

Factors Associated with Unplanned Hospital Readmission after Discharge: A Descriptive and Predictive Study Using Electronic Health Record Data



Abstract
1. Introduction
2. Methods
2.1. Dataset
2.2. Data Preprocessing
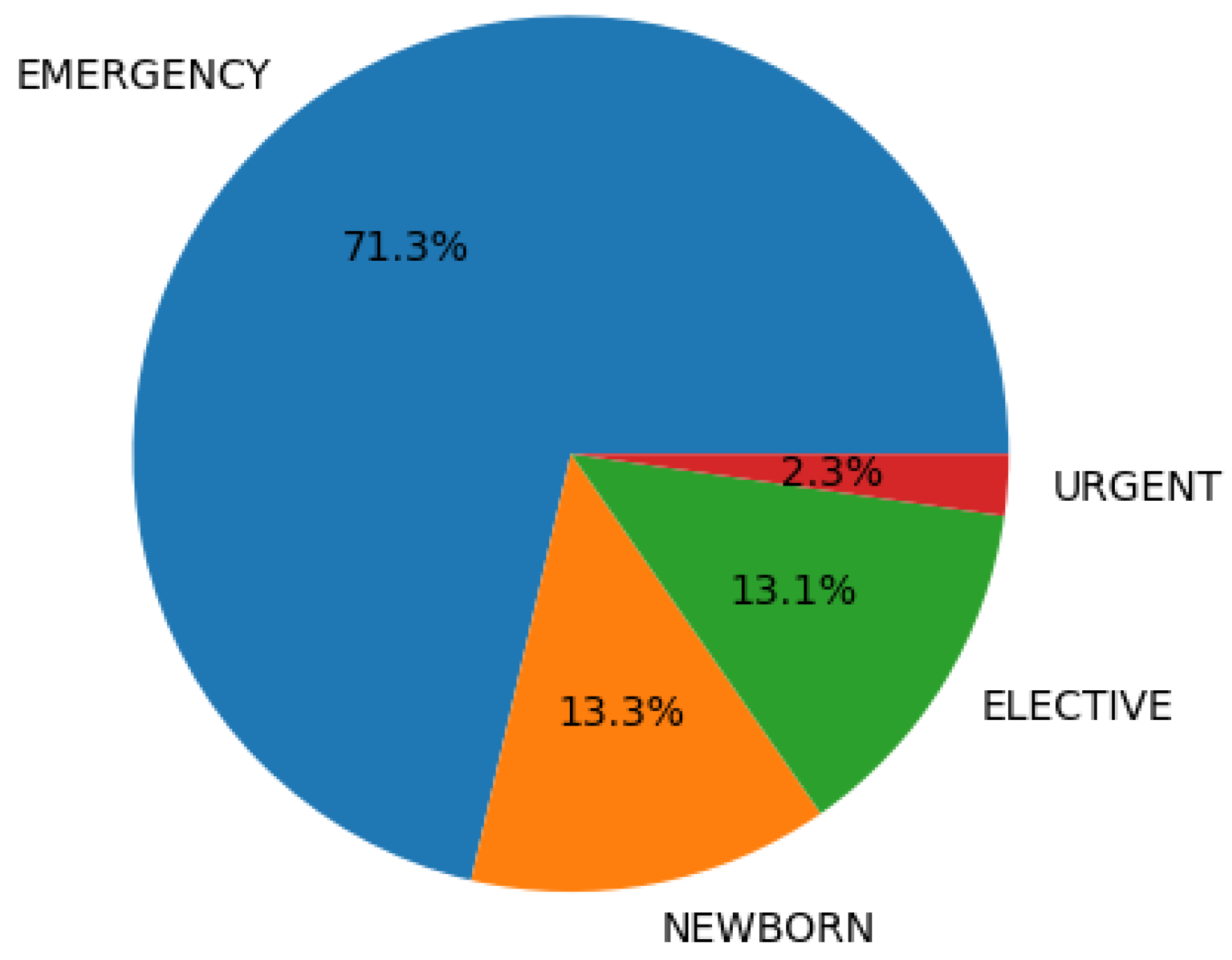
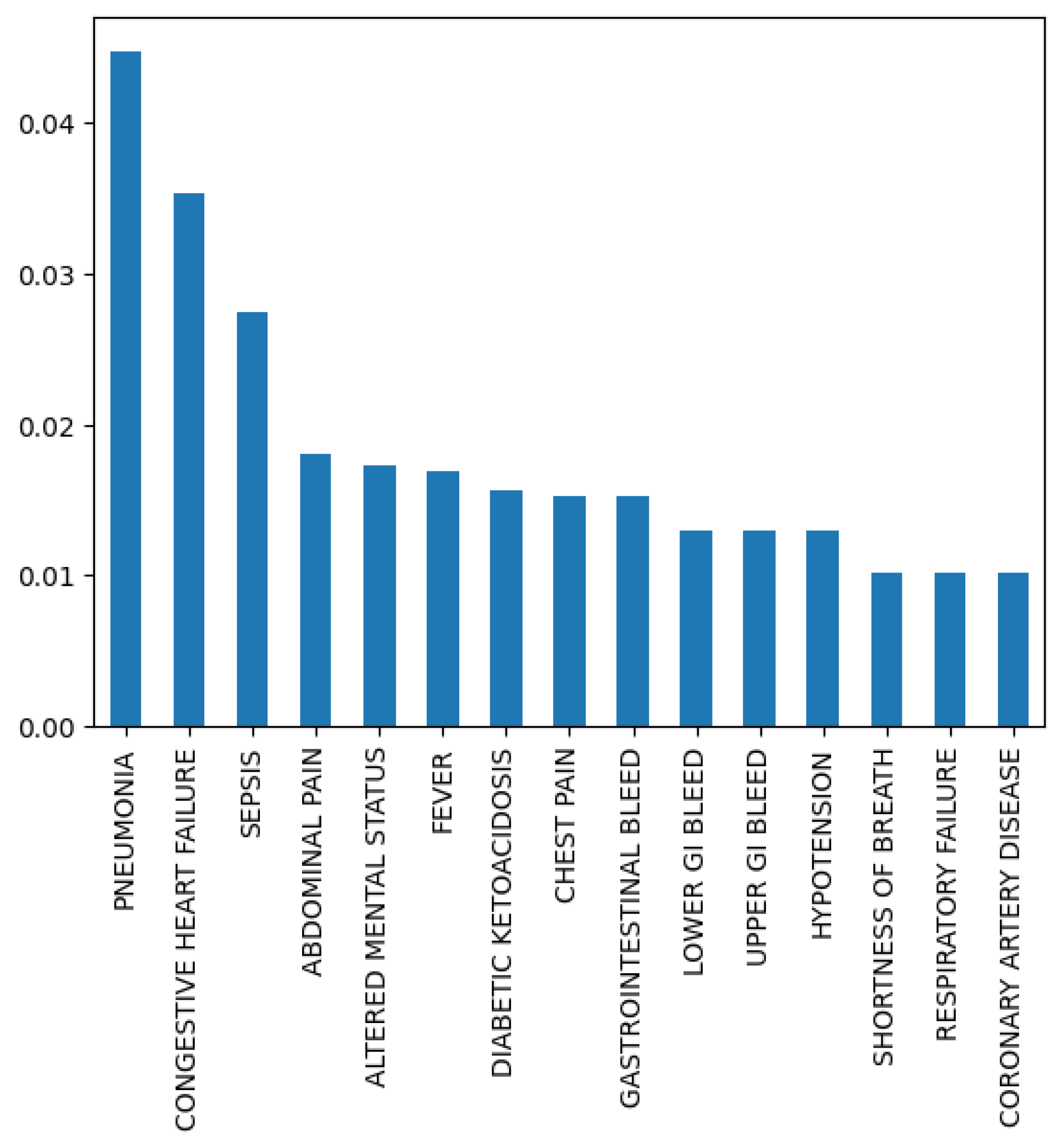
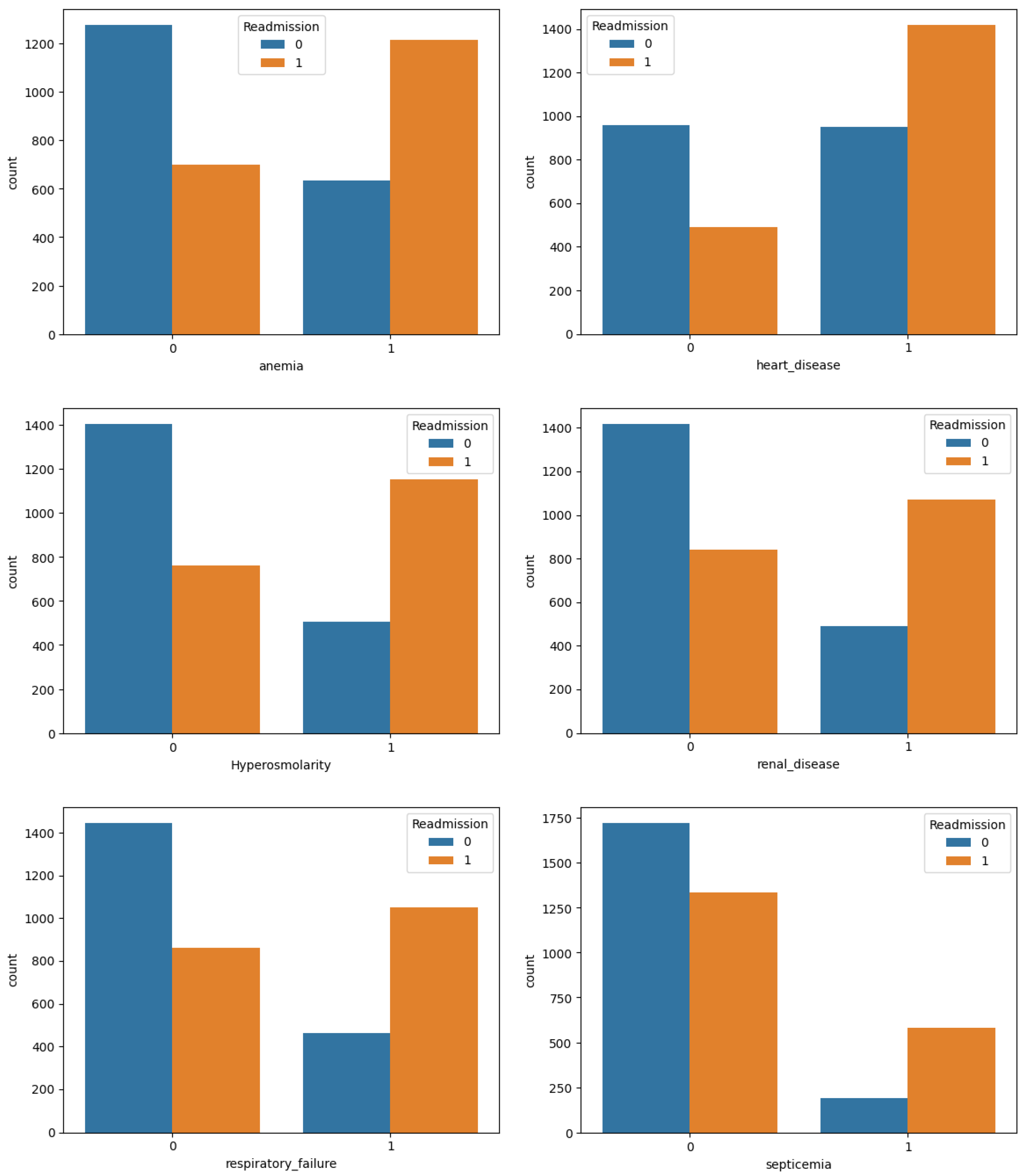
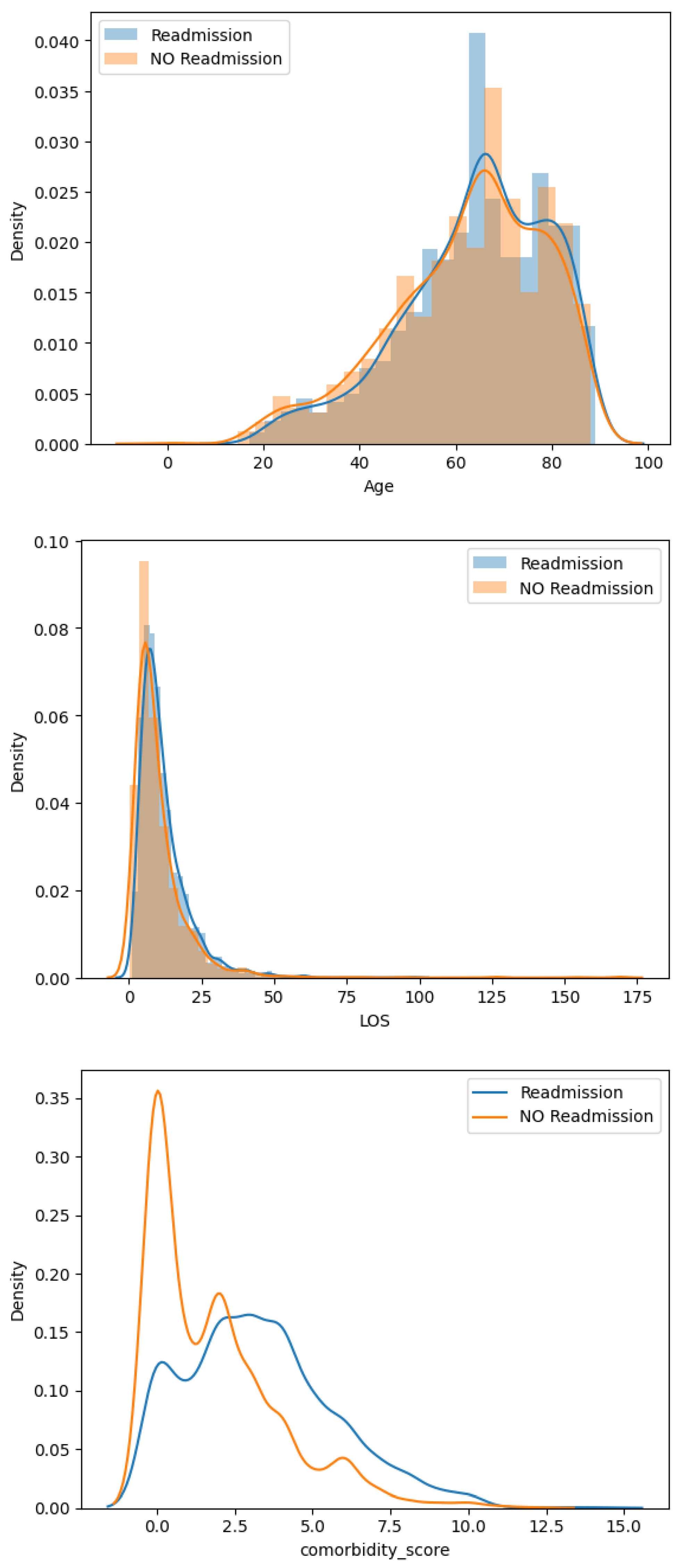
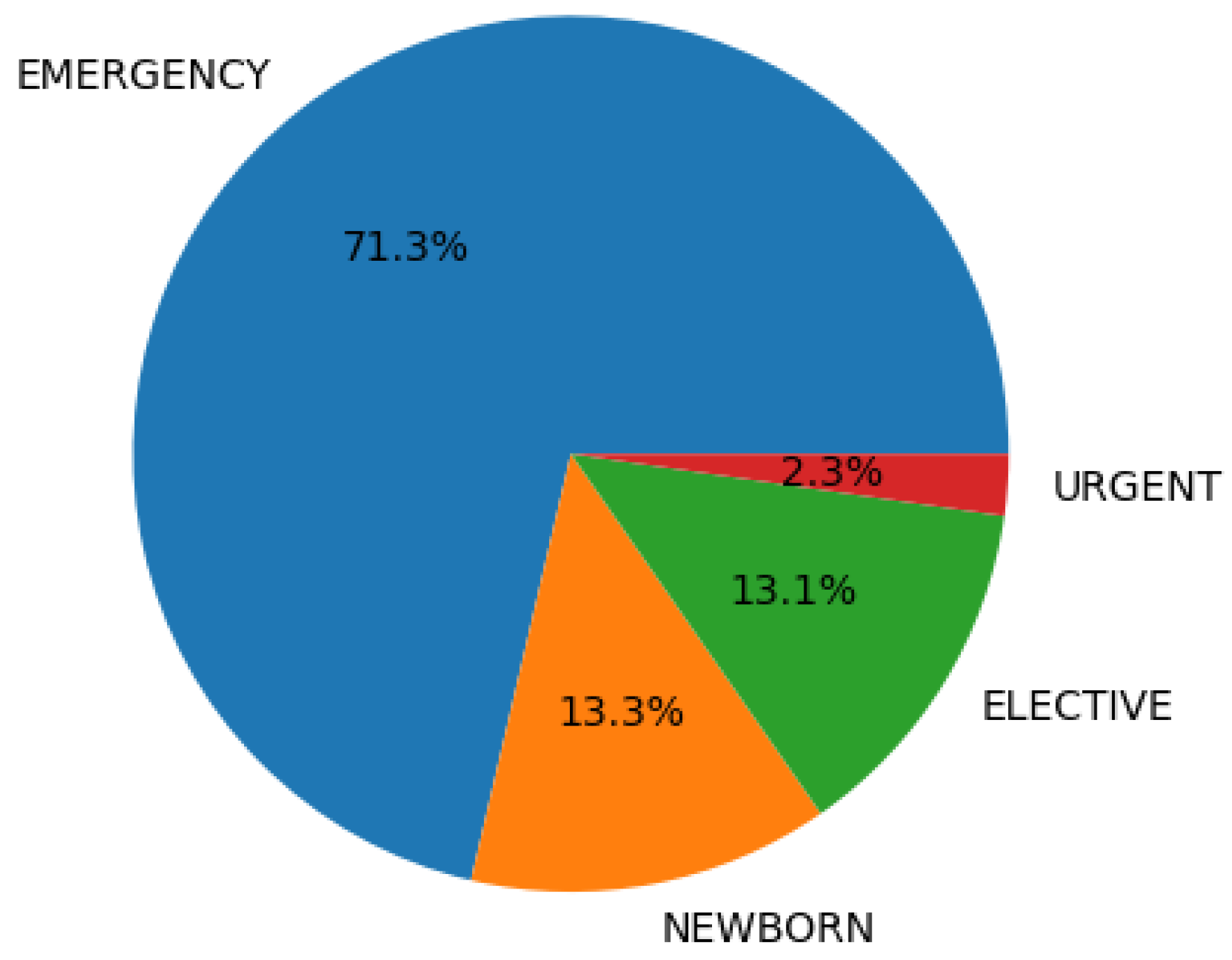
