1. Introduction
Colorectal cancer (CRC) ranks as the third most prevalent cancer globally [
1]. The development of CRC is associated with various risk factors [
2,
3]. Despite advancements in screening techniques and adjuvant therapy, metastasis remains the leading cause of death in CRC patients [
4]. Approximately 50 percent of individuals diagnosed with colorectal cancer will eventually experience metastasis. Therapeutic interventions, such as chemotherapy, not only contribute to increased survival rates but also help alleviate symptoms in metastatic CRC (mCRC) patients [
5]. In recent years, multiple studies have suggested a significant link between an imbalanced intestinal microbiome and the development of CRC. Microbial dysbiosis in the gut contributes to both the initiation and progression of CRC. Certain microbiota can promote carcinogenesis by producing carcinogenic toxins that manipulate inflammatory and tolerogenic pathways. The use of antibiotics has the potential to disrupt the normal microbiome, leading to an event known as dysbiosis. Indeed, various antibiotics have been shown to exert diverse effects on the density and diversity of the gut microbiota [
6,
7]. However, the gut microbiota can play dual roles, ranging from promoting tumorigenicity to exhibiting antitumorigenic effects. Manipulating the gut microbiota with antibiotics has shown promise in reducing tumour mass in mouse models of colon cancer. Moreover, previous studies have demonstrated that early exposure to antibiotics has significantly prevented tumorigenesis in a mouse model of inflammatory CRC. This approach holds practical therapeutic potential in managing CRC [
8]. In a retrospective study involving 120 CRC patients, antibiotic treatment two weeks before commencing oxaliplatin-based therapy resulted in a significantly improved objective response rate (ORR) and disease control rate for progressive CRC. Additionally, in CRC patients, overall survival (OS) and progression-free survival (PFS) were notably higher in the group that received antibiotics [
9,
10].
Cancer analysis relies heavily on managing vast and variable datasets. However, there are many challenges that arise due to this data deluge, including noise, heterogeneity, sparseness, incomplete data fields, random errors, systematic biases, and the difficulty of extracting relevant clinical phenotypes. These challenges are partly generated by pharmaceutical and healthcare processes [
11,
12]. These complex data types come from diverse sources, including patient populations, environmental factors, medical procedures, and treatment protocols across different medical centers. The pathogenesis of CRC involves multiple factors, such as histopathology, genetics, and environmental factors. The intricate nature of this disease highlights the need for advanced and intelligent models, methodologies, and technologies to assist healthcare professionals in effectively combating it. Indeed, in order to navigate the complexities, uncertainties, and heterogeneity of today’s cancer landscape, it is crucial to employ agile, efficient, and intelligent solutions [
13]. The application of Artificial Intelligence (AI) has the potential to enhance our understanding of various complex disease processes, enable personalized treatments, and optimize resources for individual patients.
Machine Learning (ML) models have demonstrated their effectiveness in predicting various clinical outcomes, such as acute renal damage, cardiovascular risk, and fracture risk, yielding promising results [
14,
15,
16]. ML techniques have the potential to overcome the limitations associated with traditional statistical methods in risk prediction. These techniques can capture complex multidimensional relationships between features and clinical outcomes by leveraging algorithms to analyze extensive and diverse datasets [
17]. ML approaches for cancer treatment are typically grounded in classification methods [
18]. Many examples highlight the potential of ML in healthcare. For instance, classification methods have achieved a high accuracy in cancerous blood cell diagnostics for normal cells without the operator’s intervention in cell feature determination [
19] or in dramatic situations like COVID-19 where deep learning methods, such as cutting-edge methods, have a significant tangible capacity for providing an accurate and efficient intelligent system for detecting and estimating the severity of COVID-19 [
20]. And it can even be used for image analysis when analyzing brain Magnetic Resonance Imaging (MRI) data as a valuable, easier, and faster method for supporting healthcare professionals in examining MR images of newborn brains [
21].
