

An Open-Access Dataset of Hospitalized Cardiac-Arrest Patients: Machine-Learning-Based Predictions Using Clinical Documentation

 , , and
, , and 
Abstract
:1. Introduction
- Publishing an open-access bed-head-ticket dataset.
- Introducing a machine-learning model that could predict the risk of fatal cardiac arrest and showed improved results.
- Analyzing the dataset with machine-learning models to compare the usability of the dataset.
- Dataset (Zenodo) https://zenodo.org/record/7603772
2. Materials and Methods
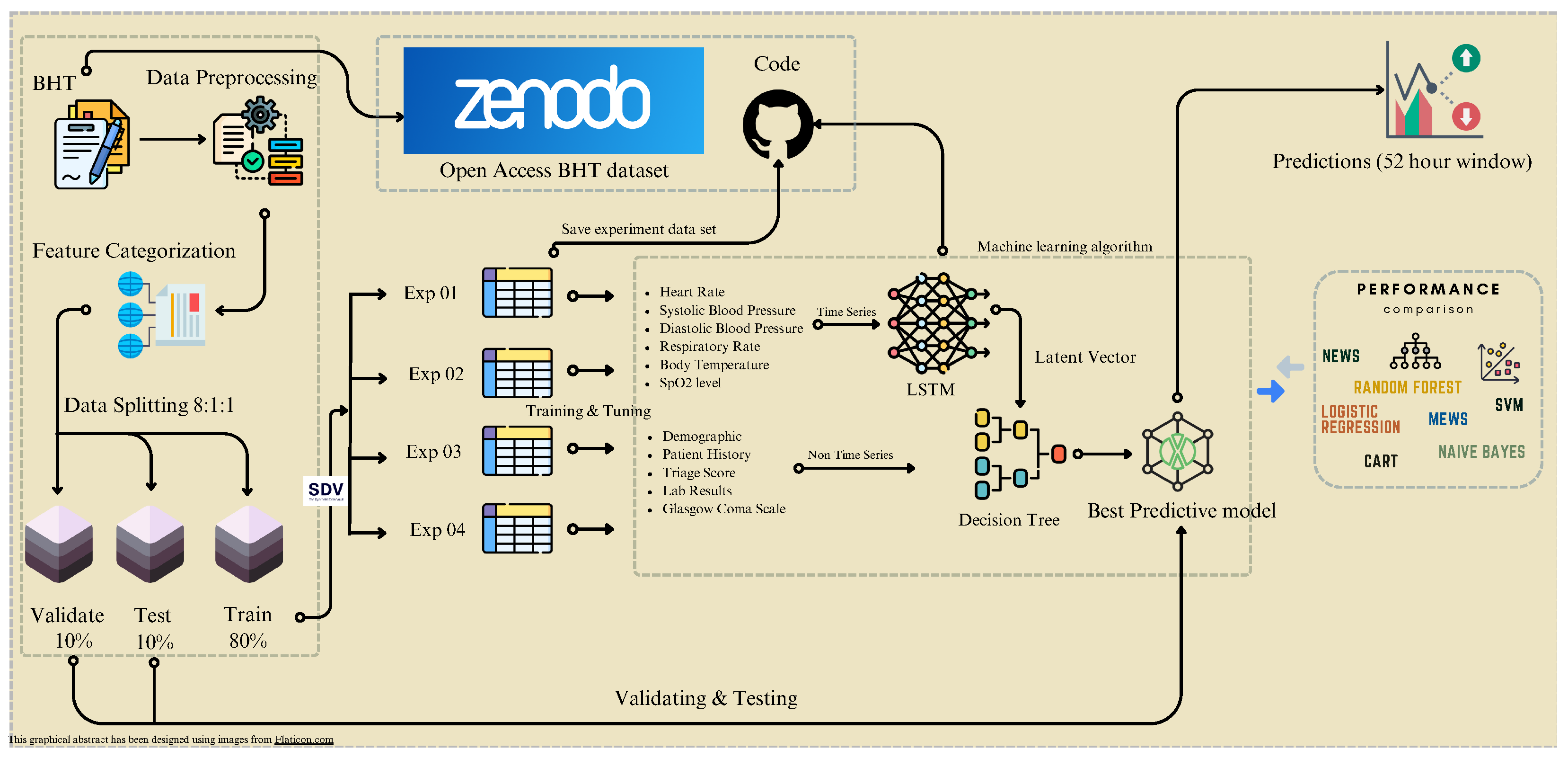
2.1. Methodology
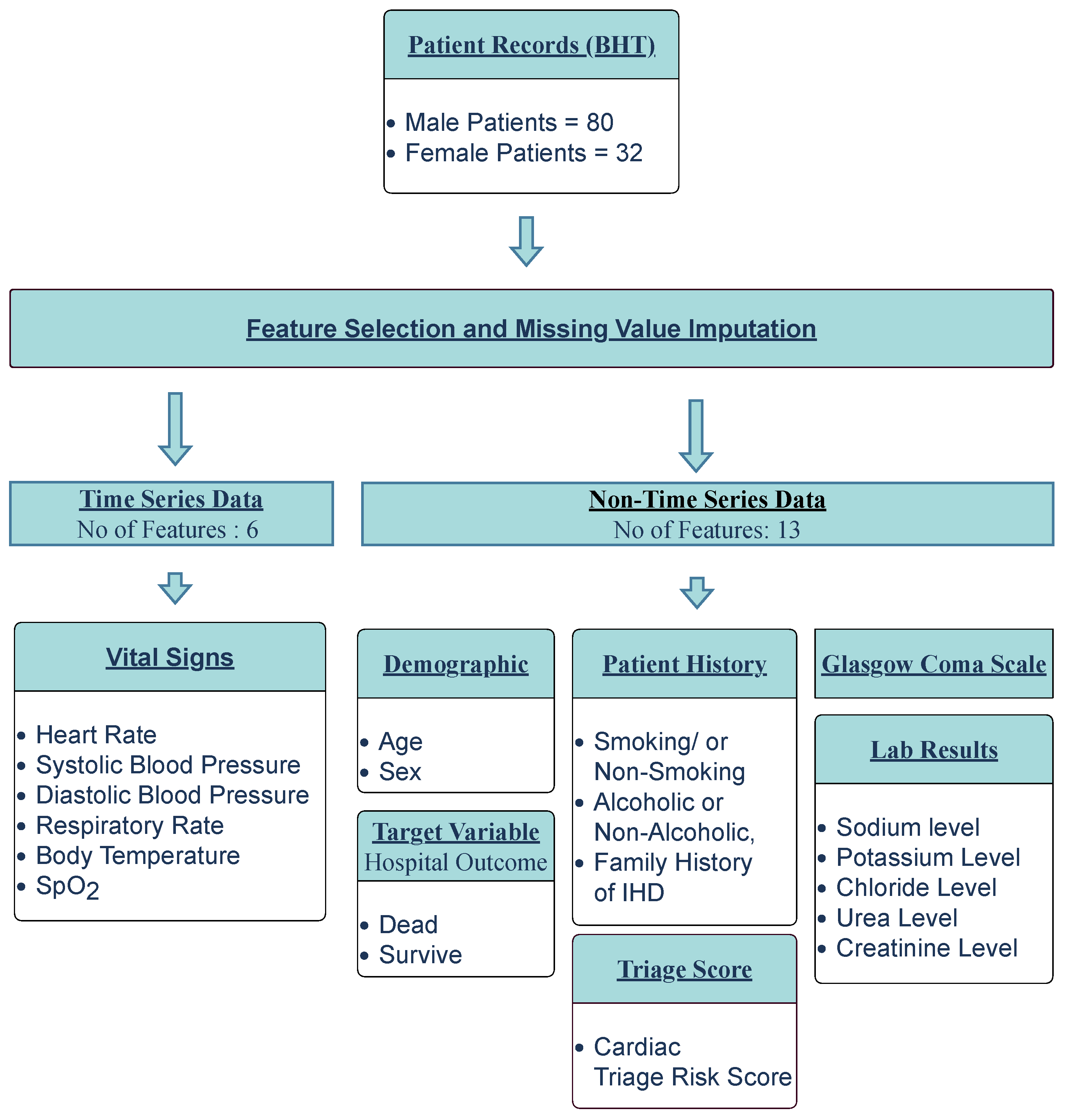
2.2. Data Pre-Processing
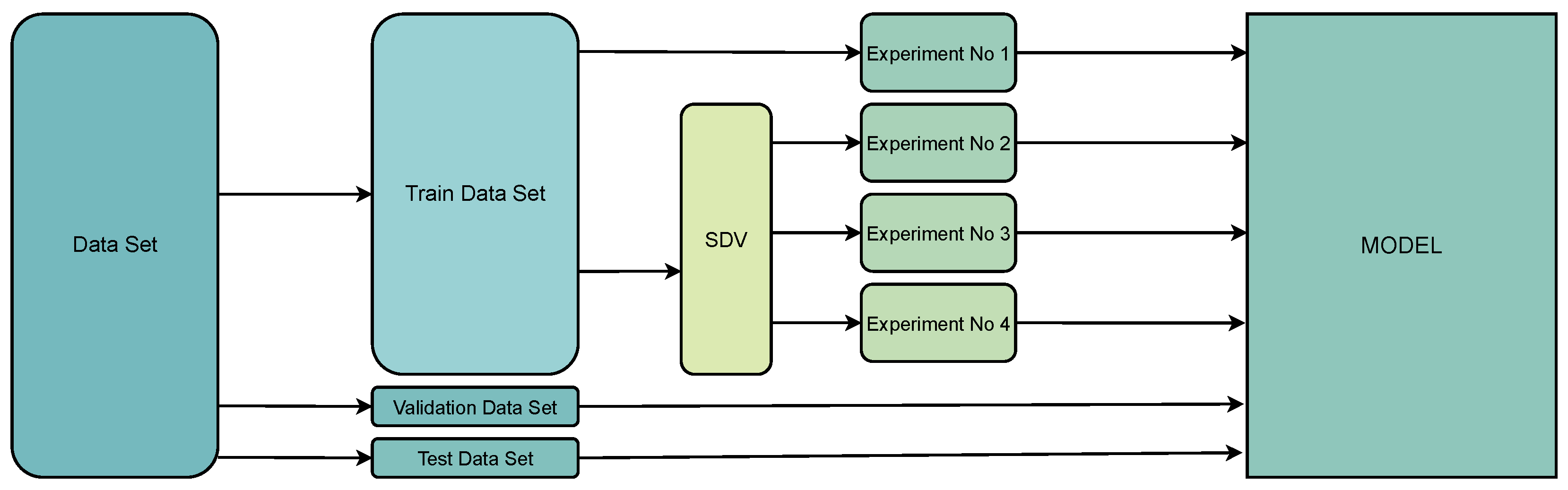
2.3. Data Division and Preparation
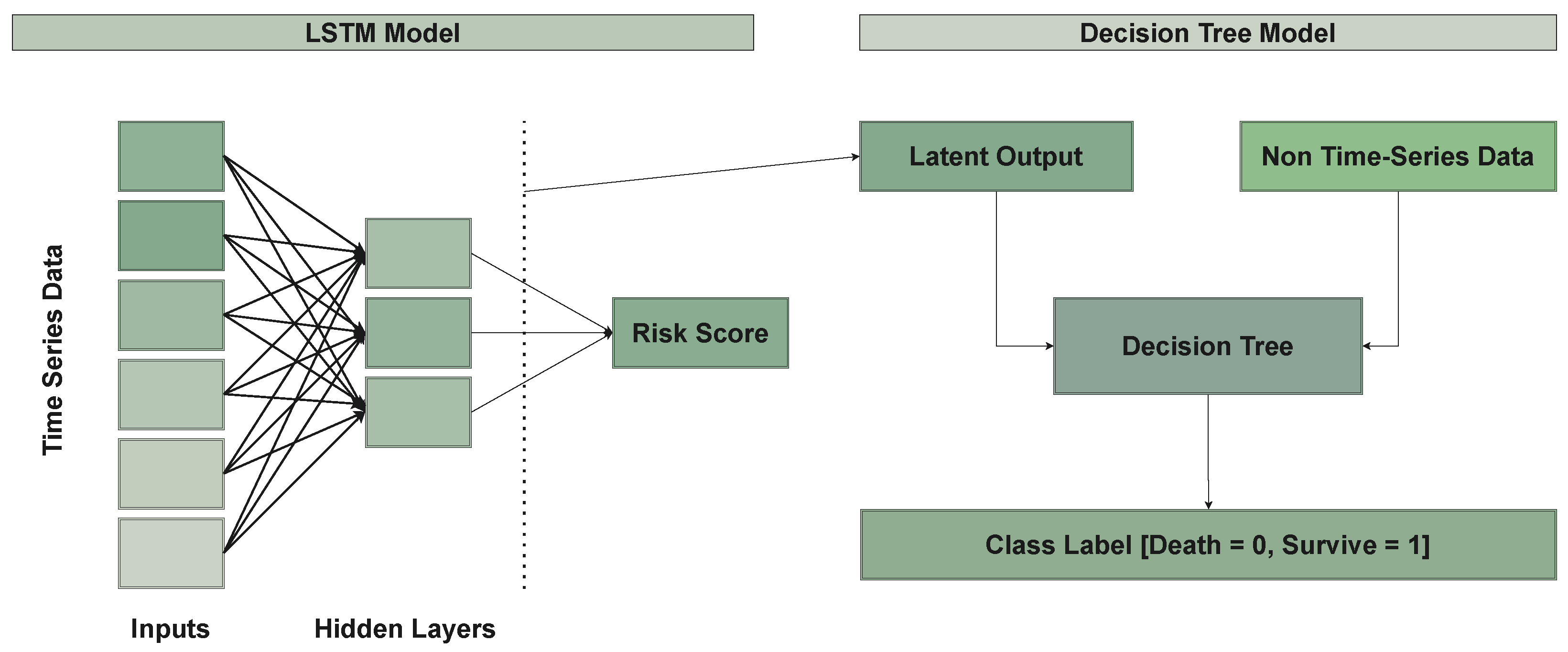
2.4. Model Architecture
2.4.1. LSTM Model
2.4.2. Decision-Tree Model
2.4.3. Latent Vector Space
2.4.4. Handling the Data-Imbalance Problem
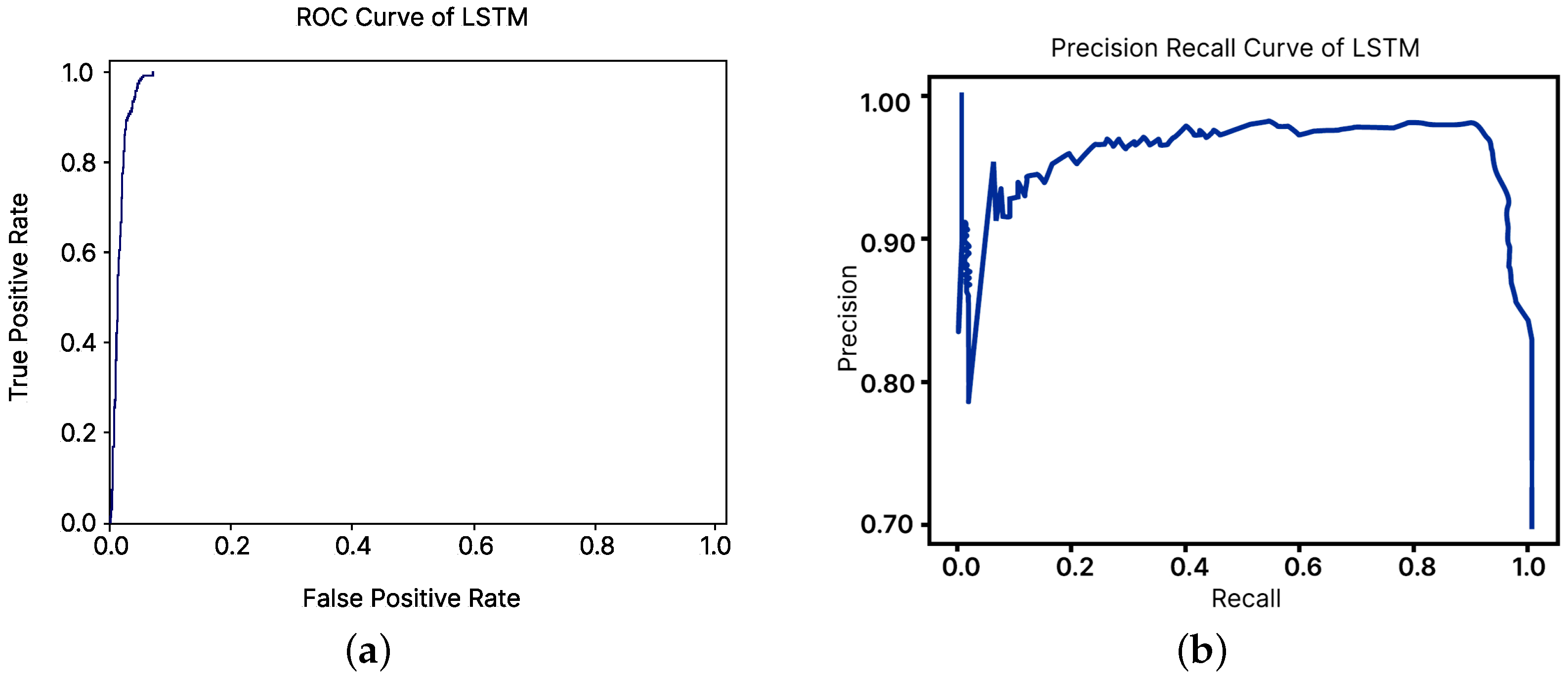
3. Results
3.1. Comparison with Existing Models
3.2. Correlation Analysis
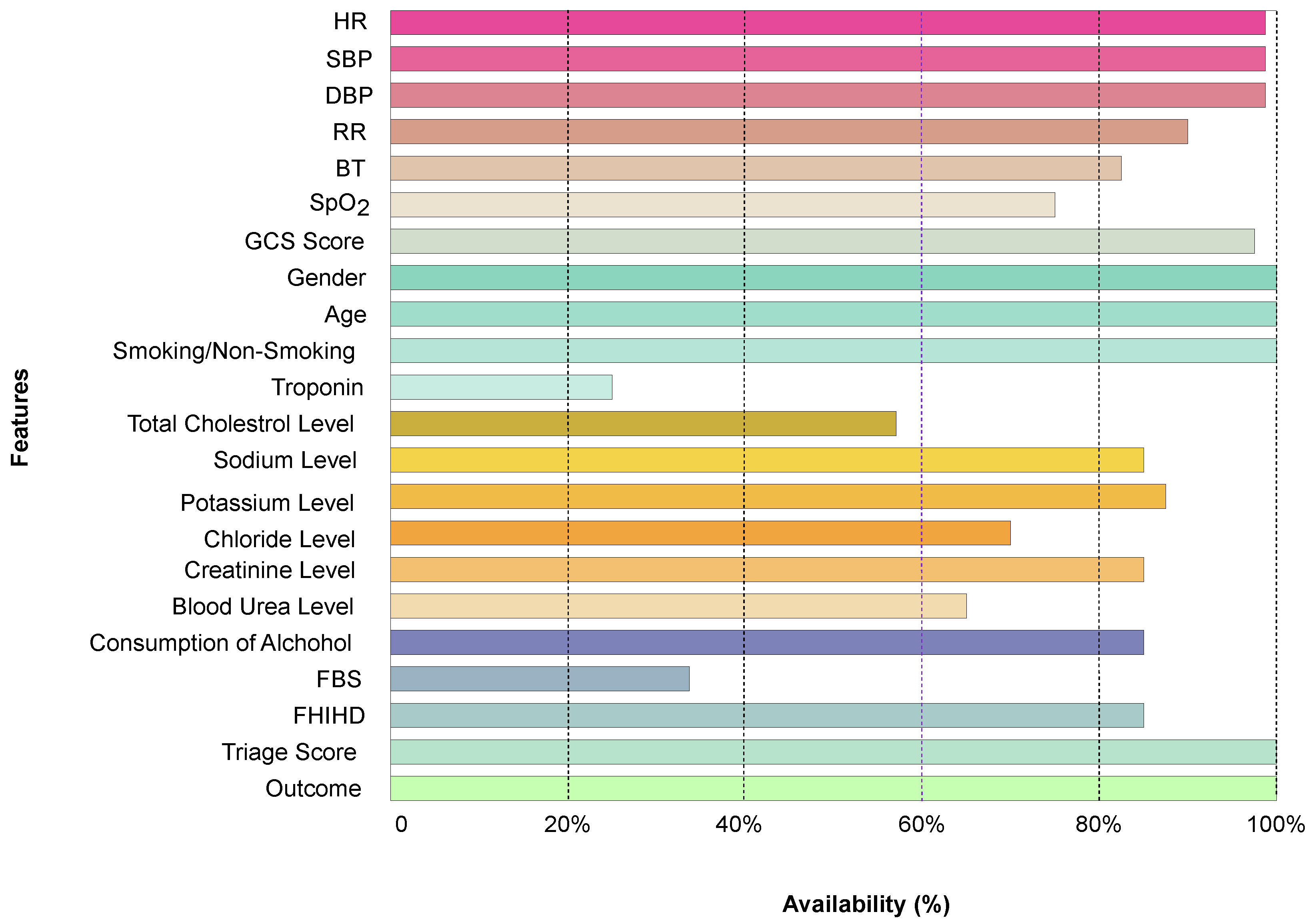
3.3. Characteristics of the Study Population
4. Discussion
4.1. Comparison with Existing EWSs
4.2. Limitations
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LSTM | Long Short-Term Memory |
| CVD | Cardiovascular Diseases |
| EWS | Early Warning System |
| RRT | Rapid Response Teams |
| DRT | Dedicated Resuscitation Teams |
| LMIC | Low- to Middle-Income Countries |
| HIC | High-Income Countries |
| BHT | Bed Head Ticket |
| THK | Teaching Hospital, Karapitiya |
| ETU | Emergency Treatment Unit |
| HR | Heart Rate |
| SBP | Systolic Blood Pressure |
| DBP | Diastolic Blood Pressure |
| RR | Respiratory Rate |
| BT | Body Temperature |
| SpO2 | Blood Oxygen Saturation Level |
| FBS | Fasting Blood Sugar |
| FHIHD | Family History of Ischemic Heart Diseases |
| DLCAPM | Deep-Learning Cardiac Arrest Prediction Model |
| RNN | Recurrent Neural Network |
| CDA | Clinical Decision Analysis |
| SMOTE | Synthetic Minority Over-sampling Technique |
| GCS | Glasgow Coma Scale |
| SVM | Support Vector Machine |
| PPV | Positive Predictive Value |
| NPV | Negative Predictive Value |
