-the-Loop (XiL) test benches are increasingly used for testing real driving emissions and applications, as noted in numerous publication sources [
15,
16,
17,
18]. One advantage of these test benches is their high degree of flexibility. Pre-conditioning time can be reduced by simulating component temperatures and ambient conditions, although this requires adequate models for the relevant conditions.
Examples of calibration on HiL test bench environments are discussed and presented for various use cases. Although the topic of emission calibration is discussed for early RDE calibration [
11,
19,
20] in conventional vehicles, the increased complexity of the powertrain motivates its application in hybrid powertrains [
21,
22,
23]. In [
24], the focus on virtual drivability calibration on an EiL test bench is discussed. High correlation is shown for the detailed simulation models for drivability and transmission with low deviations in emissions compared with chassis dynamometer tests. The use of EiL can lead to a reduction in calibration efforts by up to
and costs by up to
. Additionally, the used models are suitable to enable potential objectification in drivability [
25]. Furthermore, Schmidt et al. offer an extensive overview of system validation methods for drivability in [
26].
In parallel with the use of innovative test benches and simulation techniques, multiple approaches are being developed to pivot testing efforts toward use-case-relevant scenarios. These approaches can be categorized into four groups (generic test cycles, real-world routes, real-world driving behavior, and worst-case estimations) as described in [
8]. Generic test cycles (e.g., ADAC BAB cycle or RTS95) are commonly used fleet-generically on chassis dynamometers and offer a high level of comparability and a low vehicle-specific effort. Real-world route retracing with operating point reproduction [
27,
28,
29,
30] can transfer real-world driving behaviors or environments to test benches or simulations, with the added ability to test different traffic scenarios [
15]. Synthetically generated statistical driving profiles—primarily using Markov chains [
31]—are utilized to represent regional driving behavior and are the focus of the research in [
32,
33,
34,
35,
36,
37]. Worst-case cycles generated using Design-of-Experiments (DoE) based on engine test benches or simulations are used for the final testing of the most intensive test cases, suggesting a safety-oriented approach, as described in [
38,
39,
40,
41].
Data analysis methods are used to support modeling, calibration, and defining relevant test scenarios in addition to enabling XiL test benches [
42]. For instance, Isermann et al. outline an approach utilizing optimization algorithms in an offline simulation for base calibration focusing on emissions and fuel consumption [
43]. Wasserburger et al. propose a methodology in [
44,
45] for generating test cycles from engine-operating points and using these as input values for an optimization algorithm that adjusts the calibration of specific functions to optimize vehicle emissions. Moreover, offline powertrain models use nearest neighbor clustering algorithms to frontload the engine base calibration in [
46], and a methodology for model-based smooth calibration is presented in [
47]. The investigation of neural networks is the main topic in [
48] for developing models for the optimization of baseline calibration. Steinbach et al. analyze the virtualization of emission calibration and emission modeling for RDE optimization in [
49]. In [
50], a methodology for emission simulation is developed, which is further discussed for use on EU7 applications in [
51]. Further research and publications within the context of advanced data analysis in automotive development include the clustering of vehicle trajectories [
52] and calibration of autonomous driving systems in the automotive sector [
53,
54].
To fully utilize of the advantages resulting from the design of test scenarios and virtual test beds, a targeted analysis of measurement data is highly relevant. In the context of emission calibration, recognizing patterns, trends, and clusters is a primary challenge when assessing the quantitative effects of the identified weak spots in RDE applications. Such approaches remain largely unexplored in the current state of the research.
2. Materials and Methods
The presented methodology is part of a continuous validation concept. The application of clustering refers to critical sequences from emission measurements, which are referred to as events; the definition and detection of these events are presented in the following. The necessary pre-processing of the events as well as the methodology for the formation of the clusters in the HDBSCAN procedure are explained. Finally, necessary evaluation criteria (Silhouette Score, Density-Based Cluster Validation, and Adjusted Rand Index) are presented.
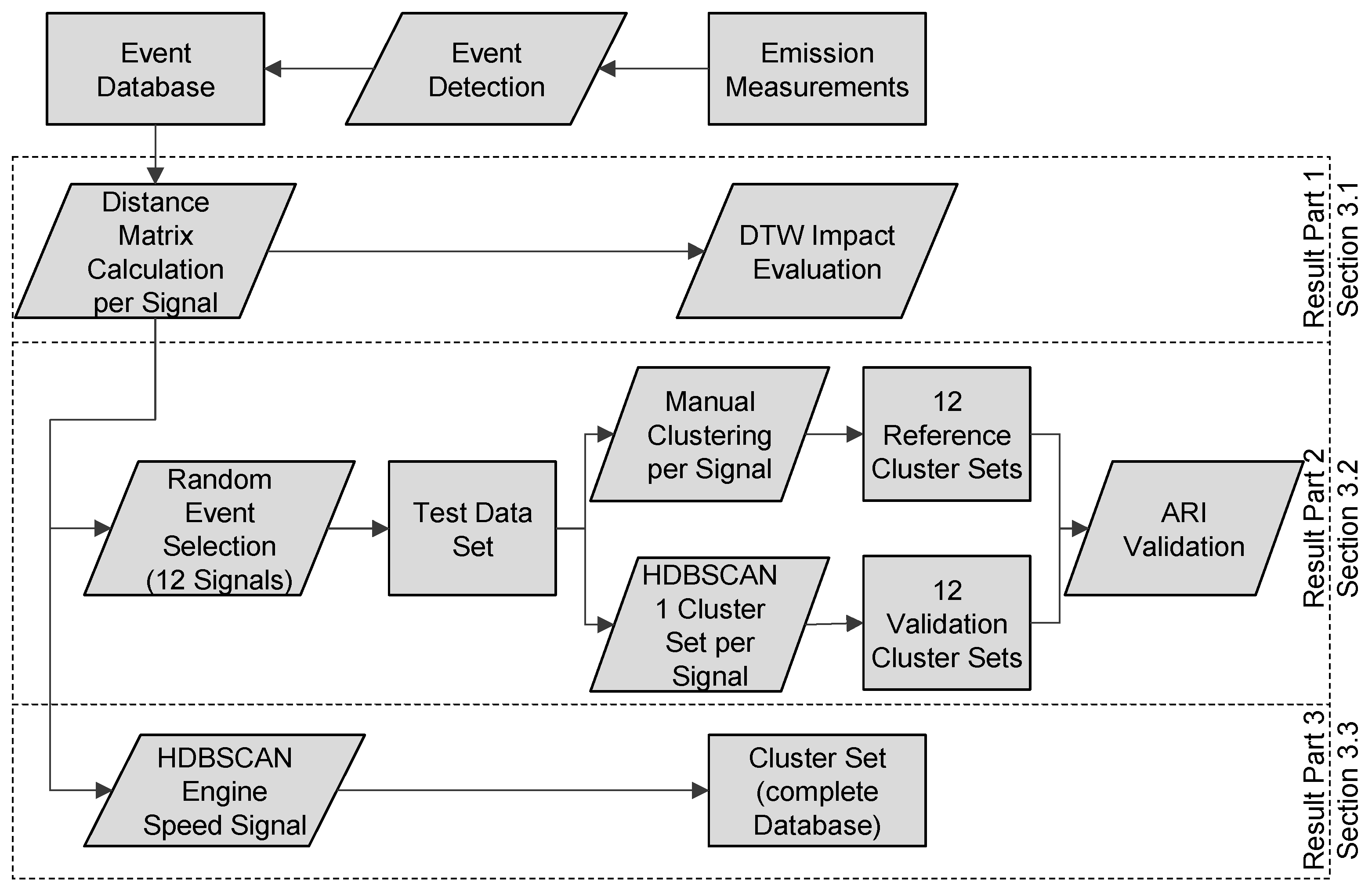
The overall methodology for measurement-based RDE validation is presented and discussed in detail in [
55] and includes—as shown in
Figure 1—four topics:
Event-based RDE validation using multiple test environments.
Identification of calibration potentials.
Quantification of statistical safety.
Dynamic and predictive cycle generation.
The clustering application is part of topic 2, which focuses on the identification of optimization potentials in vehicle calibration. Topic 3 deals with the evaluation of the statistical reliability of the used measurement database. In topic 4, the creation of test scenarios based on [
56] is implemented.
2.1. Data Source
Emission measurements from a vehicle calibration project serve as the data basis for the clustering process. The data originate from an RDE validation campaign of a production vehicle (
Table 1) with a series production engine control unit (ECU) dataset.
The total of
measurements was first analyzed for critical NO
X emission intensities using event detection, as described in
Section 2.2, and transformed into
events. The measurements carried out include temperatures between
and
. In addition to WLTC measurements,
different RDE speed profiles were tested on an emission chassis dynamometer test bench. Furthermore,
different routes in different drive modes were tested with a portable emission measurement system (PEMS) on-road. The tests were carried out with stabilized exhaust aftertreatment systems (
,
of the driven tests) as well as aged exhaust aftertreatment systems (
of the driven tests). All data were resampled to a
frequency prior to the event detection as most of the emission measurements are only available in this resolution.
2.2. Events and Event Detection
An event denotes a time sequence of increased emission intensities from emission test measurements. It encompasses all signals recorded within the sequence, including ECU measurement and test bench measurement data. To detect these sequences, the emission measurements are scanned automatically using a moving integrating window that assesses the distance-specific emission intensity, as described in [
57]. Events typically show durations of
to
, though the duration is variable and dependent upon vehicle emissions. The detection methodology is not the scope of this paper and can be seen in detail in [
57]. The applied thresholds used for the data here are listed in
Table 2.
2.3. Pre-Processing of Events and Distance Calculation
For the further processing of the events into clusters, a comparison of these is necessary. To accomplish this, a distance matrix is created, which serves as the foundation for the clustering process. The distance matrix is
with dimensions that correspond to the number of events it contains. The distance matrix contains the pairwise distance between each event toward each of the other events. Due to varying event durations, a basic Euclidean comparison is not feasible. Therefore, a dynamic time warping (DTW) approach is used.