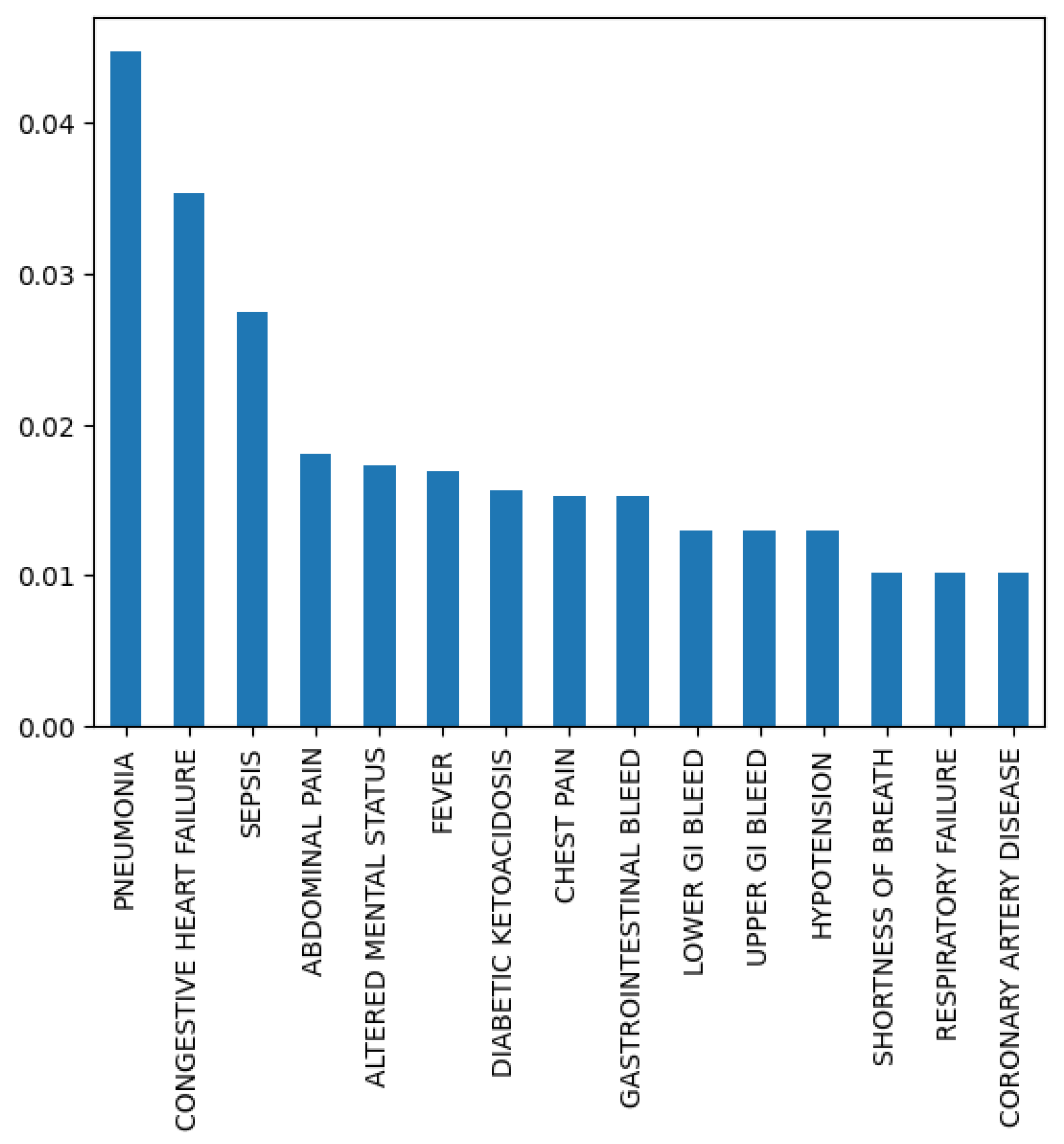
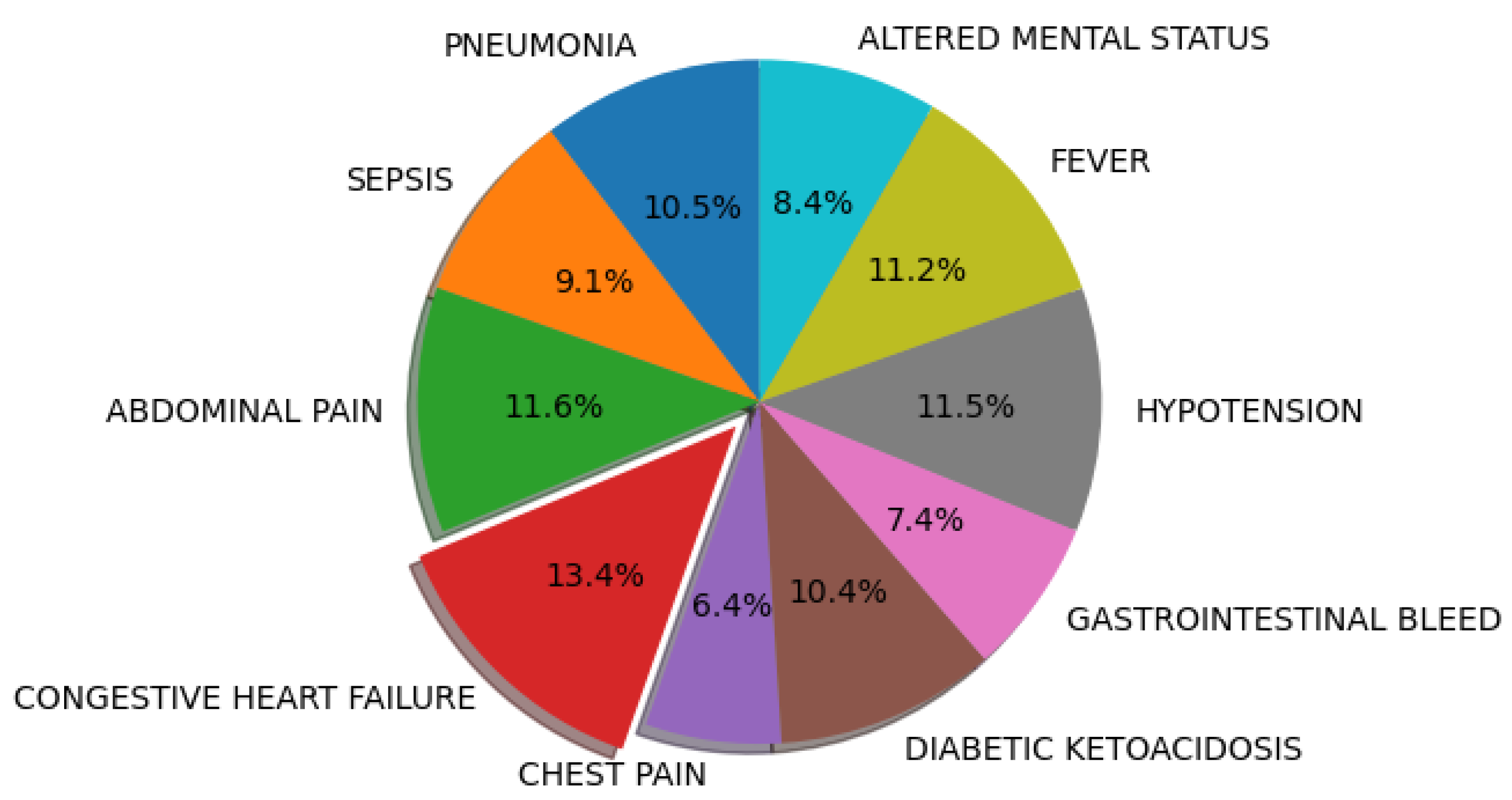
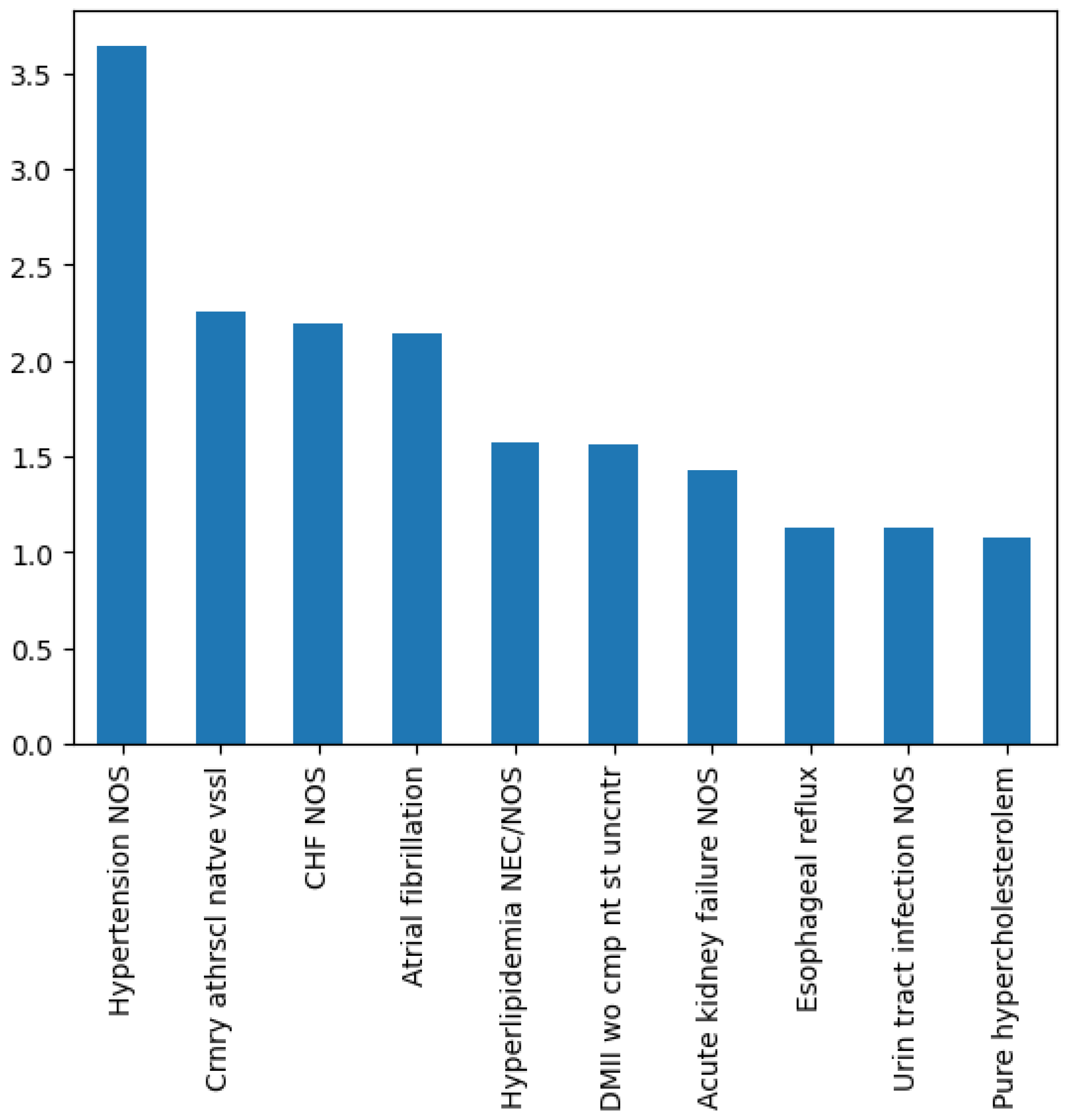
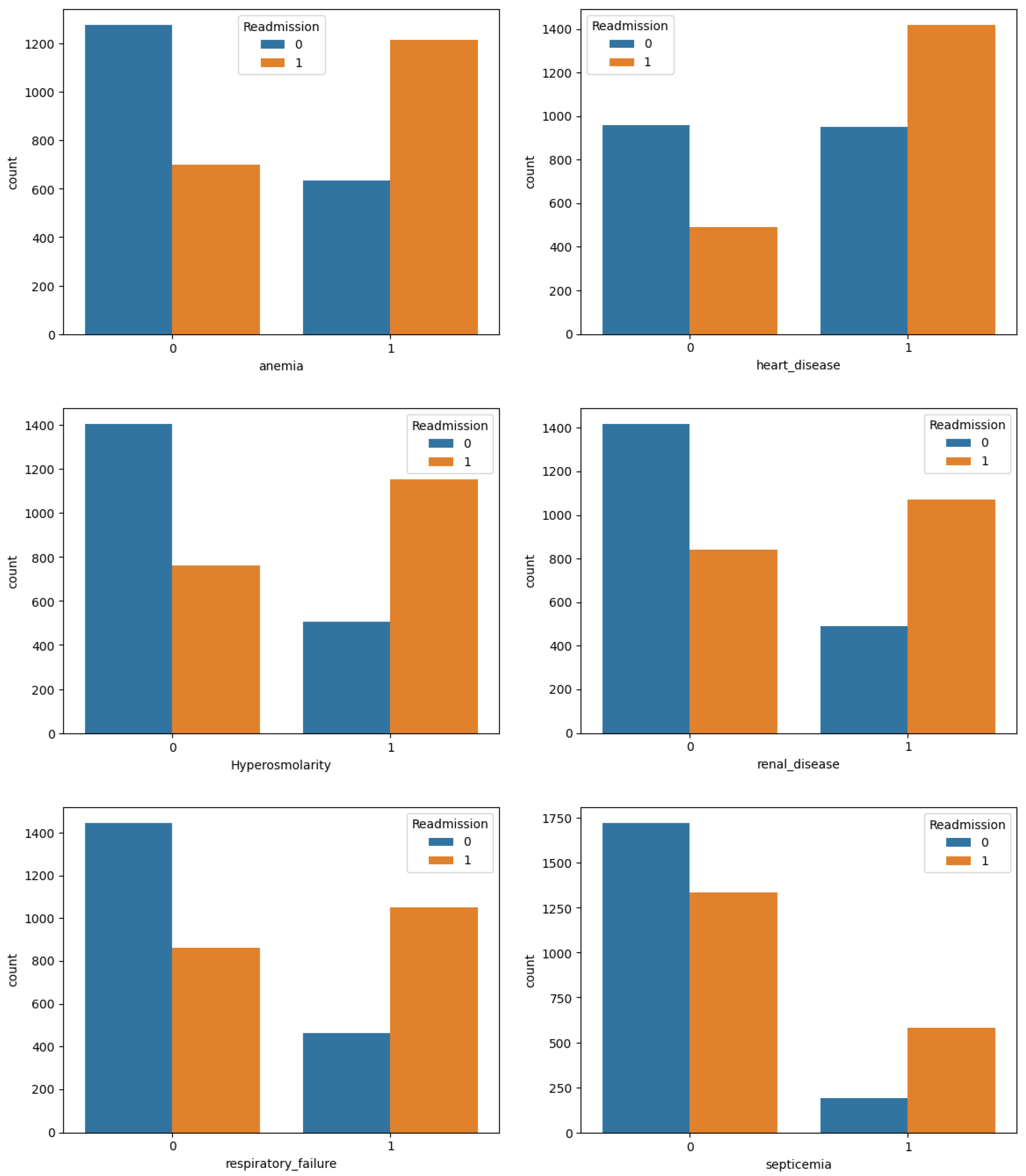
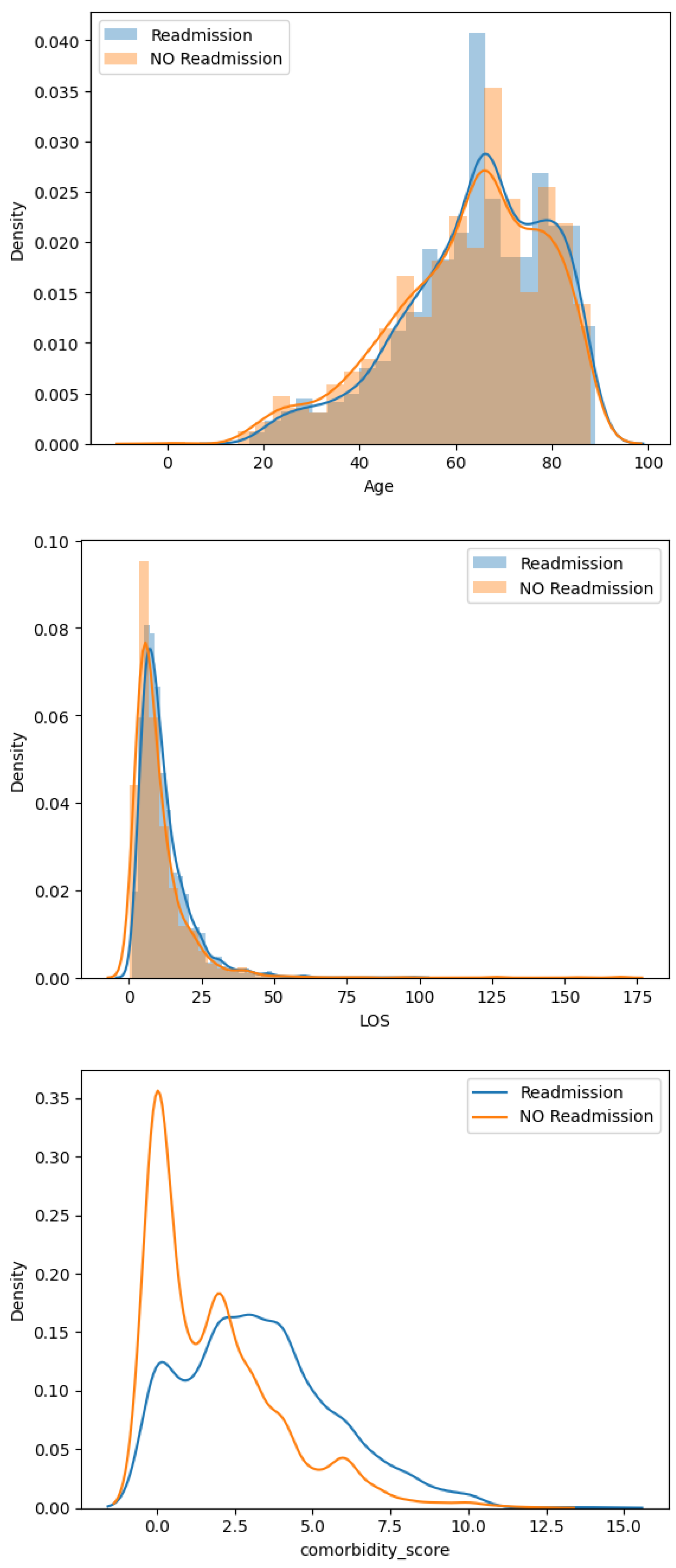
2.3. Descriptive Analysis