| TPR | True-Positive Rate |
| FPR | False-Positive Rate |
| ROC | Receiver-Operating Characteristic |
| MEWS | Modified Early Warning Score |
| CART | Cardiac Arrest Risk Triage Score |
| NEWS | National Early Warning Score |
| MD CALC | Medical Calculator |
| GRU | Gated Recurrent Unit |
| CNN | Convolutional Neural Networks |
| EMR | Electronic Medical Records |
| ICU | Intensive Care Unit |
| AWTTS | Aggregate Weighted Track and Trigger Systems |
| DEWS | Deep-Learning-Based Early Warning System |
| SMOTE | Synthetic Minority Over-Sampling Technique |
| SDV | Synthetic Data Vault |
References
- Tang, W.; Weil, M. Cardiac Arrest and Cardiopulmonary Resuscitation. In Critical Care Medicine; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef]
- Beane, A.; Ambepitiyawaduge, P.D.S.; Thilakasiri, K.; Stephens, T.; Padeniya, A.; Athapattu, P.; Mahipala, P.G.; Sigera, P.C.; Dondorp, A.M.; Haniffa, R. Practices and perspectives in cardiopulmonary resuscitation attempts and the use of do not attempt resuscitation orders: A cross-sectional survey in Sri Lanka. Indian J. Crit. Care Med.-Peer-Rev. Off. Publ. Indian Soc. Crit. Care Med. 2017, 21, 865. [Google Scholar]
- Abeywardena, M.Y. Dietary fats, carbohydrates and vascular disease: Sri Lankan perspectives. Atherosclerosis 2003, 171, 157–161. [Google Scholar] [CrossRef]
- Ye, C.; Wang, O.; Liu, M.; Zheng, L.; Xia, M.; Hao, S.; Jin, B.; Jin, H.; Zhu, C.; Huang, C.J.; et al. A real-time early warning system for monitoring inpatient mortality risk: Prospective study using electronic medical record data. J. Med. Internet Res. 2019, 21, e13719. [Google Scholar] [CrossRef]
- Marinkovic, O.; Sekulic, A.; Trpkovic, S.; Malenkovic, V.; Pavlovic, A. The importance of early warning score (EWS) in predicting in-hospital cardiac arrest—Our experience. Resuscitation 2013, 84, S85. [Google Scholar] [CrossRef]
- Nishijima, I.; Oyadomari, S.; Maedomari, S.; Toma, R.; Igei, C.; Kobata, S.; Koyama, J.; Tomori, R.; Kawamitsu, N.; Yamamoto, Y.; et al. Use of a modified early warning score system to reduce the rate of in-hospital cardiac arrest. J. Intensive Care 2016, 4, 12. [Google Scholar] [CrossRef]