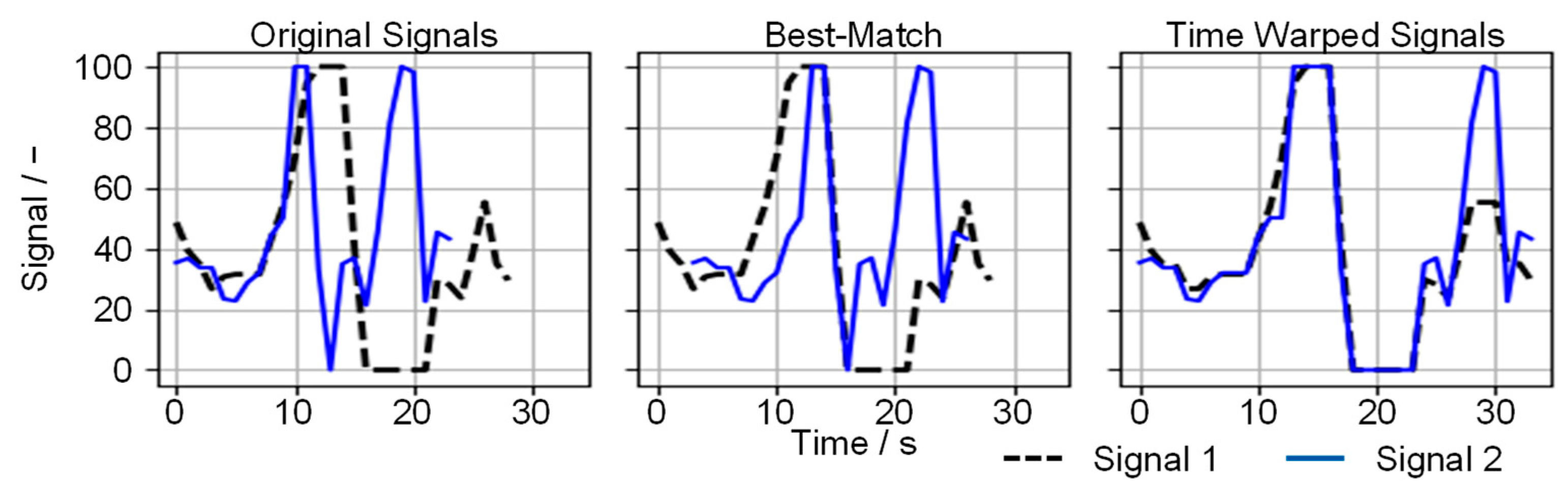
Figure 2 presents a direct comparison (left), a prior signal synchronization using a best-match approach (center), and the use of DTW (right).
While the best match approach can decrease the distance between two signals by synchronizing them beforehand, it cannot include slight differences and offsets. Additionally, when signals have various lengths, not all data points can be considered. The DTW adjusts both signals to each other to minimize the distance between both traces by duplicating individual points [
58,
59].
After pre-processing the signals with DTW, both signals share a standardized duration. Then, the signals are evaluated with a distance calculation using
norm (Equation (1)) [
58]. For each sample
of signals with total duration
(according to DTW), the difference between the two signals
and
is calculated. Here,
is used for the application of the Euclidean distance between the DTW processed traces.
The effects of DTW are examined in
Section 3.1, as manipulating signal traces, though offering advantages for dynamic signal comparisons, increases the likelihood of overfitting signals. This can result in falsely indicating high correlations between traces.
While this application only considers comparisons of events using a single signal at a time, the clustering approach could incorporate a multitude of signals by modifying the distance matrix. When comparing multiple signals, the dimension of the required distance matrix for the clustering algorithm can be kept constant by calculating the distance according to Equation (2).
While each signal in the signal set is first processed individually according to Equation (1), resulting in a scalar distance , the overall distance in the multidimensional space can be calculated using the norm. A weighting factor () is introduced to balance the weight of different signals and to potentially increase the weight of comparisons with a high distance of events for a specific signal.
2.4. Clustering Method
The hierarchical density-based method HDBSCAN [
60] is used to cluster the data based on the distance matrix. This approach does not require information on either the desired number of clusters or the maximum distances between them. The variability in signal types with different dynamic behaviors and magnitudes is a critical aspect of an appropriate clustering method in emission calibration. Various clustering algorithms could be explored for application on calibration data (such as hierarchical, partitioning, Fourier transformation-based optical clustering, etc.). However, previous analyses indicate that the HDBSCAN method has promising features [
61]. A comparison of hierarchical, partitioning, and density-based clustering methods is detailed and evaluated in [
61].
Within the HDBSCAN method, hierarchical clustering [
62,
63,
64] is utilized initially. In contrast to the conventional method, there is no requirement to specify a maximum distance [
65] in the cluster, as the optimization algorithm determines it individually for each part of the cluster tree—similar to partitioning methods [
66,
67,
68]. Furthermore, the HDBSCAN algorithm can define signals that decrease overall cluster quality as outliers.
When applying the algorithm, three parameters are used to control the clustering algorithm:
Minimum cluster size .
Minimum density .
Minimum distance between two clusters .
The analyses in [
61] demonstrate the feasibility of defining
and
identically. Additionally, the Leaf method in HDBSCAN is applied here, as it displays favorable outcomes in [
61] by tending toward generating multiple smaller more closely linked clusters. If the cluster contents indicate the same phenomena, the engineer may manually merge them post-automatic clustering.
The outcome of one HDBSCAN clustering execution on a single signal is defined as a cluster set in this paper. Different cluster sets can result from using distinct signals or event input data to the HDBSCAN execution.
2.5. Characteristic Values for Cluster Evaluation
The validation metrics Silhouette Score, Adjusted Rand Index (), and Density-Based Cluster Validation () are used to evaluate the cluster results.
The Silhouette Score is an intensive measure for evaluating clusters [
69]. To determine the Silhouette Score, the similarities within a cluster and differences with the other clusters are evaluated. For each element
of the elements
in a cluster
, the average distance (Equation (1)) to all elements in the cluster is determined. The result is described by
. In addition, the average distance to all elements of the nearest cluster
is identified. Using Equation (3), the silhouette
is calculated. The Silhouette Score of a cluster
is then defined according to Equation (4) [
69]
Silhouette Scores result in values between
and
. Results close to
indicate very well-separated and dense clusters,
reveals a cluster misattribution [
69].
The
(Equation (5)) is an intrinsic evaluation measure, which evaluates clusters of any shape based on their density among each other [
70,
71]. It compares the density within clusters to the density between clusters with resulting values between
and
. Negative
values indicate clusters that have a density lower than the environment. For a set of clusters
containing
clusters, the size of the cluster
in relation to the number of all considered elements
is factorized by the cluster validity
[
70].
is an extensive measure for the evaluation of correct cluster assignment to their expected value (Equation (7)). It evaluates the correct assignment of elements to a cluster when the correct assignment of these elements is already known. The
is based on the Rand Index
(Equation (6)), which is formed by the ratio of the sum of True Positive
and True Negative
values and the total of
,
, False Positive
, and False Negative
values. For the calculation of the
the
is corrected by the expected value
of a random assignment. The
has an expected value of
and a maximum value of
.
corresponds to ideal agreement [
72,
73].
For the application of
to the emission events in this paper, a prior manual assignment of the sampled events into clusters is necessary. Subsets are randomly selected for
different signals from the event database and manually sorted into reference clusters. This process is performed on a purely visual basis.
Table 3 shows an overview of the signals, the number of events, and the manually created reference clusters.
The manually created reference is compared with the automatically created cluster sets in
Section 3.2. The signals are selected in a way to use signals of different characteristics for the validation. The signals include very dynamic characteristics with a high range of values (e.g., engine speed), but also signals with rather smooth dynamics (e.g., vehicle speed or catalytic converter temperature). In addition, signals that change abruptly (e.g., the voltage of the two-point downstream lambda sensor) and binary signals (e.g., the flag fuel cut-off) are used. The choice of signals is exemplary and allows for verification of the generic application of the method to all available measurement data.
3. Results
In this section, the results from applying the clustering process to emission measurements are presented. The structure of the section is displayed in
Figure 3.
First, adjustments from data pre-processing are shown. Then, a validation of the HDBSCAN application on the used data is discussed for different signals, evaluating the impact of the characteristic values for cluster evaluation. Subsequently, the exemplary application of the clustering procedure to the entire data is presented.
3.1. Pre-Processing of Data
The DTW correction to the signals enables the compensation of offsets and smaller differences. This simplifies the comparison of signals of different durations and characteristics, but, at the same time, distorts the signals. Partially significant profile sections may align, resulting in the incorrect classification of two events as similar. The impact of DTW results is evaluated visually for randomly selected comparisons.
Figure 4 and
Figure 5 display the impact using the downstream lambda sensor voltage
and the vehicle speed
.
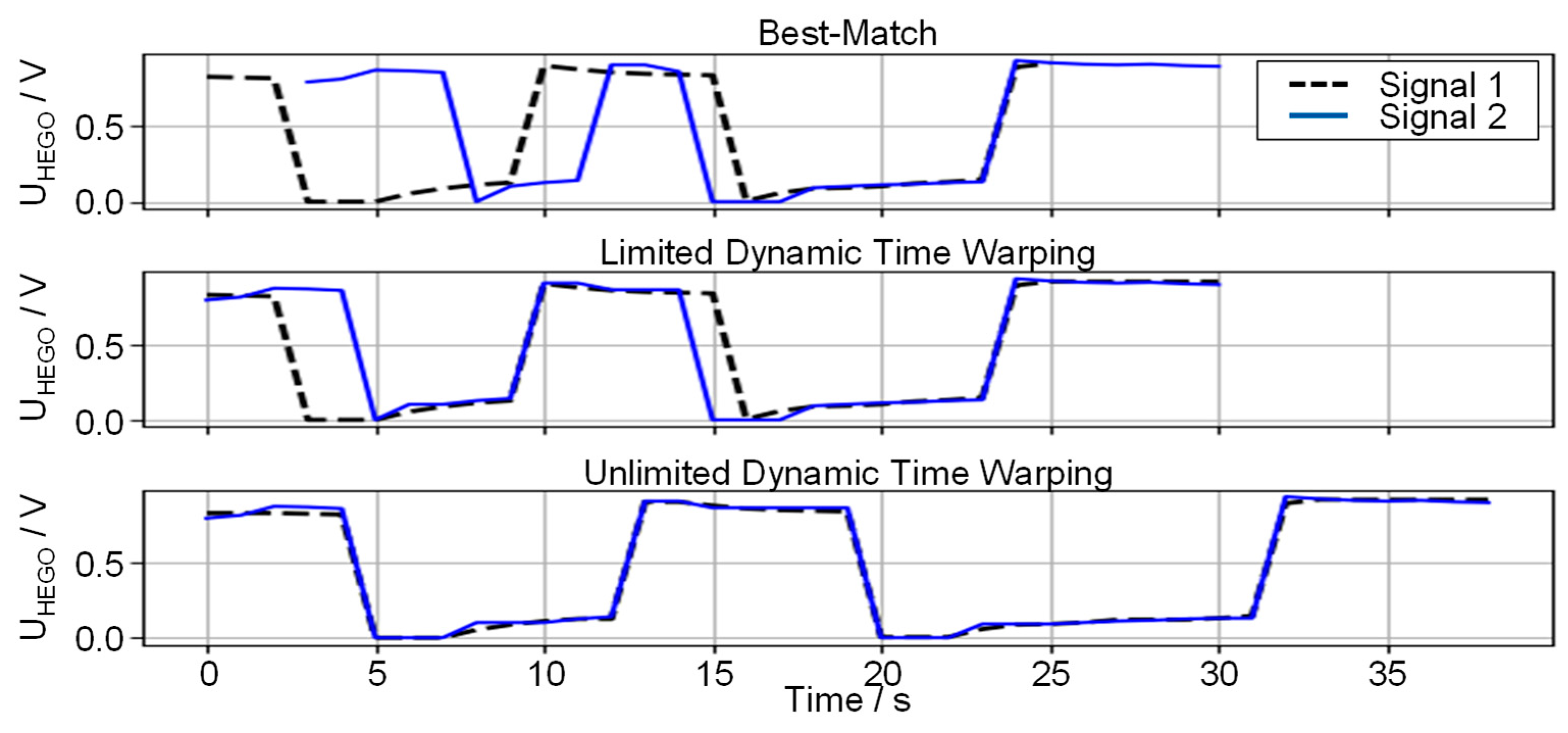
The difference between limited and unlimited DTW is illustrated in
Figure 4. The curves of the reference profile (signal 1) and the event to be compared (signal 2) show similar characteristics. The curves start with a voltage of
, indicating a normal state of the catalytic converter in the
(stoichiometric mixture) operation. After
, the sensor voltage drops to
–
. This indicates an oversaturation of the catalytic converter with oxygen. This results from a fuel cut-off maneuver. Here, the absence of fuel injection results in air being pumped through the engine and exhaust aftertreatment system (EATS). The oxygen contained in the air is stored in the catalytic converter until the maximum storable amount of oxygen is reached. The remaining oxygen is then detected by the sensor. After a further
, the fuel cut-off is terminated and fuel is re-injected. However, in the already oversaturated state of the catalytic converter, NO
X emissions cannot be reduced. As a consequence, the ECU enriches the mixture to operate at
to purge the oxygen from the catalytic converter due to the oxidation of CO and HC (
with voltage regaining
). This maneuver is repeated in both events. Signal
and signal
are to be considered equal from a technical point of view. The slight difference in the durations of the enriched and lean phases has a minor influence on the resulting emission event. Here, an unlimited DTW is useful.
