
Performance Comparison of Large Language Models for Efficient Literature Screening

 , ,
, ,  and
and 
Abstract
1. Introduction
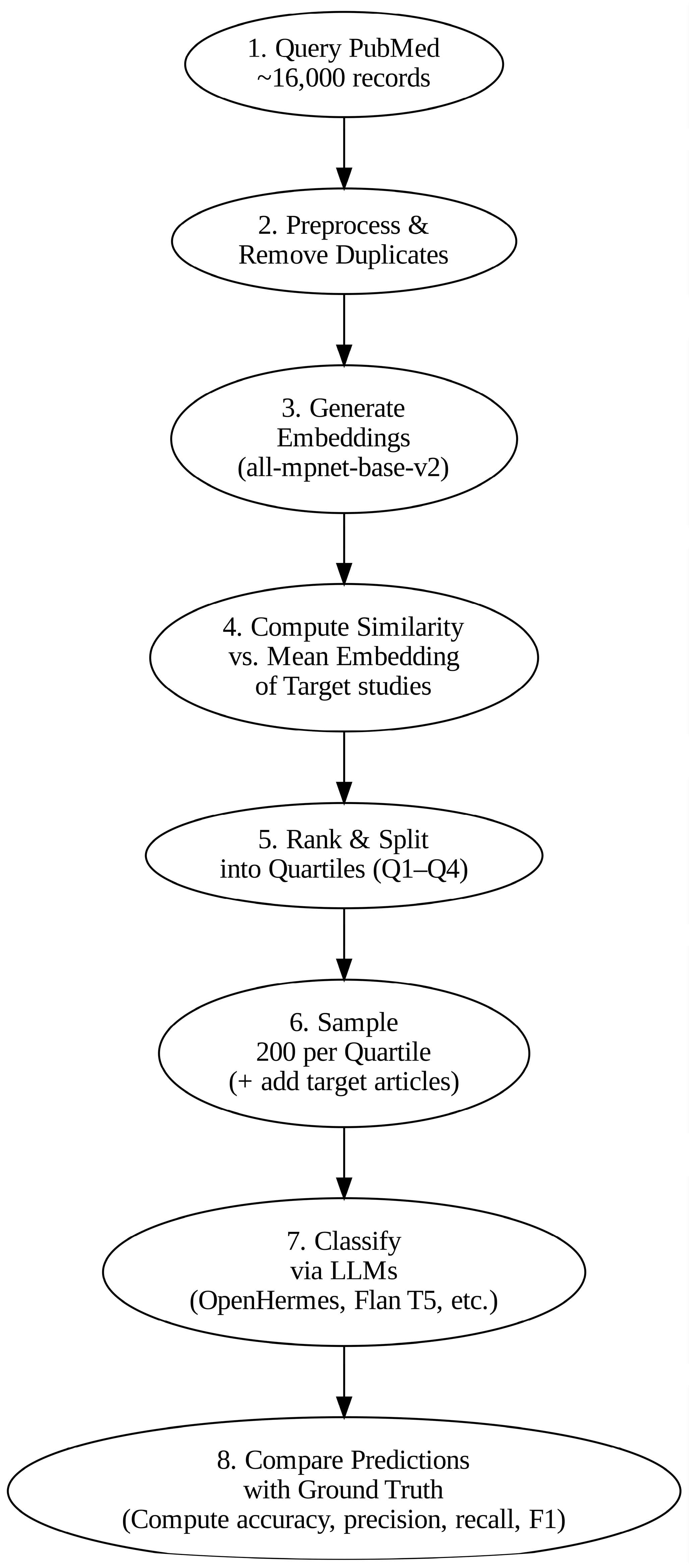
2. Materials and Methods
2.1. Study Design and Rationale
2.1.1. Fidan’s Review
- Population (P): Adult periodontitis patients (≥18 years old) with at least one intrabony or furcation defect;
- Intervention (I): Periodontal regenerative surgical procedures using EMD combined with bone grafts (EMD + BG);
- Comparison (C): Periodontal regenerative surgical procedures using bone grafts alone (BG);
- Outcomes (O): CAL gain, PD reduction (primary); secondary outcomes included pocket closure, wound healing, gingival recession (REC), tooth loss, PROMs, and adverse events.
- Study Design: Randomized controlled trials (RCTs), parallel or split-mouth, with ≥10 patients per arm;
- Follow-up: Minimum of 6 months after the surgical procedure;
- Population: Adult periodontitis patients (≥18 years) with intrabony or furcation defects;
- Intervention: EMD + BG (i.e., Emdogain combined with any bone graft material);
- Comparison: BG alone;
- Outcomes: At least CAL gain and PD reduction.
- Studies focusing exclusively on children (<18 years);
- Studies without a clear mention of EMD or bone grafts;
- Follow-up period of <6 months or uncertain;
- Non-randomized studies or fewer than 10 patients per arm.
2.1.2. Yang’s Review
- Population (P): adult patients presenting with radiologically suspicious PPLs;
- Intervention (I): CBCT-augmented bronchoscopy;
- Comparison (C): standard endobronchial or navigational tools alone;
- Outcomes (O): diagnostic yield, procedure times, and complication rates.
2.2. Data Acquisition
2.3. Data Pre-Processing
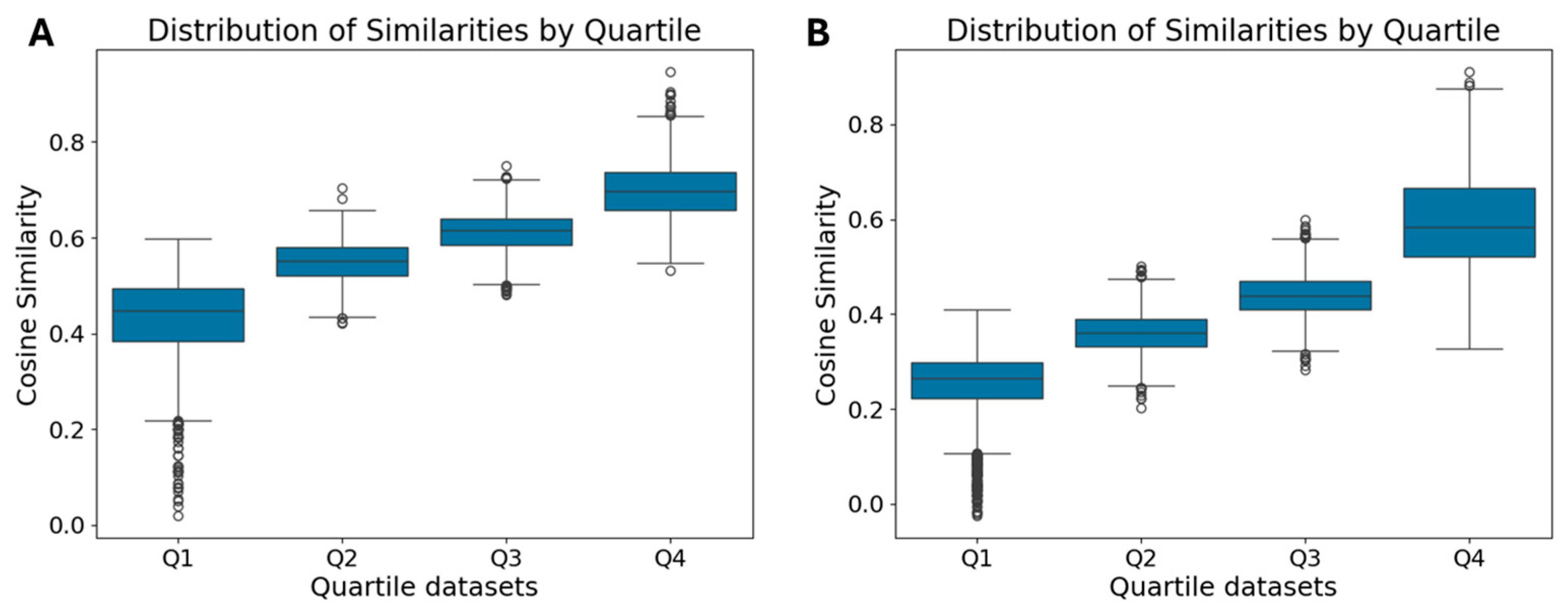
2.4. Dataset Analysis
2.5. LLM-Based Classification
- OpenHermes: OpenHermes is an instruction-tuned language model based on the Mistral 7B architecture (7 billion parameters), designed for effective natural language understanding and generation across a wide range of tasks [32]. For this study, we employed the quantized version of OpenHermes-2.5-Mistral-7B-GGUF (openhermes-2.5-mistral-7b.Q4_K_M.gguf), freely available on Huggingface.com. Quantization reduced the model’s 32-bit parameters to 4-bit values, significantly improving computational efficiency while maintaining high performance;
- Flan T5: Flan-T5 is an instruction-tuned language model developed by Google, designed for general-purpose natural language understanding and generation tasks [33]. Flan-T5 was fine-tuned on a wide array of instruction-following datasets and optimized for handling tasks such as classification, summarization, and question answering with high accuracy and contextual awareness;
- GPT-2: GPT-2, developed by OpenAI, lacks the instruction-tuning and domain-specific optimization of more advanced models, but it remains a valuable baseline for understanding the capabilities of earlier-generation language models [34];
- Claude 3 Haiku: Claude 3 Haiku is a next-generation model developed by Anthropic, featuring advanced language understanding and reasoning capabilities. Optimized for a wide range of tasks, it is instruction-tuned to follow specific prompts and has shown strong performance in classification scenarios [35];