Classification methods are ML processes that group a set of input data into categories based on one or more variables. To achieve this, the model is trained with the training data and then tested with the test data before being deployed to make predictions on new data. Recent advancements in this field have introduced successful techniques like meta models. Meta models use the meta-learning methodology to learn the most appropriate algorithms and parameters for a particular ML task. These models aim to minimize the number of false positives and false negatives without compromising accuracy. The consensus learning approach is a variation of the ensemble methods that can be used to create multiple models and combine them to produce the best possible results. This technique is useful in improving predictability and reducing the variance within stochastic learning algorithms [
22]. Ensemble methods differ from bagging (which combines many unstable predictors to create a stable ensemble predictor) and boosting (which combines many weak but stable predictors to create a strong ensemble predictor). It focuses on the use of a heterogeneous set of algorithms to capture even remote or weak similarities between the predicted sample and the training data [
23].
The main objectives of this research are as follows: (i) develop predictive models that can forecast mortality in mCRC by using diverse data, including clinical and demographic information; (ii) create predictive meta-classification models that outperform supervised classification methods; (iii) construct predictive models utilizing clinical and demographic data to predict the connection between antibiotic medication and clinical outcomes in mCRC patients undergoing bevacizumab therapy, using the dataset from [
24]; (iv) use ML methods to investigate potential correlations between the therapeutic outcomes of bevacizumab and various factors, including antibiotics, within the context of colorectal cancer and mortality; and (v) evaluate the potential of ML methods as an alternative for predicting the association between antibiotic medication and clinical outcomes in mCRC patients undergoing bevacizumab therapy in comparison to traditional statistical methods.
The rest of this paper is divided into different sections. In
Section 2, the materials and methods used for the research are outlined.
Section 3 describes the results obtained, followed by a comprehensive discussion in
Section 4. Finally,
Section 5 presents the research conclusions and discusses potential directions of future studies.
4. Discussion
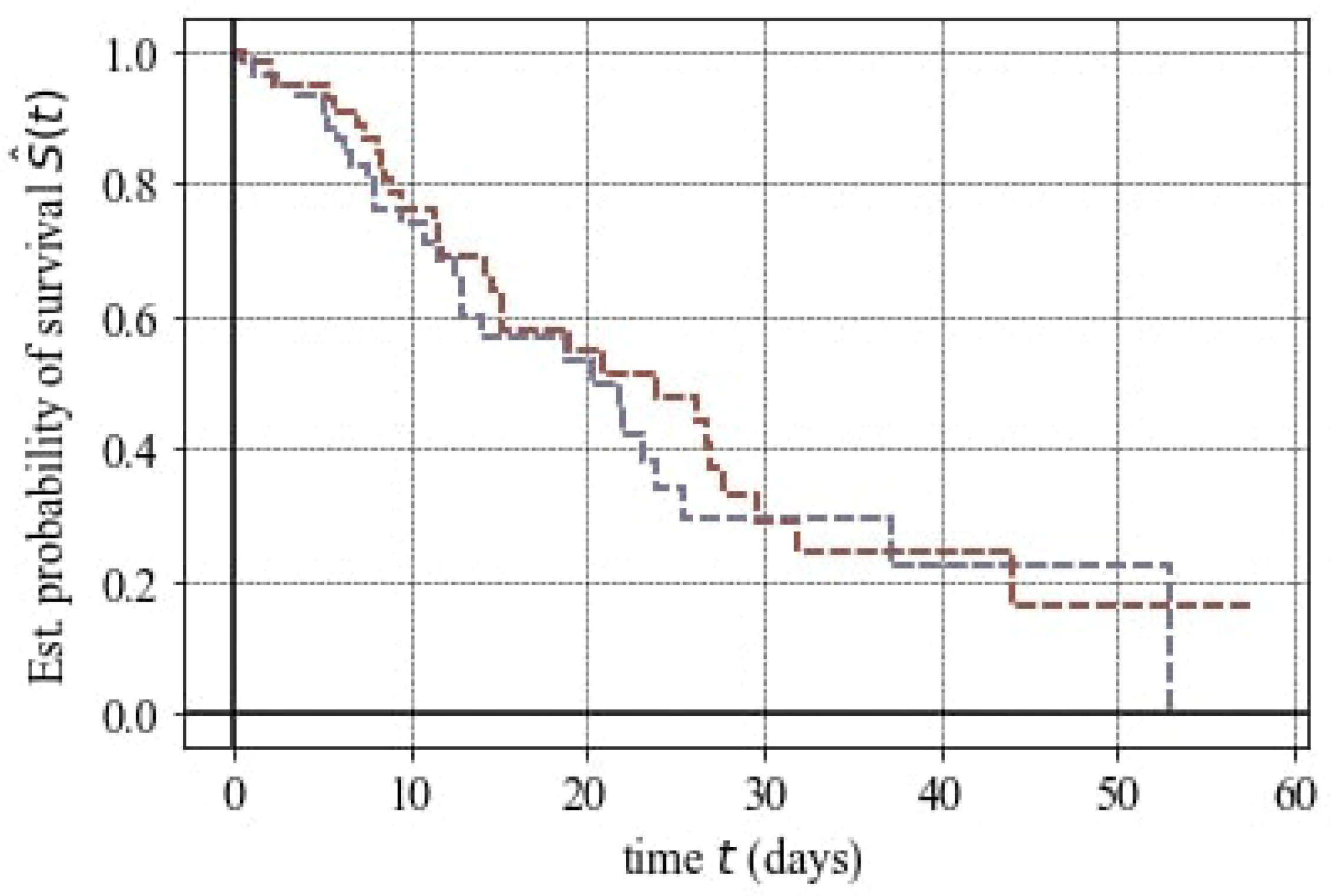
Our study suggests that a range of ML models can proficiently predict and classify cancer-related issues. The top meta models identified by consensus exhibited superior performance across various metrics. These consensus models introduce a novel weighted method explicitly crafted to minimize false negatives and false positives while maintaining accuracy. In the proposed weighted consensus model, we normalize the accuracy of individual classification models. During the prediction phase, these models might predict different classes. In the experimental evaluation of the weighted consensus model, we utilized classification algorithms, including Logistic Regression, Decision Trees, Naive Bayes, Support Vector Machines, Random Forest, and XGBoost. Our results indicate that the proposed meta-model performs comparably to the current state-of-the-art techniques, achieving an accuracy of
