1. Introduction
Due to increasing environmental pollution and traffic congestion, many strategies on giving some priority to the urban transportation system development have recently been formed. Therefore, bus transit planning captured increasing attention among researchers. A wide area of research is covered by public transit planning and prevention which is divided into a sequence of several distinguished steps, namely (1) route design, (2) setting of frequency, (3) timetabling, (4) vehicle scheduling, (5) crew scheduling, and finally (6) transportation system protection and resilience [
1,
2,
3].
A bus rapid transit system is designed to improve urban mobility and combines the best features of railways with the flexibility and cost advantages of roadway transit. In cities around the world, bus rapid transit (BRT) helps people move more reliably and quickly due to having less congestion with usual traffic because of their dedicated lanes and stations [
4]. In ref. [
5], the authors represented the advantages of Dar es Salaam BRT which were categorized into economic, social, environmental, political, and urban categories. For example, it has been recently shown that BRT systems have many advantages including affordability, high capacity vehicles, and reliable service [
6]. Additionally, ref. [
7] introduced some advantages of BRT systems such as alleviating traffic congestion, higher flexibility, better security, user-friendly, etc. In addition to the mentioned advantages, BRT is a flexible, rubber-tired rapid-transit mode that combines vehicles, stations, running ways, fare, ITS, and services component parts into an integrated network with a strong positive identity that provokes an unparalleled prototype [
4,
5,
8,
9,
10,
11,
12,
13]. It is why BRT has been successfully implemented in many places such as Australia, Iran, South America, and Europe while gaining popularity in North America.
In public transport, the system should meet the demand by providing services to passengers while minimizing one or some objectives such as passengers waiting time, vehicle traveling time, or operational costs (vehicle costs and passenger costs) [
2,
14]. Static transportation systems were widely studied, e.g., [
15,
16,
17], where parameters of the model are fixed or change periodically given known trends. However, passengers’ parameters such as demand, arrival time, and so on are subject to uncertainty and cannot be predicted by the transportation system controller. Thus, static schedules can lead to inefficiencies, long wait times, and high operational costs that in turn would lead to unreliable transportation systems and a significant drop in using such systems [
18,
19].
To address data uncertainty and prediction errors, quantitative and predictive approaches have been improved to increase the data collection and prediction precision [
20,
21,
22,
23,
24]. However, uncertainty is inevitable, and several uncertainty management advancements have been made in recent years. In particular, robust optimization (RO) is an approach to deal with data uncertainty by optimizing for the worst-case scenario. Recent RO studies have shown further advancements in theory, i.e., [
25,
26], and applications. i.e., [
27,
28]. Alternatively, stochastic programming (SP) is a branch of mathematical programming to address uncertainty by considering a predefined set of scenarios. SP models occur in most areas of science and engineering from medicine to finance [
29] and are less conservative than RO models. In particular, ref. [
30] proposed a stochastic model for vehicle scheduling in public bus transport. A more recent extension to SP is the scenario-based approach in which the objective of the scenario-based problems is to find an expected solution that performs under all scenarios. The scenario-based approach has shown applicability benefits in many real-world applications and is easy to deal with in practical situations [
31].
Various stochastic-based approaches have been studied in public transportation, especially in BRT scheduling, to cope with fluctuating parameters involved in scheduling the departure time of buses. Among uncertain parameters affecting bus scheduling, most researchers in the last decade proposed approaches where the passengers’ demand for buses is considered unknown and volatile. Particularly, ref. [
19] addresses demand uncertainty in BRT using predictive methods and consider the impact of dynamic scheduling on passenger waiting times. Wang et al. [
32] developed a data-driven scheme for real-time bus scheduling optimization to minimize the average waiting time of passengers with unknown demand. Kumar et al. [
33] dynamically dispatched buses under uncertain demand to minimize the number of trips to maximize the benefit of operators. A recent study by the authors of [
34] provided a robust-stochastic model to solve the vehicle scheduling problem, which is extendable to the BRT scheduling problem, with a time window under uncertain demand. An optimization model of the bus departure time and speed scheduling was proposed in [
35] to minimize the total waiting time of passengers, subject to uncertain demand. Tang et al. [
36] studied the impacts of fluctuating passenger demand on bus scheduling and operational strategies.
Alternatively, researchers have shown that uncertain passenger arrival times can also significantly impact bus scheduling and operational strategies in transportation systems. In particular, a model for the school bus scheduling problem with stochastic travel time was proposed in [
37]. In ref. [
38], the authors considered stochastic passenger arrival times and proposes a BRT scheduling procedure based on arrival data-based passenger assignment algorithm. Zhang et al. [
39] proposed a two-step model of coarse prediction and calibration to predict the passenger flow in real time. The authors of [
40] built a stochastic model for BRT scheduling subject to a risk threshold under time-dependent stochastic travel time and ref. [
41] proposed a stochastic bus scheduling model with normally distributed travel time and uncertain demand. Li et al. [
42] considered uncertain passenger demand and travel time among stops and proposed a timetable optimization model to cope with uncertainties.
The proposed scheduling models are mainly large-scale combinatorial problems that are difficult to solve in polynomial time. The solution methodologies proposed in the literature are mainly categorized into two groups: namely heuristic methods and exact methods. Heuristic algorithms are fast in general and provide a solution that is not necessarily a global optimal solution. Several heuristic-based algorithms such as multi-objective programming, genetic algorithm [
43], tabu search [
44], simulated annealing [
37,
45], artificial immune algorithm [
46], simulation-based algorithms [
47], etc. were employed to solve BRT scheduling problems.
Unlike heuristics, exact methodologies provide a global optimal solution although might be more time-consuming. Due to the practical and computational challenges of such algorithms, they have been less studied in the literature compared to heuristics. In particular, ref. [
48] proposed a connection-based network flow or set partitioning algorithm for solving bus scheduling problems. Furthermore, the Lagrangian approach [
49] and column-generation strategy [
50] have been demonstrated to be effective approaches to solve BRT scheduling considering timetables. However, these methods may not be able to solve all instances and need further investigation.
In this paper, we contribute to the literature of BRT scheduling and present a more comprehensive BRT scheduling model considering uncertainty. In particular, we not only consider the uncertainty in passengers’ demand and arrival time, but we also incorporate stochastic parameters such as (i) running times between stops because these times can be easily impacted by traffic conditions and are not predictable, (ii) passenger traveling time in all stops, because in many developing countries there is not a disciplined program, or even if there is a disciplined program, it may be invoked by several unexpected events such as mismanagement, traffic, passenger immoralities, etc. In this study, we propose a dynamic arithmetic model which can depict the state of the system and correlation for each stochastic parameter during time periods. To more accurately model the problem, we propose a mixed-integer nonlinear programming (MINLP) model aiming to minimize the total operational cost. Furthermore, we implement an outer approximation algorithm to solve the proposed MINLP model for larger instances by providing efficient linear cuts. The main contributions of this paper are highlighted as follows:
We propose a stochastic MINLP program that more accurately models the characteristics of BRT scheduling problems, especially the cost function.
The proposed stochastic model considers uncertain parameters to reflect the uncertain nature of transportation systems more accurately. In particular, we consider passenger-related uncertain parameters such as demand, arrival time, the running time between buses, and traveling time.
We propose an effective scenario-generation method to represent the reality of transportation systems by generating valid representative scenarios for the stochastic model.
We implement a solution methodology based on an outer approximation (OA) algorithm to effectively solve the proposed MINLP model. We verify the efficiency of the OA algorithm in our numerical example for large enough instances.
The rest of the paper is organized as follows.
Section 2 describes the problem.
Section 3 introduces the scenario-generation method.
Section 4 represents the solution methodology. In
Section 5, the computational results are demonstrated.
Section 6 discusses the managerial benefits of the proposed approach. Finally,
Section 7 concludes the paper.
2. Problem Statement
In this study, we aim to find a solution for buses departure schedules on a one-way route with stops. Running time between stops and passenger’s arrival time into stops are considered as stochastic parameters, and in order to deal with this problem in the real world, some scenarios are generated. The model presented in this paper can be viewed as an extension of the work in [
51]. The model in [
47] is deterministic where all parameters are assumed to be known in advance. However, the proposed model takes into account uncertain parameters such as running time between stops, the arrival rate of passengers, passengers’ alighting fraction, and so on. Such stochastic programming provides a more realistic model for BRT scheduling that can more efficiently handle inevitable changes in the predicted parameters.