A similar behavior is seen for further signals and events. However, an overfitting of signals using DTW must be prevented. For this purpose, the complexity of a signal is incorporated into the distance measure using the complexity estimation presented by Batista et al. in [
74]. The distance measure
for the similarity of two events
and
is expressed as the product of the distance
(calculation according to Equation (1)) and a correction factor
(Equation (10)). The correction factor describes the ratio of the complexity values
of the signals (Equation (9)). The complexity
is a measure used to judge changes in the signal course according to Equation (8). It is calculated by identifying the distances of consecutive signals values [
74].
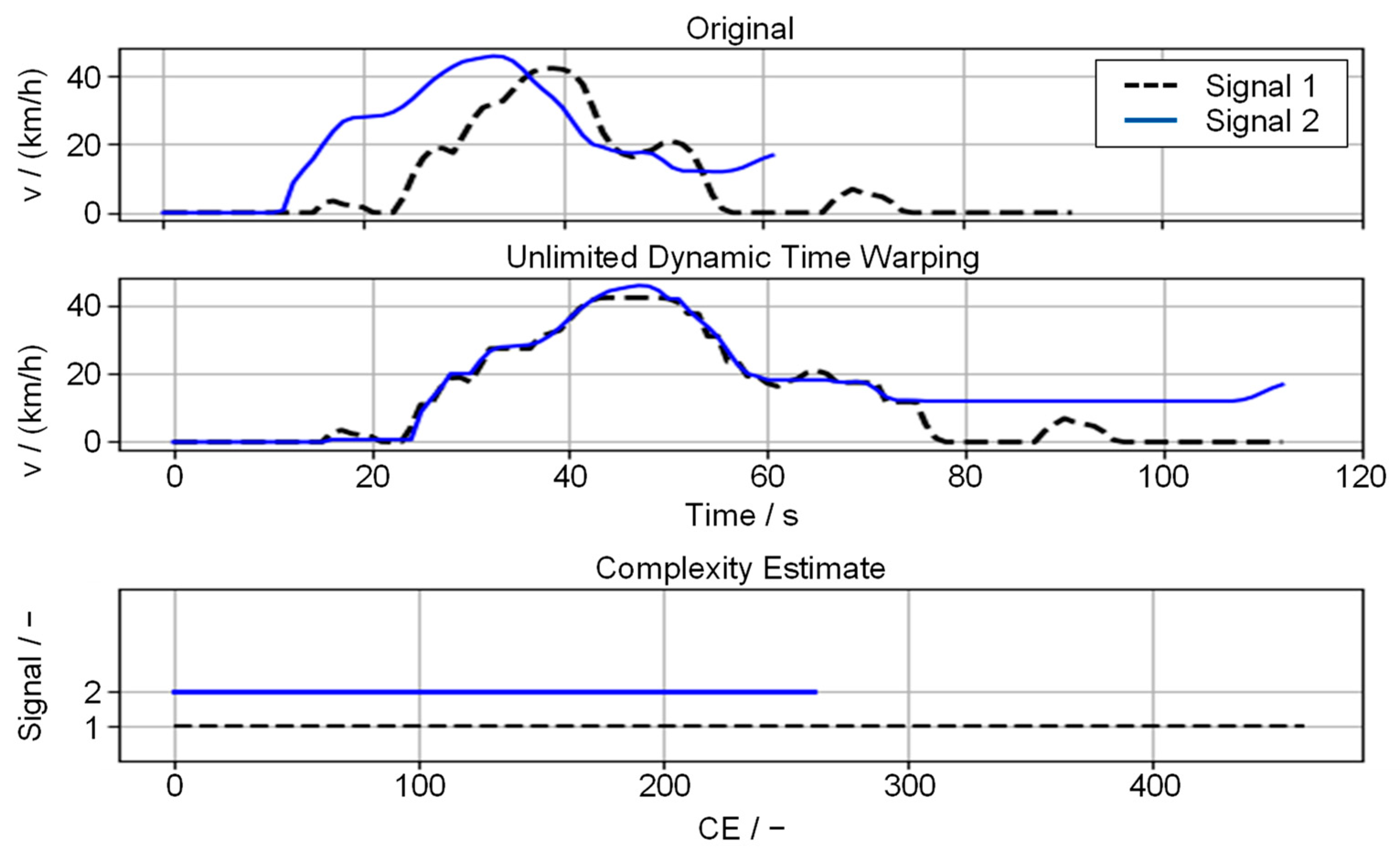
The effect of the correction is shown in
Figure 5. The velocity traces of two events are first adjusted with unlimited DTW. Since the signal of the velocity of the second event
(blue) is clearly shorter than signal one, it is distorted stronger. Similarly, the course is less complex. The difference in the complexities in the lower plot shows the quantitative evaluation, which leads to a correction factor of
with
and
.
In this way, different complexities and event durations are considered when applying the DTW correction. Thus, an overfitting due to DTW cannot be prohibited but will at least be considered in the distance matrix by the correction factor. The further creation of the distance matrix for application to the HDBSCAN clustering method is thus calculated using the complexity correction-dynamic time warped distances.
3.2. Verification of HDBSCAN Using Data Extract
The HDBSCAN procedure is initially applied per signal to the selection of emission measurement data shown in for verification. Accordingly, cluster sets are identified. The assignment of the events to the categories per cluster set can differ. The combination of different signals and agreement on the division of the same event groups into the same clusters in various cluster sets are not evaluated here.
The results of applying HDBSCAN to the test data are shown in
Table 4. While the agreement with the test clusters represented by
is predominantly good, the
evaluates the compactness of the clusters independently of the previously manual assignment. With values of
and a mean value over all signals of
, a good compactness of the data is interpreted here.
The mostly low number of classified outliers using HDBSCAN show that the density-based clustering provides good results here as well. High numbers of outliers are only observed for the signals of the optimum ignition angle and the engine torque. These two signals exhibit very dynamic trajectories, which provide high requirements for DTW and clustering due to the different signal lengths and complexities.
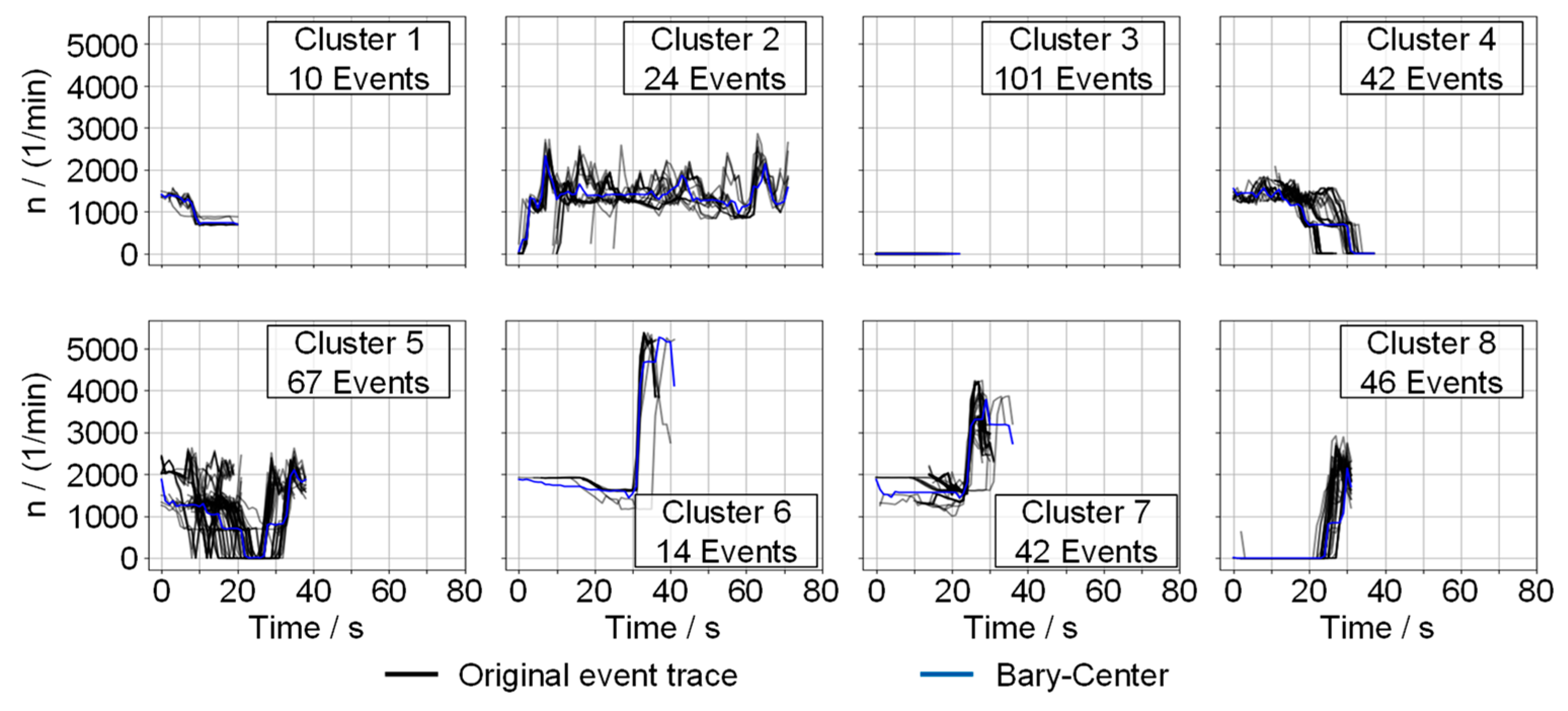
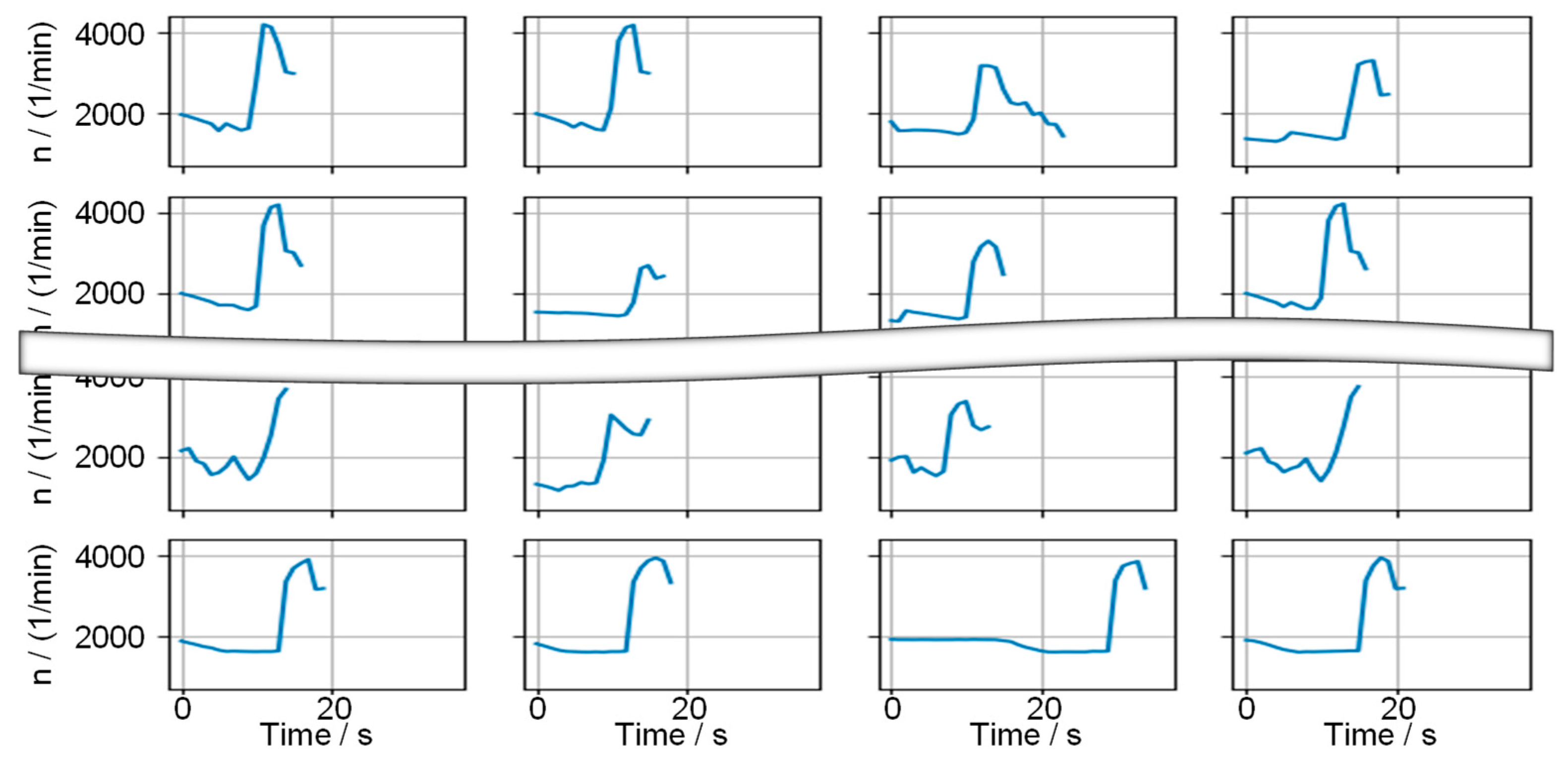
Examples of clusters are shown in
Figure 6. The original signals of the events assigned to a cluster are shown in gray without applying DTW and without specific best-fit synchronization. The blue trace shows the center event of the cluster generated using the bary-center approach [
75]. The bary-center is a synthetic trajectory computed with DTW that compensates for local temporal shifts in the signal trajectories. This allows to summarize the cluster in a representative form so that the analysis of the profile trajectories is simplified. Thus, the information in a cluster can be described by the representative signal and the cluster size.