- Smith, G.B.; Prytherch, D.R.; Schmidt, P.E.; Featherstone, P.I.; Higgins, B. A review, and performance evaluation, of single-parameter “track and trigger” systems. Resuscitation 2008, 79, 11–21. [Google Scholar] [CrossRef]
- Gerry, S.; Birks, J.; Bonnici, T.; Watkinson, P.J.; Kirtley, S.; Collins, G.S. Early warning scores for detecting deterioration in adult hospital patients: A systematic review protocol. BMJ Open 2017, 7, e019268. [Google Scholar] [CrossRef]
- Kwon, J.m.; Lee, Y.; Lee, Y.; Lee, S.; Park, J. An algorithm based on deep learning for predicting in-hospital cardiac arrest. J. Am. Heart Assoc. 2018, 7, e008678. [Google Scholar] [CrossRef]
- Kim, J.; Park, Y.R.; Lee, J.H.; Lee, J.H.; Kim, Y.H.; Huh, J.W. Development of a real-time risk prediction model for in-hospital cardiac arrest in critically ill patients using deep learning: Retrospective study. JMIR Med. Inform. 2020, 8, e16349. [Google Scholar] [CrossRef]
- Tonekaboni, S.; Mazwi, M.; Laussen, P.; Eytan, D.; Greer, R.; Goodfellow, S.D.; Goodwin, A.; Brudno, M.; Goldenberg, A. Prediction of cardiac arrest from physiological signals in the pediatric ICU. In Proceedings of the Machine Learning for Healthcare Conference, PMLR, Palo Alto, CA, USA, 17–18 August 2018; pp. 534–550. [Google Scholar]
- Alamgir, A.; Mousa, O.; Shah, Z. Artificial intelligence in predicting cardiac arrest: Scoping review. JMIR Med. Inform. 2021, 9, e30798. [Google Scholar] [CrossRef]
- Dumas, F.; Bougouin, W.; Cariou, A. Cardiac arrest: Prediction models in the early phase of hospitalization. Curr. Opin. Crit. Care 2019, 25, 204–210. [Google Scholar] [CrossRef] [PubMed]
- Somanchi, S.; Adhikari, S.; Lin, A.; Eneva, E.; Ghani, R. Early prediction of cardiac arrest (code blue) using electronic medical records. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 2119–2126. [Google Scholar]
- Ong, M.E.H.; Lee Ng, C.H.; Goh, K.; Liu, N.; Koh, Z.X.; Shahidah, N.; Zhang, T.T.; Fook-Chong, S.; Lin, Z. Prediction of cardiac arrest in critically ill patients presenting to the emergency department using a machine learning score incorporating heart rate variability compared with the modified early warning score. Crit. Care 2012, 16, R108. [Google Scholar] [CrossRef] [PubMed]
