

NJN: A Dataset for the Normal and Jaundiced Newborns


Abstract
:1. Introduction
2. Methods and Materials
2.1. Ethics Considerations
2.2. Data Description
2.3. Artificial Intelligence Techniques
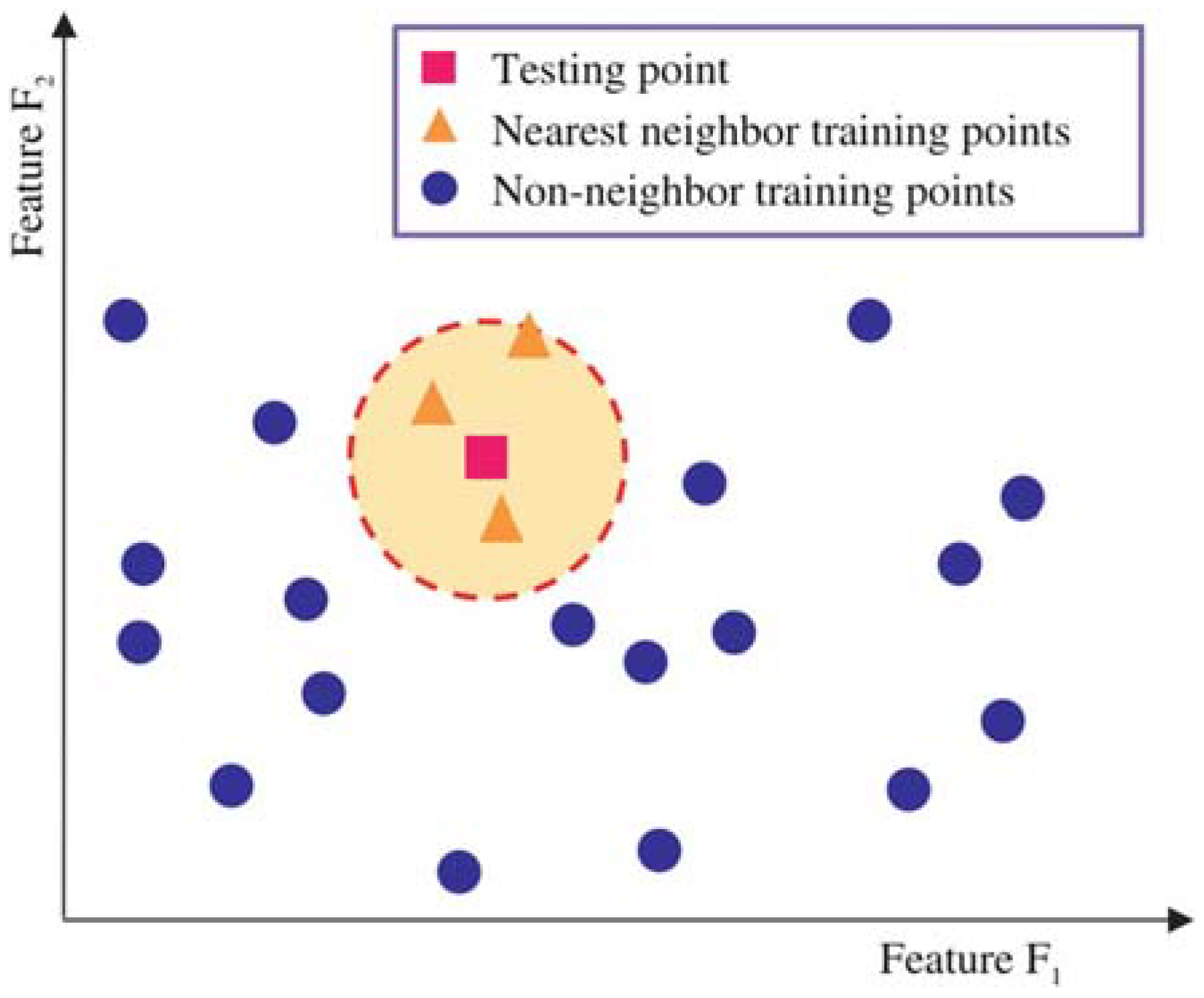
2.3.1. k-Nearest Neighbor
2.3.2. Random Forest
2.3.3. XGBoost
2.4. Evaluation Metrics
3. Results and Discussion
4. User Notes
- Images of normal and jaundiced neonates are scarce online and not easily accessible;
- Professional healthcare developers working in the AI field can benefit from these data;
- Other researchers in biomedical engineering and computer science can also use the provided images in skin color analysis for neonates to diagnose jaundice or other skin conditions;
- The provided images comprise 560 normal and 200 jaundiced infants;
- The images are in jpg format with 1000 × 1000 resolution;
- An Excel sheet in CSV (comma delimited) format is given that contains RGB and YCbCr channel values for all the provided images.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dzulkifli, F.A.; Mashor, M.Y.; Khalid, K. Methods for determining bilirubin level in neonatal jaundice screening and monitoring: A literature review. J. Eng. Res. Educ. 2018, 10, 1–10. [Google Scholar]
- Brits, H.; Adendorff, J.; Huisamen, D.; Beukes, D.; Botha, K.; Herbst, H.; Joubert, G. The prevalence of neonatal jaundice and risk factors in healthy term neonates at National District Hospital in Bloemfontein. Afr. J. Prim. Health Care Fam. Med. 2018, 10, e1–e6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhutani, V.; Zipursky, A.; Blencowe, H.; Khanna, R.; Sgro, M.; Ebbesen, F.; Bell, J.; Mori, R.; Slusher, T.; Fahmy, N.; et al. Neonatal hyperbilirubinemia and rhesus disease of the newborn: Incidence and impairment estimates for 2010 at regional and global levels. Pediatr. Res. 2013, 74, 86–100. [Google Scholar] [CrossRef] [Green Version]
- Mishra, S.; Agarwal, R.; Deorari, A.K.; Paul, V.K. Jaundice in the newborns. Indian J. Pediatr. 2008, 75, 157–163. [Google Scholar] [CrossRef]
- Pediatrics, A. Management of hyperbilirubinemia in the newborn infant 35 or more weeks of gestation. Am. Acad. Pediatr. 2004, 114, 297–316. [Google Scholar]
- Mantagou, L.; Fouzas, S.; Skylogianni, E.; Giannakopoulos, I.; Karatza, A.; Varvarigou, A. Trends of transcutaneous bilirubin in neonates who develop significant hyperbilirubinemia. Pediatrics 2012, 130, e898–e904. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdulrazzak, A.Y.; Mohammed, S.L.; Al-Naji, A.; Chahl, J. Computer-Aid System for Automated Jaundice Detection. J. Tech. 2023, 5, 8–15. [Google Scholar] [CrossRef]
- Leartveravat, S. Transcutaneous bilirubin measurement in full term neonate by digital camera. Med. J. Srisaket Surin Buriram Hosp. 2009, 24, 105–118. [Google Scholar]