The distribution of the clusters shows a reasonable categorization regarding the profile and length of the events. While rather short events are contained in clusters 1 and 3, cluster 2 shows the group of the longest events. The other clusters show similar event durations.
Cluster 3 shows an event where the engine is off during the event. This phenomenon is not based on a technical aspect of the engine or EATS but rather caused by the event detection procedure itself. Due to the window-based integration approach, each sample is assigned a distance-specific emission intensity that includes previous and following measurement samples. This method compensates for smaller synchronization errors by calculating the distance-specific intensity after filtering driven vehicle speed and emitted emissions. A direct sample-wise calculation has the disadvantage of being highly dependent on a high synchronization quality and resolution of the measurement device [
57]. However, due to the filtering, the samples where no emissions are created can be assigned with the intensity resulting from earlier or later phases. Such phenomena cause the displayed cluster 3. The cluster 3 sequences are such sequences where the engine is off and no emissions are produced. Due to the low traveled distance during vehicle standstill, the braking or acceleration phases prior to or post the identified sequences lead to a high distance-specific emission level for the standstill phases. While the later or earlier samples (after drive-off or before standstill) are not considered as critical due to the higher traveled distance, the standstill phases are considered as such.
3.3. Application of HDBSCAN on the Complete Dataset
After applying the clustering algorithm to a partial extract of the total data, the algorithm is applied to the entirety of the NOX events. As a reference signal, the engine speed is used. An automated definition of the minimum cluster size and is used. The definition is performed by calculating the for cluster sets from to . The setup that reaches the maximum is used. is defined as identical to . Based on this, is then iterated and, consistently, the value reaching the highest is selected.
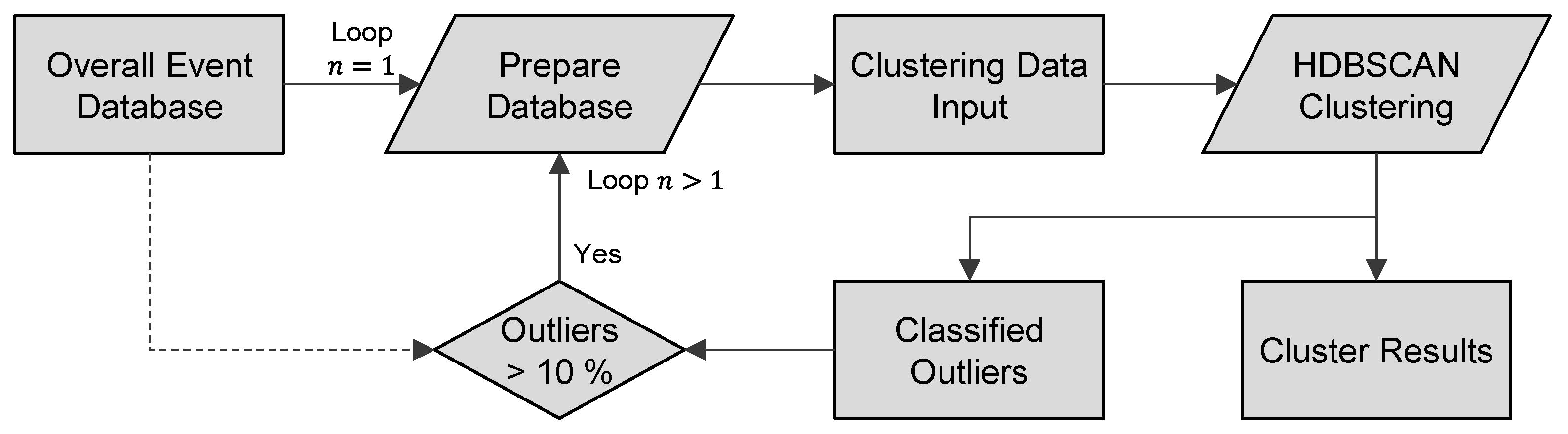
When applied to the total amount of data, the data variety increases. This causes a large number of events to be classified as outliers, in contrast to the further results of the verification run. To overcome the high amount of outliers, an iterative re-clustering approach is implemented, as shown in
Figure 7.
Initially, the overall event database is used for the first loop. For the second loop, the outliers of a cluster set are defined as new input data and subjected to re-clustering. This is repeated until the share of detected outliers in the total dataset reaches a maximum of . The resulting cluster sets of each loop are appended to the previous iterations.
The results of this iterative process are shown in
Table 5. After four iterations, the number of events classified as outliers (
) reaches
of the total events.
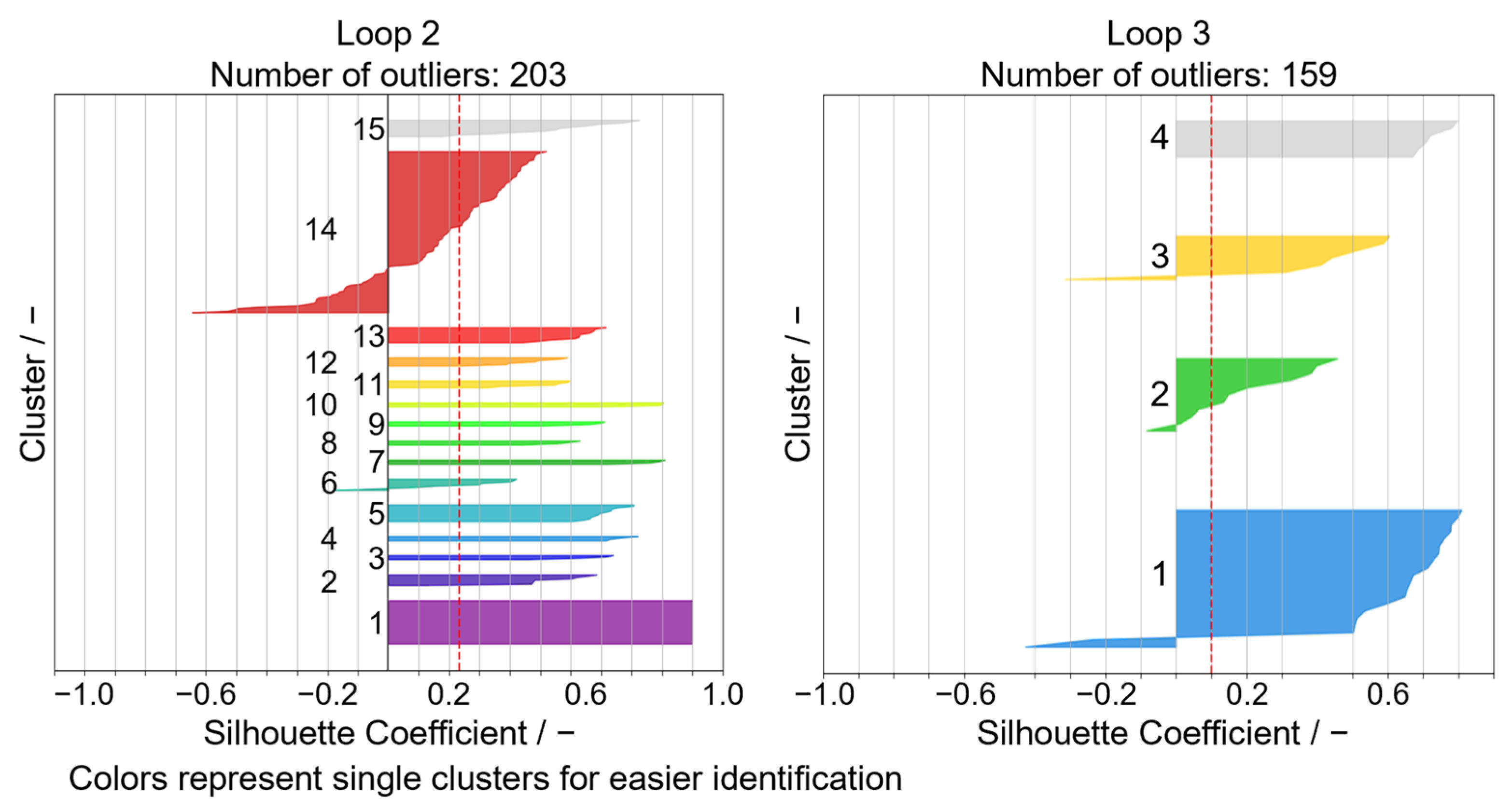
The
value shows an acceptable level, although being lower than for the verification analysis, for all iterations and is lowest at 0.303 for the third run. The average Silhouette Scores show rather low values. Given the high variance in the signal profiles, this is mostly due to individual events that do not fit perfectly into a cluster and tend to be interpreted as a transition to a neighboring cluster. The courses of the Silhouette Scores are exemplarily shown for the result cluster set of Loop 2 and Loop 3 in
Figure 8.