. Notably, it effectively mitigates false negatives and false positives. One noticeable application of the meta-model in our study involved examining the association between antibiotic exposure and clinical outcomes in mCRC patients. This analysis, reminiscent of a hospital-based cohort study, confirmed a non-significant association, aligning with the findings of other studies [
24]. However, an important observation emerged—the duration of antibiotic exposure during cancer treatment holds more significance than the mere presence or absence of antibiotic use [
52]. Our study underscores that the period of antibiotic treatment could exert a substantial influence on survival outcomes. This insight adds depth to our understanding, suggesting that assessing the duration of antibiotic use is crucial for a more nuanced interpretation of its impact on clinical outcomes. ML methods have shown promising features in cancer prediction, as evident in studies related to breast cancer and large-B-cell lymphoma (DLBCL) [
66,
67,
68]. These methods contribute to informed decision making in clinical practice for colorectal cancer. However, challenges such as dataset size, quality, and algorithm selection persist. The dataset’s quality and the algorithm’s appropriateness depend on factors like data types, sample size, time constraints, and desired prediction outcomes. Overall, the successful performance of the meta model suggests that they could be valuable tools in real-world clinical settings. By providing accurate predictions of cancer survival, these models can aid in individualized treatment strategies, optimizing dosage regimens, and ultimately improving therapeutic outcomes.
Antibiotics play a pivotal role in the management of colon cancer (CRC) across various disease stages, exerting both direct and indirect effects. However, their efficacy can vary based on the specific type utilized. Emerging research indicates that different antibiotic classes may elicit varied responses in certain cancers, potentially impeding tumour growth. Conversely, the effectiveness of previously administered antibiotics may diminish over time. Despite being commonly employed as adjuvant therapies alongside surgical, radiotherapeutic, chemotherapeutic, and immunotherapeutic interventions, concerns regarding antibiotic resistance and reproductive toxicity are mounting. Moreover, antibiotic usage can disrupt the balance of the intestinal microbiota, thus affecting the efficacy of combined cancer treatments [
69]. Consequently, careful consideration must be given to selecting the optimal type, dosage, and administration route (oral or intravenous) of antibiotics to synergize with cancer therapies.