3. Results
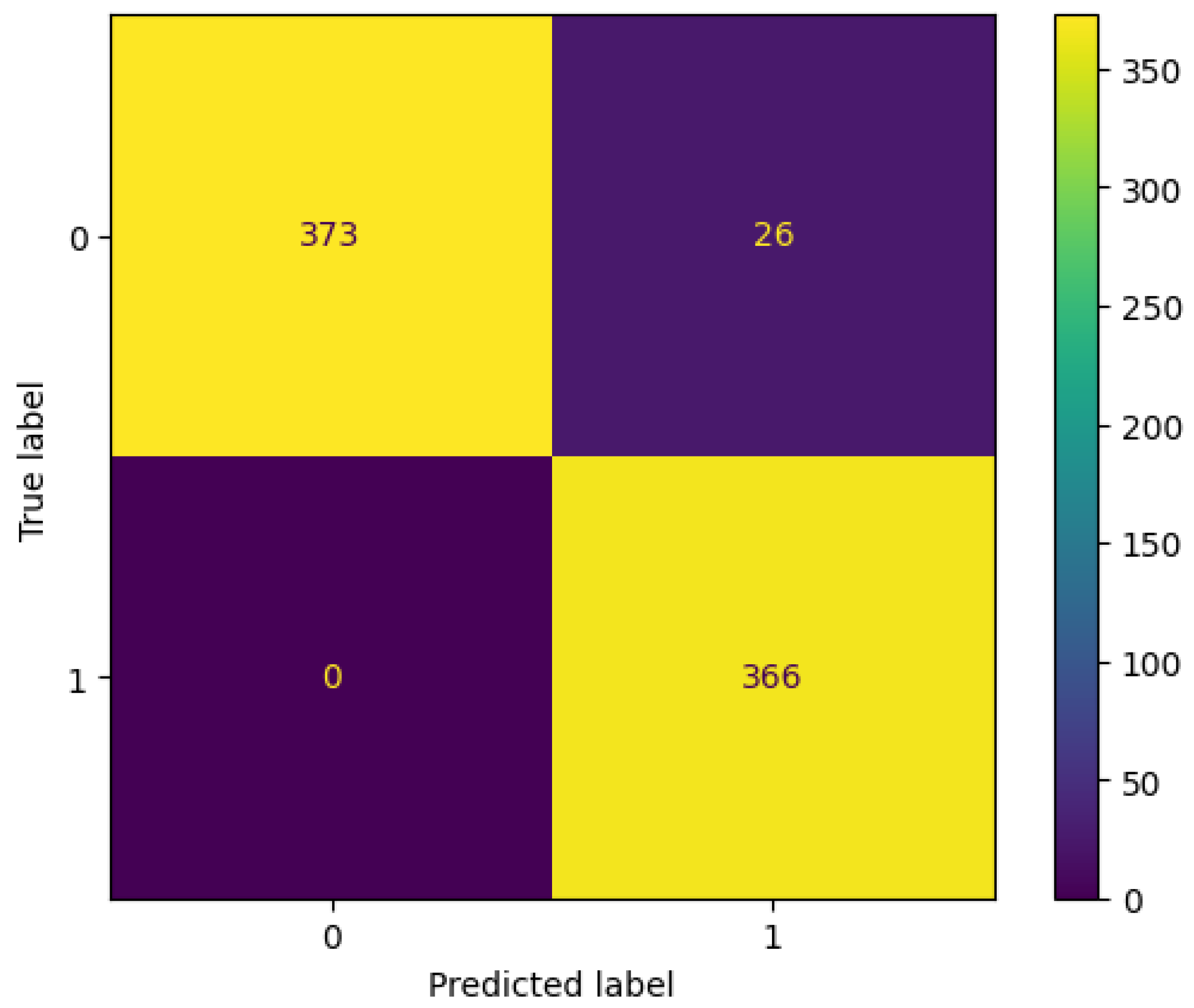
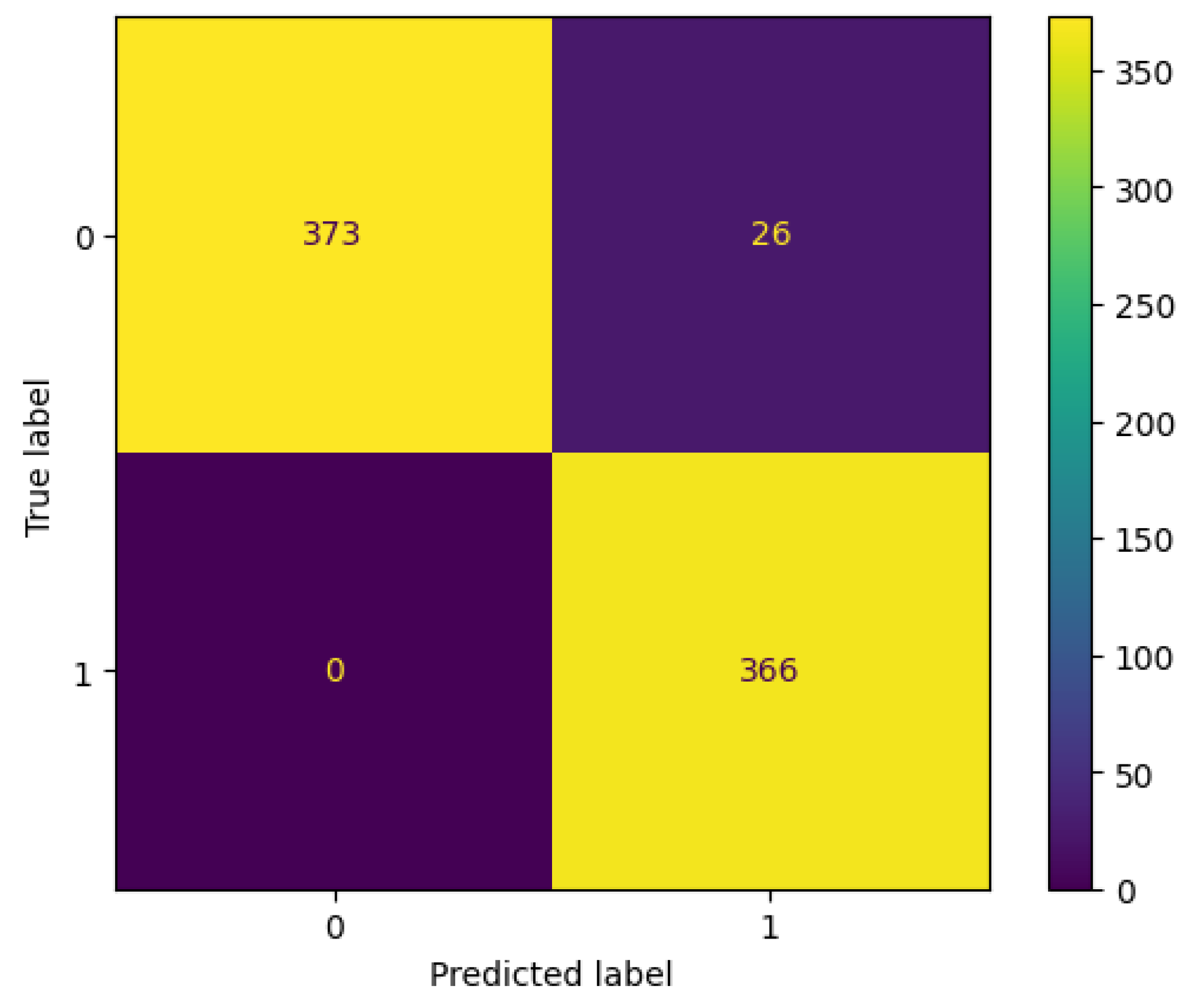
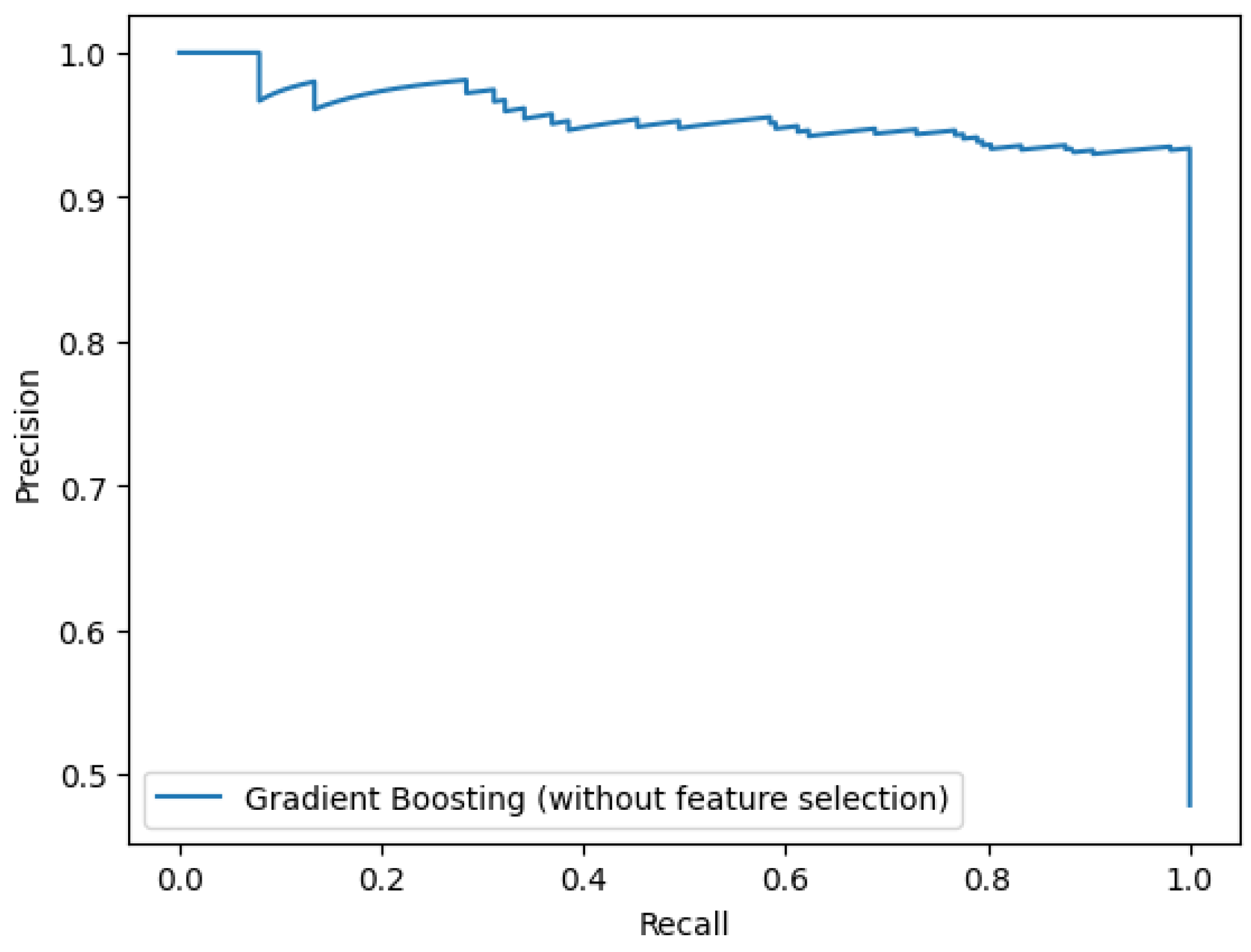
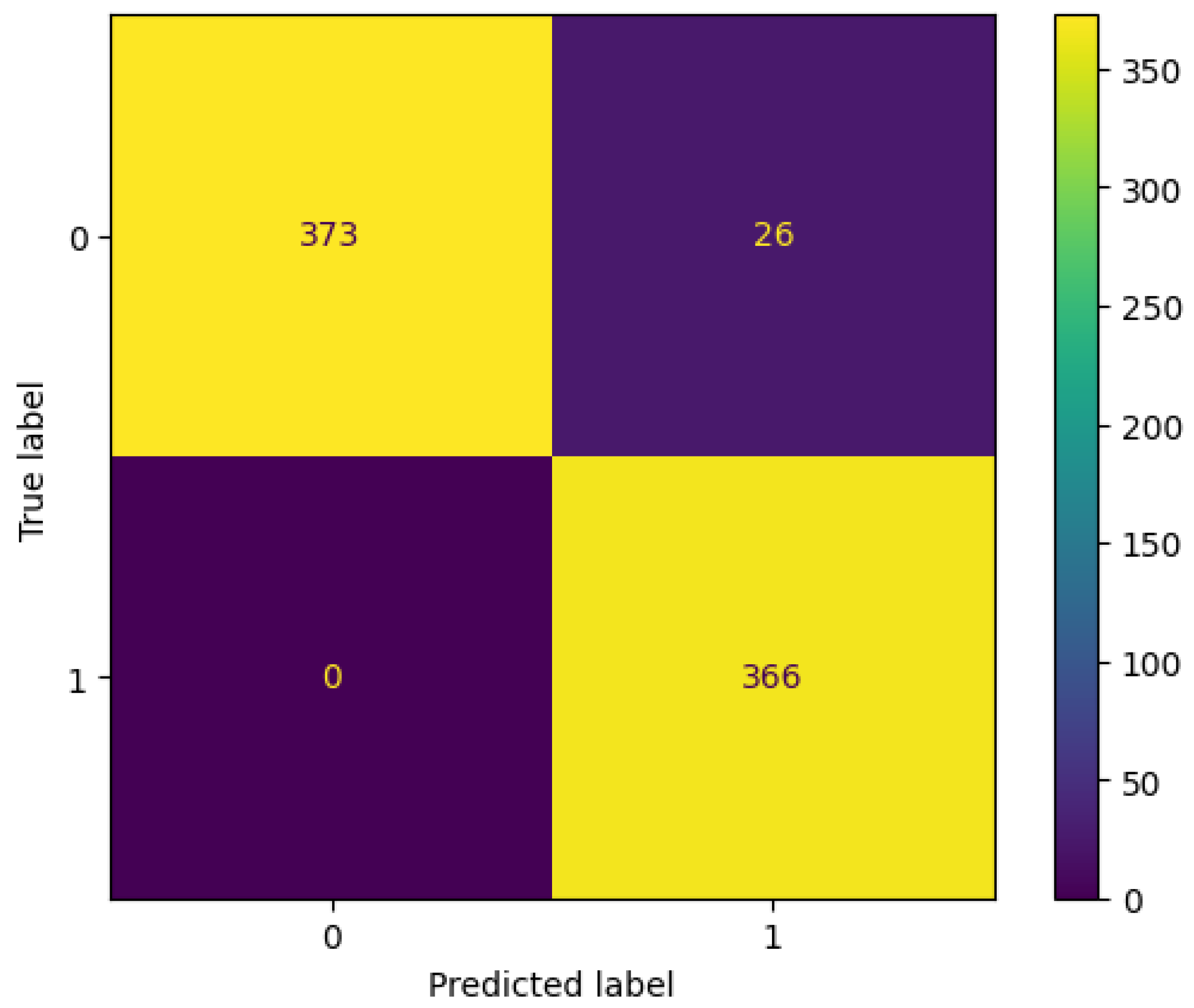
3.1. Without Feature Selection