2.1. Assumption
For approaching the reality model, some assumptions are considered as follows:
Running time between stops is stochastic (i.e., buses do not run at a constant speed, as the running time between stops is uncertain).
The arrival rate of passengers at stops, passenger alighting fraction in each stop, and passengers’ demand for buses are stochastic.
The route is a one-way straight line with stops where buses cannot overtake each other.
The dwelling time of buses at all stops is equal because each bus waits at stops to be loaded to capacity or less. So, dwelling time is almost constant or has extremely slight fluctuations which can be easily ignored, compared to other parameters.
2.2. Notations
Table 1 presents the notations and defines sets, parameters, and decision variables considered in our mathematical model.
2.3. Mathematical Model
The model proposed in the paper can be considered as an extension to that in [
51]. So, extending the objective function and adding or altering some constraints and equations are required. The present paper attempts to answer the question of when each bus has to depart from any stop to minimize the total passenger time. The mathematical programming model is presented below:
The objective function of the mathematical model is a combination of the waiting time and traveling time of passengers in all scenarios. The first part of the objective function deals with passengers waiting time which sums the waiting time of all passengers in all stops where both recently arrived passengers and left behind passenger waiting times are taken into consideration. When a bus is loaded to capacity while departing the stop, some passengers cannot board the bus. So, there is an additional waiting time for them, and we assume these passengers wait for the next oncoming bus. The second part of the objective function is passenger traveling time which includes the running time of vehicles between stops and passenger dwelling time at stops. Constraint (2) states that the arrival time of vehicle i at stop k equals its departure time from stop k − 1 plus the running time of the vehicle between these two consecutive stops (i.e., stop k − 1 and k). Constraint (3) shows the number of passengers willing to board vehicle i at stop k is equivalent to the passenger arrival rate multiplied by the headway between two consecutive vehicles plus the number of passengers left behind by vehicle i − 1 at stop k. Constraint (4) states that the number of passengers alight vehicle i at stop k equals to passenger alighting fraction at stop k multiplied by the load in vehicle i departing stop k − 1.
In constraints (5) to (8), the load in bus i departing stop k is restricted. Constraint (5) represents that the load in bus i departing stop k is equal to or less than the demand for bus i at stop k. When bus i at stop k is not at the full capacity (i.e., ), then constraints (5) and (6) are the binding (). Constraint (7) represents that the load in bus i departing stop k is equal to or less than the passenger capacity of the bus. When bus i at stop k is at the full capacity (i.e.,), then constraints (7) and (8) are the bindings (). Constraint (9) shows demand for bus i at stop k which is equal to the load on the bus i departing stop k added to the number of passengers willing to board the bus. In constraint (10), the departure time of bus i at stop k, which is equal to or more than the dwell time of each bus at stops plus the arrival time of bus i at stop k, is restricted. Constraint (11) shows that the departure time of vehicle i at stop k is less than the departure time of vehicle i + 1 at stop k − 1 plus the running time of vehicle i between stop k and k − 1. Constraint (12) shows that the number of passengers left behind at stop k is equivalent to the demand at the same stop for vehicle i less the capacity of bus i. Otherwise, when the capacity of vehicle i is more than the load in bus i departing stop k, then the number of passengers left behind at stop k is equal to zero. Constraint (13) limits to be valued by just 0 or 1, as defined above. Constraint (14), is the non-negativity constraint imposed on the arrival and departure times of buses. Constraint (15) imposes integrality restrictions on integer variables such as the number of passengers willing to board the buses, the number of passengers in buses alighting at stops, passenger capacity of buses, and passengers left behind. The proposed stochastic models (1)–(15) is an MINLP model due to the nonlinear terms and in the objective function (1).
3. Scenario-Generation Method
Most previous models of transportation programming problems are deterministic and assume that parameters are known. However, on the other hand, stochastic models take into consideration parameter uncertainties and represent the real nature of transportation programming more realistically. In stochastic programming, the uncertain parameters are assumed to be known only by their probability distribution functions. In the case of stochastic programming, we confront random parameters with their related continuous distribution functions, while most mathematical models with such parameters cannot be solved, and solution methods need discrete distributions. So, they have to be approximated by a discrete distribution, which in turn limits the number of outcomes into an identical interval [