Finally, the sets of individual clusters from the iterative loops are merged. The assigned clusters of outliers are inserted into the results of the previous loop successively. In this way, only the cluster assignment of classified outliers is corrected for each iteration. The
raw clusters are judged manually for the final interpretation. Similar clusters are combined based on engineering judgement. Merging neighboring clusters with numerical differences but similar system behavior reduces the number to
, resulting in
events as outliers. The result is shown in
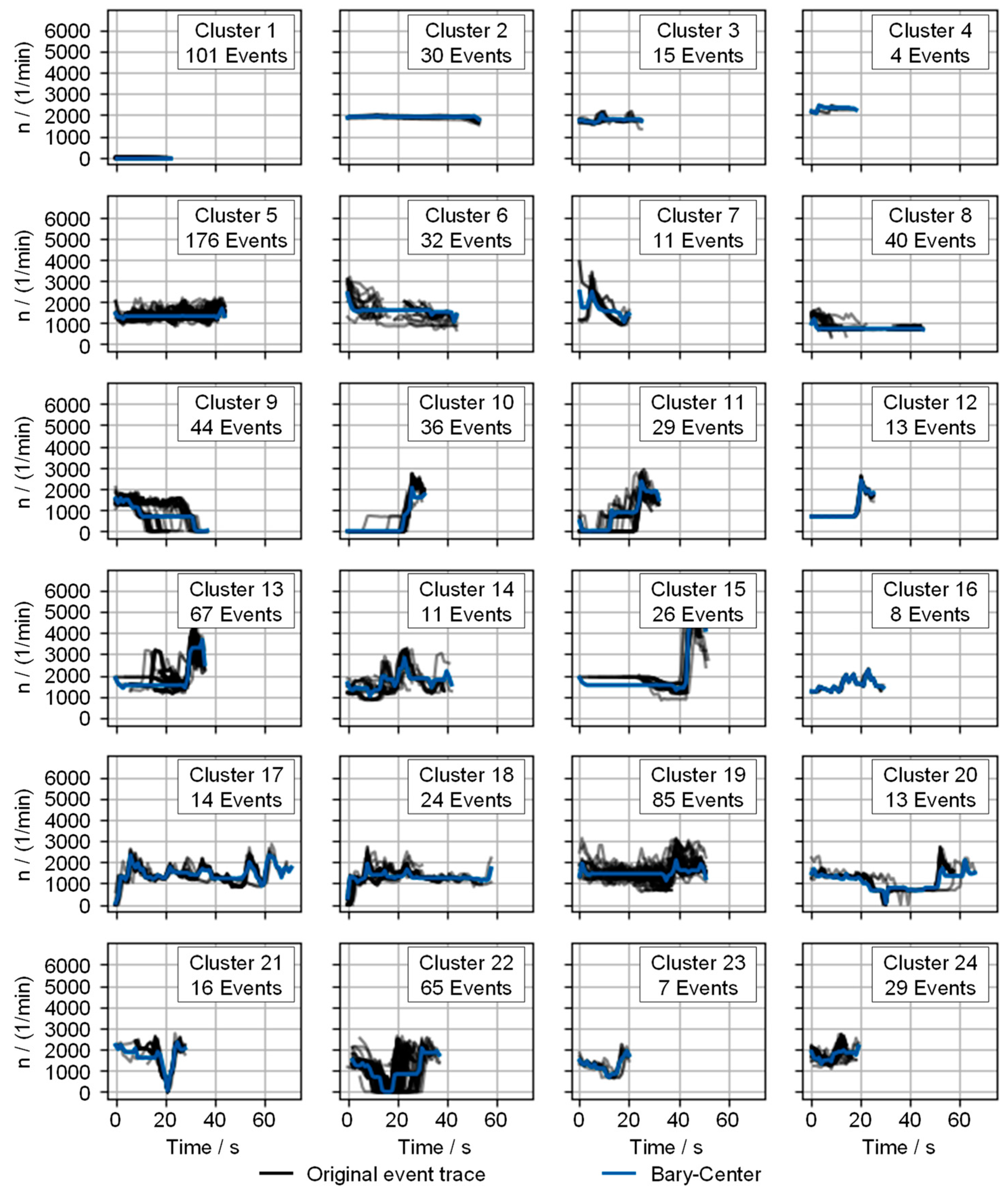
Figure 9.
The representing trace of a cluster is again expressed by the bary-center in blue. The original event traces are shown with black lines. Various phenomena are exhibited by the characteristics of the clusters. Cluster
contains events with an inactive combustion engine (cf. cluster
from the HDBSCAN verification in
Section 3.2). Clusters
–
depict continuous engine speed progressions. Due to the varying levels and durations of the events, different clusters are formed. Cluster
is characterized by slightly oscillating speed profiles between
and
. The subsequent clusters
–
display profiles with an initial braking phase.
Clusters
and
display engine start events and could be consolidated. Clusters
through
exhibit distinct acceleration processes. Specifically, cluster
contains single accelerations (
Figure 10), whereas cluster
centers on repeated accelerations. The similarity in the representation of these stems from the varying duration of events, which is evident for cluster 13 in
Figure 10.
The other clusters are formed by phases of different dynamics with slight or strong fluctuation. Phases with included standing phases are evident. While cluster contains only short standstill times (mostly to ), the standstill times in cluster vary.
4. Discussion
The discussion of the presented results is separated into sections including the evaluation criteria, the data pre-processing procedure, and the application of the clustering method to the emission measurements.
4.1. Evaluation Criteria and HDBSCAN Validation
The
correlations between the HDBSCAN results in
Section 3.2 and the defined reference clusters show a predominantly good quality of the automated results (
Table 4). At the same time, the number of detected outliers is low. This supports the use of HDBSCAN. While the possibility of detecting outliers is preferred, the reference dataset does not include any outliers. In the visual validation, the specified outliers show reasonable traces to accept them as such. Especially for the resolution of clusters, the determination of the optimal size is not perfect, and deviations from the reference distribution are expected and accepted. The results show that the automated clustering tends to over-determine clusters. Except for the clusters for speed, engine torque, relative fuel mass, and optimal ignition angle, more clusters are formed with automated clustering (
Table 3 and
Table 4). For the accelerator pedal position, automated clustering divides the data into one fewer cluster than manual clustering. A division into smaller clusters is more practicable than a few large clusters. A manual merging of clusters can be realized easily and rapidly with a graphical evaluation. A manual splitting of events, however, is more difficult.
The evaluation of the comparison of automatic clustering to the manually created reference clusters in
Section 3.2 shows an overall good correlation between
and
. In some cases, as, e.g., for the relative air charge or the relative fuel mass, the indications from
and
do not align. As an external reference-based measure, the
results are preferred. Except for the fuel cut-off flag and the temperature of the catalytic converter, the
values show a higher rating of the cluster quality than the internal density based on
. In daily use, the assessment of quality using
is not practical. However, the results of the cluster assessment show an overall good correlation between
and
(
Table 4). As an intensive criterion,
does not require further processing or preparation of the data. Thus,
is preferred for automated application in calibration.
4.2. Pre-Processing of Data
The distance matrix is created using the EDTW method on the raw signals. During the application of the method, the risk of overfitting data toward each other is seen. For the high variation in the compared data, the key feature of DTW—allowing to compare signals of different lengths and to correct offsets and slight differences—is useful. To overcome the risk of falsifying data using DTW, the complexity estimate correction is useful. Although, the influence of DTW cannot always be predicted. A visual correction of assigned events to clusters still must be carried out and can help to identify weak spots in the DTW comparison. While using only one signal at a time for the clustering approach, the validation of DTW falsification is possible. Overcoming the risks of DTW in feature-based clustering approaches might be possible when not relying on a time-series-based distance calculation directly. Approaches based on Fourier transformation or signal feature-based multi-dimensional clustering methods are yet to be further analyzed.
The signals are not normalized in advance. An investigation with normalized values on the cluster quality is still pending. The normalization significantly restricts the range of values of the event-to-event distances. This may lead to further simplification in the design of the cluster parameters. In the current non-normalized approach, the distances are strongly dependent on the magnitude of the respective signal. Thus, the findings of distance magnitudes and thresholds are not transferable across the signals without normalization. An impact on the amount of outlier classification for the complete dataset is yet to be analyzed.
4.3. Judgement of HDBSCAN Application for Emission Calibration Purposes
The results show that HDBSCAN provides an automated method for categorizing time signals of different characteristics. In emission calibration, this method allows to significantly reduce the amount of data to be analyzed and offers the potential to quantify and weigh weak points. The automated event detection condenses the total test data into only the critical parts. In the project used, 78 emission measurements with a total duration of 255,928 s are reduced to a quantity of
events relevant to NO
X emissions. These
events have a total duration of
. The automatic clustering, based on the engine speed signal in
Section 3.3, with a total of
raw clusters shows the tendency of over-classification and the formation of micro-clusters. A manual visual correction of the clusters results in
final clusters. Here, automatically assigned clusters are only merged, and splitting an existing cluster is not required. Although this step required manual engineering effort, this procedure is suggested. Variations in the HDBSCAN settings show that the formation of rather large clusters is not desirable.