- GPT-3.5 Turbo: GPT-3.5 Turbo, developed by OpenAI, is an optimized and cost-efficient version of the GPT-3.5 model, providing robust natural language understanding and generation capabilities [36]. With significantly improved contextual reasoning and instruction-following compared to GPT-2, GPT-3.5 Turbo performs better in structured classification tasks. In this study, GPT-3.5 Turbo was utilized via OpenAI’s API;
- GPT-4o: GPT-4o is the optimized version of GPT-4, and it combines enhanced instruction-following capabilities with improved contextual understanding [37]. GPT-4o performs better in complex decision-making and classification scenarios than its predecessors. GPT-4o was accessed via OpenAI’s API, too.
2.6. Prompting
2.6.1. Base Prompt
- **Population (P)**: Patients with peripheral pulmonary lesions (PPLs) detected by CT examination.
- **Intervention (I)**: Diagnostic CBCT-guided bronchoscopy.
- **Outcomes (O)**: Diagnostic yield (e.g., success rate) and/or safety outcomes (e.g., compl.ications).
- Study Size: >10 patients.
2.6.2. Double Prompt—OpenHermes, Flan T5, and GPT-2
2.6.3. Concise Prompt—Claude 3 Haiku, GPT 3.5 Turbo, and GPT 4o
- Population: If the text states patients with PPLs detected by CT, or is silent about PPLs/CT, it’s not violated.
- Intervention: If CBCT-guided bronchoscopy is mentioned or strongly implied, consider this met.
- Outcomes: If they mention diagnostic yield (e.g., success rate) or safety outcomes (e.g., complications), or are silent, do not penalize. Only reject if they clearly never measure these.
- Study Size: If they mention >10 patients or are silent, accept. If they state ≤10, reject.
2.7. Performance Evaluation
2.8. Software and Hardware
3. Results
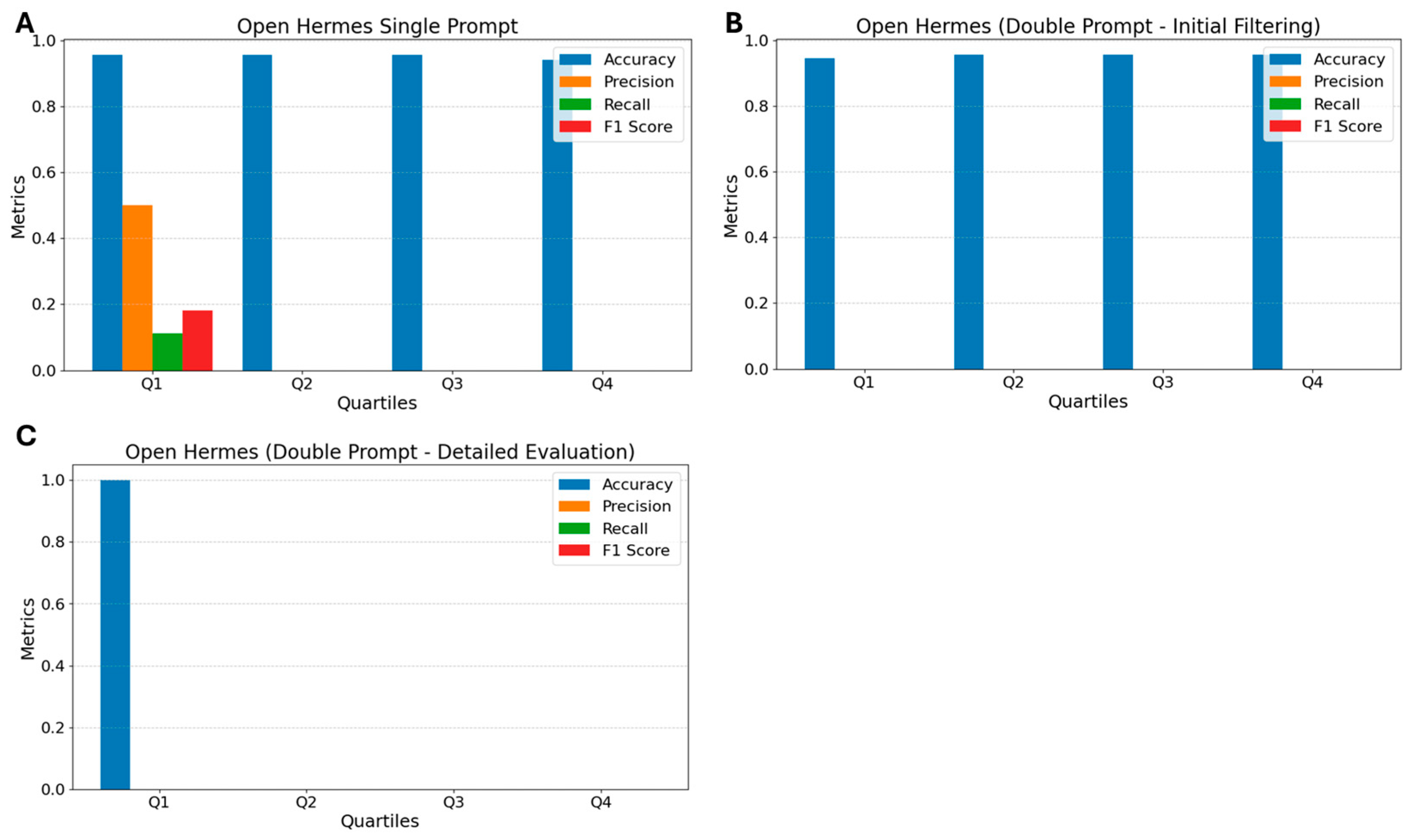
3.1. Open Hermes
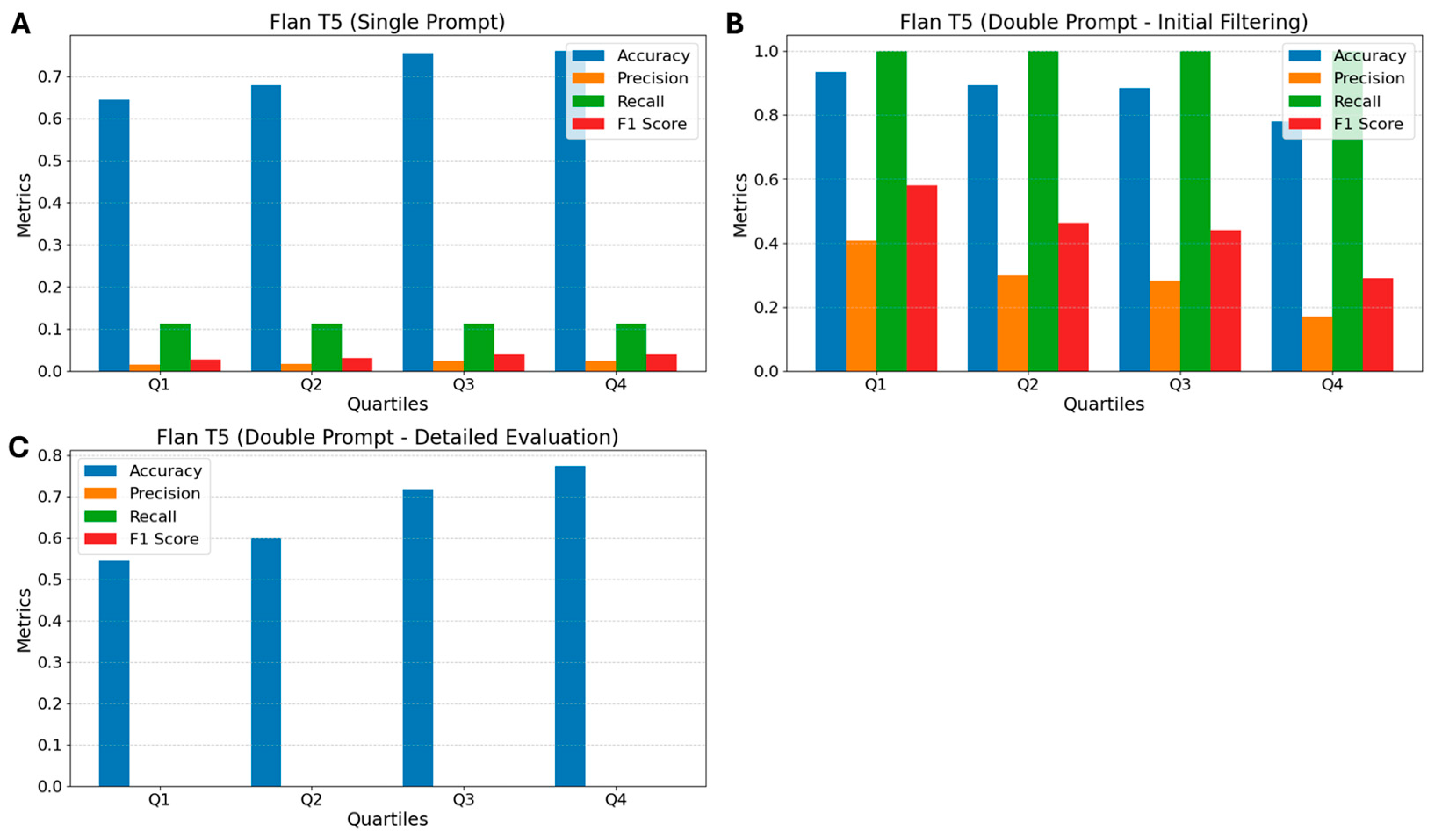
3.2. Flan T5
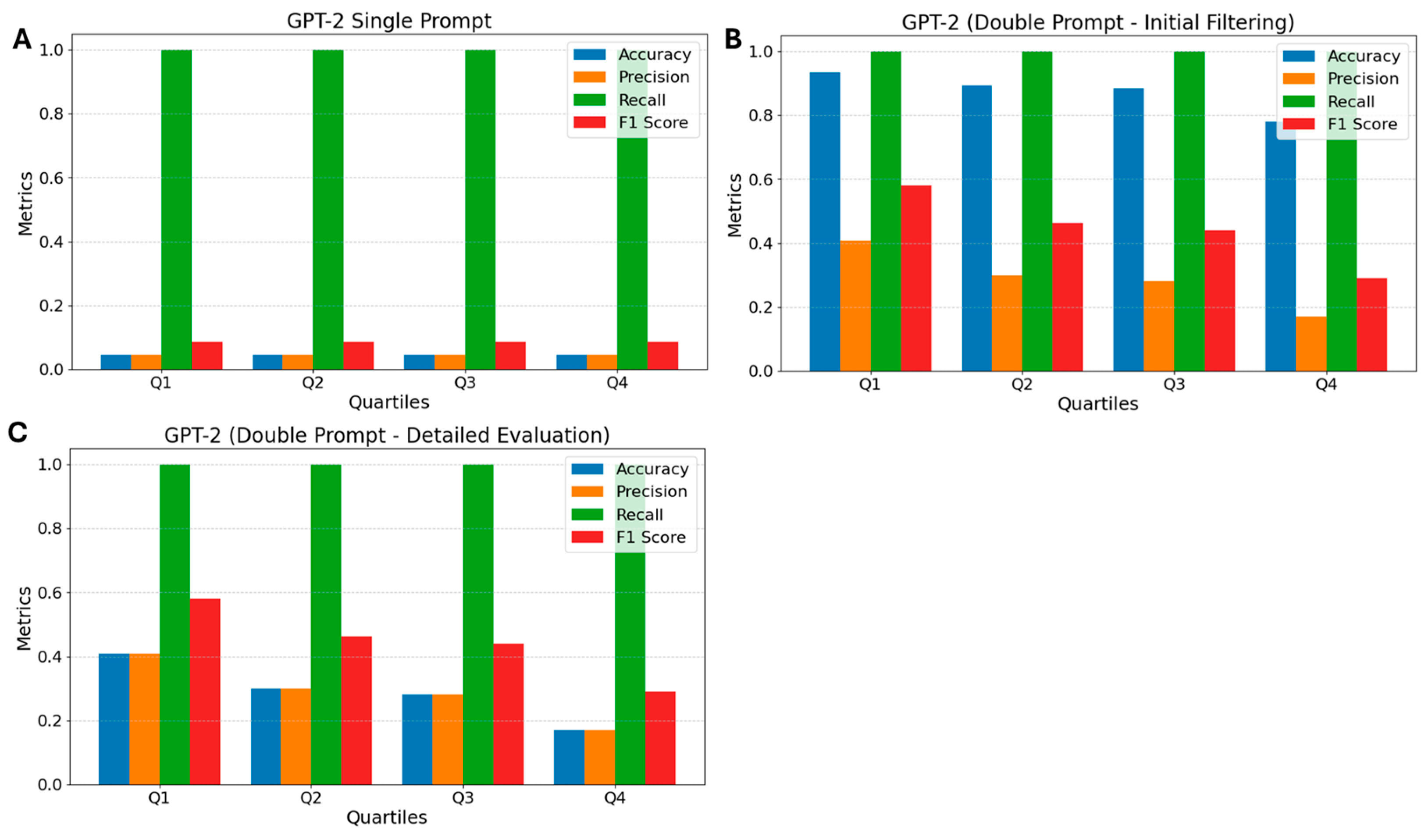
3.3. GPT-2
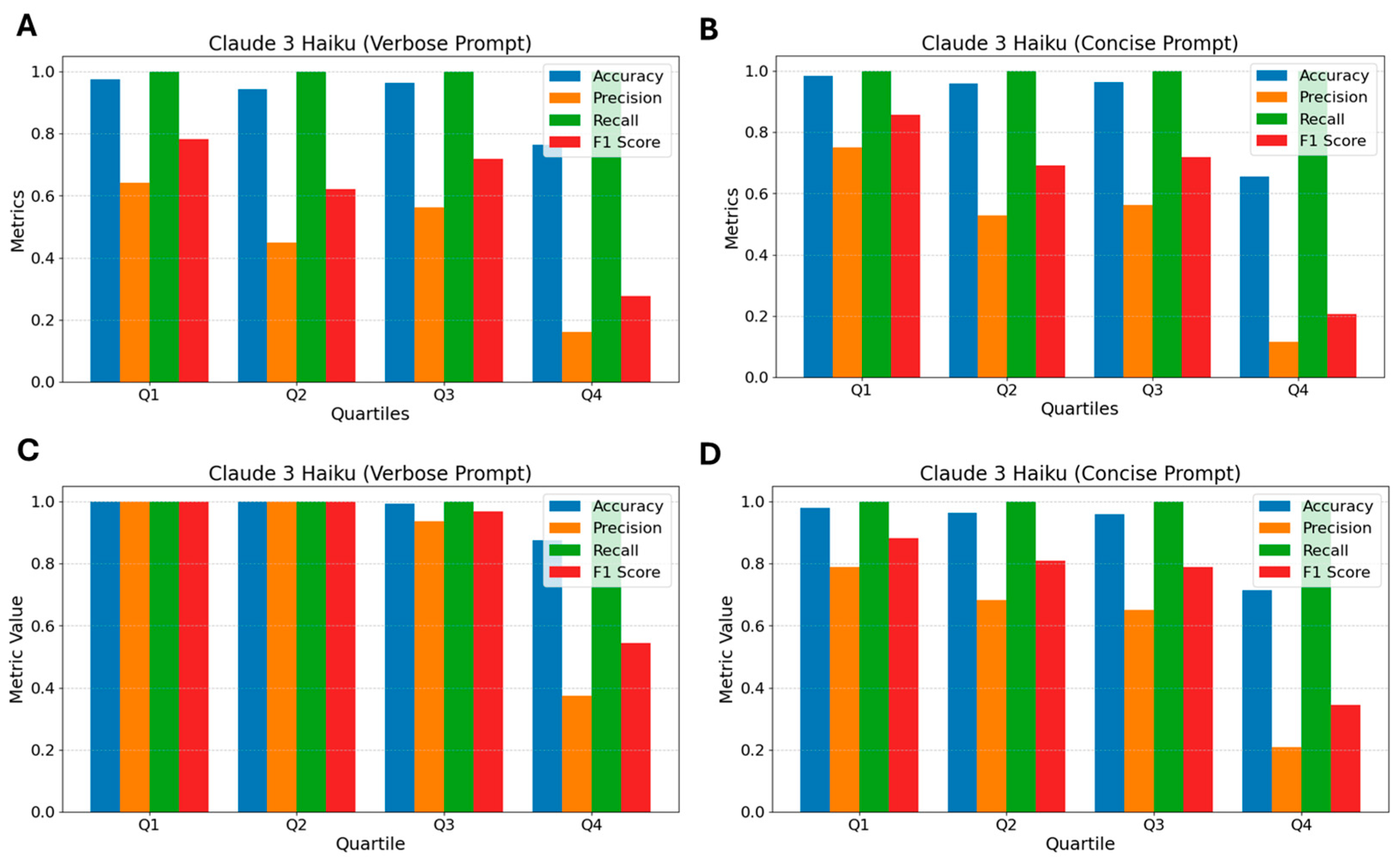
3.4. Claude 3 Haiku
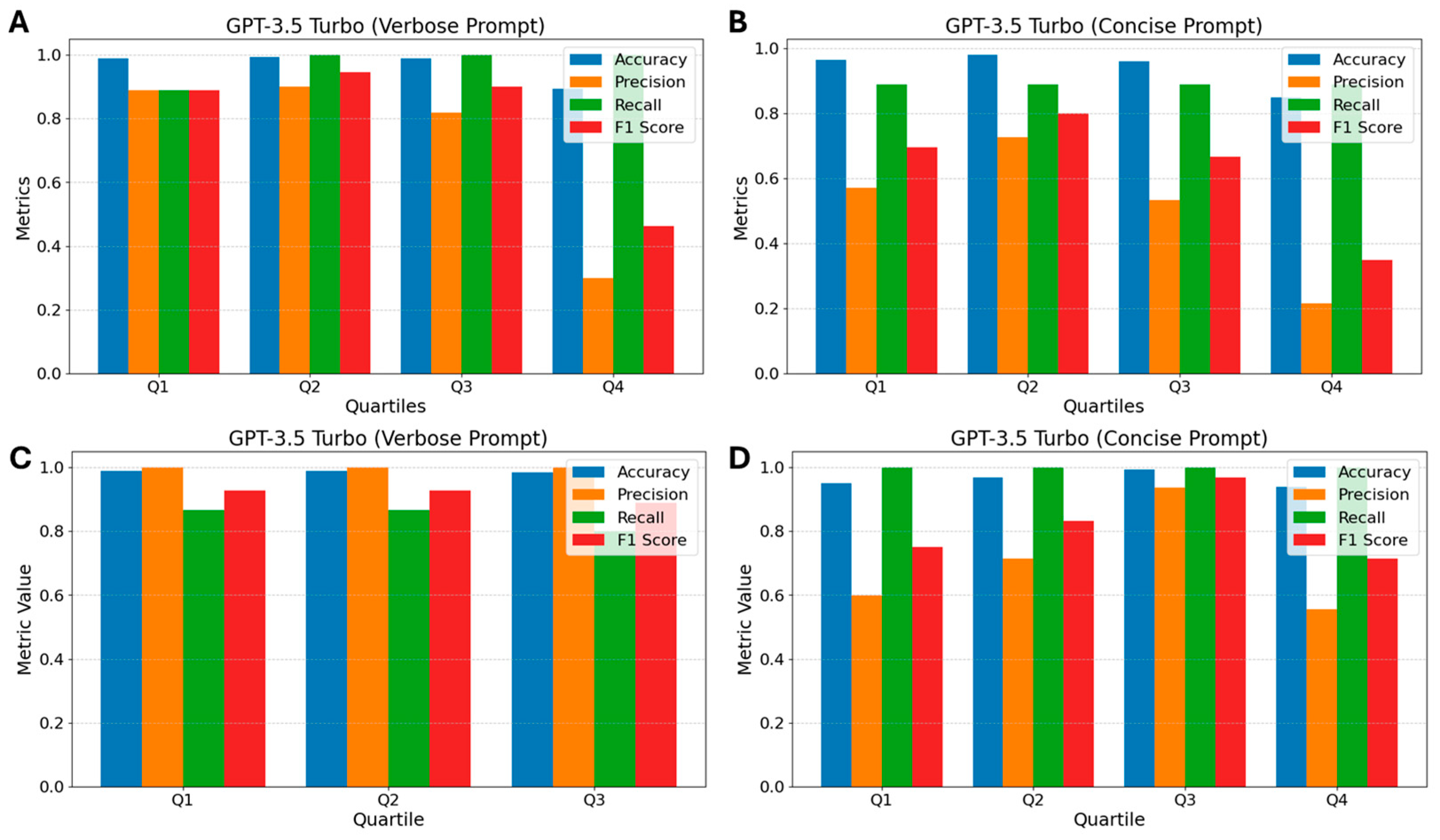
3.5. GPT-3.5 Turbo
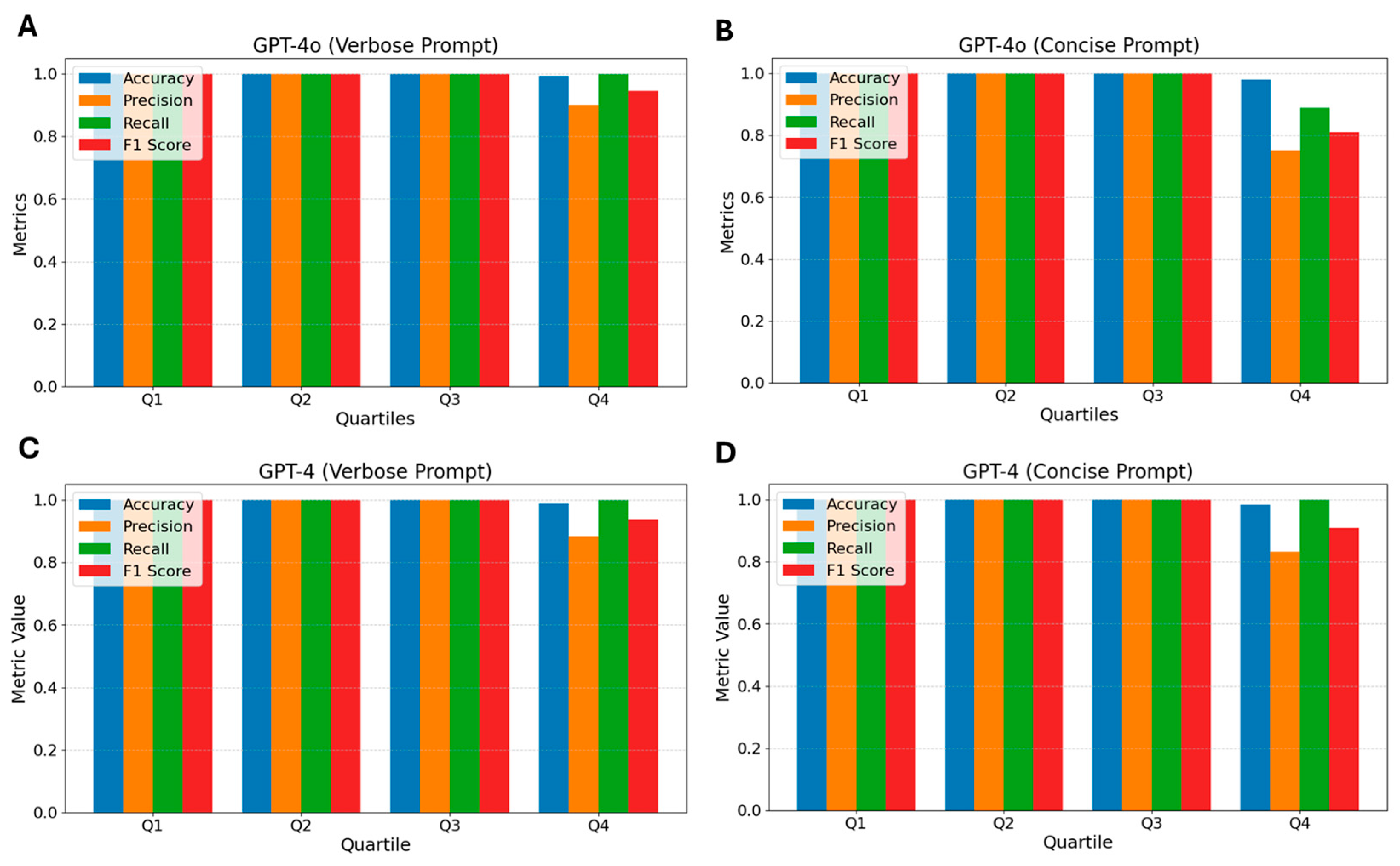
3.6. GPT-4o
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PMID | Title | Journal | Year | Reference |
|---|---|---|---|---|
| 11990444 | A Clinical Comparison of a Bovine-Derived Xenograft Used Alone and in Combination with Enamel Matrix Derivative for the Treatment of Periodontal Osseous Defects in Humans. | Journal of Periodontology | 2002 | [46] |
| 12186348 | Clinical Evaluation of an Enamel Matrix Protein Derivative (Emdogain) Combined with a Bovine-Derived Xenograft (Bio-Oss) for the Treatment of Intrabony Periodontal Defects in Humans. | International Journal of Periodontics & Restorative Dentistry | 2002 | [47] |
| 11990441 | Clinical Evaluation of an Enamel Matrix Protein Derivative Combined with a Bioactive Glass for the Treatment of Intrabony Periodontal Defects in Humans. | Journal of Periodontology | 2002 | [48] |
| 19053917 | Clinical Evaluation of Demineralized Freeze-Dried Bone Allograft With and Without Enamel Matrix Derivative for the Treatment of Periodontal Osseous Defects in Humans. | Journal of Periodontology | 2008 | [49] |
| 20054593 | Comparative Study of DFDBA in Combination with Enamel Matrix Derivative Versus DFDBA Alone for Treatment of Periodontal Intrabony Defects at 12 Months Post-Surgery. | Clinical Oral Investigations | 2011 | [50] |
| 23484181 | Evaluation of the Effectiveness of Enamel Matrix Derivative, Bone Grafts, and Membrane in the Treatment of Mandibular Class II Furcation Defects. | International Journal of Periodontics & Restorative Dentistry | 2013 | [51] |