52]. The method in which discrete outcomes are obtained for random variables is called scenario tree generation [
53].
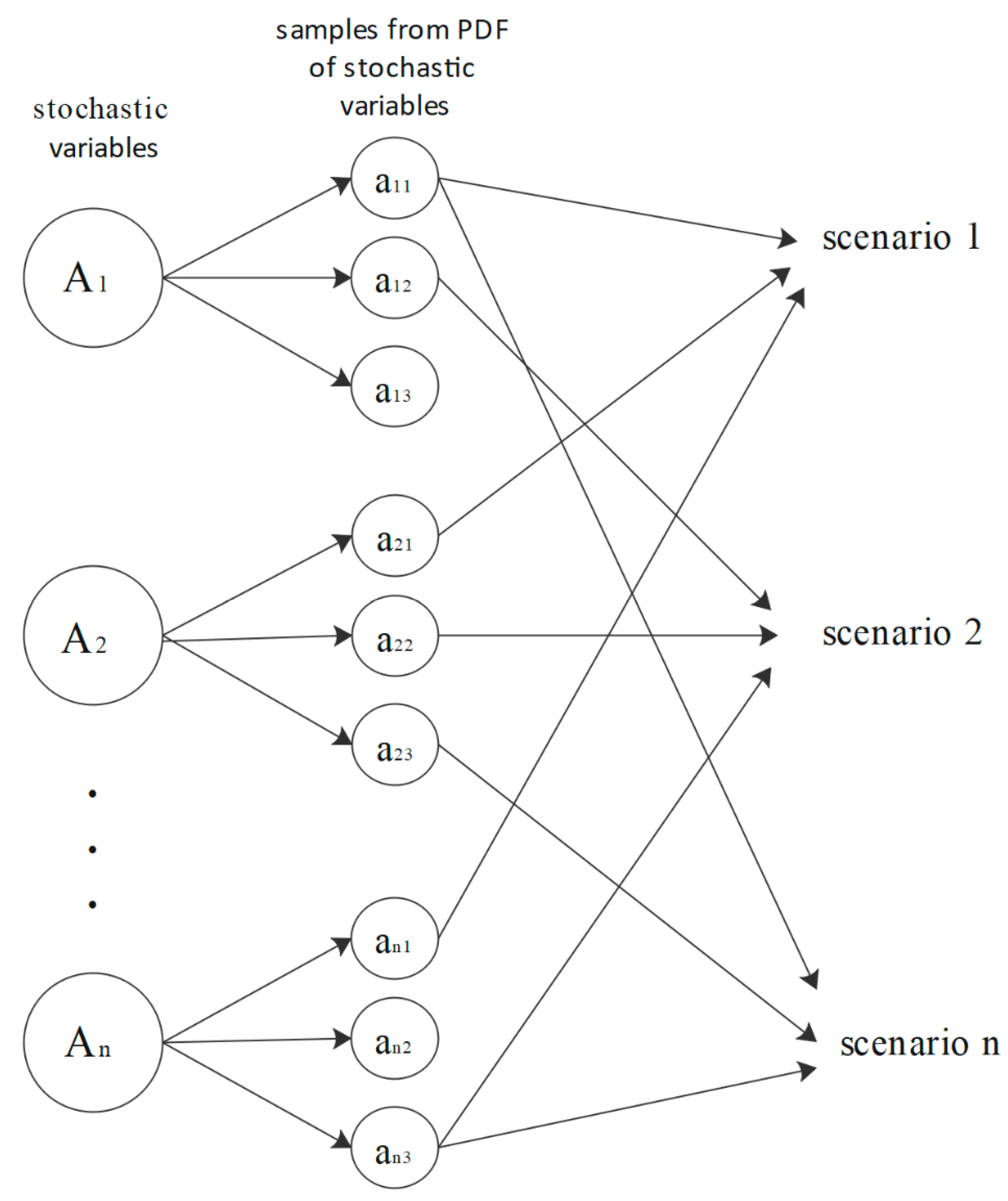
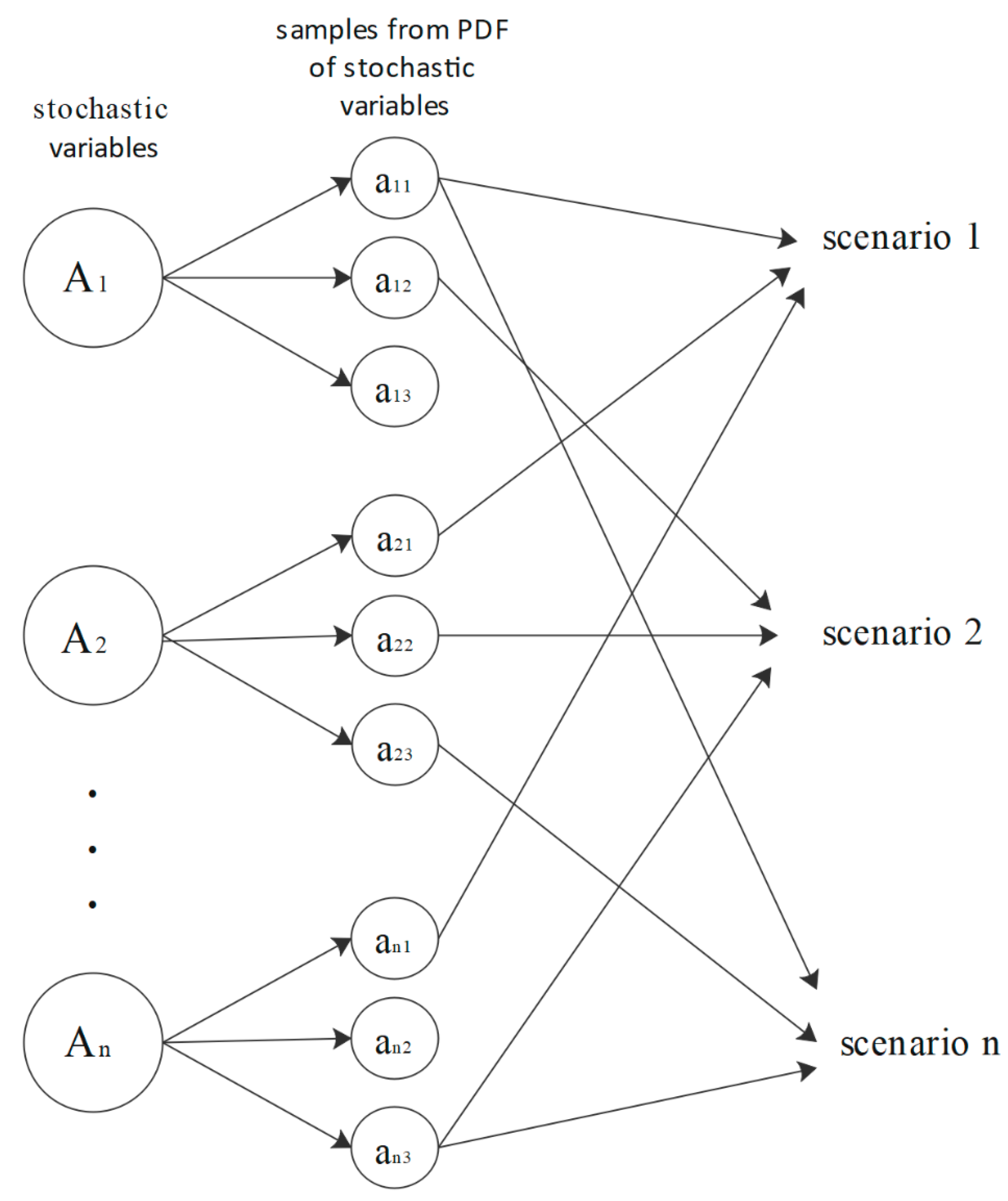
A scenario is defined as a set of values for the stochastic variables and is based on a decision tree, in which each path represents a distinct possible scenario and the values assigned to stochastic variables. The number of scenarios exponentially grows with the number of stages. In order to reduce computation cost, some techniques are recommended as follows:
Replacing stochastic variables by their expected values; therefore, just one scenario is considered.
Considering the most common scenarios and ignoring the rest.
Monte Carlo sampling.
Latin hypercube sampling.
Scenario generation is completely important in terms of reducing computation cost because it just deals with the most common situations. The main scenario-generation methods are sampling, statistical approaches, and simulation.
In this part, we aim to introduce a method for scenario generation for problems dealing with uncertain parameters which in turn can be considered as a cooperation of all methods above. A specific scenario shows the outcomes of all stochastic parameters in a particular event, so for problems with an unlimited number of parameter outcomes, we will confront an infinite number of scenarios that cover all possible consequences. However, studying all these scenarios is not possible and is not even the purpose of problem solvers; they just aim to identify the most common ones. Here we present the steps which are required to generate scenarios, and then a criterion for evaluating scenarios is introduced.
We have proposed certain assumptions for using this method as follows
Replacing stochastic variables by their expected values; therefore, just one scenario is considered.
Considering the most common scenarios and ignoring the rest.
Monte Carlo sampling.
Latin hypercube sampling.
Here we introduce the steps of the scenario-generation method:
Finding a well-suited PDF for each stochastic parameter using related historical data.
Picking out m random values from PDF of each parameter, based on problem requirements.
Every random combination of these samples makes a scenario.
As
Figure 1 shows, we can generate as many as samples we need from PDF of stochastic variables. So, an infinite number of scenarios for stochastic problems can be generated. Finding a multi-variable probability distribution function for such problems can be studied in another paper. Here we need to introduce an evaluation criterion for every random scenario made, so we revert to our only knowledge of stochastic parameters, PDF of parameters
Each sample consists of
m parameters and we need
n stochastic parameter(s) to construct a scenario, so
represents
sample of
stochastic parameter, because in distributions with continuous distribution functions the probability of
takes zero value, a symmetric interval of
around
is defined to calculate the probability for it. So, the
g index can be calculated for every single parameter of
j. A lower value for the g index of every sample represents that this sample consists of values with higher possibility. Scenarios are a combination of these stochastic parameters, and also an
index for every scenario is defined as follows:
The index has this advantage to be considered as a criterion; if a scenario consists of values with higher probability, then the index is lower for that.
Application of Proposed Method in Our Model
To apply the proposed method to generate and evaluate our scenarios, we need to identify our stochastic parameters. In this mathematical model, we deal with three stochastic parameters as follows: passenger demand, passengers’ arrival rate at stops, passengers’ alighting fraction, and running time of buses between stops. Using historical data in
Table 2, a well-suited distribution function (considering Anderson–Darling and P-value parameters) for each stochastic parameter can be obtained. These historical data are those presented in [
51]. From
Table 2, it is observed that passengers’ arrival rate has Lognormal distribution (17) with scale = −1.64466 and location = 0.70687.
Similarly, passengers’ alighting fraction has a lognormal distribution (17) with scale = 0.30014 location = 0.66970.
Running time between stops has a Weibull distribution (19) with shape (
k) = 6.65525 and scale (
λ) = 3.04438.
Next, we need to provide a sample of 20 random values for every stochastic parameter of the model. So, we randomly generate these samples using the inverse transformation method (ITM) presented in
Appendix B.