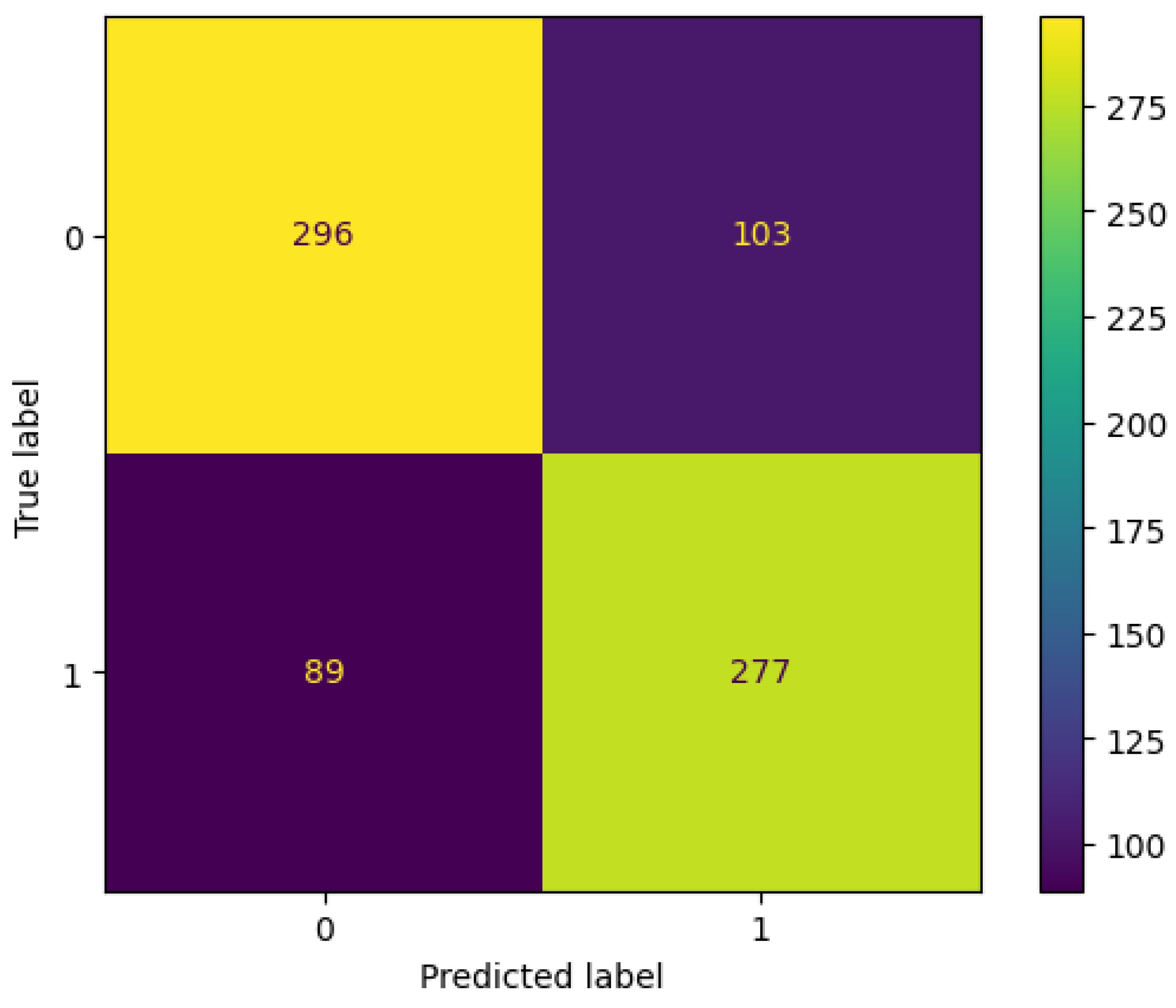
3.2. Using Only Clinical Predictors
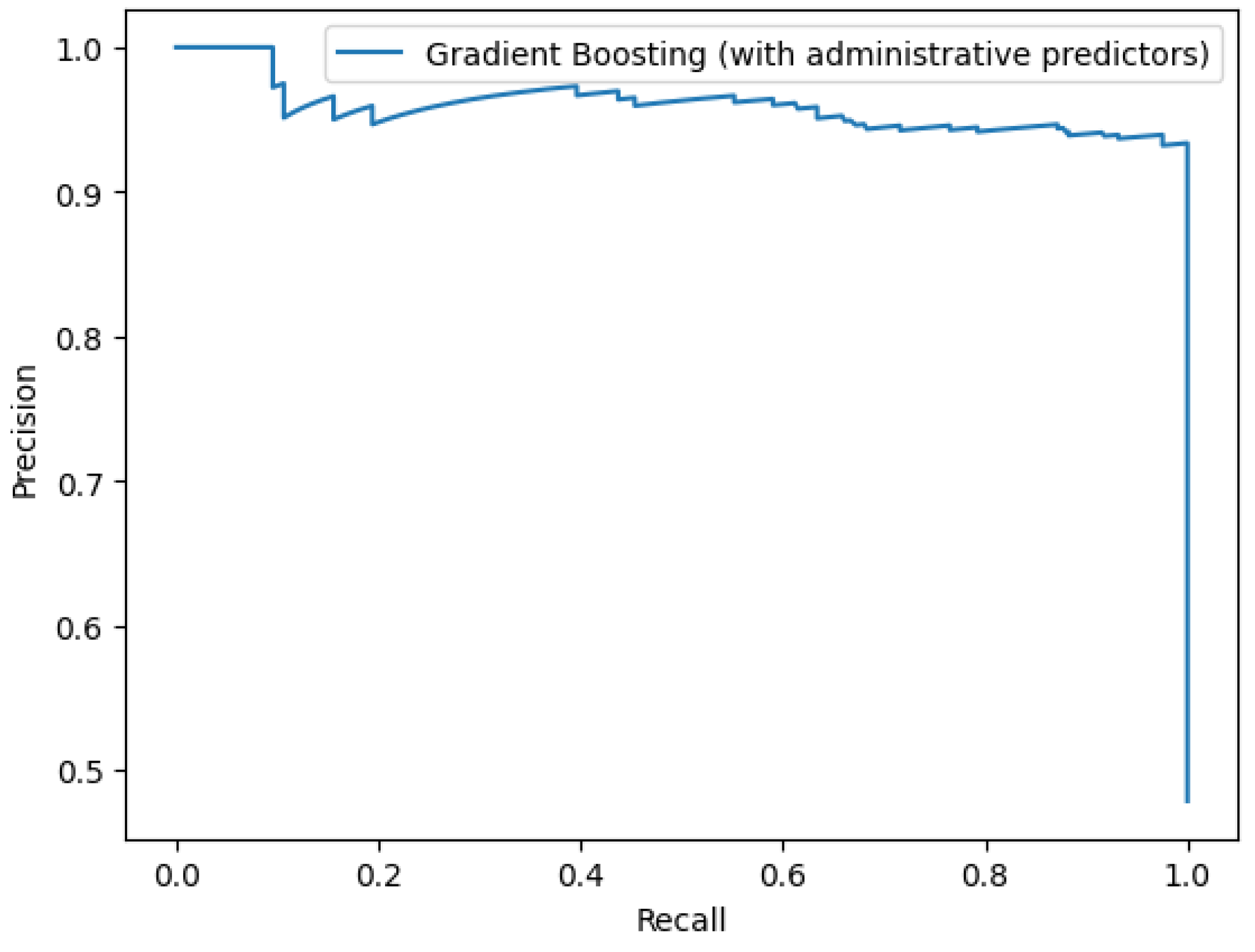
3.3. Using Only Demographic and Administrative Predictors
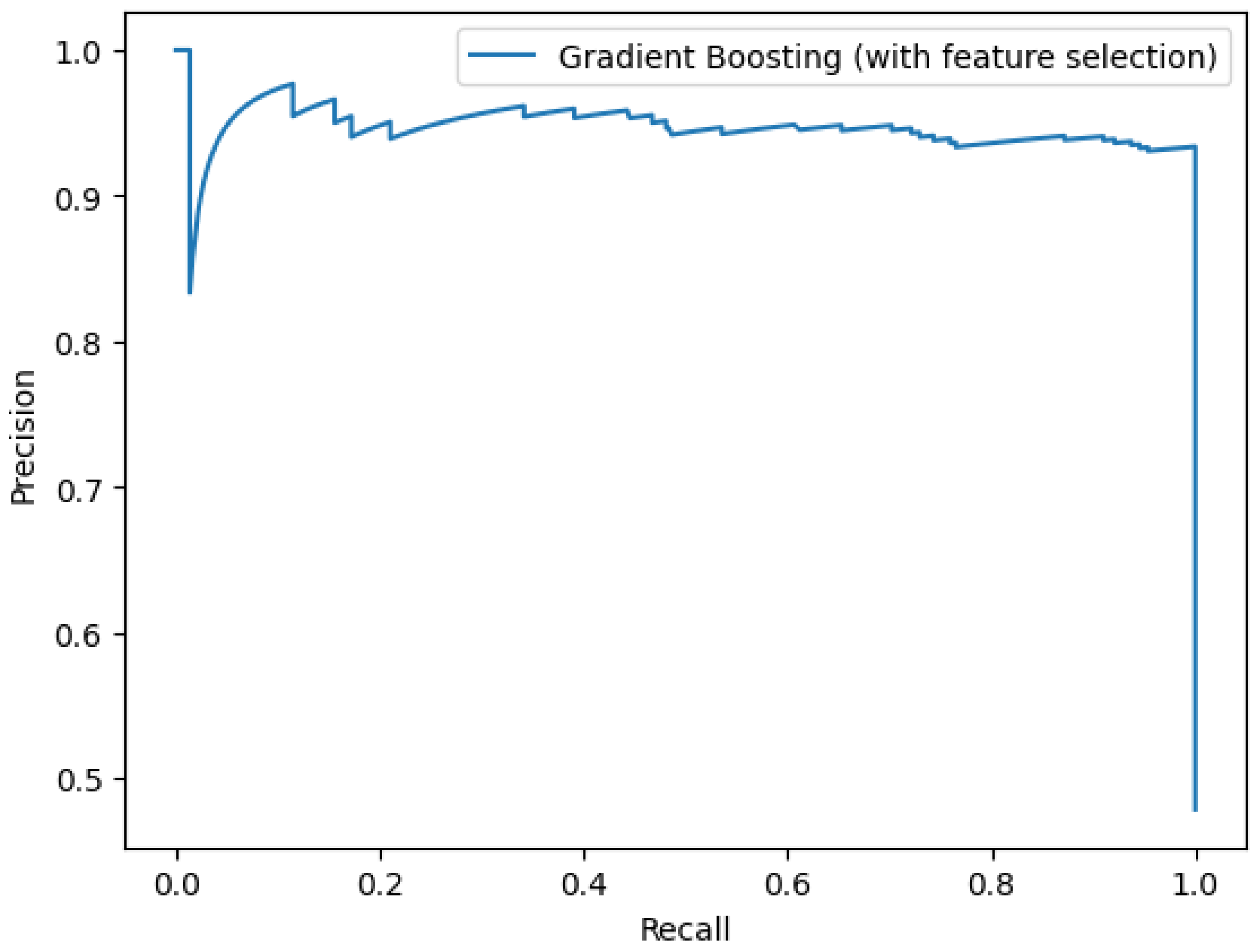