- Churpek, M.M.; Yuen, T.C.; Park, S.Y.; Meltzer, D.O.; Hall, J.B.; Edelson, D.P. Derivation of a cardiac arrest prediction model using ward vital signs. Crit. Care Med. 2012, 40, 2102. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Lin, Z.; Cao, J.; Koh, Z.; Zhang, T.; Huang, G.B.; Ser, W.; Ong, M.E.H. An intelligent scoring system and its application to cardiac arrest prediction. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1324–1331. [Google Scholar] [CrossRef] [PubMed]
- Chae, M.; Han, S.; Gil, H.; Cho, N.; Lee, H. Prediction of in-hospital cardiac arrest using shallow and deep learning. Diagnostics 2021, 11, 1255. [Google Scholar] [CrossRef] [PubMed]
- Murukesan, L.; Murugappan, M.; Iqbal, M.; Saravanan, K. Machine learning approach for sudden cardiac arrest prediction based on optimal heart rate variability features. J. Med. Imaging Health Inform. 2014, 4, 521–532. [Google Scholar] [CrossRef]
- Ueno, R.; Xu, L.; Uegami, W.; Matsui, H.; Okui, J.; Hayashi, H.; Miyajima, T.; Hayashi, Y.; Pilcher, D.; Jones, D. Value of laboratory results in addition to vital signs in a machine learning algorithm to predict in-hospital cardiac arrest: A single-center retrospective cohort study. PLoS ONE 2020, 15, e0235835. [Google Scholar] [CrossRef] [PubMed]
- De Silva, A.P.; Sujeewa, J.A.; De Silva, N.; Rathnayake, R.M.D.; Vithanage, L.; Sigera, P.C.; Munasinghe, S.; Beane, A.; Stephens, T.; Athapattu, P.L.; et al. A retrospective study of physiological observation-reporting practices and the recognition, response, and outcomes following cardiopulmonary arrest in a low-to-middle-income country. Indian J. Crit. Care Med.-Peer-Rev. Off. Publ. Indian Soc. Crit. Care Med. 2017, 21, 343. [Google Scholar] [CrossRef]
- Ranawaka, U.; Wijekoon, C.; Pathmeswaran, A.; Kasturiratne, A.; Gunasekera, D.; Chackrewarthy, S.; Kato, N.; Wickramasinghe, A. Risk Estimates of Cardiovascular Diseases in a Sri Lankan Community. Ceylon Med. J. 2016, 61, 11–17. [Google Scholar] [CrossRef]