| 23379539 | Hydroxyapatite/Beta-Tricalcium Phosphate and Enamel Matrix Derivative for Treatment of Proximal Class II Furcation Defects: A Randomized Clinical Trial. | Journal of Clinical Periodontology | 2013 | [52] |
| 26556577 | Enamel Matrix Protein Derivative and/or Synthetic Bone Substitute for the Treatment of Mandibular Class II Buccal Furcation Defects. A 12-Month Randomized Clinical Trial. | Clinical Oral Investigations | 2016 | [53] |
| 31811645 | Adjunctive Use of Enamel Matrix Derivatives to Porcine-Derived Xenograft for the Treatment of One-Wall Intrabony Defects: Two-Year Longitudinal Results of a Randomized Controlled Clinical Trial. | Journal of Periodontology | 2020 | [54] |
Appendix A.2
| PMID | Title | Journal | Year | Reference |
|---|---|---|---|---|
| 36369295 | Shape-Sensing Robotic-Assisted Bronchoscopy with Concurrent Use of Radial Endobronchial Ultrasound and Cone Beam Computed Tomography in the Evaluation of Pulmonary Lesions | Lung | 2022 | [55] |
| 36006070 | Efficacy and Safety of Cone-Beam CT. Augmented Electromagnetic Navigation Guided Bronchoscopic Biopsies of Indeterminate Pulmonary Nodules. | Tomography | 2022 | [56] |
| 35920067 | Diagnostic Yield of Cone-Beam-Derived Augmented Fluoroscopy and Ultrathin Bronchoscopy Versus Conventional Navigational Bronchoscopy Techniques. | Journal of Bronchology & Interventional Pulmonology | 2023 | [57] |
| 24665347 | Cone Beam Computertomography (CBCT) in Interventional Chest Medicine—High Feasibility for Endobronchial Realtime Navigation. | Journal of Cancer | 2014 | [58] |
| 30746241 | Cone Beam Computed Tomography-Guided Thin/Ultrathin Bronchoscopy for Diagnosis of Peripheral Lung Nodules: A Prospective Pilot Study. | Journal of Thoracic Disease | 2018 | [59] |
| 30179922 | Cone-Beam CT With Augmented Fluoroscopy Combined With Electromagnetic Navigation Bronchoscopy for Biopsy of Pulmonary Nodules. | Journal of Bronchology & Interventional Pulmonology | 2018 | [60] |
| 30505506 | Biopsy of Peripheral Lung Nodules Utilizing Cone Beam Computer Tomography With and Without Trans Bronchial Access Tool: A Retrospective Analysis. | Journal of Thoracic Disease | 2018 | [61] |
| 31121593 | Transbronchial Biopsy Using an Ultrathin Bronchoscope Guided by Cone-Beam Computed Tomography and Virtual Bronchoscopic Navigation in the Diagnosis of Pulmonary Nodules. | Respiration | 2019 | [62] |
| 33547938 | Robotic-Assisted Navigation Bronchoscopy as a Paradigm Shift in Peripheral Lung Access. | Lung | 2021 | [63] |
| 33615626 | Cone-Beam Computed Tomography Versus Computed Tomography-Guided Ultrathin Bronchoscopic Diagnosis for Peripheral Pulmonary Lesions: A Propensity Score-Matched Analysis. | Respirology | 2021 | [64] |
| 35054208 | Cone-Beam Computed Tomography-Derived Augmented Fluoroscopy Improves the Diagnostic Yield of Endobronchial Ultrasound-Guided Transbronchial Biopsy for Peripheral Pulmonary Lesions. | Diagnostics | 2021 | [65] |
| 33401270 | Cone-Beam Computed Tomography-Guided Electromagnetic Navigation for Peripheral Lung Nodules. | Respiration | 2021 | [66] |
| 32649327 | Cone-Beam CT Image Guidance With and Without Electromagnetic Navigation Bronchoscopy for Biopsy of Peripheral Pulmonary Lesions. | Journal of Bronchology & Interventional Pulmonology | 2021 | [67] |
| 34162799 | Cone-Beam CT and Augmented Fluoroscopy-Guided Navigation Bronchoscopy: Radiation Exposure and Diagnostic Accuracy Learning Curves. | Journal of Bronchology & Interventional Pulmonology | 2021 | [68] |