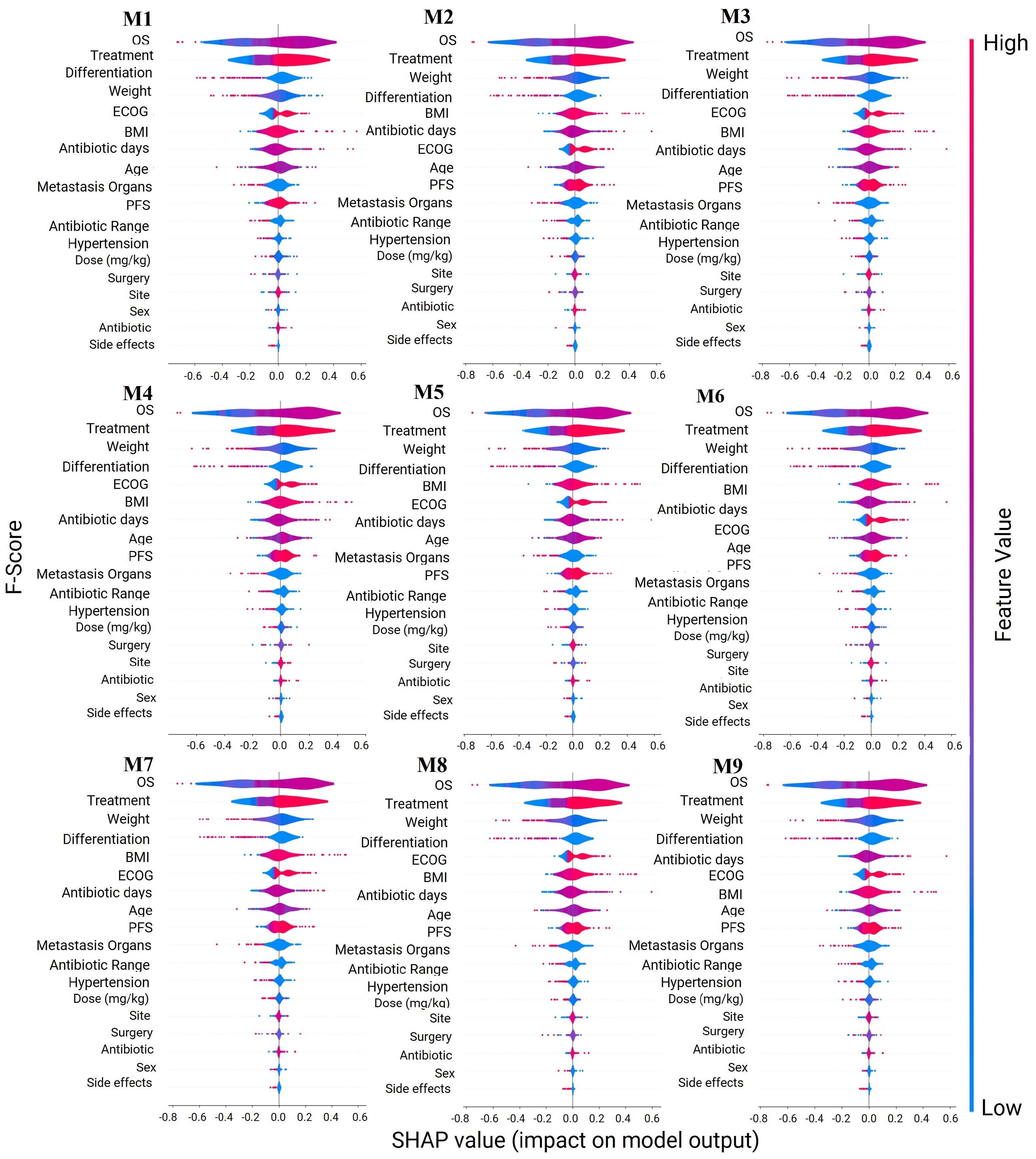
The feature importance analysis for the classification models has uncovered that certain antibiotic-related variables are more influential than the mere presence or absence of antibiotic use. This discovery aligns with the existing knowledge in the field, where the impact of antibiotics on cancer survival lacks clear significance. Our results expand on this understanding by evaluating the importance of the specific type of antibiotic used in cancer treatment. Indeed, different antibiotics have been shown to exert varying effects on the density and diversity of the microbiota [
6,
7]. This nuanced insight contributes to the ongoing discourse on the role of antibiotics in cancer treatment, highlighting the need for a more comprehensive consideration of the various factors at play.