- Rajapaksha, L.; Vidanagamachchi, S.; Gunawardena, S.; Thambawita, V. Cardiac Patient Bed Head Ticket Dataset; Zenodo: Geneva, Switzerland, 2023. [Google Scholar] [CrossRef]
- Patki, N.; Wedge, R.; Veeramachaneni, K. The synthetic data vault. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 399–410. [Google Scholar]
- Kim, J.; Chae, M.; Chang, H.J.; Kim, Y.A.; Park, E. Predicting cardiac arrest and respiratory failure using feasible artificial intelligence with simple trajectories of patient data. J. Clin. Med. 2019, 8, 1336. [Google Scholar] [CrossRef]
- Choi, E.; Schuetz, A.; Stewart, W.F.; Sun, J. Using recurrent neural network models for early detection of heart failure onset. J. Am. Med. Inform. Assoc. 2017, 24, 361–370. [Google Scholar] [CrossRef] [PubMed]
- Ge, W.; Huh, J.W.; Park, Y.R.; Lee, J.H.; Kim, Y.H.; Turchin, A. An Interpretable ICU Mortality Prediction Model Based on Logistic Regression and Recurrent Neural Networks with LSTM units. AMIA Annu. Symp. Proc. 2018, 2018, 460–469. [Google Scholar] [PubMed]
- Aczon, M.; Ledbetter, D.; Ho, L.; Gunny, A.; Flynn, A.; Williams, J.; Wetzel, R. Dynamic mortality risk predictions in pediatric critical care using recurrent neural networks. arXiv 2017, arXiv:1701.06675. [Google Scholar]
- Aleem, I.S.; Schemitsch, E.H.; Hanson, B.P. What is a clinical decision analysis study? Indian J. Orthop. 2008, 42, 137. [Google Scholar] [CrossRef]
- Bae, J.M. The clinical decision analysis using decision tree. Epidemiol. Health 2014, 36, e2014025. [Google Scholar] [CrossRef] [PubMed]
- Myers, J.; McCabe, S.J. Understanding medical decision making in hand surgery. Clin. Plast. Surg. 2005, 32, 453–461. [Google Scholar] [CrossRef] [PubMed]
- Podgorelec, V.; Kokol, P.; Stiglic, B.; Rozman, I. Decision trees: An overview and their use in medicine. J. Med. Syst. 2002, 26, 445–463. [Google Scholar] [CrossRef] [PubMed]
- van den Goorbergh, R.; van Smeden, M.; Timmerman, D.; Van Calster, B. The harm of class imbalance corrections for risk prediction models: Illustration and simulation using logistic regression. J. Am. Med. Inform. Assoc. 2022, 29, 1525–1534. [Google Scholar] [CrossRef]