While automated clustering (distance matrix calculation and HDBSCAN execution) of the given dataset requires only a couple minutes (excluding the event detection and data preparation), manually merging the clusters on a visual base requires around one hour for an engineer who is familiar with the data and the procedure. While this significantly increases the time-based effort, it allows to manually control the sensitivity of the data assignment for later analyses. The required manual data analysis for categorization is reduced to the evaluation of the overall cluster plots.
Depending on the selected signal, the categorization of events can lead directly to relevant weak spots. However, for a detailed weak spot analysis, it is necessary to consider the influence of a multitude of signals. This can be performed either by evaluating similar combinations of groups in different cluster sets based on different signals or by applying the clustering process to a multitude of signals at once. Both concepts are currently under investigation and will be discussed in subsequent publications.
Although the clustering of a single signal describing a driving maneuver (e.g., vehicle speed, engine speed, or engine torque) can provide a first indication of the general nature of weak spots, automatic clustering enables the prioritization of actions to optimize the system behavior within the identified events by quantifying their impact.
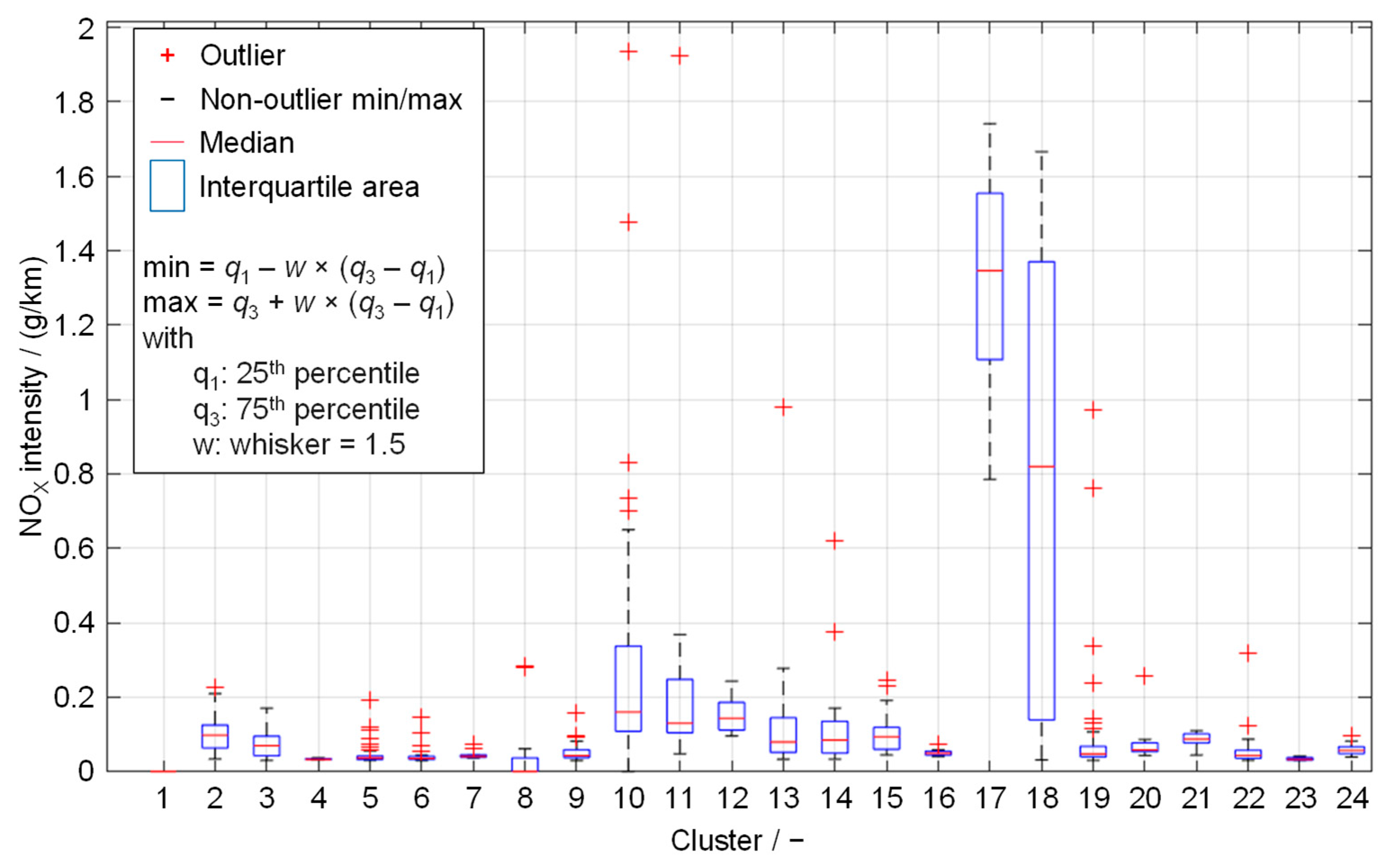
Figure 11 shows the distribution of distance-specific NO
X emission intensity of the events in the previously presented clusters. While the expected intensity of each cluster is below
for most clusters, clusters
,
,
,
,
,
and
show rather high intensities. Clusters
and
are the clusters that summarize statistically the most intense events. Cluster
and cluster
contain the highest overall events considering the outliers in the boxplot intensity distribution.
Similar analyses can be performed using different factors. In addition to the specific emission intensity distributions, information such as cumulative intensity (multiplied by cluster size), distance traveled, duration, appearance in the measurement after engine start, EATS temperature, high voltage battery SOC, etc., can be used to further judge the root causes and correlations of clusters. However, when considering the emission signal or absolute intensity, the origin of the measurement should be considered. Measured emission traces can vary in shape depending on the measurement system used (e.g., emission chassis dynamometer with constant volume sampling measurement vs. on-road PEMS measurement). Furthermore, the intensity of similar events varies with different aging conditions of the EATS.
A further detailed analysis of the events presented in this study overreaches the scope of this presentation. The presented initial categorization enables weak spots to be quantified. Thus, the total impact of a weak spot can be calculated and evaluated by the total number of events and their intensity by the cluster. This enables both a prioritization in addressing the identified weak spots and a quantitative comparison of the development of these over the ECU datasets during a project. By creating and comparing cluster sets at different stages of the calibration process, it is possible to assess whether the actions taken are simply shifting the weak spots to another issue or are optimizing the overall system behavior.
5. Conclusions
With the shift toward evaluating emissions in vehicle development in real-world conditions introduced by EU6d and further planned in EU7, validation methods and innovative test benches are becoming increasingly important. However, to efficiently exploit resulting potentials, new approaches in data evaluation are required. To efficiently optimize a system’s calibration, weak spots must not only be identified, but patterns also need to be identified.
This paper explores the potential of clustering emission data for quantifying weak spots. Using automatic event detection, complete measurements are summarized to include only the relevant parts necessary for the calibration process. This automatic process saves time and improves efficiency.
Dynamic time warping is used to construct a distance matrix based on time series comparisons to automate the processing and comparison of events of different durations. DTW has a high potential for reducing the impact of minor differences and offsets in two signals. However, there is also a risk of overfitting. In an unlimited DTW application, the complexity estimate function can account for various signal shapes and durations, factoring in the distance based on the initial signal’s difference in complexity and duration.
An initial evaluation on the usability of HDBSCAN for vehicle calibration data is conducted by manually creating reference cluster sets for 12 different signals. The automatic HDBSCAN application is then compared to the same extract of events, resulting in an overall strong correlation between manual clustering and automatic clustering with an . Already here, the algorithm displays a tendency to create multiple smaller clusters.
The algorithm applied to the entire dataset of events detected a significant number of outliers (nearly of the total data) during clustering solely based on the engine speed signal. To address this issue, a procedure is introduced that involves re-clustering the identified outliers in a separate run. This is iterated until of outliers are reached in the used dataset.
The application of the complete dataset confirms the tendency to identify a high number of small clusters. HDBSCAN’s iterative execution on outliers yields a total of clusters. From this, clusters of engine speed are summarized manually, while the remaining events are considered outliers in the final distribution. While automatic clustering requires under min, the manual merging of clusters based on a visual analysis of the given amount of clusters and events demands significantly more time, with a one-hour investment. Nevertheless, the manual merging of clusters increased the number of clusters, allowing for greater freedom in terms of the application-specific sensitivity of the results.
The presented application of clustering is performed using only a single signal to decide on the categorization of events. While more complex than an initial validation and presentation of the approach, a detailed root cause analysis requires a larger number of signals to be considered. Such applications are currently under investigation and will be presented in subsequent publications. However, even single-signal clustering offers a high benefit for the data analysis itself, as driving maneuvers (most expressed by the speed signal) can already be clustered to obtain a first impression of the available data. In addition, it can support the current manual analysis by being able to cluster data based on an already existing manual assumption. In this way, a quantification of the actual impact as well as further correlation studies on vehicle or environmental effects can be performed.
While the application is focused on emission calibration, the design of the proposed data analysis method can be flexibly applied to any use case. For example, if the event definition is not critical in terms of emission intensity but for a hybrid operating strategy, electrical energy consumption, or issues such as component protection and derating strategies on electrified vehicles in the future.
Author Contributions
Conceptualization, S.K.; methodology, S.K. and G.T.; software, S.K. and G.T.; validation, S.K. and G.T.; formal analysis, S.K. and G.T.; investigation, S.K. and G.T.; resources, S.K., M.G., M.N. and S.P.; data curation, S.K. and J.C.; writing—original draft preparation, S.K.; writing—review and editing, J.C., G.T., M.D., F.D., M.G., M.N. and S.P.; visualization, S.K. and G.T.; supervision, M.G., M.N. and S.P.; project administration, S.K.; funding acquisition, S.P. All authors have read and agreed to the published version of the manuscript.
Funding
The presented research was carried out at the Center for Mobile Propulsion (CMP) of RWTH Aachen University, funded by the German Science Council “Wissenschaftsrat” (WR) and the German Research Foundation “Deutsche Forschungsgemeinschaft” (DFG).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author. The data are not publicly available due to the complexity of the analysis which needs guidance for reproduction and confidentiality of root measurements.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of this study; in the collection, analyses, or interpretation of data; in the writing of this manuscript, or in the decision to publish the results.