| 33845482 | Efficacy and Safety of Cone-Beam Computed Tomography-Derived Augmented Fluoroscopy Combined with Endobronchial Ultrasound in Peripheral Pulmonary Lesions. | Respiration | 2021 | [69] |
Appendix B
Performance Metrics
References
- Mulrow, C.D. Systematic Reviews: Rationale for systematic reviews. BMJ 1994, 309, 597–599. [Google Scholar] [CrossRef]
- Betrán, A.P.; Say, L.; Gülmezoglu, A.M.; Allen, T.; Hampson, L. Effectiveness of different databases in identifying studies for systematic reviews: Experience from the WHO systematic review of maternal morbidity and mortality. BMC Med. Res. Methodol. 2005, 5, 6. [Google Scholar] [CrossRef] [PubMed]
- Grivell, L. Mining the bibliome: Searching for a needle in a haystack? EMBO Rep. 2002, 3, 200–203. [Google Scholar] [CrossRef] [PubMed]
- Landhuis, E. Scientific literature: Information overload. Nature 2016, 535, 457–458. [Google Scholar] [CrossRef] [PubMed]
- Scells, H.; Zuccon, G.; Koopman, B.; Deacon, A.; Azzopardi, L.; Geva, S. Integrating the Framing of Clinical Questions via PICO into the Retrieval of Medical Literature for Systematic Reviews. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; ACM: New York, NY, USA, 2017; pp. 2291–2294. [Google Scholar]
- Anderson, N.K.; Jayaratne, Y.S.N. Methodological challenges when performing a systematic review. Eur. J. Orthod. 2015, 37, 248–250. [Google Scholar] [CrossRef]
- Dennstädt, F.; Zink, J.; Putora, P.M.; Hastings, J.; Cihoric, N. Title and abstract screening for literature reviews using large language models: An exploratory study in the biomedical domain. Syst. Rev. 2024, 13, 158. [Google Scholar] [CrossRef]
- Khraisha, Q.; Put, S.; Kappenberg, J.; Warraitch, A.; Hadfield, K. Can large language models replace humans in systematic reviews? Evaluating GPT-4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages. Res. Synth. Methods 2024, 15, 616–626. [Google Scholar] [CrossRef]
- Dai, Z.-Y.; Wang, F.-Q.; Shen, C.; Ji, Y.-L.; Li, Z.-Y.; Wang, Y.; Pu, Q. Accuracy of Large Language Models for Literature Screening in Systematic Reviews and Meta-Analyses. J. Med. Internet Res. 2024, 27, e67488. [Google Scholar] [CrossRef]
- Delgado-Chaves, F.M.; Jennings, M.J.; Atalaia, A.; Wolff, J.; Horvath, R.; Mamdouh, Z.M.; Baumbach, J.; Baumbach, L. Transforming literature screening: The emerging role of large language models in systematic reviews. Proc. Natl. Acad. Sci. USA 2025, 122, e2411962122. [Google Scholar] [CrossRef]
- Scherbakov, D.; Hubig, N.; Jansari, V.; Bakumenko, A.; Lenert, L.A. The emergence of Large Language Models (LLM) as a tool in literature reviews: An LLM automated systematic review. arXiv 2024, arXiv:240904600. [Google Scholar]
- Elliott, J.H.; Synnot, A.; Turner, T.; Simmonds, M.; Akl, E.A.; McDonald, S.; Salanti, G.; Meerpohl, J.; MacLehose, H.; Hilton, J.; et al. Living systematic review: 1. Introduction—The why, what, when, and how. J. Clin. Epidemiol. 2017, 91, 23–30. [Google Scholar] [CrossRef]
- Ren, J.; Fok, M.R.; Zhang, Y.; Han, B.; Lin, Y. The role of non-steroidal anti-inflammatory drugs as adjuncts to periodontal treatment and in periodontal regeneration. J. Transl. Med. 2023, 21, 149. [Google Scholar] [CrossRef] [PubMed]
- Mijiritsky, E.; Assaf, H.D.; Peleg, O.; Shacham, M.; Cerroni, L.; Mangani, L. Use of PRP, PRF and CGF in Periodontal Regeneration and Facial Rejuvenation—A Narrative Review. Biology 2021, 10, 317. [Google Scholar] [CrossRef] [PubMed]