- Kurniawan, L.B.; Bahrun, U.; Mangarengi, F.; Darmawati, E.; Arif, M. Blood urea nitrogen as a predictor of mortality in myocardial infarction. Universa Med. 2013, 32, 172–178. [Google Scholar]
- Kughapriya, P.; Evangeline, J. Evaluation of serum electrolytes in Ischemic Heart Disease patients. Natl. J. Basic Med. Sci. 2016, 6, 1–14. [Google Scholar]
- Tan, B.Y.; Judge, D.P. A clinical approach to a family history of sudden death. Circ. Cardiovasc. Genet. 2012, 5, 697–705. [Google Scholar] [CrossRef] [PubMed]
- Mukaka, M.M. A guide to appropriate use of correlation coefficient in medical research. Malawi Med. J. 2012, 24, 69–71. [Google Scholar] [PubMed]
- Chae, M.; Gil, H.W.; Cho, N.J.; Lee, H. Machine learning-based cardiac arrest prediction for early warning system. Mathematics 2022, 10, 2049. [Google Scholar] [CrossRef]
- Subbe, C. Modified Early Warning Score (MEWS) for Clinical Deterioration; MDCalc: San Francisco, CA, USA, 2020. [Google Scholar]
- Smith, G.; Redfern, O.; Pimentel, M.; Gerry, S.; Collins, G.; Malycha, J.; Prytherch, D.; Schmidt, P.; Watkinson, P. The national early warning score 2 (NEWS2). Clin. Med. 2019, 19, 260. [Google Scholar] [CrossRef]
- Beane, A.; De Silva, A.P.; De Silva, N.; Sujeewa, J.A.; Rathnayake, R.D.; Sigera, P.C.; Athapattu, P.L.; Mahipala, P.G.; Rashan, A.; Munasinghe, S.B.; et al. Evaluation of the feasibility and performance of early warning scores to identify patients at risk of adverse outcomes in a low-middle income country setting. BMJ Open 2018, 8, e019387. [Google Scholar] [CrossRef]
- Brlek, P.; Pavelić, E.S.; Mešić, J.; Vrdoljak, K.; Skelin, A.; Manola, Š.; Pavlović, N.; Ćatić, J.; Matijević, G.; Brugada, J.; et al. State-of-the-art Risk-modifying Treatment of Sudden Cardiac Death in an Asymptomatic Patient with a Mutation in the SCN5A Gene and Review of the Literature. Front. Cardiovasc. Med. 2023, 10, 1193878. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset 01 | Training Dataset 02 | Training Dataset 03 | Training Dataset 04 | |||||
|---|---|---|---|---|---|---|---|---|
| No. of Sequences | No. of Records | No. of Sequences | No. of Records | No. of Sequences | No. of Records | No. of Sequences | No. of Records | |