While colorectal cancer can affect individuals of all genders, current evidence does not indicate a differential impact of gender on the incidence of colon cancer itself [
70]. However, certain risk factors, such as the influence of sex hormones and age, may vary between genders and contribute to the development of colon cancer. Furthermore, variations in symptoms and clinical presentation have been observed between men and women diagnosed with colon cancer. Therefore, any analysis of colon cancer must take into account these gender-related factors. Consequently, future analyses should consider stratifying the data by sex to explore potential differences between females and males in colorectal cancer outcomes and the impact of antibiotics on their survival [
71].
Unfortunately, different datasets present different variables, making it challenging to make comparisons between different studies. The analysis of cancer heavily relies on managing vast and variable datasets. Challenges arising from this data deluge include noise, heterogeneity, sparseness, incomplete data fields, random errors, systematic biases, and extracting relevant clinical phenotypes. All of these challenges are generated by pharmaceutical and healthcare processes [
11,
12]. Consequently, the comparable analysis makes it difficult to perform. For this reason, it is essential to acknowledge that these studies faced certain limitations. Firstly, they often dealt with a relatively limited amount of data, which may impact the generalizability of their models. Additionally, the lack of external validation in many of these studies raises concerns about the robustness and reliability of their findings. Finally, heterogeneity and not homogeneity between hospitals or research centres make it difficult to analyze the generalizability of the impact of these models. Even though a small-sample-size dataset may limit the ability to detect small size effects and can lead to overestimation or underestimation of size effects, our study relied solely on a small public dataset, which is a constraint of our research. While the dataset exhibits high accuracy, its generalizability is constrained by several limitations. These include its relatively small size and the lack of external validation. Recognizing and mitigating these limitations are crucial for a more precise interpretation of the findings. Additionally, it is essential to proactively address any potential biases in the analysis.
Working with larger and more diverse datasets, including private datasets, may lead to different or complementary findings, such as identifying other determining factors that can be significant in predicting the impact of bevacizumab in the treatment of mCRC patients. However, meta models can adaptively balance the effect of meta learning and task-specific learning within each task, minimizing the possibility of having imbalance and overfitting problems. In a published study, a meta-analysis on 2760 mCRC patients suggested that primary tumour resection was the critical factor in the improved survival of mCRC patients who received bevacizumab treatment [
72]. A systemic review and meta-analysis of nearly 4000 previously untreated or advanced mCRC patients showed that the combination of chemotherapy and bevacizumab increased the survival rates of patients who had not received prior chemotherapy for metastatic colorectal cancer. The patients who received bolus 5-FU or capecitabine-based chemotherapy with bevacizumab showed higher progression-free survival and overall survival rates compared to those who received infusional 5-FU plus bevacizumab, where there was no difference in progression-free survival and overall survival [
73]. In a study that examined the impact of primary tumour location on the efficacy of bevacizumab combined with CAPEOX (capecitabine and oxaliplatin) in the first-line treatment of metastatic colorectal cancer (mCRC), researchers found that patients with primary tumours in the sigmoid colon and rectum had significantly better outcomes in terms of progression-free survival (PFS) and OS compared to those with primary tumours from the cecum to the descending colon. This study included a cohort of 667 mCRC patients treated with CAPEOX and bevacizumab from 2006 to 2011, revealed a median PFS of
months and a median OS of
months for patients with sigmoid colon and rectal tumours, substantially better than the outcomes for patients with tumours in other locations. These findings were consistent even after adjusting for other prognostic factors in multivariate analyses. However, for patients treated solely with CAPEOX, no significant association between primary tumor location and treatment outcomes was observed. This suggests that the addition of bevacizumab to CAPEOX may predominantly benefit mCRC patients with primary tumors in the rectum and sigmoid colon, a hypothesis that warrants further validation through data from completed randomized trials [
74]. These studies demonstrate that other factors, such as chemotherapy regimes, tumour resection, and primary tumour location, can change the outcome of using bevacizumab in mCRC patients. Thus, the impact and effectiveness of using this antibiotic in the treatment of mCRC patients cannot be predicted accurately without considering other factors that affect cancer pathophysiology as well as patients’ health and survival.



 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