- Miron, R.J.; Moraschini, V.; Estrin, N.E.; Shibli, J.A.; Cosgarea, R.; Jepsen, K.; Jervøe-Storm, P.; Sculean, A.; Jepsen, S. Periodontal regeneration using platelet-rich fibrin. Furcation defects: A systematic review with meta-analysis. Periodontol 2000 2024, 97, 191–214. [Google Scholar] [CrossRef]
- Woo, H.N.; Cho, Y.J.; Tarafder, S.; Lee, C.H. The recent advances in scaffolds for integrated periodontal regeneration. Bioact. Mater. 2021, 6, 3328–3342. [Google Scholar] [CrossRef] [PubMed]
- Fidan, I.; Labreuche, J.; Huck, O.; Agossa, K. Combination of Enamel Matrix Derivatives with Bone Graft vs Bone Graft Alone in the Treatment of Periodontal Intrabony and Furcation Defects: A Systematic Review and Meta-Analysis. Oral Health Prev. Dent. 2024, 22, 655–664. [Google Scholar]
- Yang, H.; Huang, J.; Zhang, Y.; Guo, J.; Xie, S.; Zheng, Z.; Ma, Y.; Deng, Q.; Zhong, C.; Li, S. The diagnostic performance and optimal strategy of cone beam CT-assisted bronchoscopy for peripheral pulmonary lesions: A systematic review and meta-analysis. Pulmonology 2025, 31, 1–2420562. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:190810084. [Google Scholar]
- Stankevičius, L.; Lukoševičius, M. Extracting Sentence Embeddings from Pretrained Transformer Models. Appl. Sci. 2024, 14, 8887. [Google Scholar] [CrossRef]
- Li, B.; Han, L. Distance Weighted Cosine Similarity Measure for Text Classification. In Intelligent Data Engineering and Automated Learning—IDEAL 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 611–618. [Google Scholar]
- Cichosz, P. Assessing the quality of classification models: Performance measures and evaluation procedures. Open Eng. 2011, 1, 132–158. [Google Scholar] [CrossRef]
- Cottam, J.A.; Heller, N.C.; Ebsch, C.L.; Deshmukh, R.; Mackey, P.; Chin, G. Evaluation of Alignment: Precision, Recall, Weighting and Limitations. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 2513–2519. [Google Scholar]
- Abbade, L.P.F.; Wang, M.; Sriganesh, K.; Mbuagbaw, L.; Thabane, L. Framing of research question using the PICOT format in randomised controlled trials of venous ulcer disease: A protocol for a systematic survey of the literature. BMJ Open 2016, 6, e013175. [Google Scholar] [CrossRef]
- White, J. PubMed 2.0. Med. Ref. Serv. Q 2020, 39, 382–387. [Google Scholar] [CrossRef]
- Chapman, B.; Chang, J. Biopython: Python tools for computational biology. ACM Sigbio Newsl. 2000, 20, 15–19. [Google Scholar] [CrossRef]
- Cock, P.J.; Antao, T.; Chang, J.T.; Chapman, B.A.; Cox, C.J.; Dalke, A.; Friedberg, I.; Hamelryck, T.; Kauff, F.; Wilczynski, B.; et al. Biopython: Freely available Python tools for computational molecular biology and bioinformatics. Bioinformatics 2009, 25, 1422–1423. [Google Scholar] [CrossRef] [PubMed]
- Mckinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- McInnes, L.; Healy, J.; Astels, S. hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar]
- Thakkar, H.; Manimaran, A. Comprehensive Examination of Instruction-Based Language Models: A Comparative Analysis of Mistral-7B and Llama-2-7B. In Proceedings of the 2023 International Conference on Emerging Research in Computational Science (ICERCS), Coimbatore, India, 7–9 December 2023; pp. 1–6. [Google Scholar]
- Oza, J.; Yadav, H. Enhancing Question Prediction with Flan T5-A Context-Aware Language Model Approach. Authorea 2023. [Google Scholar]