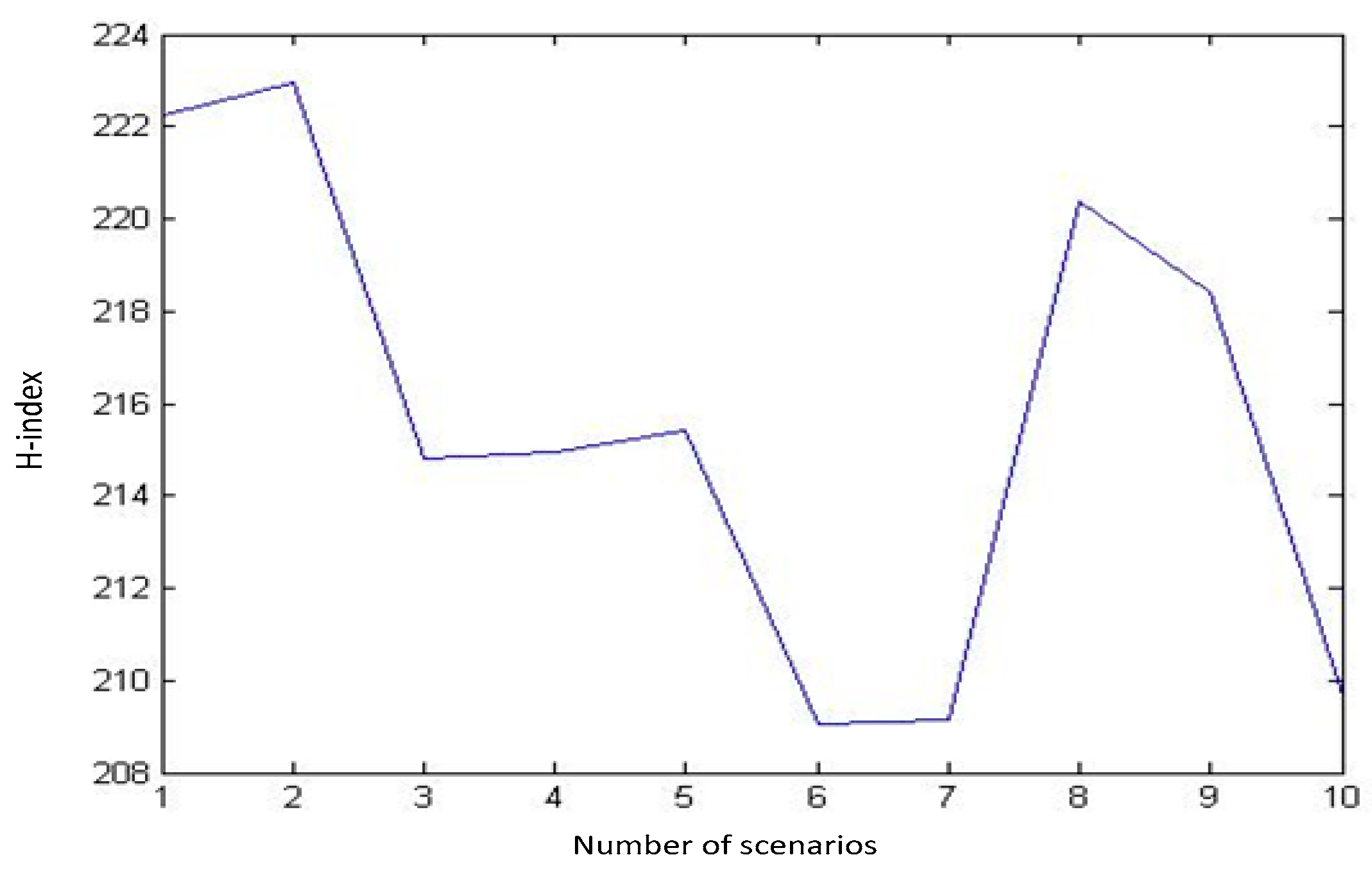
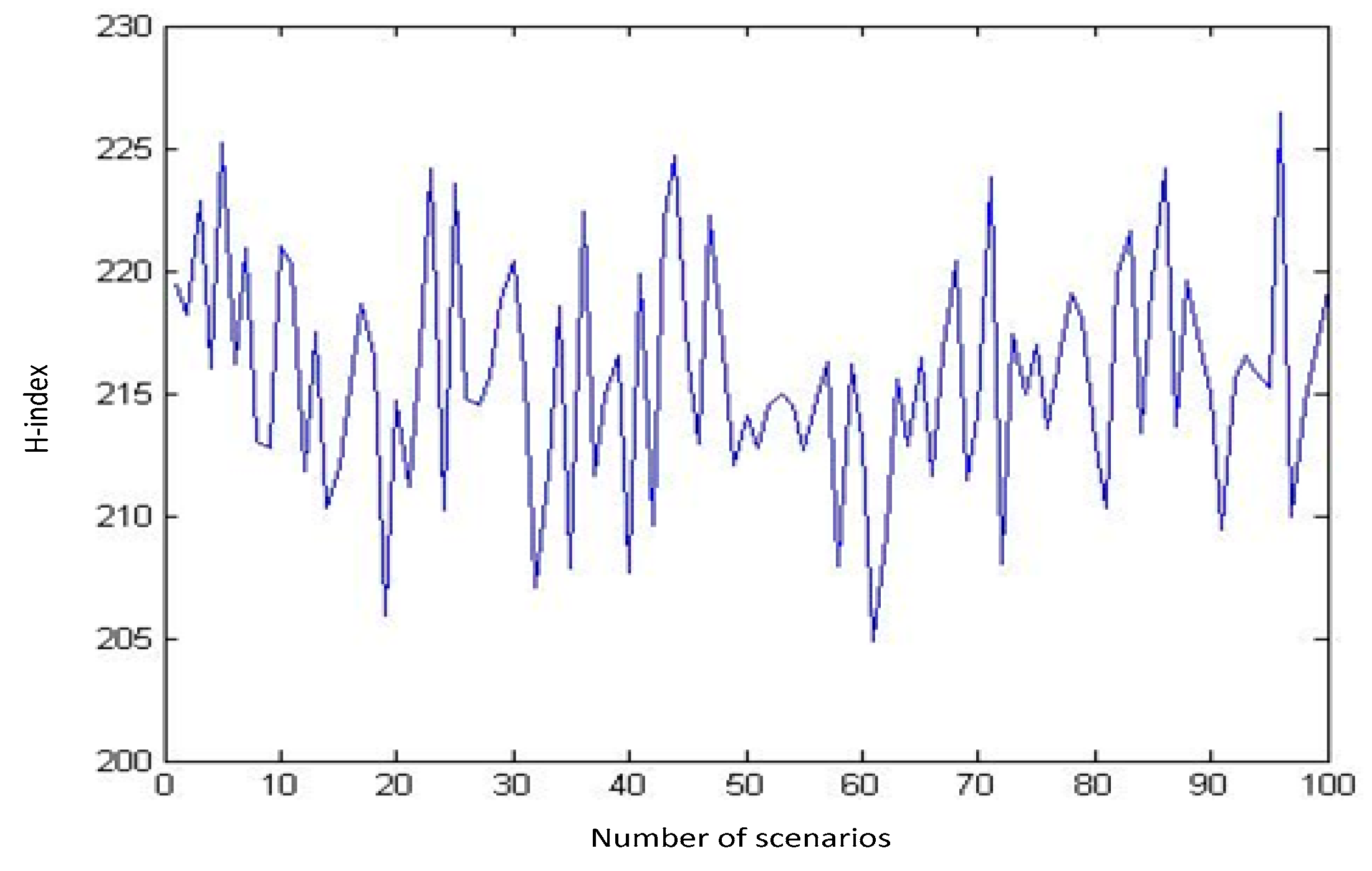
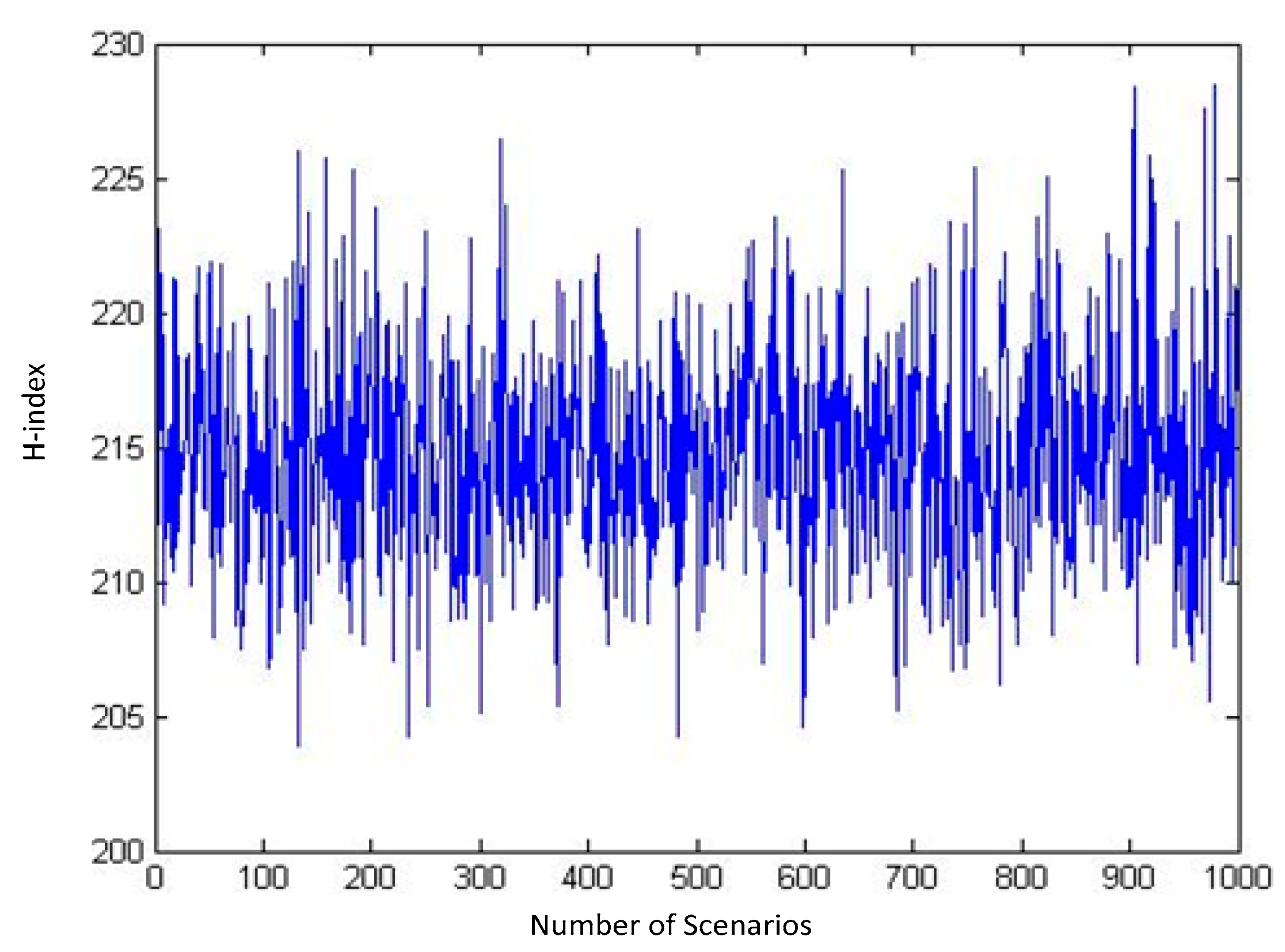
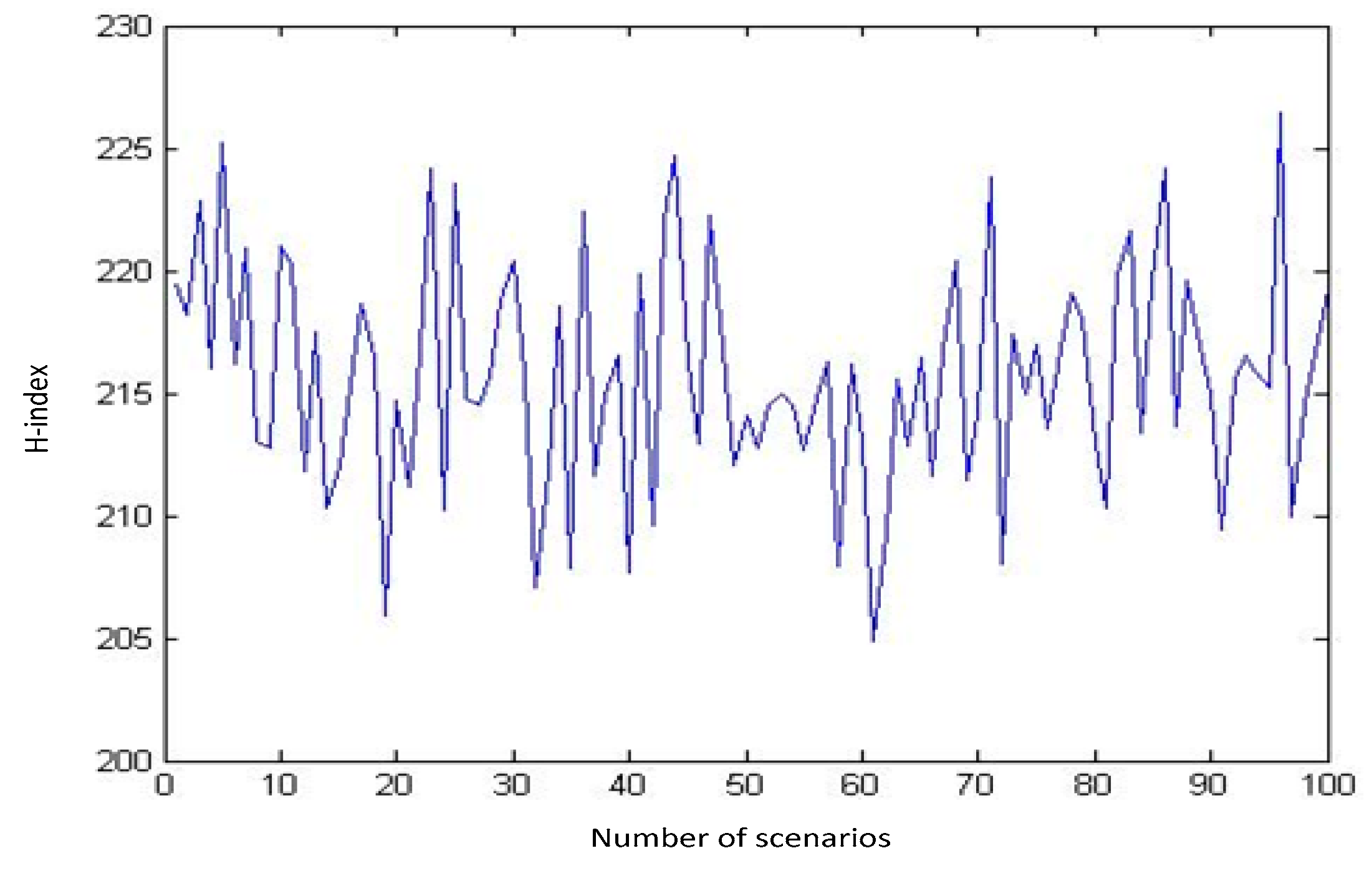
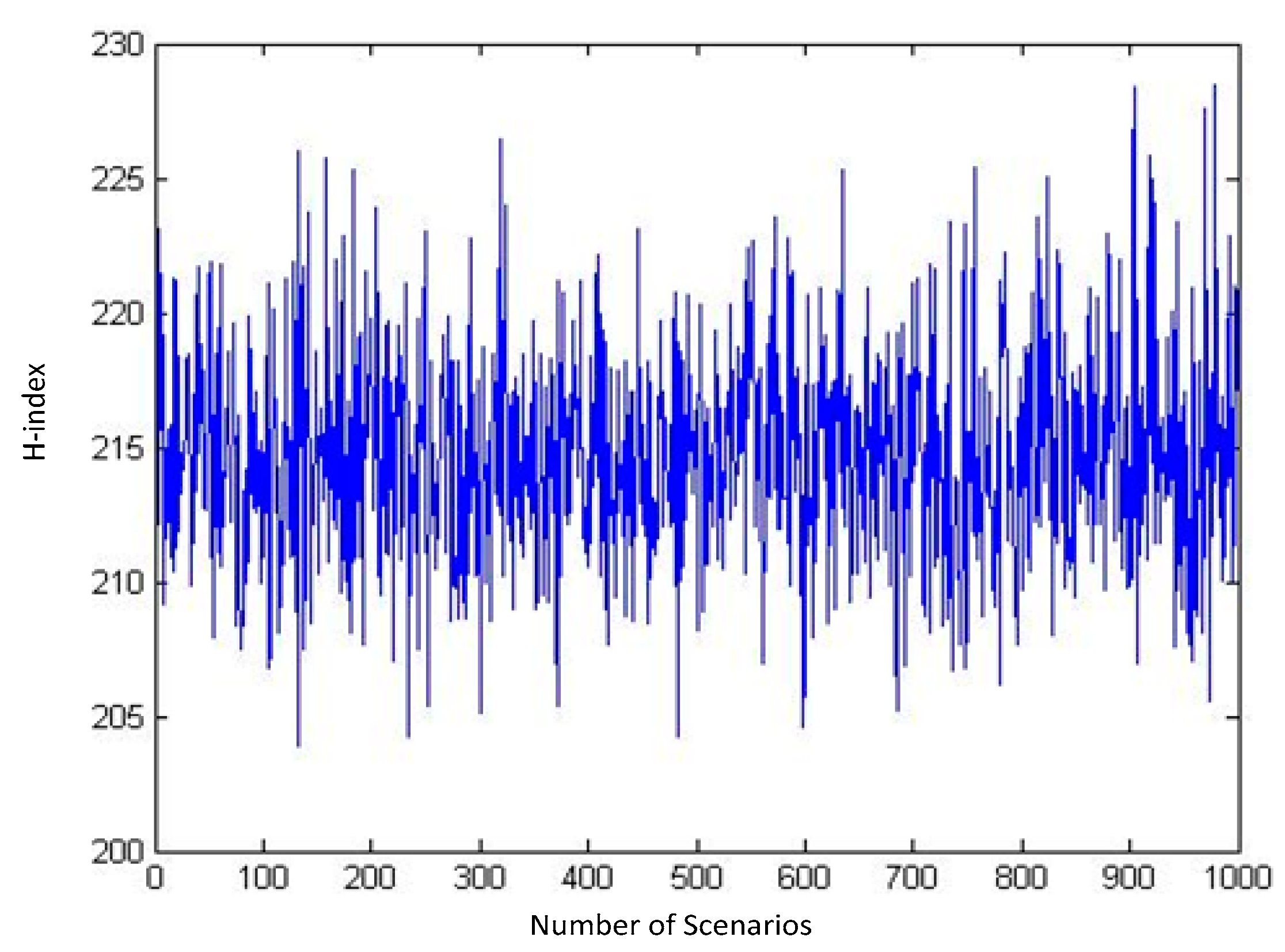
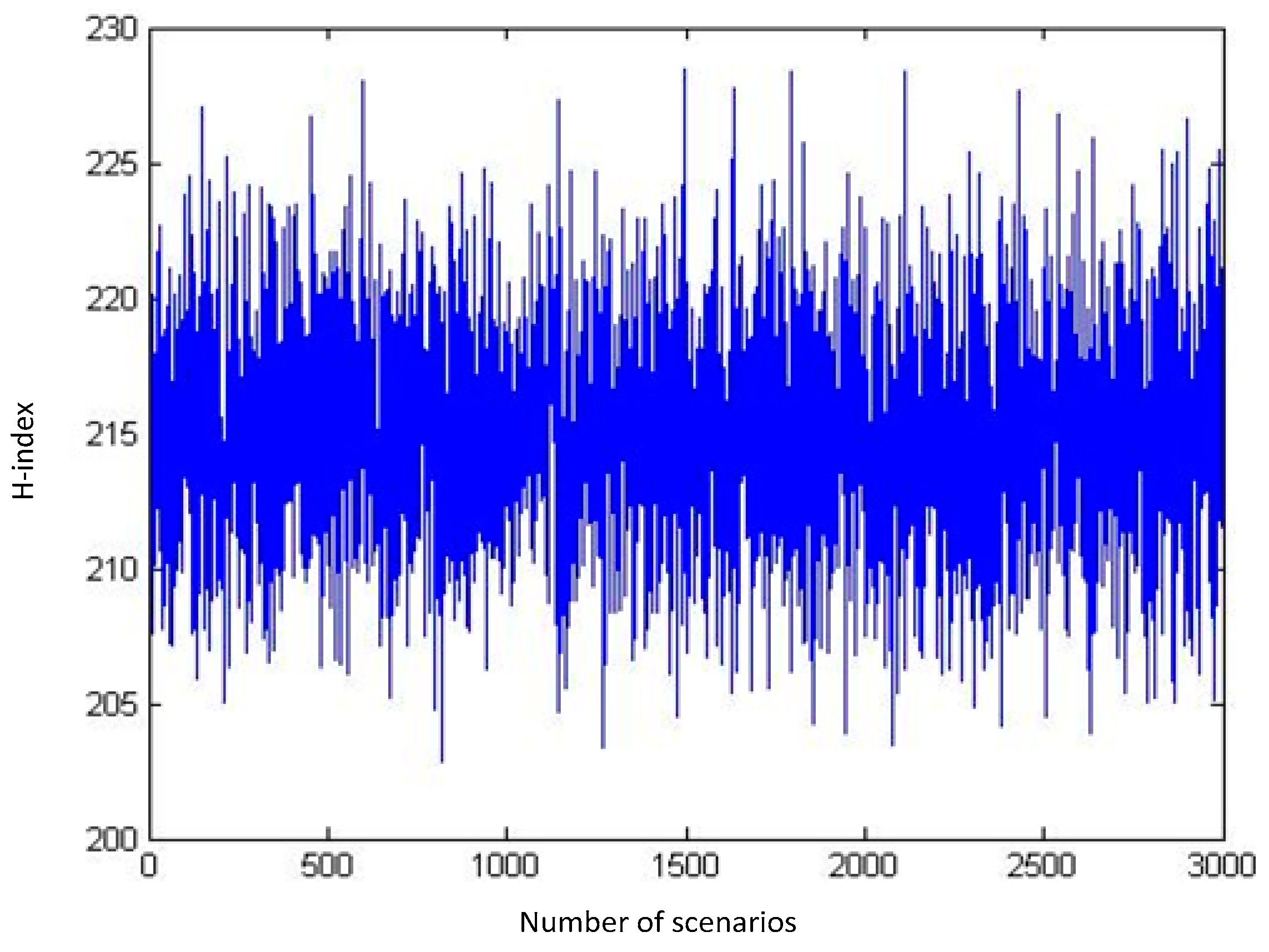
Every combination of these samples makes a scenario. Using MATLAB, we generate numerous scenarios and calculate the H-index for those scenarios. The outputs of our runs for a sequence of 10, 100, 1000, and 3000 distinct random scenarios are shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5 respectively.
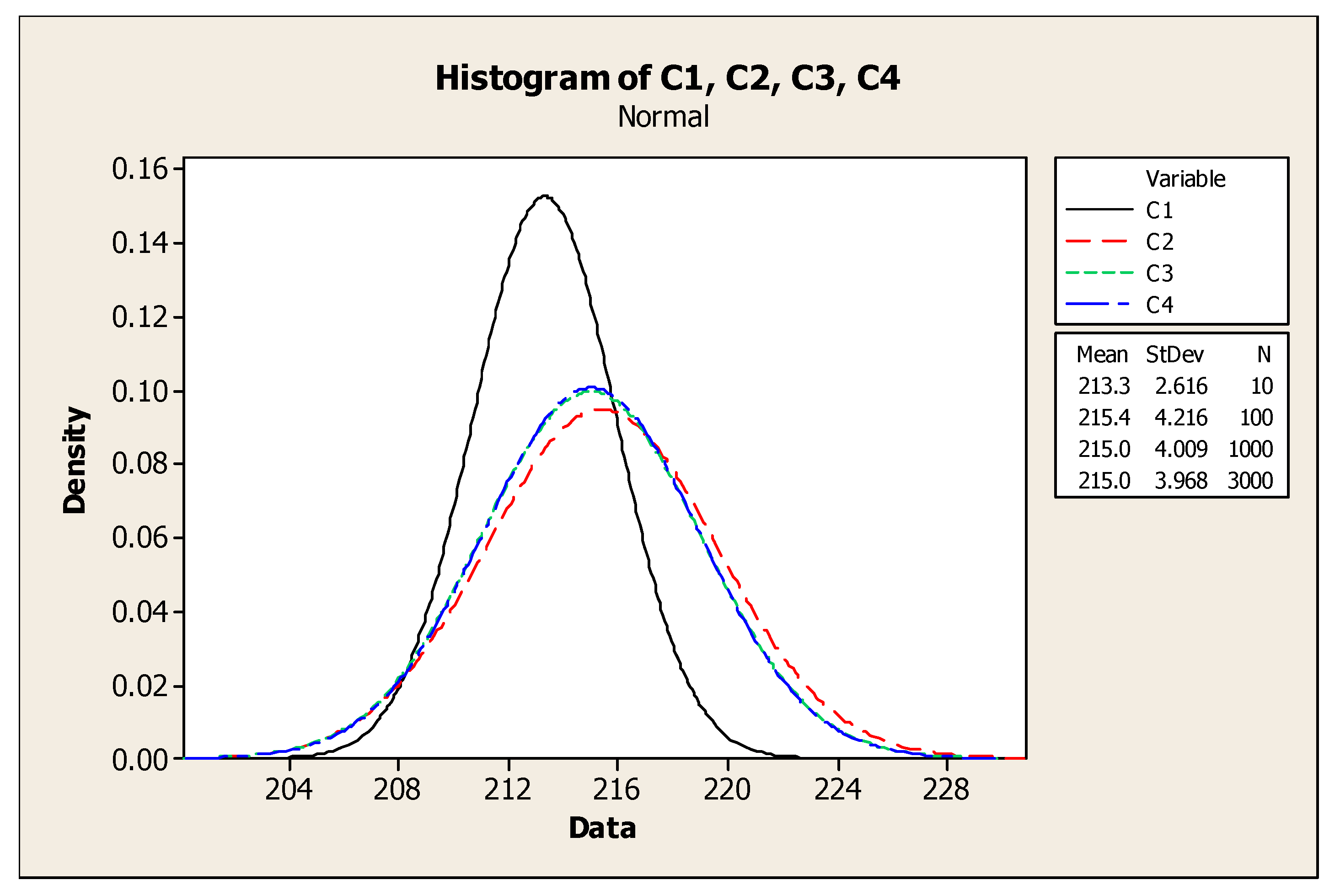
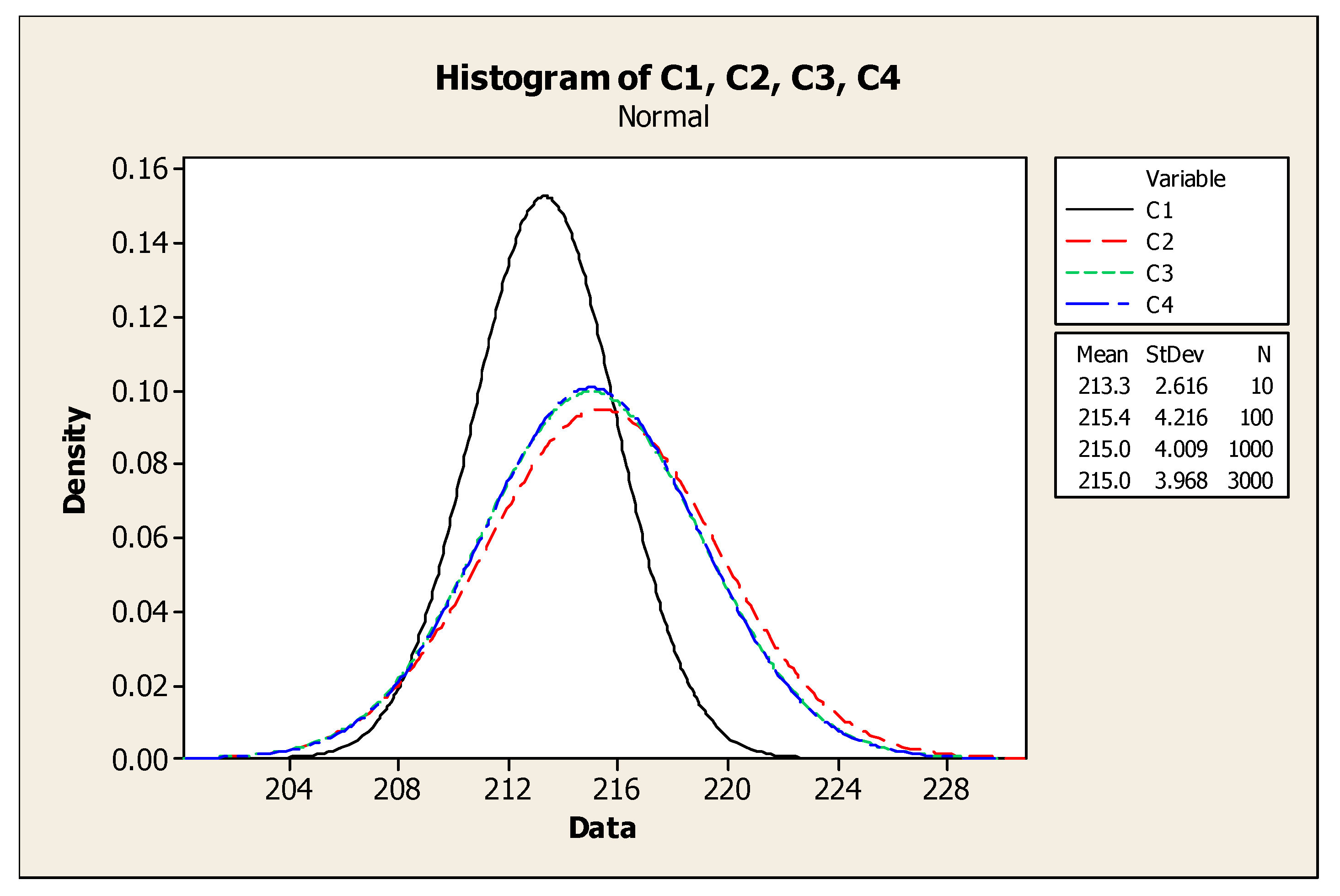
It can be inferred from these diagrams that as the number of randomly generated scenarios grows, the H-index tends to follow a normal distribution (
Figure 6).
As shown, by changing the number of scenarios from 1000 to 3000 only small changes in Mean and StDev of distribution are caused. So, 1000 scenarios can be enough to fit a normal distribution function for H-indexes. Using a sample of 1000 scenarios, we have fitted a normal distribution for the H-index with a mean of 215 and StDev of 4.009 in our problem as shown in