List of Abbreviations
| ARI | Adjusted Rand Index |
| AT | automatic transmission |
| AWD | all-wheel drive |
| CE | complexity estimate |
| cf. | confer |
| CF | complexity factor |
| CO | carbon monoxide |
| DBCV | Density-Based Cluster Validation |
| DoE | Design-of-Experiments |
| DTW | dynamic time warping |
| e.g. | for example |
| EATS | exhaust aftertreatment system |
| ECU | engine control unit |
| EDTW | complexity estimate dynamic time warping |
| EiL | Engine-in-the-Loop |
| FN | False Negative |
| FP | False Positive |
| GPF | gasoline particulate filter |
| HC | hydrocarbons |
| HDBSCAN | Hierarchical Density-based Spatial Clustering of Applications with Noise |
| HiL | Hardware-in-the-Loop |
| MiL | Model-in-the-Loop |
| NOX | nitrogen oxides |
| PEMS | portable emission measurement system |
| PiL | Powertrain-in-the-Loop |
| RDE | real driving emissions |
| RI | Rand Index |
| SOC | state of charge |
| TN | True Negative |
| TP | True Positive |
| TWC | three-way catalytic converter |
| ViL | Vehicle-in-the-Loop |
| WLTC | Worldwide Harmonized Light Vehicles Test Cycle |
| XiL | X-in-the-Loop |
References
- Maurer, R.; Yadla, S.K.; Balazs, A.; Thewes, M.; Walter, V.; Uhlmann, T. Designing Zero Impact Emission Vehicle Concepts. In Experten-Forum Powertrain: Ladungswechsel und Emissionierung 2020; Liebl, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2021; pp. 75–116. ISBN 978-3-662-63523-0. [Google Scholar]
- Mulholland, E.; Miller, J.; Bernard, Y.; Lee, K.; Rodríguez, F. The role of NOx emission reductions in Euro 7/VII vehicle emission standards to reduce adverse health impacts in the EU27 through 2050. Transp. Eng. 2022, 9, 100133. [Google Scholar] [CrossRef]
- European Commission. The European Green Deal: Communication from the Commission to the European Parliament, the European Council, the Council, the European Economic and Social Committee and the Committee of the Regions; European Commission: Brussels, Belgium, 2019; 640p. [Google Scholar]
- Mulholland, E.; Miller, J.; Braun, C.; Jin, L.; Rodríguez, F. Quantifying the Long-Term Air Quality and Health Benefits from Euro 7/VII Standards in Europe. Int. Counc. Clean Transp. 2021. Available online: https://euagenda.eu/upload/publications/eu-euro7-standards-health-benefits-jun21.pdf (accessed on 1 January 2024).
- Boger, T.; Rose, D.; He, S.; Joshi, A. Developments for future EU7 regulations and the path to zero impact emissions—A catalyst substrate and filter supplier’s perspective. Transp. Eng. 2022, 10, 100129. [Google Scholar] [CrossRef]
- European Commission. Commission Regulation (EU) 2017/1151; European Commission: Brussels, Belgium, 2017. [Google Scholar]
- European Commission. Proposal for a Regulation of the European Parliament and of the Council on Type-Approval of Motor Vehicles and Engines and of Systems, Components and Separate Technical Units Intended for such Vehicles, with Respect to Their Emissions and Battery Durability (Euro 7) and Repealing Regulations (EC) No 715/2007 and (EC) No 595/2009; Proposal; European Commission: Brussels, Belgium, 2022; Volume 0365. [Google Scholar]
- Claßen, J.; Krysmon, S.; Dorscheidt, F.; Sterlepper, S.; Pischinger, S. Real Driving Emission Calibration—Review of Current Validation Methods against the Background of Future Emission Legislation. Appl. Sci. 2021, 11, 5429. [Google Scholar] [CrossRef]
- Andert, J.; Xia, F.; Klein, S.; Guse, D.; Savelsberg, R.; Tharmakulasingam, R.; Thewes, M.; Scharf, J. Road-to-rig-to-desktop: Virtual development using real-time engine modelling and powertrain co-simulation. Int. J. Engine Res. 2019, 20, 686–695. [Google Scholar] [CrossRef]
- Fathy, H.K.; Filipi, Z.S.; Hagena, J.; Stein, J.L. Review of hardware-in-the-loop simulation and its prospects in the automotive area. In Modeling and Simulation for Military Applications SPIE:62280E, Proceedings of the Defense and Security Symposium, Orlando, FL, USA, 17 April 2006; SPIE Proceedings; Schum, K., Sisti, A.F., Eds.; SPIE: Orlando, FL, USA; Kissimme, FL, USA, 2006. [Google Scholar]
- Lee, S.-Y.; Andert, J.; Neumann, D.; Querel, C.; Scheel, T.; Aktas, S.; Miccio, M.; Scahub, J.; Koetter, M.; Ehrly, M. Hardware-in-the-Loop-Based Virtual Calibration Approach to Meet Real Driving Emissions Requirements; SAE Technical Paper Series; SAE International: Warrendale, PA, USA, 2018. [Google Scholar]
- Filipi, Z.; Fathy, H.; Hagena, J.; Knafl, A.; Ahlawat, R.; Liu, J.; Jung, D.; Assanis, D.; Peng, H.; Stein, J. Engine-in-the-Loop Testing for Evaluating Hybrid Propulsion Concepts and Transient Emissions—HMMWV Case Study. SAE Trans. 2006, 115, 23–41. [Google Scholar] [CrossRef]
- Gerstenberg, J.; Hartlief, H.; Tafel, S. RDE-Entwicklungsumgebung am hochdynamischen Motorprüfstand. ATZextra 2015, 20, 36–41. [Google Scholar] [CrossRef]
- Jiang, S.; Smith, M.H.; Kitchen, J.; Ogawa, A. Development of an Engine-in-the-Loop Vehicle Simulation System in Engine Dynamometer Test Cell; SAE Technical Paper 2009-01-1039; SAE International: Warrendale, PA, USA, 2009. [Google Scholar] [CrossRef]
- Donn, C.; Zulehner, W.; Pfister, F. Realfahrtests für die Antriebsentwicklung mithilfe des virtuellen Fahrversuchs. ATZextra 2019, 24, 44–49. [Google Scholar] [CrossRef]
- Hipp, J.; Schmidt, D.; Bauer, S.; Steinhaus, T.; Beidl, C. Methodikbaukasten zur effizienten, zielgerichteten RDE-Entwicklung—Potenziale und Perspektiven. In Simulation und Test 2018; Liebl, J., Ed.; Springer Fachmedien Wiesbaden GmbH: Wiesbaden, Germany, 2019; ISBN 978-3-658-25293-9. [Google Scholar]
- Fagcang, H.; Stobart, R.; Steffen, T. A review of component-in-the-loop: Cyber-physical experiments for rapid system development and integration. Adv. Mech. Eng. 2022, 14, 168781322211099. [Google Scholar] [CrossRef]
- Picerno, M.; Lee, S.-Y.; Ehrly, M.; Schaub, J.; Andert, J. Virtual Powertrain Simulation: X-in-the-Loop Methods for Concept and Software Development. In 21. Internationales Stuttgarter Symposium; Bargende, M., Reuss, H.-C., Wagner, A., Eds.; Springer Fachmedien Wiesbaden GmbH: Wiesbaden, Germany, 2021; pp. 531–545. ISBN 978-3-658-33465-9. [Google Scholar]
- Wenig, M.; Artukovic, D.; Armbruster, C. vRDE—Virtual Real Driving Emission. In VPC—Simulation und Test 2016; Liebl, J., Beidl, C., Eds.; Springer Fachmedien Wiesbaden GmbH: Wiesbaden, Germany, 2017; ISBN 978-3-658-16753-0. [Google Scholar]
- Riccio, A.; Monzani, F.; Landi, M. Towards a Powerful Hardware-in-the-Loop System for Virtual Calibration of an Off-Road Diesel Engine. Energies 2022, 15, 646. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, H.; Motevalli, V.; Qian, Y.; Wolfe, A. Hybrid Electric Vehicle Powertrain Controller Development Using Hardware in the Loop Simulation; SAE Technical Paper Series; SAE International: Warrendale, PA, USA, 2013. [Google Scholar]
- Merl, R.; Kokalj, G.; Wultsch, B.; Klumaier, K.; Eberhard, F.; Ivarson, M. Innovative Lösungen zur Applikation hybrider Antriebe. In Experten-Forum Powertrain: Simulation und Test 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–134. [Google Scholar] [CrossRef]
- Kuznik, A.; Steinhaus, T.; Stumpp, M.; Beidl, C. Optimierung des Emissionsverhaltens innerhalb der hybriden Betriebsstrategie am Prüfstand mittels Co-Simulation. In Experten-Forum Powertrain: Simulation und Test 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 31–45. [Google Scholar] [CrossRef]
- Guse, D.; Andert, J.; Walter, S.; Meyer, N. Next Level of Testing—Extended Frontloading through Latency-optimized EiL Test Benches. MTZ Worldw. 2020, 81, 44–49. [Google Scholar] [CrossRef]
- Heusch, C.; Guse, D.; Dorscheidt, F.; Claßen, J.; Fahrbach, T.; Pischinger, S.; Tegelkamp, S.; Görgen, M.; Nijs, M.; Scharf, J. Analysis of Drivability Influence on Tailpipe Emissions in Early Stages of a Vehicle Development Program by Means of Engine-in-the-Loop Test Benches; SAE Technical Paper 2020-01-0373; SAE International: Warrendale, PA, USA, 2020. [Google Scholar]
- Schmidt, H.; Buttner, K.; Prokop, G. Methods for virtual validation of automotive powertrain systems in terms of vehicle drivability—A systematic literature review. IEEE Access 2023, 1, 27043–27065. [Google Scholar] [CrossRef]
- Mason, A.; Roberts, P.; Whelan, S.; Kondo, Y.; Brenton, L. RDE Plus—A Road to Rig Development Methodology for Complete RDE Compliance: Road to Chassis Perspective; SAE Technical Paper 2020-01-0378; SAE International: Warrendale, PA, USA, 2020. [Google Scholar]
- Roberts, P.J.; Mumby, R.; Mason, A.; Redford-Knight, L.; Kaur, P. RDE Plus—The Development of a Road, Rig and Engine-in-the-Loop Test Methodology for Real Driving Emissions Compliance; SAE Technical Paper 2019-01-0756 Series; SAE International: Warrendale, PA, USA, 2019. [Google Scholar]
- Roberts, P.; Mason, A.; Whelan, S.; Tabata, K.; Kondo, Y.; Kumagai, T.; Mumby, R.; Bates, L. RDE Plus—A Road to Rig Development Methodology for Whole Vehicle RDE Compliance: Overview; SAE Technical Paper 2020-01-0376; SAE International: Warrendale, PA, USA, 2020. [Google Scholar]
- Donateo, T.; Giovinazzi, M. Building a cycle for Real Driving Emissions. Energy Procedia 2017, 126, 891–898. [Google Scholar] [CrossRef]
- Knopov, P.S.; Samosonok, A.S. On Markov stochastic processes with local interaction for solving some applied problems. Cybern. Syst. Anal. 2011, 47, 346–359. [Google Scholar] [CrossRef]
- Kooijman, D.G.; Balau, A.E.; Wilkins, S.; Ligterink, N.; Cuelenaere, R. WLTP Random Cycle Generator. In Proceedings of the 2015 IEEE Vehicle Power and Propulsion Conference (VPPC), Montreal, QC, Canada, 19–22 October 2015; pp. 1–6, ISBN 978-1-4673-7637-2. [Google Scholar]