- Patwardhan, I.; Gandhi, S.; Khare, O.; Joshi, A.; Sawant, S. A Comparative Analysis of Distributed Training Strategies for GPT-2. arXiv 2024, arXiv:240515628. [Google Scholar]
- Nguyen, C.; Carrion, D.; Badawy, M. Comparative Performance of Claude and GPT Models in Basic Radiological Imaging Tasks. medRxiv 2024. [Google Scholar] [CrossRef]
- Williams, C.Y.K.; Miao, B.Y.; Butte, A.J. Evaluating the use of GPT-3.5-turbo to provide clinical recommendations in the Emergency Department. medRxiv 2023. [Google Scholar] [CrossRef]
- Islam, R.; Moushi, O.M. Gpt-4o: The cutting-edge advancement in multimodal llm. Authorea 2024. [Google Scholar] [CrossRef]
- Cao, C.; Sang, J.; Arora, R.; Kloosterman, R.; Cecere, M.; Gorla, J.; Saleh, R.; Chen, D.; Drennan, I.; Teja, B.; et al. Development of prompt templates for large language model–driven screening in systematic reviews. Ann. Int. Med. 2025, 178, 389–401. [Google Scholar] [CrossRef]
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Bisong, E., Ed.; Apress: Berkeley, CA, USA, 2019; pp. 59–64. [Google Scholar]
- Sentence-Transformers/All-Mpnet-Base-v2. Available online: https://huggingface.co/sentence-transformers/all-mpnet-base-v2 (accessed on 10 February 2024).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Luo, R.; Sastimoglu, Z.; Faisal, A.I.; Deen, M.J. Evaluating the Efficacy of Large Language Models for Systematic Review and Meta-Analysis Screening. medRxiv 2024. [Google Scholar]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef] [PubMed]
- Chai, K.E.K.; Lines, R.L.J.; Gucciardi, D.F.; Ng, L. Research Screener: A machine learning tool to semi-automate abstract screening for systematic reviews. Syst. Rev. 2021, 10, 93. [Google Scholar] [CrossRef]
- Khalil, H.; Ameen, D.; Zarnegar, A. Tools to support the automation of systematic reviews: A scoping review. J. Clin. Epidemiol. 2022, 144, 22–42. [Google Scholar] [CrossRef]
- Scheyer, E.T.; Velasquez-Plata, D.; Brunsvold, M.A.; Lasho, D.J.; Mellonig, J.T. A clinical comparison of a bovine-derived xenograft used alone and in combination with enamel matrix derivative for the treatment of periodontal osseous defects in humans. J. Periodontol. 2002, 73, 423–432. [Google Scholar] [CrossRef] [PubMed]
- Sculean, A.; Chiantella, G.C.; Windisch, P.; Gera, I.; Reich, E. Clinical evaluation of an enamel matrix protein derivative (Emdogain) combined with a bovine-derived xenograft (Bio-Oss) for the treatment of intrabony periodontal defects in humans. Int. J. Periodontics Restor. Dent. 2002, 22, 259–267. [Google Scholar]
- Sculean, A.; Barbé, G.; Chiantella, G.C.; Arweiler, N.B.; Berakdar, M.; Brecx, M. Clinical evaluation of an enamel matrix protein derivative combined with a bioactive glass for the treatment of intrabony periodontal defects in humans. J. Periodontol. 2002, 73, 401–408. [Google Scholar] [CrossRef]
- Hoidal, M.J.; Grimard, B.A.; Mills, M.P.; Schoolfield, J.D.; Mellonig, J.T.; Mealey, B.L. Clinical evaluation of demineralized freeze-dried bone allograft with and without enamel matrix derivative for the treatment of periodontal osseous defects in humans. J. Periodontol. 2008, 79, 2273–2280. [Google Scholar] [CrossRef]
- Aspriello, S.D.; Ferrante, L.; Rubini, C.; Piemontese, M. Comparative study of DFDBA in combination with enamel matrix derivative versus DFDBA alone for treatment of periodontal intrabony defects at 12 months post-surgery. Clin. Oral Investig. 2011, 15, 225–232. [Google Scholar] [CrossRef]