- Mansor, M.; Yaacob, S.; Hariharan, M.; Basah, S.; Jamil, S.A.; Khidir, M.M.; Rejab, M.; Ibrahim, K.K.; Jamil, A.A.; Junoh, A. Jaundice in newborn monitoring using color detection method. Procedia Eng. 2012, 29, 1631–1635. [Google Scholar] [CrossRef] [Green Version]
- Leung, T.S.; Kapur, K.; Guilliam, A.; Okell, J.; Lim, B.; MacDonald, L.W.; Meek, J. Screening neonatal jaundice based on the sclera color of the eye using digital photography. Biomed. Opt. Express 2015, 6, 4529–4538. [Google Scholar] [CrossRef] [Green Version]
- Munkholm, S.B.; Krøgholt, T.; Ebbesen, F.; Szecsi, P.B.; Kristensen, S.R. The smartphone camera as a potential method for transcutaneous bilirubin measurement. PLoS ONE 2018, 13, e0197938. [Google Scholar] [CrossRef] [Green Version]
- Juliastuti, E.; Nadhira, V.; Satwika, Y.W.; Aziz, N.A.; Zahra, N. Risk zone estimation of newborn jaundice based on skin color image analysis. In Proceedings of the 2019 6th International Conference on Instrumentation, Control, and Automation (ICA), Bandung, Indonesia, 31 July–2 August 2019; pp. 176–181. [Google Scholar]
- Padidar, P.; Shaker, M.; Amoozgar, H.; Khorraminejad-Shirazi, M.; Hemmati, F.; Najib, K.S.; Pourarian, S. Detection of neonatal jaundice by using an android OS-based smartphone application. Iran. J. Pediatr. 2019, 29, e84397. [Google Scholar] [CrossRef] [Green Version]
- Aydın, M.; Hardalaç, F.; Ural, B.; Karap, S. Neonatal jaundice detection system. J. Med. Syst. 2016, 40, 166. [Google Scholar] [CrossRef]
- Hashim, W.; Al-Naji, A.; Al-Rayahi, I.A.; Oudah, M. Computer vision for jaundice detection in neonates using graphic user interface. In IOP Conference Series: Materials Science and Engineering, Proceedings of the Fifth Scientific Conference for Engineering and Postgraduate Research (PEC 2020), Baghdad, Iraq, 21–22 December 2020; IOP Science: Bristol, UK, 2021; p. 012076. [Google Scholar]
- Hashim, W.; Al-Naji, A.; Al-Rayahi, I.A.; Alkhaled, M.; Chahl, J. Neonatal Jaundice Detection Using a Computer Vision System. Designs 2021, 5, 63. [Google Scholar] [CrossRef]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In On the Move to Meaningful Internet Systems, Proceedings of the OTM Confederated International Conferences, CoopIS, DOA, and ODBASE 2003, Catania, Italy, 3–7 November 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Hu, C.; Jain, G.; Zhang, P.; Schmidt, C.; Gomadam, P.; Gorka, T. Data-driven method based on particle swarm optimization and k-nearest neighbor regression for estimating capacity of lithium-ion battery. Appl. Energy 2014, 129, 49–55. [Google Scholar] [CrossRef]