- Balau, A.E.; Kooijman, D.; Vazquez Rodarte, I.; Ligterink, N. Stochastic Real-World Drive Cycle Generation Based on a Two Stage Markov Chain Approach. SAE Int. J. Mater. Manf. 2015, 8, 390–397. [Google Scholar] [CrossRef]
- Ashtari, A.; Bibeau, E.; Shahidinejad, S. Using Large Driving Record Samples and a Stochastic Approach for Real-World Driving Cycle Construction: Winnipeg Driving Cycle. Transp. Sci. 2014, 48, 170–183. [Google Scholar] [CrossRef]
- Galgamuwa, U.; Perera, L.; Bandara, S. A Representative Driving Cycle for the Southern Expressway Compared to Existing Driving Cycles. Transp. Dev. Econ. 2016, 2, 589. [Google Scholar] [CrossRef]
- Della Ragione, L.; Meccariello, G. Statistical approach to identify Naples city’s real driving cycle referring to the Worldwide harmonized Light duty Test Cycle (WLTC) framework. Sustain. Dev. Plan. 2017, 210, 555–566. [Google Scholar] [CrossRef]
- Kondaru, M.K.; Telikepalli, K.P.; Thimmalapura, S.V.; Pandey, N.K. Generating a Real World Drive Cycle—A Statistical Approach; SAE Technical Paper 2018-01-0325; SAE International: Warrendale, PA, USA, 2018. [Google Scholar]
- Nies, H.; Beidl, C.; Hüners, H.; Fischer, K. Systematische Entwicklungsmethodik für eine robuste Motorkalibrierung unter RDE-Randbedingungen. In Experten-Forum Powertrain: Simulation und Test 2019; Springer: Berlin/Heidelberg, Germany, 2019; Volume 76, pp. 50–62. [Google Scholar] [CrossRef]
- Maschmeyer, H.; Beidl, C.; Düser, T.; Schick, B. RDE-Homologation—Herausforderungen, Lösungen und Chancen. MTZ Mot. Z 2016, 77, 84–91. [Google Scholar] [CrossRef]
- Faubel, L.; Lensch-Franzen, C.; Schuhardt, A.; Krohn, C. Übertrag von RDE-Anforderungen in eine modellbasierte Prüfstandsumgebung. MTZ Extra 2016, 21, 44–49. [Google Scholar] [CrossRef]
- Mayr, C.; Merl, R.; Gigerl, H.-P.; Teitzer, M.; König, D.; Stemmer, D.; Retter, F. Test emissionsrelevanter Fahrzyklen auf dem Motorprüfstand. In Simulation und Test 2018; Liebl, J., Ed.; Springer Fachmedien Wiesbaden GmbH: Wiesbaden, Germany, 2019; ISBN 978-3-658-25293-9. [Google Scholar]
- Mirfendreski, A. Powertrain Development with Artificial Intelligence: History, Work Processes, Concepts, Methods and Application Examples; Springer: Berlin/Heidelberg, Germany, 2022; ISBN 9783662638620. [Google Scholar]
- Isermann, R.; Sequenz, H. Model-based development of combustion-engine control and optimal calibration for driving cycles: General procedure and application. IFAC-PapersOnLine 2016, 49, 633–640. [Google Scholar] [CrossRef]
- Wasserburger, A.; Hametner, C. Automated Generation of Real Driving Emissions Compliant Drive Cycles Using Conditional Probability Modeling. In Proceedings of the 2020 IEEE Vehicle Power and Propulsion Conference (VPPC), Gijon, Spain, 18 November–16 December 2020; pp. 1–6, ISBN 978-1-7281-8959-8. [Google Scholar]
- Wasserburger, A.; Didcock, N.; Hametner, C. Efficient real driving emissions calibration of automotive powertrains under operating uncertainties. Eng. Optim. 2021, 55, 140–157. [Google Scholar] [CrossRef]
- Millo, F.; Piano, A.; Zanelli, A.; Boccardo, G.; Rimondi, M.; Fuso, R. Development of a Fully Physical Vehicle Model for Off-Line Powertrain Optimization: A Virtual Approach to Engine Calibration; SAE Technical Paper Series; SAE International: Warrendale, PA, USA, 2021. [Google Scholar]
- Arya, P.; Millo, F.; Mallamo, F. A fully automated smooth calibration generation methodology for optimization of latest generation of automotive diesel engines. Energy 2019, 178, 334–343. [Google Scholar] [CrossRef]
- Meli, M.; Pischinger, S.; Kansagara, J.; Dönitz, C.; Liberda, N.; Nijs, M. Proof of Concept for Hardware-in-the-Loop Based Knock Detection Calibration; SAE Technical Paper 2021-01-0424; SAE International: Warrendale, PA, USA, 2021. [Google Scholar]
- Neumann, D.; Steinbach, M.; Kutzner, T.; Lehmann, A.; Kassem, V.; Dreiser, M. Model supported calibration process for future RDE requirements. In 16. Internationales Stuttgarter Symposium; Bargende, M., Reuss, H.-C., Wiedemann, J., Eds.; Springer Fachmedien Wiesbaden GmbH: Wiesbaden, Germany, 2016; pp. 565–579. ISBN 978-3-658-13254-5. [Google Scholar]
- Böhmer, M. Simulation der Abgasemissionen von Hybridfahrzeugen für Reale Fahrbedingungen. Ph.D. Dissertation, Rheinisch-Westfälische Technische Hochschule Aachen, Aachen, Germany, 2017. [Google Scholar]
- Morcinkowski, B.; Adomeit, P.; Mally, M.; Esposito, S.; Walter, V.; Yadla, S. Emissionsvorhersage in der Entwicklung ottomotorischer EU7-Antriebe. In Experten-Forum Powertrain: Ladungswechsel und Emissionierung 2019; Liebl, J., Ed.; Springer Fachmedien Wiesbaden GmbH: Wiesbaden, Germany, 2020; pp. 11–23. ISBN 978-3-658-28708-5. [Google Scholar]
- Wang, W.; Xia, F.; Nie, H.; Chen, Z.; Gong, Z.; Kong, X.; Wei, W. Vehicle Trajectory Clustering Based on Dynamic Representation Learning of Internet of Vehicles. IEEE Trans. Intell. Transport. Syst. 2021, 22, 3567–3576. [Google Scholar] [CrossRef]
- Shi, X.; Wong, Y.D.; Chai, C.; Li, M.Z.-F.; Chen, T.; Zeng, Z. Automatic Clustering for Unsupervised Risk Diagnosis of Vehicle Driving for Smart Road. IEEE Trans. Intell. Transport. Syst. 2022, 23, 17451–17465. [Google Scholar] [CrossRef]
- Novotny, G.; Liu, Y.; Wober, W.; Olaverri-Monreal, C. Autonomous Vehicle Calibration via Linear Optimization. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 527–532, ISBN 978-1-6654-8821-1. [Google Scholar]
- Krysmon, S.; Dorscheidt, F.; Claßen, J.; Düzgün, M.; Pischinger, S. Real Driving Emissions—Conception of a Data-Driven Calibration Methodology for Hybrid Powertrains Combining Statistical Analysis and Virtual Calibration Platforms. Energies 2021, 14, 4747. [Google Scholar] [CrossRef]
- Claßen, J.; Pischinger, S.; Krysmon, S.; Sterlepper, S.; Dorscheidt, F.; Doucet, M.; Reuber, C.; Görgen, M.; Scharf, J.; Nijs, M.; et al. Statistically supported real driving emission calibration: Using cycle generation to provide vehicle-specific and statistically representative test scenarios for Euro 7. Int. J. Engine Res. 2020, 21, 1783–1799. [Google Scholar] [CrossRef]
- Claßen, J. Entwicklung Statistisch Relevanter Prüfszenarien zur Bewertung der Fahrzeug-Emissionsrobustheit unter Realen Fahrbedingungen. Ph.D. Dissertation, Rheinisch-Westfälische Technische Hochschule Aachen, Aachen, Germany, 2022. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. IDA 2007, 11, 561–580. [Google Scholar] [CrossRef]
- Serrà, J.; Arcos, J.L. An empirical evaluation of similarity measures for time series classification. Knowl. Based Syst. 2014, 67, 305–314. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Astels, S. HDBSCAN: Hierarchical density based clustering. JOSS 2017, 2, 205. [Google Scholar] [CrossRef]
- Krysmon, S.; Claßen, J.; Pischinger, S.; Trendafilov, G.; Düzgün, M.; Dorscheidt, F. RDE Calibration—Evaluating Fundamentals of Clustering Approaches to Support the Calibration Process. Vehicles 2023, 5, 404–423. [Google Scholar] [CrossRef]
- Petitjean, F.; Forestier, G.; Webb, G.I.; Nicholson, A.E.; Chen, Y.; Keogh, E. Faster and more accurate classification of time series by exploiting a novel dynamic time warping averaging algorithm. Knowl. Inf. Syst. 2016, 47, 1–26. [Google Scholar] [CrossRef]
- Abanda, A.; Mori, U.; Lozano, J.A. A review on distance based time series classification. Data Min. Knowl. Disc. 2019, 33, 378–412. [Google Scholar] [CrossRef]
- Rani, S.; Sikka, G. Recent Techniques of Clustering of Time Series Data: A Survey. IJCA 2012, 52, 1–9. [Google Scholar] [CrossRef]
- Jung, Y.; Park, H.; Du, D.-Z.; Drake, B.L. A Decision Criterion for the Optimal Number of Cluster in Hierarchical Clustering. J. Glob. Optim. 2003, 25, 91–111. [Google Scholar] [CrossRef]
- Na, S.; Xumin, L.; Yong, G. Research on k-means Clustering Algorithm: An Improved k-means Clustering Algorithm. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics (IITSI), Ji’an, China, 2–4 April 2010; pp. 63–67, ISBN 978-1-4244-6730-3. [Google Scholar]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means Algorithm: A Comprehensive Survey and Performance Evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Wiedenbeck, M.; Züll, C. Klassifikation mit Clusteranalyse: Grundlegende Techniken Hierarchischer und K-Means-Verfahren. GESIS-How-to(10). 2001. Available online: https://nbn-resolving.org/urn:nbn:de:0168-ssoar-201428 (accessed on 1 January 2024).
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Moulavi, D.; Jaskowiak, P.A.; Campello, R.J.G.B.; Zimek, A.; Sander, J. Density-Based Clustering Validation. In Proceedings of the 14th SIAM International Conference on Data Mining (SDM), Philadelphia, PA, USA, 24–26 April 2014; pp. 839–847. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Rand, W.M. Objective Criteria for the Evaluation of Clustering Methods. J. Am. Stat. Assoc. 1971, 66, 846. [Google Scholar] [CrossRef]
- Steinley, D. Properties of the Hubert-Arabie adjusted Rand index. Psychol. Methods 2004, 9, 386–396. [Google Scholar] [CrossRef]
- Batista, G.E.A.P.A.; Wang, X.; Keogh, E.J. A Complexity-Invariant Distance Measure for Time Series. In Proceedings of the Eleventh SIAM International Conference on Data Mining, SDM 2011, Mesa, AZ, USA, 28–30 April 2011; pp. 699–710. [Google Scholar] [CrossRef]
- Petitjean, F.; Ketterlin, A.; Gançarski, P. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognit. 2011, 44, 678–693. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}