- Jaiswal, R.; Deo, V. Evaluation of the effectiveness of enamel matrix derivative, bone grafts, and membrane in the treatment of mandibular Class II furcation defects. Int. J. Periodontics Restor. Dent. 2013, 33, e58–e64. [Google Scholar] [CrossRef]
- Peres, M.F.S.; Ribeiro, É.D.P.; Casarin, R.C.V.; Ruiz, K.G.S.; Junior, F.H.N.; Sallum, E.A.; Casati, M.Z. Hydroxyapatite/β-tricalcium phosphate and enamel matrix derivative for treatment of proximal class II furcation defects: A randomized clinical trial. J. Clin. Periodontol. 2013, 40, 252–259. [Google Scholar] [CrossRef]
- Queiroz, L.A.; Santamaria, M.P.; Casati, M.Z.; Ruiz, K.S.; Nociti, F.; Sallum, A.W.; Sallum, E.A. Enamel matrix protein derivative and/or synthetic bone substitute for the treatment of mandibular class II buccal furcation defects. A 12-month randomized clinical trial. Clin. Oral Investig. 2016, 20, 1597–1606. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.-H.; Kim, D.-H.; Jeong, S.-N. Adjunctive use of enamel matrix derivatives to porcine-derived xenograft for the treatment of one-wall intrabony defects: Two-year longitudinal results of a randomized controlled clinical trial. J. Periodontol. 2020, 91, 880–889. [Google Scholar] [CrossRef] [PubMed]
- Styrvoky, K.; Schwalk, A.; Pham, D.; Chiu, H.T.; Rudkovskaia, A.; Madsen, K.; Carrio, S.; Kurian, E.M.; Casas, L.D.L.; Abu-Hijleh, M. Shape-Sensing Robotic-Assisted Bronchoscopy with Concurrent use of Radial Endobronchial Ultrasound and Cone Beam Computed Tomography in the Evaluation of Pulmonary Lesions. Lung 2022, 200, 755–761. [Google Scholar] [CrossRef]
- Podder, S.; Chaudry, S.; Singh, H.; Jondall, E.M.; Kurman, J.S.; Benn, B.S. Efficacy and Safety of Cone-Beam CT Augmented Electromagnetic Navigation Guided Bronchoscopic Biopsies of Indeterminate Pulmonary Nodules. Tomography 2022, 8, 2049–2058. [Google Scholar] [CrossRef]
- DiBardino, D.M.; Kim, R.Y.; Cao, Y.B.; Andronov, M.; Lanfranco, A.R.; Haas, A.R.; Vachani, A.; Ma, K.C.; Hutchinson, C.T. Diagnostic Yield of Cone-beam–Derived Augmented Fluoroscopy and Ultrathin Bronchoscopy Versus Conventional Navigational Bronchoscopy Techniques. J. Bronc-Interv. Pulmonol. 2022, 30, 335–345. [Google Scholar] [CrossRef]
- Hohenforst-Schmidt, W.; Zarogoulidis, P.; Vogl, T.; Turner, J.F. Browning, R.; Linsmeier, B.; Huang, H.; Li, Q.; Darwiche, K.; Freitag, L.; Simoff, M.; Kioumis, I.; Zarogoulidis, K.; Brachmann. J. Cone Beam Computertomography (CBCT) in Interventional Chest Medicine—High Feasibility for Endobronchial Realtime Navigation. J. Cancer 2014, 5, 231–241. [Google Scholar] [CrossRef]
- Casal, R.F.; Sarkiss, M.; Jones, A.K.; Stewart, J.; Tam, A.; Grosu, H.B.; Ost, D.E.; Jimenez, C.A.; Eapen, G.A. Cone beam computed tomography-guided thin/ultrathin bronchoscopy for diagnosis of peripheral lung nodules: A prospective pilot study. J. Thorac. Dis. 2018, 10, 6950–6959. [Google Scholar] [CrossRef] [PubMed]
- Pritchett, M.A.; Schampaert, S.; de Groot, J.A.H.; Schirmer, C.C.; van der Bom, I. Cone-Beam CT With Augmented Fluoroscopy Combined With Electromagnetic Navigation Bronchoscopy for Biopsy of Pulmonary Nodules. J. Bronc-Interv. Pulmonol. 2018, 25, 274–282. [Google Scholar] [CrossRef] [PubMed]
- Sobieszczyk, M.J.; Yuan, Z.; Li, W.; Krimsky, W. Biopsy of peripheral lung nodules utilizing cone beam computer tomography with and without trans bronchial access tool: A retrospective analysis. J. Thorac. Dis. 2018, 10, 5953–5959. [Google Scholar] [CrossRef]