Figure 6. Therefore, as we look for scenarios with the highest possibility to happen, we should go through the scenarios with a lower H-index. Here in our problem, we choose four scenarios with H-indexes in the interval [μ-3σ, μ-2.5σ], which equals to [202.973, 204.97], and with an identical approximation based on the expert judgments and also in order to avoid bias in further analysis, we can consider equal probability for each of these four scenarios. The data for all four scenarios are available in
Appendix C.
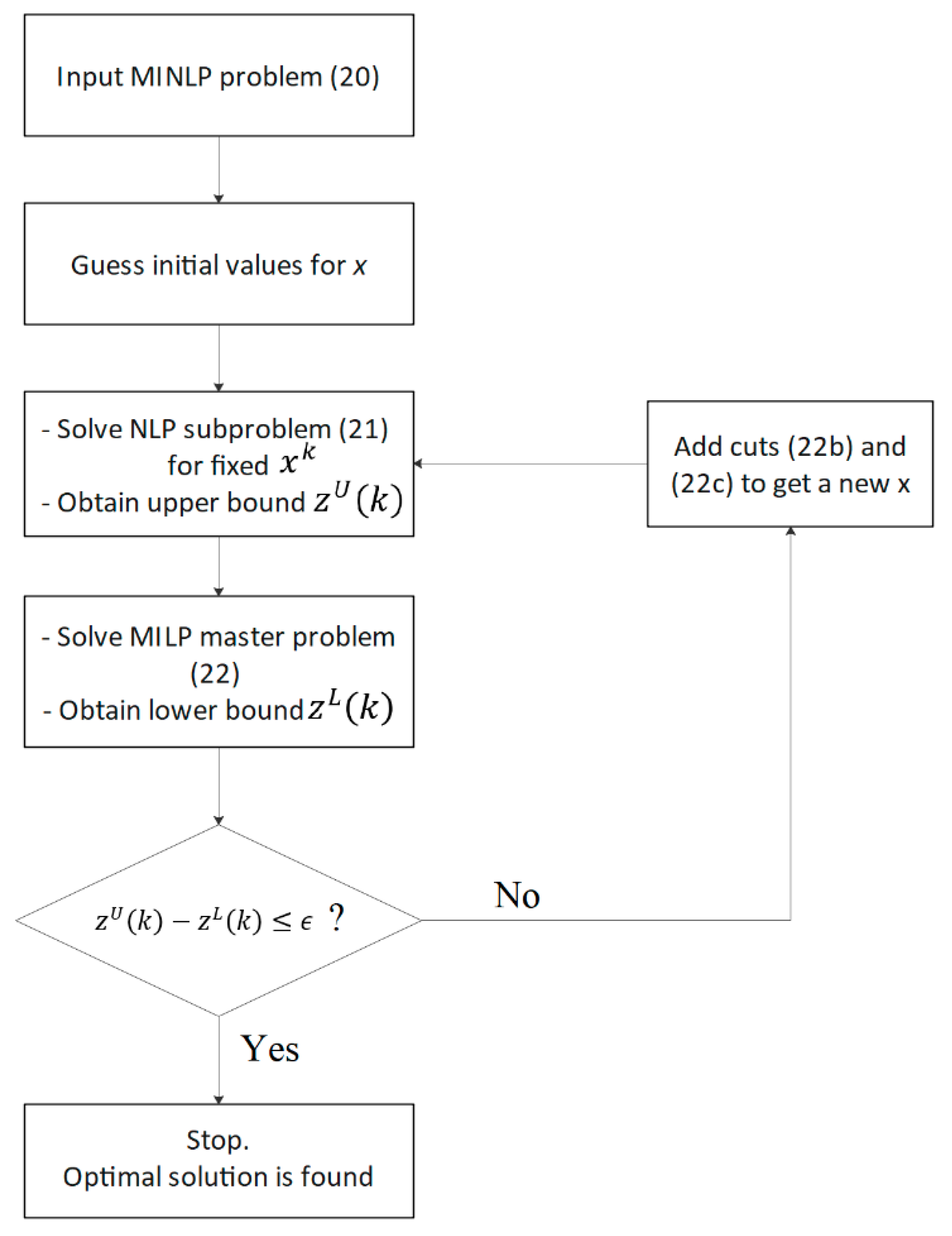
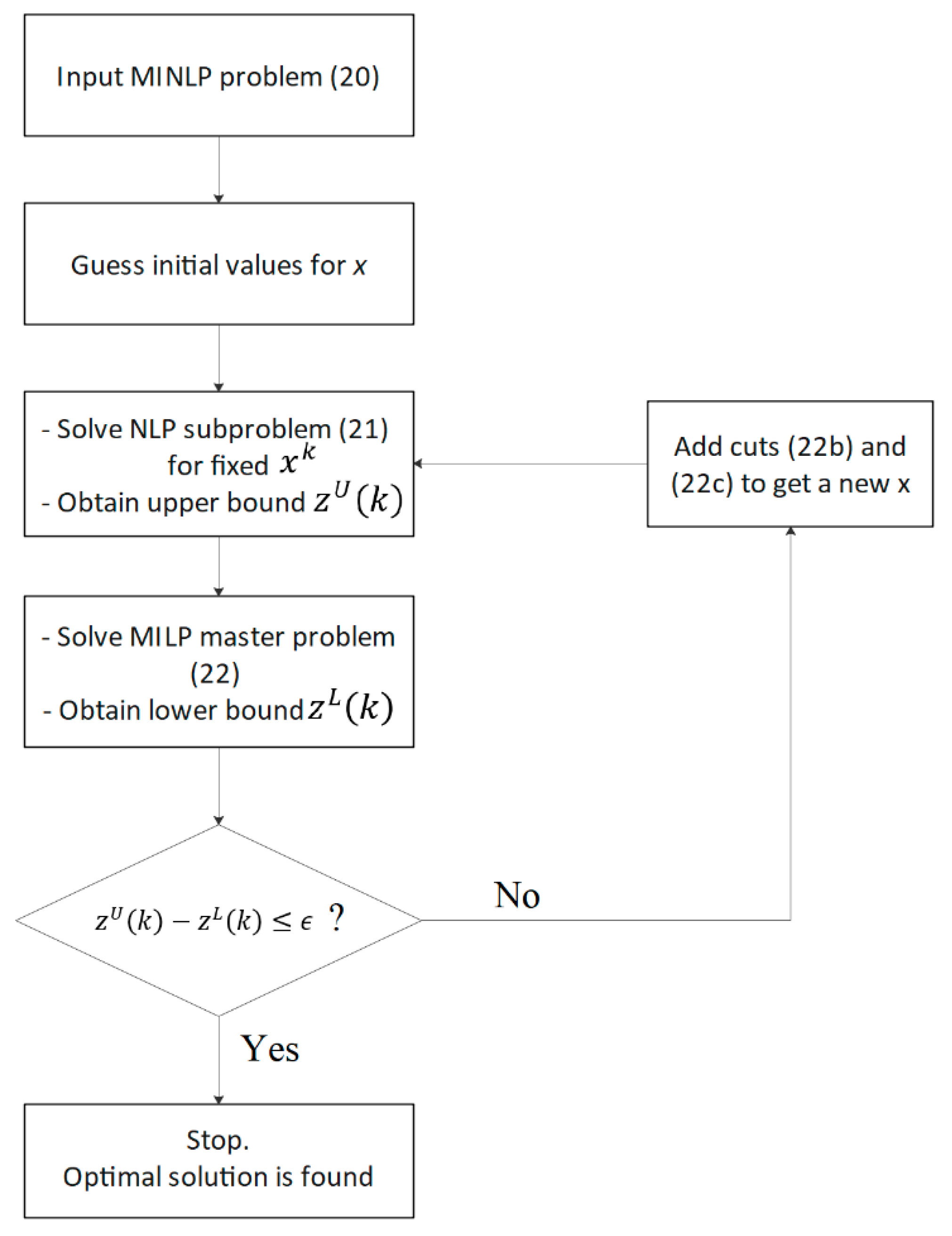
4. Solution Methodology
Mixed-integer nonlinear programming (MINLP) is a class of optimization problems that consists of (i) linear and nonlinear functions, and (ii) continuous and integer variables. Incorporating integer or binary variables in nonlinear functions makes MINLPs powerful in accurately modeling complex systems. However, it imposes computational challenges on the problem. In particular, the branch and bound (B&B) algorithm that is used for branching on integer variables might be inefficient for such problems since solving MINLP is generally NP-hard. One