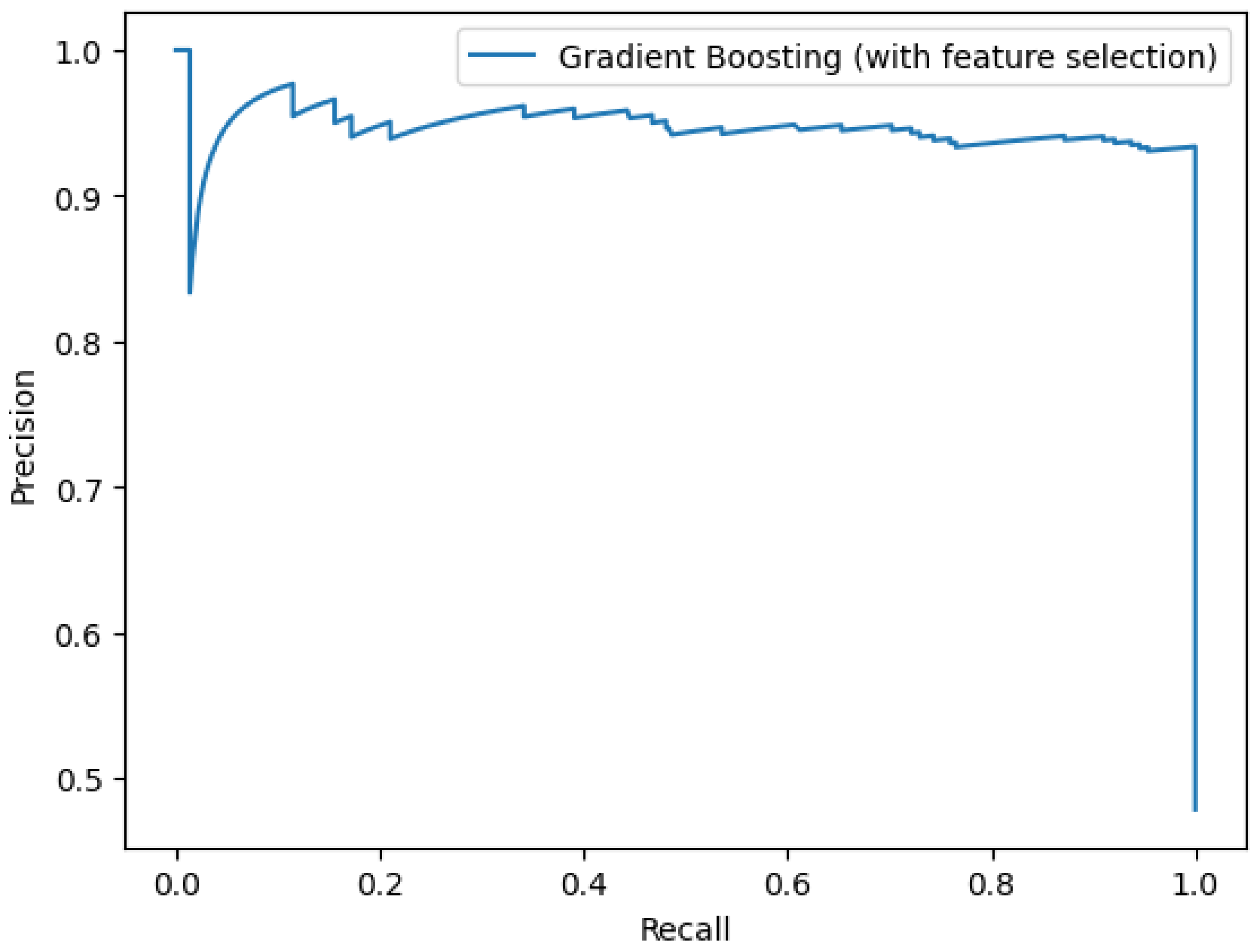
3.4. Feature Selection Using Statistical Tests
3.5. Performance of Top Selected Features and Administrative Data without the “Number of Hospital Admissions”
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Weiss, A.J.; Jiang, H.J. Overview of Clinical Conditions with Frequent and Costly Hospital Readmissions by Payer, 2018; Agency for Healthcare Research and Quality: Rockville, MD, USA, 2021.