| Real Survived-Patient Data | 4287 | 74 | 4287 | 74 | 0 | 0 | 4287 | 74 |
| Synthetic Survived-Patient Data | 0 | 0 | 0 | 0 | 4870 | 74 | 4870 | 74 |
| Real Dead-Patient Data | 743 | 15 | 743 | 15 | 0 | 0 | 743 | 15 |
| Synthetic Dead-Patient Data | 0 | 0 | 1768 | 59 | 4702 | 74 | 5259 | 133 |
| Total | 5030 | 89 | 6798 | 148 | 9572 | 148 | 15,159 | 296 |
| Experiment No. | RS | RD | SS | SD | Accuracy |
|---|---|---|---|---|---|
| 01 | 74 | 15 | - | - | 0.954 |
| 02 | 74 | 15 | - | 59 | 0.954 |
| 03 | - | - | 74 | 74 | 0.964 |
| 04 | 74 | 15 | 74 | 133 | 0.967 |
| No. of Epochs | Learning Rate | Batch Size | LSTM Nodes | Optimizer |
|---|---|---|---|---|
| 100 | 0.001 | 10 | 2 | Adam |
| Model | Accuracy | Sensitivity | Specificity | PPV | NPV | F-Score |
|---|---|---|---|---|---|---|
| LSTM | 0.96 | 0.95 | 0.93 | 0.98 | 0.81 | 0.86 |
| Decision Tree | 0.76 | 0.69 | 0.81 | 0.72 | 0.79 | 0.80 |
| SVM | 0.89 | 0.84 | 0.82 | 0.81 | 0.82 | 0.84 |
| Logistic Regression | 0.88 | 0.93 | 0.81 | 0.92 | 0.81 | 0.87 |
| Random Forest | 0.88 | 0.89 | 0.90 | 0.87 | 0.81 | 0.91 |
| Naïve Bayes | 0.85 | 0.89 | 0.80 | 0.82 | 0.88 | 0.91 |
| Characteristic | Data |
|---|---|
| Study period | 13 August 2018–6 February 2020 |
| Hospital | Teaching Hospital Karapitiya, Galle, Sri Lanka |
| Total patients | 112 |
| Input vectors | 19 |
| Age group | 59–76 years |
| Male (%) | 73% |
| Symptoms before admission | Chest pain on the left side (1/2 h before the admission), Tightening of the chest, Vomiting, Sweating, Nausea, Cough, Fever |
| Patients with FHIHD (%) | 37% |
| Consume alcohol, Male (%) | 69% |
| Smoking, Male (%) | 63% |
| Smoking & use alcohol, Male (%) | 26% |
| Metric | LSTM | Decision Tree | ||||||
|---|---|---|---|---|---|---|---|---|
| Experiment Number | Experiment Number | |||||||
| 01 | 02 | 03 | 04 | 01 | 02 | 03 | 04 | |
| Accuracy | 0.93 | 0.85 | 0.94 | 0.96 | 0.80 | 0.83 | 0.80 | 0.76 |
| Precision | 0.90 | 0.88 | 0.90 | 0.98 | 0.68 | 0.70 | 0.66 | 0.72 |
| Recall | 0.91 | 0.85 | 0.91 | 0.95 | 0.65 | 0.68 | 0.63 | 0.69 |
| F-Score | 0.81 | 0.86 | 0.81 | 0.86 | 0.82 | 0.85 | 0.82 | 0.80 |