efficient approach is to add cuts in the B&B method so that the search spaces shrink while the integer solutions are not removed. Among various cutting plane methods proposed in the literature, outer approximation (OA) [
54] turns out to be effective in various applications of MINLP [
55]. In this section, we implement the OA algorithm in our problem to then verify its efficiency in the numerical results of the next section.
A general MINLP problem can be written as follows:
where functions
and
are convex and possibly nonlinear. The proposed model in (1)–(15) is a form of problem (20a–d). To clearly show this equivalence, let continuous variable vector
be
and similarly, integer variable vector
be
, where bold notation is used for indicating vectors and matrices in problem (1)-(15)
. Therefore, constraint (20a) corresponds to the objective function (1), constraint (20b) corresponds to the set of constraints (2)–(12), constraint (20c) is a general form of constraint (13) to specify the bounds on integer variables, and finally, constraint (20d) corresponds to the set of constraints (14) and (15). For brevity and simplicity in notations, we show the steps of the OA algorithm on the general problem (20a) in matrix form. Then in our implementation, we use the proper definitions of variable vectors
and
and also functions
and
to map problem (1)–(15) to problem (20a–d). The idea of the OA algorithm is to effectively exploit the structure of the original problem based on principles of decomposition. So, the OA solves a series of mixed-integer linear programs (MILP) and a set of nonlinear programs (NLP), sequentially [
54], and consists of two steps, namely the subproblem and master problem.
4.1. Subproblem (SP)
The subproblem initially fixes the integer variables and then solves an NLP for given integer variables. Generally, the subproblem at iteration
can be written as a nonlinear program (21a–c) where
is the fixed values of integer variables.
Subproblem (21a–c) finds the optimal solution for fixed , and since we solve this problem iteratively, we denote optimal solution by . Term of subproblem (21a–c) provides an upper bound on the optimal value of z in the original problem (20a–d). It is because we restricted the integer values to take fixed values, and adding restrictions shrinks the feasible region, which in turn might increase the objective function value or keep it unchanged. Thus,
4.2. Master Problem (MP)
Once the solution of the continuous variable in iteration
is known, i.e.,
, the master problem uses the value of
to outer approximate the nonlinear function at this point by generating a cut. The master problem solves a MILP where the nonlinear functions are linearized. The master problem (22a–e) is shown as follows.
Constraints (22b,c) correspond to the cuts to linearize (outer approximate) nonlinear functions. Since in (22b) we approximated the nonlinear function
from below, the master problem provides a lower bound on the objective function value of the original problem (20a–d). The OA algorithm can terminate based on a prespecified condition. In particular, one efficient stopping condition is to check the gap between the upper and lower bounds on the original objective function value, i.e.,
. Once
is within an acceptable value
, which is defined by the user, we can terminate the algorithm, as shown in
Figure 7. Further details on the implementation of the OA algorithm can be found in [
54,
55,
56].


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}