- Liechti, F.D.; Bütikofer, L.; Mancinetti, M.; Leuppi, J.D.; Genné, D.; John, G.; Donzé, J.D. Factors associated with one-year mortality after hospital discharge: A multicenter prospective cohort study. PLoS ONE 2023, 18, e0288842. [Google Scholar] [CrossRef] [PubMed]
- Rubens, M.; Ramamoorthy, V.; Saxena, A.; Ruiz-Pelaez, J.G.; Ahmed, M.A.; Zhang, Z.; McGranaghan, P.; Chaparro, S.; Jimenez, J. Association Between Frailty, 30-day Unplanned Readmission and Mortality After Hospitalization for Heart Failure: Results From the Nationwide Readmissions Database. J. Aging Health 2023, 35, 08982643231152694. [Google Scholar] [CrossRef] [PubMed]
- Glans, M.; Kragh Ekstam, A.; Jakobsson, U.; Bondesson, Å.; Midlöv, P. Risk factors for hospital readmission in older adults within 30 days of discharge–a comparative retrospective study. BMC Geriatr. 2020, 20, 467. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Cheng, K.; Ku, K.; Li, J.; Hu, H.; Ung, C.O.L. Modelling 30-day hospital readmission after discharge for COPD patients based on electronic health records. NPJ Prim. Care Respir. Med. 2023, 33, 16. [Google Scholar] [CrossRef] [PubMed]
- Zhu, D.; Ding, R.; Ma, Y.; Chen, Z.; Shi, X.; He, P. Comorbidity in lung cancer patients and its association with hospital readmission and fatality in China. BMC Cancer 2021, 21, 557. [Google Scholar] [CrossRef] [PubMed]
- Bowles, K.H.; Murtaugh, C.M.; Jordan, L.; Barrón, Y.; Mikkelsen, M.E.; Whitehouse, C.R.; Chase, J.A.D.; Ryvicker, M.; Feldman, P.H. Sepsis survivors transitioned to home health care: Characteristics and early readmission risk factors. J. Am. Med. Dir. Assoc. 2020, 21, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Deschepper, M.; Eeckloo, K.; Vogelaers, D.; Waegeman, W. A hospital wide predictive model for unplanned readmission using hierarchical ICD data. Comput. Methods Programs Biomed. 2019, 173, 177–183. [Google Scholar] [CrossRef] [PubMed]
- Lo, Y.T.; Liao, J.C.; Chen, M.H.; Chang, C.M.; Li, C.T. Predictive modeling for 14-day unplanned hospital readmission risk by using machine learning algorithms. BMC Med. Inform. Decis. Mak. 2021, 21, 288. [Google Scholar] [CrossRef]
- Mohanty, S.D.; Lekan, D.; McCoy, T.P.; Jenkins, M.; Manda, P. Machine learning for predicting readmission risk among the frail: Explainable AI for healthcare. Patterns 2022, 3, 100395. [Google Scholar] [CrossRef] [PubMed]
- Gruneir, A.; Dhalla, I.A.; van Walraven, C.; Fischer, H.D.; Camacho, X.; Rochon, P.A.; Anderson, G.M. Unplanned readmissions after hospital discharge among patients identified as being at high risk for readmission using a validated predictive algorithm. Open Med. 2011, 5, e104. [Google Scholar] [PubMed]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.w.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed]
- Charlson, M.; Szatrowski, T.P.; Peterson, J.; Gold, J. Validation of a combined comorbidity index. J. Clin. Epidemiol. 1994, 47, 1245–1251. [Google Scholar] [CrossRef] [PubMed]
- D’Hoore, W.; Sicotte, C.; Tilquin, C. Risk adjustment in outcome assessment: The Charlson comorbidity index. Methods Inf. Med. 1993, 32, 382–387. [Google Scholar]
- Kingsford, C.; Salzberg, S.L. What are decision trees? Nat. Biotechnol. 2008, 26, 1011–1013. [Google Scholar] [CrossRef] [PubMed]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In Proceedings of the on the Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE: OTM Confederated International Conferences, CoopIS, DOA, and ODBASE 2003, Catania, Sicily, Italy, 3–7 November 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Liu, Y.; Wang, Y.; Zhang, J. New machine learning algorithm: Random forest. In Proceedings of the Information Computing and Applications: Third International Conference, ICICA 2012, Chengde, China, 14–16 September 2012; Proceedings 3; Springer: Berlin/Heidelberg, Germany, 2012; pp. 246–252. [Google Scholar]
- Semenick, D. Tests and measurements: The T-test. Strength Cond. J. 1990, 12, 36–37. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | All (%) | Readmitted (%) | Not Readmitted (%) |
|---|---|---|---|
| Gender | |||
| Male | 2140 (56%) | 1083 (56.67%) | 1057 (55.31%) |
| Female | 1682 (44%) | 828 (43.32%) | 854 (44.68%) |
| Age (years) | |||
| Mean | 63.40 | 64.28 | 62.52 |
| Median | 66 | 66 | 65 |
| LOS (days) | |||
| Mean | 11.05 | 11.85 | 10.26 |
| Median | 8.38 | 9.48 | 7.18 |
| NoH-12 | |||
| No | 1775 (46.44%) | - | 1775 (92.89%) |
| 1–3 | 1831 (47.90%) | 1697 (88.80%) | 134 (7.01%) |
| 4+ | 216 (5.65%) | 214 (11.20%) | 2 (0.1%) |
| Comorbidity (CCI) | |||
| No | 1042 (27.26%) | 276 (14.44%) | 766 (40.08%) |
| 1–2 | 1082 (28.3%) | 496 (25.58%) | 586 (30.65%) |
| 3–4 | 978 (25.58) | 621 (32.48%) | 357 (18.68%) |
| 5+ | 720 (18.83%) | 518 (27.10%) | 202 (10.57%) |
| Model | Average Precision | ROC-AUC |
|---|---|---|
| With all features | ||
| KNN | 80.1% | 74.3% |
| Decision Tree | 95.6% | 96.9% |
| Random Forests | 94% | 96.4% |
| Gradient Boosting | 95.6% | 97.3% |
| XGBoost | 95.3% | 97.3% |
| With clinical predictors | ||
| KNN | 76.7% | 72% |
| Decision Tree | 74.5% | 71.5% |
| Random Forests | 76% | 75.2% |
| Gradient Boosting | 80.4% | 83.7% |
| XGBoost | 77.9% | 80.1% |
| With administrative predictors | ||
| KNN | 94.4% | 94.6% |
| Decision Tree | 95.1% | 96.9% |
| Random Forests | 93.7% | 96.5% |
| Gradient Boosting | 95.9% | 97.6% |
| XGBoost | 95.3% | 97.5% |
| With statistical feature selection (K = 20) | ||
| KNN | 84.8% | 79.1% |
| Decision Tree | 95.4% | 96.3% |
| Random Forests | 93.2% | 96.2% |
| Gradient Boosting | 95.2% | 97.4% |
| XGBoost | 93.8% | 96.9% |
| With statistical feature selection (K = 15) | ||
| KNN | 85.9% | 81.6% |
| Decision Tree | 96.4% | 96.3% |
| Random Forests | 93.4% | 96.3% |
| Gradient Boosting | 94.7% | 97.3% |
| XGBoost | 94.4% | 97.1% |
| With statistical feature selection (K = 10) | ||
| KNN | 88.4% | 83.8% |
| Decision Tree | 95.4% | 96.3% |
| Random Forests | 94.4% | 96.6% |
| Gradient Boosting | 95.6% | 97.5% |
| XGBoost | 94.8% | 97.4% |
| With statistical feature selection (K = 5) | ||
| KNN | 94.0% | 95.7% |
| Decision Tree | 95.5% | 96.7% |
| Random Forests | 94.1% | 96.2% |
| Gradient Boosting | 95.3% | 97.2% |
| XGBoost | 94.7% | 97.0% |
| Variables | p-Value |
|---|---|
| Number of hospital admissions | |
| Hyperosmolarity | |
| Charlson Comorbidity Index | |
| Respiratory failure | |
| Renal disease | |
| Anemia | |
| Circulatory system disease | |
| Pneumonia | |
| Urinary infection | |
| Heart disease | |
| Septicemia | |
| Coagulation disorder | |
| Pulmonary circulation disease | |
| Intestinal disease | |
| Hypertensive chronic kidney disease | |
| Chronic rheumatic heart disease | |
| Fluid disorder |
| Model | Average Precision | ROC-AUC |
|---|---|---|
| With statistical feature selection (K = 15) | ||
| KNN | 77.8% | 73.6% |
| Decision Tree | 76.1% | 70.8% |
| Random Forests | 72.4% | 71.0% |
| Gradient Boosting | 81.6% | 83.4% |
| XGBoost | 79.1% | 80.1% |
| With administrative features | ||
| KNN | 63.0% | 64.5% |
| Decision Tree | 65.2% | 67.3% |
| Random Forests | 60.8% | 62.1% |
| Gradient Boosting | 65.1% | 71.2% |
| XGBoost | 63.1% | 68.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dafrallah, S.; Akhloufi, M.A. Factors Associated with Unplanned Hospital Readmission after Discharge: A Descriptive and Predictive Study Using Electronic Health Record Data. BioMedInformatics 2024, 4, 219-235. https://doi.org/10.3390/biomedinformatics4010014
Dafrallah S, Akhloufi MA. Factors Associated with Unplanned Hospital Readmission after Discharge: A Descriptive and Predictive Study Using Electronic Health Record Data. BioMedInformatics. 2024; 4(1):219-235. https://doi.org/10.3390/biomedinformatics4010014
Chicago/Turabian StyleDafrallah, Safaa, and Moulay A. Akhloufi. 2024. "Factors Associated with Unplanned Hospital Readmission after Discharge: A Descriptive and Predictive Study Using Electronic Health Record Data" BioMedInformatics 4, no. 1: 219-235. https://doi.org/10.3390/biomedinformatics4010014
APA StyleDafrallah, S., & Akhloufi, M. A. (2024). Factors Associated with Unplanned Hospital Readmission after Discharge: A Descriptive and Predictive Study Using Electronic Health Record Data. BioMedInformatics, 4(1), 219-235. https://doi.org/10.3390/biomedinformatics4010014