| AUC score | 0.97 | 0.95 | 0.97 | 0.98 | 0.79 | 0.83 | 0.79 | 0.75 |
| Statistic | Value | 95% CI | ||
|---|---|---|---|---|
| LSTM Model | Decision-Tree Model | LSTM Model | Decision-Tree Model | |
| Sensitivity | 95.83% | 69.57% | 95.37% to 96.25% | 47.08% to 86.79% |
| Specificity | 93.42% | 81.82% | 92.07% to 94.61% | 64.54% to 93.02% |
| Positive Predictive Value | 98.71% | 72.73% | 98.44% to 98.93% | 55.19% to 85.24% |
| Negative Predictive Value | 81.04% | 79.41% | 79.37% to 82.60% | 67.07% to 87.96% |
| Model | Accuracy | Sensitivity | Specificity | PPV | NPV | F-Score |
|---|---|---|---|---|---|---|
| LSTM | 0.96 | 0.95 | 0.93 | 0.98 | 0.81 | 0.86 |
| Decision Tree | 0.76 | 0.69 | 0.81 | 0.72 | 0.79 | 0.80 |
| CART | 0.60 | 0.50 | 0.75 | 0.75 | 0.75 | 0.60 |
| MEWS | 0.80 | 0.93 | 0.40 | 0.82 | 0.4 | 0.50 |
| NEWS | 0.80 | 0.84 | 0.66 | 0.94 | 0.66 | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajapaksha, L.T.W.; Vidanagamachchi, S.M.; Gunawardena, S.; Thambawita, V. An Open-Access Dataset of Hospitalized Cardiac-Arrest Patients: Machine-Learning-Based Predictions Using Clinical Documentation. BioMedInformatics 2024, 4, 34-49. https://doi.org/10.3390/biomedinformatics4010003
Rajapaksha LTW, Vidanagamachchi SM, Gunawardena S, Thambawita V. An Open-Access Dataset of Hospitalized Cardiac-Arrest Patients: Machine-Learning-Based Predictions Using Clinical Documentation. BioMedInformatics. 2024; 4(1):34-49. https://doi.org/10.3390/biomedinformatics4010003
Chicago/Turabian StyleRajapaksha, Lahiru Theekshana Weerasinghe, Sugandima Mihirani Vidanagamachchi, Sampath Gunawardena, and Vajira Thambawita. 2024. "An Open-Access Dataset of Hospitalized Cardiac-Arrest Patients: Machine-Learning-Based Predictions Using Clinical Documentation" BioMedInformatics 4, no. 1: 34-49. https://doi.org/10.3390/biomedinformatics4010003
APA StyleRajapaksha, L. T. W., Vidanagamachchi, S. M., Gunawardena, S., & Thambawita, V. (2024). An Open-Access Dataset of Hospitalized Cardiac-Arrest Patients: Machine-Learning-Based Predictions Using Clinical Documentation. BioMedInformatics, 4(1), 34-49. https://doi.org/10.3390/biomedinformatics4010003