- Ali, E.A.A.; Takizawa, H.; Kawakita, N.; Sawada, T.; Tsuboi, M.; Toba, H.; Takashima, M.; Matsumoto, D.; Yoshida, M.; Kawakami, Y.; et al. Transbronchial Biopsy Using an Ultrathin Bronchoscope Guided by Cone-Beam Computed Tomography and Virtual Bronchoscopic Navigation in the Diagnosis of Pulmonary Nodules. Respiration 2019, 98, 321–328. [Google Scholar] [CrossRef]
- Benn, B.S.; Romero, A.O.; Lum, M.; Krishna, G. Robotic-Assisted Navigation Bronchoscopy as a Paradigm Shift in Peripheral Lung Access. Lung 2021, 199, 177–186. [Google Scholar] [CrossRef] [PubMed]
- Kawakita, N.; Takizawa, H.; Toba, H.; Sakamoto, S.; Miyamoto, N.; Matsumoto, D.; Takashima, M.; Tsuboi, M.; Yoshida, M.; Kawakami, Y.; et al. Cone-beam computed tomography versus computed tomography-guided ultrathin bronchoscopic diagnosis for peripheral pulmonary lesions: A propensity score-matched analysis. Respirology 2021, 26, 477–484. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.-K.; Fan, H.-J.; Yao, Z.-H.; Lin, Y.-T.; Wen, Y.-F.; Wu, S.-G.; Ho, C.-C. Cone-Beam Computed Tomography-Derived Augmented Fluoroscopy Improves the Diagnostic Yield of Endobronchial Ultrasound-Guided Transbronchial Biopsy for Peripheral Pulmonary Lesions. Diagnostics 2021, 12, 41. [Google Scholar] [CrossRef]
- Kheir, F.; Thakore, S.R.; Uribe Becerra, J.P.; Tahboub, M.; Kamat, R.; Abdelghani, R.; Fernandez-Bussy, S.; Kaphle, U.R.; Majid, A. Cone-Beam Computed Tomography-Guided Electromagnetic Navigation for Peripheral Lung Nodules. Respiration 2021, 100, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Verhoeven, R.L.J.; Fütterer, J.J.; Hoefsloot, W.; Van Der Heijden, E.H.F.M. Cone-Beam CT Image Guidance With and Without Electromagnetic Navigation Bronchoscopy for Biopsy of Peripheral Pulmonary Lesions. J. Bronchol. Interv. Pulmonol. 2021, 28, 60–69. [Google Scholar] [CrossRef]
- Verhoeven, R.L.J.; van der Sterren, W.M.; Kong, W.M.; Langereis, S.; van der Tol, P.M.; van der Heijden, E.H. Cone-beam CT and Augmented Fluoroscopy–guided Navigation Bronchoscopy. J Bronchol. Interv Pulmonol. 2021, 28, 262–271. [Google Scholar] [CrossRef]
- Yu, K.-L.; Yang, S.-M.; Ko, H.-J.; Tsai, H.-Y.; Ko, J.-C.; Lin, C.-K.; Ho, C.-C.; Shih, J.-Y. Efficacy and Safety of Cone-Beam Computed Tomography-Derived Augmented Fluoroscopy Combined with Endobronchial Ultrasound in Peripheral Pulmonary Lesions. Respiration 2021, 100, 538–546. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Colangelo, M.T.; Guizzardi, S.; Meleti, M.; Calciolari, E.; Galli, C. Performance Comparison of Large Language Models for Efficient Literature Screening. BioMedInformatics 2025, 5, 25. https://doi.org/10.3390/biomedinformatics5020025
Colangelo MT, Guizzardi S, Meleti M, Calciolari E, Galli C. Performance Comparison of Large Language Models for Efficient Literature Screening. BioMedInformatics. 2025; 5(2):25. https://doi.org/10.3390/biomedinformatics5020025
Chicago/Turabian StyleColangelo, Maria Teresa, Stefano Guizzardi, Marco Meleti, Elena Calciolari, and Carlo Galli. 2025. "Performance Comparison of Large Language Models for Efficient Literature Screening" BioMedInformatics 5, no. 2: 25. https://doi.org/10.3390/biomedinformatics5020025
APA StyleColangelo, M. T., Guizzardi, S., Meleti, M., Calciolari, E., & Galli, C. (2025). Performance Comparison of Large Language Models for Efficient Literature Screening. BioMedInformatics, 5(2), 25. https://doi.org/10.3390/biomedinformatics5020025