- Nguyen, H.; Bui, X.-N.; Bui, H.-B.; Cuong, D.T. Developing an XGBoost model to predict blast-induced peak particle velocity in an open-pit mine: A case study. Acta Geophys. 2019, 67, 477–490. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Kabiraj, S.; Raihan, M.; Alvi, N.; Afrin, M.; Akter, L.; Sohagi, S.A.; Podder, E. Breast cancer risk prediction using XGBoost and random forest algorithm. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–4. [Google Scholar]
- Ramraj, S.; Uzir, N.; Sunil, R.; Banerjee, S. Experimenting XGBoost algorithm for prediction and classification of different datasets. Int. J. Control. Theory Appl. 2016, 9, 651–662. [Google Scholar]
- Malik, S.; Harode, R.; Kunwar, A. XGBoost: A deep dive into boosting. Simon Fraser Univ. 2020, 1–21. [Google Scholar]
- Kramer, O.; Kramer, O. K-nearest neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control. Eng. 2014, 2, 602–609. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T. Xgboost: Extreme Gradient Boosting; R Package Version 0.4–2; R Package, 2015. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Description |
|---|---|
| Beneficiaries | Biomedical Engineers and Computer Science researchers. |
| Specific subject area | AI for neonatal jaundice and skin diseases. |
| Type of data | Images and Excel sheet in CSV format for RGB and YCrCb channel values and the status of each row. |
| How data were acquired | Images were taken with an iPhone 11 pro max camera. |
| Data format | Jpg format. |
| Parameters for data collection | Images were taken from different angles and lighting conditions. |
| Description of data collection | Images were collected from the NICU for 600 aseptic normal and jaundiced neonates. |
| Data source location | NICU ward in Al-Elwiya Maternity Teaching Hospital in Al Rusafa, Baghdad, Iraq. |
| Data accessibility | The dataset is freely accessible at (https://zenodo.org/record/7825810#.ZDgONrpBy3A (1 June 2023). |
| Technique | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| KNN | 95.4% | 96% | 95% | 96% |
| RF | 97.3% | 97% | 97% | 97% |
| XGboot | 98.6% | 99% | 99% | 99% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulrazzak, A.Y.; Mohammed, S.L.; Al-Naji, A. NJN: A Dataset for the Normal and Jaundiced Newborns. BioMedInformatics 2023, 3, 543-552. https://doi.org/10.3390/biomedinformatics3030037
Abdulrazzak AY, Mohammed SL, Al-Naji A. NJN: A Dataset for the Normal and Jaundiced Newborns. BioMedInformatics. 2023; 3(3):543-552. https://doi.org/10.3390/biomedinformatics3030037
Chicago/Turabian StyleAbdulrazzak, Ahmad Yaseen, Saleem Latif Mohammed, and Ali Al-Naji. 2023. "NJN: A Dataset for the Normal and Jaundiced Newborns" BioMedInformatics 3, no. 3: 543-552. https://doi.org/10.3390/biomedinformatics3030037
APA StyleAbdulrazzak, A. Y., Mohammed, S. L., & Al-Naji, A. (2023). NJN: A Dataset for the Normal and Jaundiced Newborns. BioMedInformatics, 3(3), 543-552. https://doi.org/10.3390/biomedinformatics3030037